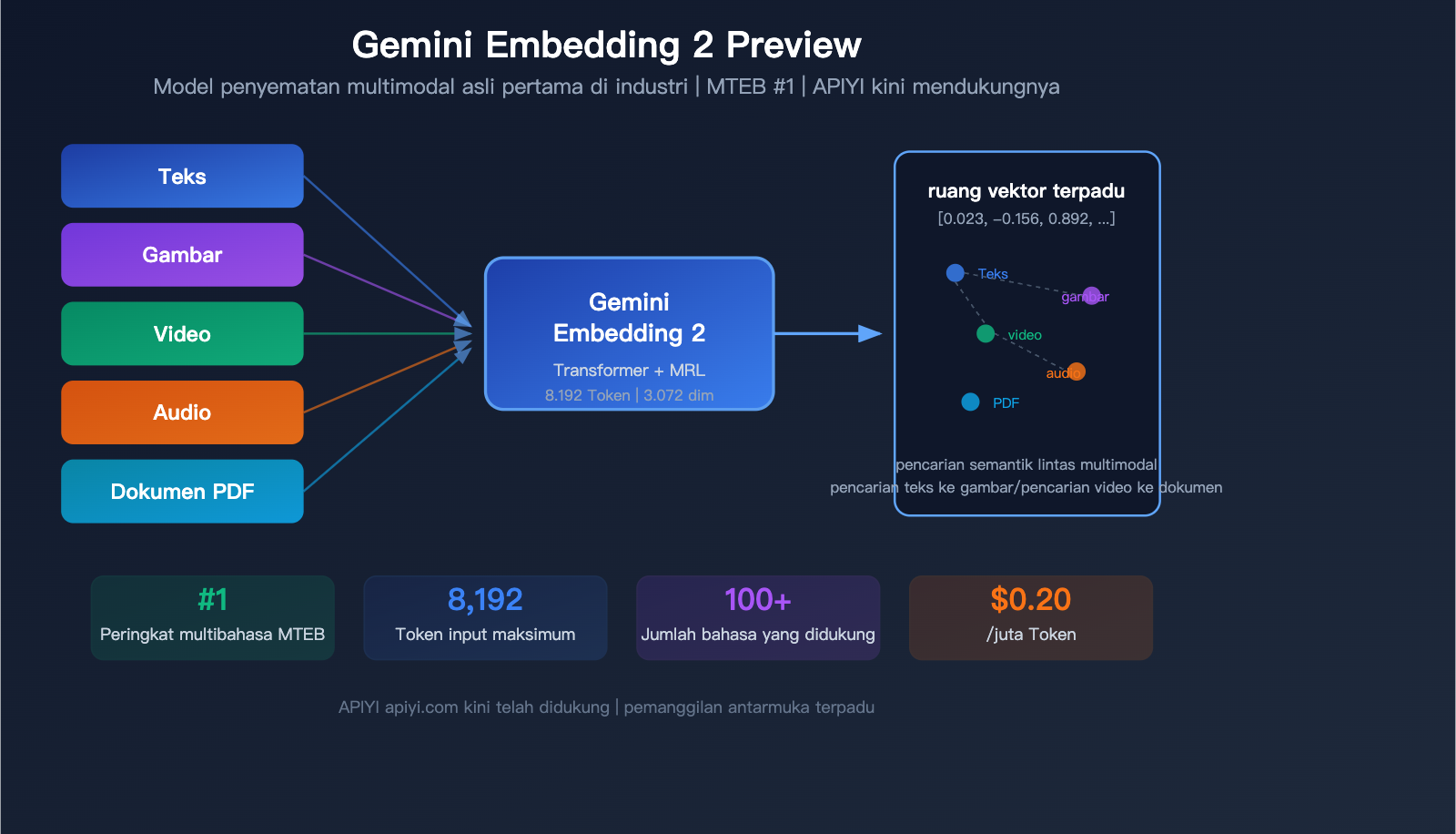
Google merilis model penting pada Maret 2026—Gemini Embedding 2 Preview, model embedding multimodal natif pertama di industri. Model ini mampu memetakan teks, gambar, video, audio, dan dokumen PDF ke dalam ruang vektor yang sama, menempati peringkat ke-1 dalam tolok ukur multibahasa MTEB, mengungguli posisi kedua dengan selisih lebih dari 5 persen.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami 5 terobosan teknis Gemini Embedding 2 Preview, perbandingan harga dan performa dengan kompetitor, serta cara mengaksesnya dengan cepat melalui API.
Apa itu Gemini Embedding 2 Preview
Gemini Embedding 2 Preview adalah model embedding terbaru yang dirilis oleh Google pada 10 Maret 2026. Model ini diinisialisasi berdasarkan arsitektur Gemini, menggunakan struktur Transformer perhatian dua arah (bidirectional attention), dan merupakan model embedding pertama dari Google yang mendukung input multimodal secara natif.
| Spesifikasi | Detail |
|---|---|
| ID Model | gemini-embedding-2-preview |
| Tanggal Rilis | 10 Maret 2026 |
| Status | Preview (Pratinjau, versi resmi menyusul) |
| Dimensi Output Default | 3.072 |
| Rentang Dimensi Opsional | 128 — 3.072 |
| Token Input Maksimum | 8.192 (4 kali lipat dari generasi sebelumnya) |
| Dukungan Multimodal | Teks, gambar, video, audio, PDF |
| Dukungan Bahasa | 100+ bahasa |
| Pelatihan Matryoshka | Didukung (dapat memotong dimensi dengan tetap menjaga kualitas semantik) |
| Platform Tersedia | Gemini API, Vertex AI, APIYI apiyi.com |
Perbedaan Utama dengan Model Generasi Sebelumnya
| Fitur | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| Token Input Maksimum | 2.048 | 2.048 | 8.192 |
| Dimensi Output | Maksimal 768 | 128-3.072 | 128-3.072 |
| Multimodal | Hanya teks | Hanya teks | Teks+Gambar+Video+Audio+PDF |
| Penentuan Tipe Tugas | Bidang task_type |
Bidang task_type |
Instruksi tersemat dalam petunjuk |
| Dukungan MRL | Tidak didukung | Didukung | Didukung |
| Harga/Juta Token | Layanan dihentikan | $0,15 | $0,20 |
🎯 Tips Akses: APIYI apiyi.com telah mendukung pemanggilan model gemini-embedding-2-preview,
Anda dapat mengaksesnya melalui antarmuka yang kompatibel dengan OpenAI, tanpa perlu mengonfigurasi kunci API Google secara terpisah.
Penjelasan Mendalam 5 Terobosan Teknis
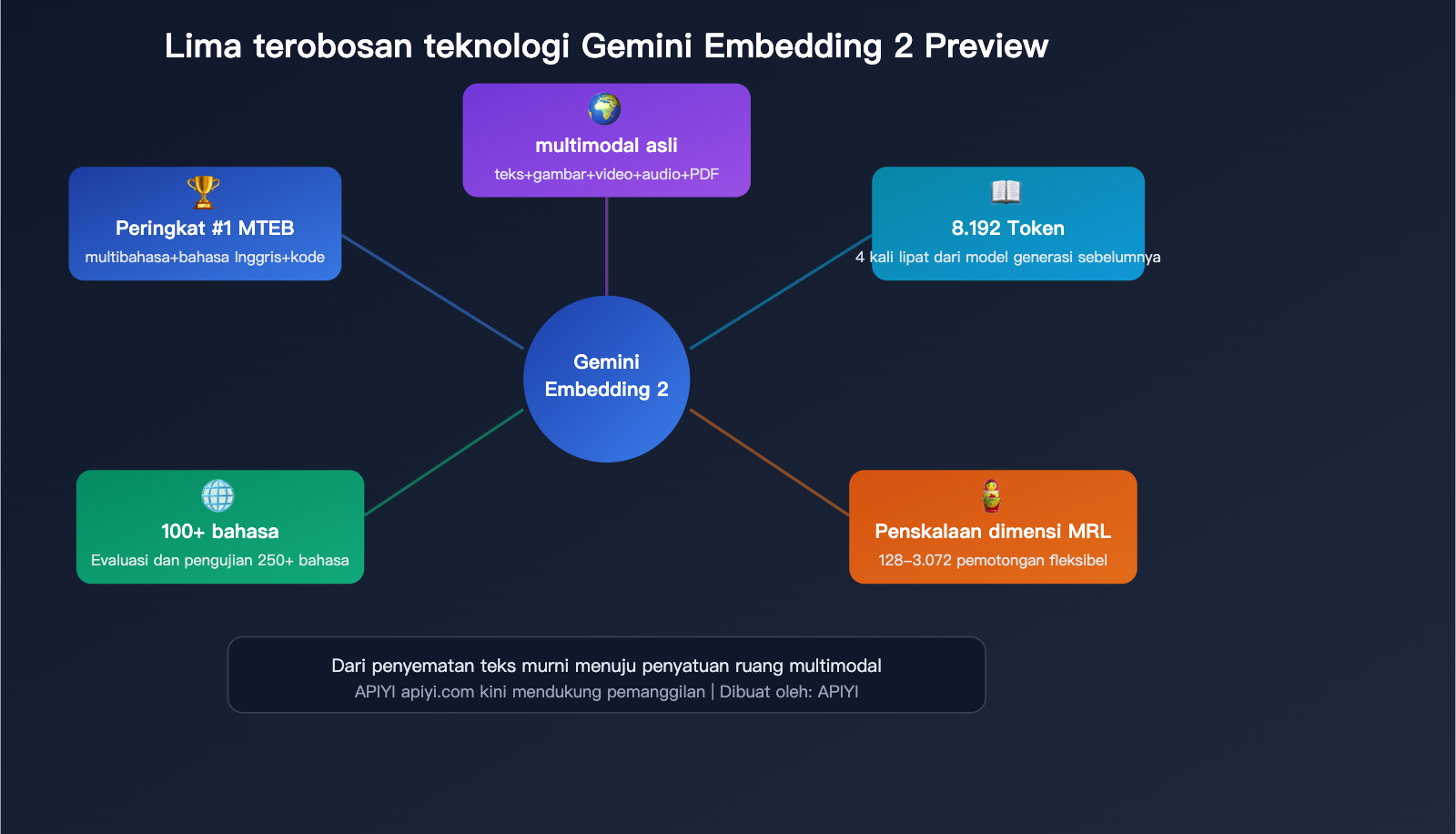
Terobosan 1: Ruang Embedding Terpadu Multimodal Asli
Ini adalah keunggulan pembeda terbesar dari Gemini Embedding 2—konten dari 5 modalitas dipetakan ke dalam ruang vektor yang sama.
| Modalitas | Persyaratan Format | Batas per Permintaan | Keterangan |
|---|---|---|---|
| Teks | Teks murni | 8.192 Token | Mendukung 100+ bahasa |
| Gambar | PNG, JPEG | Maks. 6 per permintaan | Memproses piksel secara langsung |
| Video | MP4, MOV | Maks. 120 detik | Pengambilan sampel otomatis maks. 32 frame |
| Audio | MP3, WAV | Maks. 80 detik | Pemrosesan asli, tanpa transkripsi |
| Dokumen PDF | Maks. 6 halaman per permintaan | Termasuk kemampuan OCR |
Skenario aplikasi nyata:
- Mencari gambar menggunakan teks ("mobil sport merah di lintasan balap" → mengembalikan gambar yang cocok)
- Mencari klip video serupa menggunakan gambar
- Mencari dokumen terkait menggunakan deskripsi suara
- Membangun basis pengetahuan terpadu lintas modalitas
Hal ini mustahil dilakukan pada model embedding sebelumnya—seri text-embedding-3 dari OpenAI hanya mendukung teks. Jika Anda memerlukan pencarian gambar, Anda harus menggunakan model visual untuk mengekstrak deskripsi terlebih dahulu sebelum melakukan embedding, yang menambah langkah dan menyebabkan hilangnya informasi.
Terobosan 2: Jendela Konteks 8.192 Token
Jendela input ditingkatkan dari 2.048 menjadi 8.192 Token, yang berarti Anda dapat melakukan embedding pada segmen dokumen yang lebih panjang sekaligus.
Bagi sistem RAG (Retrieval-Augmented Generation), peningkatan ini sangat praktis:
- Sebelumnya, dokumen perlu dipotong menjadi segmen kecil 500-1000 Token
- Sekarang, Anda dapat menggunakan segmen besar 2000-4000 Token untuk mempertahankan lebih banyak konteks
- Segmen dokumen yang lebih besar = lebih sedikit pemotongan = hasil pencarian yang lebih lengkap
Terobosan 3: Skalabilitas Dimensi Matryoshka
Gemini Embedding 2 dilatih menggunakan Matryoshka Representation Learning (MRL), di mana model memusatkan informasi semantik terpenting pada dimensi awal vektor.
Ini berarti Anda dapat memilih dimensi secara fleksibel sesuai dengan skenario:
| Dimensi | Ukuran Vektor | Skenario yang Sesuai | Kehilangan Kualitas |
|---|---|---|---|
| 3.072 (Default) | 12,3 KB | Pencarian presisi tertinggi | Tidak ada |
| 1.536 | 6,1 KB | Keseimbangan presisi & penyimpanan | Sangat kecil |
| 768 | 3,1 KB | Pilihan utama untuk deployment skala besar | Kecil |
| 256 | 1,0 KB | Sistem rekomendasi real-time | Sedang |
| 128 | 0,5 KB | Skenario kompresi ekstrem | Besar |
Catatan: Saat menggunakan dimensi di bawah 3.072, Anda perlu melakukan normalisasi vektor secara manual sebelum menghitung kemiripan.
Terobosan 4: Dukungan 100+ Bahasa
Dalam benchmark multibahasa MTEB, Gemini Embedding 2 telah dievaluasi pada 250+ bahasa, dengan cakupan yang jauh melampaui kompetitor.
Indikator kinerja bahasa utama:
- Bitext Mining: 79,32 poin
- Pencarian Lintas Bahasa (XOR-Retrieve): Recall@5kt 90,42 poin
- Pemahaman Multibahasa (XTREME-UP): MRR@10 64,33 poin
Terobosan 5: Peringkat #1 di Berbagai Benchmark MTEB
| Benchmark | Skor | Peringkat | Selisih Keunggulan |
|---|---|---|---|
| MTEB Multibahasa (Mean Task) | 68,32 | #1 | +5,09 |
| MTEB Multibahasa (Mean Type) | 59,64 | #1 | — |
| MTEB Inggris v2 (Mean Task) | 73,30 | #1 | — |
| MTEB Inggris v2 (Mean Type) | 67,67 | #1 | — |
| MTEB Kode (Mean All) | 74,66 | #1 | — |
Sebagai perbandingan, model peringkat kedua, gte-Qwen2-7B-instruct, memiliki skor 62,51 pada MTEB multibahasa—Gemini Embedding 2 unggul hampir 6 poin, yang merupakan selisih yang sangat besar di bidang model embedding.
💡 Saran Pengembangan: Jika Anda sedang membangun sistem RAG atau aplikasi pencarian semantik,
Gemini Embedding 2 adalah pilihan terkuat saat ini untuk skenario multibahasa dan kode.
Melalui APIYI (apiyi.com), Anda dapat mengakses model ini dengan satu klik, sekaligus mendukung model embedding OpenAI,
sehingga memudahkan perbandingan hasil secara cepat.
Perbandingan Harga dan Performa dengan Kompetitor
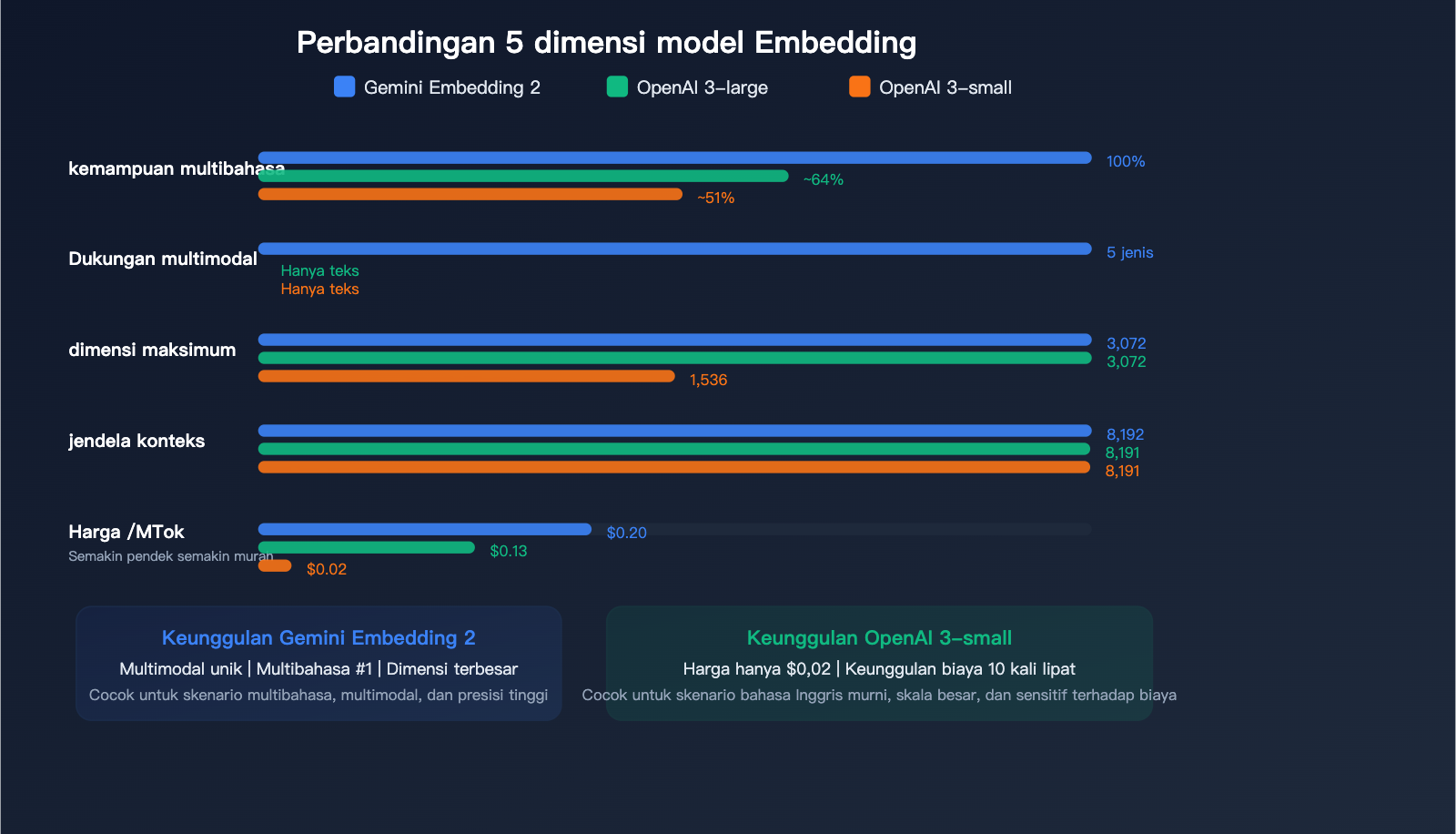
Perbandingan Harga Embedding Teks
| Model | Harga/Juta Token | Dimensi Maks | Input Maks | Multimodal | Peringkat Multibahasa |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3.072 | 8.192 | ✅ Lima modal | #1 |
| gemini-embedding-001 | $0.15 | 3.072 | 2.048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3.072 | 8.191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1.536 | 8.191 | ❌ | — |
Harga Konten Multimodal (Eksklusif untuk Gemini Embedding 2):
| Tipe Input | Harga Berbayar/Juta Token | Harga Batch/Juta Token |
|---|---|---|
| Teks | $0.20 | $0.10 |
| Gambar | $0.45 (~$0,00012/gambar) | $0.225 |
| Audio | $6.50 (~$0,00016/detik) | $3.25 |
| Video | $12.00 (~$0,00079/frame) | $6.00 |
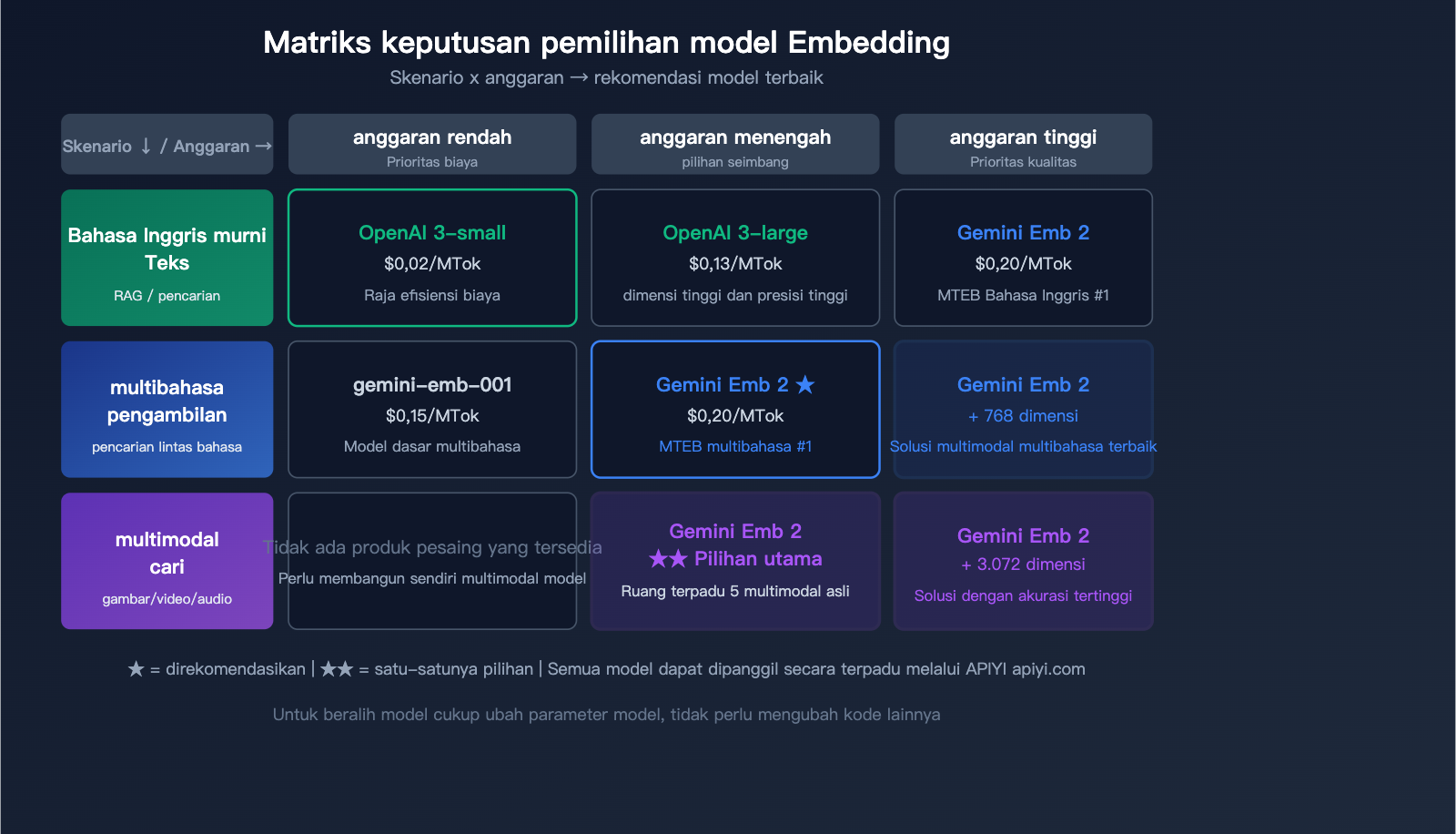
Saran Pemilihan Model
| Skenario Kebutuhan | Model yang Direkomendasikan | Alasan |
|---|---|---|
| Teks murni, sensitif biaya | OpenAI text-embedding-3-small | Termurah ($0.02) |
| Teks murni, akurasi tinggi | Gemini Embedding 2 atau OpenAI 3-large | Akurasi setara, Gemini lebih unggul di multibahasa |
| Pencarian multimodal | Gemini Embedding 2 | Satu-satunya solusi multimodal asli |
| Pencarian multibahasa | Gemini Embedding 2 | #1 MTEB Multibahasa |
| Pencarian kode | Gemini Embedding 2 | #1 MTEB Kode |
| Skala besar, biaya rendah | OpenAI 3-small + API Batch | Keunggulan harga 10x lipat |
🎯 Saran Pemilihan: Memilih model embedding bergantung pada skenario spesifik Anda.
Kami menyarankan untuk mencoba Gemini dan OpenAI melalui platform APIYI (apiyi.com).
Bandingkan hasil pencarian dengan data asli sebelum memutuskan. Platform ini mendukung antarmuka terpadu, sehingga Anda bisa mengganti model tanpa mengubah kode.
Penjelasan Detail Cara Pemanggilan API
Cara Menentukan Tipe Tugas (Perubahan Penting)
Berbeda dengan gemini-embedding-001, Gemini Embedding 2 tidak lagi menggunakan parameter task_type, melainkan menentukan tipe tugas dengan menyematkan instruksi tugas ke dalam konten input.
8 Tipe tugas yang didukung:
| Tipe Tugas | Format Sisi Kueri | Format Sisi Dokumen |
|---|---|---|
| Pencarian/Retrieval | task: search result | query: {konten} |
title: {judul} | text: {konten} |
| Tanya Jawab | task: question answering | query: {pertanyaan} |
title: {judul} | text: {konten} |
| Verifikasi Fakta | task: fact checking | query: {pernyataan} |
title: {judul} | text: {konten} |
| Pencarian Kode | task: code retrieval | query: {deskripsi} |
title: {judul} | text: {kode} |
| Klasifikasi | task: classification | query: {konten} |
Format sama |
| Klasterisasi | task: clustering | query: {konten} |
Format sama |
| Kemiripan Kalimat | task: sentence similarity | query: {kalimat} |
Format sama |
Untuk sisi dokumen, jika tidak ada judul, gunakan title: none.
Contoh Pemanggilan Python
import openai
# Memanggil melalui antarmuka terpadu APIYI
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Embedding teks - skenario pencarian
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: apa itu basis data vektor",
dimensions=768 # Dimensi opsional: 128-3072
)
embedding = response.data[0].embedding
print(f"Dimensi vektor: {len(embedding)}")
print(f"5 nilai pertama: {embedding[:5]}")
Lihat kode alur pencarian RAG lengkap
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""Mendapatkan vektor embedding teks"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# Dimensi pemotongan MRL perlu dinormalisasi secara manual
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""Mendapatkan vektor embedding dokumen"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""Menghitung kemiripan kosinus"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Contoh penggunaan
query_vec = get_embedding("bagaimana mengoptimalkan hasil pencarian RAG")
doc_vec = get_doc_embedding(
"Panduan Optimasi RAG",
"Artikel ini memperkenalkan 5 metode untuk mengoptimalkan kualitas pencarian RAG..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"Kemiripan: {similarity:.4f}")
🚀 Mulai Cepat: Direkomendasikan untuk menggunakan platform APIYI (apiyi.com) untuk integrasi cepat Gemini Embedding 2.
Platform ini menyediakan antarmuka embedding yang kompatibel dengan OpenAI, integrasi selesai dalam 5 menit,
serta mendukung pemanggilan terpadu untuk model embedding utama seperti OpenAI, Gemini, dan Cohere.
Catatan Penggunaan
Batasan Status Preview
| Batasan | Penjelasan | Dampak |
|---|---|---|
| Perubahan Versi | Spesifikasi dan harga dapat berubah selama tahap Preview | Disarankan menyiapkan rencana fallback untuk lingkungan produksi |
| Ketidakcocokan Ruang Vektor | Tidak dapat dicampur dengan vektor model lama | Upgrade memerlukan pengindeksan ulang secara penuh |
| Normalisasi Dimensi Rendah | Perlu normalisasi manual jika menggunakan dimensi <3.072 | Perlu menambahkan langkah normalisasi dalam kode |
| Batas Laju Ketat | Kuota model Preview lebih rendah daripada model GA | Perlu mengajukan kenaikan kuota untuk penggunaan skala besar |
| Penggunaan Data Tier Gratis | Data di tier gratis akan digunakan untuk peningkatan produk | Disarankan menggunakan tier berbayar untuk data sensitif |
Catatan Migrasi dari Model Lama
- Wajib Membangun Ulang Indeks: Ruang vektor antar model tidak kompatibel, tidak bisa dicampur dalam database yang sama.
- Perubahan Format Tipe Tugas: Berubah dari parameter
task_typemenjadi instruksi yang disematkan dalam petunjuk (prompt). - Pemrosesan Normalisasi: Jika menggunakan dimensi non-default, logika normalisasi harus ditambahkan ke dalam kode.
- Uji Efektivitas Sebelum Migrasi: Disarankan untuk membandingkan efektivitas pengambilan (retrieval) antara model lama dan baru di lingkungan pengujian sebelum memutuskan untuk migrasi.
Pertanyaan Umum (FAQ)
Q1: Apa keunggulan Gemini Embedding 2 Preview dibandingkan OpenAI text-embedding-3-large?
Keunggulan utamanya ada di tiga aspek: dukungan multimodal asli (OpenAI hanya mendukung teks), peringkat ke-1 dalam MTEB multibahasa (dengan margin yang signifikan), serta kualitas penyematan (embedding) kode yang lebih baik. Namun, harga OpenAI text-embedding-3-large lebih murah ($0,13 vs $0,20), dan jika Anda hanya memerlukan penyematan teks bahasa Inggris, kualitas keduanya sangat mirip. Melalui APIYI apiyi.com, Anda dapat memanggil kedua model secara bersamaan untuk membandingkannya dengan data nyata.
Q2: Apa kegunaan praktis dari penyematan multimodal?
Aplikasi yang paling langsung adalah pencarian lintas modal: pengguna memasukkan teks, dan pencarian mengembalikan gambar, video, atau dokumen yang relevan. Misalnya, dalam skenario e-commerce, menggunakan "gaun merah" untuk mencari gambar produk, atau dalam basis pengetahuan perusahaan, menggunakan deskripsi teks untuk mencari cuplikan yang relevan dalam video pelatihan. Cara tradisional mengharuskan penggunaan model visual untuk mengekstrak deskripsi terlebih dahulu sebelum menyematkan teks, sedangkan Gemini Embedding 2 memproses gambar/video mentah secara langsung, sehingga kehilangan informasi lebih minim.
Q3: Berapa dimensi yang tepat untuk dipilih? Apakah ada perbedaan besar antara 768 dan 3072?
Untuk sebagian besar aplikasi, 768 dimensi adalah titik keseimbangan terbaik—biaya penyimpanan hanya 1/4 dari 3072 dimensi, namun kualitas pengambilan data hanya berkurang sedikit (berkat pelatihan Matryoshka). Jika dataset Anda kecil (<1 juta entri) dan memerlukan presisi yang sangat tinggi, gunakan 3072 dimensi. Jika volume data besar atau memerlukan pengambilan data secara real-time, 768 atau bahkan 256 dimensi adalah pilihan yang masuk akal.
Q4: Bagaimana APIYI mendukung Gemini Embedding 2? Apakah perlu konfigurasi tambahan?
APIYI apiyi.com telah mendukung model gemini-embedding-2-preview. Anda dapat memanggilnya melalui antarmuka embedding standar yang kompatibel dengan OpenAI tanpa perlu konfigurasi kunci API Google tambahan. Cukup tentukan gemini-embedding-2-preview pada parameter model, dan parameter lainnya (seperti dimensions) akan sama persis dengan antarmuka embedding OpenAI.
Kesimpulan: Standar Baru untuk Embedding Multimodal
Gemini Embedding 2 Preview menandai tonggak penting bagi model embedding—peralihan dari sekadar teks menuju ruang multimodal yang benar-benar terpadu. Dengan meraih peringkat ke-1 di tiga dimensi sekaligus (multibahasa, bahasa Inggris, dan kode) pada MTEB, ditambah jendela konteks 8K dan penskalaan dimensi MRL, model ini menyediakan kemampuan dasar terkuat saat ini untuk sistem RAG, pencarian semantik, dan pembangunan basis pengetahuan.
Ringkasan Poin Utama:
- Model embedding lima modalitas asli pertama di industri (teks + gambar + video + audio + PDF)
- Peringkat ke-1 di tolok ukur multibahasa MTEB, unggul lebih dari 5 poin
- Jendela konteks 8.192 token, 4 kali lipat dari generasi sebelumnya
- Pelatihan MRL mendukung penskalaan dimensi fleksibel dari 128 hingga 3.072
- Harga $0,20/juta token, sangat hemat biaya untuk skenario multimodal
Direkomendasikan untuk mengakses Gemini Embedding 2 Preview dengan cepat melalui APIYI apiyi.com. Satu kunci API mendukung model embedding utama seperti Gemini, OpenAI, dan lainnya, sehingga memudahkan perbandingan dan peralihan antar model.
📝 Penulis Artikel: Tim Teknis APIYI | APIYI apiyi.com – Platform akses terpadu untuk 300+ API Model Bahasa Besar AI
Referensi
-
Blog Resmi Google: Pengumuman rilis Gemini Embedding 2
- Tautan:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - Penjelasan: Berisi filosofi desain model dan pengenalan kemampuan multimodal
- Tautan:
-
Dokumentasi Embedding API Gemini: Panduan penggunaan API resmi
- Tautan:
ai.google.dev/gemini-api/docs/embeddings - Penjelasan: Parameter API lengkap dan contoh pemanggilan
- Tautan:
-
Makalah Penelitian Gemini Embedding: Detail teknis dan tolok ukur
- Tautan:
arxiv.org/html/2503.07891v1 - Penjelasan: Data pengujian MTEB terperinci dan analisis arsitektur model
- Tautan:
-
Harga API Gemini: Informasi harga terperinci untuk setiap modalitas
- Tautan:
ai.google.dev/gemini-api/docs/pricing - Penjelasan: Penetapan harga terpisah untuk teks, gambar, audio, dan video
- Tautan: