Seri Grok 4.20 Beta dari xAI kini resmi hadir di platform APIYI—menambahkan 4 model baru sekaligus yang mencakup seluruh skenario, mulai dari tanya jawab cepat hingga riset mendalam berbasis multi-agen. Dengan harga $2 per juta token untuk input dan $6 per juta token untuk output, ini adalah salah satu pilihan dengan rasio harga-performa terbaik di antara model unggulan saat ini.
Keempat model ini bukan sekadar peningkatan versi biasa, melainkan perbedaan pada level arsitektur: ada yang dirancang untuk respons secepat kilat, ada yang fokus pada penalaran mendalam, dan satu model yang memungkinkan 4 agen AI bekerja sama secara simultan—menurunkan tingkat halusinasi hingga 65%.
Nilai Utama: Setelah membaca artikel ini, Anda akan memahami posisi dan skenario penggunaan terbaik dari keempat model Grok 4.20 Beta, menguasai cara pemanggilan API, serta mampu mengambil keputusan pemilihan model yang paling optimal.

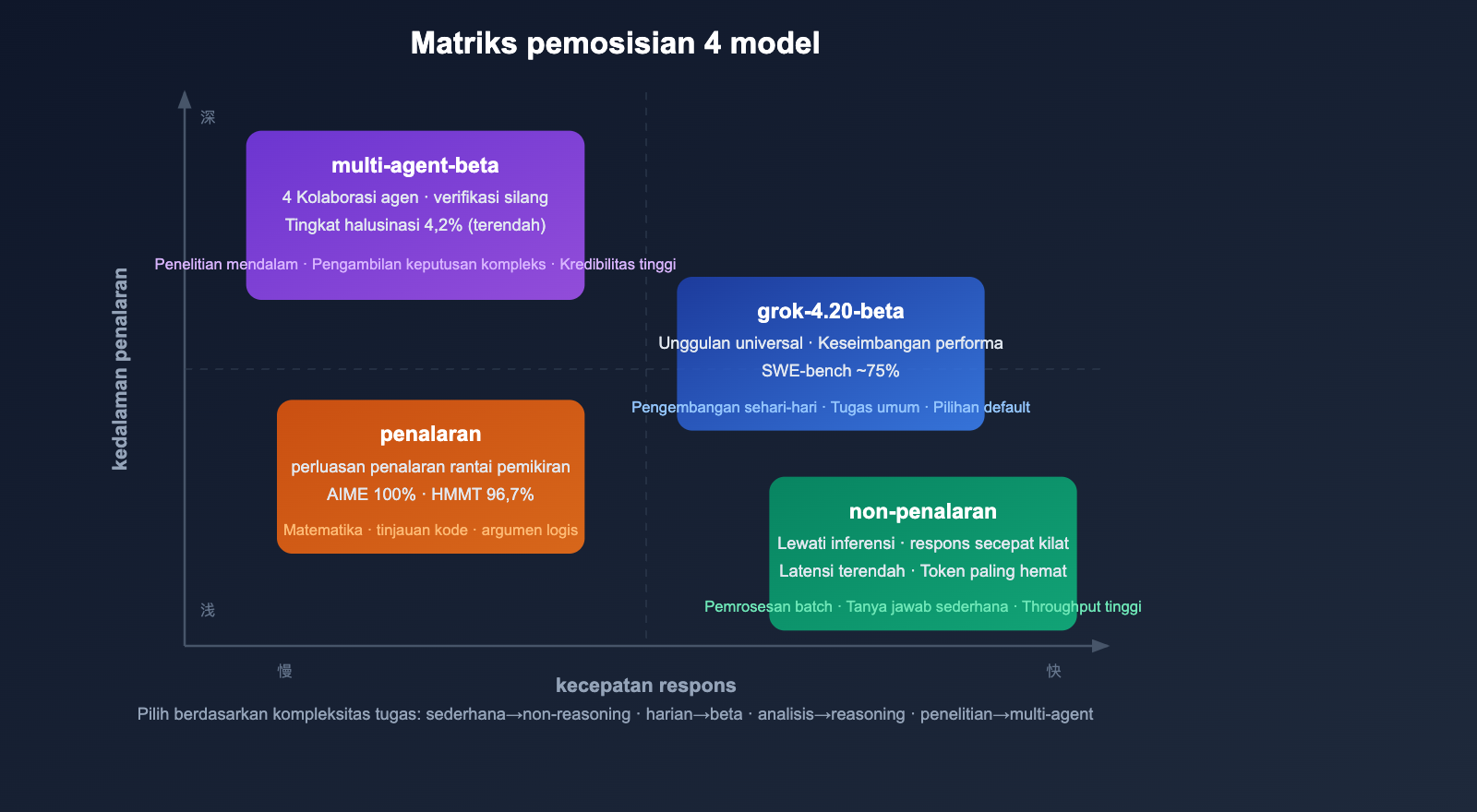
Sekilas 4 Model: Cek Cepat Perbedaan Utama
Matriks Model
| ID Model | Posisi | Fitur Utama | Skenario Terbaik |
|---|---|---|---|
grok-4.20-beta |
Unggulan Umum | Keseimbangan performa & kecepatan | Pengembangan harian, tugas umum |
grok-4.20-multi-agent-beta-0309 |
Kolaborasi Multi-Agen | 4 Agen bekerja paralel | Riset mendalam, analisis kompleks |
grok-4.20-beta-0309-non-reasoning |
Respons Cepat | Lewati rantai penalaran, latensi rendah | Pemrosesan batch, tanya jawab simpel |
grok-4.20-beta-0309-reasoning |
Penalaran Mendalam | Rantai pemikiran yang diperluas | Matematika, analisis kode, argumen logis |
Harga Seragam
| Item Penagihan | Harga |
|---|---|
| Token Input | $2.00 / juta token |
| Token Output | $6.00 / juta token |
| Jendela Konteks | 2 juta token (2M) |
| Diskon Batch | 50% |
Perbandingan Harga dengan Kompetitor:
| Model | Harga Input | Harga Output | Rasio Harga-Performa |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 Terbaik |
| Gemini 3.1 Pro | $2.00 | $12.00 | Baik |
| GPT-5.4 | $2.50 | $15.00 | Biasa |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Biasa |
| Claude Opus 4.6 | $15.00 | $75.00 | Cukup Tinggi |
Harga output Grok 4.20 hanya 40% dari Claude Sonnet 4.6 dan 8% dari Claude Opus 4.6. Untuk tugas yang intensif dalam output (pembuatan kode, teks panjang), keunggulan biayanya sangat signifikan.
🎯 Catatan Harga: Seri Grok 4.20 Beta yang tersedia di APIYI (apiyi.com) memiliki harga yang sama dengan situs resmi xAI (Input $2 / Output $6), dengan diskon tambahan yang tersedia melalui aktivitas isi ulang saldo platform. Satu kunci API dapat digunakan untuk memanggil 200+ model termasuk Grok, Claude, GPT, dan lainnya.
Analisis Mendalam 4 Model
Model 1: grok-4.20-beta (Flagship Umum)
Ini adalah pintu masuk standar untuk seri Grok 4.20, yang menyeimbangkan performa, kecepatan, dan biaya.
Fitur Utama:
- Mewarisi semua kemampuan keluarga Grok 4
- Jendela konteks 2 juta token—terbesar di antara model mutakhir Barat
- Mendukung input gambar (JPG/PNG)
- Terus ditingkatkan setiap minggu berdasarkan umpan balik dunia nyata
Performa Tolok Ukur:
- SWE-bench: ~75% (mendekati 74,9% milik GPT-5)
- GPQA (tingkat pascasarjana): 88,4%
- Arena Elo: ~1.505-1.535
Skenario Penggunaan: Bantuan pemrograman harian, pembuatan konten, analisis data, percakapan umum
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "Implementasikan cache LRU menggunakan Python"}
]
)
print(response.choices[0].message.content)
Model 2: grok-4.20-multi-agent-beta-0309 (Multi-Agen)
Ini adalah varian paling inovatif dari Grok 4.20—4 agen AI bekerja sama secara simultan untuk memproses permintaan Anda.
4 Agen dengan Peran Masing-masing:
| Agen | Peran | Keahlian |
|---|---|---|
| Grok (Kapten) | Koordinator | Pemecahan tugas, manajemen alur, agregasi output |
| Harper | Peneliti | Pencarian data real-time, verifikasi fakta (akses data X/Twitter) |
| Benjamin | Analis | Penalaran logis, perhitungan matematika, analisis kode |
| Lucas | Penantang | Sintesis kreatif, posisi oposisi bawaan—mempertanyakan kesimpulan agen lain |
Alur Kerja:
Pertanyaan pengguna
↓
Grok memecah tugas → mendistribusikan ke 4 agen
↓
Harper mengumpulkan data | Benjamin analisis logika | Lucas menantang
↓
Debat internal antar agen + verifikasi silang
↓
Grok mengagregasi konsensus → mengembalikan jawaban akhir
Keunggulan Utama—Tingkat halusinasi berkurang 65%:
| Metrik | Basis Model Tunggal | Mode Multi-Agen | Peningkatan |
|---|---|---|---|
| Tingkat halusinasi | ~12% | ~4,2% | Turun 65% |
| Rasio "mengatakan tidak tahu saat tidak yakin" | — | 78% | Tertinggi di industri |
"Posisi oposisi bawaan" milik Lucas adalah desain kunci: tugasnya adalah mencari celah dalam kesimpulan agen lain. Kolaborasi adversarial ini membuat output akhir jauh lebih andal.
Skenario Penggunaan: Laporan penelitian mendalam, analisis pengambilan keputusan yang kompleks, output yang membutuhkan kredibilitas tinggi
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "Analisis lanskap persaingan dan prediksi tren pasar alat pemrograman AI tahun 2026"}
]
)
Model 3: grok-4.20-beta-0309-non-reasoning (Non-Penalaran)
Ini adalah varian yang dioptimalkan untuk kecepatan dan throughput. Model ini melewati rantai penalaran internal (Chain-of-Thought) dan langsung menghasilkan jawaban.
Fitur Utama:
- Latensi rendah, throughput tinggi
- Tidak menghasilkan token penalaran internal, menghemat biaya output
- Cocok untuk tugas sederhana dan jelas
Skenario Penggunaan:
- Pemanggilan API frekuensi tinggi (pemrosesan data batch)
- Chatbot / sistem layanan pelanggan
- Klasifikasi konten, ekstraksi label
- Pelengkapan kode sederhana
- Terjemahan, ringkasan
Tidak cocok untuk: Penurunan matematika yang kompleks, analisis logika multi-langkah, desain arsitektur yang membutuhkan pemikiran mendalam
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "Konversi JSON berikut ke format CSV: ..."}
]
)
Model 4: grok-4.20-beta-0309-reasoning (Penalaran)
Ini adalah varian penalaran mendalam yang berlawanan dengan versi non-penalaran. Model ini mengaktifkan rantai pemikiran yang diperluas (Extended Chain-of-Thought) untuk melakukan penalaran internal yang mendalam sebelum menjawab.
Fitur Utama:
- Token penalaran yang diperluas, analisis masalah secara mendalam
- Performa luar biasa dalam tugas matematika dan logika (AIME 2025: 100%, HMMT25: 96,7%)
- Indeks Kecerdasan Artificial Analysis: 48
Skenario Penggunaan:
- Pembuktian dan penurunan matematika
- Tinjauan kode dan analisis Bug
- Pertimbangan desain arsitektur
- Argumen logika kompleks
- Analisis makalah akademik
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "Analisis potensi kondisi balapan (race condition) dan risiko kebuntuan (deadlock) dalam kode konkuren ini"}
]
)
💡 Saran Pemilihan: Untuk sebagian besar tugas harian,
grok-4.20-betasudah cukup. Gunakan versi multi-agen untuk output dengan kredibilitas tinggi, versi non-penalaran untuk pemrosesan batch, dan versi penalaran untuk analisis kompleks. Anda dapat memanggil keempat model tersebut hanya dengan satu kunci melalui APIYI (apiyi.com) dan beralih sesuai kebutuhan.
Pohon Keputusan Pemilihan Model
Memilih Berdasarkan Jenis Tugas
| Jenis Tugas | Model Rekomendasi | Alasan |
|---|---|---|
| Bantuan Pemrograman Harian | grok-4.20-beta |
Keseimbangan performa dan biaya |
| Pemrosesan Data Batch | non-reasoning |
Kecepatan tertinggi, latensi terendah |
| Analisis Kode/Bug | reasoning |
Memerlukan penalaran mendalam |
| Penulisan Laporan Riset | multi-agent |
Verifikasi silang 4 agen |
| Analisis Data Real-time | multi-agent |
Harper terhubung dengan data X real-time |
| Penalaran Matematika/Logika | reasoning |
Skor sempurna 100% AIME |
| Chatbot | non-reasoning |
Respons cepat dengan latensi rendah |
| Terjemahan/Ringkasan Konten | non-reasoning |
Tugas sederhana tidak butuh penalaran |
| Desain Arsitektur | reasoning atau multi-agent |
Memerlukan analisis kompromi |
Memilih Berdasarkan Sensitivitas Biaya
Paling Hemat → non-reasoning (tanpa token penalaran, output minimal)
↓
Efisiensi Harian → grok-4.20-beta (keseimbangan umum)
↓
Prioritas Kualitas → reasoning (penalaran mendalam, output token lebih banyak)
↓
Kredibilitas Tertinggi → multi-agent (4 agen, output paling detail)
🚀 Mulai Cepat: Disarankan untuk mencoba
grok-4.20-betaterlebih dahulu. Daftar melalui APIYI di apiyi.com untuk mendapatkan kunci API. Harga sama dengan situs resmi xAI ($2 untuk input / $6 untuk output), dengan diskon yang tersedia melalui promosi isi ulang.
Perbandingan Grok 4.20 vs Model Utama
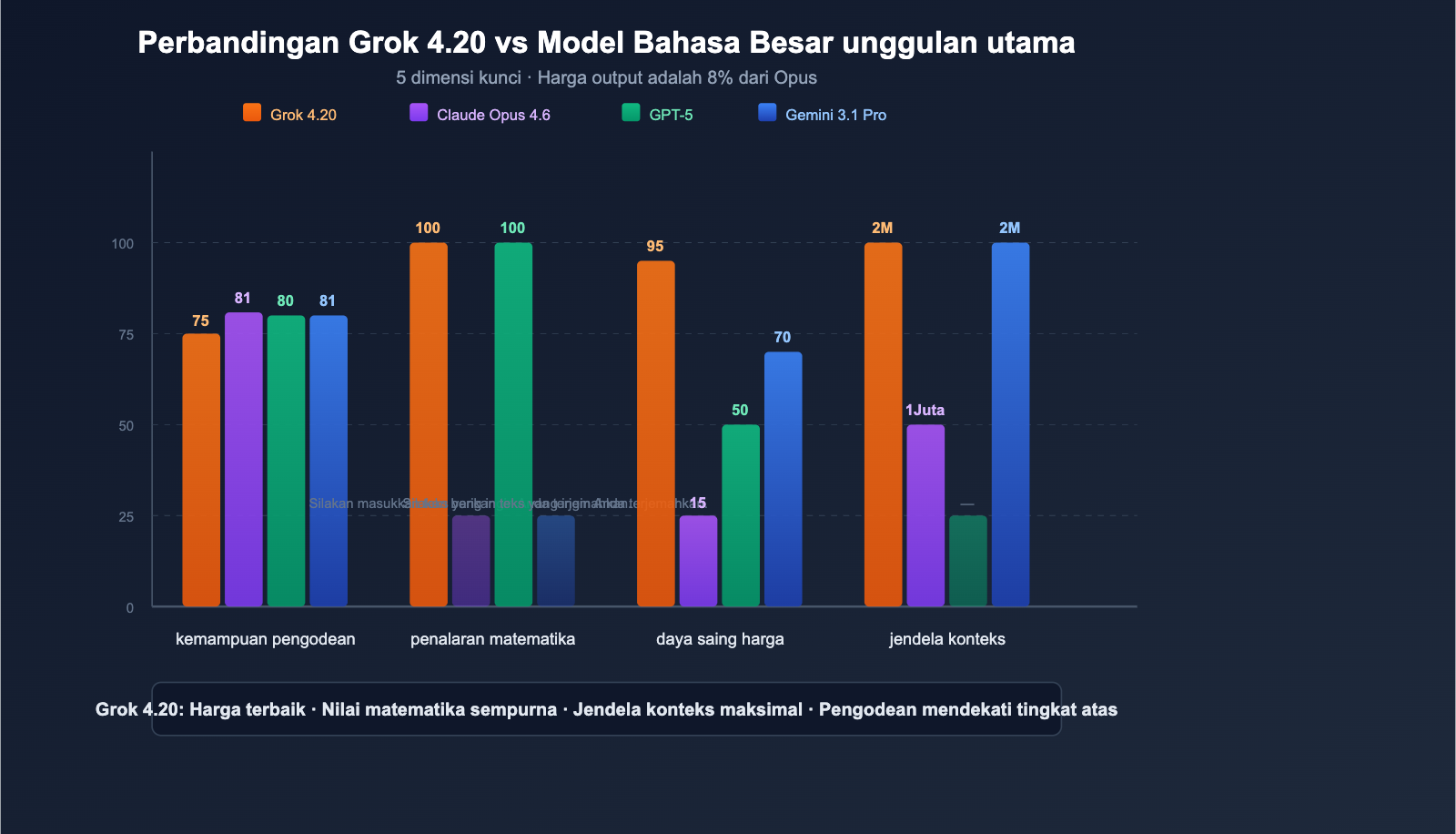
Perbandingan Seluruh Dimensi
| Dimensi | Grok 4.20 Beta | Claude Opus 4.6 | Seri GPT-5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| Matematika (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| Konteks | 2 Juta | 1 Juta | Bervariasi | 2 Juta |
| Harga Input | $2 | $15 | $2.50 | $2 |
| Harga Output | $6 | $75 | $15 | $12 |
| Multi-agen | ✅ 4 Agen | ❌ | ❌ | ❌ |
| Data Real-time | ✅ X/Twitter | ❌ | ✅ Pencarian | ✅ Pencarian |
| Kontrol Halusinasi | 4.2% (Terendah) | Rendah | Rendah | Sedang |
| Input Gambar | ✅ JPG/PNG | ✅ Multi-format | ✅ Multi-format | ✅ Multi-format |
Skenario Terbaik untuk Setiap Model
- Grok 4.20: Umum dengan efisiensi biaya tinggi, riset mendalam (multi-agen), analisis data real-time
- Claude Opus 4.6: Rekayasa perangkat lunak (SWE-bench tertinggi), output sangat panjang (128K), keamanan tingkat perusahaan
- GPT-5: Skor matematika sempurna, otomatisasi desktop, ekosistem pengguna terbesar
- Gemini 3.1 Pro: Integrasi ekosistem Google, konteks 2 juta, biaya moderat
💰 Analisis Efisiensi Biaya: Harga output Grok 4.20 ($6/MTok) hanya 8% dari harga Claude Opus 4.6 ($75/MTok). Untuk tugas yang padat output (pembuatan kode panjang, laporan riset), menggunakan Grok 4.20 dapat memangkas biaya hingga lebih dari 90%. Melalui APIYI di apiyi.com, Anda dapat mengakses seluruh seri model Grok, Claude, dan GPT secara bersamaan, serta beralih dengan fleksibel sesuai kebutuhan tugas.
Praktik Pemanggilan API
Contoh Pemanggilan Dasar
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
# Tugas umum → Versi dasar
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "Anda adalah pengembang Python senior."},
{"role": "user", "content": "Implementasikan antrean tugas asinkron"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Pemilihan Model Otomatis Berdasarkan Tugas
def choose_grok_model(task_type):
"""Memilih model Grok optimal berdasarkan jenis tugas"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# Contoh penggunaan
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Analisis hambatan performa kode ini..."}]
)
Lihat kode uji perbandingan multi-model
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Implementasikan quick sort dengan Python dan analisis kompleksitas waktunya"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" Waktu: {elapsed:.1f}s | Token: {tokens}")
print(f" Pratinjau: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | Error: {e}")
time.sleep(1)
🎯 Saran Praktis: Disarankan untuk menjalankan benchmark dengan
grok-4.20-betaterlebih dahulu, lalu bandingkan kualitas output tugas kompleks dengan versireasoning. Anda bisa memanggil keempat model tersebut melalui APIYI di apiyi.com, dengan harga yang sama seperti situs resmi dan diskon yang tersedia melalui promosi isi ulang.
Pertanyaan Umum
Q1: Apakah harga keempat model tersebut sama?
Ya, keempat model memiliki harga seragam: $2 untuk input / $6 untuk output per satu juta token. Namun, biaya aktual bervariasi tergantung model—model penalaran akan menghasilkan lebih banyak token penalaran (dihitung sebagai output), dan versi multi-agen mungkin mengonsumsi lebih banyak token karena kolaborasi 4 Agen. Versi non-penalaran adalah yang paling hemat biaya karena melewati rantai penalaran dan menghasilkan token output paling sedikit. Pemanggilan melalui APIYI apiyi.com memiliki harga yang sama dengan situs resmi xAI, dengan diskon yang diberikan melalui aktivitas isi ulang platform.
Q2: Apa perbedaan antara versi multi-agen dan versi penalaran?
Versi penalaran adalah satu Agen yang melakukan pemikiran mendalam—cocok untuk tugas analisis yang memiliki jawaban pasti (matematika, tinjauan kode). Versi multi-agen adalah 4 Agen yang berdiskusi secara kolaboratif—cocok untuk pertanyaan terbuka yang memerlukan analisis dari berbagai sudut pandang (riset pasar, analisis keputusan). Keunggulan utama versi multi-agen adalah verifikasi silang untuk mengurangi tingkat halusinasi (dari 12% turun menjadi 4,2%).
Q3: Bisakah Grok 4.20 menggantikan Claude untuk tinjauan kode?
Dalam beberapa skenario, bisa. Grok 4.20 versi penalaran mencapai ~75% pada SWE-bench, di bawah Claude Opus 4.6 yang mencapai 81,4%, tetapi harganya hanya 8% dari harga Claude. Untuk tinjauan kode harian yang tidak kritis terhadap keamanan, Grok 4.20 versi penalaran adalah pilihan yang sangat hemat biaya. Untuk audit keamanan dan tinjauan arsitektur skala besar, Claude Opus 4.6 tetap lebih andal. Melalui APIYI apiyi.com, Anda dapat mengakses kedua model tersebut dan beralih secara fleksibel sesuai tugas.
Q4: Apa kegunaan praktis dari jendela konteks 2 juta token?
2 juta token setara dengan buku teknis setebal 1500 halaman. Aplikasi praktisnya: (1) Memuat seluruh basis kode menengah hingga besar untuk dianalisis sekaligus; (2) Memproses dokumen super panjang (kontrak hukum, kumpulan makalah akademik); (3) Menjaga memori percakapan yang sangat panjang. Ini adalah jendela konteks terbesar di antara model-model mutakhir Barat saat ini.
Q5: Bagaimana cara memanggil model-model ini di platform APIYI?
Setelah mendaftar di APIYI apiyi.com dan mendapatkan kunci API, Anda cukup menggunakan format yang kompatibel dengan OpenAI. Atur base_url ke https://api.apiyi.com/v1 dan model ke ID model yang sesuai (misalnya grok-4.20-beta). Lihat contoh kode di atas. Harga keempat model sama dengan situs resmi, dan diskon diberikan melalui aktivitas isi ulang.
Ringkasan: Strategi Penggunaan Optimal untuk 4 Model
Seri Grok 4.20 Beta menawarkan pilihan model yang presisi untuk berbagai skenario. Strategi intinya adalah mencocokkan model berdasarkan kompleksitas tugas:
| Kompleksitas | Model Rekomendasi | Biaya |
|---|---|---|
| 🟢 Sederhana/Frekuensi Tinggi | non-reasoning |
Terendah |
| 🟡 Umum Sehari-hari | grok-4.20-beta |
Sedang |
| 🟠 Analisis Mendalam | reasoning |
Lebih Tinggi |
| 🔴 Kepercayaan Tertinggi | multi-agent |
Tertinggi |
Penetapan harga $2/$6 menjadikan Grok 4.20 sebagai model unggulan dengan biaya output terendah di pasar saat ini. Didukung oleh jendela konteks 2 juta token dan sistem multi-agen, model ini sangat kompetitif untuk skenario riset, analisis, dan throughput tinggi.
Kami merekomendasikan akses satu pintu ke seluruh seri model Grok 4.20 Beta melalui APIYI apiyi.com. Penetapan harga sama dengan situs resmi, dengan diskon yang tersedia melalui promosi isi ulang. Satu kunci API dapat digunakan untuk memanggil lebih dari 200 model, termasuk Grok, Claude, GPT, dan lainnya.
Referensi
-
Dokumentasi Resmi xAI: Penjelasan model dan harga Grok
- Tautan:
docs.x.ai/developers/models
- Tautan:
-
Artificial Analysis: Benchmark evaluasi Grok 4.20 Beta
- Tautan:
artificialanalysis.ai/models/grok-4-20
- Tautan:
-
Dokumentasi Multi-Agen xAI: Penjelasan mendalam kemampuan Multi-Agent
- Tautan:
docs.x.ai/developers/model-capabilities/text/multi-agent
- Tautan:
-
OpenRouter: Halaman model Grok 4.20 Beta
- Tautan:
openrouter.ai
- Tautan:
Penulis: Tim APIYI | Menghadirkan model AI terbaru dengan cepat. Kunjungi APIYI apiyi.com untuk mencoba seluruh seri model Grok 4.20 Beta.