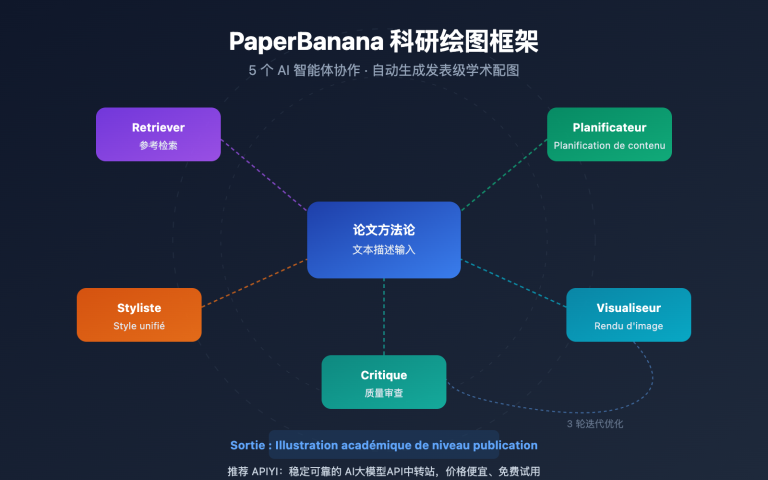
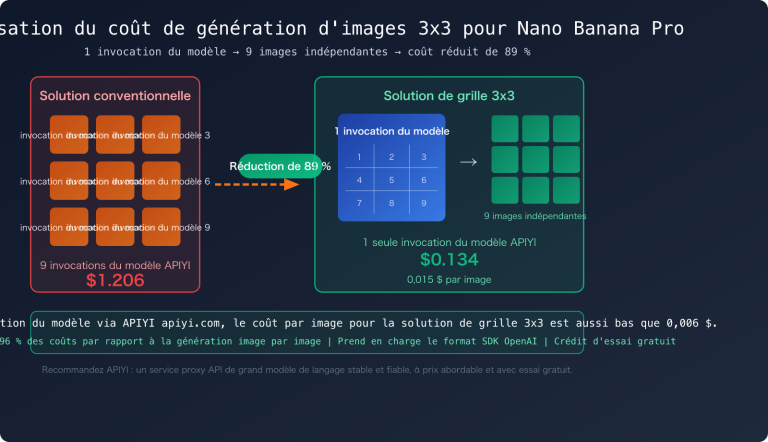
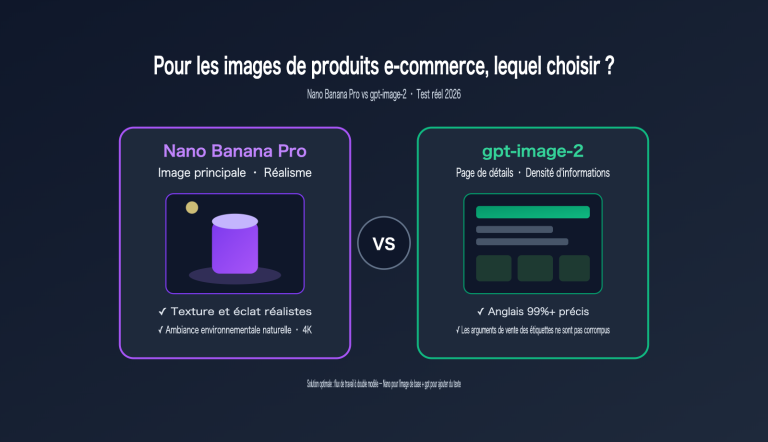
Note de l'auteur : Cet article propose une analyse systématique de la valeur opérationnelle de gpt-image-2 dans 6 domaines clés : e-commerce, UI/UX, publicité, storyboarding, agents développeurs et localisation de contenu, afin d'aider les équipes à planifier leur intégration dès l'ouverture de l'API.
Si vous utilisez régulièrement la génération d'images par IA, vous avez sans doute remarqué qu'il existe une catégorie de besoins qui restent systématiquement "bloqués" : les photos de produits avec des étiquettes mal orthographiées, les supports publicitaires nécessitant une correction manuelle du texte, ou l'impossibilité de générer instantanément des déclinaisons multilingues pour une campagne locale. Ces limites ne sont pas dues aux capacités des modèles, mais aux plafonds technologiques des anciens modèles d'image en matière de rendu de texte, de résolution et de connaissances du monde réel.
Cela peut sembler être un problème récurrent, mais gpt-image-2 est en train de briser systématiquement ces plafonds. Cet article décompose les cas d'usage de gpt-image-2 : flux de travail réels dans 6 secteurs d'activité, méthodes d'intégration via API, et ce que cela implique concrètement pour votre équipe.
Valeur ajoutée : Des scénarios aux exemples de code, vous comprendrez quels métiers bénéficieront en priorité de gpt-image-2 et comment l'intégrer à vos pipelines dès le premier jour de disponibilité de l'API.

Points clés des cas d'usage de gpt-image-2
| Cas d'usage | Valeur ajoutée | Points de douleur des anciens modèles |
|---|---|---|
| E-commerce et photographie produit | Image produit 4K + texte d'emballage précis | Étiquettes erronées, résolution insuffisante |
| Prototypage UI/UX | Mockups haute fidélité en quelques secondes | Texte des boutons/icônes incohérent |
| Publicité et visuels clés | Polices de marque prêtes à l'emploi + 4K | Nécessite des retouches Photoshop |
| Storyboarding et pré-production | Itération en 3 secondes + connaissances du monde | Coût élevé de réitération des plans |
| Pipelines d'agents développeurs | Intégration directe sans modifier le SDK | Génération instable, difficile à automatiser |
| Localisation de contenu | Synchronisation CJK/RTL/Latin | Mise en page manuelle pour les langues non anglaises |
Points communs des cas d'usage
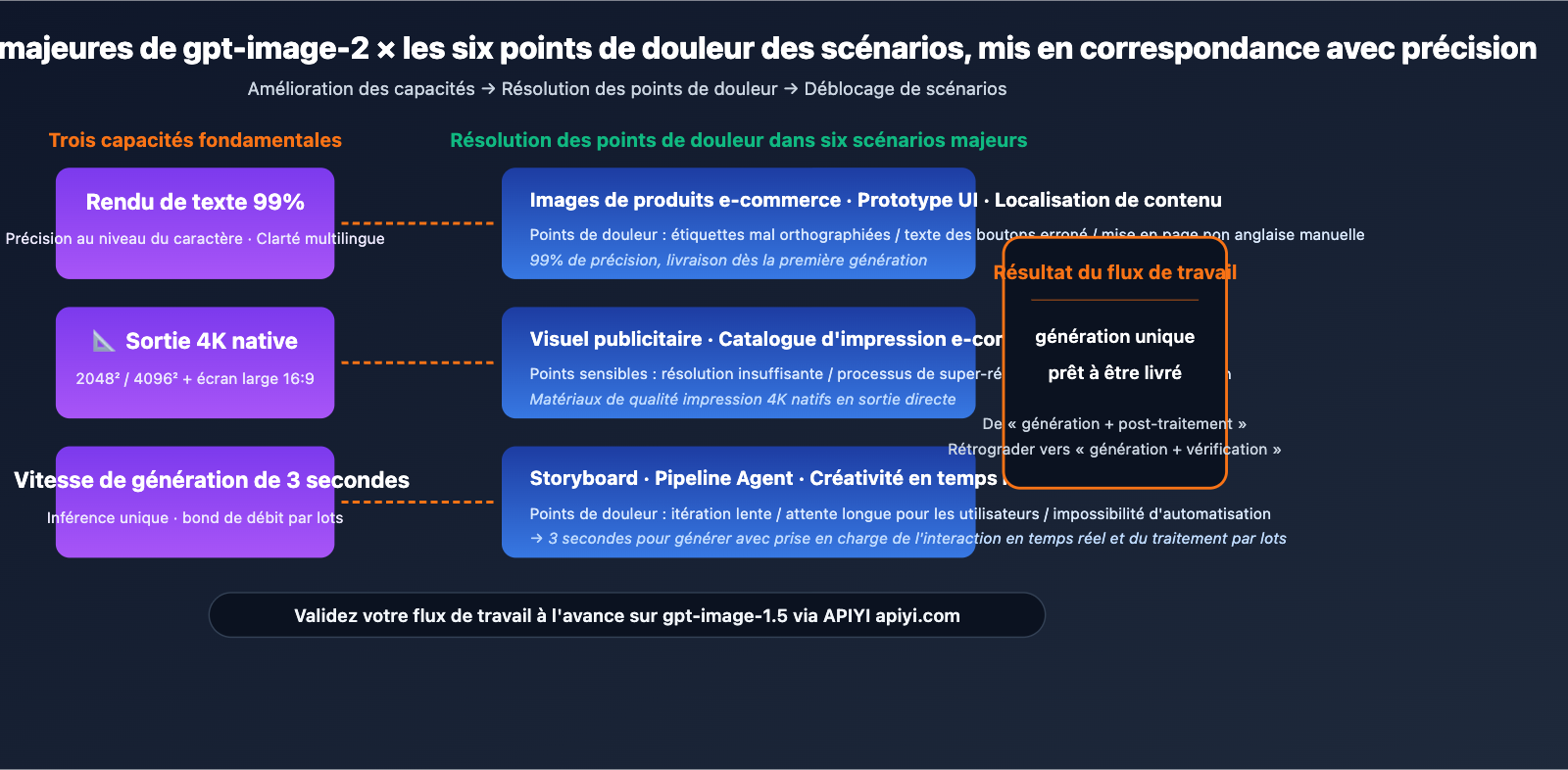
Le dénominateur commun de ces 6 scénarios : Le flux de travail était auparavant bloqué par le "plafond de verre des anciens modèles d'image en matière de rendu de texte, de résolution et de connaissances du monde". Les trois indicateurs clés de gpt-image-2 (99 % de précision textuelle, sortie native 4K, vitesse de génération de 3 secondes) répondent précisément à ces goulots d'étranglement.
Ce que cela signifie : Ces scénarios, qui nécessitaient autrefois un flux de travail en deux étapes (génération par IA + post-traitement manuel), peuvent désormais être simplifiés avec gpt-image-2 en une livraison dès la première génération. L'intervention humaine passe du statut de "réparation" à celui de "validation". L'efficacité de la production d'images au sein des équipes va connaître un saut qualitatif majeur.
Cas d'usage n°1 : E-commerce et photographie produit
Description du scénario
Ce qui donne le plus de fil à retordre aux équipes e-commerce, c'est la cohérence de marque sur les lots d'images produits : un même produit nécessite des dizaines de contenus A+ (images de rayon, mises en situation, gros plans, thématiques saisonnières). Auparavant, il fallait soit engager des photographes professionnels, soit passer par une génération IA suivie de retouches fastidieuses sur les étiquettes et les textes d'emballage.
Comment gpt-image-2 change la donne
- Étiquettes lisibles et emballages précis : Avec 99 % de précision textuelle, le nom du produit, les spécifications et les étiquettes d'ingrédients sont corrects dès la première génération.
- Scènes de rayon réalistes : Grâce à ses connaissances du monde, les arrière-plans (cafés, cuisines, bureaux) correspondent parfaitement à l'identité de marque.
- Résolution 4K prête pour l'impression : La sortie native peut être utilisée directement pour les catalogues imprimés et le contenu A+ des plateformes e-commerce, éliminant ainsi l'étape d'upscaling.
Comparaison des flux de travail
| Étapes | IA traditionnelle | Flux de travail gpt-image-2 |
|---|---|---|
| Production d'une image principale | 3-5 tentatives + retouches PS | 1 génération |
| Génération de 20 variantes | Environ 2-3 heures | Environ 10 minutes |
| Résolution pour impression | Nécessite un logiciel d'upscaling | Sortie native 4K directe |
| Précision des étiquettes de marque | Nécessite une relecture humaine | Environ 99 % de précision automatique |
Conseil d'utilisation : Les équipes e-commerce peuvent utiliser le service proxy API APIYI (apiyi.com) pour intégrer gpt-image-1.5 dès maintenant et se familiariser avec la structure des appels en masse. Le jour de la sortie de gpt-image-2, il suffira de remplacer le champ
modelpour bénéficier instantanément de la mise à niveau 4K et de la précision textuelle de 99 %.
gpt-image-2 Cas d'utilisation 2 : Prototypage UI / UX
Description du scénario
Les chefs de produit et les designers ont souvent besoin de présenter rapidement des mockups d'interface haute fidélité aux parties prenantes lors des phases initiales. Créer un projet de zéro sur Figma prend des heures, et faire appel à des prestataires externes alourdit considérablement les coûts de communication. Avec les anciens modèles d'image, les captures d'écran UI générées présentaient souvent des textes de boutons illisibles et des icônes mal alignées, les rendant pratiquement inutilisables.
Comment gpt-image-2 change la donne
- Production de mockups haute fidélité en quelques secondes : 3 secondes de génération avec un texte précis pour des concepts "prêts à l'emploi".
- Précision accrue du texte, des icônes et de la structure : Le contenu des boutons, les étiquettes de navigation et les tableaux de données sont parfaitement lisibles.
- Validation par les parties prenantes avant même l'ouverture de Figma : Réduction drastique du cycle de décision produit.
Exemple d'invite typique
A modern mobile banking app dashboard screen,
- Top navigation: "Accounts · Transfer · Pay · Invest"
- Account card showing balance "$12,847.50" with "Main Checking"
- Transaction list with 3 items: "Starbucks -$5.40", "Salary +$4,200", "Netflix -$15.99"
- Bottom tab bar: Home, Cards, Rewards, Settings
iOS-style, light mode, Apple system font
En saisissant cette invite dans gpt-image-2, les textes mentionnés ci-dessus seront rendus avec une précision caractère par caractère dans la capture d'écran générée — une prouesse qu'aucun modèle d'image précédent n'avait réussi à accomplir.
gpt-image-2 Cas d'utilisation 3 : Publicité et visuels clés
Description du scénario
Les visuels clés des équipes marketing (affiches, bannières, couvertures de réseaux sociaux) doivent répondre à des exigences de qualité professionnelle : polices de marque respectées, intégration naturelle du produit et éclairage de scène cohérent. Le processus traditionnel nécessite la collaboration d'un photographe, d'un retoucheur et d'un designer sur plusieurs jours.
Comment gpt-image-2 change la donne
- Polices de marque respectées : Un taux de précision de 99 % garantit que les slogans, noms de produits et textes des boutons CTA sont parfaits dès le premier essai.
- Intégration naturelle du produit : Grâce à sa connaissance du monde, le modèle place le produit dans des scénarios de consommation réels, évitant l'effet de "collage" artificiel.
- Éclairage de scène maîtrisé : Les avancées en matière de réalisme permettent aux portraits, aux mains et aux reflets de correspondre aux conditions d'éclairage photographique réelles.
- Sortie 4K pour supprimer l'étape d'upscaling : L'étape de super-résolution, autrefois indispensable dans la plupart des pipelines marketing, devient inutile.
Types de publicités bénéficiant le plus de cette technologie
| Type de publicité | Valeur ajoutée de gpt-image-2 |
|---|---|
| Flux réseaux sociaux | Format carré 1:1 + précision du texte CTA |
| Miniature YouTube | Format natif 16:9 + lisibilité sur écran 4K |
| Affichage extérieur/LED | Sortie directe en 4096×4096 pour grands écrans |
| Affiches imprimées | Support natif 4K pour impression A3/A2 |
| En-tête d'e-mail | Itération rapide de versions multiples pour tests A/B |
Conseil d'intégration : Pour les pipelines de création publicitaire, nous recommandons d'utiliser l'interface unifiée d'APIYI (apiyi.com). Lors de la sortie de gpt-image-2, aucune modification de votre code métier ne sera nécessaire ; il suffira de basculer vers le nom du nouveau modèle.
gpt-image-2 Cas d'usage 4 : Storyboarding et pré-production
Description du scénario
Les réalisateurs, directeurs artistiques et créateurs d'animation ont besoin d'itérer rapidement sur leurs storyboards lors de la phase de pré-production. Le processus traditionnel repose sur des dessinateurs réalisant des croquis à la main d'après un script, chaque itération prenant plusieurs heures. Même avec l'aide de l'IA, les modèles précédents manquaient de stabilité en termes de "cohérence faciale" et de "précision des scènes".
Comment gpt-image-2 change la donne
- Itération rapide des storyboards : Une vitesse de génération de 3 secondes permet au réalisateur d'ajuster le rythme des plans en temps réel lors de discussions avec les scénaristes ou les clients.
- Respect du rythme, des scènes et du positionnement : Grâce à sa connaissance du monde, des scènes complexes comme "parking souterrain + nuit pluvieuse + protagoniste sous un lampadaire" sont réussies du premier coup.
- Réduction des coûts de réitération : On passe d'une moyenne de 5 à 6 essais pour obtenir une image exploitable à seulement 1 ou 2.
Évolution du flux de travail
Flux de travail traditionnel :
Script → Croquis manuel → Validation réalisateur → Modification → Redessin (3-5 cycles)
Temps : 1-2 semaines / épisode
Flux de travail assisté par gpt-image-2 :
Script → Génération gpt-image-2 (3s) → Ajustement de l'invite en temps réel → Finalisation
Temps : 1-2 jours / épisode
Gain d'efficacité : Le cycle de pré-production peut être réduit de plus de 80 %, libérant du temps pour une conception de plans plus détaillée. Il est recommandé d'utiliser les interfaces de traitement par lots d'APIYI (apiyi.com) pour gérer l'intégralité des storyboards d'un épisode.
gpt-image-2 Cas d'usage 5 : Outils développeurs et pipelines d'agents

Description du scénario
De plus en plus de produits IA nécessitent une génération dynamique de contenu visuel : agents éducatifs générant des captures d'écran de tutoriels, agents de jeux générant des concepts de scènes, ou agents de documents générant des illustrations. Auparavant, l'intégration de modèles d'image exigeait de modifier les SDK, de gérer des comptes multi-fournisseurs et de s'adapter à différentes structures d'API.
Comment gpt-image-2 change la donne
- Intégration directe sans modification de SDK : La structure des paramètres de l'API est entièrement compatible avec gpt-image-1.5.
- Idéal pour les agents ayant besoin de rendre des interfaces utilisateur, des supports de tutoriels ou du contenu visuel à la demande.
- Compatibilité native avec OpenAI Agents SDK et AgentKit : Le Function Calling peut déclencher directement la génération d'images.
Exemple minimal de pipeline d'agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def agent_generate_image(scene_description: str) -> str:
"""Outil d'agent : générer une illustration de scène à la demande"""
response = client.images.generate(
model="gpt-image-1.5", # À remplacer par "gpt-image-2" après le lancement
prompt=scene_description,
size="1024x1024",
quality="high"
)
return response.data[0].url
image_url = agent_generate_image(
"Étape 3 du tutoriel : l'utilisateur clique sur le bouton 'Connecter la clé API' dans les paramètres"
)
Voir le code d’intégration complet de l’agent (avec Function Calling)
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
tools = [{
"type": "function",
"function": {
"name": "generate_image",
"description": "Générer une image pour l'étape actuelle du tutoriel",
"parameters": {
"type": "object",
"properties": {
"prompt": {"type": "string", "description": "Description de l'image"},
"size": {"type": "string", "enum": ["1024x1024", "1536x1024"]}
},
"required": ["prompt"]
}
}
}]
def generate_image(prompt: str, size: str = "1024x1024") -> str:
response = client.images.generate(
model="gpt-image-1.5",
prompt=prompt,
size=size,
quality="high"
)
return response.data[0].url
messages = [{"role": "user", "content": "Créer une image de tutoriel pour la configuration de la clé API"}]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools
)
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
image_url = generate_image(**args)
print(f"L'agent a produit l'image : {image_url}")
Conseil aux développeurs : Utilisez APIYI (apiyi.com) pour une intégration unifiée à l'écosystème OpenAI. Une seule clé API suffit pour invoquer gpt-image-2, GPT-4o et tous les autres modèles, évitant ainsi la gestion de comptes multiples.
gpt-image-2 Cas d'usage 6 : Localisation de contenu
Description du scénario
Le défi majeur pour les marques internationales et le commerce transfrontalier est de décliner une même création pour des marchés multilingues : anglais, chinois (simplifié/traditionnel), japonais, coréen, arabe, espagnol, etc. Auparavant, le texte généré par l'IA dans des langues autres que l'anglais était souvent erroné, obligeant les équipes de localisation à effectuer une mise en page manuelle fastidieuse.
Comment gpt-image-2 change la donne
- Génération simultanée pour les langues CJK, RTL et latines : Une seule invite + un paramètre de langue suffisent pour générer toutes les versions.
- Plus besoin de mise en page manuelle : Le rendu de texte multilingue passe de plusieurs jours à quelques minutes.
- Cycle de localisation considérablement réduit : On passe d'un processus linéaire "Validation anglais → Traduction → Remise en page manuelle" à un flux de travail par lots en parallèle.
Comparaison de l'efficacité de localisation
| Type de contenu | Localisation traditionnelle | Localisation gpt-image-2 |
|---|---|---|
| Design d'emballage produit | 5-7 jours/langue | 10 minutes/langue |
| Publicité réseaux sociaux | 2-3 jours/langue | 5 minutes/langue |
| Captures d'écran de tutoriels | 1-2 jours/langue | 3 minutes/langue |
| En-tête d'e-mail | 0,5 jour/langue | 2 minutes/langue |
Exemple de génération par lots multilingue
# Définition des slogans par langue
languages = {
"en": "Summer Sale — Up to 50% Off",
"zh": "夏季特惠 — 低至 5 折",
"ja": "サマーセール — 最大 50% オフ",
"ar": "تخفيضات الصيف — خصم حتى 50%"
}
for lang, slogan in languages.items():
# Création de l'invite pour l'invocation du modèle
prompt = f"E-commerce hero banner, product showcase with slogan '{slogan}', modern style"
url = generate_image(prompt, size="1536x1024")
print(f"[{lang}] {url}")
Conseil pour les équipes de localisation : Utilisez l'interface unifiée d'APIYI (apiyi.com) pour traiter vos ressources multilingues par lots. La plateforme offre des crédits de test gratuits pour vérifier la qualité du rendu dans différentes langues.
Comparaison des solutions par scénario d'application gpt-image-2
| Scénario | Priorité de lancement | ROI attendu | Complexité d'intégration |
|---|---|---|---|
| Images produits e-commerce | ⭐⭐⭐⭐⭐ | Élevé (économie de frais photo) | Faible |
| Prototypage UI/UX | ⭐⭐⭐⭐⭐ | Élevé (cycle de décision réduit) | Faible |
| Visuels publicitaires | ⭐⭐⭐⭐ | Élevé (économie de post-production) | Moyenne |
| Storyboarding | ⭐⭐⭐ | Moyen (efficacité créative) | Faible |
| Pipeline d'agents | ⭐⭐⭐⭐ | Moyen (industrialisation) | Moyenne |
| Localisation de contenu | ⭐⭐⭐⭐⭐ | Très élevé (jours → minutes) | Moyenne |
Conseils pour la priorisation
Planifiez un lancement immédiat (dès le jour de la sortie) : Images produits e-commerce, prototypage UI/UX et localisation de contenu. Ces trois scénarios dépendent le plus des trois améliorations majeures de gpt-image-2 (texte/4K/multilingue).
Migration à moyen terme (observation sur 2-4 semaines) : Visuels publicitaires et pipelines d'agents. Il est conseillé d'attendre la stabilisation de l'API et la clarification des limites de débit avant un déploiement à grande échelle.
Exploration opportuniste : Storyboarding. Idéal pour les petites équipes et les créateurs indépendants, car la résistance au changement des flux de travail traditionnels est plus faible.
Note de décision : La priorité dépend de la structure de votre équipe et de votre rythme opérationnel. Nous vous recommandons de tester d'abord avec gpt-image-1.5 sur APIYI (apiyi.com) et d'évaluer le ROI avec des données réelles avant de décider du niveau d'investissement pour gpt-image-2.
FAQ – Foire aux questions
Q1 : Pour quels cas d’usage gpt-image-2 est-il le plus adapté ?
Six scénarios sont prioritaires : les visuels de produits e-commerce (4K + étiquettes précises), les prototypes UI/UX (maquettes haute fidélité), les visuels publicitaires (qualité professionnelle), les storyboards (itération rapide), les pipelines d'agents développeurs (sans modification du SDK) et la localisation de contenu (génération multilingue en une seule fois). Le point commun est que les modèles précédents étaient limités par la gestion du texte, la résolution ou les connaissances générales, des points que gpt-image-2 résout systématiquement.
Q2 : Quand les équipes e-commerce doivent-elles se préparer à gpt-image-2 ?
Nous recommandons de mettre en place immédiatement un pipeline de génération par lots sur gpt-image-1.5 pour vous familiariser avec les modèles d'invites, les paramètres de dimension et les niveaux de qualité. Le jour de la sortie de gpt-image-2, il suffira de remplacer le champ model pour bénéficier de la 4K et d'une précision textuelle de 99 %. Les équipes préparées pourront lancer leurs nouveaux visuels produits 1 à 2 semaines avant leurs concurrents.
Q3 : Quand gpt-image-2 sera-t-il officiellement disponible pour la production ?
Au 17 avril 2026, OpenAI n'a pas encore fait d'annonce officielle, et les modèles de la série "tape" sont toujours en test A/B sur le LM Arena. Selon le calendrier historique, la sortie est prévue entre fin avril et mi-mai 2026. Il pourrait y avoir des limites de débit au lancement ; nous conseillons d'utiliser un service proxy API comme APIYI (apiyi.com) pour éviter les problèmes de quotas au démarrage.
Q4 : Les prototypes UI/UX peuvent-ils vraiment remplacer Figma ?
Ils ne le remplacent pas, ils le précèdent. gpt-image-2 est idéal pour la phase de preuve de concept avant Figma : utilisez des maquettes générées en quelques secondes pour permettre aux parties prenantes de prendre une décision rapide (Go/No-Go), évitant ainsi de passer des heures sur Figma pour un résultat qui pourrait s'avérer hors sujet. Une fois la direction validée, Figma/Sketch reste l'outil de livraison de design final.
Q5 : Comment intégrer gpt-image-2 dans mes agents existants via API ?
Nous recommandons de passer par APIYI (apiyi.com) pour une transition sans modification le jour de la sortie de gpt-image-2 :
- Inscrivez-vous sur apiyi.com pour obtenir votre clé API.
- Configurez
base_urlsurhttps://vip.apiyi.com/v1et utilisez le SDK officiel d'OpenAI. - Utilisez actuellement
model="gpt-image-1.5"pour construire vos fonctions d'appel d'agent (Function Calling). - Le jour de la sortie, remplacez simplement par
model="gpt-image-2".
APIYI déploie les nouveaux modèles en synchronisation avec OpenAI ; vos clés, votre solde et votre facturation restent inchangés, sans avoir besoin de créer un nouveau compte ou de changer de SDK.
Q6 : À quoi faut-il faire attention pour la localisation de contenu ?
Trois détails cruciaux : (1) donnez le texte cible directement dans l'invite plutôt que de demander au modèle de traduire ; (2) pour les langues RTL (arabe, hébreu, etc.), précisez explicitement "right-to-left layout" dans l'invite ; (3) les caractères CJK (chinois, japonais, coréen) peuvent être légèrement flous en dessous de 1536×1024, nous recommandons une sortie 4K pour les textes critiques (support natif par gpt-image-2).
Q7 : Par quel scénario commencer pour une petite équipe au budget limité ?
Nous suggérons de commencer par les prototypes UI/UX et l'itération de storyboards. Ces deux cas nécessitent peu de complexité d'intégration, et quelques dizaines à centaines d'invocations par mois suffisent pour constater un gain d'efficacité significatif, avec un ROI rapidement vérifiable. Vous pourrez ensuite étendre aux visuels e-commerce et à l'intégration de pipelines d'agents.
Q8 : Quels scénarios ne sont pas adaptés à gpt-image-2 ?
Voici trois limites objectives : (1) Style artistique extrême : Midjourney reste plus performant sur des esthétiques spécifiques, gpt-image-2 étant plus orienté vers le réalisme ; (2) Génération de vidéo : il s'agit d'un modèle d'image, pour la vidéo, utilisez des modèles dédiés comme Sora ; (3) Contenu textuel très long : la précision diminue pour les paragraphes de plus de 50 mots sur une seule image ; il est préférable de générer par blocs puis d'assembler.
Points clés des cas d'usage de gpt-image-2
- 6 scénarios prioritaires : produits e-commerce, prototypes UI, visuels publicitaires, storyboards, pipelines d'agents, localisation de contenu.
- Points communs : les points de douleur (texte/résolution/connaissances) correspondent précisément aux trois améliorations de gpt-image-2.
- Priorité maximale : e-commerce, prototypes UI et localisation — là où le ROI est le plus immédiat.
- Zéro barrière à l'entrée : structure d'API entièrement compatible avec gpt-image-1.5, aucun changement de SDK nécessaire.
- Parcours de démarrage : utilisez APIYI (apiyi.com) pour tester gpt-image-1.5 et basculez sans effort le jour de la sortie officielle.
Résumé
L'analyse clé des cas d'usage de gpt-image-2 :
- Approche axée sur les usages plutôt que sur la technologie : La véritable valeur ne réside pas simplement dans la "génération d'images par IA", mais dans la refonte des flux de travail bloqués par les anciens modèles. Là où il fallait auparavant plusieurs personnes et de nombreuses étapes pour créer des visuels e-commerce, des maquettes UI ou des supports localisés, tout peut désormais être généré et livré en une seule fois.
- Hiérarchisation des priorités : Les scénarios liés à l'e-commerce, aux prototypes UI et à la localisation offrent la valeur ajoutée la plus immédiate. La publicité et les pipelines d'agents nécessitent une planification à moyen terme, tandis que les storyboards représentent une opportunité idéale pour les petites équipes.
- La migration transparente comme avantage majeur : La compatibilité des paramètres API signifie que vous pouvez commencer à construire vos pipelines avec gpt-image-1.5 dès aujourd'hui. Le jour de la sortie de gpt-image-2, il vous suffira de remplacer le nom du modèle pour bénéficier instantanément de toutes les améliorations.
Pour les décisions d'équipe, nous recommandons d'intégrer immédiatement gpt-image-1.5 via APIYI (apiyi.com) pour tester un ou deux scénarios prioritaires. Utilisez vos données métier réelles pour constituer votre bibliothèque d'invites et vos pipelines de traitement par lots ; ainsi, vous serez prêt à passer à la vitesse supérieure dès le lancement de gpt-image-2.
Lectures complémentaires
Si les cas d'usage de gpt-image-2 vous intéressent, nous vous recommandons la lecture des articles suivants :
- 📘 Analyse complète des 8 améliorations majeures : gpt-image-2 vs gpt-image-1.5 – Pour comprendre les raisons techniques de ce saut de performance.
- 📊 Guide complet d'invocation de l'API gpt-image-1.5 – Pour maîtriser les meilleures pratiques du modèle phare actuel.
- 🚀 Optimisation des invocations par lots de l'API de génération d'images en environnement de production – Pour explorer les stratégies de pipelines, de concurrence et de mise en cache.
📚 Références
-
Analyse des cas d'usage de MindStudio : Interprétation des capacités de GPT Image 2
- Lien :
mindstudio.ai/blog/what-is-gpt-image-2 - Description : Synthèse systématique de GPT Image 2 pour le e-commerce, l'UI, le marketing, etc.
- Lien :
-
Bibliothèque d'exemples GitHub d'EvoLinkAI : awesome-gpt-image-2-prompts
- Lien :
github.com/EvoLinkAI/awesome-gpt-image-2-prompts - Description : Collection d'invites testées par la communauté pour les portraits, affiches, maquettes UI et design de personnages.
- Lien :
-
Documentation du SDK OpenAI Agents : Construire un pipeline d'Agent de génération d'images
- Lien :
openai.github.io/openai-agents-python - Description : Spécifications officielles pour l'intégration de la génération d'images via le Function Calling.
- Lien :
-
Analyse approfondie des scénarios ChatIMG : Captures d'écran Web, modèles TikTok, maquettes UI
- Lien :
chatimg.ai/en/blog/gpt-image-2 - Description : Études de cas concrètes destinées aux designers et aux développeurs.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans les commentaires. Pour plus de ressources, consultez le centre de documentation APIYI sur docs.apiyi.com