Google Gemma 4 telah resmi dirilis, dengan lisensi sumber terbuka penuh Apache 2.0 untuk pertama kalinya, serta menghadirkan 4 model yang mencakup skenario komputasi lengkap mulai dari Raspberry Pi hingga pusat data. Sebagai versi sumber terbuka dari teknologi yang sama dengan Gemini 3, Gemma 4 telah mencapai peningkatan yang jauh melampaui Gemma 3 dalam hal penalaran, pengodean, visual, dan jendela konteks yang panjang.
Nilai Inti: Setelah membaca artikel ini, Anda akan menguasai pemilihan 4 model Gemma 4, inovasi arsitektur inti, batasan kemampuan multimodal, serta persyaratan perangkat keras untuk penerapan lokal.

Ringkasan Informasi Inti Gemma 4
Gemma 4 dirilis pada 2 April 2026 di Google Cloud Next, dibangun berdasarkan penelitian yang sama dengan Gemini 3, dan merupakan produk generasi keempat dari keluarga model sumber terbuka Google.
| Item Informasi | Detail |
|---|---|
| Waktu Rilis | 2 April 2026 |
| Jumlah Model | 4 (E2B / E4B / 26B-A4B / 31B) |
| Lisensi | Apache 2.0 (Pertama kali, sebelumnya menggunakan lisensi milik Google) |
| Konteks Maksimum | 256K token (31B dan 26B-A4B) |
| Multimodal | Teks + Gambar + Video + Audio (E2B/E4B) |
| Sorotan Arsitektur | Varian MoE pertama, teknologi PLE, atensi campuran |
| Platform Tersedia | Hugging Face, Google AI Studio, Vertex AI, Ollama, dll. |
Sekilas 4 Model Gemma 4
| Model | Parameter Efektif | Total Parameter | Arsitektur | Konteks | Multimodal |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Dense | 128K | Teks+Gambar+Video+Audio |
| Gemma 4 E4B | 4.5B | 8B | Dense | 128K | Teks+Gambar+Video+Audio |
| Gemma 4 26B-A4B | 3.8B aktif | 25.2B | MoE | 256K | Teks+Gambar+Video |
| Gemma 4 31B | 30.7B | 30.7B | Dense | 256K | Teks+Gambar+Video |
Aturan Penamaan: Awalan "E" mewakili "Effective Parameters" (parameter efektif), karena teknologi PLE menyebabkan total parameter lebih besar daripada parameter efektif. 26B-A4B menunjukkan arsitektur MoE dengan total parameter 26B dan parameter aktif 4B per token.
🎯 Saran Teknis: Keempat model Gemma 4 mencakup semua skenario mulai dari perangkat edge hingga inferensi cloud. Jika Anda perlu membandingkan performa antar berbagai model sumber terbuka, disarankan untuk mengaksesnya melalui platform APIYI apiyi.com untuk beralih dan mengevaluasi model yang berbeda dengan cepat.
Perbandingan Performa Gemma 4 vs Gemma 3: Peningkatan Antargenerasi Terbesar dalam Sejarah
Google secara resmi menyatakan bahwa Gemma 4 adalah "peningkatan performa satu generasi terbesar dalam dunia model sumber terbuka". Data tolok ukur (benchmark) sepenuhnya mendukung klaim tersebut.
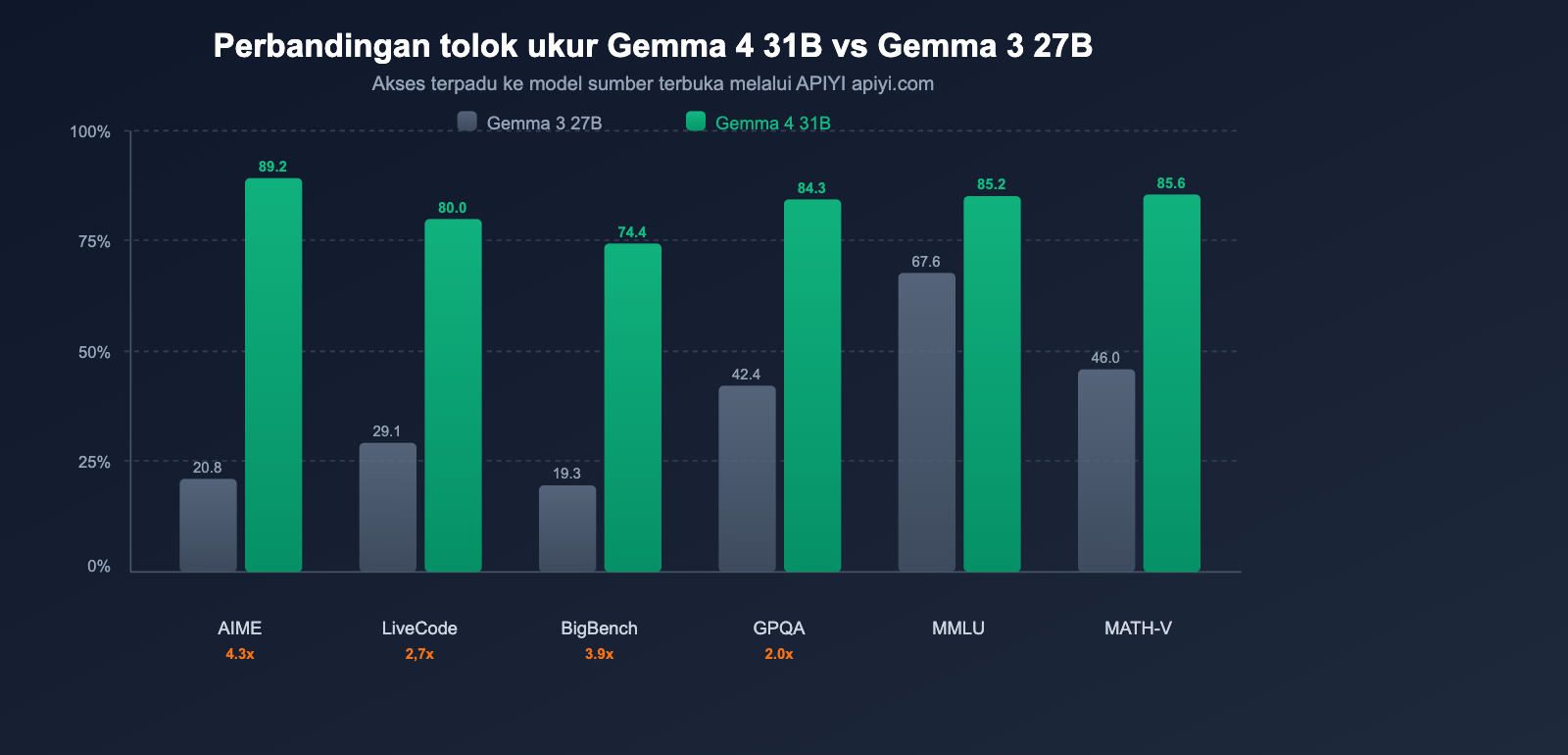
Perbandingan Tolok Ukur Inti
| Tolok Ukur | Gemma 3 27B | Gemma 4 31B | Peningkatan |
|---|---|---|---|
| AIME 2026 (Penalaran Matematika) | 20.8% | 89.2% | +68.4 pts (4.3x) |
| LiveCodeBench v6 (Coding) | 29.1% | 80.0% | +50.9 pts (2.7x) |
| BigBench Extra Hard (Penalaran) | 19.3% | 74.4% | +55.1 pts (3.9x) |
| GPQA Diamond (Penalaran Ilmiah) | 42.4% | 84.3% | +41.9 pts (2.0x) |
| MMLU Pro (Pengetahuan) | 67.6% | 85.2% | +17.6 pts |
| MATH-Vision (Matematika Visual) | 46.0% | 85.6% | +39.6 pts |
| MRCR 128K (Jendela Konteks Panjang) | 13.5% | 66.4% | +52.9 pts |
Temuan Utama: Penalaran matematika AIME melonjak dari 20,8% menjadi 89,2%, meningkat 4,3 kali lipat; coding LiveCodeBench dari 29,1% menjadi 80,0%, meningkat 2,7 kali lipat. Ini bukan peningkatan bertahap, melainkan lompatan antargenerasi.
Data Tolok Ukur Lengkap 4 Model
| Tolok Ukur | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (Visual) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
Keunggulan Efisiensi MoE: 26B-A4B hanya menggunakan 3,8B parameter aktif untuk mencapai sekitar 97% performa model 31B Dense, sehingga biaya pemanggilan model jauh lebih rendah. Di LMArena, 26B-A4B (~1441 ELO) bahkan melampaui gpt-oss-120B milik OpenAI.
💡 Saran Pemilihan: Pilih 31B untuk performa maksimal, atau 26B-A4B untuk efisiensi biaya (97% performa hanya dengan 12% parameter aktif). Melalui platform APIYI apiyi.com, Anda dapat dengan cepat membandingkan performa aktual kedua versi ini dalam skenario bisnis spesifik Anda.
6 Inovasi Arsitektur Inti Gemma 4
Gemma 4 memperkenalkan serangkaian teknologi inovatif di tingkat arsitektur, yang menjadi alasan utama di balik lompatan performanya.

Teknik 1: Per-Layer Embeddings (PLE)
PLE menambahkan jalur kondisional paralel di luar aliran residual utama, yang menghasilkan vektor token khusus untuk setiap lapisan decoder. Teknologi ini meningkatkan kemampuan ekspresi model kecil, sehingga E2B dengan 2,3 miliar parameter efektif mampu mencapai performa yang jauh melampaui jumlah parameternya.
Teknik 2: Perhatian Hibrida (Hybrid Attention)
Menggunakan kombinasi antara lapisan perhatian jendela geser lokal dan perhatian konteks penuh global secara bergantian:
- Lapisan jendela geser: Menangani konteks lokal (E2B/E4B: 512 token; 31B/26B: 1024 token)
- Lapisan perhatian global: Menangani cakupan konteks penuh
Desain hibrida ini secara signifikan mengurangi beban komputasi sambil tetap mempertahankan kemampuan konteks panjang.
Teknik 3: Pengodean Posisi Dual RoPE
- Lapisan jendela geser menggunakan RoPE standar
- Lapisan perhatian global menggunakan Proportional RoPE
Desain dual RoPE ini memungkinkan konteks 256K tanpa mengorbankan kualitas.
Teknik 4: Cache KV Bersama (Shared KV Cache)
N lapisan terakhir menggunakan kembali tensor K/V dari lapisan non-bersama terakhir yang sejenis, sehingga secara drastis mengurangi jumlah komputasi dan penggunaan memori video (VRAM). Ini adalah salah satu teknologi kunci yang memungkinkan Gemma 4 menjalankan Model Bahasa Besar pada perangkat keras konsumen.
Teknik 5: MoE (Mixture of Experts) (26B-A4B)
Gemma 4 untuk pertama kalinya memperkenalkan varian MoE:
- 128 pakar kecil
- Mengaktifkan 8 pakar + 1 pakar bersama per token
- Mencapai sekitar 97% performa dari 31B Dense dengan parameter aktif 3,8B
Teknik 6: Multimodal Asli
Kemampuan visual dan audio diintegrasikan langsung pada tahap pra-pelatihan:
- Encoder visual: E2B/E4B ~150M parameter; 31B/26B ~550M parameter
- Encoder audio: Conformer gaya USM, ~300M parameter (hanya E2B/E4B)
- Mendukung gambar dengan rasio aspek variabel, dengan anggaran token yang dapat dikonfigurasi (70-1120 token)
Penjelasan Mendalam Kemampuan Multimodal dan Agen Gemma 4
Gemma 4 bukan sekadar model percakapan biasa, melainkan sistem multimodal yang dilengkapi dengan kemampuan Agen penuh.
Kemampuan Input Multimodal
| Modalitas | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| Teks | ✅ | ✅ | ✅ | ✅ |
| Gambar | ✅ | ✅ | ✅ | ✅ |
| Video (maks. 60 detik, 1fps) | ✅ | ✅ | ✅ | ✅ |
| Audio (maks. 30 detik) | ✅ | ✅ | ❌ | ❌ |
Kemampuan visual mencakup:
- Deteksi objek dan output kotak pembatas (format JSON asli)
- Deteksi dan penunjukan elemen GUI
- Analisis dokumen/PDF, pemahaman diagram
- Pemahaman layar/antarmuka UI
- Input silang teks-gambar (campuran dalam urutan apa pun)
Pemanggilan Fungsi Asli dan Kemampuan Agen
Gemma 4 memiliki kemampuan pemanggilan fungsi bawaan sejak tahap pelatihan, bukan ditambahkan melalui fine-tuning di tahap akhir:
- Pemanggilan Fungsi Asli: Dioptimalkan langsung pada tahap pelatihan, mendukung orkestrasi multi-alat.
- Extended Thinking: Dapat mengaktifkan penalaran multi-langkah melalui
enable_thinking=True. - Output Terstruktur: Output JSON asli, cocok untuk integrasi API.
- Alur Agen Multi-putaran: Mendukung siklus Agen otonom dengan alur rencana-eksekusi-observasi.
# Contoh pemanggilan fungsi Gemma 4 (melalui antarmuka terpadu APIYI)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Mendapatkan cuaca di kota tertentu",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "Bagaimana cuaca di Beijing hari ini?"}],
tools=tools,
tool_choice="auto",
)
🚀 Mulai Cepat: Pemanggilan fungsi asli Gemma 4 menjadikannya pilihan ideal untuk membangun Agen AI. Disarankan menggunakan platform APIYI apiyi.com untuk akses cepat, mendukung antarmuka yang kompatibel dengan OpenAI tanpa perlu adaptasi tambahan.
Panduan Perangkat Keras untuk Deployment Lokal Gemma 4
Lisensi Apache 2.0 berarti Anda bebas melakukan deployment Gemma 4 pada perangkat keras apa pun. Berikut adalah kebutuhan perangkat keras untuk masing-masing model.
Sekilas Kebutuhan Perangkat Keras
| Model | Perangkat Keras Minimum | Skenario Deployment Umum |
|---|---|---|
| E2B (2.3B) | RAM <1.5GB | Raspberry Pi 5 (133 tok/s prefill, 7.6 tok/s decode) |
| E4B (4.5B) | NPU/GPU kelas ponsel | Perangkat seluler, Apple Silicon (MLX) |
| 26B-A4B (MoE) | Satu GPU kelas konsumen (kuantisasi) | Workstation pribadi, server kecil |
| 31B (Dense) | Satu H100 80GB (FP16) | Inferensi cloud, pusat data |
Perangkat Keras dan Framework yang Didukung
| Perangkat Keras/Framework | Status Dukungan |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ Dukungan penuh seri |
| Google TPU (Trillium/Ironwood) | ✅ Optimasi asli |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ Didukung |
| Qualcomm NPU (IQ8) | ✅ Inferensi perangkat seluler |
| GGUF (llama.cpp/Ollama) | ✅ Kuantisasi 2-bit/4-bit |
| ONNX (WebGPU/Browser) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ Deployment kontainer |
E2B dapat berjalan di Raspberry Pi 5 dengan kecepatan dekode 7,6 token per detik, yang membuka kemungkinan baru untuk aplikasi AI di edge.
Lisensi Apache 2.0: Mengapa Kali Ini Berbeda
Gemma 4 untuk pertama kalinya mengadopsi lisensi Apache 2.0, sebuah perubahan yang sangat signifikan. Sebelumnya, semua model Gemma menggunakan perjanjian lisensi milik Google yang memiliki batasan penggunaan tertentu serta hak penghentian sepihak.
Perbandingan Lisensi
| Dimensi | Gemma 3 (Lisensi Google) | Gemma 4 (Apache 2.0) |
|---|---|---|
| Penggunaan Komersial | Dengan syarat terbatas | ✅ Sepenuhnya bebas |
| Modifikasi & Distribusi | Harus mematuhi klausul tambahan | ✅ Sepenuhnya bebas |
| Model Turunan | Terbatas | ✅ Sepenuhnya bebas |
| Hak Penghentian | Google berhak menghentikan | ❌ Tidak dapat dibatalkan |
| Lisensi Paten | Terbatas | ✅ Lisensi eksplisit |
Apache 2.0 berarti:
- Perusahaan dapat menggunakannya dalam produk komersial dengan tenang tanpa risiko hukum.
- Bebas melakukan penyesuaian (fine-tuning) dan mendistribusikan model turunan.
- Selaras dengan strategi sumber terbuka (open-source) dari Meta Llama dan DeepSeek.
- Menurunkan ambang batas kepatuhan secara signifikan bagi adopsi perusahaan.
💰 Optimasi Biaya: Apache 2.0 + penerapan lokal = nol biaya pemanggilan model. Untuk skenario dengan volume inferensi tinggi, penerapan lokal Gemma 4 mungkin jauh lebih ekonomis daripada pemanggilan API. Jika Anda perlu membandingkan efisiensi biaya antara penerapan lokal dan pemanggilan API, Anda bisa menggunakan platform APIYI apiyi.com untuk memvalidasi hasil terlebih dahulu sebelum memutuskan untuk melakukan penerapan lokal.
Cara Mendapatkan dan Memulai Cepat Model Gemma 4
Saluran Pengunduhan Model
| Platform | Model Tersedia | Kegunaan |
|---|---|---|
| Hugging Face | Keempat model (base + IT) | Unduhan umum, riset |
| Google AI Studio | 31B, 26B MoE | Uji coba daring gratis |
| Vertex AI | Keempat model | Penerapan tingkat perusahaan |
| Ollama / llama.cpp | Versi kuantisasi GGUF | Penerapan lokal cepat |
| Google AI Edge Gallery | E4B, E2B | Penerapan perangkat seluler |
Penerapan Sekali Klik dengan Ollama
# Menjalankan Gemma 4 31B (direkomendasikan)
ollama run gemma4:31b
# Menjalankan versi MoE (hemat biaya)
ollama run gemma4:26b-a4b
# Menjalankan versi ringan (perangkat edge)
ollama run gemma4:e4b
Dukungan Penyesuaian (Fine-tuning)
Gemma 4 menyediakan ekosistem penyesuaian yang lengkap:
| Kerangka Kerja | Metode yang Didukung |
|---|---|
| TRL | SFT, DPO, pembelajaran penguatan (termasuk multimodal) |
| PEFT | LoRA, QLoRA (via bitsandbytes) |
| Vertex AI | Pelatihan terkelola |
| Unsloth Studio | Penyesuaian berbasis UI |
Encoder visual dan audio dapat dibekukan, sehingga Anda hanya perlu menyesuaikan bagian teks, yang secara drastis mengurangi biaya penyesuaian.
🎯 Saran Teknis: Disarankan untuk menguji performa Gemma 4 melalui platform APIYI apiyi.com menggunakan metode API terlebih dahulu. Setelah yakin kebutuhan Anda terpenuhi, barulah lakukan penerapan lokal atau penyesuaian untuk menghindari pemborosan sumber daya.
Pertanyaan Umum
Q1: Apa hubungan antara Gemma 4 dan Gemini 3?
Gemma 4 dibangun berdasarkan penelitian yang sama dengan Gemini 3, jadi bisa dibilang ini adalah versi sumber terbuka (open-source) dari teknologi Gemini 3. Skala model Gemma 4 memang lebih kecil (maksimal 31B dibandingkan dengan ratusan miliar parameter pada Gemini), namun menggunakan inovasi arsitektur inti yang sama. Melalui platform APIYI apiyi.com, Anda bisa menggunakan Gemma 4 dan seri model Gemini secara bersamaan untuk melakukan perbandingan.
Q2: Bagaimana cara memilih antara 26B MoE dan 31B Dense?
Jika perangkat keras Anda terbatas atau membutuhkan throughput tinggi, pilih 26B-A4B MoE — model ini hanya menggunakan 3,8B parameter aktif untuk mencapai sekitar 97% performa dari model 31B. Jika Anda mengejar performa maksimal dan memiliki GPU 80GB, pilih 31B Dense. Biaya inferensi versi MoE sekitar 1/8 dari versi Dense.
Q3: Skenario apa yang cocok untuk E2B dan E4B?
E2B cocok untuk skenario edge yang ekstrem (Raspberry Pi, perangkat IoT, ponsel), sedangkan E4B cocok untuk perangkat seluler dan PC kelas ringan. Keduanya mendukung input audio, fitur yang tidak dimiliki oleh model 31B dan 26B. Jika aplikasi Anda membutuhkan pemahaman suara, Anda wajib memilih E2B atau E4B.
Q4: Apa dampak lisensi Apache 2.0 terhadap penggunaan komersial?
Apache 2.0 adalah salah satu lisensi sumber terbuka yang paling longgar, memungkinkan penggunaan komersial, modifikasi, dan distribusi secara bebas dan tidak dapat dibatalkan. Dibandingkan dengan lisensi kepemilikan Google pada Gemma 3, perusahaan tidak perlu khawatir tentang risiko kepatuhan. Anda bisa mencoba API-nya terlebih dahulu di platform APIYI apiyi.com, dan setelah hasilnya sesuai, Anda bisa melakukan deployment lokal untuk produk komersial Anda.
Kesimpulan
Gemma 4 merupakan peningkatan besar dalam strategi AI sumber terbuka Google. Lisensi Apache 2.0 mendobrak hambatan penggunaan sebelumnya; 4 model yang tersedia mencakup semua skenario komputasi mulai dari Raspberry Pi hingga H100; lompatan performa antar generasi sebesar 4,3 kali lipat pada AIME dan 2,7 kali lipat pada LiveCodeBench; serta kemampuan multimodal dan pemanggilan fungsi (function calling) bawaan menjadikannya model dasar pilihan utama untuk pengembangan Agent sumber terbuka.
Ringkasan Poin Utama:
- Lisensi: Pertama kalinya menggunakan Apache 2.0, sepenuhnya bebas untuk komersial
- Model: 4 varian mencakup 2B-31B, termasuk varian MoE pertama
- Performa: AIME +68pts (4,3x), LiveCodeBench +51pts (2,7x)
- Multimodal: Teks + gambar + video + audio, terintegrasi secara native
- Agent: Pemanggilan fungsi native + Extended Thinking
- Deployment: Mencakup segalanya dari Raspberry Pi hingga H100, mendukung berbagai framework seperti GGUF/ONNX/MLX
Disarankan untuk segera mengakses seri model Gemma 4 melalui APIYI apiyi.com guna membandingkan performa aktual berbagai model di bawah satu antarmuka yang terpadu.
Referensi
- Blog Resmi Google – Rilis Gemma 4:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Model Gemma 4:
huggingface.co/blog/gemma4 - Google AI – Kartu Model Gemma 4:
ai.google.dev/gemma/docs/core/model_card_4
Artikel ini ditulis oleh tim teknis APIYI. Untuk tutorial penggunaan Model Bahasa Besar lainnya, silakan kunjungi APIYI di apiyi.com