title: "Mengapa Token Output Gemini 3.1 Pro Preview Jauh Melebihi Teks yang Terlihat? Penjelasan Lengkap: Mekanisme Rantai Pikir Thinking Tokens, Aturan Penagihan, dan Tips Hemat dengan thinking_level"
date: 2024-12-25
tags: [Gemini, Google, Model Bahasa Besar, API, Biaya]
category: Panduan Teknis
description: "Panduan lengkap tentang mekanisme Thinking Tokens di Gemini 3.1 Pro Preview, cara kerja, penagihan, dan cara menghemat hingga 80% biaya output dengan parameter thinking_level."
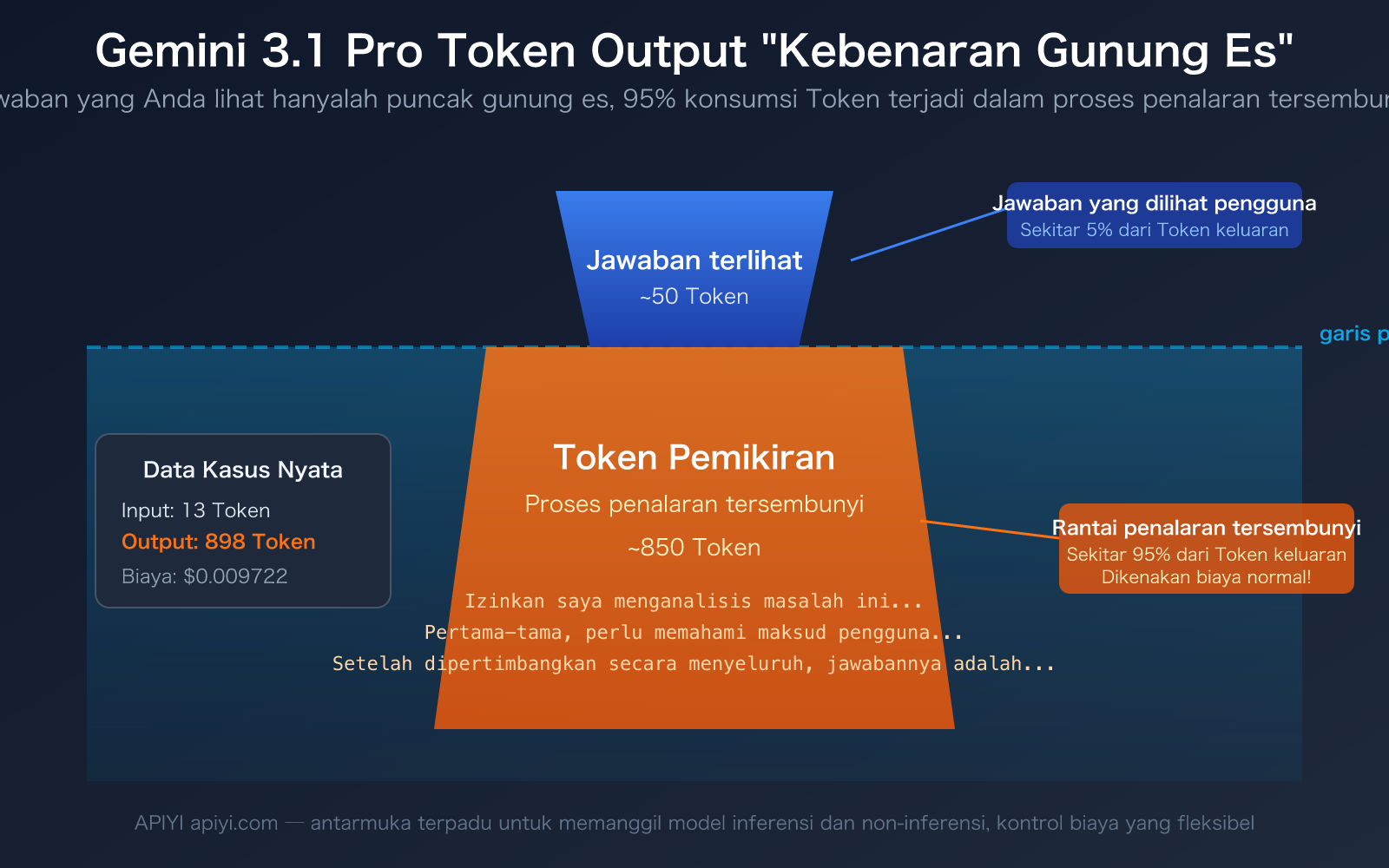
"Pertanyaan saya cuma satu kalimat, balasan model juga cuma belasan kata, tapi kenapa output Token-nya hampir 900? Uangnya habis ke mana?" — Ini adalah kebingungan nyata banyak developer saat pertama kali menggunakan Gemini 3.1 Pro Preview. Data di tangkapan layar juga jelas menunjukkan fenomena ini: Input 13 Token, Output malah mencapai 898 Token.
Jawabannya adalah Thinking Tokens (Token Pikir). Gemini 3.1 Pro adalah model penalaran (reasoning model). Sebelum memberi jawaban, ia akan melakukan proses berpikir dan penalaran yang panjang di "kepalanya". Konten penalaran ini secara default tidak ditampilkan kepada Anda, tetapi akan dihitung sebagai Output Token dan ditagih secara normal.
Nilai Inti: Setelah membaca artikel ini, Anda akan sepenuhnya memahami mekanisme Thinking Tokens pada model penalaran, belajar menggunakan parameter thinking_level untuk mengontrol kedalaman penalaran, dan menghemat 50-80% biaya Output Token dengan tetap menjaga kualitas.
Poin Inti Thinking Tokens Gemini 3.1 Pro
Perbedaan terbesar antara model penalaran (reasoning model) dan model percakapan biasa terletak pada komposisi Output Token yang sama sekali berbeda. Berikut adalah konsep inti yang perlu Anda pahami:
| Poin | Penjelasan | Dampak Nyata |
|---|---|---|
| Output Token = Berpikir + Jawaban | Output Token Gemini 3.1 Pro mencakup Thinking Tokens (rantai penalaran) dan jawaban aktual | Teks yang terlihat sedikit, tetapi total Token tinggi |
| Thinking Tokens Ditagih Normal | Proses penalaran meskipun tidak terlihat, tetap ditagih berdasarkan harga Output Token ($12/juta Token) | Satu pertanyaan sederhana bisa menghabiskan biaya 5-10 kali lipat model biasa |
thinking_level Dapat Disesuaikan |
Mendukung kontrol kedalaman penalaran tiga tingkat: LOW/MEDIUM/HIGH | Tingkat LOW dapat menghemat 80%+ Output Token |
| Model Non-Penalaran Tidak Punya Masalah Ini | Model seperti GPT-4o, Claude Sonnet 4.6 (dengan Extended Thinking dimatikan) bersifat what you see is what you get | Untuk tugas sederhana, gunakan model non-penalaran lebih hemat |
Studi Kasus Konsumsi Nyata Thinking Tokens Gemini 3.1 Pro
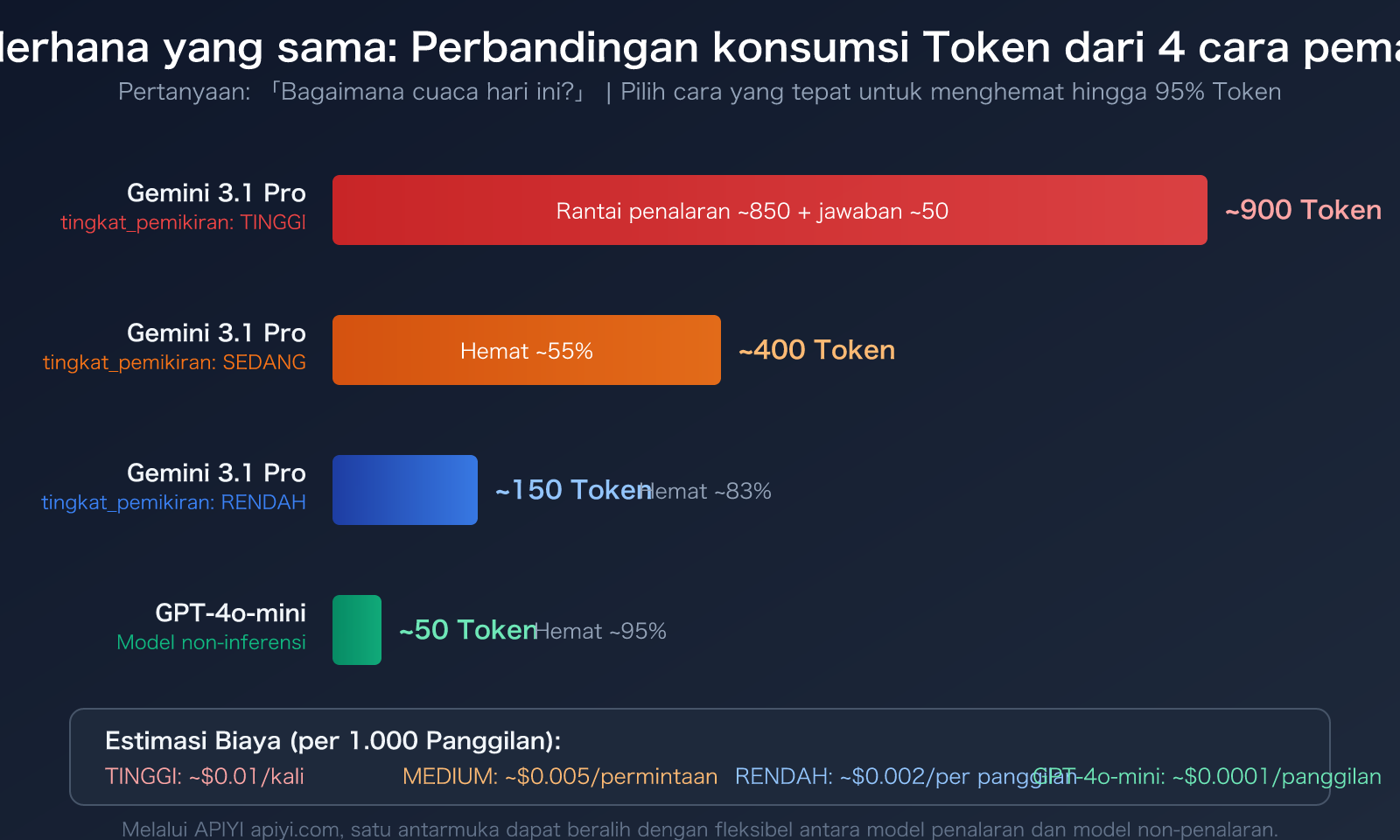
Kembali ke contoh di tangkapan layar. Pengguna mengajukan pertanyaan sederhana, model membalas sekitar belasan kata, tetapi Output Token menunjukkan 891-898. Komposisi Token tersebut kira-kira sebagai berikut:
- Jawaban yang Terlihat: Sekitar 30-50 Token (belasan kata yang Anda lihat)
- Thinking Tokens: Sekitar 840-860 Token (proses penalaran internal model)
Artinya, lebih dari 95% Output Token tidak Anda lihat, mereka dikonsumsi dalam rantai penalaran model. Ini seperti Anda bertanya kepada guru matematika "1+1 berapa?", guru hanya berkata "sama dengan 2", tetapi di pikirannya sebenarnya berpikir: "Ini adalah masalah aritmatika dasar, perlu menggunakan operasi penjumlahan…" — lalu Anda membayar untuk seluruh proses berpikir guru tersebut.
Mekanisme ini bukan bug, melainkan karakteristik desain model penalaran. Alasan Gemini 3.1 Pro berkinerja lebih baik pada masalah kompleks (skor MATH 95.1%, ARC-AGI-2 mencapai 77.1%) adalah karena ia melakukan penalaran mendalam sebelum menjawab.
Mekanisme Kerja Thinking Tokens pada Model Penalaran Gemini 3.1 Pro
Perbedaan Mendasar antara Model Penalaran dan Model Biasa
Model biasa (seperti GPT-4o) langsung menghasilkan jawaban setelah menerima pertanyaan Anda. Token keluaran yang dikonsumsi sama persis dengan jumlah kata yang Anda lihat. Ini adalah prinsip "apa yang Anda lihat adalah apa yang Anda dapatkan".
Model penalaran (seperti Gemini 3.1 Pro Preview) akan menghasilkan rantai penalaran internal (Chain of Thought) terlebih dahulu setelah menerima pertanyaan, kemudian menghasilkan jawaban akhir berdasarkan hasil penalaran tersebut. Anda hanya melihat jawaban akhirnya, tetapi yang ditagih adalah total Token dari "rantai penalaran + jawaban".
| Tipe Model | Model Perwakilan | Komposisi Token Keluaran | Biaya Pertanyaan Sederhana | Keunggulan Pertanyaan Kompleks |
|---|---|---|---|---|
| Model Biasa | GPT-4o, Claude Sonnet 4.6 | 100% jawaban yang terlihat | Rendah (apa yang dilihat adalah yang didapat) | Kemampuan penalaran biasa |
| Model Penalaran | Gemini 3.1 Pro, GPT-5.4 Thinking | Rantai penalaran + jawaban yang terlihat | Tinggi (5-10 kali lipat atau lebih) | Kemampuan penalaran kompleks yang kuat |
| Model yang Dapat Dialihkan | Claude Sonnet 4.6 (Extended Thinking) | Opsional untuk mengaktifkan penalaran | Fleksibel untuk dialihkan | Aktifkan penalaran sesuai kebutuhan |
3 Detail Kunci Thinking Tokens Gemini 3.1 Pro
Detail 1: Cara Penagihan Thinking Tokens. Menurut dokumentasi resmi Google, Thinking Tokens ditagih sesuai harga standar Token keluaran. Harga Token keluaran Gemini 3.1 Pro adalah $12/juta Token. Ketika model menggunakan 4000 Token untuk penalaran dan 500 Token untuk menjawab, Anda perlu membayar untuk 4500 Token keluaran — bukan 500 Token.
Detail 2: Cara Membedakannya dalam Respons API. Dalam respons API Gemini, bidang usage_metadata akan mengembalikan thoughts_token_count (jumlah Token penalaran) dan candidates_token_count (total Token keluaran) secara terpisah. Namun perlu diperhatikan: candidatesTokenCount pada API Gemini sudah mencakup Thinking Tokens, sedangkan candidatesTokenCount pada Vertex AI tidak mencakupnya.
Detail 3: Konten rantai penalaran tidak terlihat secara default. Anda bisa mendapatkan ringkasan proses penalaran (bukan rantai penalaran lengkap) dengan mengatur includeThoughts: true, atau mengaktifkan fungsi tampilan rantai penalaran di alat seperti Cherry Studio untuk melihat proses pemikiran model.
🎯 Saran Penghematan: Jika Anda hanya melakukan percakapan sederhana atau tugas terjemahan yang tidak memerlukan penalaran mendalam, disarankan untuk beralih ke model biasa (seperti GPT-4o-mini atau Claude Sonnet 4.6). APIYI apiyi.com mendukung pengalihan model hanya dengan mengubah satu parameter
model, tanpa perlu mengubah kode lainnya.
Optimisasi Thinking Tokens Gemini 3.1 Pro: 3 Strategi Penghematan
Strategi 1: Mengontrol Kedalaman Penalaran dengan Parameter thinking_level
Gemini 3.1 Pro menyediakan parameter thinking_level yang mendukung tiga tingkat: LOW, MEDIUM, HIGH. Perbedaan konsumsi Token antar tingkat sangat besar:
| thinking_level | Kedalaman Penalaran | Konsumsi Token | Skenario Penggunaan | Perbandingan dengan HIGH |
|---|---|---|---|---|
| LOW | Penalaran dangkal | Terendah | Terjemahan, klasifikasi, tanya jawab sederhana | Hemat sekitar 80%+ |
| MEDIUM | Penalaran seimbang | Sedang | Pemrograman sehari-hari, pembuatan dokumen, analisis umum | Hemat sekitar 50% |
| HIGH | Penalaran mendalam | Tertinggi | Derivasi matematika, masalah ilmiah, logika kompleks | Garis dasar |
Berikut adalah contoh kode untuk mengatur thinking_level:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Untuk tugas sederhana gunakan LOW, mengurangi Thinking Tokens secara signifikan
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"总输出 Token: {response.usage.completion_tokens}")
Lihat kode perutean cerdas lengkap (memilih kedalaman penalaran otomatis berdasarkan kompleksitas masalah)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Panggilan cerdas ke Gemini 3.1 Pro, memilih kedalaman penalaran otomatis berdasarkan kompleksitas tugas
Args:
prompt: Input pengguna
complexity: "low" / "medium" / "high" / "auto"
api_key: Kunci API
Returns:
Kamus yang berisi jawaban dan statistik penggunaan Token
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Penilaian otomatis kompleksitas
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# Contoh penggunaan
# Tugas sederhana → pilih LOW otomatis
result = smart_gemini_call("翻译:今天天气真好")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
# Tugas kompleks → pilih HIGH otomatis
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
Saran: Saat memanggil Gemini 3.1 Pro melalui APIYI apiyi.com, parameter
thinking_leveldidukung. Disarankan untuk mengatur ke MEDIUM untuk penggunaan sehari-hari, dan gunakan HIGH hanya pada skenario penalaran kompleks seperti matematika/ilmiah.
Strategi 2: Gunakan Model Non-Penalaran Langsung untuk Tugas Sederhana
Tidak semua skenario memerlukan model penalaran. Untuk tugas seperti terjemahan, konversi format, tanya jawab sederhana, menggunakan model non-penalaran dapat menghemat biaya Token 5-10 kali lipat:
- GPT-4o-mini: Rasio harga-kinerja sangat tinggi, pilihan utama untuk percakapan sehari-hari
- Claude Sonnet 4.6 (dengan Extended Thinking dimatikan): Kualitas keluaran tinggi, Token sesuai yang dilihat
- Gemini 3.1 Flash: Model ringan dari Google, cepat dan biaya rendah
Strategi 3: Atur Batas max_tokens untuk Membatasi Keluaran
Menambahkan parameter max_tokens pada panggilan API dapat mencegah model penalaran "terlalu banyak berpikir". Namun perlu diperhatikan: max_tokens membatasi total keluaran (penalaran + jawaban), jika diatur terlalu rendah dapat menyebabkan jawaban terpotong. Disarankan untuk mengaturnya 2-3 kali lipat dari panjang jawaban yang diharapkan.
🎯 Saran Komprehensif: Di platform APIYI apiyi.com, Anda dapat mengakses model penalaran dan non-penalaran secara bersamaan dengan antarmuka yang seragam, dan beralih secara dinamis berdasarkan jenis tugas. Satu Kunci API dapat memanggil seluruh seri model Gemini, Claude, dan GPT.
Pertanyaan Umum
Q1: Mengapa proses penalaran Gemini 3.1 Pro Thinking Tokens tidak ditampilkan secara default?
Ini adalah pilihan desain produk dari Google. Rantai penalaran lengkap dapat berisi ribuan Token untuk derivasi perantara, dan menampilkannya secara langsung akan sangat memengaruhi pengalaman pengguna. Anda bisa mendapatkan ringkasan penalaran dengan mengatur includeThoughts: true, atau mengaktifkan fitur tampilan rantai penalaran di klien seperti Cherry Studio untuk melihat proses pemikirannya.
Q2: Bagaimana cara melihat berapa banyak Thinking Tokens yang dikonsumsi dalam respons API?
Lihat bidang thoughts_token_count di usage_metadata yang dikembalikan oleh Gemini API. Jika Anda memanggil melalui APIYI apiyi.com, Anda dapat melihat rincian dekomposisi Token (input/output/penalaran) untuk setiap panggilan di halaman statistik penggunaan platform, yang memudahkan pemantauan dan pengoptimalan biaya.
Q3: Selain Gemini 3.1 Pro, model lain apa yang memiliki mekanisme Thinking Tokens serupa?
Model penalaran utama memiliki mekanisme serupa:
- GPT-5.4 Thinking: Model penalaran OpenAI, Token penalaran juga dihitung sebagai bagian dari Token output untuk penagihan
- Claude Sonnet 4.6 Extended Thinking: Mode penalaran Anthropic, dapat diaktifkan secara opsional
- DeepSeek-R1: Model penalaran sumber terbuka, rantai penalaran sepenuhnya terlihat
Perbedaan kuncinya adalah: beberapa model (seperti Claude) memungkinkan mode penalaran dihidupkan/mati secara fleksibel, sementara beberapa model (seperti Gemini 3.1 Pro) mengaktifkan penalaran secara default. Melalui APIYI apiyi.com, Anda dapat menggunakan antarmuka terpadu untuk menguji dan membandingkan konsumsi Token aktual dari model-model ini.
Kesimpulan
Poin inti dari Gemini 3.1 Pro Thinking Tokens:
- Token output mencakup rantai penalaran tersembunyi: Yang Anda lihat hanyalah bagian jawaban, lebih dari 95% konsumsi Token output ada di Thinking Tokens yang tidak terlihat.
- Thinking Tokens dikenakan biaya normal: Dikenakan biaya sesuai harga standar Token output, biaya untuk pertanyaan sederhana bisa 5-10 kali lipat dari model non-penalaran.
- Gunakan parameter
thinking_leveluntuk menghemat biaya: Level LOW dapat menghemat 80%+ Token, MEDIUM cocok untuk penggunaan sehari-hari, gunakan HIGH hanya untuk tugas kompleks. - Pilih model non-penalaran untuk tugas sederhana: Untuk skenario seperti terjemahan, klasifikasi, tanya jawab sederhana, lebih hemat biaya untuk langsung menggunakan GPT-4o-mini atau Claude Sonnet 4.6.
Dengan memahami mekanisme Thinking Tokens, Anda dapat mengalokasikan anggaran penalaran secara wajar. Direkomendasikan untuk mengelola pemanggilan multi-model melalui antarmuka terpadu APIYI apiyi.com, dan memilih model penalaran atau non-penalaran secara dinamis berdasarkan kompleksitas tugas, untuk mencapai keseimbangan kualitas/biaya yang optimal.
📚 Referensi
-
Dokumentasi Google Cloud – Mode Thinking: Dokumentasi teknis resmi untuk model reasoning Gemini
- Tautan:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - Penjelasan: Sumber otoritatif untuk aturan penagihan Thinking Tokens dan konfigurasi parameter
thinking_level
- Tautan:
-
Dokumentasi Pengembang Google AI – Penghitungan Token: Penjelasan resmi tentang penghitungan token dan field
usage_metadata- Tautan:
ai.google.dev/gemini-api/docs/tokens - Penjelasan: Cara membedakan
thoughts_token_countdancandidates_token_countdalam respons API
- Tautan:
-
Google DeepMind – Kartu Model Gemini 3.1 Pro: Detail kemampuan model dan pengujian patokan reasoning
- Tautan:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Penjelasan: Sumber resmi untuk data performa seperti MATH 95.1%, ARC-AGI-2 77.1%
- Tautan:
-
OpenRouter – Praktik Terbaik Token Reasoning: Praktik terbaik komunitas untuk manajemen token model reasoning
- Tautan:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - Penjelasan: Perbandingan aturan penagihan reasoning token lintas model dan saran optimasi
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Selamat berdiskusi di kolom komentar tentang pengalaman optimasi token model reasoning. Untuk tutorial pemanggilan model lainnya, kunjungi pusat dokumentasi APIYI di docs.apiyi.com