Panggilan API Qwen3.5 dari Alibaba Cloud yang lambat adalah salah satu topik yang paling banyak dibahas di komunitas pengembang belakangan ini. Sebagai model yang dikembangkan sendiri oleh Alibaba, Qwen3.5-Plus dan Qwen3.5-Flash secara teori seharusnya berkinerja baik di infrastruktur komputasi mereka sendiri. Namun, pengalaman aktual membuat banyak pengembang bingung — model internal berjalan lambat di platform mereka sendiri, dan memanggil model pihak ketiga seperti GLM-5, Kimi-K2.5, dan MiniMax-M2.5 melalui Alibaba Cloud bahkan lebih lambat.
Nilai Inti: Artikel ini akan menganalisis secara mendalam akar penyebab lambatnya respons API Alibaba Cloud dari tiga dimensi: pasokan daya komputasi, desain arsitektur, dan strategi penjadwalan. Kami juga akan memberikan 3 solusi alternatif yang telah terbukti untuk membantu Anda mendapatkan pengalaman inferensi yang lebih cepat dalam proyek Anda.
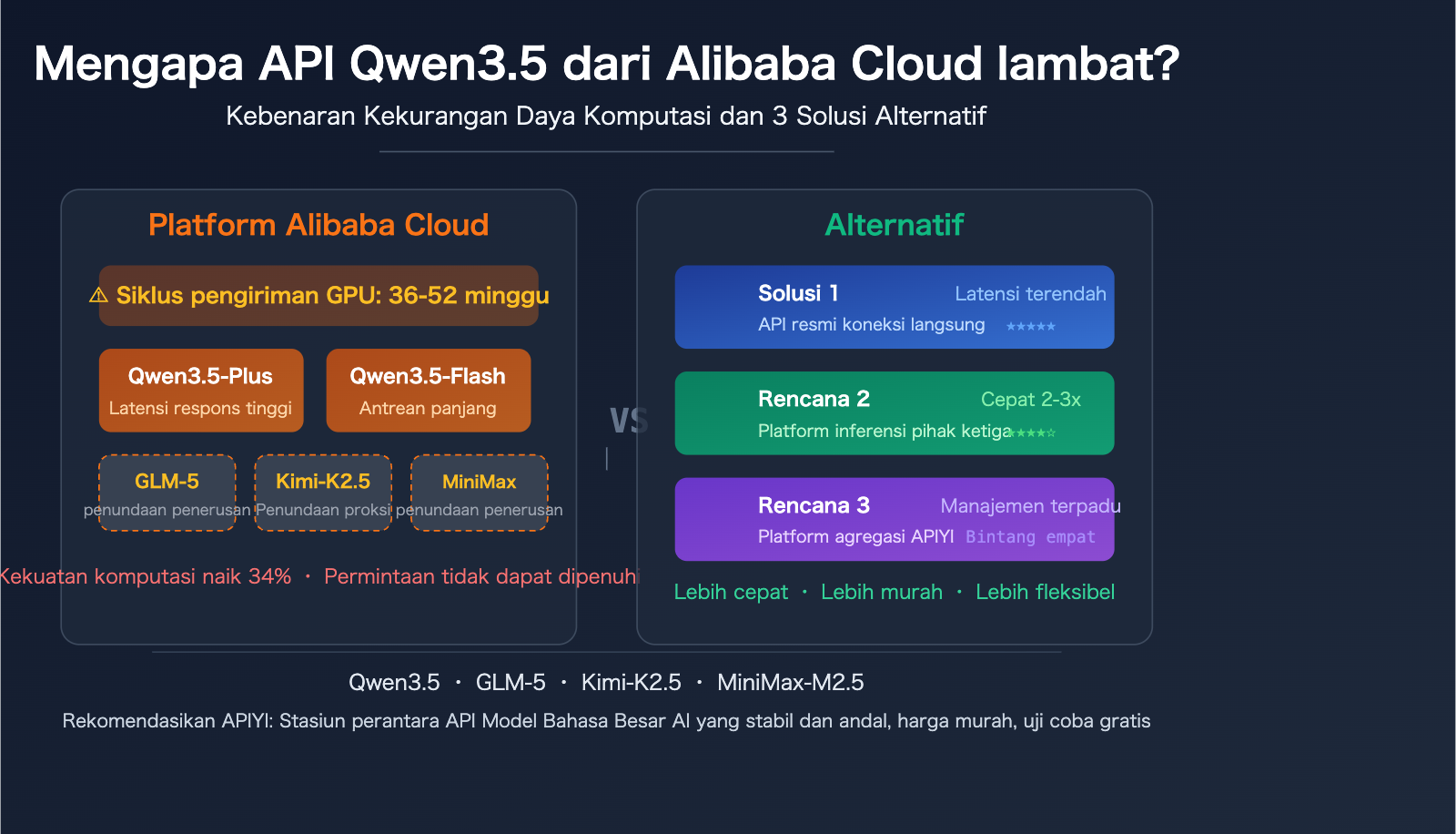
Analisis 5 Penyebab Utama Lambatnya API Qwen3.5 Alibaba Cloud
Penyebab 1: Pasokan Daya Komputasi GPU Global Sangat Tidak Mencukupi
Ini bukan hanya masalah Alibaba Cloud, tetapi kontradiksi struktural di seluruh industri. Siklus pengiriman GPU kelas pusat data pada tahun 2026 telah diperpanjang menjadi 36-52 minggu. Eksekutif Alibaba Cloud secara terbuka mengakui bahwa terjadi kekurangan produsen semikonduktor, chip penyimpanan, dan komponen memori secara luas, yang diperkirakan akan menjadi "kendala besar" dalam 2-3 tahun ke depan.
| Indikator Pasokan Daya Komputasi | Tahun 2025 | Tahun 2026 | Tren Perubahan |
|---|---|---|---|
| Siklus Pengiriman GPU | 12-24 minggu | 36-52 minggu | ↑ Sangat Diperpanjang |
| Pertumbuhan Pendapatan AI Alibaba Cloud | — | 34% | Ledakan Permintaan |
| Penyesuaian Harga Daya Komputasi Alibaba Cloud | Harga Dasar | Naik hingga 34% | ↑ Mulai 18 April 2026 |
| Proporsi Pengeluaran Inferensi AI Global | 42% | 55% | Melampaui Pelatihan untuk Pertama Kalinya |
Alibaba Cloud telah mengumumkan kenaikan harga daya komputasi AI mulai 18 April 2026, dengan kenaikan hingga 34%. Alasan langsungnya adalah "ledakan permintaan AI global dan kenaikan harga rantai pasokan." Meskipun pendapatan Alibaba Cloud meningkat 34%, mereka menyatakan masih tidak dapat memenuhi permintaan—ini adalah latar belakang makro mengapa API Qwen3.5 lambat.
Penyebab 2: Konsumsi Daya Komputasi Arsitektur Model Qwen3.5
Keluarga Qwen3.5 mengadopsi arsitektur MoE (Mixture of Experts). Versi andalannya, Qwen3.5-397B-A17B, memiliki total parameter 397 miliar, dengan 17 miliar parameter diaktifkan setiap kali inferensi. Bahkan Qwen3.5-Flash yang ringan (berbasis 35B-A3B) secara native mendukung jendela konteks 1 juta token dan input multimodal (teks + gambar).
| Versi Model | Total Parameter | Parameter Aktif | Konteks Default | Dukungan Multimodal |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (Flagship) | 397 miliar | 17 miliar | 262K→1M | Teks+Gambar |
| Qwen3.5-Plus (Versi API) | Tidak Dipublikasikan | Tidak Dipublikasikan | 1M | Teks+Gambar |
| Qwen3.5-Flash (Versi API) | 35 miliar | 3 miliar | 1M | Teks+Gambar |
| Qwen3.5-122B-A10B | 122 miliar | 10 miliar | 262K | Teks+Gambar |
Model-model ini menggunakan arsitektur multimodal early-fusion sejak tahap pelatihan, yang secara native mendukung pemrosesan terpadu teks, gambar, dan video. Konsekuensi dari fungsionalitas yang kuat adalah: biaya komputasi per permintaan jauh lebih tinggi daripada model teks murni. Ditambah lagi dengan jendela konteks jutaan token, penggunaan memori dan daya komputasi untuk satu kali inferensi meningkat secara signifikan.
Penyebab 3: Latensi Tambahan dari Alibaba Cloud yang Menjual Ulang Model Pihak Ketiga
Saat memanggil model pihak ketiga seperti GLM-5 (Zhipu AI), Kimi-K2.5 (Moonshot AI), dan MiniMax-M2.5 melalui platform DashScope Alibaba Cloud, jalur permintaan sebenarnya menjadi:
Aplikasi Anda → Gerbang API Alibaba Cloud → Lapisan Penjadwalan DashScope → Layanan Model Pihak Ketiga
Setiap lapisan penerusan tambahan menambah latensi. Yang lebih penting, saat Alibaba Cloud menjual ulang model-model ini, prioritas alokasi sumber daya GPU mungkin lebih rendah daripada model milik sendiri—lagipula, daya komputasi yang tersedia sudah tidak mencukupi. Umpan balik umum dari pengembang di industri adalah: Memanggil GLM-5, Kimi-K2.5, dan MiniMax-M2.5 melalui Alibaba Cloud jelas lebih lambat daripada API resmi.
Penyebab 4: Optimalisasi Strategi Penjadwalan Inferensi yang Kurang
Platform inferensi pihak ketiga yang profesional (seperti SiliconFlow, Fireworks AI, Together AI) memiliki keunggulan signifikan dalam efisiensi inferensi melalui teknik seperti kernel CUDA kustom, mekanisme perhatian terpadu, dan penjadwalan fine-grained. Data pengujian menunjukkan:
- SiliconFlow: Kecepatan inferensi hingga 2,3 kali lebih cepat daripada platform cloud umum, dengan latensi berkurang 32%.
- Fireworks AI: Teknologi FireAttention v2 diklaim memberikan peningkatan kecepatan hingga 8 kali lipat, dengan hasil pengujian sekitar 747 TPS.
- Together AI: Peningkatan kecepatan inferensi model sumber terbuka hingga 2 kali lipat melalui speculative decoding dan kuantisasi FP4.
Sebagai platform cloud umum, penjadwalan inferensi Alibaba Cloud lebih fokus pada keserbagunaan dan stabilitas daripada optimalisasi kecepatan inferensi ekstrem. Hal ini tidak terlalu berpengaruh saat daya komputasi melimpah, tetapi perbedaannya akan diperbesar saat GPU langka.
Penyebab 5: Perebutan Sumber Daya Multi-Tenant
Sebagai penyedia layanan cloud terbesar di Tiongkok, cluster inferensi AI Alibaba Cloud melayani jutaan pengguna secara bersamaan. Selama jam sibuk, perebutan sumber daya GPU secara langsung menyebabkan peningkatan waktu antrean. Meskipun sistem pemusatan sumber daya Aegaeon yang dikembangkan Alibaba Cloud diklaim dapat meningkatkan utilisasi GPU sebesar 82%, pada dasarnya ini adalah "memotong kue yang terbatas menjadi lebih kecil" dan tidak dapat secara fundamental menyelesaikan masalah kekurangan total daya komputasi.
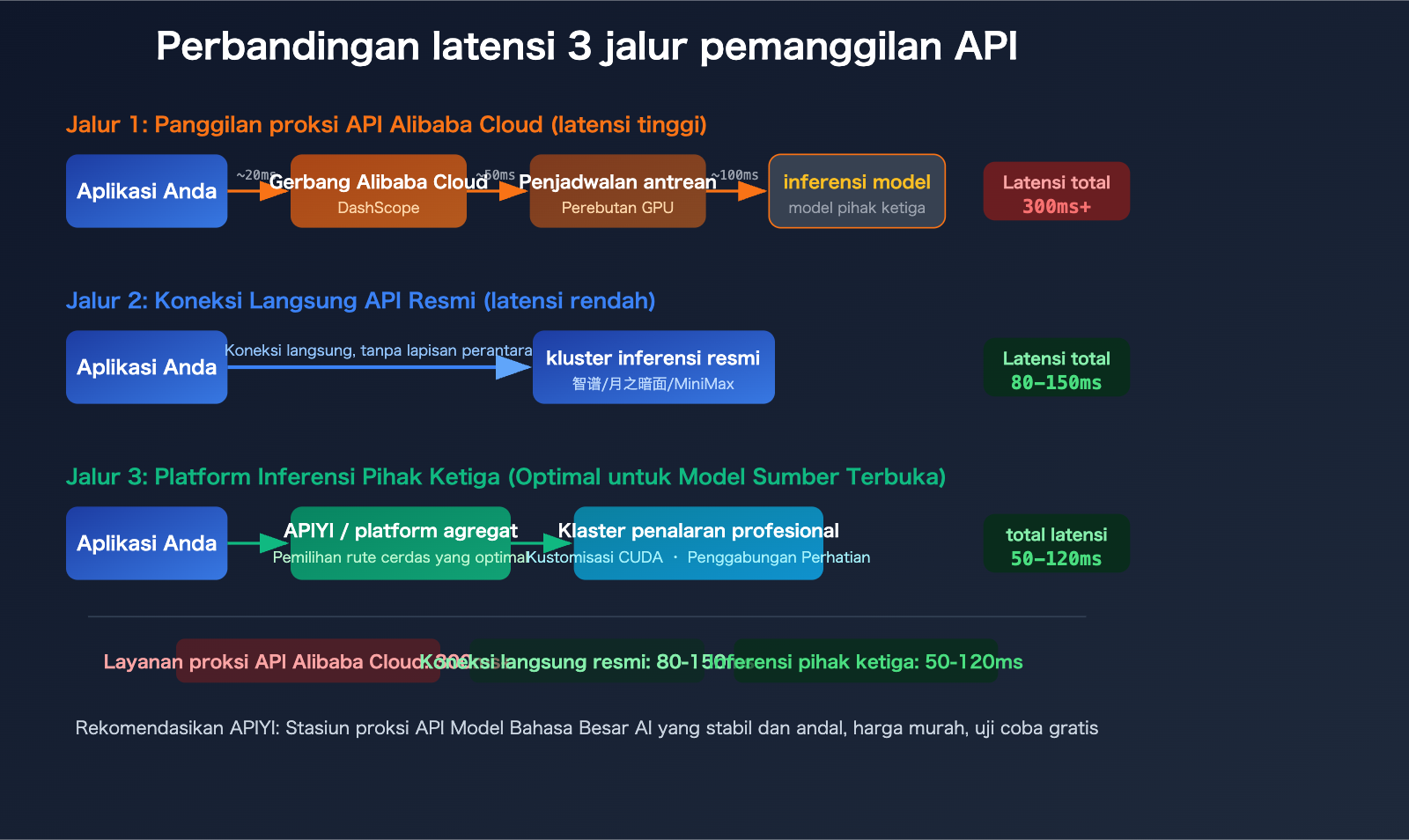
GLM-5、Kimi-K2.5、MiniMax-M2.5: Perbandingan Latensi Panggilan Melalui Alibaba Cloud vs API Resmi
Setelah memahami alasannya, mari kita lihat skenario pemanggilan model yang spesifik. Berikut adalah analisis perbedaan pengalaman antara 3 model populer di berbagai platform.
Analisis Latensi Panggilan API GLM-5 (Zhipu AI)
GLM-5 adalah model unggulan yang dirilis oleh Zhipu AI pada Februari 2026. Model ini memiliki total 744 miliar parameter, dengan 40 miliar parameter aktif, dan menggunakan arsitektur MoE. Dilatih pada chip Ascend Huawei, GLM-5 mendukung jendela konteks 200 ribu token dan sudah bersifat open-source (lisensi MIT).
Fakta Kunci: GLM-5 secara native mendukung mode Agent, yang memungkinkannya untuk memecah tugas menjadi sub-tugas dan mengeksekusinya secara mandiri. Model ini juga dapat langsung menghasilkan dokumen perkantoran profesional (.docx, .pdf, .xlsx). Harganya adalah $1.00/M token untuk input dan $3.20/M token untuk output.
Saat memanggil GLM-5 melalui Alibaba Cloud, permintaan harus melewati lapisan gateway dan penjadwalan tambahan, yang secara signifikan meningkatkan latensi. Sebaliknya, koneksi langsung ke API resmi Zhipu AI (bigmodel.cn) memungkinkan permintaan mencapai cluster inferensi Zhipu secara langsung, menghasilkan respons yang lebih cepat.
Analisis Latensi Panggilan API Kimi-K2.5 (Moonshot AI)
Kimi-K2.5 dirilis pada Januari 2026. Model ini adalah model MoE dengan 1 triliun parameter, yang hanya mengaktifkan 32 miliar parameter per permintaan. Model ini dilatih sebelumnya pada 15 triliun token gabungan visual dan teks, serta bersifat multimodal secara native.
Sorotan Utama: Fitur Agent Swarm – yang dapat mengoordinasikan hingga 100 Agent AI profesional secara bersamaan untuk bekerja sama, mengurangi waktu eksekusi hingga 4,5 kali lipat. Kimi-K2.5 melampaui Gemini 3 Pro pada SWE-Bench Verified, dan Cursor AI telah mengonfirmasi bahwa fitur Composer 2 mereka dibangun di atas teknologi Kimi.
Memanggil Kimi-K2.5 melalui layanan proksi API Alibaba Cloud, dengan jalur penerusan tambahan, membuat pengalaman model triliunan parameter yang sudah membutuhkan banyak komputasi menjadi lebih buruk. Disarankan untuk menggunakan API resmi Moonshot AI (platform.moonshot.ai) secara langsung.
Analisis Latensi Panggilan API MiniMax-M2.5
MiniMax-M2.5 dirilis pada Februari 2026, dengan total 230 miliar parameter dan 10 miliar parameter aktif. Model ini mencetak skor 80,2% pada SWE-Bench Verified, dengan kecepatan penyelesaian 37% lebih cepat dibandingkan M2.1, setara dengan Claude Opus 4.6.
Keunggulan Biaya yang Menonjol: Model ini diklaim sebagai model terdepan pertama yang "pengguna tidak perlu khawatir tentang biaya" – hanya membutuhkan sekitar $1 untuk berjalan terus menerus selama 1 jam dengan kecepatan 100 token/detik. Model ini sudah open-source di Hugging Face, dan disarankan untuk menggunakan vLLM atau SGLang untuk deployment.
| Model | Waktu Rilis | Total Parameter | Parameter Aktif | Cara Panggilan yang Direkomendasikan | Status Open-Source |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 744 Miliar | 40 Miliar | API Resmi Zhipu AI | Open-Source MIT |
| Kimi-K2.5 | 2026.01.27 | 1 Triliun | 32 Miliar | API Resmi Moonshot AI | Open-Source |
| MiniMax-M2.5 | 2026.02.12 | 230 Miliar | 10 Miliar | Resmi MiniMax / Pihak Ketiga | Modifikasi MIT |
🎯 Rekomendasi Praktis: Untuk model pihak ketiga yang closed-source atau semi-open-source seperti GLM-5, Kimi-K2.5, dan MiniMax-M2.5, disarankan untuk langsung terhubung ke API resmi masing-masing penyedia untuk mendapatkan pengalaman terbaik. Jika Anda perlu mengelola antarmuka API dari berbagai model secara terpusat, Anda dapat menggunakan platform APIYI apiyi.com untuk memanggil berbagai model dengan satu kunci API, sambil menikmati harga yang lebih baik.
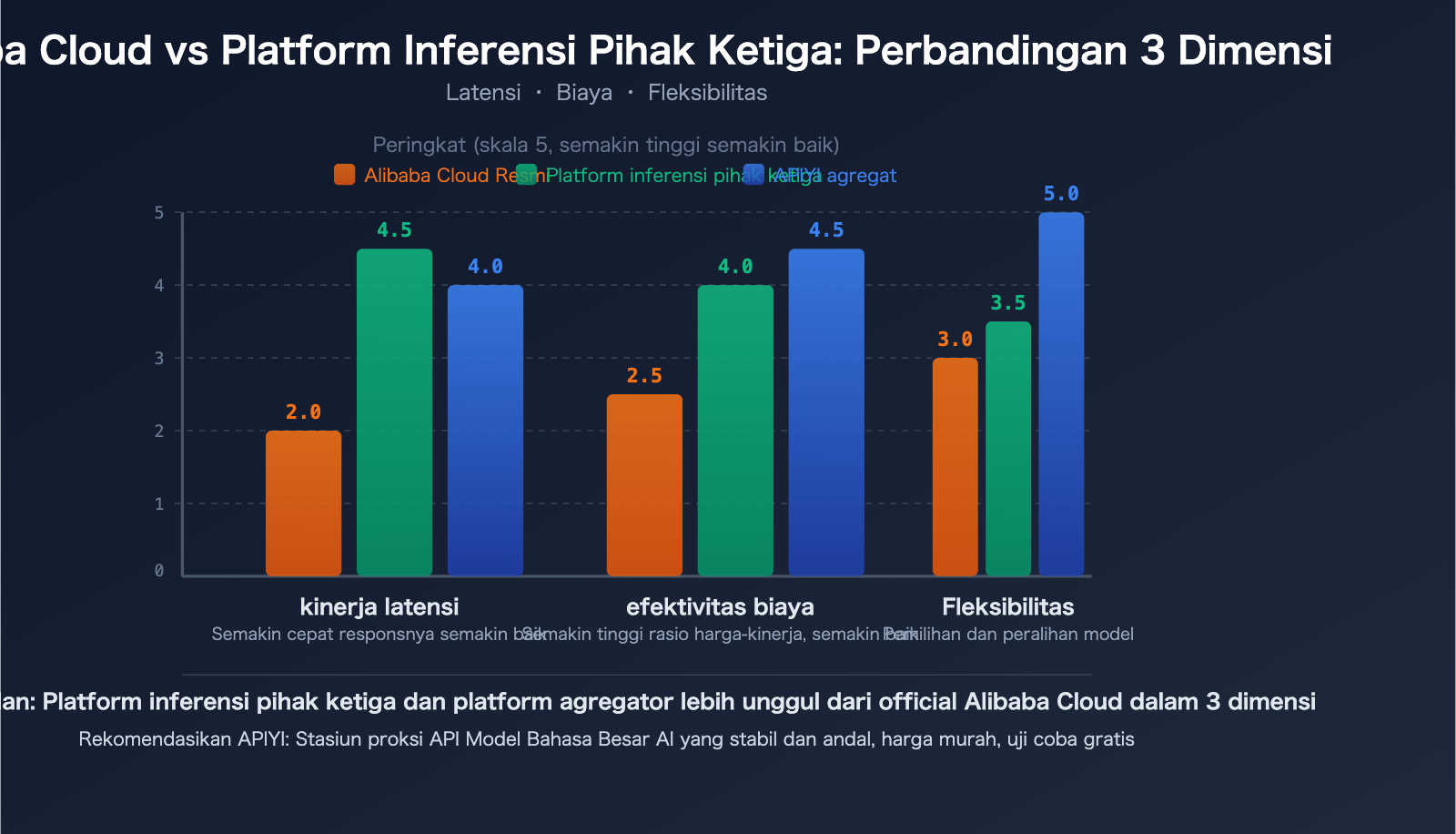
Platform Inferensi Pihak Ketiga vs. Alibaba Cloud: 3 Keunggulan Utama Deployment Model Open-Source
Untuk model open-source seperti Qwen3.5, selain API resmi Alibaba Cloud, pengembang memiliki lebih banyak pilihan. Platform inferensi pihak ketiga seringkali memiliki performa yang setara atau bahkan melampaui performa pabrikan asli dalam hal deployment model open-source.
Keunggulan 1: Kecepatan Inferensi Lebih Cepat
Kompetensi inti platform inferensi profesional adalah kecepatan. Melalui optimasi engine inferensi kustom, mereka mencapai latensi yang lebih rendah pada model yang sama:
| Tipe Platform | Latensi Khas | Throughput | Keunggulan Kecepatan |
|---|---|---|---|
| Platform Cloud Umum (Alibaba Cloud, dll.) | 100-300ms | Baseline | — |
| SiliconFlow | Turun 32% | Naik 2,3x | Custom CUDA Kernels |
| Fireworks AI | ~0.17s | ~747 TPS | FireAttention v2 |
| Together AI | — | Naik 2x | Speculative Decoding + FP4 Quantization |
| APIYI apiyi.com | Pemilihan Multi-Channel | Intelligent Routing | Memilih jalur tercepat secara otomatis |
Keunggulan 2: Biaya Lebih Rendah
Pada tahun 2026, pengeluaran inferensi AI untuk pertama kalinya melampaui pengeluaran pelatihan, menyumbang 55% dari total pengeluaran infrastruktur cloud AI. Dalam konteks ini, optimasi biaya inferensi menjadi sangat penting:
- Memanggil model open-source melalui API pihak ketiga biasanya berharga di bawah $1/M token, menghemat 70-90% dibandingkan model closed-source.
- Platform inferensi profesional memanfaatkan perangkat keras generasi baru seperti NVIDIA Blackwell untuk mengurangi biaya inferensi AI hingga 10 kali lipat.
- Tidak perlu membangun cluster GPU sendiri, bayar sesuai pemakaian, cocok untuk tim kecil dan menengah serta pengembang individu.
Keunggulan 3: Pilihan Model Lebih Fleksibel
Platform pihak ketiga biasanya mendukung model open-source dan closed-source, menyediakan antarmuka API terpadu dan penetapan harga yang transparan. Ini berarti:
- Tanpa Ketergantungan Vendor: Tidak terikat pada penyedia layanan cloud mana pun.
- Pergantian Cepat: Memanggil banyak model dengan satu antarmuka, memilih yang terbaik setelah membandingkan hasilnya.
- Optimasi Kustom: Model open-source mendukung operasi kustom seperti kuantisasi, fine-tuning, dan penggabungan.
💡 Saran Pemilihan: Untuk model open-source seperti Qwen3.5, deployment melalui platform inferensi pihak ketiga mungkin memberikan hasil yang lebih baik daripada API resmi Alibaba Cloud. Kami menyarankan untuk melakukan pengujian perbandingan aktual melalui platform APIYI apiyi.com, yang mengagregasi banyak jalur inferensi dan secara otomatis memilih jalur dengan latensi terendah untuk Anda.
Panggilan API Model Open-Source Cepat: Panduan Akses 5 Menit
Mengambil Qwen3.5-Flash sebagai contoh, panduan ini menunjukkan cara memanggil API model open-source dengan cepat melalui platform pihak ketiga.
Contoh Kode Minimalis
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Analisis keunggulan arsitektur MoE Qwen3.5"}
]
)
print(response.choices[0].message.content)
Lihat Kode Lengkap (termasuk peralihan multi-model dan penanganan kesalahan)
import openai
import time
# Inisialisasi klien - Panggil berbagai model secara terpadu melalui APIYI
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# Daftar model yang didukung
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "Jelaskan keunggulan arsitektur MoE dalam inferensi Model Bahasa Besar dalam 3 kalimat"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] Waktu yang dibutuhkan: {elapsed:.2f}s")
print(f"Balasan: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] Panggilan gagal: {e}")
🚀 Mulai Cepat: Sangat disarankan untuk menggunakan platform APIYI apiyi.com untuk menguji model di atas dengan cepat. Dapatkan kuota gratis saat mendaftar, dan satu kunci API dapat digunakan untuk memanggil model-model populer seperti Qwen3.5, GLM-5, Kimi-K2.5, MiniMax-M2.5, dll., tanpa perlu mendaftar di berbagai platform secara terpisah.
Rekomendasi Solusi Pemanggilan Model untuk Skenario Berbeda
Pilih cara pemanggilan yang paling sesuai berdasarkan kebutuhan Anda:
Skenario 1: Perlu Memanggil Model Tertutup/Semi-Tertutup
Jika Anda terutama menggunakan versi tertutup dari model seperti GLM-5, Kimi-K2.5 (bukan yang di-deploy sendiri), disarankan:
- Pilihan Utama: Langsung hubungi API resmi masing-masing, latensi terendah.
- Pilihan Kedua: Panggil secara terpadu melalui platform agregat seperti APIYI apiyi.com, mengorbankan sedikit latensi demi kemudahan pengelolaan.
Skenario 2: Perlu Menyebarkan Model Open-Source
Jika Anda menggunakan model seperti versi open-source Qwen3.5, GLM-5, MiniMax-M2.5:
- Anggaran Cukup: Pilih platform inferensi profesional seperti SiliconFlow, Together AI, latensi optimal.
- Prioritas Biaya-Efektivitas: Panggil secara terpadu melalui APIYI apiyi.com, yang secara otomatis merutekan ke saluran optimal.
- Kontrol Penuh: Gunakan vLLM atau SGLang untuk membangun layanan inferensi sendiri, memerlukan sumber daya GPU sendiri.
Skenario 3: Perlu Perbandingan Pengujian Multi-Model
Saat Anda perlu membandingkan efek beberapa model dengan cepat di awal pengembangan:
- Direkomendasikan: Gunakan antarmuka API terpadu (seperti APIYI apiyi.com), satu pendaftaran memungkinkan pengujian berbagai model.
- Hindari mendaftar akun terpisah dan mengelola banyak kunci API untuk setiap model.
💰 Saran Optimalisasi Biaya: Untuk proyek yang sensitif terhadap anggaran, memanggil API model open-source melalui platform APIYI apiyi.com adalah solusi yang paling hemat biaya. Platform ini menawarkan metode penagihan yang fleksibel, dan biaya pemanggilan model open-source jauh lebih rendah daripada harga resmi model tertutup.
Pertanyaan Umum
Q1: Qwen3.5-Flash disebut sebagai model ringan, mengapa API-nya tetap lambat?
Meskipun Qwen3.5-Flash hanya mengaktifkan 3 miliar parameter per inferensi, model ini secara default mendukung jendela konteks 1 juta token, serta mengintegrasikan kemampuan pemrosesan multimodal (teks + gambar + video) dan pemanggilan alat bawaan. "Biaya tersembunyi" ini membuat konsumsi daya komputasinya jauh lebih tinggi daripada model teks murni dengan jumlah parameter yang sama. Ditambah lagi dengan latar belakang sumber daya GPU Alibaba Cloud yang terbatas, waktu antrean semakin memperpanjang latensi yang dirasakan.
Q2: Jika model open-source di-deploy di platform pihak ketiga, apakah performanya akan berkurang?
Tidak. Platform inferensi pihak ketiga yang profesional (seperti SiliconFlow, Together AI) menggunakan bobot open-source versi asli, dikombinasikan dengan mesin inferensi yang dioptimalkan, sehingga performanya sama dengan pabrikan asli, bahkan kecepatan inferensinya lebih cepat. Melalui platform APIYI apiyi.com, Anda dapat dengan cepat membandingkan kualitas dan kecepatan inferensi dari berbagai saluran, lalu memilih solusi terbaik.
Q3: Kapan masalah daya komputasi Alibaba Cloud akan teratasi?
Menurut pernyataan publik dari eksekutif Alibaba Cloud, kekurangan pasokan GPU diperkirakan akan berlangsung selama 2-3 tahun. Dalam jangka pendek, Alibaba Cloud lebih memilih untuk meningkatkan pemanfaatan GPU yang ada melalui teknologi pooling sumber daya seperti Aegaeon, daripada melakukan ekspansi besar-besaran. Disarankan agar pengembang tidak menunggu optimasi platform, melainkan secara proaktif memilih solusi pemanggilan yang lebih sesuai — koneksi langsung API resmi atau platform inferensi pihak ketiga adalah solusi alternatif yang layak saat ini. Anda dapat menguji kecepatan pemanggilan berbagai model secara gratis melalui APIYI apiyi.com.
Kesimpulan: Strategi Mengatasi API Qwen3.5 Alibaba Cloud yang Lambat
Penyebab mendasar lambatnya respons API Qwen3.5 Alibaba Cloud adalah kekurangan pasokan daya komputasi GPU global, ditambah dengan konsumsi daya komputasi yang tinggi dari arsitektur model, perebutan sumber daya antar penyewa, dan faktor-faktor lainnya. Untuk masalah kelambatan yang terjadi saat memanggil model pihak ketiga seperti GLM-5, Kimi-K2.5, MiniMax-M2.5 melalui Alibaba Cloud, pada dasarnya disebabkan oleh alasan yang sama — Alibaba Cloud memprioritaskan sumber daya untuk model internalnya sendiri, sementara alokasi sumber daya untuk model pihak ketiga berada di posisi sekunder.
3 Saran Inti:
- Model Tertutup Langsung ke Resmi: Gunakan Zhipu API untuk GLM-5, Moonshot API untuk Kimi-K2.5, dan MiniMax API untuk MiniMax-M2.5, hindari latensi penerusan melalui lapisan perantara.
- Model Terbuka Pilih Pihak Ketiga: Performa model open-source seperti Qwen3.5 di platform inferensi profesional mungkin lebih baik daripada API resmi Alibaba Cloud.
- Manajemen Terpadu Gunakan Platform Agregat: Jika Anda perlu menggunakan beberapa model secara bersamaan, disarankan untuk menggunakan APIYI apiyi.com untuk memanggil semua model melalui satu antarmuka, yang menggabungkan efisiensi dan kemudahan pengelolaan.
Kekurangan daya komputasi akan menjadi hal yang lumrah bagi seluruh industri dalam 2-3 tahun ke depan. Daripada menunggu secara pasif perluasan kapasitas platform cloud, lebih baik mengoptimalkan strategi pemanggilan secara proaktif — memilih kombinasi platform dan model yang paling sesuai adalah jalur terbaik untuk meningkatkan pengalaman aplikasi AI.
Penulis: Tim APIYI | Untuk kiat pemanggilan API model AI lainnya, selamat datang di APIYI apiyi.com untuk mendapatkan tutorial terbaru dan kuota uji coba gratis
📚 Referensi
-
Dokumentasi Resmi Seri Model Qwen3.5: Spesifikasi Teknis Model Qwen Alibaba Cloud
- Tautan:
github.com/QwenLM/Qwen3.5 - Deskripsi: Berisi parameter model lengkap, pengujian benchmark, dan panduan penggunaan.
- Tautan:
-
Pengumuman Penyesuaian Harga Komputasi Alibaba Cloud: Kenaikan Harga Komputasi AI Mulai April 2026
- Tautan:
www.alibabacloud.com - Deskripsi: Penjelasan resmi mengenai ketidakseimbangan pasokan dan permintaan komputasi.
- Tautan:
-
Laporan Teknis GLM-5: Detail Teknis Model Unggulan Zhipu AI
- Tautan:
github.com/THUDM/GLM-5 - Deskripsi: Penjelasan arsitektur MoE 744 miliar parameter dan mode Agen.
- Tautan:
-
Dokumentasi Resmi Kimi-K2.5: Model Triliunan Parameter dari Moonshot AI
- Tautan:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - Deskripsi: Panduan fungsionalitas Agent Swarm dan akses API.
- Tautan:
-
Blog Teknis MiniMax-M2.5: Penjelasan Mendalam Model Open Source Terkini
- Tautan:
www.minimax.io/news/minimax-m25 - Deskripsi: Benchmark kinerja, saran penerapan, dan analisis biaya.
- Tautan: