Catatan penulis: Menjawab pertanyaan yang paling sering ditanyakan developer: Apakah API Model Bahasa Besar bisa langsung menerima file PDF? Jawabannya adalah sebagian besar tidak mendukung. Artikel ini menjelaskan 3 solusi praktis: ekstraksi teks, pemahaman gambar, dan pemrosesan di sisi klien.
"Bisakah API Model Bahasa Besar langsung menerima file PDF?" — Ini adalah salah satu pertanyaan yang paling sering muncul di grup dukungan pelanggan kami. Banyak developer yang terbiasa menggunakan fitur "seret dan lepas PDF langsung untuk berinteraksi" di ChatGPT atau Claude versi web, mengira API juga bisa beroperasi dengan cara yang sama.
Kenyataannya adalah: Sebagian besar API Model Bahasa Besar tidak mendukung input langsung file PDF. Bahkan vendor utama seperti OpenAI dan Anthropic, format input inti API mereka tetap berupa teks dan gambar — PDF tidak termasuk dalam dukungan standar. Yang lebih penting lagi, platform proksi API pihak ketiga seperti APIYI juga tidak mendukung pengiriman langsung PDF, karena protokol dasarnya memang tidak mendukung.
Tapi jangan khawatir, pemrosesan PDF sebenarnya memiliki 3 solusi yang sudah matang. Artikel ini akan membawa Anda memahami alur ceritanya, dan memilih cara yang paling cocok untuk Anda.
Nilai inti: Setelah membaca artikel ini, Anda akan memahami mengapa API Model Bahasa Besar tidak mendukung PDF, serta bagaimana menggunakan 3 skema pra-pemrosesan untuk memenuhi kebutuhan input PDF secara efisien.

Poin Inti Input PDF untuk API Model Bahasa Besar
| Poin | Penjelasan | Dampak |
|---|---|---|
| API Tidak Menerima PDF Langsung | Input standar API model utama seperti GPT, DeepSeek, Llama, Qwen adalah teks dan gambar | Diperlukan alur pra-pemrosesan terlebih dahulu |
| Versi Web ≠ API | Unggah PDF di ChatGPT, Claude versi web adalah pra-pemrosesan frontend sebelum memanggil API | Jangan samakan pengalaman web dengan kemampuan API |
| Platform Pihak Ketiga Juga Tidak Mendukung | Platform proksi seperti APIYI meneruskan protokol API asli, jika lapisan dasar tidak mendukung maka platform juga tidak | Jangan berharap platform proksi memproses PDF tambahan |
| 3 Skema Pra-pemrosesan Sudah Matang dan Andal | Ekstraksi teks, pemahaman gambar, pemrosesan klien masing-masing memiliki skenario yang cocok | Memilih skema yang tepat lebih praktis daripada mencari "API yang mendukung PDF" |
Mengapa API Model Bahasa Besar Tidak Mendukung Input PDF?
Banyak pengembang bingung: versi web jelas bisa mengunggah PDF, mengapa API tidak bisa? Alasannya sederhana—fungsi "unggah PDF" di versi web bukanlah model itu sendiri yang memproses PDF, melainkan frontend/backend melakukan pra-pemrosesan di tempat yang tidak Anda lihat:
- Ekstraksi Teks: Frontend mengekstrak teks dari PDF, mengubahnya menjadi teks biasa baru kemudian mengirimkannya ke model
- Rendering Halaman: Merender setiap halaman PDF menjadi gambar, memungkinkan model memahami melalui kemampuan Vision
- Retrieval RAG: Menyimpan konten PDF secara vektorisasi, saat percakapan hanya mengambil potongan terkait yang dikirim ke model
Langkah-langkah pra-pemrosesan ini dikemas dalam produk versi web, pengguna tidak menyadarinya. Tetapi ketika Anda memanggil API secara langsung, pra-pemrosesan ini perlu Anda selesaikan sendiri.
Cepat Cek Dukungan PDF untuk API Model Bahasa Besar
| Model | Unggah PDF Langsung ke API | Format Input Standar | Saran Penanganan PDF |
|---|---|---|---|
| GPT-4o / GPT-4.1 | Tidak didukung | Teks + gambar (Base64) | Ekstrak teks atau konversi ke gambar terlebih dahulu |
| Claude | Didukung sebagian (Beta) | Teks + gambar | Disarankan tetap melalui alur pra-pemrosesan agar lebih stabil |
| Gemini | Didukung sebagian | Teks + gambar | Disarankan tetap melalui alur pra-pemrosesan agar lebih terkontrol |
| DeepSeek | Tidak didukung | Teks biasa | Harus mengekstrak teks terlebih dahulu |
| Llama / Qwen | Tidak didukung | Teks (sebagian mendukung gambar) | Harus mengekstrak teks terlebih dahulu |
| APIYI dan Pihak Ketiga Lainnya | Tidak didukung | Meneruskan protokol asli | Perlu pra-pemrosesan sendiri sebelum pemanggilan |
🎯 Penjelasan Penting: Meskipun dokumentasi API resmi Claude dan Gemini menyebutkan fungsi input PDF, fungsi ini memiliki ketidakpastian kompatibilitas dan stabilitas, dan tidak mendukung unggah PDF langsung saat dipanggil melalui platform proksi pihak ketiga seperti APIYI. Kami menyarankan untuk menggunakan skema pra-pemrosesan secara seragam, kompatibilitas terbaik dan paling stabil.
Skema Penanganan PDF API Model Bahasa Besar 1: Ekstraksi Teks Terlebih Dahulu
Ini adalah skema yang paling universal, biaya terendah, dan kompatibel dengan semua model. Inti pemikirannya: Pertama gunakan pustaka Python untuk mengubah PDF menjadi Markdown atau teks biasa, lalu kirim teks sebagai petunjuk ke API.
Perbandingan Alat Ekstraksi Teks PDF
| Alat | Kecepatan | Skenario Terbaik | Karakteristik |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/dokumen | Ekstraksi teks umum + tabel | Keseimbangan kecepatan dan kualitas terbaik, keluaran Markdown |
| pdfplumber | Sedang | Ekstraksi data tabel | Presisi ekstraksi tabel tingkat koordinat tinggi |
| Marker-PDF | ~11s/dokumen | Konversi tata letak kompleks dengan kesetiaan tinggi | Struktur dipertahankan dengan baik, kecepatan lambat |
| PyPDF2 | Cepat | PDF teks biasa sederhana | Ringan, cocok untuk ekstraksi dasar |
Contoh Kode Ekstraksi Teks PDF
Berikut adalah skema yang paling umum digunakan, mengekstrak teks PDF lalu mengirimkannya ke API Model Bahasa Besar:
import pymupdf4llm
import openai
# Langkah 1: PDF ke Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Langkah 2: Kirim teks biasa ke Model Bahasa Besar apa pun
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Tolong rangkum poin inti dari laporan ini:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Skenario yang Cocok: PDF yang didominasi teks seperti kontrak, makalah, laporan, dokumen teknis. Selama PDF memiliki lapisan teks tertanam (bukan hasil pindaian), efek ekstraksinya bagus.
Saran: Skema ekstraksi teks kompatibel dengan semua Model Bahasa Besar—GPT, Claude, DeepSeek, Llama, Qwen semuanya bisa. Dapatkan Kunci API melalui APIYI apiyi.com, satu Kunci dapat digunakan untuk memanggil semua model untuk pengujian perbandingan.
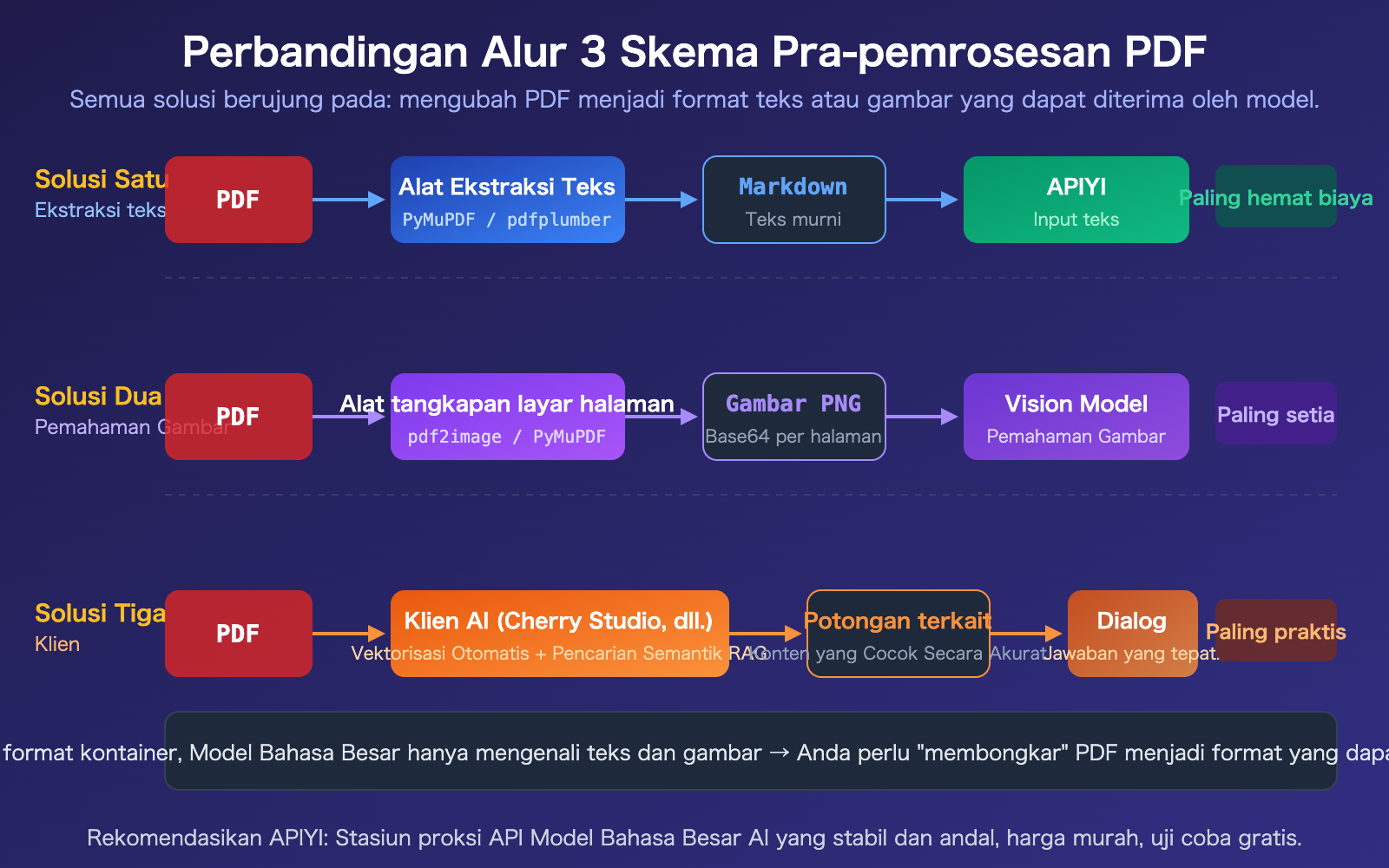
Solusi Pemrosesan PDF dengan API Model Bahasa Besar 2: Konversi ke Gambar + Pemahaman Visual
Ketika PDF berisi informasi visual seperti grafik, dokumen hasil pindai, tata letak kompleks, ekstraksi teks murni akan kehilangan konten tersebut. Dalam kasus ini, Anda perlu merender setiap halaman PDF menjadi gambar, lalu memahaminya melalui model yang mendukung Vision.
Contoh Kode Konversi PDF ke Gambar
import fitz # PyMuPDF
import base64
import openai
# Langkah 1: Konversi PDF halaman demi halaman ke gambar PNG
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
Lihat kode lengkap: Mengirim Gambar ke Vision API
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""Mengonversi PDF ke gambar lalu mengirimkannya ke Vision API"""
doc = fitz.open(pdf_path)
# Bangun pesan multi-gambar (perhatikan jumlah halaman untuk menghindari kelebihan Token)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# Contoh penggunaan
result = pdf_to_vision(
"financial_report.pdf",
"Analisis grafik tren dalam laporan keuangan ini dan rangkum data intinya",
max_pages=5 # Kontrol jumlah halaman, setiap halaman kira-kira menghabiskan 765 token
)
print(result)
Skenario yang Cocok: PDF kaya informasi visual seperti laporan penelitian dengan grafik, dokumen hasil pindai, faktur, gambar teknik arsitektur.
Pengingat Biaya: Setiap halaman gambar menghabiskan sekitar 765 token (resolusi standar GPT-4o), PDF 10 halaman berarti sekitar 7.650 token untuk biaya gambar, ditambah pertanyaan dan jawaban teks bisa melebihi 10.000 token. Pastikan untuk mengontrol jumlah halaman.
🎯 Saran Pengendalian Biaya: Jangan kirim semua halaman PDF sekaligus. Gunakan dulu Solusi 1 untuk mengekstrak teks dan melakukan penyaringan kasar, tentukan halaman kunci, lalu gunakan Solusi 2 untuk memahami gambar pada halaman tertentu. Anda dapat memantau konsumsi token secara real-time melalui panel penggunaan di APIYI apiyi.com.
Solusi Pemrosesan PDF dengan API Model Bahasa Besar 3: Pemrosesan oleh Klien AI
Jika Anda tidak ingin menulis kode dan hanya perlu "bertanya tentang isi PDF" dalam percakapan sehari-hari, menggunakan klien AI adalah cara termudah.
Prinsip Pemrosesan PDF oleh Klien seperti Cherry Studio
Klien semacam ini pada dasarnya secara otomatis menyelesaikan pekerjaan dari Solusi 1 dan 2:
- Vektorisasi Otomatis: Mengekstrak konten PDF, memotongnya menjadi potongan-potongan kecil, dan menyimpannya ke dalam basis data vektor lokal.
- Pencarian Semantik: Saat Anda bertanya, klien terlebih dahulu mengambil potongan konten yang paling relevan.
- Pengiriman Tepat: Hanya mengirimkan potongan yang relevan (bukan seluruh teks) ke API Model Bahasa Besar.
- Hemat Token: Mengurangi drastis jumlah konten yang dikirim ke model melalui pencarian RAG.
Hal yang Perlu Diperhatikan Saat Memproses PDF dengan Klien
- Konfigurasi Kunci API: Masukkan Kunci API dari APIYI apiyi.com ke dalam klien, maka Anda dapat mengakses semua model dengan satu kunci.
- Kontrol Ukuran File: PDF yang sangat besar (ratusan halaman) memerlukan waktu vektorisasi yang lama, disarankan untuk membaginya terlebih dahulu.
- Perhatikan Biaya Token: Meskipun RAG mengompresi konten, dokumen panjang tetap dapat menghasilkan biaya yang tinggi.
- Pilih Model yang Tepat: Untuk tanya jawab sederhana, gunakan model yang lebih murah (seperti GPT-4o-mini). Untuk analisis kompleks, gunakan model unggulan.
Perbandingan 3 Solusi Pemrosesan PDF dengan API Model Bahasa Besar

| Solusi | Biaya Token | Dukungan Grafik | Tingkat Kesulitan Pengembangan | Kompatibilitas Model | Skenario Terbaik |
|---|---|---|---|---|---|
| Ekstraksi Teks | Terendah (300-1500/halaman) | Tidak mendukung | Sedang | Semua model | PDF teks murni, volume besar |
| Konversi ke Gambar | Lebih tinggi (~765/halaman) | Dukungan lengkap | Sedang | Membutuhkan model Vision | Grafik, dokumen hasil pindai |
| Pemrosesan Klien | Sedang (kompresi RAG) | Tergantung klien | Tanpa kode | Semua model | Percakapan sehari-hari, non-pengembang |
Penjelasan Perbandingan: Ketiga solusi ini tidak saling eksklusif, dalam proyek nyata sering dikombinasikan. Misalnya, gunakan solusi pertama untuk ekstraksi teks sebagai penyaringan awal, lalu gunakan solusi kedua untuk halaman kunci dengan pemahaman gambar. Melalui APIYI apiyi.com, Anda dapat mengintegrasikan semua model secara terpadu.
Pertanyaan Umum
Q1: Mengapa ChatGPT versi web bisa mengunggah PDF, tapi API tidak mendukung?
Fitur "unggah PDF" di versi web adalah hasil pemrosesan awal yang dilakukan oleh antarmuka produk untuk Anda—mengekstrak teks, merender gambar, membangun indeks pencarian—baru kemudian memanggil API di balik layar. Format input inti dari API itu sendiri adalah teks dan gambar. PDF, sebagai format wadah dokumen yang kompleks, tidak termasuk dalam dukungan standar. Saat Anda memanggil API, Anda perlu menyelesaikan langkah-langkah pra-pemrosesan ini sendiri.
Q2: Apakah platform proksi pihak ketiga seperti APIYI bisa membantu saya memproses PDF?
Tidak bisa. Inti dari platform proksi seperti APIYI adalah meneruskan permintaan API secara transparan. Jika protokol dasarnya tidak mendukung PDF, platform juga tidak bisa memprosesnya. Anda perlu menyelesaikan pra-pemrosesan PDF sendiri (mengekstrak teks atau mengonversi ke gambar) sebelum memanggil API, lalu mengirim teks atau gambar yang sudah diproses ke Model Bahasa Besar melalui APIYI di apiyi.com.
Q3: Bagaimana mengontrol biaya Token saat memproses PDF?
Beberapa tips praktis:
- Prioritaskan skema pertama (ekstraksi teks), biayanya paling rendah
- Hanya proses halaman yang dibutuhkan, jangan kirim seluruh dokumen sekaligus
- Gunakan teknik RAG untuk memotong + mencari, hanya kirim potongan yang relevan ke model
- Gunakan model murah (GPT-4o-mini) untuk tanya jawab sederhana, dan model unggulan untuk analisis kompleks
- Pantau konsumsi secara real-time melalui panel penggunaan di APIYI apiyi.com
Ringkasan
Inti dari input PDF ke API Model Bahasa Besar:
- Sebagian besar API tidak mendukung input PDF langsung: Input inti Model Bahasa Besar adalah teks dan gambar, PDF perlu diproses terlebih dahulu sebelum digunakan
- Platform pihak ketiga juga tidak mendukung: Platform proksi seperti APIYI meneruskan protokol asli, tidak bisa memproses PDF tambahan
- Pilih dari 3 skema sesuai kebutuhan: PDF teks murni gunakan ekstraksi teks (paling hemat), PDF bergambar konversi ke gambar (paling akurat), percakapan sehari-hari gunakan klien (paling praktis)
Jangan terlalu fokus pada "API mana yang mendukung PDF", tetapi alihkan perhatian pada memilih skema pra-pemrosesan yang tepat—ini adalah cara berpikir yang benar.
Disarankan untuk mendapatkan kuota gratis melalui APIYI di apiyi.com, lalu setelah memproses PDF, gunakan satu Kunci API untuk memanggil dan menguji perbandingan semua model utama seperti GPT, Claude, DeepSeek.
📚 Referensi
-
Dokumentasi PyMuPDF4LLM: Alat ekstraksi teks PDF
- Tautan:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Keterangan: Alat PDF ke Markdown tercepat, direkomendasikan sebagai pilihan utama
- Tautan:
-
Dokumentasi pdfplumber: Alat khusus ekstraksi tabel
- Tautan:
github.com/jsvine/pdfplumber - Keterangan: Alat dengan akurasi tertinggi untuk ekstraksi data tabel dari PDF
- Tautan:
-
Cherry Studio: Klien AI sumber terbuka
- Tautan:
github.com/CherryHQ/cherry-studio - Keterangan: Klien gratis yang mendukung drag-and-drop PDF ke dalam percakapan, dapat dikonfigurasi dengan APIYI sebagai backend
- Tautan:
-
Dokumentasi Platform APIYI: Akses terpadu ke berbagai API Model Bahasa Besar
- Tautan:
docs.apiyi.com - Keterangan: Cara mendapatkan kunci API, daftar model, dan contoh pemanggilan
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Selamat berdiskusi di kolom komentar, materi lebih lanjut dapat diakses di pusat dokumentasi APIYI docs.apiyi.com