Note de l'auteur : Le dernier modèle de la série mini d'OpenAI, gpt-5.4-mini, est désormais disponible via API. Avec un score de 54,4 % sur SWE-Bench Pro, il surpasse les 45,7 % du GPT-5 mini. Cet article analyse en profondeur son saut de performance, la réduction de 90 % sur les entrées en cache, et les arbitrages à faire entre les versions 4o-mini, 5-mini et cette nouvelle mouture.
Si vous utilisez encore gpt-4o-mini ou gpt-5-mini, vous avez peut-être remarqué qu'OpenAI a lancé le 17 mars 2026 ce qu'ils appellent "notre modèle mini le plus puissant à ce jour" : le gpt-5.4-mini. Il atteint 54,4 % sur SWE-Bench Pro (contre 45,7 % pour le GPT-5 mini), 60,0 % sur Terminal-Bench 2.0, et 72,1 % sur OSWorld-Verified pour les tâches de Computer Use, le tout avec une vitesse de réponse deux fois plus rapide que la génération précédente.
Cela ressemble à une mise à jour mineure, mais l'intention derrière est bien plus ambitieuse. OpenAI positionne officiellement le gpt-5.4-mini comme un modèle "optimisé pour la programmation, le Computer Use et les sous-agents" — c'est la première fois que la série mini démocratise des capacités agentiques à un tarif d'entrée de gamme. Cet article décortique ce qu'est réellement le GPT-5.4 mini, ses améliorations par rapport aux versions 4o-mini et 5-mini, et ce que cela implique concrètement pour votre travail.
Valeur ajoutée : Une analyse complète de la solution d'intégration du GPT-5.4 mini sous quatre angles : saut de performance, structure tarifaire, optimisation du cache et choix stratégiques par rapport aux anciennes séries mini, avec des critères de mise à niveau clairs.

Points clés de l'API GPT-5.4 mini
| Point clé | Description | Valeur |
|---|---|---|
| Saut de performance | SWE-Bench Pro 54,4 % vs GPT-5 mini 45,7 % | Amélioration de 19 % du taux de réussite en codage |
| Contexte long 400K | 400 000 tokens en entrée + 128 000 en sortie | Traitement complet de bases de code / longs documents |
| 90 % de remise cache | Entrée en cache à seulement 0,075 $ / 1M | Baisse drastique des coûts pour les contextes fréquents |
| Computer Use | OSWorld-Verified 72,1 % | Support complet de l'automatisation de bureau pour la série mini |
| Ouverture par défaut | Disponible directement via APIYI | Utilisation immédiate sans demande d'accès |
Différences majeures entre le GPT-5.4 mini et la génération précédente
Le GPT-5.4 mini n'est pas qu'une simple "version moins chère". OpenAI a apporté des améliorations substantielles sur trois axes :
Premièrement, l'orchestration par sous-agents arrive pour la première fois dans la gamme mini. Auparavant, il était presque impossible pour un modèle mini de coordonner de manière fiable plusieurs sous-tâches ou de gérer des chaînes d'appels d'outils ; ils perdaient généralement le fil ou ignoraient les instructions après 3 ou 4 étapes. Grâce à un mécanisme de jetons de raisonnement renforcé et à un entraînement au suivi d'instructions, le GPT-5.4 mini atteint une fiabilité d'environ 90 % par rapport à la version standard GPT-5.4 dans les scénarios multi-agents, pour seulement 1/6 du coût.
Deuxièmement, le support complet du Computer Use. Le GPT-5.4 mini est le premier modèle de la série mini d'OpenAI à atteindre plus de 70 % sur OSWorld-Verified. Cela signifie que vous pouvez déployer des agents d'automatisation de bureau complets au tarif mini pour effectuer des clics, remplir des formulaires ou manipuler des fichiers.
Troisièmement, une vitesse de réponse multipliée par 2. Tout en augmentant ses capacités, le GPT-5.4 mini est deux fois plus rapide que le GPT-5 mini. Pour les scénarios à haut débit (service client, traitement par lots), cela représente une économie directe.

Démarrage rapide avec l'API GPT-5.4 mini
Exemple Python minimaliste (remplacement de l'ancien modèle mini)
Si vous utilisiez déjà gpt-4o-mini ou gpt-5-mini, il suffit de modifier le paramètre model pour passer à gpt-5.4-mini. Le reste du code demeure inchangé :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini", # Seule cette ligne change
messages=[
{"role": "user", "content": "Implémente en Python un cache concurrent supportant l'éviction LRU"}
]
)
print(response.choices[0].message.content)
Exemple cURL minimaliste
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer VOTRE_CLE_API" \
-d '{
"model": "gpt-5.4-mini",
"messages": [
{"role": "user", "content": "Résume les points clés de ce long document"}
]
}'
Paradigme d'invocation "Computer Use" (supporté pour la première fois sur la série mini)
# Activer l'outil Computer Use
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{
"role": "user",
"content": "Aide-moi à ouvrir le navigateur, cherche 'Documentation API OpenAI', et clique sur le premier résultat"
}],
tools=[{
"type": "computer_use",
"config": {
"screen_width": 1920,
"screen_height": 1080
}
}]
)
# Le modèle renvoie des instructions structurées (click/type/scroll, etc.)
for action in response.choices[0].message.tool_calls:
print(f"Action: {action.function.name}, Paramètres: {action.function.arguments}")
Voir le code complet d’invocation en environnement de production (avec suivi des hits de cache et statistiques de coût)
import openai
from typing import List, Dict
# Tarifs GPT-5.4 mini (par 1M de jetons)
PRICE_INPUT = 0.75
PRICE_INPUT_CACHED = 0.075 # Prix avec hit de cache (90% de réduction)
PRICE_OUTPUT = 4.50
def call_gpt54_mini(
messages: List[Dict],
api_key: str,
max_tokens: int = 4096
) -> Dict:
"""
Invocation de niveau production pour GPT-5.4 mini, avec suivi du taux de hit de cache
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=messages,
max_tokens=max_tokens
)
usage = response.usage
input_tokens = usage.prompt_tokens
output_tokens = usage.completion_tokens
# Jetons en cache (dépend de la version du SDK)
cached_tokens = getattr(usage, 'prompt_tokens_details', {}).get('cached_tokens', 0)
regular_input = input_tokens - cached_tokens
# Facturation segmentée
input_cost = (
regular_input / 1_000_000 * PRICE_INPUT +
cached_tokens / 1_000_000 * PRICE_INPUT_CACHED
)
output_cost = output_tokens / 1_000_000 * PRICE_OUTPUT
total_cost = input_cost + output_cost
cache_rate = cached_tokens / max(input_tokens, 1) * 100
print(f"📊 Entrée: {input_tokens:,} | Hit cache: {cached_tokens:,} ({cache_rate:.1f}%)")
print(f"📊 Sortie: {output_tokens:,} jetons")
print(f"💰 Coût de l'opération: ${total_cost:.4f}")
print(f"💰 Économie via cache: ${(cached_tokens / 1_000_000 * (PRICE_INPUT - PRICE_INPUT_CACHED)):.4f}")
return {
"content": response.choices[0].message.content,
"tokens": {
"input": input_tokens,
"cached": cached_tokens,
"output": output_tokens
},
"cost_usd": total_cost,
"cache_hit_rate": cache_rate
}
except openai.RateLimitError:
return {"error": "Limite de débit atteinte, réessayez plus tard"}
except openai.APIError as e:
return {"error": f"Erreur API: {str(e)}"}
# Exemple d'utilisation
result = call_gpt54_mini(
messages=[
{"role": "system", "content": "Tu es un ingénieur Python expérimenté"},
{"role": "user", "content": "Aide-moi à examiner les problèmes de sécurité concurrentielle de ce code..."}
],
api_key="VOTRE_CLE_API"
)
print(result["content"])
🎯 Conseil de démarrage rapide : GPT-5.4 mini est déjà entièrement ouvert sur le groupe par défaut chez APIYI, les nouveaux utilisateurs peuvent l'appeler sans demande préalable. Nous recommandons de passer par la plateforme APIYI apiyi.com : 100 $ rechargés offrent 10 % de bonus, ce qui équivaut à environ 15 % de réduction par rapport au site officiel, avec une connexion directe sans VPN et une compatibilité totale avec le SDK OpenAI.
Détails des tarifs de l'API GPT-5.4 mini
Structure tarifaire officielle
La tarification de GPT-5.4 mini est plus élevée que celle de l'ancienne série mini, mais le mécanisme de cache permet de réduire considérablement les coûts réels :
| Type de facturation | Prix (par 1M de jetons) | Remarques |
|---|---|---|
| Entrée | 0,75 $ | Tarif standard |
| Entrée en cache | 0,075 $ | 90 % de réduction, réduction massive des coûts |
| Sortie | 4,50 $ | Inclut les jetons de raisonnement |
| Entrée Batch API | 0,75 $ | Identique au tarif standard |
| Point de terminaison de résidence des données | +10 % | Scénarios de conformité des données |
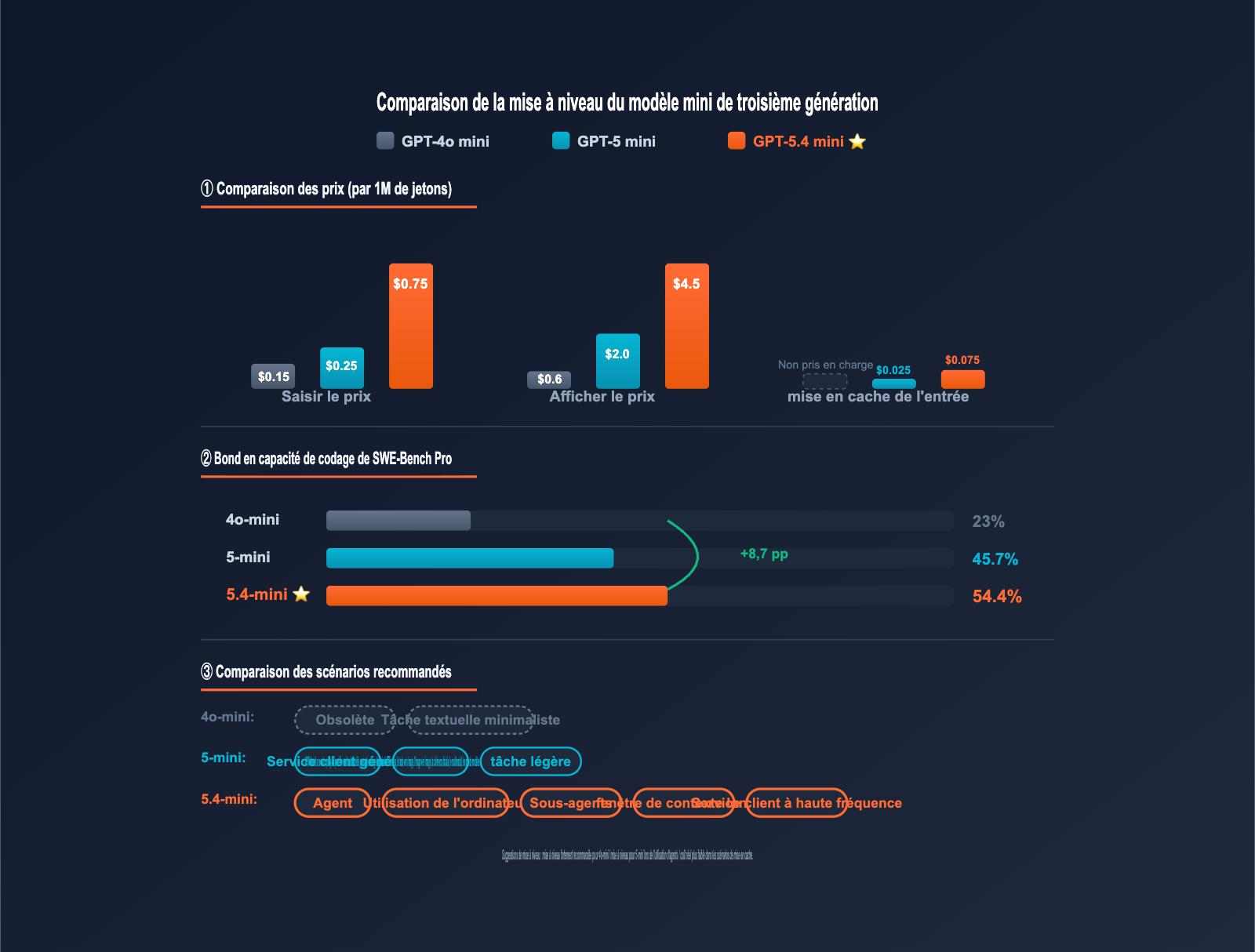
Comparaison des prix de la série mini (3 générations)
| Modèle | Prix entrée | Entrée cache | Prix sortie | Fenêtre de contexte | Sortie max |
|---|---|---|---|---|---|
| GPT-4o mini | 0,15 $ | Non supporté | 0,60 $ | 128K | 16K |
| GPT-5 mini | 0,25 $ | 0,025 $ | 2,00 $ | 400K | 128K |
| GPT-5.4 mini | 0,75 $ | 0,075 $ | 4,50 $ | 400K | 128K |
⚠️ Observation importante : Le prix standard de GPT-5.4 mini est 5 fois supérieur à celui de GPT-4o mini et 3 fois supérieur à celui de GPT-5 mini. Cependant, notez deux faits clés : 1) Une fois le cache activé, le coût unitaire peut descendre jusqu'à 0,0075 $/1M (dans certains scénarios à haute fréquence), et 2) le saut de performance permet souvent d'éviter les débogages multi-tours, réduisant ainsi le nombre total d'appels.
Estimation des coûts en scénarios de hit de cache
La réduction de 90 % sur le cache de GPT-5.4 mini est la fonctionnalité la plus sous-estimée de cette mise à jour :
| Scénario | Jetons d'entrée | Taux de hit cache | Coût unitaire réel |
|---|---|---|---|
| Service client haute fréquence (réutilisation du prompt système) | 5K | 80 % | 0,0046 $ |
| Assistant de code (réutilisation du contexte) | 50K | 70 % | 0,034 $ |
| Q&A sur longs documents (réutilisation de document) | 200K | 90 % | 0,030 $ |
| Orchestration Subagent (instructions partagées) | 30K | 85 % | 0,0162 $ |
💰 Conseil d'optimisation du cache : Le mécanisme de cache de GPT-5.4 mini est le plus efficace pour les scénarios avec long prompt système + contexte répétitif. Pour le service client, les assistants de code et les questions-réponses sur longs documents, le coût réel peut être inférieur à celui de GPT-5 mini. Vous pouvez réduire davantage votre facture grâce au bonus de 10 % sur les recharges via APIYI apiyi.com.
Bond technique : montée en puissance de l'API GPT-5.4 mini
Comparaison des benchmarks
| Dimension d'évaluation | GPT-4o mini | GPT-5 mini | GPT-5.4 mini | Progression |
|---|---|---|---|---|
| SWE-Bench Pro (codage) | ~23% | 45,7% | 54,4% | +8,7 pp |
| Terminal-Bench 2.0 | ~30% | ~50% | 60,0% | +10 pp |
| OSWorld-Verified (Computer Use) | Non supporté | ~58% | 72,1% | +14 pp |
| Vitesse de réponse | Référence | Référence | 2x plus rapide | Doublée |
Analyse de la montée en puissance
SWE-Bench Pro 54,4% : C'est la donnée la plus impressionnante pour le GPT-5.4 mini. Avec 54,4%, il se rapproche des 57,7% de la version standard de GPT-5.4, tout en coûtant six fois moins cher. Pour la résolution de tickets GitHub réels ou la refactorisation de bases de code, le modèle "mini" est désormais un choix très fiable.
Terminal-Bench 60,0% : Cela signifie que le modèle mini peut accomplir plus de 60 % des tâches liées à l'exécution de commandes en terminal, au débogage et aux flux de travail automatisés. En le combinant avec une orchestration de sous-agents, vous pouvez concevoir des applications robustes comme des bots de revue de code ou des pipelines CI/CD automatisés.
OSWorld 72,1% : Il s'agit d'une percée historique pour la gamme mini en matière de "Computer Use". Vous pouvez désormais déployer des agents d'automatisation de bureau à un coût abordable pour gérer des formulaires, des clics et des manipulations de fichiers.
Comparaison : GPT-5.4 mini vs modèles équivalents
| Modèle | Entrée / Sortie | Fenêtre de contexte | Capacité de codage | Computer Use | Scénarios recommandés |
|---|---|---|---|---|---|
| GPT-4o mini | 0,15 $ / 0,60 $ | 128K | Faible | Non supporté | Obsolète, tâches simples |
| GPT-5 mini | 0,25 $ / 2,00 $ | 400K | Moyen | Support partiel | Service client, tâches légères |
| GPT-5.4 mini | 0,75 $ / 4,50 $ | 400K | Fort | Support complet | Agent / Computer Use / Contexte long |
| GPT-5.4 Standard | 5,00 $ / 30,00 $ | 1M | Excellent | Excellent | Raisonnement complexe, décisions critiques |
| Claude Haiku 4.5 | 0,80 $ / 4,00 $ | 200K | Fort | Non supporté | Rédaction / Style littéraire |
Conseils pour votre décision de mise à niveau
4o-mini → 5.4-mini : Le GPT-4o mini conserve un avantage tarifaire sur les tâches textuelles basiques. Cependant, ses capacités sont désormais largement dépassées. Dès que votre application nécessite du raisonnement, du codage ou une longue fenêtre de contexte, la mise à niveau vers le 5.4-mini est largement justifiée. Même avec un coût unitaire multiplié par 5, le gain en qualité et la réduction du nombre d'appels nécessaires rendent l'opération plus rentable.
5-mini → 5.4-mini : Le GPT-5 mini reste compétent pour le service client ou la traduction. Mais si vous avez besoin de Computer Use, d'orchestration de sous-agents ou de flux de travail d'agents complexes, le 5.4-mini est indispensable. De plus, bien que la remise sur cache reste à 90 %, la valeur absolue est plus avantageuse sur le long terme.
5.4-mini → 5.4 Standard : Le GPT-5.4 mini offre des performances similaires sur 80 % des tâches courantes pour seulement 1/6 du prix. Ne basculez vers la version Standard que si la tâche exige un raisonnement de haut niveau (preuves mathématiques, agents complexes tournant sur 20 heures, etc.).
📊 Conseil de migration : Via APIYI (apiyi.com), vous pouvez comparer en toute transparence les performances réelles des modèles 4o-mini, 5-mini, 5.4-mini et 5.4 Standard avec la même clé API, simplement en modifiant le paramètre
model. Cette approche unifiée est idéale pour les équipes souhaitant effectuer une migration progressive ou des tests A/B.
Cas d'usage pour l'API GPT-5.4 mini
La combinaison "haute capacité + optimisation du cache + Computer Use + sous-agents" du GPT-5.4 mini est particulièrement adaptée aux scénarios suivants :
- Service client conversationnel à haut débit : taux de succès du cache élevé, temps de réponse rapide et profondeur de raisonnement suffisante pour traiter des problèmes complexes.
- Génération de contenu à grande échelle : résumé, traduction et réécriture par lots, avec une fenêtre de contexte de 400K permettant de traiter des documents entiers en une seule fois.
- Collaboration multi-agents (Subagents) : pour la première fois, une orchestration fiable des sous-tâches est accessible dans la gamme de prix "mini".
- Agent d'automatisation de bureau : avec un score de 72,1 % sur OSWorld, il rend possibles les manipulations de navigateurs, de formulaires et de fichiers.
- Auto-complétion et revue de code légère : avec 54,4 % sur SWE-Bench Pro, ses performances approchent celles de la version standard, idéal pour une intégration IDE.
- Traitement de documents par lots : combiné à l'API Batch et au cache, il offre un avantage de coût majeur pour le traitement de dizaines de milliers de documents.
- Outils de tutorat éducatif : l'amélioration des jetons de raisonnement permet une résolution de problèmes et une assistance plus fiables.
🎯 Décision stratégique : Si votre application dépasse les 10 000 appels par jour, avec un taux de succès du cache supérieur à 50 %, et que vous avez besoin de capacités de raisonnement ou d'outils, le GPT-5.4 mini est le modèle "mini" le plus pertinent en 2026. Accessible directement via APIYI (apiyi.com), sans aucune demande préalable requise pour le groupe par défaut.
Instructions d'intégration de GPT-5.4 mini sur APIYI
Stratégie d'accès par groupe par défaut
La plateforme APIYI adopte pour GPT-5.4 mini une stratégie d'accès identique à celle de Grok 4.3, mais différente de celle de GPT-5.5 Pro :
- ✅ Groupe Default (par défaut) : Ouvert à tous, accessible dès l'inscription.
- ✅ Groupe SVIP (avancé) : Ouvert à tous, sans aucune restriction.
- ✅ Synchronisation des remises sur cache : Le tarif de 0,075 $ / 1M de jetons en cache est pleinement appliqué.
Pourquoi GPT-5.4 mini est-il ouvert à tous les groupes alors que GPT-5.5 Pro est réservé aux SVIP ? La raison principale repose sur l'évaluation des risques par invocation :
- GPT-5.4 mini : Le coût par invocation est généralement de quelques centimes, l'ouverture à tous les groupes ne présente aucun risque.
- GPT-5.5 Pro : Le coût par invocation peut atteindre plusieurs dollars, nécessitant la protection du groupe SVIP pour éviter toute erreur de manipulation par les nouveaux utilisateurs.
Cette gestion basée sur le niveau de risque permet à la gamme mini de rester accessible à tous les développeurs, tout en offrant une protection pour les modèles à haute valeur ajoutée.
Comparaison des coûts : APIYI vs Site officiel
| Élément | Site officiel OpenAI | APIYI apiyi.com |
|---|---|---|
| Prix de base | 0,75 $ / 4,50 $ par 1M | 0,75 $ / 4,50 $ par 1M (identique) |
| Remise sur cache | 0,075 $ / 1M (90%) | 0,075 $ / 1M (synchronisation totale) |
| Bonus de recharge | Aucun | 100 $ rechargés = 10 $ offerts (10%) |
| Coût réel | 100 % du prix standard | Env. 90 % du prix standard (env. -15%) |
| Accès depuis la Chine | VPN requis | Accès direct, sans VPN |
| Moyens de paiement | Carte bancaire internationale | CNY, Alipay, WeChat Pay |
| Compatibilité SDK | Natif OpenAI | Entièrement compatible SDK OpenAI |
| Restrictions de groupe | Aucune | Default + SVIP ouverts à tous |
💰 Optimisation des coûts : En passant par APIYI apiyi.com pour GPT-5.4 mini, le bonus de 10 % pour 100 $ rechargés équivaut à une réduction de 15 % par rapport au site officiel, avec une synchronisation totale des remises sur cache. Pour les applications à fort volume d'appels et à taux de succès de cache élevé, le coût global peut être inférieur de plus de 20 % par rapport au site officiel d'OpenAI.
FAQ – Questions fréquentes
Q1 : Qu’est-ce que GPT-5.4 mini ? Quelles sont les différences majeures avec GPT-5 mini et GPT-4o mini ?
GPT-5.4 mini est la nouvelle génération de modèles mini lancée par OpenAI le 17/03/2026, positionnée comme "notre modèle mini le plus puissant à ce jour". Différences clés : 1) Score SWE-Bench Pro de 54,4 %, surpassant nettement les 45,7 % de GPT-5 mini et les 23 % de 4o-mini ; 2) Support complet et inédit du Computer Use (72,1 % sur OSWorld) ; 3) Capacités d'orchestration de sous-agents accessibles au tarif mini ; 4) Vitesse de réponse 2x plus rapide que le 5 mini. Le prix est cependant passé à 0,75 $/4,50 $, coût partiellement compensé par le cache.
Q2 : J’utilise actuellement gpt-4o-mini / gpt-5-mini, est-ce que ça vaut le coup de passer au 5.4-mini ?
Pour les utilisateurs de 4o-mini, la mise à niveau est fortement recommandée : l'écart de performance est devenu trop important. Même avec un prix unitaire multiplié par 5, la qualité globale et la réduction des itérations de débogage rendent l'opération plus rentable.
Pour les utilisateurs de 5-mini, cela dépend de l'usage :
- ✅ Recommandé : Pour les applications impliquant le Computer Use, les sous-agents, des chaînes d'outils complexes ou une longue fenêtre de contexte (>200K).
- ⏸️ À conserver : Pour les FAQ de service client simples, la traduction légère ou la génération de texte pur, où le 5-mini suffit.
Bonne pratique : effectuez un test A/B avec la même clé API sur APIYI apiyi.com pour voir ce qui est le plus rentable.
Q3 : Comment activer la remise sur cache de 0,075 $/1M pour GPT-5.4 mini ?
Le mécanisme de cache d'OpenAI est automatique, aucun paramètre supplémentaire n'est requis. Lorsque le préfixe de votre invite (généralement le system prompt + le contexte partagé) correspond aux requêtes des 5 à 10 dernières minutes, le cache est automatiquement utilisé, bénéficiant d'une remise de 90 % (0,075 $/1M).
Conseils d'optimisation :
- Placez le system prompt au début du tableau
messages. - Placez le contexte partagé (ex: base de connaissances, résumé de document) après le system prompt.
- Placez la requête utilisateur réelle à la fin.
- Maintenez une fréquence d'appel élevée (le cache expire après >5 minutes).
Lors d'un appel via la plateforme APIYI apiyi.com, la remise sur cache est parfaitement synchronisée avec le site officiel, sans configuration supplémentaire.
Q4 : Quand utiliser GPT-5.4 mini plutôt que la version standard de GPT-5.4 ?
Scénarios privilégiant le modèle mini :
- Haut débit (>10K appels/jour).
- Taux de succès de cache > 50 %.
- Tâches de type SWE-Bench / Terminal-Bench.
- Automatisation via Computer Use.
- Environnements de production sensibles aux coûts.
Scénarios privilégiant la version standard :
- Preuves mathématiques de niveau FrontierMath.
- Agents complexes fonctionnant sur de longues durées (20h+).
- Tâches à haut risque (lecture approfondie de contrats juridiques, diagnostics médicaux).
- Décisions critiques où la valeur d'un seul appel dépasse 0,10 $.
Principe simple : 80 % des tâches sont couvertes par le modèle mini ; ne passez à la version standard que pour les raisonnements extrêmement complexes.
Q5 : Comment appeler GPT-5.4 mini via APIYI ? Quelles modifications de code sont nécessaires ?
APIYI est entièrement compatible avec le SDK OpenAI, trois étapes suffisent :
- Visitez APIYI apiyi.com pour créer un compte (aucune demande nécessaire, le groupe Default est directement disponible).
- Obtenez votre clé API.
- Modifiez le
base_urlde votre code enhttps://vip.apiyi.com/v1et définissez le modèle surgpt-5.4-mini.
client = openai.OpenAI(
api_key="VOTRE_CLE",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[...]
)
Le bonus de 10 % pour 100 $ rechargés équivaut à une réduction d'environ 15 % par rapport au site officiel, avec une synchronisation totale des remises sur cache.
Q6 : GPT-5.4 mini prend-il en charge le réglage fin (Fine-tuning) ?
Non. C'est l'une des principales limitations actuelles de GPT-5.4 mini. Si votre application nécessite impérativement un réglage fin, vous devez choisir :
- GPT-5 mini (supporte le réglage fin, capacités légèrement inférieures).
- GPT-4o mini (supporte le réglage fin, capacités plus faibles).
- GPT-5.4 standard (supporte le réglage fin, prix 6x supérieur).
Alternative : L'utilisation combinée des jetons de raisonnement (Reasoning Tokens), du Function Calling et du mécanisme de cache de GPT-5.4 mini permet souvent d'obtenir d'excellents résultats sans réglage fin.
Q7 : Comment appeler la fonction Computer Use de GPT-5.4 mini ?
Activez-la via le paramètre tools :
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": "Aide-moi à ouvrir une page web et à chercher..."}],
tools=[{
"type": "computer_use",
"config": {"screen_width": 1920, "screen_height": 1080}
}]
)
Le modèle renverra des instructions d'action structurées (clic/saisie/défilement/capture d'écran) ; vous devez implémenter ces actions côté client et renvoyer les résultats au modèle pour poursuivre le raisonnement. Un score de 72,1 % sur OSWorld signifie que la plupart des tâches de bureau peuvent être automatisées.
Q8 : Quelles sont les limitations connues de GPT-5.4 mini ?
Les principales limitations sont :
- Pas de réglage fin (Fine-tuning) : Impossible d'utiliser des jeux de données personnalisés.
- Pas de sortie d'image : Sortie texte uniquement, impossible de générer des images.
- Prix plus élevé que les anciens modèles mini : Le prix standard est 5 fois supérieur à celui du 4o-mini, nécessite une optimisation via le cache.
- Facturation des jetons de raisonnement : Les coûts de sortie pour les tâches complexes peuvent dépasser les attentes.
- Résidence des données régionales +10 % : Frais supplémentaires pour les scénarios de conformité.
Pour les scénarios extrêmement sensibles à la latence (réponse < 1 seconde), il est conseillé d'effectuer des tests avant de décider de basculer.
Points clés de l'API GPT-5.4 mini
- Bond en termes de capacités : 54,4 % sur SWE-Bench Pro, soit 8,7 points de pourcentage de plus que les 45,7 % du GPT-5 mini.
- Réduction sur le cache : 90 % de réduction sur le cache d'entrée à 0,075 $/1M, ce qui réduit considérablement les coûts pour les scénarios à haute fréquence.
- Computer Use : 72,1 % sur OSWorld, marquant la première prise en charge complète de l'automatisation de bureau pour la série mini.
- Adapté aux sous-agents : Pour la première fois, la collaboration multi-agents est accessible au niveau de prix "mini".
- Fenêtre de contexte de 400K : Traitez des livres techniques entiers ou des bases de code complètes en une seule fois.
- Vitesse de réponse doublée : Une vitesse multipliée par deux tout en améliorant les capacités.
- Accès par défaut : Disponible immédiatement dans le groupe par défaut d'APIYI, aucune demande nécessaire.
Résumé
Les points essentiels de l'API GPT-5.4 mini :
- Motivation de la mise à niveau : Amélioration globale sur trois dimensions majeures (SWE-Bench Pro / Terminal-Bench / OSWorld), avec l'introduction du Computer Use et des sous-agents dans la gamme de prix "mini".
- Positionnement tarifaire : 0,75 $ / 4,50 $ par 1M de jetons, avec une réduction de 90 % sur le cache d'entrée à 0,075 $. Pour les scénarios à haute fréquence, le coût réel peut être inférieur à celui de l'ancien modèle mini.
- Accès : Appel direct via le groupe par défaut sur APIYI (apiyi.com). Profitez de 10 % offerts pour tout rechargement de 100, avec une connexion directe depuis la Chine sans besoin de VPN.
Le GPT-5.4 mini n'est pas simplement une "version plus chère du GPT-5 mini", mais une étape clé pour OpenAI visant à rendre les capacités d'agent accessibles à un tarif d'entrée de gamme. Pour les applications effectuant plus de 10 000 invocations par jour, avec un taux de réussite du cache supérieur à 50 % et nécessitant des capacités d'agent ou de Computer Use, cette mise à niveau est pratiquement indispensable. Pour les tâches textuelles simples, le GPT-4o mini ou le GPT-5 mini restent tout à fait pertinents.
Nous vous recommandons d'accéder rapidement au GPT-5.4 mini via la plateforme APIYI (apiyi.com) : le groupe par défaut ne nécessite aucune demande, les réductions sur le cache sont entièrement synchronisées, vous bénéficiez de 10 % de bonus sur vos rechargements et la connexion est stable et directe.
Lectures complémentaires
Si le GPT-5.4 mini API vous intéresse, nous vous recommandons de poursuivre votre lecture avec ces articles :
- 📘 Guide d'intégration de l'API GPT-5.5 Pro – Découvrez le fleuron du raisonnement d'OpenAI, idéal pour compléter les usages du modèle mini.
- 📊 Analyse approfondie du mécanisme de cache d'OpenAI : bonnes pratiques pour bénéficier de 90 % de réduction – Maîtrisez les techniques d'ingénierie pour optimiser vos coûts.
- 🚀 Mise en pratique : construire un agent d'automatisation "Computer Use" basé sur GPT-5.4 mini – Explorez les applications de production pour l'automatisation de bureau.
📚 Références
-
Documentation officielle du modèle GPT-5.4 mini d'OpenAI : spécifications du modèle, tarification et exemples d'invocation.
- Lien :
developers.openai.com/api/docs/models/gpt-5.4-mini - Note : Accédez aux paramètres techniques officiels les plus récents et les plus fiables.
- Lien :
-
Évaluation du GPT-5.4 mini par DataCamp : analyse détaillée des benchmarks et comparaison intergénérationnelle.
- Lien :
datacamp.com/blog/gpt-5-4-mini-nano - Note : Évaluation indépendante par un tiers, idéale pour comparer ce modèle avec ses concurrents.
- Lien :
-
Documentation d'intégration APIYI pour GPT-5.4 mini : solutions d'invocation en Chine, explications sur le regroupement et offres de recharge.
- Lien :
docs.apiyi.com - Note : Guide pratique pour les développeurs souhaitant une intégration fluide.
- Lien :
-
Page de tarification d'OpenAI : grille tarifaire complète et explications sur le mécanisme de cache.
- Lien :
developers.openai.com/api/docs/pricing - Note : Normes de facturation les plus récentes pour tous les modèles.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter de votre expérience avec la mise à jour du GPT-5.4 mini dans les commentaires. Pour plus de ressources sur l'intégration de modèles, consultez le centre de documentation APIYI sur docs.apiyi.com.