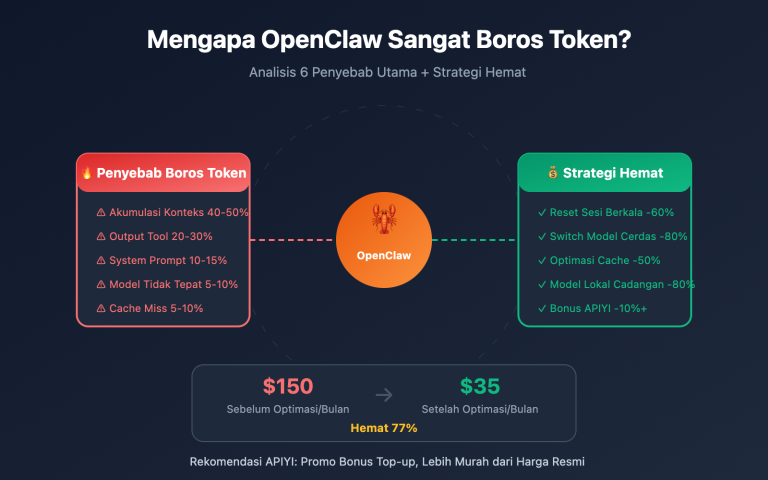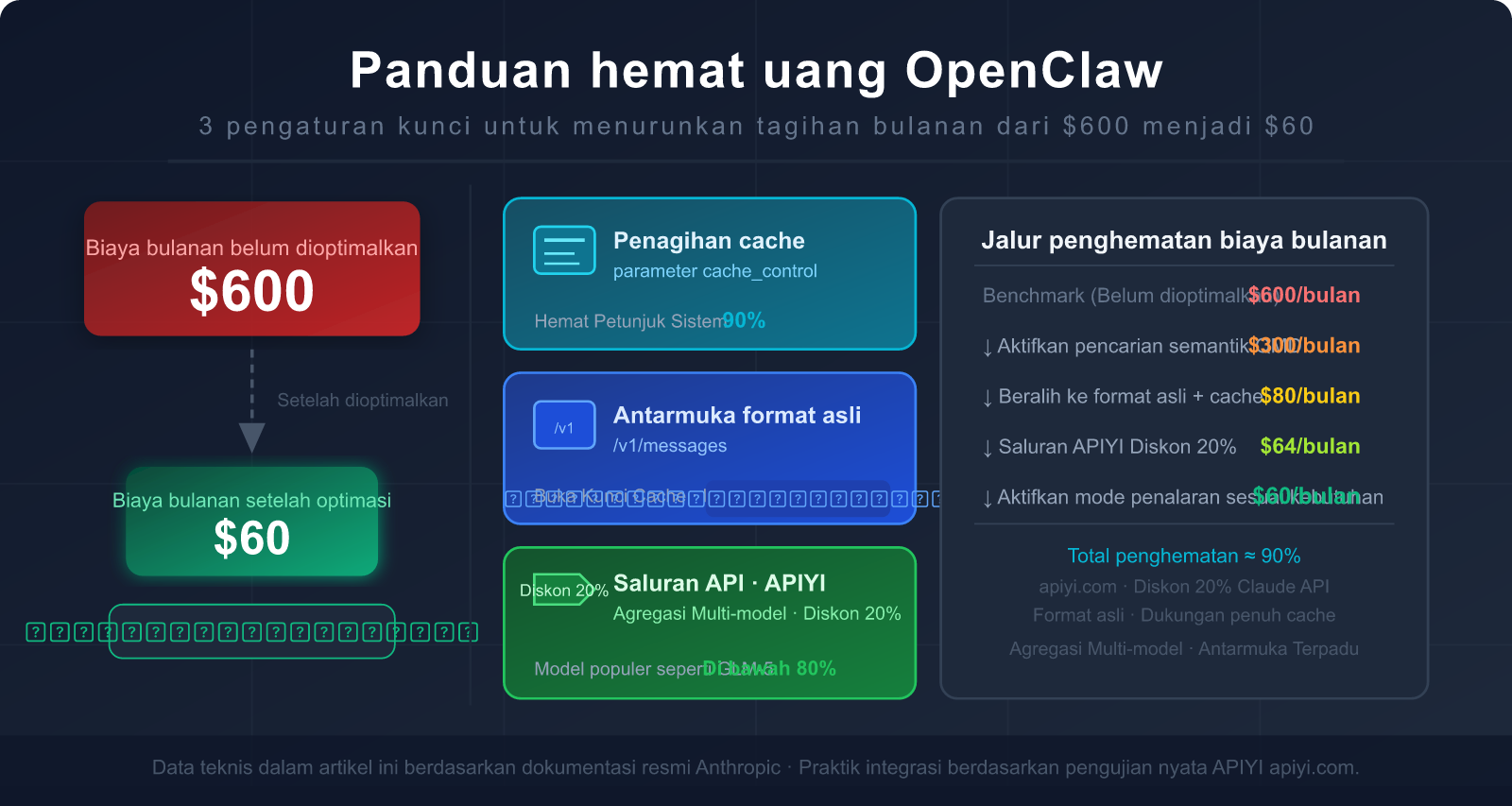
Anda menggunakan OpenClaw untuk alur kerja harian, tapi setiap kali melihat tagihan API di akhir bulan, rasanya bikin meringis—$300, $500, bahkan lebih dari $600?
Ini bukan salah Anda, tapi memang begitulah desain arsitektur OpenClaw. Instans OpenClaw yang belum dioptimalkan bakal mengirimkan banyak "konten tidak perlu" ke model AI setiap kali ada tugas, yang ujung-ujungnya cuma buang-buang Token secara percuma.
Kabar baiknya: ada beberapa pengaturan kunci yang bisa memangkas tagihan sampai 80-90%, dan kebanyakan orang nggak tahu trik paling ampuh: pakai antarmuka format asli Claude, jangan pakai mode kompatibilitas OpenAI.
Artikel ini bakal mengupas tuntas kenapa Token di OpenClaw bisa boros banget, dan saya akan pandu Anda langkah demi langkah buat pakai antarmuka yang benar, atur caching, sampai pilih saluran API yang pas supaya tagihan bulanan Anda turun dari $600 jadi cuma $60.
I. Kenapa OpenClaw Begitu Boros Token: 3 Alasan Utama
Alasan 1: Setiap Permintaan Mengirim Ulang Seluruh Riwayat Percakapan
Ini adalah alasan yang paling sering diabaikan, namun memiliki dampak terbesar.
OpenClaw dirancang dengan prinsip "konteks lengkap": setiap kali mengirim permintaan ke model AI, ia akan menyertakan semua pesan riwayat sejak awal percakapan. Hal ini dilakukan agar model dapat "mengingat" apa yang telah dilakukan dan dikatakan sebelumnya.
Sebagai contoh:
Putaran 1: Pengguna mengirim 50 token, AI membalas 200 token → Total pengiriman 250 token
Putaran 2: Pengguna mengirim 50 token, AI membalas 200 token → Total pengiriman 500 token (termasuk putaran 1)
Putaran 3: Pengguna mengirim 50 token, AI membalas 200 token → Total pengiriman 750 token (termasuk putaran 1+2)
...
Putaran 10: Sebenarnya hanya ada tambahan 250 token baru, tapi jumlah yang dikirim sudah mencapai 2.500 token
Dalam alur kerja OpenClaw yang menangani tugas-tugas kompleks, "efek bola salju" ini akan membuat konsumsi Token tumbuh secara eksponensial. Riwayat konteks biasanya memakan 40-50% dari total konsumsi Token.
Alasan 2: Petunjuk Sistem (System Prompt) Dikirim Ulang Setiap Saat
Petunjuk sistem (System Prompt) di OpenClaw mendefinisikan identitas Agent, batasan kemampuan, daftar alat yang tersedia, aturan perilaku, dan konten inti lainnya, yang biasanya berukuran antara 5.000-10.000 token.
Masalah utamanya: System Prompt yang besar ini akan dikirim secara utuh dalam setiap pemanggilan API.
Misalkan Anda menggunakan OpenClaw untuk memproses 50 tugas setiap hari, dengan System Prompt sebesar 8.000 token setiap kali:
Konsumsi System Prompt harian = 50 × 8.000 = 400.000 token
Konsumsi bulanan ≈ 12.000.000 token (Hanya untuk System Prompt saja!)
Berdasarkan harga input Claude Sonnet 4.6 ($3/juta token), biaya untuk System Prompt saja bisa mencapai $36 per bulan. Ini belum termasuk konten percakapan dan output-nya.
Alasan 3: Mode Penalaran Membuat Token Melonjak 10-50 Kali Lipat
Saat OpenClaw menghadapi tugas yang rumit, ia akan mengaktifkan "Chain of Thought" atau "Mode Penalaran" (Thinking/Reasoning). Mode ini membuat AI "berpikir matang-matang sebelum berbicara", sehingga kualitas output-nya lebih tinggi—namun harganya adalah lonjakan konsumsi Token yang drastis.
Karakteristik konsumsi Token penalaran:
- Proses berpikir menghasilkan banyak Token perantara (biasanya tidak terlihat, tapi tetap ditagih)
- Proses penalaran untuk tugas kompleks bisa menghasilkan 10.000-50.000 token
- Jika tidak dikendalikan, beberapa tugas kompleks saja bisa menghabiskan anggaran harian Anda
| Skenario Konsumsi Token | Mode Biasa | Mode Penalaran | Perbandingan |
|---|---|---|---|
| Tugas tanya jawab sederhana | ~500 token | ~2.000 token | 4 kali lipat |
| Alur pemrosesan email | ~2.000 token | ~15.000 token | 7,5 kali lipat |
| Tugas analisis kode | ~5.000 token | ~80.000 token | 16 kali lipat |
| Riset multi-langkah yang kompleks | ~10.000 token | ~200.000 token | 20 kali lipat+ |
🎯 Diagnosis Cepat: Jika tagihan OpenClaw Anda sangat tinggi, periksa penggunaan mode penalaran di log Token Anda.
Mematikan mode penalaran untuk tugas yang tidak mendesak adalah salah satu cara paling efektif untuk menghemat biaya.
Beralih ke model yang lebih sesuai juga dapat menekan biaya secara signifikan—melalui APIYI apiyi.com, Anda dapat dengan cepat berganti dan menguji berbagai model.
Proporsi Konsumsi dari Tiga Alasan Utama
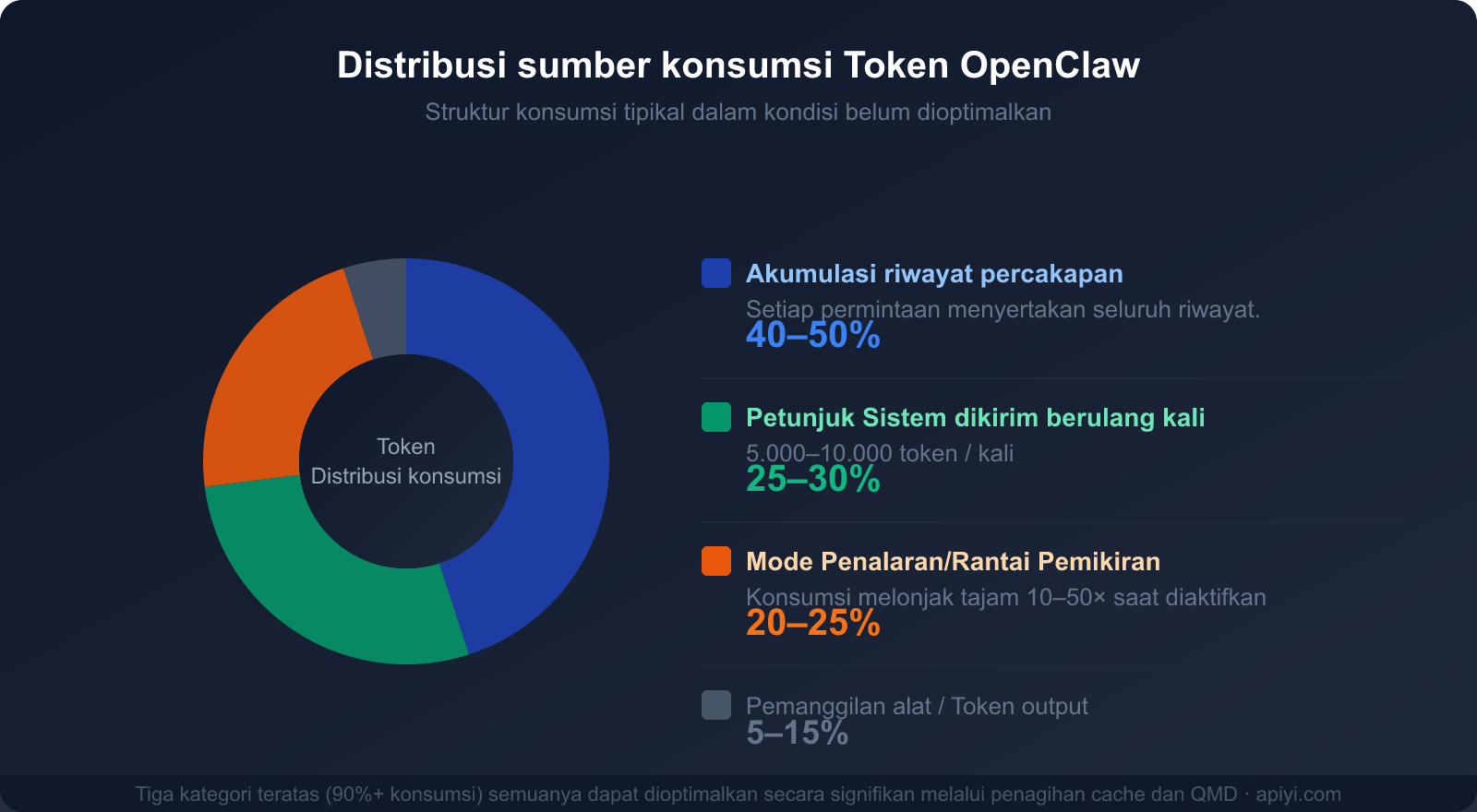
Memahami tiga sumber utama konsumsi ini adalah langkah awal untuk menyusun strategi penghematan:
| Sumber Konsumsi | Proporsi Total | Bisa Dioptimalkan? | Cara Optimasi Utama |
|---|---|---|---|
| Riwayat Percakapan (Akumulasi Konteks) | 40-50% | ✅ Sangat Bisa | Caching, pembersihan berkala, QMD |
| Pengiriman Ulang System Prompt | 25-30% | ✅ Sangat Bisa | Penagihan cache (hemat 90%) |
| Mode Penalaran/Chain of Thought | 20-25% | ✅ Sesuai Kebutuhan | Aktifkan hanya untuk tugas kompleks |
| Pemanggilan Alat dan Output | 5-15% | ⚡ Terbatas | Persingkat deskripsi alat |
II. Senjata Penghemat Uang yang Paling Sering Terlewatkan: Penagihan Cache Claude
Apa itu Penagihan Cache Claude
Prompt Caching (Penyimpanan Petunjuk dalam Cache) Claude adalah fitur asli yang diluncurkan oleh Anthropic pada akhir tahun 2024. Logika intinya adalah: Menyimpan konten yang sering dikirim berulang kali di sisi server, sehingga pemanggilan berikutnya langsung membaca dari cache alih-alih memproses ulang.
Harga pembacaan cache: Hanya 10% dari harga input normal (Hemat 90%)
Ini berarti: Setiap kali mengirim System Prompt sebesar 8.000 token, setelah cache diaktifkan, saat terjadi cache hit berulang, Anda hanya perlu membayar seharga 800 token. Bagi pengguna OpenClaw yang mengirim puluhan permintaan setiap hari, optimasi ini saja bisa menghemat ratusan dolar per bulan.
Sistem Harga Lengkap Penagihan Cache
| Jenis Cache | Kelipatan Biaya | Durasi Valid | Skenario Penggunaan |
|---|---|---|---|
| Token Input Normal | 1× Harga Dasar | Tidak dicache | Diproses ulang setiap kali |
| Penulisan Cache (Pertama kali) | 1.25× | 5 Menit TTL | Membangun cache |
| Penulisan Cache (Jangka Panjang) | 2× | 1 Jam TTL | Skenario pemanggilan frekuensi tinggi |
| Pembacaan Cache (Hit) | 0.1× (Hemat 90%) | Selama masa berlaku | Permintaan berulang |
Contoh Perhitungan Penghematan Nyata:
Skenario: System Prompt OpenClaw 8.000 token
50 kali pemanggilan per hari, dengan 48 kali cache hit
Tanpa cache: 50 × 8.000 = 400.000 token
Biaya = 400.000 × $3/1M = $1.20/hari = $36/bulan
Dengan cache: 2 kali penulisan: 2 × 8.000 × 1.25 = 20.000 token = $0.06
48 kali hit: 48 × 8.000 × 0.1 = 38.400 token = $0.12
Biaya harian ≈ $0.18 → Bulanan ≈ $5.40
Hemat: $36 - $5.40 = $30.60/bulan (Hanya dari satu item System Prompt)
Rasio penghematan: 85%
Cara Mengaktifkan Penagihan Cache di OpenClaw
Pengaktifan penagihan cache memiliki satu prasyarat utama: Anda harus menggunakan antarmuka format asli Anthropic (/v1/messages), bukan mode kompatibilitas OpenAI (/v1/chat/completions).
Cara Konfigurasi yang Benar (Contoh SDK Python):
import anthropic
# Harus menggunakan SDK asli Anthropic, tidak bisa menggunakan SDK OpenAI
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI mendukung format asli Anthropic
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "Anda adalah asisten AI profesional...[8000 token system prompt]",
"cache_control": {"type": "ephemeral"} # ← Kunci: Menandai konten ini sebagai kandidat cache
}
],
messages=[
{"role": "user", "content": "Bantu saya merapikan email hari ini"}
]
)
Batasan Teknis Cache:
- Maksimal mengatur 4 titik henti cache (penanda
cache_control) - Seri Sonnet: Konten minimal yang dapat dicache ≥ 1.024 token
- Opus / Haiku 4.5: Konten minimal yang dapat dicache ≥ 4.096 token
- Model yang mendukung cache: Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3, dll.
🎯 Tips Penting: APIYI apiyi.com mendukung penuh pemanggilan format asli Anthropic,
termasuk parametercache_control. Menggunakan format asli untuk memanggil model Claude di APIYI,
Anda bisa menikmati penagihan cache (hemat hingga 90%) + diskon 20% dari APIYI, efek tumpukannya sangat signifikan.
III. Wawasan Penting: Mengapa Mode Kompatibilitas OpenAI Tidak Bisa Menghemat Token
Ini adalah bagian di mana kebanyakan pengguna OpenClaw paling sering terjebak.
Perbedaan Mendasar Antara Dua Format Antarmuka
Banyak alat AI pihak ketiga dan layanan proksi menyediakan mode kompatibilitas OpenAI demi kenyamanan pengguna—yaitu menggunakan format antarmuka /v1/chat/completions milik OpenAI untuk memanggil model non-OpenAI seperti Claude.
Sekilas, ini memudahkan pengguna karena "satu set kode bisa memanggil semua model". Namun, ada satu kelemahan fatal:
Dalam format antarmuka /v1/chat/completions, tidak ada tempat untuk parameter cache_control—karena ini adalah fitur asli eksklusif milik Anthropic.
Saat Anda memanggil Claude melalui format kompatibilitas OpenAI:
- Permintaan Anda dikonversi ke format OpenAI
- Layanan proksi/agen kemudian mengubahnya kembali ke format asli Anthropic
- Namun, informasi
cache_controlsudah hilang di langkah pertama - Server Claude menerima permintaan tanpa penanda cache, sehingga setiap kali dihitung sebagai token penuh
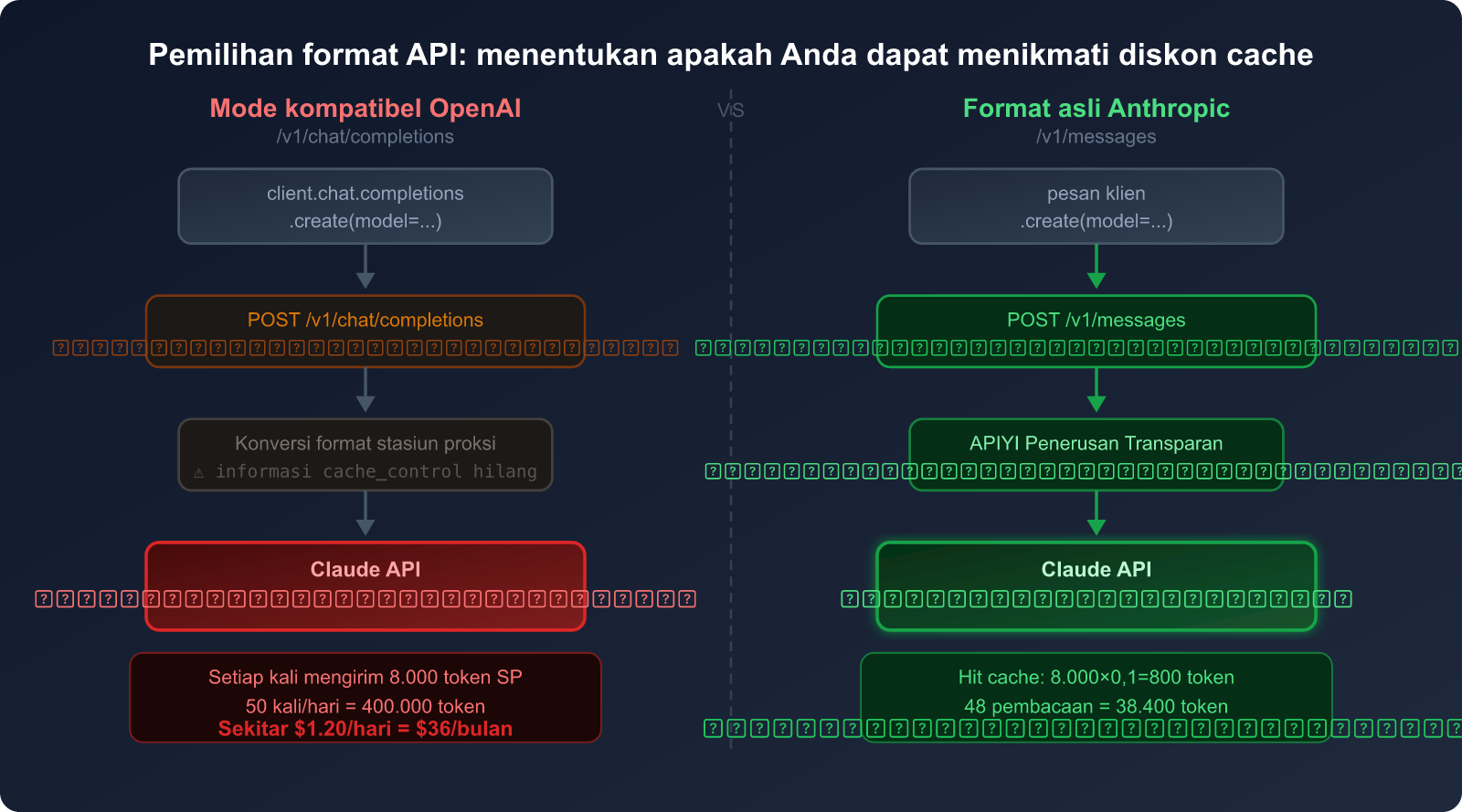
Perbandingan Mode Kompatibilitas OpenAI vs Format Asli Anthropic
| Dimensi Perbandingan | Mode Kompatibilitas OpenAI | Format Asli Anthropic |
|---|---|---|
| Jalur Antarmuka | /v1/chat/completions |
/v1/messages |
| Dukungan Cache Claude | ❌ Tidak mendukung | ✅ Mendukung penuh |
Parameter cache_control |
❌ Tidak ada field ini | ✅ Mendukung 4 titik henti |
| Penagihan System Prompt | 💸 Harga penuh (1× harga) | 💰 Pembacaan cache (0.1× harga) |
| Kompleksitas Kode | Rendah (kode umum) | Sedang (perlu SDK Anthropic) |
| Efek Penghematan (Skenario Frekuensi Tinggi) | 0% | Hingga 90% |
Masalah Tambahan pada Penyebaran API Non-Pabrikan Asli
Selain masalah format antarmuka, ada situasi lain yang sering membingungkan: Model dengan "nama yang sama" yang disebarkan oleh penyedia cloud tidak sama dengan pabrikan asli.
Ambil contoh GLM-5 (Zhipu AI):
- API Asli dari situs z.ai: Mendukung fitur penagihan cache yang dikembangkan sendiri oleh Zhipu.
- GLM-5 yang disebarkan di Alibaba Cloud / Tencent Cloud, dll.: Menggunakan API Gateway penyedia cloud, tidak memiliki fitur penagihan cache asli.
Ini bukan masalah GLM-5, melainkan masalah umum pada penyebaran non-pabrikan asli: Saat menghosting model, penyedia cloud biasanya hanya mengekspos API percakapan standar dan tidak meneruskan fitur privat dari pabrikan asli model tersebut (seperti penagihan cache, dll.).
Analogi: Seperti membeli barang melalui agen, Anda tidak bisa menikmati layanan purna jual khusus dari pabrikan resmi.
Dampak Nyata:
Skenario: 50 kali pemanggilan per hari, System Prompt 6.000 token
API Asli (Mendukung Cache):
Penulisan: 2 kali × 6.000 × 1.25 = 15.000 token
Pembacaan: 48 kali × 6.000 × 0.1 = 28.800 token
Konsumsi setara ≈ 43.800 token/hari
API Non-Asli (Tanpa Cache):
Harga Penuh: 50 kali × 6.000 = 300.000 token/hari
Selisih: Konsumsi tanpa cache adalah 6,85 kali lipat dari yang menggunakan cache
IV. Perbandingan API Original: Cara Memilih Skema Akses Terbaik untuk OpenClaw
Perbandingan Empat Skema Akses
| Skema Akses | Harga (Relatif terhadap Harga Asli) | Dukungan Cache | Dukungan Multi-model | Skenario Penggunaan |
|---|---|---|---|---|
| API Resmi Anthropic | 100% (Harga Asli) | ✅ Lengkap | ❌ Hanya Claude | Anggaran cukup, pengguna khusus Claude |
| APIYI (Format Native Anthropic) | 80% (Diskon 20%) | ✅ Lengkap | ✅ Multi-model | Rekomendasi: Hemat biaya + peralihan fleksibel |
| Layanan Proksi Umum (Kompatibel OpenAI) | Bervariasi 85-95% | ❌ Tidak mendukung | ✅ Multi-model | Saat tidak menggunakan cache Claude |
| Deployment Non-Original dari Penyedia Cloud | Bervariasi 90-110% | ❌ Tidak mendukung | ❌ Model tunggal | Skenario persyaratan kepatuhan perusahaan |
Logika Penghematan Ganda APIYI
Keunggulan APIYI pada model Claude terletak pada: mendukung format native Anthropic sekaligus harga diskon 20%.
Kombinasi kedua poin ini berarti:
Pengguna Biasa (Harga Asli + Kompatibel OpenAI, Tanpa Cache):
Konsumsi Token System Prompt per Bulan: 12.000.000 token
Biaya = 12.000.000 × $3/1M = $36
Pengguna APIYI (Diskon 20% + Format Native + Cache):
Token yang Ditagih Sebenarnya ≈ 1.440.000 token (Setelah Cache)
Biaya = 1.440.000 × $3×0.8/1M = $3.46
Total Penghematan = ($36 - $3.46) / $36 ≈ 90%
🎯 Saran Pemilihan: Jika Anda menggunakan OpenClaw dan model utamanya adalah Claude, sangat disarankan untuk mengakses melalui APIYI apiyi.com menggunakan format native Anthropic. Harga dasar diskon 20% + penghematan cache 90%, kombinasi keduanya dapat menurunkan tagihan sebesar 85-90%. Selain itu, APIYI juga mendukung berbagai model seperti GLM-5, GPT, dll., memudahkan Anda untuk beralih dan membandingkan hasilnya kapan saja.
V. Panduan Lengkap Hemat Biaya OpenClaw: 5 Langkah yang Bisa Segera Dilakukan
Langkah 1: Beralih ke Interface Format Native Anthropic
Ini adalah langkah terpenting, yang secara langsung menentukan apakah Anda bisa menikmati penagihan berbasis cache.
Metode Konfigurasi OpenClaw:
Dalam konfigurasi model OpenClaw (config.json), cari field models.providers, tambahkan APIYI sebagai penyedia dengan format berikut. Kuncinya adalah mengatur field api menjadi "anthropic-messages", agar dapat menggunakan format native Anthropic dan mendukung penagihan cache:
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-isi-token-di-sini",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
Penjelasan Poin Konfigurasi:
"api": "anthropic-messages"← Paling krusial, menentukan penggunaan format native/v1/messages, bukan format kompatibel/v1/chat/completions"baseUrl": "https://api.apiyi.com"← Base URL APIYI (tidak perlu menambah/v1, OpenClaw akan menggabungkannya secara otomatis)"anthropic-version": "2023-06-01"← Header versi API Anthropic, tanpa header ini permintaan akan gagalcontextWindow: 200000← Claude Sonnet 4.6 mendukung jendela konteks 200K
Verifikasi Apakah Cache Berfungsi:
Periksa field cache_read_input_tokens dan cache_creation_input_tokens di header respons API atau log. Jika ada nilainya, berarti cache sudah aktif:
# Verifikasi respons cache
response = client.messages.create(...)
# Periksa field usage
print(response.usage)
# Contoh output:
# Usage(
# input_tokens=150, # Token baru pada sesi ini
# cache_creation_input_tokens=8000, # Penulisan cache pertama kali (ditagih 1.25x)
# cache_read_input_tokens=0, # Hit cache berikutnya (ditagih 0.1x)
# output_tokens=300
# )
🎯 Cara Akses: Setelah mendaftar dan mendapatkan kunci API melalui APIYI apiyi.com, cukup atur
base_urlkehttps://api.apiyi.com/v1untuk menggunakan format native Anthropic. Tidak perlu mengubah kode lain, penagihan cache Claude akan segera aktif.
Langkah 2: Letakkan Titik Henti Cache (Cache Breakpoint) Secara Bijak
Posisi titik henti cache (cache_control) sangatlah penting. Anda harus mencadangkan konten yang "besar dan statis":
# Praktik terbaik: Cache petunjuk sistem + definisi alat
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # Petunjuk sistem utama 5.000-10.000 token
"cache_control": {"type": "ephemeral"} # Titik henti 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # Daftar alat (biasanya juga besar)
"cache_control": {"type": "ephemeral"} # Titik henti 2
}
],
messages=conversation_history, # Riwayat percakapan (tidak dicache, berubah setiap saat)
...
)
Poin Strategi Cache:
- ✅ Cocok untuk dicache: Petunjuk sistem, definisi alat, dokumen statis besar, konten dokumen hasil pencarian RAG
- ❌ Tidak cocok untuk dicache: Pesan pengguna saat ini, konten yang dibuat secara dinamis, data yang berubah setiap saat
- ⚠️ Perhatikan urutan: Cache menggunakan pencocokan awalan (prefix matching), konten statis harus diletakkan di bagian awal urutan pesan.
Langkah 3: Aktifkan QMD untuk Mengurangi Panjang Konteks
QMD (Quick Memory Database) adalah fitur pencarian semantik lokal dari OpenClaw. Cara kerjanya:
Cara Tradisional:
Mengirim [seluruh riwayat percakapan] setiap saat → Mengonsumsi banyak Token
Cara QMD:
Membangun database vektor lokal → Mencari fragmen riwayat yang paling relevan
Hanya mengirim [3-5 riwayat paling relevan] setiap saat → Menghemat 60-97% Token
Efek Penghematan Nyata QMD: Berdasarkan dokumentasi resmi OpenClaw, QMD dapat menghasilkan penghematan Token sebesar 60-97%, tergantung pada volume riwayat percakapan dan jenis tugas.
Cara Mengaktifkan (Antarmuka Pengaturan OpenClaw):
- Settings → Memory → Enable QMD
- Atur jalur penyimpanan QMD (lokal, data tidak diunggah)
- Atur ambang batas relevansi (direkomendasikan di atas 0.7 untuk menghindari riwayat yang tidak relevan)
Langkah 4: Pilih Model yang Sesuai Berdasarkan Jenis Tugas
Tidak semua tugas memerlukan model terkuat. Pembagian model yang tepat adalah kunci pengendalian biaya:
Strategi Tingkatan Tugas:
Tugas Sederhana (pengingat jadwal, konversi format, pencarian sederhana)
→ Gunakan Claude Haiku 4.5 (paling cepat, paling murah)
→ Sekitar 1/5 dari harga Sonnet
Tugas Menengah (pemrosesan email, pengaturan file, review kode)
→ Gunakan Claude Sonnet 4.6 (seimbang)
→ Tingkat keberhasilan 86.9% (Peringkat pertama di PinchBench)
Tugas Kompleks (analisis arsitektur, riset multi-langkah, penalaran kompleks)
→ Gunakan Claude Opus 4.6 (penalaran terkuat)
→ Hanya aktifkan mode penalaran saat benar-benar dibutuhkan
Langkah 5: Bersihkan Konteks Secara Berkala
Riwayat percakapan adalah salah satu sumber konsumsi Token terbesar (40-50%). Disarankan:
- Atur jumlah putaran konteks maksimum: Ringkas dan bersihkan riwayat secara otomatis setelah lebih dari 15-20 putaran
- Bersihkan secara manual setelah tugas selesai: Reset konteks sebelum memulai tugas baru
- Aktifkan fitur kompresi sesi OpenClaw: Gunakan AI untuk mengompres riwayat panjang menjadi ringkasan
Estimasi Efek Komprehensif dari Optimasi Lima Langkah
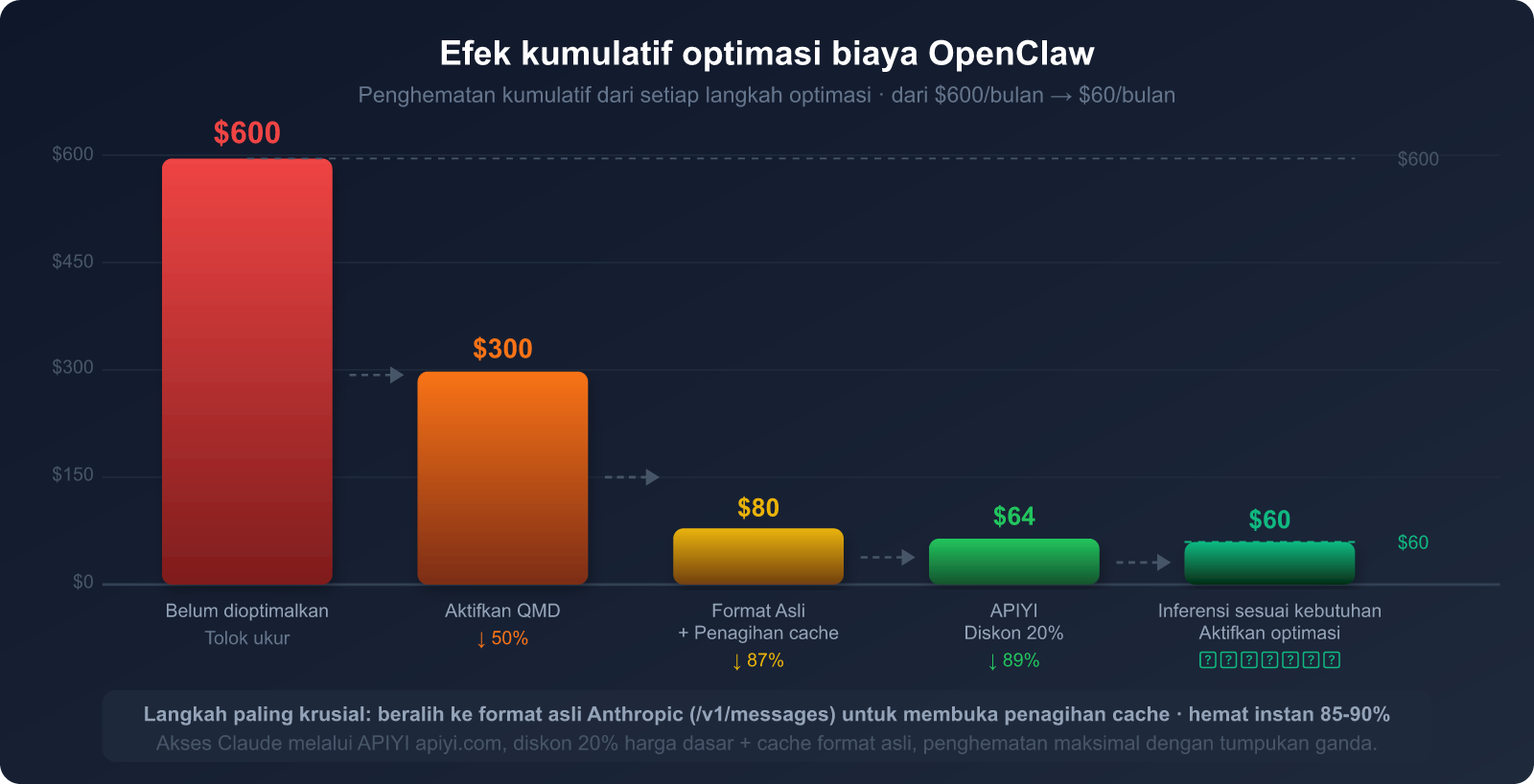
Berdasarkan pengguna OpenClaw tingkat menengah (biaya bulanan tanpa optimasi sekitar $300-600), berikut adalah efek yang diharapkan setelah menjalankan lima langkah di atas:
| Langkah Optimasi | Target Sumber Konsumsi | Estimasi Persentase Penghematan | Tingkat Kesulitan Eksekusi |
|---|---|---|---|
| 1. Beralih ke Format Native Anthropic | Penagihan berulang System Prompt | Hemat 85-90% (bagian SP) | ⭐ Rendah (ubah base_url) |
| 2. Atur titik henti cache | Definisi alat + dokumen statis | Hemat 80-90% (bagian alat) | ⭐⭐ Rendah-Menengah |
| 3. Aktifkan QMD | Token riwayat percakapan | Hemat 60-97% (bagian riwayat) | ⭐⭐ Rendah-Menengah |
| 4. Pembagian model berdasarkan tugas | Total biaya Token | Hemat 30-70% (selisih harga model) | ⭐⭐⭐ Menengah |
| 5. Pembersihan konteks berkala | Efek bola salju akumulasi riwayat | Hemat 20-40% (keuntungan jangka panjang) | ⭐ Rendah |
🎯 Saran Prioritas Eksekusi: Langkah 1 (beralih ke format native) dan Langkah 3 (mengaktifkan QMD) adalah dua langkah dengan keuntungan tertinggi dan pengoperasian termudah. Disarankan untuk memprioritaskan kedua langkah ini, yang biasanya dapat langsung menurunkan tagihan sebesar 60-80%. Melalui akses Claude di APIYI apiyi.com, Langkah 1 hanya memerlukan perubahan satu baris konfigurasi pada
base_urldan dapat diselesaikan dalam waktu kurang dari 5 menit.
VI. Konfigurasi Praktis: Contoh Lengkap OpenClaw + APIYI + Claude Cache
Berikut adalah contoh konfigurasi OpenClaw yang lengkap dan telah dioptimalkan, cocok untuk langsung digunakan oleh sebagian besar pengguna:
import anthropic
# Menggunakan format asli Anthropic melalui APIYI
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # Kunci APIYI (dapatkan dengan mendaftar di apiyi.com)
base_url="https://api.apiyi.com/v1"
)
# Mendefinisikan petunjuk sistem (konten besar, cocok untuk cache)
SYSTEM_PROMPT = """
Anda adalah asisten AI profesional yang berjalan di platform OpenClaw.
Tugas Anda meliputi: mengelola jadwal, memproses email, merapikan file, membantu pengembangan kode...
[Biasanya berisi instruksi detail sebanyak 5.000-10.000 token]
"""
# Mendefinisikan daftar alat (juga konten tetap yang besar, cocok untuk cache)
TOOL_DEFINITIONS = """
Alat yang tersedia: calendar_api, email_api, file_system, code_runner...
[Penjelasan detail alat, biasanya 2.000-5.000 token]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""Pemanggilan API OpenClaw yang dioptimalkan dengan mengaktifkan cache"""
response = client.messages.create(
model="claude-sonnet-4-6", # Peringkat pertama di PinchBench
max_tokens=4096,
# Petunjuk sistem: tandai breakpoint cache
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # Breakpoint cache 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # Breakpoint cache 2
}
],
# Riwayat percakapan + pesan baru
messages=[
*conversation_history, # Pesan riwayat (tidak di-cache karena berubah setiap saat)
{"role": "user", "content": user_message}
]
)
# Cetak penggunaan Token (untuk memantau efek optimasi)
usage = response.usage
print(f"Token Input: {usage.input_tokens}")
print(f"Penulisan Cache: {usage.cache_creation_input_tokens}")
print(f"Pembacaan Cache: {usage.cache_read_input_tokens}")
print(f"Token Output: {usage.output_tokens}")
return response.content[0].text
🎯 Mulai Cepat: Ganti
api_keypada kode di atas dengan kunci yang Anda dapatkan setelah mendaftar di APIYI (apiyi.com). Tanpa perlu modifikasi lain, Anda bisa langsung menikmati kombinasi format asli Anthropic + penagihan cache + diskon 20% dari APIYI.
Tanya Jawab Umum (FAQ)
Q: Apakah APIYI benar-benar mendukung format asli Anthropic (/v1/messages)?
Ya, APIYI (apiyi.com) mendukung dua format antarmuka sekaligus:
- Format asli Anthropic:
/v1/messages(mendukung penagihan cache) - Format kompatibel OpenAI:
/v1/chat/completions(memudahkan kode umum)
Untuk model Claude, sangat disarankan menggunakan format asli Anthropic agar bisa menikmati fitur penagihan cache. Cukup gunakan SDK Python anthropic dan arahkan base_url ke APIYI.
🎯 Kunjungi APIYI (apiyi.com) untuk mendaftarkan akun. Di konsol, Anda dapat melihat contoh kode akses untuk kedua format tersebut.
Q: Apakah TTL cache 5 menit cukup? Bagaimana cara menentukan jika butuh TTL 1 jam?
Ini tergantung pada frekuensi pemanggilan Anda:
- Jika pemanggilan OpenClaw Anda berjarak < 5 menit (seperti memproses alur tugas terus-menerus), gunakan TTL default 5 menit.
- Jika jeda pemanggilan antara 5 menit hingga 1 jam (misalnya berhenti sejenak setelah memproses satu batch tugas), pertimbangkan TTL 1 jam (biayanya 2x harga penulisan, tetapi tingkat keberhasilan cache lebih tinggi).
- Jika jeda pemanggilan > 1 jam, penggunaan cache kurang berarti, lebih baik tulis ulang setiap kali.
Q: Apa saran hemat biaya saat menggunakan model domestik seperti GLM-5?
Fitur cache GLM-5 memerlukan pemanggilan API asli melalui situs resmi Zhipu AI (z.ai). Deployment pihak ketiga seperti Alibaba Cloud tidak dapat menggunakannya.
APIYI juga mendukung model domestik seperti GLM-5 dengan harga diskon 20% atau lebih, memudahkan Anda membandingkan efek berbagai model dengan satu antarmuka selama tahap pengujian. Setelah menentukan model yang cocok untuk skenario Anda, barulah putuskan apakah akan lanjut menggunakan APIYI atau langsung ke produsen aslinya.
Q: Saya sudah menggunakan layanan proksi API pihak ketiga, seberapa sulit migrasi ke platform yang mendukung format asli?
Biaya migrasinya sangat rendah. Satu-satunya yang perlu diubah adalah dua parameter dalam kode:
# Sebelum migrasi (Format kompatibel OpenAI)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="alamat proksi lama")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# Setelah migrasi (Format asli Anthropic, mendukung cache)
import anthropic
client = anthropic.Anthropic(
api_key="sk-KunciAPIYIBaru", # ← Ganti dengan kunci dari APIYI
base_url="https://api.apiyi.com/v1" # ← Ganti dengan alamat APIYI
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# Kemudian tambahkan cache_control pada parameter system untuk mengaktifkan cache
Beban kerja utamanya adalah mengubah chat.completions.create menjadi messages.create. Ada sedikit perbedaan format pesan (struktur role/content tetap sama, tetapi system berubah dari string menjadi daftar objek). Biasanya migrasi dapat diselesaikan dalam waktu setengah hari.
Q: Bagaimana cara memverifikasi apakah instans OpenClaw saya sudah berhasil mengaktifkan cache?
Cara paling langsung: Perhatikan objek usage dalam respons API saat melakukan dua pemanggilan berturut-turut:
- Pemanggilan pertama:
cache_creation_input_tokensmemiliki nilai (penulisan cache). - Pemanggilan kedua:
cache_read_input_tokensmemiliki nilai (cache hit).
Jika cache_read_input_tokens pada pemanggilan kedua sama dengan jumlah token System Prompt, berarti cache berfungsi sepenuhnya.
Q: Apakah mode penalaran/berpikir (Extended Thinking) harus dimatikan?
Tidak harus dimatikan sepenuhnya, tetapi harus digunakan sesuai kebutuhan. Strategi yang disarankan:
- Tugas sederhana (klasifikasi email, pengaturan jadwal): Matikan mode penalaran.
- Tugas menengah (review kode, ringkasan informasi): Matikan secara default, aktifkan saat menemui kesulitan.
- Tugas kompleks (keputusan arsitektur, riset multi-langkah): Aktifkan, tetapi atur batas
budget_tokensyang masuk akal.
Di API Claude, Anda dapat membatasi konsumsi token maksimum mode penalaran melalui thinking: {"type": "enabled", "budget_tokens": 5000}.
Ringkasan: Logika Inti Penghematan Biaya OpenClaw
Mari kita rangkum semua metode penghematan dalam satu diagram:
Mari kita tinjau kembali poin-poin inti dari artikel ini:
Tiga Akar Penyebab Konsumsi Tinggi:
- Riwayat percakapan dikirim ulang setiap kali (memakan 40-50% konsumsi)
- System Prompt dikirim ulang setiap kali (memakan 25-30%)
- Penggunaan mode penalaran tanpa kendali (memakan 20-25%)
Metode Penghematan Paling Efisien:
- 🥇 Penagihan Cache Claude: Hemat hingga 90% (harus menggunakan format asli Anthropic)
- 🥈 Pencarian Semantik Lokal QMD: Menghemat 60-97% Token jendela konteks riwayat
- 🥉 Klasifikasi Model Berdasarkan Tugas: Gunakan Haiku untuk tugas ringan, Sonnet/Opus untuk tugas berat
- Saluran API Pilih APIYI: Harga dasar diskon 20% + dukungan format asli
Satu Wawasan Paling Penting:
Format kompatibel OpenAI (/v1/chat/completions) tidak dapat meneruskan
cache_control,
sehingga meskipun melalui layanan proksi API untuk pemanggilan model Claude, Anda tidak akan menikmati diskon cache.
Untuk menghemat uang, Anda harus menggunakan format asli Anthropic (/v1/messages).
🎯 Tindak Sekarang: Kunjungi APIYI apiyi.com untuk mendaftar dan dapatkan kunci API yang mendukung format asli Anthropic.
Ganti base_url menjadihttps://api.apiyi.com/v1, selesaikan peralihan dalam 3 menit,
dan Anda akan melihat penurunan tagihan Token yang signifikan pada hari yang sama. Model Claude diskon 20%, antarmuka terpadu untuk berbagai model,
adalah pilihan optimal bagi pengguna OpenClaw untuk memangkas biaya dan meningkatkan efisiensi.
Semua data harga API dalam artikel ini berdasarkan informasi publik Maret 2026, harga aktual mengacu pada pengumuman resmi masing-masing platform.
Penulis: Tim APIYI | Untuk tips penggunaan OpenClaw lainnya, silakan kunjungi Pusat Bantuan APIYI apiyi.com