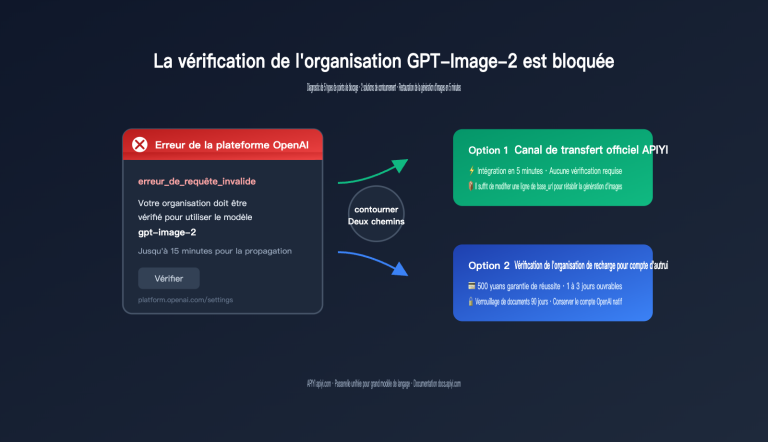
« Quel niveau de concurrence dois-je choisir ? » — C'est la question que les développeurs posent le plus souvent lors de la génération par lots d'images avec l'API Nano Banana 2. La réponse ne réside pas dans les limites de la plateforme, mais dans la quantité de données d'images Base64 que votre bande passante et votre mémoire peuvent supporter.
Valeur ajoutée : En lisant cet article, vous comprendrez les goulots d'étranglement de l'invocation concurrente de l'API Nano Banana 2, vous apprendrez à calculer le nombre optimal de requêtes simultanées en fonction de votre infrastructure, et vous découvrirez 5 astuces d'optimisation des performances éprouvées.

title: "Problèmes de concurrence de l'API Nano Banana 2 : le goulot d'étranglement n'est pas la plateforme, mais votre pipeline"
La première réaction de nombreux développeurs est de demander : « Combien de requêtes simultanées la plateforme peut-elle supporter ? ». En réalité, la plateforme APIYI ne limite pas la concurrence ; le débit (RPM – requêtes par minute) peut facilement atteindre 1 000 par utilisateur, et nous pouvons augmenter les quotas sur demande.
Le véritable goulot d'étranglement est le suivant : l'API de génération d'images Gemini utilise l'encodage Base64 pour transférer les données d'image. Cela signifie que chaque téléchargement ou envoi d'image se traduit par un texte JSON massif, plutôt que par un flux binaire efficace. Cela exerce une pression énorme sur votre bande passante et votre mémoire.
Pourquoi le Base64 est le principal goulot d'étranglement de la concurrence
L'API officielle de Gemini (y compris gemini-3.1-flash-image-preview utilisé par Nano Banana 2) ne prend en charge que le transfert d'images via l'encodage Base64. L'encodage Base64 augmente la taille des données binaires d'environ 33 %, ce qui signifie :
| Résolution | Taille image brute | Après encodage Base64 | Volume de réponse API |
|---|---|---|---|
| 512px (0.5K) | ~400 Ko | ~530 Ko | ~600 Ko – 1 Mo |
| 1K (par défaut) | ~1,5 Mo | ~2 Mo | ~2 Mo |
| 2K | ~4 Mo | ~5,3 Mo | ~5-8 Mo |
| 4K | ~15 Mo | ~20 Mo | ~20 Mo |
Une réponse API pour une image 4K pèse 20 Mo. Si vous lancez 10 requêtes simultanées en 4K, ce sont 200 Mo de données qui transitent sur votre réseau et dans votre mémoire.
Fiche technique des paramètres du modèle API Nano Banana 2
| Paramètre | Valeur |
|---|---|
| ID du modèle | gemini-3.1-flash-image-preview |
| Contexte d'entrée | 131 072 jetons |
| Limite de sortie | 32 768 jetons |
| Résolutions supportées | 512px / 1K / 2K / 4K |
| Ratios d'aspect | 14 types (1:1, 3:2, 4:3, 16:9, 9:16, 21:9, etc.) |
| Max images de référence | 14 (10 objets + 4 personnages) |
| Vitesse de génération | 3-5 secondes/image |
| RPM APIYI | 1 000/utilisateur (quota extensible) |
| Limite de concurrence APIYI | Aucune |
🎯 Conseil technique : La plateforme APIYI apiyi.com ne limite pas la concurrence pour Nano Banana 2 et supporte 1 000 RPM par utilisateur. Le goulot d'étranglement se situe dans votre environnement local : votre bande passante et votre mémoire déterminent le niveau de concurrence que vous pouvez réellement gérer.
Calcul de la concurrence pour l'API Nano Banana 2 : choisir la meilleure approche selon votre environnement
Le nombre de requêtes simultanées ne se décide pas au hasard ; il doit être calculé en fonction de votre environnement réel. Trois indicateurs clés sont à prendre en compte : la bande passante, la mémoire et la résolution cible.

Étape 1 : Vérifiez votre bande passante
La bande passante détermine la quantité de données pouvant être transférées simultanément. Formule de calcul :
Concurrence max (bande passante) = Bande passante disponible (Mo/s) ÷ Taille d'une réponse (Mo)
| Environnement réseau | Bande passante dispo | Limite 1K | Limite 2K | Limite 4K |
|---|---|---|---|---|
| Fibre domestique (100 Mbps) | ~12 Mo/s | 6 | 2 | 0-1 |
| Réseau entreprise (500 Mbps) | ~60 Mo/s | 30 | 10 | 3 |
| Serveur Cloud (1 Gbps) | ~120 Mo/s | 60 | 20 | 6 |
| Serveur haute perf (10 Gbps) | ~1200 Mo/s | 600 | 200 | 60 |
Étape 2 : Vérifiez votre mémoire disponible
Chaque requête simultanée doit conserver l'intégralité de la réponse Base64 en mémoire jusqu'à ce que le décodage et l'écriture sur disque soient terminés. Formule de calcul de la mémoire :
Mémoire requise = Concurrence × Taille d'une réponse × 2,5 (coefficient de tampon de décodage)
Le multiplicateur 2,5 est utilisé car, lors du décodage Base64, la chaîne brute et les données binaires décodées coexistent en mémoire, en plus de la surcharge liée à l'analyse JSON.
| Mémoire disponible | Limite 1K | Limite 2K | Limite 4K |
|---|---|---|---|
| 2 Go | 400 | 100 | 40 |
| 4 Go | 800 | 200 | 80 |
| 8 Go | 1600 | 400 | 160 |
Étape 3 : Prenez la valeur la plus faible des deux
Concurrence recommandée = min(Limite bande passante, Limite mémoire)
En pratique, dans la plupart des scénarios, la bande passante est le véritable goulot d'étranglement, et non la mémoire.
Recommandations de concurrence par scénario
| Scénario | Résolution recommandée | Concurrence recommandée | Débit estimé |
|---|---|---|---|
| Développement/Test perso | 1K | 3-5 | ~1 img/s |
| Génération par lots (petite équipe) | 1K | 10-20 | ~4 img/s |
| Environnement de production | 1K-2K | 20-50 | ~10 img/s |
| Service d'images haut débit | 1K | 50-100 | ~20 img/s |
| Besoin d'images 4K HD | 4K | 3-5 | ~1 img/s |
💡 Conseil pratique : Si vous n'êtes pas sûr du niveau de concurrence, commencez par 5, puis augmentez progressivement à 10, 20, tout en observant le temps de réponse et le taux d'erreur. Si le temps de réponse augmente significativement ou si des timeouts apparaissent, vous approchez de la limite. Lors de vos tests sur la plateforme APIYI apiyi.com, ne vous souciez pas des limites côté plateforme, concentrez-vous sur les performances de votre environnement local.
title: "Guide d'intégration rapide de l'API Nano Banana 2 : 3 étapes pour démarrer"
description: "Apprenez à intégrer l'API Nano Banana 2 en 3 étapes simples et découvrez 5 astuces pour optimiser vos performances de génération d'images."
Guide d'intégration rapide de l'API Nano Banana 2 : 3 étapes pour démarrer
Étape 1 : Installation des dépendances
pip install openai Pillow
Étape 2 : Exemple d'invocation minimaliste
import openai
import base64
from pathlib import Path
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": "Génère un chat mignon portant des lunettes de soleil sur une plage"
}
]
)
# Extraire les données d'image Base64 et les enregistrer
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
img_bytes = base64.b64decode(part.image.data)
Path("output.png").write_bytes(img_bytes)
print("Image enregistrée : output.png")
Voir le code complet pour la génération par lots en concurrence
import openai
import base64
import asyncio
import aiohttp
import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
# Paramètres de configuration
MAX_CONCURRENCY = 10 # Concurrence maximale, à ajuster selon votre bande passante
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
def generate_single_image(prompt: str, index: int) -> dict:
"""Génère une seule image et l'enregistre immédiatement pour libérer la mémoire"""
start = time.time()
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Décodage et sauvegarde immédiats pour éviter que la chaîne Base64 n'occupe la mémoire
img_bytes = base64.b64decode(part.image.data)
filepath = OUTPUT_DIR / f"image_{index:04d}.png"
filepath.write_bytes(img_bytes)
elapsed = time.time() - start
size_mb = len(img_bytes) / (1024 * 1024)
return {
"index": index,
"success": True,
"time": elapsed,
"size_mb": size_mb,
"path": str(filepath)
}
except Exception as e:
return {
"index": index,
"success": False,
"error": str(e),
"time": time.time() - start
}
def batch_generate(prompts: list[str]):
"""Utilise un pool de threads pour générer des images en concurrence"""
results = []
total = len(prompts)
completed = 0
with ThreadPoolExecutor(max_workers=MAX_CONCURRENCY) as executor:
futures = {
executor.submit(generate_single_image, p, i): i
for i, p in enumerate(prompts)
}
for future in futures:
result = future.result()
completed += 1
status = "OK" if result["success"] else "FAIL"
print(f"[{completed}/{total}] {status} - {result['time']:.1f}s")
results.append(result)
# Statistiques
success = [r for r in results if r["success"]]
print(f"\nTerminé : {len(success)}/{total} succès")
if success:
avg_time = sum(r["time"] for r in success) / len(success)
total_size = sum(r["size_mb"] for r in success)
print(f"Temps moyen : {avg_time:.1f}s | Taille totale : {total_size:.1f} Mo")
# Exemple d'utilisation
prompts = [
"Une ville futuriste au coucher du soleil",
"L'intérieur d'un café confortable",
"Une scène de récif corallien sous-marin",
"Un paysage de montagne avec des aurores boréales",
"Un robot mignon jouant de la guitare",
]
batch_generate(prompts)
Étape 3 : Télécharger une image de référence (Image vers image)
Pour les scénarios d'image vers image, vous devez télécharger une image de référence, également encodée en Base64 :
import base64
# Lire l'image locale et la convertir en Base64
with open("reference.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Convertis cette photo en style aquarelle"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{img_base64}"
}
}
]
}
]
)
Attention : Lors du téléchargement d'une image de référence, la taille totale de la requête ne doit pas dépasser 20 Mo. Si l'image est volumineuse, il est recommandé de la compresser en dessous d'une résolution de 1K.
5 astuces pratiques pour l'optimisation de la concurrence de l'API Nano Banana 2
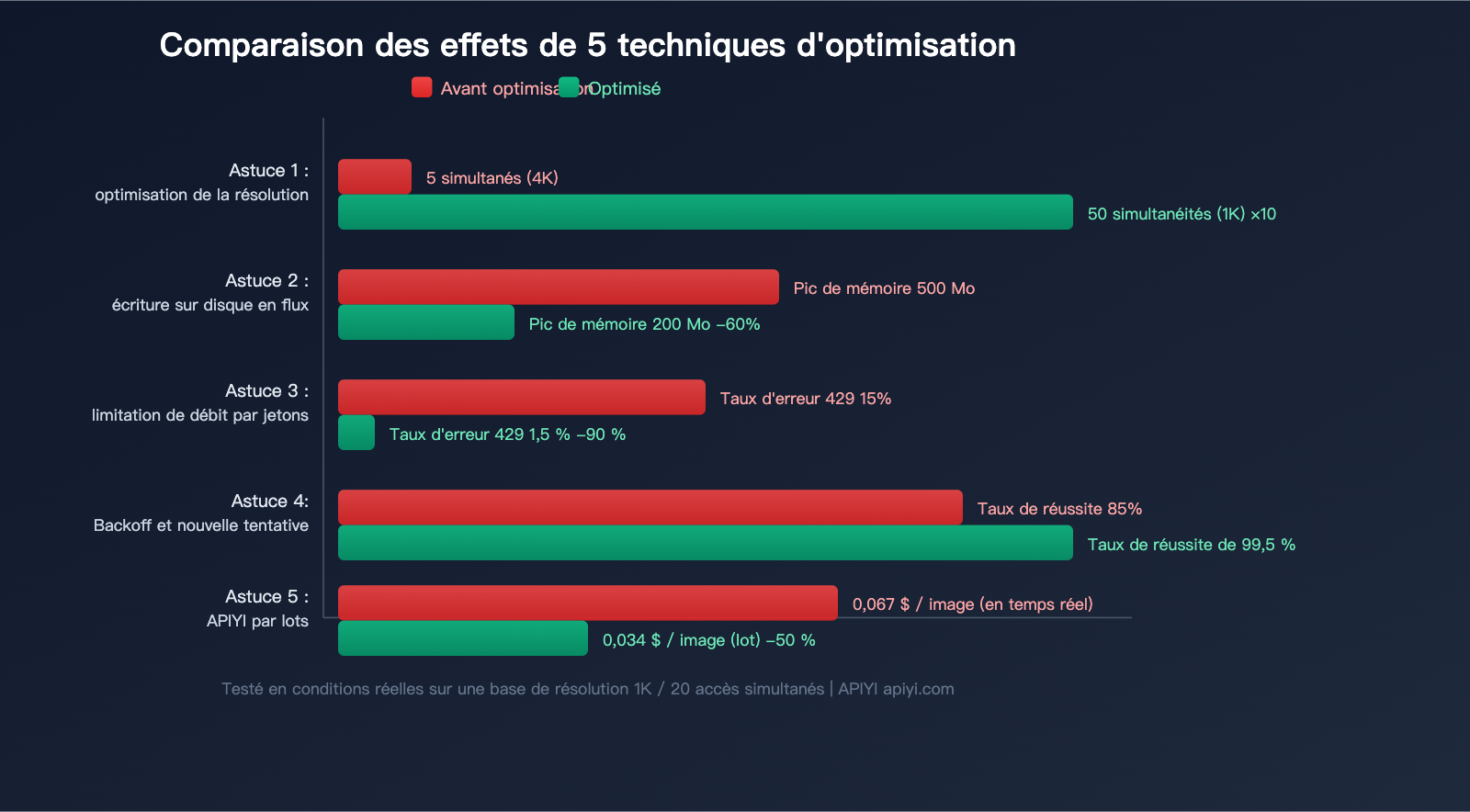
Astuce 1 : Choisissez la résolution selon vos besoins, évitez le 4K par défaut
C'est l'optimisation la plus simple et la plus efficace. De nombreux développeurs demandent du 4K par défaut, mais dans la plupart des cas, le 1K suffit amplement :
| Cas d'utilisation | Résolution recommandée | Taille par image | Efficacité de la concurrence |
|---|---|---|---|
| Réseaux sociaux | 1K | ~2 Mo | Élevée |
| E-commerce | 2K | ~6 Mo | Moyenne |
| Impression/Affiche | 4K | ~20 Mo | Faible |
| Aperçu/Miniature | 512px | ~0.7 Mo | Très élevée |
Passer du 4K au 1K permet d'augmenter la capacité de concurrence d'environ 10 fois à conditions égales.
Astuce 2 : Réception en flux + écriture immédiate sur disque
N'attendez pas que toute la réponse JSON soit reçue pour traiter les données. Utilisez la réception en flux, décodez au fur et à mesure et écrivez sur le disque :
import gc
def generate_and_save(prompt, filepath):
"""Génère l'image et l'enregistre immédiatement, libérant activement la mémoire"""
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Décodage immédiat
img_bytes = base64.b64decode(part.image.data)
# Suppression immédiate de la référence à la chaîne Base64
del part.image.data
# Écriture immédiate sur disque
Path(filepath).write_bytes(img_bytes)
del img_bytes
gc.collect() # Déclenchement actif du ramasse-miettes
Astuce 3 : Contrôlez le rythme de la concurrence avec un limiteur de jetons (Token Bucket)
Ne lancez pas toutes les requêtes d'un coup, utilisez l'algorithme du "Token Bucket" pour répartir les requêtes uniformément :
import threading
import time
class TokenBucket:
"""Limiteur de débit par jetons"""
def __init__(self, rate: float, capacity: int):
self.rate = rate # Taux de remplissage par seconde
self.capacity = capacity # Capacité du seau
self.tokens = capacity
self.lock = threading.Lock()
self.last_refill = time.monotonic()
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.rate
)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep(0.05)
# Utilisation : Maximum 10 requêtes par seconde, pic à 20
limiter = TokenBucket(rate=10, capacity=20)
def rate_limited_generate(prompt, index):
limiter.acquire() # Attente d'un jeton
return generate_single_image(prompt, index)
Astuce 4 : Gérez les erreurs 429 avec un retrait exponentiel
En cas de limitation de débit (HTTP 429), utilisez une stratégie de retrait exponentiel :
import random
def generate_with_retry(prompt, index, max_retries=5):
"""Mécanisme de réessai avec retrait exponentiel"""
for attempt in range(max_retries):
try:
return generate_single_image(prompt, index)
except openai.RateLimitError:
delay = min(60, (2 ** attempt)) + random.uniform(0, 0.5)
print(f"Limitation de débit, attente de {delay:.1f}s avant réessai...")
time.sleep(delay)
return {"index": index, "success": False, "error": "nombre max de réessais atteint"}
Astuce 5 : Économisez 50 % avec l'API Batch pour les tâches par lots
Pour les tâches par lots qui ne nécessitent pas de résultats en temps réel, Nano Banana 2 prend en charge l'API Batch, ce qui réduit les coûts de moitié :
| Mode | Prix unitaire image 1K | Prix unitaire image 4K | Latence | Cas d'utilisation |
|---|---|---|---|---|
| API Temps réel | 0,067 $ | 0,151 $ | 3-5 s | Applications interactives |
| API Batch | 0,034 $ | 0,076 $ | Quelques min à heures | Pré-génération par lots |
💰 Optimisation des coûts : Si votre scénario permet d'attendre, l'utilisation de l'API Batch via APIYI (apiyi.com) peut réduire vos coûts de 50 %. C'est particulièrement adapté à la génération par lots d'images de produits e-commerce, à la préparation de supports marketing, etc.
Détails sur les coûts et la consommation de jetons par résolution pour Nano Banana 2
Comprendre la consommation de jetons vous aide à mieux maîtriser vos coûts :
| Résolution | Consommation de jetons | Prix standard | Prix Batch (50% de remise) | Coût pour 100 images |
|---|---|---|---|---|
| 512px | 747 jetons | 0,045 $ | 0,022 $ | 4,50 $ / 2,20 $ |
| 1K | 1 120 jetons | 0,067 $ | 0,034 $ | 6,70 $ / 3,40 $ |
| 2K | 1 680 jetons | 0,101 $ | 0,050 $ | 10,10 $ / 5,00 $ |
| 4K | 2 520 jetons | 0,151 $ | 0,076 $ | 15,10 $ / 7,60 $ |
🚀 Démarrage rapide : Appelez Nano Banana 2 via la plateforme APIYI (apiyi.com). Les prix sont identiques à ceux officiels, sans limite de concurrence, avec un support de 1000 RPM par utilisateur. Inscrivez-vous pour obtenir un crédit de test.
Comparaison entre Nano Banana 2 et les modèles précédents
| Point de comparaison | Nano Banana | Nano Banana Pro | Nano Banana 2 |
|---|---|---|---|
| ID du modèle | gemini-2.5-flash (image) | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview |
| Résolution max. | 1024×1024 | 4K | 4K |
| Prix unitaire 1K | 0,039 $ | 0,134 $ | 0,067 $ |
| Prix unitaire 4K | Non supporté | 0,240 $ | 0,151 $ |
| Vitesse de génération | 2-4 secondes | 5-8 secondes | 3-5 secondes |
| API Batch | Non supporté | Non supporté | Supporté (50% de remise) |
| Limite d'images de référence | 5 images | 10 images | 14 images |
| Disponible sur APIYI | ✅ | ✅ | ✅ |
Par rapport à la version Pro, Nano Banana 2 réduit le prix du 4K de 37 %, améliore la vitesse de 40 % et ajoute le support de l'API Batch.
Surveillance des performances de concurrence de l'API Nano Banana 2
Lors de l'exécution de tâches simultanées, il est recommandé de surveiller les indicateurs suivants :
import psutil
import time
class PerformanceMonitor:
"""Moniteur de performances de concurrence"""
def __init__(self):
self.start_time = time.time()
self.request_count = 0
self.total_bytes = 0
self.errors = 0
def record(self, success: bool, size_bytes: int = 0):
self.request_count += 1
if success:
self.total_bytes += size_bytes
else:
self.errors += 1
def report(self):
elapsed = time.time() - self.start_time
mem = psutil.Process().memory_info().rss / (1024**2)
print(f"--- Rapport de performance ---")
print(f"Temps d'exécution : {elapsed:.1f}s")
print(f"Requêtes terminées : {self.request_count}")
print(f"Taux de réussite : {(self.request_count-self.errors)/max(1,self.request_count)*100:.1f}%")
print(f"Débit : {self.request_count/elapsed:.2f} req/s")
print(f"Volume de données : {self.total_bytes/(1024**2):.1f} Mo")
print(f"Utilisation de la bande passante : {self.total_bytes/(1024**2)/elapsed:.1f} Mo/s")
print(f"Utilisation mémoire : {mem:.0f} Mo")
Questions fréquentes
Q1 : La plateforme APIYI impose-t-elle des limites de concurrence pour Nano Banana 2 ?
La plateforme APIYI ne limite pas le nombre de requêtes simultanées pour Nano Banana 2. Le RPM (requêtes par minute) est fixé par défaut à 1000 par utilisateur ; si vous avez des besoins plus élevés, contactez le service client pour obtenir un quota supplémentaire. Le goulot d'étranglement réel dépendra de votre bande passante locale et de votre mémoire. Nous vous conseillons d'effectuer des tests réels via la plateforme APIYI apiyi.com pour déterminer le niveau de concurrence optimal pour votre environnement.
Q2 : Pourquoi l’API d’images Gemini ne prend-elle en charge que le transfert en Base64 ?
Il s'agit d'un choix de conception actuel de l'API Google Gemini. L'encodage Base64 permet d'intégrer directement les données d'image dans la réponse JSON, sans nécessiter de stockage de fichiers supplémentaire ou de distribution via CDN. L'inconvénient est une augmentation de la taille des données d'environ 33 %, ce qui est moins efficace pour la bande passante et la mémoire. La communauté des développeurs a fait remonter ce point à Google en demandant l'ajout d'une sortie au format JPEG et d'options de téléchargement via URL temporaire, mais cela n'a pas encore été implémenté.
Q3 : La différence de rendu entre les résolutions 1K et 4K est-elle importante ?
Cela dépend de votre cas d'usage. Pour des illustrations sur les réseaux sociaux, des interfaces web ou des applications, la résolution 1K est largement suffisante et la différence est quasi imperceptible à l'œil nu. Le 4K est principalement destiné à l'impression, aux affiches, aux fonds d'écran haute définition ou aux scénarios nécessitant une inspection détaillée. Nous vous suggérons de tester le rendu en 1K d'abord, puis de passer au 4K si une clarté supérieure est nécessaire. Via APIYI apiyi.com, vous pouvez basculer facilement entre les résolutions à tout moment.
Q4 : Que faire en cas d’erreurs 429 fréquentes ?
Une erreur 429 indique que vous avez atteint la limite de débit. Solutions : (1) Réduisez le nombre de requêtes simultanées ; (2) Utilisez un limiteur de débit (token bucket) pour répartir uniformément vos requêtes ; (3) Implémentez une stratégie de nouvelle tentative avec recul exponentiel ; (4) Pour les tâches en masse, passez à l'API Batch. Si vous rencontrez des problèmes de limitation sur la plateforme APIYI, contactez le service client pour augmenter votre quota de RPM.
Q5 : Comment estimer le coût total d’une génération en masse ?
Utilisez la formule : Coût total = Nombre d'images × Prix unitaire. Par exemple, pour générer 1000 images en 1K : mode Standard 1000 × 0,067 $ = 67 $, mode Batch 1000 × 0,034 $ = 34 $. Les tarifs sur APIYI apiyi.com sont identiques à ceux officiels, avec une flexibilité de recharge adaptée à une utilisation à la demande.
Résumé : Trouvez la meilleure stratégie de concurrence pour l'API Nano Banana 2
L'optimisation de la concurrence pour l'API Nano Banana 2 ne dépend pas de ce que « la plateforme autorise », mais de ce que « votre pipeline peut supporter ». Gardez ces 3 points clés en tête :
- La résolution est déterminante : Passer du 4K au 1K multiplie votre capacité de concurrence par 10 et réduit vos coûts de 56 %.
- La bande passante est le véritable goulot d'étranglement : L'encodage Base64 alourdit chaque image de 33 % par rapport à sa taille réelle ; la pression sur la bande passante est bien plus forte que celle sur le CPU.
- Optimisez progressivement : Commencez avec 5 requêtes simultanées, surveillez le temps de réponse ainsi que le taux d'erreur, puis augmentez progressivement jusqu'à atteindre la valeur optimale.
Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour vos invocations de l'API Nano Banana 2. Sans limite de concurrence, avec un débit de 1000 RPM par utilisateur et des tarifs identiques à ceux officiels, vous pouvez vous concentrer sur l'optimisation des performances de votre pipeline sans vous soucier des restrictions de la plateforme.

Références
-
Gemini 3.1 Flash Image Preview : Spécifications du modèle et documentation de l'API
- Lien :
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview
- Lien :
-
Gemini Image Generation API : Guide d'utilisation de l'API de génération d'images
- Lien :
ai.google.dev/gemini-api/docs/image-generation
- Lien :
-
Gemini API Rate Limits : Documentation officielle sur les limites de débit
- Lien :
ai.google.dev/gemini-api/docs/rate-limits
- Lien :
-
Documentation d'intégration APIYI Nano Banana 2 : Description de l'interface API unifiée
- Lien :
api.apiyi.com
- Lien :
📝 Auteur : Équipe APIYI | L'équipe technique d'APIYI se spécialise dans le domaine de l'API de génération d'images IA et propose aux développeurs, via apiyi.com, un service d'accès à l'API Nano Banana 2 avec une concurrence illimitée et une facturation flexible.