Zhipu AI secara resmi merilis GLM-5 pada 11 Februari 2026, yang merupakan salah satu Model Bahasa Besar (LLM) sumber terbuka dengan skala parameter terbesar saat ini. GLM-5 menggunakan arsitektur Mixture-of-Experts (MoE) 744B, dengan 40B parameter yang diaktifkan setiap kali inferensi, mencapai level terbaik untuk model sumber terbuka dalam tugas penalaran, pengkodean, dan Agent.
Nilai Inti: Setelah membaca artikel ini, Anda akan menguasai prinsip arsitektur teknis GLM-5, metode pemanggilan API, konfigurasi mode penalaran Thinking, serta cara memaksimalkan nilai dari model unggulan sumber terbuka 744B ini dalam proyek nyata.

Sekilas Parameter Inti GLM-5
Sebelum mendalami detail teknisnya, mari kita lihat parameter kunci dari GLM-5:
| Parameter | Nilai | Keterangan |
|---|---|---|
| Total Parameter | 744B (744 Miliar) | Salah satu model sumber terbuka terbesar saat ini |
| Parameter Aktif | 40B (40 Miliar) | Digunakan secara nyata dalam setiap inferensi |
| Tipe Arsitektur | MoE (Mixture of Experts) | 256 ahli, 8 diaktifkan per token |
| Jendela Konteks | 200.000 token | Mendukung pemrosesan dokumen sangat panjang |
| Output Maksimal | 128.000 token | Memenuhi kebutuhan pembuatan teks panjang |
| Data Pra-pelatihan | 28,5T token | Meningkat 24% dibandingkan generasi sebelumnya |
| Lisensi | Apache-2.0 | Sepenuhnya sumber terbuka, mendukung penggunaan komersial |
| Hardware Pelatihan | Chip Huawei Ascend | Tumpukan daya komputasi lokal penuh, tidak bergantung hardware luar negeri |
Salah satu fitur menonjol dari GLM-5 adalah model ini sepenuhnya dilatih berdasarkan chip Huawei Ascend dan kerangka kerja MindSpore, mewujudkan verifikasi lengkap terhadap tumpukan daya komputasi domestik. Bagi pengembang lokal, ini berarti ada pilihan kuat lainnya untuk tumpukan teknologi yang mandiri dan terkendali.
Evolusi Versi Seri GLM
GLM-5 adalah produk generasi kelima dari seri GLM Zhipu AI, di mana setiap generasi memiliki lompatan kemampuan yang signifikan:
| Versi | Waktu Rilis | Skala Parameter | Terobosan Inti |
|---|---|---|---|
| GLM-4 | 01-2024 | Tidak diungkapkan | Kemampuan dasar multimodal |
| GLM-4.5 | 03-2025 | 355B (32B aktif) | Pertama kali memperkenalkan arsitektur MoE |
| GLM-4.5-X | 06-2025 | Sama seperti di atas | Penguatan penalaran, posisi unggulan |
| GLM-4.7 | 10-2025 | Tidak diungkapkan | Mode penalaran Thinking |
| GLM-4.7-FlashX | 12-2025 | Tidak diungkapkan | Inferensi cepat biaya super rendah |
| GLM-5 | 02-2026 | 744B (40B aktif) | Terobosan kemampuan Agent, tingkat halusinasi turun 56% |
Dari 355B pada GLM-4.5 menjadi 744B pada GLM-5, total parameter meningkat lebih dari dua kali lipat; parameter aktif meningkat dari 32B menjadi 40B, naik 25%; data pra-pelatihan meningkat dari 23T menjadi 28,5T token. Di balik angka-angka ini terdapat investasi menyeluruh dari Zhipu AI dalam tiga dimensi: daya komputasi, data, dan algoritma.
🚀 Pengalaman Cepat: GLM-5 telah tersedia di APIYI (apiyi.com). Harganya sama dengan situs resmi, dan dengan aktivitas bonus isi ulang, Anda bisa menikmati diskon sekitar 20%, sangat cocok bagi pengembang yang ingin segera mencoba model unggulan 744B ini.
Analisis Teknis Arsitektur MoE GLM-5
Mengapa GLM-5 Memilih Arsitektur MoE
MoE (Mixture of Experts) merupakan lini teknologi utama yang digunakan untuk penskalaan Model Bahasa Besar saat ini. Berbeda dengan arsitektur Dense (di mana semua parameter terlibat dalam setiap inferensi), arsitektur MoE hanya mengaktifkan sebagian kecil jaringan pakar untuk memproses setiap token. Hal ini secara signifikan mengurangi biaya inferensi sambil tetap mempertahankan kapasitas pengetahuan model yang besar.
Desain arsitektur MoE pada GLM-5 memiliki karakteristik utama sebagai berikut:
| Karakteristik Arsitektur | Implementasi GLM-5 | Nilai Teknis |
|---|---|---|
| Total Pakar | 256 pakar | Kapasitas pengetahuan sangat besar |
| Aktivasi per token | 8 pakar | Efisiensi inferensi tinggi |
| Tingkat Sparsitas | 5,9% | Hanya menggunakan sebagian kecil parameter |
| Mekanisme Atensi | DSA + MLA | Mengurangi biaya deployment |
| Optimasi Memori | MLA berkurang 33% | Penggunaan VRAM lebih rendah |
Sederhananya, meskipun GLM-5 memiliki 744 miliar parameter, setiap inferensi hanya mengaktifkan 40 miliar parameter (sekitar 5,9%). Ini berarti biaya inferensinya jauh lebih rendah daripada model Dense dengan ukuran yang sama, namun tetap dapat memanfaatkan kekayaan pengetahuan yang terkandung dalam 744 miliar parameter tersebut.
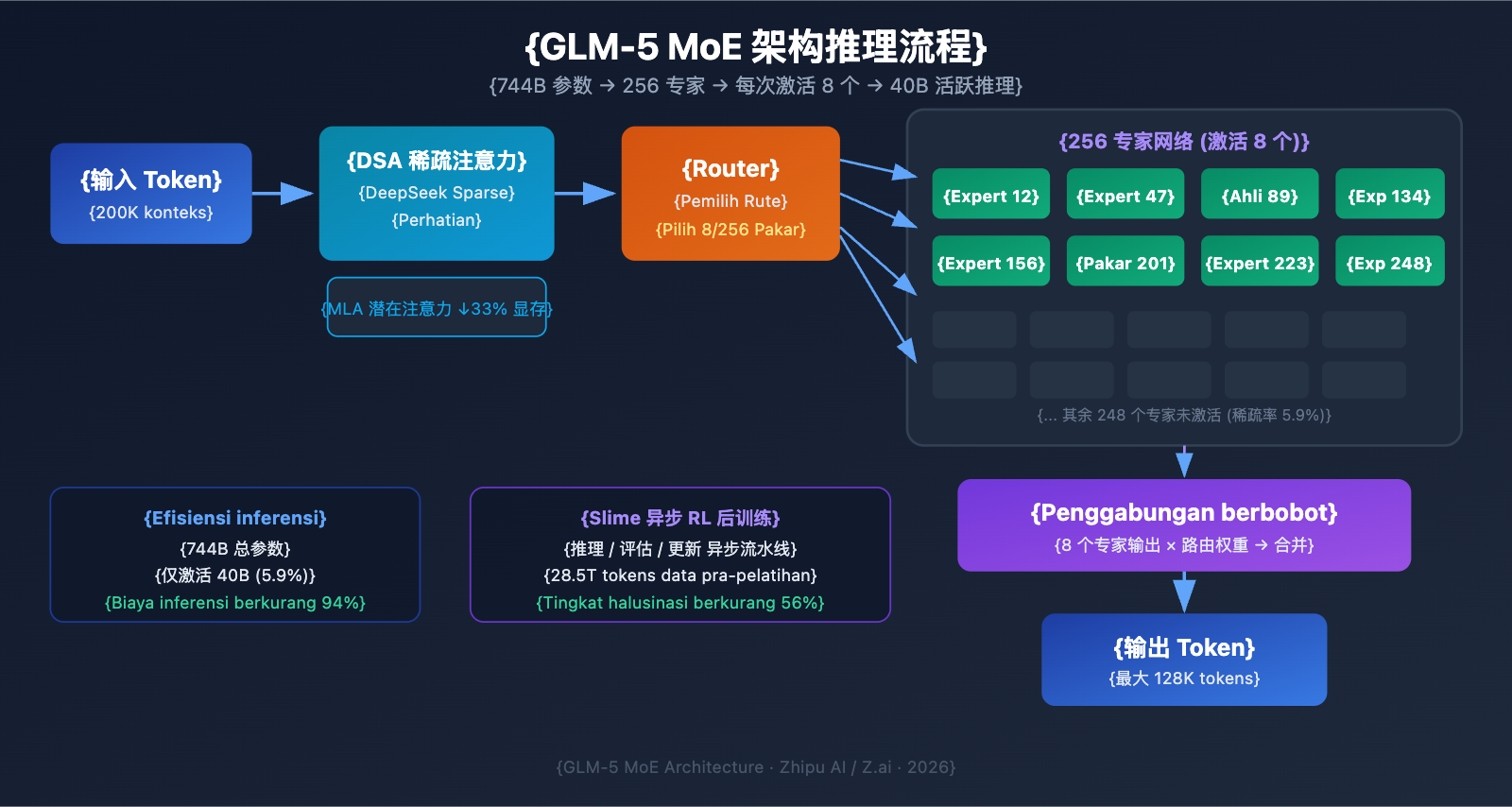
DeepSeek Sparse Attention (DSA) pada GLM-5
GLM-5 mengintegrasikan mekanisme DeepSeek Sparse Attention, sebuah teknologi yang secara signifikan mengurangi biaya deployment sambil tetap mempertahankan kemampuan konteks panjang. Bersama dengan Multi-head Latent Attention (MLA), GLM-5 tetap dapat beroperasi secara efisien bahkan dalam jendela konteks super panjang hingga 200 ribu token.
Secara spesifik:
- DSA (DeepSeek Sparse Attention): Mengurangi kompleksitas perhitungan atensi melalui pola atensi jarang (sparse). Mekanisme atensi penuh tradisional memerlukan komputasi yang sangat besar saat menangani 200 ribu token. DSA mengurangi beban komputasi dengan fokus secara selektif pada posisi token kunci, sehingga menjaga integritas informasi dengan biaya lebih rendah.
- MLA (Multi-head Latent Attention): Mengompresi KV cache dari head atensi ke dalam ruang laten, yang mengurangi penggunaan memori sekitar 33%. Dalam skenario konteks panjang, KV cache biasanya menjadi pengonsumsi utama VRAM; MLA secara efektif mengatasi hambatan ini.
Kombinasi kedua teknologi ini berarti: bahkan model skala 744B pun dapat dijalankan pada 8 GPU setelah kuantisasi FP8, yang secara drastis menurunkan ambang batas deployment.
Pasca-pelatihan GLM-5: Sistem RL Asinkron Slime
GLM-5 menggunakan infrastruktur pembelajaran penguatan (reinforcement learning/RL) asinkron baru yang disebut "slime" untuk tahap pasca-pelatihan. Pelatihan RL tradisional sering kali mengalami hambatan efisiensi—terdapat banyak waktu tunggu antara langkah pembuatan (generation), evaluasi, dan pembaruan (update). Slime mengasinkronkan langkah-langkah ini, memungkinkan iterasi pasca-pelatihan yang lebih halus dan meningkatkan throughput pelatihan secara signifikan.
Dalam alur pelatihan RL tradisional, model harus menyelesaikan satu batch inferensi, menunggu hasil evaluasi, baru kemudian memperbarui parameter; ketiga langkah ini dijalankan secara berurutan (serial). Slime memisahkan ketiga langkah ini menjadi pipeline asinkron yang independen, sehingga inferensi, evaluasi, dan pembaruan dapat berjalan secara paralel.
Peningkatan teknis ini tercermin langsung pada tingkat halusinasi GLM-5—berkurang 56% dibandingkan versi sebelumnya. Iterasi pasca-pelatihan yang lebih memadai memungkinkan model memperoleh peningkatan nyata dalam akurasi faktual.
Perbandingan GLM-5 dengan Arsitektur Dense
Untuk lebih memahami keunggulan arsitektur MoE, mari kita bandingkan GLM-5 dengan asumsi model Dense pada skala yang sama:
| Dimensi Perbandingan | GLM-5 (744B MoE) | Asumsi 744B Dense | Perbedaan Nyata |
|---|---|---|---|
| Parameter per Inferensi | 40B (5,9%) | 744B (100%) | MoE berkurang 94% |
| Kebutuhan VRAM Inferensi | 8x GPU (FP8) | Sekitar 96x GPU | MoE jauh lebih rendah |
| Kecepatan Inferensi | Relatif Cepat | Sangat Lambat | MoE lebih cocok untuk deployment nyata |
| Kapasitas Pengetahuan | Pengetahuan penuh 744B | Pengetahuan penuh 744B | Setara |
| Kemampuan Spesialisasi | Pakar berbeda ahli dalam tugas berbeda | Pemrosesan seragam | MoE lebih presisi |
| Biaya Pelatihan | Tinggi namun terkendali | Sangat Tinggi | MoE memiliki rasio performa-biaya lebih baik |
Keunggulan inti dari arsitektur MoE adalah: ia memberikan efisiensi tinggi dengan biaya inferensi hanya 40 miliar parameter, namun memiliki kapasitas pengetahuan dari 744 miliar parameter. Inilah alasan mengapa GLM-5 dapat mempertahankan performa mutakhir sambil menawarkan harga yang jauh lebih rendah daripada model closed-source di kelas yang sama.
Panduan Cepat Pemanggilan API GLM-5
Detail Parameter Permintaan API GLM-5
Sebelum mulai menulis kode, mari kita pahami dulu konfigurasi parameter API GLM-5:
| Parameter | Tipe | Wajib | Nilai Default | Keterangan |
|---|---|---|---|---|
model |
string | ✅ | – | Tetap di "glm-5" |
messages |
array | ✅ | – | Pesan dalam format chat standar |
max_tokens |
int | ❌ | 4096 | Jumlah token output maksimum (batas atas 128K) |
temperature |
float | ❌ | 1.0 | Suhu pengambilan sampel, semakin rendah semakin deterministik |
top_p |
float | ❌ | 1.0 | Parameter nucleus sampling |
stream |
bool | ❌ | false | Apakah menggunakan output streaming |
thinking |
object | ❌ | disabled | {"type": "enabled"} untuk mengaktifkan penalaran |
tools |
array | ❌ | – | Definisi alat Function Calling |
tool_choice |
string | ❌ | auto | Strategi pemilihan alat |
Contoh Pemanggilan GLM-5 Super Simpel
GLM-5 kompatibel dengan format antarmuka SDK OpenAI, Anda hanya perlu mengganti parameter base_url dan model untuk terhubung dengan cepat:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Anda adalah seorang pakar teknologi AI senior"},
{"role": "user", "content": "Jelaskan prinsip kerja dan keunggulan arsitektur Mixture of Experts (MoE)"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Potongan kode di atas adalah cara paling dasar untuk memanggil GLM-5. ID model yang digunakan adalah glm-5, dan antarmukanya sepenuhnya kompatibel dengan format chat.completions milik OpenAI, sehingga migrasi proyek yang sudah ada hanya memerlukan perubahan pada dua parameter saja.
Mode Penalaran GLM-5 Thinking
GLM-5 mendukung mode Thinking, mirip dengan kemampuan berpikir yang diperluas pada DeepSeek R1 dan Claude. Setelah diaktifkan, model akan melakukan penalaran berantai internal sebelum menjawab, yang secara signifikan meningkatkan performa pada masalah matematika, logika, dan pemrograman yang kompleks:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Buktikan: Untuk semua bilangan bulat positif n, n^3 - n dapat dibagi habis oleh 6"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Disarankan menggunakan 1.0 untuk mode Thinking
)
print(response.choices[0].message.content)
Saran Penggunaan Mode GLM-5 Thinking:
| Skenario | Aktifkan Thinking? | Saran temperature | Keterangan |
|---|---|---|---|
| Pembuktian matematika/Soal kompetisi | ✅ Aktif | 1.0 | Membutuhkan penalaran mendalam |
| Debugging kode/Desain arsitektur | ✅ Aktif | 1.0 | Membutuhkan analisis sistematis |
| Penalaran logika/Analisis | ✅ Aktif | 1.0 | Membutuhkan pemikiran berantai |
| Percakapan sehari-hari/Menulis | ❌ Nonaktif | 0.5-0.7 | Tidak butuh penalaran rumit |
| Ekstraksi informasi/Ringkasan | ❌ Nonaktif | 0.3-0.5 | Mengejar output yang stabil |
| Pembuatan konten kreatif | ❌ Nonaktif | 0.8-1.0 | Membutuhkan variasi |
Output Streaming GLM-5
Untuk skenario yang membutuhkan interaksi real-time, GLM-5 mendukung output streaming, sehingga pengguna dapat melihat hasil secara bertahap saat model sedang membuatnya:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Implementasikan klien HTTP dengan cache menggunakan Python"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling dan Membangun Agent
GLM-5 mendukung Function Calling secara native, yang merupakan kemampuan inti untuk membangun sistem Agent. GLM-5 meraih skor 50,4% pada HLE w/ Tools, melampaui Claude Opus (43,4%), yang menunjukkan performa luar biasa dalam pemanggilan alat dan orkestrasi tugas:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "Mencari dokumen relevan dalam basis pengetahuan",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Kata kunci pencarian"},
"top_k": {"type": "integer", "description": "Jumlah hasil yang dikembalikan", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "Menjalankan kode Python dalam lingkungan sandbox",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "Kode Python yang akan dijalankan"},
"timeout": {"type": "integer", "description": "Waktu habis (detik)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Anda adalah asisten AI yang mampu mencari dokumen dan menjalankan kode"},
{"role": "user", "content": "Bantu saya mencari parameter teknis GLM-5, lalu buatkan grafik perbandingan performa menggunakan kode"}
],
tools=tools,
tool_choice="auto"
)
# Menangani pemanggilan alat
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"Memanggil alat: {tool_call.function.name}")
print(f"Parameter: {tool_call.function.arguments}")
Lihat Contoh Pemanggilan cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "Anda adalah seorang insinyur perangkat lunak senior"},
{"role": "user", "content": "Rancang arsitektur sistem penjadwalan tugas terdistribusi"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 Saran Teknis: GLM-5 kompatibel dengan format SDK OpenAI, proyek yang sudah ada hanya perlu mengubah dua parameter, yaitu
base_urldanmodel, untuk migrasi. Melalui platform APIYI apiyi.com, Anda dapat menikmati manajemen antarmuka terpadu dan bonus isi ulang.
Pengujian Performa Benchmark GLM-5
Data Benchmark Inti GLM-5
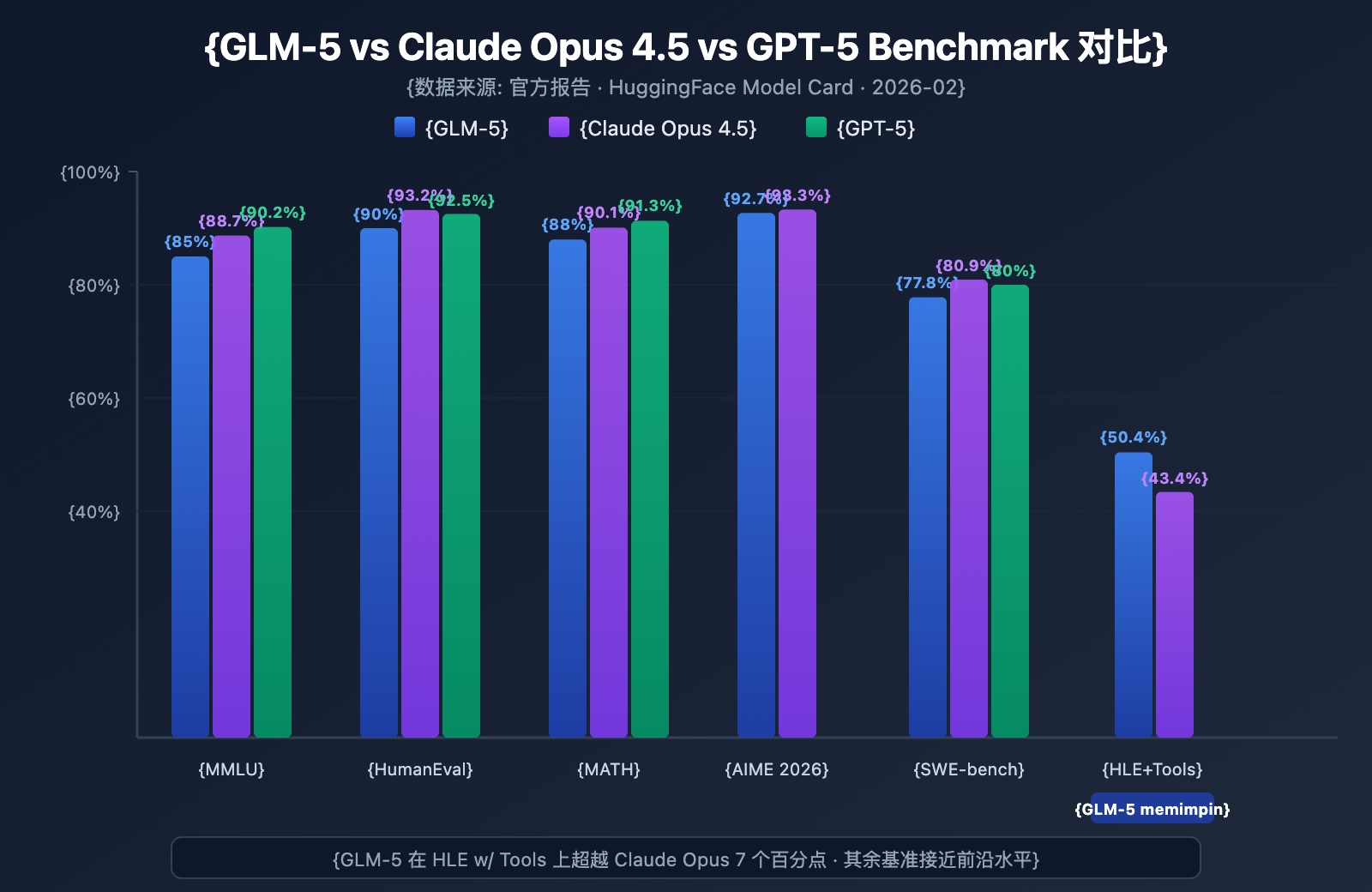
GLM-5 menunjukkan level terkuat di antara model open-source pada berbagai benchmark utama:
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5 | Konten Pengujian |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | 57 Pengetahuan Akademik |
| MMLU Pro | 70.4% | – | – | Multidisiplin Versi Ditingkatkan |
| GPQA | 68.2% | 71.4% | 73.1% | Sains Tingkat Pascasarjana |
| HumanEval | 90.0% | 93.2% | 92.5% | Pemrograman Python |
| MATH | 88.0% | 90.1% | 91.3% | Penalaran Matematika |
| GSM8k | 97.0% | 98.2% | 98.5% | Soal Cerita Matematika |
| AIME 2026 I | 92.7% | 93.3% | – | Kompetisi Matematika |
| SWE-bench | 77.8% | 80.9% | 80.0% | Rekayasa Perangkat Lunak Nyata |
| HLE w/ Tools | 50.4% | 43.4% | – | Penalaran dengan Alat |
| IFEval | 88.0% | – | – | Kepatuhan Instruksi |
| Terminal-Bench | 56.2% | 57.9% | – | Operasi Terminal |
Analisis Performa GLM-5: 4 Keunggulan Utama
Dari data benchmark, ada beberapa poin yang patut diperhatikan:
1. Kemampuan Agent GLM-5: HLE w/ Tools Melampaui Model Tertutup
GLM-5 meraih skor 50,4% pada Humanity's Last Exam (dengan penggunaan alat), melampaui Claude Opus yang sebesar 43,4%, dan hanya kalah tipis dari Kimi K2.5 (51,8%). Ini menunjukkan bahwa dalam skenario Agent—tugas kompleks yang membutuhkan perencanaan, pemanggilan alat, dan penyelesaian iteratif—GLM-5 telah mencapai level model terdepan.
Hasil ini sejalan dengan filosofi desain GLM-5: dari arsitektur hingga post-training, semuanya dioptimalkan secara khusus untuk alur kerja Agent. Bagi pengembang yang ingin membangun sistem AI Agent, GLM-5 menawarkan pilihan open-source dengan rasio performa-biaya yang tinggi.
2. Kemampuan Coding GLM-5: Masuk ke Jajaran Elit
HumanEval 90% dan SWE-bench Verified 77,8% menunjukkan bahwa GLM-5 dalam pembuatan kode dan tugas rekayasa perangkat lunak nyata sudah sangat mendekati level Claude Opus (80,9%) dan GPT-5 (80,0%). Sebagai model open-source, skor SWE-bench 77,8% adalah terobosan penting—ini berarti GLM-5 sudah mampu memahami issue GitHub yang nyata, menemukan lokasi masalah kode, dan mengirimkan perbaikan yang efektif.
3. Penalaran Matematika GLM-5: Mendekati Batas Atas
Pada AIME 2026 I, GLM-5 meraih 92,7%, hanya tertinggal 0,6 poin persentase dari Claude Opus. Skor GSM8k 97% juga menunjukkan bahwa pada masalah matematika tingkat menengah, GLM-5 sudah sangat andal. Skor MATH 88% juga menempatkannya di jajaran teratas.
4. Kontrol Halusinasi GLM-5: Berkurang Drastis
Menurut data resmi, tingkat halusinasi GLM-5 berkurang 56% dibandingkan generasi sebelumnya. Hal ini berkat iterasi post-training yang lebih memadai melalui sistem Slime asynchronous RL. Dalam skenario yang membutuhkan akurasi tinggi seperti ekstraksi informasi, ringkasan dokumen, dan tanya jawab basis pengetahuan, tingkat halusinasi yang lebih rendah langsung diterjemahkan menjadi kualitas output yang lebih andal.
Posisi GLM-5 Dibandingkan Model Open-Source Selevel
Dalam peta persaingan Model Bahasa Besar open-source saat ini, posisi GLM-5 cukup jelas:
| Model | Skala Parameter | Arsitektur | Keunggulan Utama | Lisensi |
|---|---|---|---|---|
| GLM-5 | 744B (40B aktif) | MoE | Agent + Halusinasi Rendah | Apache-2.0 |
| DeepSeek V3 | 671B (37B aktif) | MoE | Rasio Performa-Biaya + Penalaran | MIT |
| Llama 4 Maverick | 400B (17B aktif) | MoE | Multimodal + Ekosistem | Llama License |
| Qwen 3 | 235B | Dense | Multibahasa + Alat | Apache-2.0 |
Keunggulan diferensiasi GLM-5 terutama terlihat dalam tiga aspek: optimasi khusus untuk alur kerja Agent (unggul di HLE w/ Tools), tingkat halusinasi yang sangat rendah (berkurang 56%), serta keamanan rantai pasokan yang dibawa oleh pelatihan dengan daya komputasi domestik. Bagi perusahaan yang perlu menerapkan model open-source terdepan, GLM-5 adalah opsi yang patut diperhatikan secara serius.
GLM-5 定价与成本分析
GLM-5 官方定价
| 计费类型 | Z.ai 官方价格 | OpenRouter 价格 | 说明 |
|---|---|---|---|
| 输入 Token | $1.00/M | $0.80/M | 每百万输入 token |
| 输出 Token | $3.20/M | $2.56/M | 每百万输出 token |
| 缓存输入 | $0.20/M | $0.16/M | 缓存命中时的输入价格 |
| 缓存存储 | 暂时免费 | – | 缓存数据存储费用 |
GLM-5 与竞品价格对比
GLM-5 的定价策略非常有竞争力,特别是与闭源前沿模型相比:
| 模型 | 输入 ($/M) | 输出 ($/M) | 相对 GLM-5 成本 | 模型定位 |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 基准 | 开源旗舰 |
| Claude Opus 4.6 | $5.00 | $25.00 | 约 5-8x | 闭源旗舰 |
| GPT-5 | $1.25 | $10.00 | 约 1.3-3x | 闭源旗舰 |
| DeepSeek V3 | $0.27 | $1.10 | 约 0.3x | 开源性价比 |
| GLM-4.7 | $0.60 | $2.20 | 约 0.6-0.7x | 上代旗舰 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 约 0.07-0.13x | 超低成本 |
从价格看,GLM-5 定位在 GPT-5 和 DeepSeek V3 之间——比大部分闭源前沿模型便宜很多,但比轻量级开源模型略贵。考虑到 744B 的参数规模和开源最强的性能表现,这个定价是合理的。
GLM 全系列产品线与定价
如果 GLM-5 不完全匹配你的场景,智谱还提供了完整的产品线供选择:
| 模型 | 输入 ($/M) | 输出 ($/M) | 适用场景 |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 复杂推理、Agent、长文档 |
| GLM-5-Code | $1.20 | $5.00 | 代码开发专用 |
| GLM-4.7 | $0.60 | $2.20 | 中等复杂度通用任务 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 高频低成本调用 |
| GLM-4.5-Air | $0.20 | $1.10 | 轻量平衡 |
| GLM-4.7/4.5-Flash | 免费 | 免费 | 入门体验和简单任务 |
💰 成本优化: GLM-5 已上线 APIYI apiyi.com,价格与 Z.ai 官方一致。通过平台充值加赠活动,实际使用成本大约可以降到官方价格的 8 折,适合有持续调用需求的团队和开发者。
GLM-5 适用场景与选型建议
GLM-5 适合哪些场景
根据 GLM-5 的技术特点和 benchmark 表现,以下是具体的场景推荐:
强烈推荐的场景:
- Agent 工作流: GLM-5 专为长周期 Agent 任务设计,HLE w/ Tools 50.4% 超越 Claude Opus,适合构建自主规划和工具调用的 Agent 系统
- 代码工程任务: HumanEval 90%、SWE-bench 77.8%,胜任代码生成、Bug 修复、代码审查和架构设计
- 数学与科学推理: AIME 92.7%、MATH 88%,适合数学证明、公式推导和科学计算
- 超长文档分析: 200K 上下文窗口,处理完整代码库、技术文档、法律合同等超长文本
- 低幻觉问答: 幻觉率减少 56%,适合知识库问答、文档摘要等需要高准确性的场景
可以考虑其他方案的场景:
- 多模态任务: GLM-5 本体仅支持文本,需要图像理解请选择 GLM-4.6V 等视觉模型
- 极致低延迟: 744B MoE 模型的推理速度不如小模型,高频低延迟场景建议使用 GLM-4.7-FlashX
- 超低成本批量处理: 大批量文本处理如果对质量要求不高,DeepSeek V3 或 GLM-4.7-FlashX 成本更低
GLM-5 与 GLM-4.7 选型对比
| 对比维度 | GLM-5 | GLM-4.7 | 选型建议 |
|---|---|---|---|
| 参数规模 | 744B (40B 活跃) | 未公开 | GLM-5 更大 |
| 推理能力 | AIME 92.7% | ~85% | 复杂推理选 GLM-5 |
| Agent 能力 | HLE w/ Tools 50.4% | ~38% | Agent 任务选 GLM-5 |
| 编码能力 | HumanEval 90% | ~85% | 代码开发选 GLM-5 |
| 幻觉控制 | 减少 56% | 基准 | 高准确性选 GLM-5 |
| 输入价格 | $1.00/M | $0.60/M | 成本敏感选 GLM-4.7 |
| 输出价格 | $3.20/M | $2.20/M | 成本敏感选 GLM-4.7 |
| 上下文长度 | 200K | 128K+ | 长文档选 GLM-5 |
💡 选择建议: 如果你的项目需要顶级推理能力、Agent 工作流或超长上下文处理,GLM-5 是更好的选择。如果预算有限且任务复杂度适中,GLM-4.7 也是不错的性价比方案。两个模型都可以通过 APIYI apiyi.com 平台调用,方便随时切换测试。
FAQ Pemanggilan API GLM-5
Q1: Apa perbedaan antara GLM-5 dan GLM-5-Code?
GLM-5 adalah model flagship umum (Input $1.00/jt, Output $3.20/jt) yang cocok untuk berbagai tugas teks. GLM-5-Code adalah versi yang dioptimalkan khusus untuk kode (Input $1.20/jt, Output $5.00/jt), dengan pengoptimalan tambahan pada pembuatan kode, debugging, dan tugas rekayasa perangkat lunak. Jika skenario utama Anda adalah pengembangan kode, GLM-5-Code sangat layak dicoba. Kedua model ini mendukung pemanggilan melalui antarmuka terpadu yang kompatibel dengan OpenAI.
Q2: Apakah mode Thinking pada GLM-5 memengaruhi kecepatan output?
Ya. Dalam mode Thinking, GLM-5 akan menghasilkan rantai penalaran (reasoning chain) internal terlebih dahulu sebelum memberikan jawaban akhir, sehingga latensi token pertama (TTFT) akan meningkat. Untuk pertanyaan sederhana, disarankan untuk mematikan mode Thinking guna mendapatkan respons yang lebih cepat. Untuk masalah matematika, pemrograman, dan logika yang kompleks, disarankan untuk mengaktifkannya; meskipun sedikit lebih lambat, tingkat akurasinya akan meningkat secara signifikan.
Q3: Apa saja kode yang perlu diubah saat migrasi dari GPT-4 atau Claude ke GLM-5?
Migrasinya sangat mudah, Anda hanya perlu mengubah dua parameter:
- Ubah
base_urlmenjadi alamat antarmuka APIYI:https://api.apiyi.com/v1 - Ubah parameter
modelmenjadi"glm-5"
GLM-5 sepenuhnya kompatibel dengan format antarmuka chat.completions dari OpenAI SDK, termasuk peran system/user/assistant, output streaming, Function Calling, dan fitur lainnya. Melalui platform perantara API yang terpadu, Anda juga dapat beralih antar model dari berbagai vendor di bawah satu API Key yang sama, sangat memudahkan untuk pengujian A/B.
Q4: Apakah GLM-5 mendukung input gambar?
Tidak. GLM-5 sendiri adalah model teks murni dan tidak mendukung input gambar, audio, atau video. Jika Anda membutuhkan kemampuan pemahaman gambar, Anda dapat menggunakan model varian visi dari Zhipu seperti GLM-4.6V atau GLM-4.5V.
Q5: Bagaimana cara menggunakan fitur Context Caching pada GLM-5?
GLM-5 mendukung Context Caching (Penyimpanan Konteks), di mana harga input yang tersimpan di cache hanya $0.20/jt, yaitu 1/5 dari harga input normal. Dalam percakapan panjang atau skenario yang memerlukan pemrosesan berulang pada awalan (prefix) yang sama, fitur cache ini dapat mengurangi biaya secara signifikan. Saat ini, penyimpanan cache masih gratis untuk sementara. Dalam percakapan multi-putaran, sistem akan secara otomatis mengenali dan menyimpan awalan konteks yang berulang ke dalam cache.
Q6: Berapa panjang output maksimal GLM-5?
GLM-5 mendukung panjang output maksimal hingga 128.000 token. Untuk sebagian besar skenario, nilai default 4096 token sudah cukup. Jika Anda perlu menghasilkan teks panjang (seperti dokumen teknis lengkap atau blok kode yang besar), Anda dapat menyesuaikannya melalui parameter max_tokens. Perlu diperhatikan bahwa semakin panjang outputnya, konsumsi token dan waktu tunggu juga akan meningkat secara proporsional.
Praktik Terbaik Pemanggilan API GLM-5
Saat menggunakan GLM-5 dalam praktik nyata, beberapa pengalaman berikut dapat membantu Anda mendapatkan hasil yang lebih baik:
Optimasi System Prompt GLM-5
GLM-5 memberikan respons yang sangat baik terhadap system prompt. Merancang system prompt dengan bijak dapat meningkatkan kualitas output secara signifikan:
# Rekomendasi: Definisi peran yang jelas + persyaratan format output
messages = [
{
"role": "system",
"content": """Anda adalah seorang arsitek sistem terdistribusi senior.
Harap ikuti aturan berikut:
1. Jawaban harus terstruktur, gunakan format Markdown
2. Berikan solusi teknis yang spesifik, bukan sekadar penjelasan umum
3. Jika melibatkan kode, berikan contoh yang dapat dijalankan
4. Cantumkan risiko potensial dan hal-hal yang perlu diperhatikan di bagian yang sesuai"""
},
{
"role": "user",
"content": "Rancang sistem message queue yang mendukung jutaan koneksi bersamaan (concurrent)"
}
]
Panduan Penyetelan Temperature GLM-5
Tugas yang berbeda memiliki sensitivitas yang berbeda terhadap parameter temperature. Berikut adalah saran berdasarkan pengujian:
- temperature 0.1-0.3: Untuk tugas yang membutuhkan output presisi seperti pembuatan kode, ekstraksi data, dan konversi format.
- temperature 0.5-0.7: Untuk tugas yang membutuhkan stabilitas namun tetap fleksibel dalam ekspresi, seperti dokumen teknis, tanya jawab, dan ringkasan.
- temperature 0.8-1.0: Untuk tugas yang membutuhkan keberagaman seperti penulisan kreatif dan brainstorming.
- temperature 1.0 (Mode Thinking): Untuk tugas penalaran mendalam seperti penalaran matematika dan pemrograman kompleks.
Tips Penanganan Konteks Panjang GLM-5
GLM-5 mendukung jendela konteks hingga 200K token, namun dalam penggunaan praktis perlu memperhatikan hal berikut:
- Prioritaskan Informasi Penting: Letakkan konteks yang paling krusial di awal petunjuk (prompt), bukan di akhir.
- Pemrosesan Bertahap: Untuk dokumen yang melebihi 100K token, disarankan untuk memprosesnya dalam beberapa bagian kemudian menggabungkannya untuk mendapatkan output yang lebih stabil.
- Manfaatkan Cache: Dalam percakapan multi-putaran, konten awalan yang sama akan otomatis disimpan di cache, dengan harga input cache hanya $0.20/jt.
- Kontrol Panjang Output: Saat memasukkan konteks yang panjang, atur
max_tokensdengan tepat untuk menghindari output yang terlalu panjang yang dapat menambah biaya yang tidak perlu.
Referensi Deployment Lokal GLM-5
Jika Anda perlu men-deploy GLM-5 di infrastruktur sendiri, berikut adalah metode deployment utamanya:
| Metode Deployment | Hardware Rekomendasi | Presisi | Fitur |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | Framework inferensi mainstream, mendukung speculative decoding |
| SGLang | 8x H100/B200 | FP8 | Inferensi performa tinggi, optimasi GPU Blackwell |
| xLLM | Huawei Ascend NPU | BF16/FP8 | Adaptasi daya komputasi domestik |
| KTransformers | GPU Kelas Konsumen | Kuantisasi | Inferensi akselerasi GPU |
| Ollama | Hardware Kelas Konsumen | Kuantisasi | Pengalaman lokal termudah |
GLM-5 menyediakan format bobot (weight) BF16 full precision dan kuantisasi FP8, yang bisa diunduh dari HuggingFace (huggingface.co/zai-org/GLM-5) atau ModelScope. Versi kuantisasi FP8 secara signifikan mengurangi kebutuhan VRAM sambil tetap mempertahankan sebagian besar performanya.
Konfigurasi kunci yang diperlukan untuk men-deploy GLM-5:
- Tensor Parallel: 8 jalur (tensor-parallel-size 8)
- Utilisasi VRAM: Disarankan diatur ke 0.85
- Parser Pemanggilan Alat (Tool Call): glm47
- Parser Inferensi: glm45
- Speculative Decoding: Mendukung metode MTP dan EAGLE
Bagi sebagian besar pengembang, memanggil melalui API adalah cara yang paling efisien karena menghemat biaya operasional deployment, sehingga Anda bisa fokus pada pengembangan aplikasi. Untuk skenario yang membutuhkan deployment privat, silakan merujuk ke dokumentasi resmi:
github.com/zai-org/GLM-5
Ringkasan Pemanggilan API GLM-5
Cek Cepat Kemampuan Inti GLM-5
| Dimensi Kemampuan | Performa GLM-5 | Skenario Penggunaan |
|---|---|---|
| Penalaran | AIME 92.7%, MATH 88% | Pembuktian matematika, penalaran ilmiah, analisis logika |
| Pengodean | HumanEval 90%, SWE-bench 77.8% | Pembuatan kode, perbaikan bug, desain arsitektur |
| Agent | HLE w/ Tools 50.4% | Pemanggilan alat, perencanaan tugas, eksekusi mandiri |
| Pengetahuan | MMLU 85%, GPQA 68.2% | Tanya jawab subjek, konsultasi teknis, ekstraksi pengetahuan |
| Instruksi | IFEval 88% | Output terformat, pembuatan terstruktur, kepatuhan aturan |
| Akurasi | Halusinasi berkurang 56% | Ringkasan dokumen, pemeriksaan fakta, ekstraksi informasi |
Nilai Ekosistem Open Source GLM-5
GLM-5 menggunakan lisensi Apache-2.0, yang berarti:
- Kebebasan Komersial: Perusahaan dapat menggunakan, memodifikasi, dan mendistribusikan secara gratis tanpa biaya lisensi.
- Fine-tuning Kustom: Anda bisa melakukan fine-tuning domain berdasarkan GLM-5 untuk membangun model khusus industri.
- Deployment Privat: Data sensitif tidak keluar dari jaringan internal, memenuhi persyaratan kepatuhan di sektor keuangan, medis, dan pemerintahan.
- Ekosistem Komunitas: Sudah ada 11+ varian kuantisasi dan 7+ versi fine-tuning di HuggingFace, ekosistem terus berkembang.
Sebagai model unggulan terbaru dari Zhipu AI, GLM-5 menetapkan standar baru di bidang Model Bahasa Besar open source:
- Arsitektur MoE 744B: Sistem 256 pakar (experts), mengaktifkan 40B parameter setiap inferensi, mencapai keseimbangan luar biasa antara kapasitas model dan efisiensi inferensi.
- Agent Open Source Terkuat: Skor HLE w/ Tools 50.4% melampaui Claude Opus, dirancang khusus untuk alur kerja Agent siklus panjang.
- Pelatihan dengan Daya Komputasi Domestik: Dilatih menggunakan 100.000 chip Huawei Ascend, membuktikan kemampuan pelatihan model mutakhir dengan tumpukan daya komputasi domestik.
- Hemat Biaya: Input $1/M, Output $3.2/M, jauh lebih rendah dibanding model closed-source di kelas yang sama, komunitas open source bebas untuk men-deploy dan melakukan fine-tuning.
- Konteks Super Panjang 200K: Mendukung pemrosesan basis kode lengkap dan dokumen teknis besar sekaligus, dengan output maksimal 128K token.
- Halusinasi Rendah 56%: Post-training Slime asynchronous RL secara signifikan meningkatkan akurasi faktual.
Kami merekomendasikan untuk mencoba berbagai kemampuan GLM-5 dengan cepat melalui APIYI apiyi.com. Harga platform sama dengan harga resmi, dan tersedia promo tambahan saldo saat top-up yang memberikan diskon sekitar 20%.
Artikel ini ditulis oleh tim teknis APIYI Team. Untuk tutorial penggunaan model AI lainnya, silakan ikuti Pusat Bantuan APIYI apiyi.com.