Catatan Penulis: Analisis mendalam terhadap 3 model AI pemecah matematika terkuat tahun 2026, mencakup data benchmark otoritatif seperti AIME dan MATH, untuk membantu Anda menemukan model penalaran matematika yang paling tepat.
Memilih model AI yang tepat untuk menyelesaikan soal matematika selalu menjadi salah satu pertimbangan utama bagi pengembang dan pelajar. Artikel ini membandingkan tiga model penalaran matematika terbaru yang dirilis tahun 2026: Gemini 3.1 Pro Preview, Claude Sonnet 4.6, dan GPT-5.4. Kami akan memberikan rekomendasi jelas dari berbagai dimensi seperti skor benchmark, kemampuan penalaran, harga API, dan skenario penggunaan.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami model AI mana yang harus dipilih dalam berbagai skenario pemecahan soal matematika, serta cara memanggilnya dengan biaya yang paling optimal.
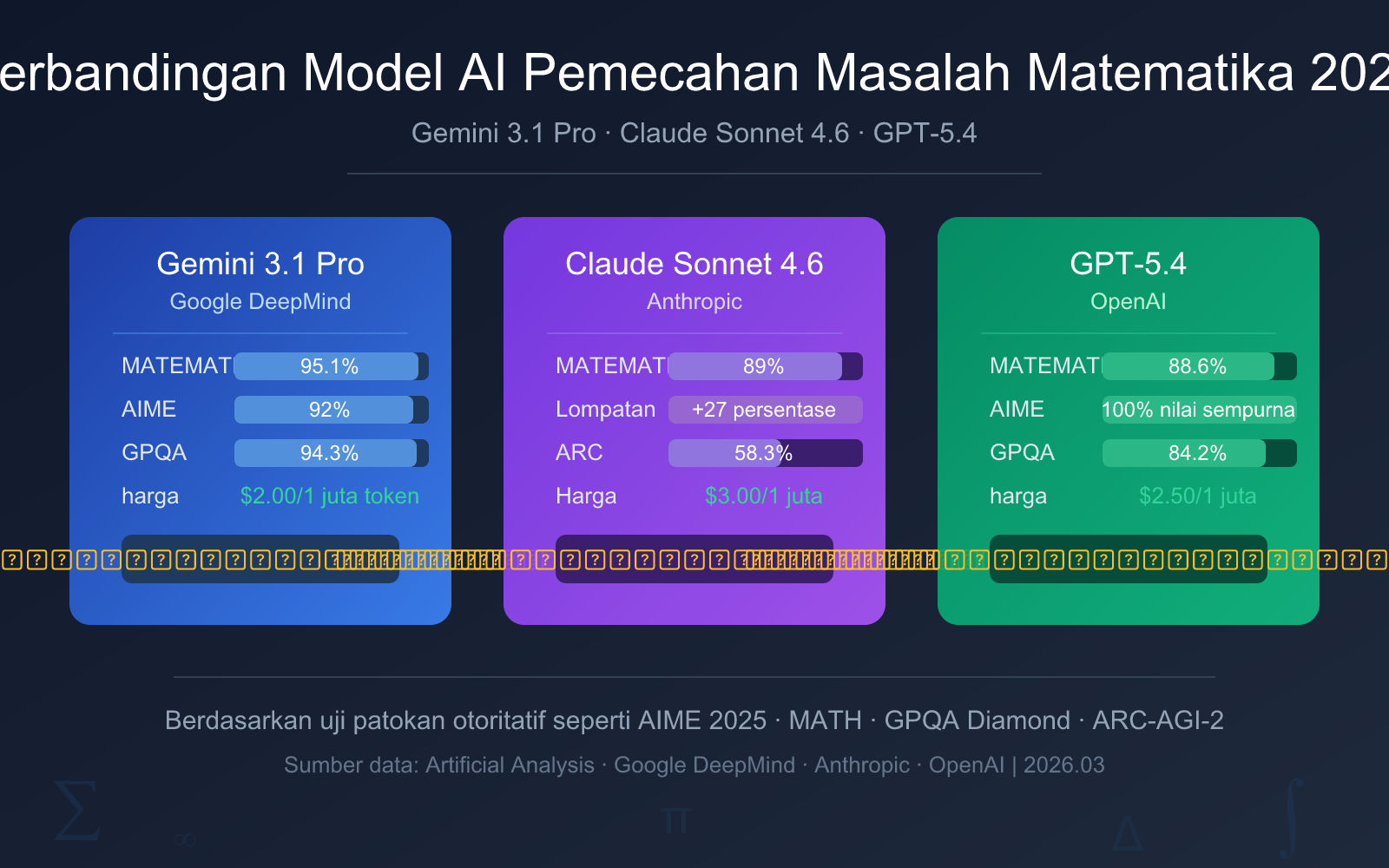
Perbandingan Cepat Model AI Pemecah Masalah Matematika Inti
Sebelum masuk ke analisis detail, mari lihat tabel perbandingan data inti ini untuk memahami perbedaan kunci antara tiga model AI pemecah masalah matematika dengan cepat.
| Dimensi Perbandingan | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Tanggal Rilis | 19 Februari 2026 | Awal 2026 | 6 Maret 2026 |
| AIME 2025 | 92% (tanpa alat) | — | 100% (skor sempurna) |
| Benchmark MATH | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| Harga Input | $2.00/1M token | $3.00/1M token | $2.50/1M token |
| Harga Output | $12.00/1M token | $15.00/1M token | $15.00/1M token |
| Rekomendasi Umum | ⭐ Rekomendasi Utama | ⭐ Pilihan untuk Belajar | ⭐ Pilihan untuk Kompetisi |
Urutan Rekomendasi Model AI Pemecah Masalah Matematika
Dari sudut pandang nilai untuk uang secara keseluruhan, kami memberikan saran urutan berikut:
- Pilihan Utama Gemini 3.1 Pro Preview: Benchmark MATH 95.1% memimpin, harga termurah, kemampuan matematika menyeluruh terkuat.
- Pilihan Kedua Claude Sonnet 4.6: Kemampuan matematika melonjak 27 poin persentase, proses pemecahan masalah jelas dan mudah dipahami, cocok untuk skenario pembelajaran.
- Tingkat Kompetisi GPT-5.4: AIME 2025 skor sempurna 100%, cocok untuk kompetisi matematika tingkat tinggi dan penelitian profesional.
🎯 Saran Teknis: Ketiga model dapat dipanggil secara terpadu melalui platform APIYI apiyi.com. Disarankan untuk menguji satu per satu pada masalah matematika nyata untuk memilih model yang paling sesuai dengan kebutuhan Anda.
Analisis Detail Kemampuan Pemecahan Masalah Matematika Gemini 3.1 Pro Preview
Gemini 3.1 Pro Preview adalah model unggulan terbaru yang dirilis oleh Google DeepMind pada 19 Februari 2026. Ini adalah pertama kalinya Google menggunakan peningkatan versi ".1" (sebelumnya pembaruan menengah selalu menggunakan ".5"), menandakan bahwa ini adalah peningkatan yang difokuskan pada kemampuan penalaran cerdas.
Skor Benchmark Matematika Gemini 3.1 Pro
| Benchmark | Skor | Keterangan |
|---|---|---|
| MATH | 95.1% | Tes matematika komprehensif yang mencakup aljabar, geometri, kalkulus, dan bidang lainnya. |
| AIME 2025 (tanpa alat) | 92% | American Invitational Mathematics Examination, tingkat kesulitan kompetisi sekolah menengah. |
| AIME 2025 (eksekusi kode) | 100% | Generasi sebelumnya Gemini 3 Pro mendapat skor sempurna setelah mengaktifkan eksekusi kode. |
| GPQA Diamond | 94.3% | Tanya jawab sains tingkat pascasarjana, memimpin semua model setara. |
| ARC-AGI-2 | 77.1% | Kemampuan penalaran abstrak, dua kali lipat dari generasi sebelumnya 3 Pro. |
| MathArena Apex | Memimpin signifikan | Peningkatan lebih dari 20 kali lipat dibandingkan generasi sebelumnya. |
Gemini 3.1 Pro meraih peringkat pertama dalam 12 dari 18 benchmark utama yang diumumkan secara resmi oleh Google. Dalam penalaran matematika, kinerja benchmark MATH 95.1% sangat menonjol, yang berarti model ini memiliki kemampuan pemecahan masalah yang sangat kuat di berbagai sub-bidang matematika seperti aljabar, geometri, probabilitas, dan kalkulus.
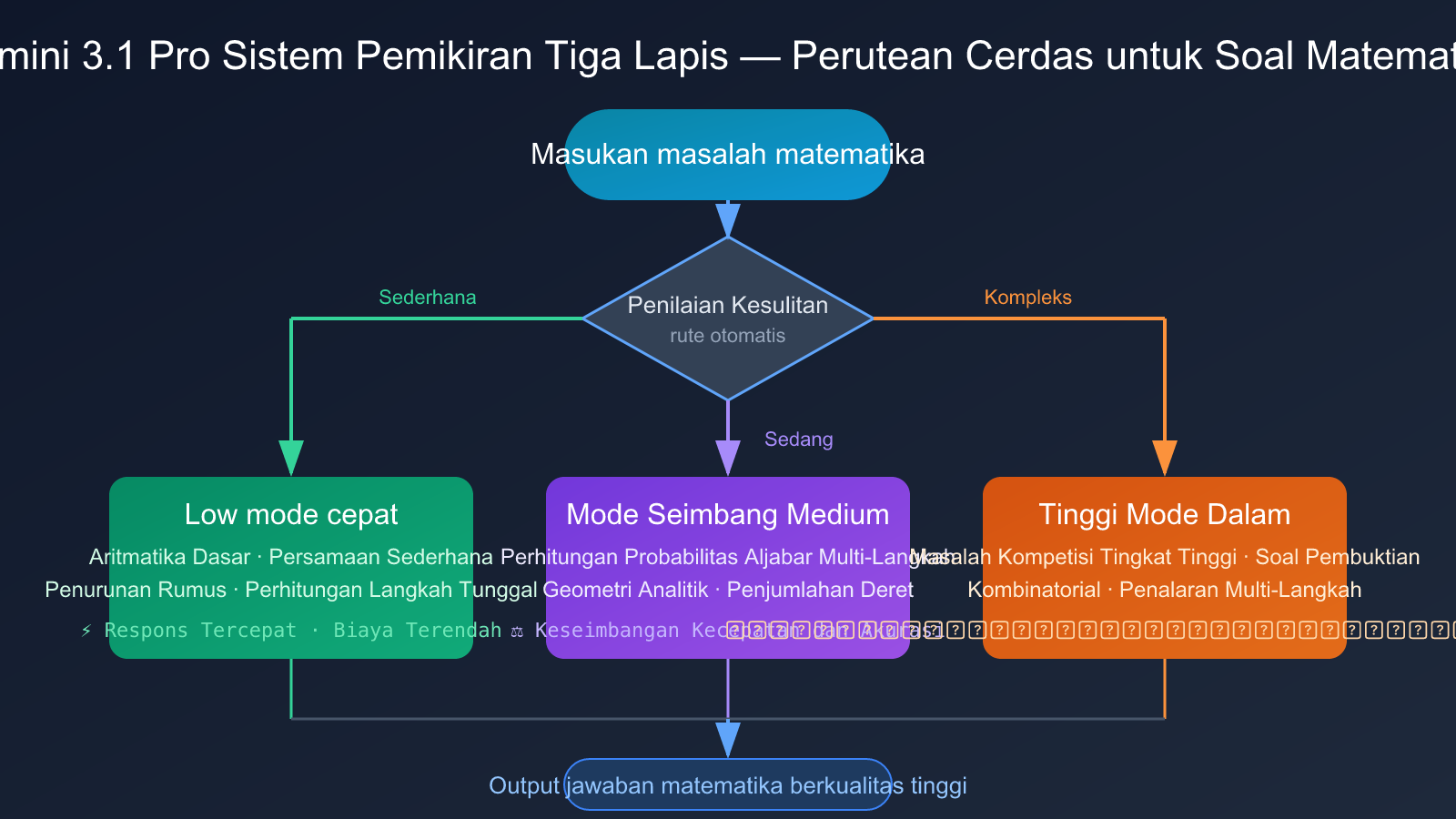
Sistem Tiga Lapis Berpikir Gemini 3.1 Pro
Gemini 3.1 Pro memperkenalkan inovasi arsitektur kunci — sistem tiga lapis berpikir:
- Low (Mode Cepat): Menangani perhitungan matematika sederhana dan deduksi rumus, kecepatan respons tercepat.
- Medium (Mode Seimbang): Lapisan menengah baru, menangani masalah matematika dengan tingkat kesulitan sedang, menyeimbangkan kecepatan dan akurasi.
- High (Mode Mendalam): Menangani masalah penalaran multi-langkah yang kompleks, seperti soal matematika tingkat kompetisi.
Sistem tiga lapis ini memungkinkan pengembang untuk merutekan secara fleksibel berdasarkan tingkat kesulitan masalah matematika, tanpa harus memilih antara "cepat tetapi kasar" dan "lambat tetapi presisi". Keunggulan arsitektur ini sangat jelas untuk skenario yang memproses banyak soal matematika dengan tingkat kesulitan berbeda (misalnya, sistem penilaian adaptif di platform pendidikan).
Pengalaman Nyata Pemecahan Masalah Matematika Gemini 3.1 Pro
Dalam pemecahan masalah matematika nyata, kinerja Gemini 3.1 Pro Preview dapat diringkas sebagai "komprehensif dan stabil":
- Bidang Aljabar: Operasi polinomial, penyelesaian sistem persamaan, pembuktian ketidaksetaraan, hampir tanpa kesalahan, berkat cakupan tinggi MATH 95.1%.
- Bidang Geometri: Rantai penalaran geometri analitik dan geometri ruang lengkap, terutama unggul dalam soal perhitungan terkait sistem koordinat.
- Probabilitas dan Statistik: Logika penalaran untuk probabilitas bersyarat, permutasi dan kombinasi jelas, mampu menangani perhitungan bertahap yang kompleks dengan benar.
- Kalkulus: Penyelesaian integral tentu dan tak tentu akurat, dapat mengenali teknik integrasi umum dan menerapkannya dengan benar.
Pencapaian Gemini 3.1 Pro yang meraih peringkat pertama dalam 12 dari 18 benchmark utama bukanlah kebetulan. Skor Artificial Analysis Intelligence Index-nya adalah 57, setara dengan GPT-5.4 (xhigh) di peringkat pertama, jauh melampaui median 28, yang mencerminkan keunggulan penalaran cerdas yang menyeluruh.
Claude Sonnet 4.6: Kemampuan Pemecahan Masalah Matematika yang Diperjelas
Claude Sonnet 4.6 adalah model menengah terbaru dari Anthropic yang menunjukkan lompatan kualitatif dalam kemampuan penalaran matematika—dari 62% pada pendahulunya, Sonnet 4.5, melonjak menjadi 89%, peningkatan sebesar 27 poin persentase.
Skor Benchmark Matematika Claude Sonnet 4.6
| Benchmark | Sonnet 4.6 | Sonnet 4.5 (Pendahulu) | Peningkatan |
|---|---|---|---|
| Matematika Komprehensif | 89% | 62% | +27 poin persentase |
| ARC-AGI-2 | 58.3% | 13.6% | Peningkatan 4.3x |
| GPQA Diamond | 74.1% | — | Penalaran Sains Tingkat Pascasarjana |
| Kemampuan Pemrograman | 79.6% | — | Mendekati Opus 4.6 (80.8%) |
| Analisis Keuangan | 63.3% | — | Terbaik di kelasnya |
Lonjakan kemampuan matematika dari 62% ke 89% adalah salah satu perubahan paling mencolok pada Sonnet 4.6. Ini berarti model ini telah bertransformasi dari "model yang sesekali melakukan kesalahan dalam soal matematika" menjadi "model yang dapat menangani perhitungan kompleks dengan andal".
Mekanisme Pemikiran Adaptif Claude Sonnet 4.6
Sorotan lain dari Claude Sonnet 4.6 adalah mekanisme Kedalaman Pemikiran Adaptif (Adaptive Thinking):
- Pertanyaan Sederhana: Respons cepat, tidak membuang sumber daya penalaran. Contoh: aritmatika dasar, penyelesaian persamaan sederhana.
- Pertanyaan Menengah: Rantai pemikiran diperpanjang secukupnya. Contoh: operasi aljabar multi-langkah, perhitungan probabilitas.
- Pertanyaan Kompleks: Secara otomatis memicu rantai penalaran mendalam. Contoh: matematika kombinatorial, soal pembuktian, masalah tingkat kompetisi.
Manfaat mekanisme adaptif ini dalam penggunaan praktis adalah: Anda tidak perlu secara manual mengatur kedalaman penalaran. Model akan secara otomatis menilai tingkat kesulitan masalah matematika dan mengalokasikan sumber daya komputasi yang sesuai, mencapai keseimbangan optimal antara latensi dan biaya.
Keunggulan Unik Claude Sonnet 4.6: Proses Penyelesaian
Dalam skenario pemecahan masalah matematika, Claude Sonnet 4.6 memiliki keunggulan unik yang diakui luas—kejelasan proses penyelesaian. Beberapa evaluasi menunjukkan bahwa model Claude memiliki performa terbaik dalam menjelaskan konsep matematika. Selain itu, Learning Mode (Mode Belajar) yang diluncurkan Anthropic dirancang khusus untuk memandu proses penalaran siswa, bukan langsung memberikan jawaban.
Ini membuat Claude Sonnet 4.6 sangat cocok untuk:
- Skenario pendidikan dan bimbingan matematika.
- Pembelajar yang perlu memahami langkah-langkah penyelesaian.
- Peneliti yang ingin memverifikasi alur pemikiran penyelesaian.
💡 Saran Belajar: Jika kebutuhan inti Anda adalah "memahami proses penyelesaian masalah matematika" dan bukan hanya mendapatkan jawaban, Claude Sonnet 4.6 adalah pilihan terbaik. Anda bisa mendapatkan kuota uji coba gratis melalui APIYI apiyi.com untuk merasakan seberapa detail proses penyelesaiannya.
GPT-5.4: Kemampuan Pemecahan Masalah Matematika yang Diperjelas
GPT-5.4 adalah model flagship terbaru dari OpenAI yang dirilis pada 6 Maret 2026. Ini adalah model penalaran OpenAI pertama yang mengintegrasikan kemampuan profesional mutakhir, kemampuan pemrograman (dari GPT-5.3-Codex), operasi komputer asli, dan jendela konteks 1.05M dalam satu model default yang sama.
Skor Benchmark Matematika GPT-5.4
| Benchmark | Skor | Penjelasan |
|---|---|---|
| AIME 2025 | 100% (nilai sempurna) | Tingkat kompetisi matematika SMA, performa sempurna. |
| GSM8K | 99% | Soal cerita matematika SD, hampir sempurna. |
| MATH | 88.6% | Benchmark penalaran matematika komprehensif. |
| GPQA Diamond | 84.2% (standar) / 92.8% (penalaran tinggi) | Penalaran sains tingkat pascasarjana. |
| ARC-AGI-2 | 73.3% (standar) / 83.3% (Pro) | Kemampuan penalaran abstrak. |
| FrontierMath (pendahulu 5.2) | 40.3% | Rekor baru untuk matematika mutakhir tingkat ahli. |
GPT-5.4 mencapai skor menakjubkan 100% sempurna pada AIME 2025, yang berarti ia dapat menyelesaikan dengan sempurna semua soal kompetisi tingkat tinggi dalam American Invitational Mathematics Examination. Bagi pengguna yang perlu menyelesaikan masalah matematika tingkat kompetisi, performa ini sangat meyakinkan.
Perlu diperhatikan, skor GPT-5.4 pada benchmark MATH adalah 88.6%, yang memiliki kesenjangan tertentu dibandingkan Gemini 3.1 Pro (95.1%). Ini menunjukkan bahwa meskipun GPT-5.4 tampil sempurna pada soal kompetisi yang sulit, ia bukan yang terkuat dalam tes komprehensif yang mencakup berbagai bidang matematika.
Opsi Konfigurasi Penalaran GPT-5.4
GPT-5.4 menyediakan berbagai konfigurasi penalaran untuk menyesuaikan dengan masalah matematika yang berbeda:
- GPT-5.4 Edisi Standar: Cocok untuk perhitungan matematika sehari-hari dan masalah dengan tingkat kesulitan sedang.
- GPT-5.4 Thinking: Mengaktifkan penalaran tingkat lanjut, cocok untuk penalaran dan pembuktian multi-langkah yang kompleks.
- GPT-5.4 Pro: Konfigurasi performa tertinggi, ARC-AGI-2 dapat mencapai 83.3%, cocok untuk skenario dengan kesulitan tertinggi.
Namun, perlu diingat bahwa harga GPT-5.4 Pro adalah $30.00/1M input + $180.00/1M output, biayanya jauh lebih tinggi daripada edisi standar. Untuk sebagian besar skenario pemecahan masalah matematika, edisi standar sudah cukup.
Pengalaman Nyata Pemecahan Masalah Matematika dengan GPT-5.4
Performa GPT-5.4 pada soal matematika tingkat kompetisi sangat mengesankan:
- Matematika Kompetisi: Soal-soal komprehensif teori bilangan, kombinatorial, geometri tingkat AMC/AIME hampir selalu dijawab dengan sempurna, skor sempurna 100% pada AIME pantas didapatkan.
- Soal Pembuktian: Dapat membangun rantai pembuktian matematika yang lengkap, logis ketat, dengan transisi antar langkah yang alami.
- Matematika Terapan: Skor 99% pada GSM8K menunjukkan bahwa model ini juga sangat andal dalam soal cerita terapan (seperti perhitungan teknik, pemodelan ekonomi).
- Penalaran Multi-Langkah: Berkat jendela konteks super panjang 1.05M, dapat mempertahankan rantai penalaran lengkap sambil menangani masalah matematika multi-langkah yang sangat kompleks.
Salah satu keunggulan unik GPT-5.4 adalah pendahulunya, GPT-5.2, menciptakan rekor baru 40.3% pada FrontierMath (matematika mutakhir tingkat ahli). Ini berarti seri GPT juga memiliki kemampuan eksplorasi tertentu pada masalah matematika yang benar-benar mutakhir dan belum terpecahkan, sesuatu yang sulit dicapai oleh model lain saat ini.
Interpretasi Benchmark Model AI Penyelesaian Matematika
Sebelum membandingkan model AI penyelesaian matematika, penting untuk memahami makna dan fokus dari setiap benchmark agar dapat menilai kemampuan model dengan lebih akurat:
| Benchmark | Nama Lengkap | Konten Pengujian | Tingkat Kesulitan |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | Soal kompetisi matematika Amerika, mencakup teori bilangan, kombinatorika, geometri, dll. | Tingkat kompetisi SMA (Top 5% siswa) |
| MATH | Mathematics Aptitude Test of Heuristics | Tes komprehensif mencakup 7 bidang utama seperti aljabar, geometri, kalkulus | Tingkat SMA hingga Sarjana |
| GSM8K | Grade School Math 8K | 8000 soal cerita matematika tingkat SD hingga SMP | Tingkat Dasar |
| GPQA Diamond | Graduate-Level Google-Proof QA | Pertanyaan penalaran ilmiah tingkat pascasarjana, ditulis oleh ahli bidang | Tingkat Pascasarjana/Doktoral |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | Pengenalan pola logika baru, menguji kemampuan penalaran abstrak | Tingkat Kecerdasan Umum |
| FrontierMath | Frontier Mathematics | Masalah matematika tingkat ahli/frontier, melibatkan bidang yang belum terpecahkan atau baru | Tingkat Ahli/Peneliti |
Pemahaman Kunci: AIME lebih menekankan keterampilan matematika tingkat kompetisi dan pemikiran kreatif, sedangkan MATH lebih menekankan kemampuan cakupan luas di berbagai bidang. Sebuah model yang mendapat nilai sempurna di AIME tetapi bukan nilai tertinggi di MATH (seperti GPT-5.4), menunjukkan bahwa model tersebut sangat kuat dalam soal-soal rumit tingkat kompetisi, tetapi cakupannya di beberapa bidang dasar mungkin sedikit lebih rendah dibandingkan model dengan skor MATH yang lebih tinggi.
Inilah alasan kami merekomendasikan Gemini 3.1 Pro Preview sebagai pilihan utama secara komprehensif — skor MATH 95.1% berarti model ini memiliki performa yang lebih seimbang di berbagai sub-bidang matematika.
Perlu diperhatikan bahwa benchmark AIME 2025 saat ini cenderung jenuh — banyak model top (dikombinasikan dengan eksekusi kode) dapat mencapai 95% atau bahkan nilai sempurna. Oleh karena itu, benchmark yang lebih sulit seperti MathArena Apex dan FrontierMath lebih mampu membedakan kemampuan matematika sejati model. Pada MathArena Apex, Gemini 3.1 Pro menunjukkan peningkatan lebih dari 20 kali lipat dibandingkan generasi sebelumnya, menunjukkan fondasi penalaran matematika internal yang sangat kuat.
Dimensi lain yang patut diperhatikan adalah ARC-AGI-2 (kemampuan penalaran abstrak). Tes ini mengevaluasi kemampuan model untuk mengenali pola logika yang benar-benar baru — pola yang belum pernah dilihat model selama pelatihan. Gemini 3.1 Pro Preview memimpin dengan skor 77.1%, menunjukkan bahwa model ini tidak hanya dapat menyelesaikan tipe soal yang pernah dilihat, tetapi juga memiliki kemampuan penalaran generalisasi yang lebih kuat, sehingga performanya lebih baik saat menghadapi jenis masalah matematika yang benar-benar baru.
Praktik Pemanggilan API Model AI Penyelesaian Matematika
Berikut adalah contoh kode minimalis untuk memanggil API model AI penyelesaian matematika, dapat dijalankan hanya dengan 10 baris kode:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI - antarmuka terpadu
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Dapat diganti dengan claude-sonnet-4.6 atau gpt-5.4
messages=[{"role": "user", "content": "Selesaikan: Diketahui barisan aritmatika {an} dengan suku pertama a1=2, beda d=3, tentukan jumlah 20 suku pertama S20"}]
)
print(response.choices[0].message.content)
Lihat kode pemanggilan penyelesaian matematika lengkap (dengan perbandingan multi-model)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
Memanggil model AI untuk menyelesaikan soal matematika
Args:
problem: Deskripsi soal matematika
model: Nama model, mendukung gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4
system_prompt: Petunjuk sistem, dapat menentukan gaya penyelesaian
Returns:
Respons penyelesaian dari model
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI - antarmuka terpadu
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "Anda adalah ahli penyelesaian matematika. Selesaikan soal matematika dengan langkah-langkah yang jelas, jelaskan dasar penalaran untuk setiap langkah."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Contoh penggunaan: Bandingkan penyelesaian satu soal dengan tiga model
problem = "Dalam segitiga ABC, diketahui a=5, b=7, C=60°, tentukan luas segitiga dan panjang sisi ketiga c"
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"Model: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
Saran: Dapatkan kuota uji coba gratis melalui APIYI di apiyi.com. Dengan satu Kunci API, Anda dapat memanggil ketiga model penyelesaian matematika di atas, dan dengan cepat membandingkan perbedaan performa mereka pada soal-soal aktual Anda.
Perbandingan Harga dan Nilai Uang Model AI Pemecah Masalah Matematika
Saat memilih model AI untuk memecahkan masalah matematika, harga adalah faktor yang tidak bisa diabaikan. Berikut adalah perbandingan harga detail dari tiga model:
| Dimensi Harga | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Harga Input | $2.00/1M token | $3.00/1M token | $2.50/1M token |
| Harga Output | $12.00/1M token | $15.00/1M token | $15.00/1M token |
| Harga Campuran (3:1) | $4.50/1M token | $6.00/1M token | $5.63/1M token |
| Biaya Tambah Konteks Panjang | >200K ganda | Tidak ada | >272K ganda |
| Jendela Konteks | 1M token | Jendela standar | 1.05M token |
| Output Maksimum | 65,536 token | Output standar | 128,000 token |
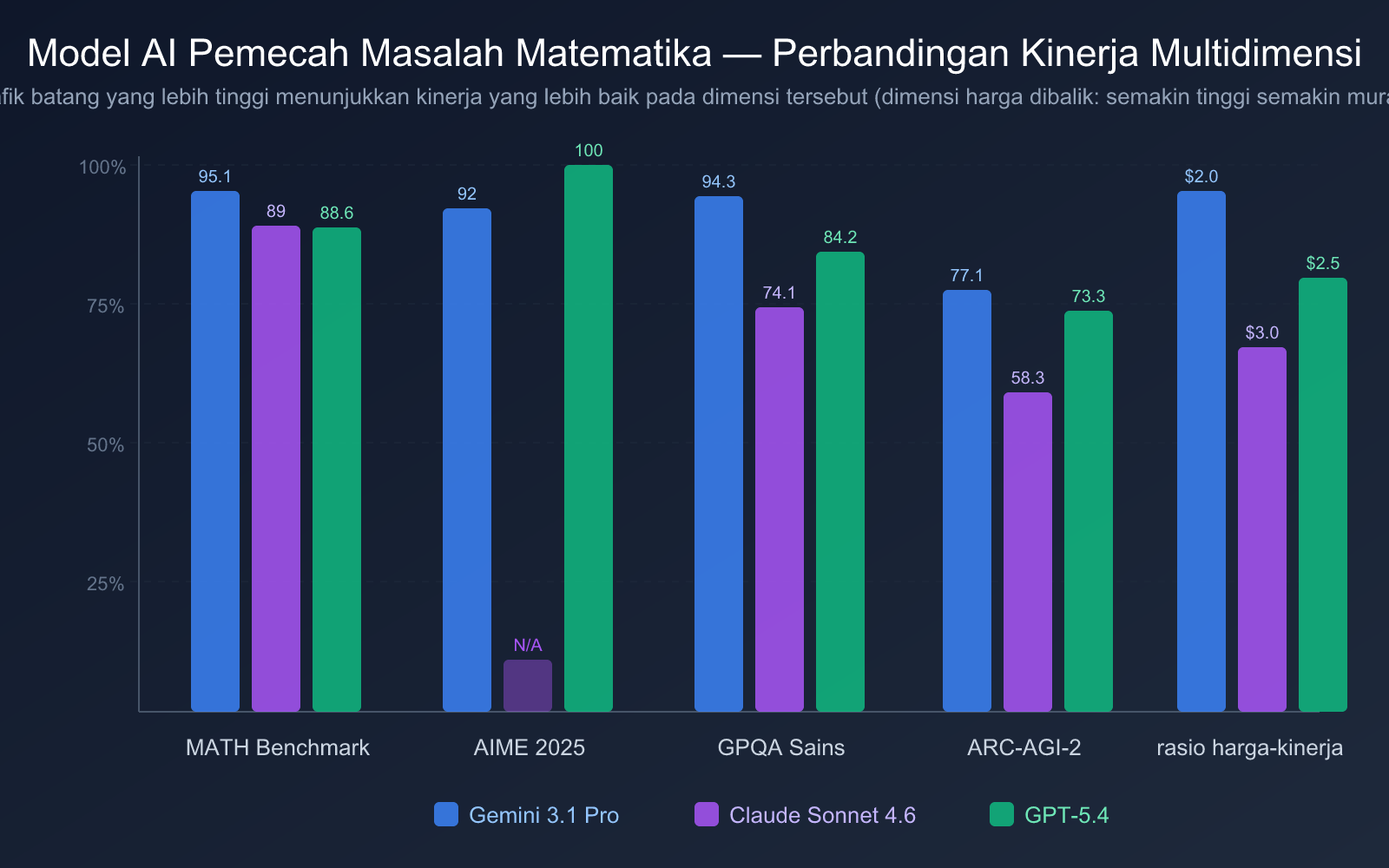
Dari sudut pandang nilai uang:
- Gemini 3.1 Pro Preview memiliki nilai uang tertinggi: Harga input hanya $2.00/1M token, dan skor tolok ukur MATH 95.1% memimpin. Menurut analisis Artificial Analysis, biaya operasionalnya sekitar 1/7.5 dari Claude Opus 4.6, namun performanya pada tolok ukur matematika dan pemrograman setara atau bahkan melampaui.
- Claude Sonnet 4.6 harga sedang: Harga $3.00/$15.00 sama dengan generasi sebelumnya Sonnet 4.5, tetapi kemampuan matematikanya meningkat 27 poin persentase, nilai uangnya meningkat signifikan.
- GPT-5.4 versi standar harga wajar: Harga $2.50/$15.00 berada dalam rentang wajar, tetapi jika menggunakan GPT-5.4 Pro ($30/$180), biayanya akan naik drastis.
💰 Saran Biaya: Untuk kebutuhan pemecahan masalah matematika sehari-hari, disarankan menggunakan Gemini 3.1 Pro Preview untuk mendapatkan nilai uang terbaik. Jika perlu mengoptimalkan biaya lebih lanjut, pertimbangkan untuk menggunakan platform agregator API untuk mendapatkan skema pengisian yang lebih fleksibel.
Estimasi Biaya Nyata Pemecahan Masalah Matematika
Untuk membantu Anda memahami perbedaan biaya dengan lebih intuitif, berikut adalah estimasi biaya untuk skenario pemecahan masalah matematika yang khas:
Asumsi Skenario: Menjawab 100 soal matematika dengan tingkat kesulitan sedang setiap hari, setiap soal rata-rata mengonsumsi 500 token input + 1500 token output.
| Model | Biaya Input Harian | Biaya Output Harian | Total Biaya Harian | Biaya Bulanan (30 hari) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0.10 | $1.80 | $1.90 | $57.00 |
| GPT-5.4 | $0.13 | $2.25 | $2.38 | $71.25 |
| Claude Sonnet 4.6 | $0.15 | $2.25 | $2.40 | $72.00 |
| GPT-5.4 Pro | $1.50 | $27.00 | $28.50 | $855.00 |
| DeepSeek R2 | $0.03 | $0.33 | $0.36 | $10.80 |
Dari estimasi biaya ini dapat dilihat dengan jelas:
- Biaya bulanan Gemini 3.1 Pro Preview sekitar $57, yang paling ekonomis di antara tiga model utama.
- Biaya Claude Sonnet 4.6 dan GPT-5.4 versi standar hampir sama, sekitar $71-72/bulan.
- Biaya GPT-5.4 Pro mencapai $855/bulan, hanya cocok untuk skenario dengan anggaran besar dan membutuhkan akurasi tertinggi.
- DeepSeek R2 menawarkan solusi yang sangat kompetitif dengan biaya super rendah $10.80/bulan.
Perbandingan Indeks Kecerdasan Komprehensif Model AI Pemecah Matematika
Selain pengujian benchmark tunggal, indeks kecerdasan komprehensif dapat mencerminkan potensi penalaran matematika model secara lebih menyeluruh. Artificial Analysis Intelligence Index adalah salah satu sistem evaluasi komprehensif paling otoritatif saat ini, yang menghitung skor komprehensif model berdasarkan empat dimensi: penalaran, pengetahuan, matematika, dan pemrograman.
| Model | Indeks Kecerdasan Komprehensif | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | Evaluasi Komprehensif |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | Raja soal kompetisi, indeks komprehensif setara pertama |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | Indeks komprehensif setara pertama, cakupan matematika paling lengkap |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | Kemampuan penalaran sains dan penjelasan terbaik |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | Rasio harga-kinerja sangat baik, proses pemecahan paling jelas |
Dari indeks kecerdasan komprehensif, GPT-5.4 (xhigh) dan Gemini 3.1 Pro Preview sama-sama menempati posisi pertama dengan skor 57, tetapi keduanya memiliki fokus yang berbeda:
- GPT-5.4: Performa sempurna (100%) pada soal kompetisi seperti AIME, tetapi benchmark komprehensif MATH (88.6%) sedikit lebih rendah.
- Gemini 3.1 Pro: Lebih seimbang pada benchmark komprehensif MATH (95.1%) dan penalaran sains GPQA Diamond (94.3%).
Ini berarti jika kebutuhan matematika Anda cenderung pada kompetisi dan soal-soal ekstrem yang sulit, GPT-5.4 lebih unggul. Namun, jika Anda memerlukan performa stabil yang mencakup berbagai bidang matematika, Gemini 3.1 Pro Preview adalah pilihan yang lebih aman.
Rekomendasi Model AI Pemecah Matematika Berdasarkan Skenario
Skenario penerapan matematika yang berbeda memiliki kebutuhan model yang berbeda. Berikut adalah rekomendasi berdasarkan skenario penggunaan aktual:
Skenario Matematika untuk Memilih Gemini 3.1 Pro Preview
- Platform Bimbingan Matematika Komprehensif: Mencakup semua bidang seperti aljabar, geometri, kalkulus, dengan kemampuan komprehensif MATH 95.1% terkuat.
- Pemrosesan Soal Matematika dalam Jumlah Besar: Harga termurah, sistem pemikiran tiga lapis dapat secara otomatis menyesuaikan tingkat kesulitan soal, mengurangi biaya pemrosesan.
- Skenario yang Menggabungkan Komputasi Sains: Kemampuan penalaran sains GPQA Diamond 94.3%, cocok untuk soal-soal yang menggabungkan fisika, kimia, dan matematika.
- Masalah Matematika Visual: Dalam menangani soal matematika yang melibatkan diagram dan bentuk geometri, kemampuan multimodal Gemini memiliki keunggulan.
Skenario Matematika untuk Memilih Claude Sonnet 4.6
- Pendidikan dan Bimbingan Matematika: Proses pemecahan paling jelas, Learning Mode khusus membimbing siswa dalam penalaran, tidak langsung memberikan jawaban tetapi membimbing pemikiran.
- Pembelajaran Langkah-Langkah Pemecahan Masalah: Skenario yang membutuhkan pemahaman "mengapa dilakukan seperti ini", kemampuan penjelasan Claude diakui sebagai yang terbaik. 70% pengguna lebih memilih Sonnet 4.6 daripada versi sebelumnya 4.5, menunjukkan peningkatan kualitas pengalaman pengguna yang signifikan.
- Asistensi Penelitian Matematika: Cocok untuk peneliti yang memerlukan proses derivasi rinci untuk memverifikasi ide, kedalaman pemikiran adaptif dapat secara otomatis mencocokkan kompleksitas masalah.
- Komputasi Perkantoran dan Keuangan: Analisis keuangan 63.3% terbaik di kelasnya, produktivitas perkantoran GDPval-AA skor 1633 Elo bahkan melampaui Opus 4.6 yang lebih mahal.
- Kombinasi Pemrograman + Matematika: Kemampuan pemrograman 79.6% mendekati Opus 4.6, cocok untuk pengembang yang perlu menulis program perhitungan matematika.
Skenario Matematika untuk Memilih GPT-5.4
- Kompetisi Matematika Tingkat Tinggi: Skor sempurna AIME 100%, model pilihan utama untuk soal matematika tingkat kompetisi.
- Penalaran Matematika Dokumen Panjang: Jendela konteks 1.05M, cocok untuk menangani masalah kompleks yang memerlukan banyak informasi latar belakang matematika.
- Penelitian Matematika Profesional: Generasi sebelumnya GPT-5.2 menciptakan rekor baru 40.3% di FrontierMath, kemampuan matematika tingkat lanjut ahli yang kuat.
- Perbankan Investasi dan Keuangan Kuantitatif: Skor tinggi 87.3% pada tugas pemodelan perbankan investasi, cocok untuk skenario matematika keuangan tingkat tinggi.
Strategi Penggunaan Campuran: Kombinasi Terbaik Model Pemecah Matematika
Dalam lingkungan produksi aktual, banyak tim menggunakan strategi penggunaan campuran untuk mendapatkan hasil terbaik:
Strategi 1: Routing Berdasarkan Tingkat Kesulitan
- Soal dasar (aritmatika, persamaan sederhana) → Mode Gemini 3.1 Pro Low, biaya termurah.
- Soal menengah (penalaran multi-langkah, soal cerita) → Mode adaptif Claude Sonnet 4.6, proses pemecahan jelas.
- Soal tingkat tinggi (kompetisi, pembuktian) → Mode Thinking GPT-5.4, akurasi tertinggi.
Strategi 2: Validasi Silang
- Pertama, gunakan Gemini 3.1 Pro untuk memecahkan soal dengan cepat (biaya rendah, kecepatan tinggi).
- Hasil kunci divalidasi ulang dengan GPT-5.4 (akurasi tinggi).
- Saat perlu dijelaskan kepada pengguna, gunakan Claude Sonnet 4.6 untuk merumuskan ulang (ekspresi jelas).
🚀 Saran Implementasi: Strategi penggunaan campuran di atas dapat dengan mudah diimplementasikan melalui platform APIYI apiyi.com. Satu Kunci API dapat digunakan untuk memanggil semua model, cukup dengan mengganti parameter
modeldalam kode.
Rekomendasi Pemilihan Model AI untuk Penyelesaian Masalah Matematika
Berdasarkan analisis di atas, berikut adalah rekomendasi pemilihan model untuk berbagai kelompok pengguna:
| Tipe Pengguna | Model yang Direkomendasikan | Alasan Rekomendasi |
|---|---|---|
| Siswa/Pembelajar Mandiri | Claude Sonnet 4.6 | Proses penyelesaian masalah yang jelas, Mode Pembelajaran (Learning Mode) membantu memandu pemikiran |
| Pengembang Platform Edukasi | Gemini 3.1 Pro Preview | Kemampuan komprehensif terbaik, harga termurah, tiga lapis pemikiran (three-layer reasoning) dapat menyesuaikan tingkat kesulitan |
| Peserta/Pelatih Kompetisi | GPT-5.4 | Skor AIME sempurna, kemampuan terkuat dalam menyelesaikan masalah tingkat kompetisi |
| Peneliti | Gemini 3.1 Pro Preview | GPQA Diamond 94.3%, kemampuan terdepan dalam bidang sains dan matematika yang saling bersinggungan |
| Pemrosesan Batch Perusahaan | Gemini 3.1 Pro Preview | Rasio harga-kinerja tertinggi, harga input $2.00 per 1 juta token |
| Tim Kuantitatif Keuangan | GPT-5.4 | Pemodelan investment banking 87.3%, terkuat dalam skenario matematika keuangan |
💡 Saran Pemilihan: Model AI penyelesaian matematika mana yang dipilih terutama bergantung pada skenario aplikasi spesifik Anda. Jika Anda tidak yakin mana yang paling cocok, kami sarankan untuk menguji ketiga model menggunakan soal matematika yang sama melalui platform APIYI di apiyi.com. Buatlah pilihan akhir berdasarkan kualitas penyelesaian dan kecepatan respons. Platform ini mendukung pemanggilan melalui antarmuka yang terpadu, memudahkan perbandingan cepat dan pergantian model.
Model Penyelesaian Matematika Lain yang Patut Diperhatikan
Selain tiga model utama di atas, ada beberapa model AI penyelesaian matematika lain yang patut diperhatikan dalam skenario tertentu:
| Nama Model | AIME 2025 | Keunggulan Inti | Harga API (Input/Output) | Skenario yang Cocok |
|---|---|---|---|---|
| DeepSeek R2 | Mengalahkan Gemini 3.1 Pro | Rasio harga-kinerja terbaik | $0.55/$2.19 per 1 juta token | Pemrosesan batch matematika yang sensitif terhadap anggaran |
| Claude Opus 4.6 | — | GPQA 91.3%, penjelasan terdalam | $15/$75 per 1 juta token | Penelitian tingkat tinggi dan penalaran mendalam |
| Qwen3-235B | 89.2% | Model open-source terkuat | Biaya penyebaran sendiri | Skenario yang memerlukan penyebaran privat |
| DeepSeek R1 | Sekitar 87.5% | Patokan open-source, arsitektur MoE 671B | Biaya penyebaran sendiri | Penelitian komunitas open-source dan pengembangan ulang |
| MiMo-V2-Flash | 94.1% | Biaya inferensi hanya 2.5% dari Claude | Sangat rendah | Inferensi skala besar dengan biaya sangat rendah |
Yang patut mendapat perhatian khusus adalah DeepSeek R2. Model ini mengalahkan Gemini 3.1 Pro Preview dalam tes AIME, dengan harga hanya sekitar 1/4 dari Gemini. Jika skenario penyelesaian matematika Anda sangat sensitif terhadap anggaran, DeepSeek R2 adalah pilihan yang sangat kompetitif.
Sementara itu, MiMo-V2-Flash mencapai skor tinggi 94.1% pada AIME 2025, dengan biaya inferensi hanya 2.5% dari Claude. Ini sangat cocok untuk platform teknologi pendidikan yang memerlukan pemrosesan batch soal matematika dalam skala besar.
Teknik Optimalisasi Petunjuk (Prompt) untuk Model AI Penyelesaian Matematika
Terlepas dari model mana yang dipilih, petunjuk yang baik dapat secara signifikan meningkatkan kualitas penyelesaian masalah matematika. Berikut adalah teknik petunjuk yang telah teruji:
- Jelaskan Tipe Soal: Tandai dalam petunjuk dengan "Ini adalah soal kombinatorik" atau "Ini adalah soal geometri analitik" untuk membantu model memanggil strategi penyelesaian yang tepat.
- Minta Solusi Bertahap: Tambahkan "Tolong turunkan langkah demi langkah, beri label teorema atau rumus yang digunakan di setiap langkah" untuk meningkatkan keterbacaan proses penyelesaian.
- Tentukan Format Output: Misalnya, "Gunakan format LaTeX untuk menampilkan rumus matematika" atau "Tandai jawaban akhir dengan kotak".
- Berikan Batasan Latar Belakang: Seperti "Asumsikan x adalah bilangan bulat positif" atau "Selesaikan dalam rentang bilangan real" untuk menghindari model membuat diskusi klasifikasi yang tidak perlu.
- Validasi Silang dengan Beberapa Model: Untuk hasil kritis, gunakan model yang berbeda untuk memverifikasi konsistensi jawaban, guna meningkatkan tingkat kepercayaan.
Pertanyaan Umum
Q1: Apakah hasil benchmark model AI pemecah soal matematika dapat dipercaya?
Benchmark memberikan dasar perbandingan standar secara horizontal, namun efektivitas aktual juga dipengaruhi oleh jenis soal, kualitas petunjuk, dan faktor lainnya. AIME dan MATH saat ini adalah benchmark penalaran matematika paling otoritatif, yang diakui luas oleh akademisi dan industri. Disarankan untuk menguji dan memverifikasi dengan soal-soal aktual Anda sendiri sambil merujuk data benchmark.
Q2: Saya seorang pelajar, model AI pemecah soal matematika mana yang harus saya pilih?
Disarankan untuk memilih Claude Sonnet 4.6 sebagai prioritas utama. Proses pemecahan soalnya paling jelas, setiap langkah dilengkapi dengan penjelasan penalaran yang eksplisit, sangat cocok untuk belajar dan memahami alur berpikir penyelesaian soal matematika. Fitur Learning Mode dari Anthropic bahkan dapat memandu Anda untuk berpikir sendiri, bukan langsung memberikan jawaban. Jika menemui soal kompetisi yang sangat sulit, Anda dapat beralih ke GPT-5.4 untuk meminta bantuan.
Q3: Bagaimana cara cepat memulai pengujian model-model AI pemecah soal matematika ini?
Disarankan menggunakan platform agregasi API yang mendukung antarmuka terpadu untuk banyak model untuk pengujian:
- Kunjungi APIYI apiyi.com dan daftar akun
- Dapatkan kunci API dan kuota uji coba gratis
- Gunakan contoh kode Python yang disediakan dalam artikel ini, cukup ubah parameter
modeluntuk beralih antar model yang berbeda - Uji ketiga model dengan soal matematika yang sama, bandingkan kualitas penyelesaian dan kecepatan respons
Q4: Apakah model-model AI pemecah soal matematika ini mendukung output rumus LaTeX?
Ketiga model mendukung output rumus matematika dalam format LaTeX. Cukup tambahkan "Harap output semua rumus matematika dalam format LaTeX" di dalam petunjuk. Gemini 3.1 Pro dan GPT-5.4 memiliki format LaTeX yang lebih standar, sedangkan Claude Sonnet 4.6 memberikan penjelasan teks yang lebih detail di antara rumus-rumus. Untuk skenario yang memerlukan penyalinan langsung rumus ke dalam makalah, disarankan menggunakan Gemini atau GPT.
Q5: Bisakah model AI pemecah soal matematika memproses soal matematika dalam gambar?
Gemini 3.1 Pro Preview dan GPT-5.4 keduanya mendukung input multimodal, dapat langsung mengunggah gambar yang berisi soal matematika untuk dijawab. Gemini menunjukkan performa yang sangat baik dalam menangani gambar yang berisi bentuk geometri dan rumus tulisan tangan. Claude Sonnet 4.6 juga mendukung input gambar, namun sedikit tertinggal dari Gemini dalam pengenalan bentuk geometri yang kompleks. Jika soal matematika Anda sering muncul dalam bentuk gambar (seperti foto pencarian soal), Gemini 3.1 Pro Preview adalah pilihan terbaik.
Kesimpulan
Inti pemilihan model AI pemecah soal matematika:
- Pilihan Utama Kemampuan Komprehensif: Gemini 3.1 Pro Preview – Memimpin komprehensif dengan MATH 95.1%, harga terbaik $2.00/1M token, sistem tiga lapis pemikiran yang fleksibel beradaptasi dengan tingkat kesulitan berbeda.
- Pilihan Utama Pembelajaran & Pemahaman: Claude Sonnet 4.6 – Kemampuan matematika melonjak 27 poin persentase menjadi 89%, langkah penyelesaian soal jelas, kedalaman pemikiran adaptif menyeimbangkan biaya dan kualitas.
- Pilihan Utama Soal Kompetisi Sulit: GPT-5.4 – AIME 2025 skor sempurna 100%, konteks super panjang 1.05M, kemampuan penalaran tingkat tinggi tak tertandingi.
Tidak ada satu model pun yang merupakan solusi terbaik di semua skenario matematika. Lanskap persaingan model AI pemecah soal matematika tahun 2026 dapat disimpulkan sebagai berikut:
- Cakupan Komprehensif: Gemini 3.1 Pro Preview dengan MATH 95.1% dan harga terendah menduduki posisi pilihan utama komprehensif.
- Pendidikan & Pembelajaran: Claude Sonnet 4.6 dengan lonjakan matematika 27 poin persentase dan kemampuan penjelasan penyelesaian soal yang tak tertandingi, menjadi pilihan terbaik untuk skenario pendidikan.
- Kompetisi Ekstrem: GPT-5.4 dengan kemampuan mutlak skor sempurna AIME, tak tertandingi di bidang kompetisi matematika berkesulitan tinggi.
- Prioritas Anggaran: DeepSeek R2 dengan harga kurang dari 1/4 Gemini memberikan kemampuan penalaran matematika yang sebanding.
Strategi paling bijak adalah memilih model yang sesuai dengan kebutuhan aktual Anda, bahkan menggunakan beberapa model secara campuran untuk soal-soal dengan tingkat kesulitan berbeda, memanfaatkan sepenuhnya keunggulan unik setiap model.
Disarankan untuk menguji dan membandingkan model-model ini dengan cepat melalui APIYI apiyi.com. Platform ini menyediakan kuota gratis dan antarmuka API terpadu, sekali integrasi dapat memanggil semua model penalaran matematika utama secara fleksibel, dengan mudah menerapkan strategi penggunaan multi-model campuran.
📚 Referensi
-
Model Card Google DeepMind Gemini 3.1 Pro: Data benchmark dan detail teknis resmi
- Tautan:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Penjelasan: Berisi skor pengujian benchmark lengkap dan penjelasan arsitektur
- Tautan:
-
Catatan Rilis Anthropic Claude Sonnet 4.6: Detail peningkatan kemampuan penalaran matematika
- Tautan:
docs.anthropic.com - Penjelasan: Berisi data perbandingan Sonnet 4.6 dengan generasi sebelumnya dan penjelasan mekanisme pemikiran adaptif
- Tautan:
-
Pengumuman Rilis OpenAI GPT-5.4: Fitur model terbaru dan data benchmark
- Tautan:
openai.com/index/introducing-gpt-5-4/ - Penjelasan: Berisi skor pengujian benchmark lengkap GPT-5.4 dan penjelasan konfigurasi penalaran
- Tautan:
-
Evaluasi Model Artificial Analysis: Platform perbandingan benchmark pihak ketiga independen
- Tautan:
artificialanalysis.ai/evaluations/aime-2025 - Penjelasan: Menyediakan papan peringkat dan analisis independen untuk pengujian benchmark seperti AIME 2025
- Tautan:
-
Papan Peringkat Benchmark AIME 2025: Perbandingan otoritatif kemampuan penalaran matematika
- Tautan:
vals.ai/benchmarks/aime - Penjelasan: Data peringkat benchmark penalaran matematika AI yang terus diperbarui
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Bagikan pengalamanmu menggunakan AI untuk menyelesaikan soal matematika di bagian komentar. Untuk tutorial pemanggilan model lebih lanjut, kunjungi pusat dokumentasi APIYI di docs.apiyi.com