"Qual o nível ideal de concorrência?" — essa é a pergunta que mais ouvimos de desenvolvedores que usam a API do Nano Banana 2 para geração de imagens em lote. A resposta não está nas limitações da plataforma, mas sim em quanto de dados de imagem em Base64 sua largura de banda e memória conseguem suportar.
Valor central: Ao terminar este artigo, você entenderá os principais gargalos das chamadas simultâneas da API do Nano Banana 2, aprenderá a calcular o número ideal de concorrência com base nas condições do seu servidor e receberá 5 dicas de otimização de desempenho comprovadas.

Problemas de concorrência na API Nano Banana 2: o gargalo não é a plataforma, é o seu pipeline
A primeira reação de muitos desenvolvedores é: "Quantas conexões simultâneas a plataforma suporta?". Mas, na verdade, a plataforma APIYI não limita a concorrência; o RPM (requisições por minuto) pode suportar 1000 por usuário sem problemas, e podemos aumentar a cota individualmente se necessário.
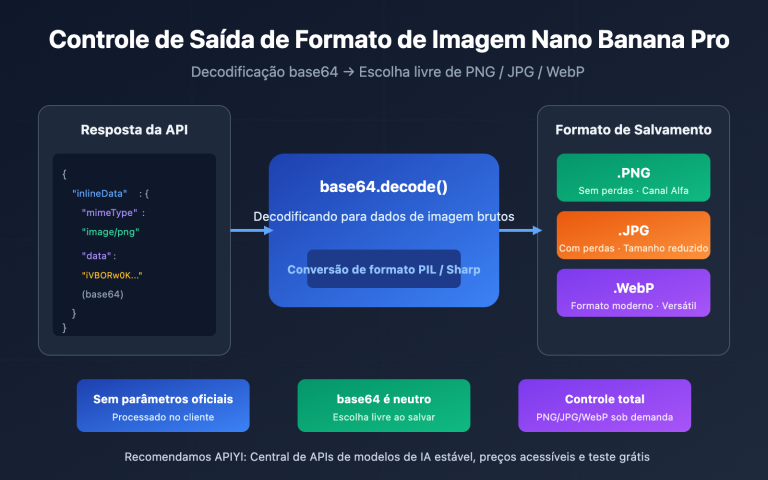
O verdadeiro gargalo está aqui: a API de geração de imagens do Gemini usa codificação Base64 para transmitir dados de imagem. Isso significa que o upload e o download de cada imagem são textos JSON gigantescos, em vez de fluxos binários eficientes. Isso coloca uma pressão enorme na sua largura de banda e na sua memória.
Por que o Base64 é o principal gargalo de concorrência
A API oficial do Gemini (incluindo a gemini-3.1-flash-image-preview usada pela Nano Banana 2) suporta apenas a transmissão de imagens via codificação Base64. A codificação Base64 expande os dados binários em cerca de 33%, o que significa:
| Resolução | Tamanho original | Após Base64 | Volume da resposta da API |
|---|---|---|---|
| 512px (0.5K) | ~400 KB | ~530 KB | ~600 KB – 1 MB |
| 1K (padrão) | ~1.5 MB | ~2 MB | ~2 MB |
| 2K | ~4 MB | ~5.3 MB | ~5-8 MB |
| 4K | ~15 MB | ~20 MB | ~20 MB |
Uma resposta da API para uma imagem 4K tem 20 MB. Se você disparar 10 requisições simultâneas de 4K, terá 200 MB de dados de resposta trafegando pela rede e ocupando a memória.
Consulta rápida de parâmetros do modelo API Nano Banana 2
| Parâmetro | Valor |
|---|---|
| ID do modelo | gemini-3.1-flash-image-preview |
| Contexto de entrada | 131.072 tokens |
| Limite de saída | 32.768 tokens |
| Resoluções suportadas | 512px / 1K / 2K / 4K |
| Proporções suportadas | 14 tipos, incluindo 1:1, 3:2, 4:3, 16:9, 9:16, 21:9, etc. |
| Máximo de imagens de referência | 14 (10 objetos + 4 personagens) |
| Velocidade de geração | 3-5 segundos/imagem |
| RPM na APIYI | 1000/usuário (cota expansível) |
| Limite de concorrência na APIYI | Ilimitado |
🎯 Dica técnica: A plataforma APIYI apiyi.com não impõe limites de concorrência para a Nano Banana 2, com suporte a 1000 RPM por usuário. O gargalo está no seu ambiente local — a largura de banda e a memória determinam quantas requisições simultâneas você consegue executar na prática.
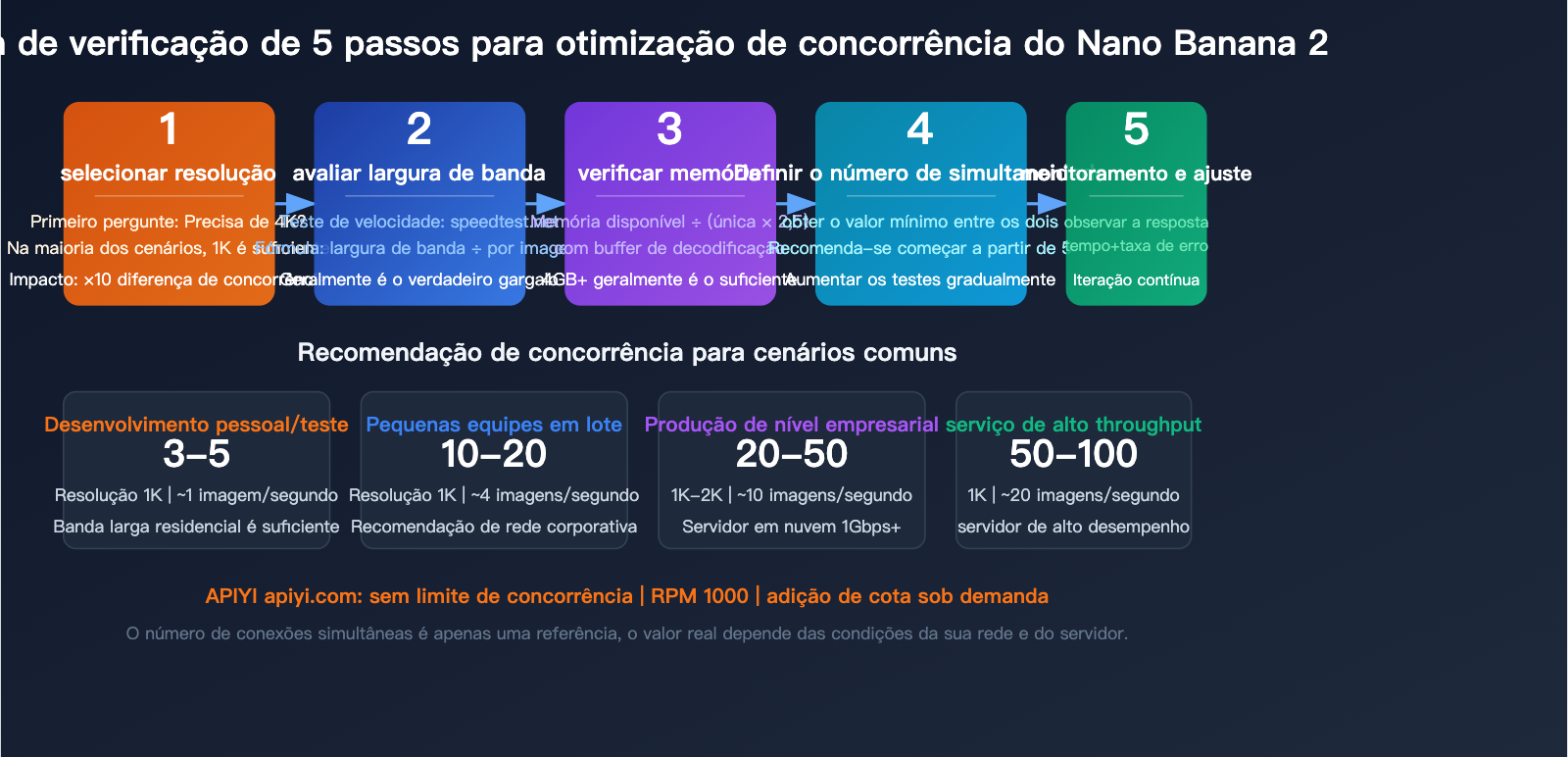
Cálculo de concorrência da API Nano Banana 2: escolha a melhor estratégia para o seu ambiente
O número de conexões simultâneas não deve ser definido por palpite, mas calculado com base no seu ambiente real. Existem três indicadores-chave: largura de banda, memória e resolução alvo.
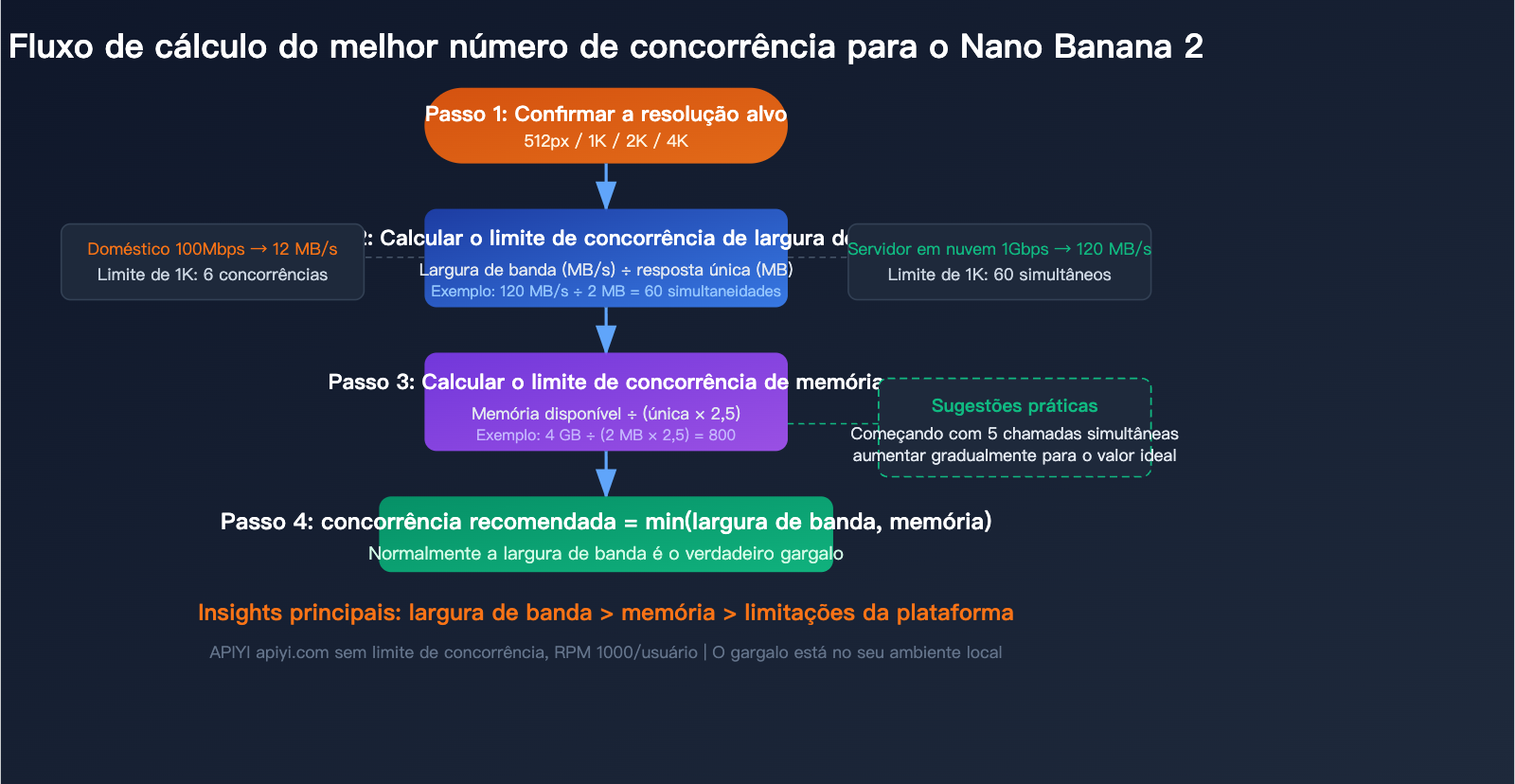
Passo 1: Confirme sua largura de banda
A largura de banda determina quantos dados podem ser transmitidos simultaneamente. Fórmula de cálculo:
Concorrência máxima (banda) = Largura de banda disponível (MB/s) ÷ Tamanho da resposta (MB)
| Ambiente de rede | Banda disponível | Limite 1K | Limite 2K | Limite 4K |
|---|---|---|---|---|
| Banda larga residencial (100Mbps) | ~12 MB/s | 6 | 2 | 0-1 |
| Rede corporativa (500Mbps) | ~60 MB/s | 30 | 10 | 3 |
| Servidor em nuvem (1Gbps) | ~120 MB/s | 60 | 20 | 6 |
| Servidor de alto desempenho (10Gbps) | ~1200 MB/s | 600 | 200 | 60 |
Passo 2: Confirme sua memória disponível
Cada requisição simultânea precisa manter os dados da resposta Base64 completos na memória até que a decodificação e a gravação em disco sejam concluídas. Fórmula de memória:
Memória necessária = Concorrência × Tamanho da resposta × 2.5 (fator de buffer de decodificação)
Multiplicamos por 2.5 porque, durante o processo de decodificação Base64, a string original e os dados binários decodificados coexistem na memória, além do overhead de processamento JSON.
| Memória disponível | Limite 1K | Limite 2K | Limite 4K |
|---|---|---|---|
| 2 GB | 400 | 100 | 40 |
| 4 GB | 800 | 200 | 80 |
| 8 GB | 1600 | 400 | 160 |
Passo 3: Escolha o menor valor entre os dois
Concorrência máxima recomendada = min(limite de banda, limite de memória)
Na prática, na maioria dos cenários, a largura de banda é o verdadeiro gargalo, e não a memória.
Concorrência recomendada por cenário
| Cenário | Resolução recomendada | Concorrência recomendada | Throughput estimado |
|---|---|---|---|
| Desenvolvimento/Teste pessoal | 1K | 3-5 | ~1 img/seg |
| Geração em lote (pequenas equipes) | 1K | 10-20 | ~4 img/seg |
| Ambiente de produção corporativo | 1K-2K | 20-50 | ~10 img/seg |
| Serviço de imagem de alto throughput | 1K | 50-100 | ~20 img/seg |
| Necessidade de imagens 4K | 4K | 3-5 | ~1 img/seg |
💡 Dica prática: Se não tiver certeza de quanta concorrência abrir, comece com 5 e aumente gradualmente para 10, 20, observando o tempo de resposta e a taxa de erro. Se o tempo de resposta aumentar significativamente ou ocorrerem timeouts, você está chegando ao gargalo. Ao testar na plataforma APIYI apiyi.com, não se preocupe com limites do lado da plataforma; foque apenas no desempenho local.
Integração Rápida da API Nano Banana 2: 3 Passos para a Implementação
Passo 1: Instalar dependências
pip install openai Pillow
Passo 2: Exemplo de invocação minimalista
import openai
import base64
from pathlib import Path
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": "Gere um gato fofo usando óculos de sol em uma praia"
}
]
)
# Extrair dados da imagem em Base64 e salvar
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
img_bytes = base64.b64decode(part.image.data)
Path("output.png").write_bytes(img_bytes)
print("Imagem salva: output.png")
Ver código completo para geração em lote com concorrência
import openai
import base64
import asyncio
import aiohttp
import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
# Parâmetros de configuração
MAX_CONCURRENCY = 10 # Concorrência máxima, ajuste conforme sua largura de banda
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
def generate_single_image(prompt: str, index: int) -> dict:
"""Gera uma única imagem e salva imediatamente, liberando memória"""
start = time.time()
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Decodifica e salva imediatamente para evitar que a string Base64 ocupe memória por muito tempo
img_bytes = base64.b64decode(part.image.data)
filepath = OUTPUT_DIR / f"image_{index:04d}.png"
filepath.write_bytes(img_bytes)
elapsed = time.time() - start
size_mb = len(img_bytes) / (1024 * 1024)
return {
"index": index,
"success": True,
"time": elapsed,
"size_mb": size_mb,
"path": str(filepath)
}
except Exception as e:
return {
"index": index,
"success": False,
"error": str(e),
"time": time.time() - start
}
def batch_generate(prompts: list[str]):
"""Usa pool de threads para geração concorrente de imagens"""
results = []
total = len(prompts)
completed = 0
with ThreadPoolExecutor(max_workers=MAX_CONCURRENCY) as executor:
futures = {
executor.submit(generate_single_image, p, i): i
for i, p in enumerate(prompts)
}
for future in futures:
result = future.result()
completed += 1
status = "OK" if result["success"] else "FAIL"
print(f"[{completed}/{total}] {status} - {result['time']:.1f}s")
results.append(result)
# Estatísticas
success = [r for r in results if r["success"]]
print(f"\nConcluído: {len(success)}/{total} com sucesso")
if success:
avg_time = sum(r["time"] for r in success) / len(success)
total_size = sum(r["size_mb"] for r in success)
print(f"Tempo médio: {avg_time:.1f}s | Tamanho total: {total_size:.1f} MB")
# Exemplo de uso
prompts = [
"Uma cidade futurista ao pôr do sol",
"Interior de uma cafeteria aconchegante",
"Cena de um recife de coral subaquático",
"Paisagem montanhosa com aurora boreal",
"Um robô fofo tocando guitarra",
]
batch_generate(prompts)
Passo 3: Enviar imagem de referência (imagem para imagem)
Cenários de imagem para imagem exigem o envio de uma imagem de referência, também codificada em Base64:
import base64
# Lê a imagem local e converte para Base64
with open("reference.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Converta esta foto para o estilo de pintura em aquarela"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{img_base64}"
}
}
]
}
]
)
Nota: Ao enviar uma imagem de referência, o tamanho total do corpo da requisição não pode exceder 20 MB. Se a imagem de referência for grande, recomendamos comprimi-la para uma resolução abaixo de 1K.
5 Dicas Práticas para Otimização de Concorrência da API Nano Banana 2
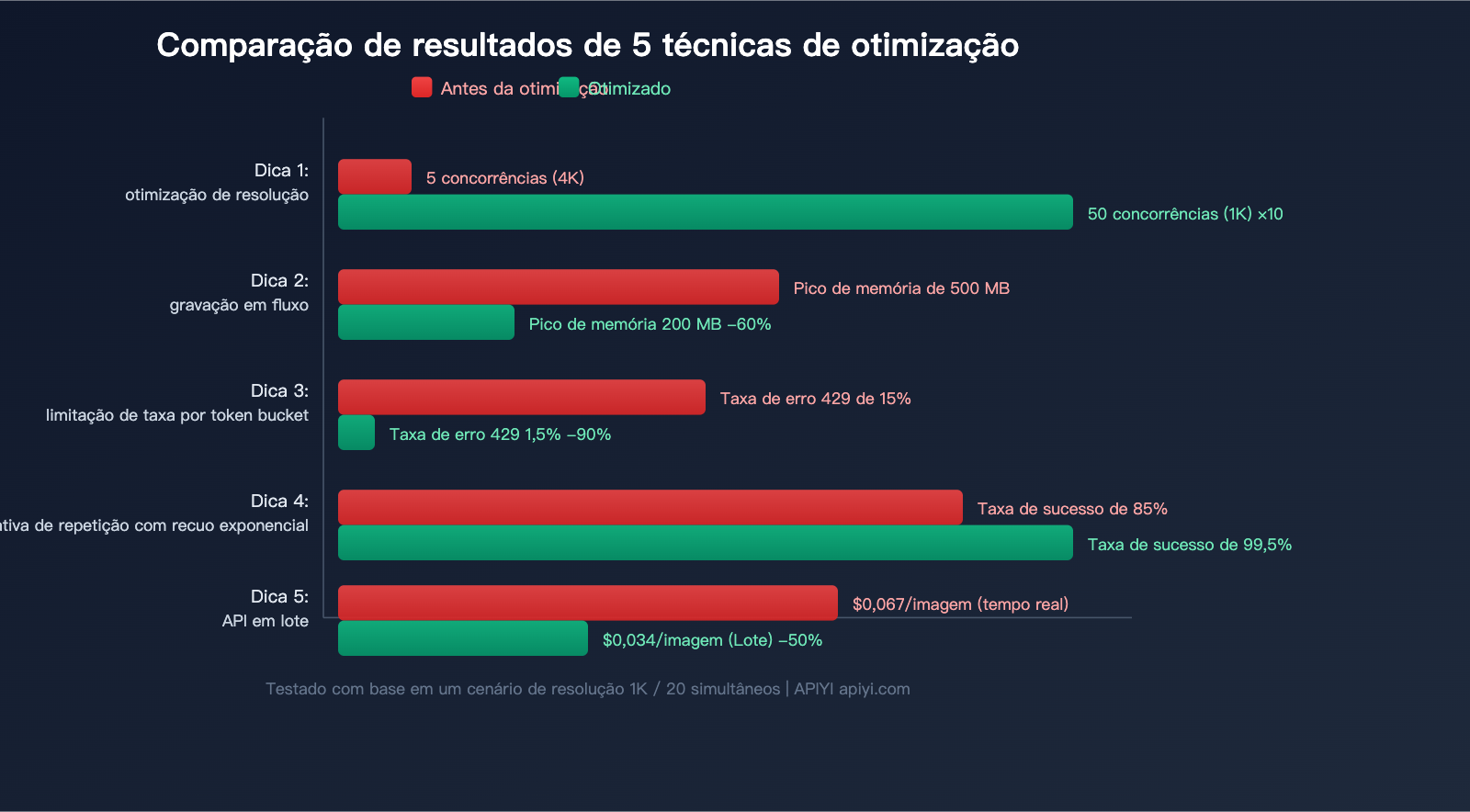
Dica 1: Escolha a resolução sob demanda, evite o 4K padrão
Esta é a otimização mais simples e eficaz. Muitos desenvolvedores solicitam 4K por padrão, mas em cenários reais, 1K é suficiente:
| Cenário de uso | Resolução recomendada | Tamanho por imagem | Eficiência de concorrência |
|---|---|---|---|
| Imagens para redes sociais | 1K | ~2 MB | Alta |
| Imagens de produtos de e-commerce | 2K | ~6 MB | Média |
| Impressão/Pôsteres | 4K | ~20 MB | Baixa |
| Visualização/Miniaturas | 512px | ~0.7 MB | Altíssima |
Ao mudar de 4K para 1K, a capacidade de concorrência aumenta cerca de 10 vezes sob as mesmas condições.
Dica 2: Recebimento via streaming + gravação imediata em disco
Não espere que toda a resposta JSON seja recebida antes de processar. Use o recebimento via streaming, decodificando e gravando no disco conforme os dados chegam:
import gc
def generate_and_save(prompt, filepath):
"""Gera a imagem e salva imediatamente, liberando memória ativamente"""
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Decodifica imediatamente
img_bytes = base64.b64decode(part.image.data)
# Remove a referência da string Base64 imediatamente
del part.image.data
# Grava no disco imediatamente
Path(filepath).write_bytes(img_bytes)
del img_bytes
gc.collect() # Aciona a coleta de lixo ativamente
Dica 3: Limitador de taxa (Token Bucket) para controlar o ritmo de concorrência
Não envie todas as requisições de uma vez; use o algoritmo de "balde de tokens" (Token Bucket) para distribuir as requisições uniformemente:
import threading
import time
class TokenBucket:
"""Limitador de taxa de balde de tokens"""
def __init__(self, rate: float, capacity: int):
self.rate = rate # Taxa de reposição por segundo
self.capacity = capacity # Capacidade do balde
self.tokens = capacity
self.lock = threading.Lock()
self.last_refill = time.monotonic()
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.rate
)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep(0.05)
# Uso: Máximo de 10 requisições por segundo, pico de 20
limiter = TokenBucket(rate=10, capacity=20)
def rate_limited_generate(prompt, index):
limiter.acquire() # Aguarda o token
return generate_single_image(prompt, index)
Dica 4: Tratamento de erro 429 com reintento de recuo exponencial
Ao encontrar limitação de taxa (HTTP 429), use uma estratégia de recuo exponencial:
import random
def generate_with_retry(prompt, index, max_retries=5):
"""Mecanismo de reintento com recuo exponencial"""
for attempt in range(max_retries):
try:
return generate_single_image(prompt, index)
except openai.RateLimitError:
delay = min(60, (2 ** attempt)) + random.uniform(0, 0.5)
print(f"Limite excedido, aguardando {delay:.1f}s para tentar novamente...")
time.sleep(delay)
return {"index": index, "success": False, "error": "max retries"}
Dica 5: Economize 50% usando Batch API para tarefas em lote
Para tarefas em lote que não exigem resultados em tempo real, o Nano Banana 2 suporta a Batch API, reduzindo o custo pela metade:
| Modo | Preço unitário imagem 1K | Preço unitário imagem 4K | Latência | Cenário ideal |
|---|---|---|---|---|
| API em tempo real | $0.067 | $0.151 | 3-5 segundos | Aplicações interativas |
| Batch API | $0.034 | $0.076 | Minutos a horas | Pré-geração em lote |
💰 Otimização de custos: Se o seu cenário permitir espera, utilizar a Batch API via APIYI (apiyi.com) pode economizar 50% nos custos. Especialmente adequado para geração em lote de imagens de produtos de e-commerce, pré-produção de materiais de marketing, etc.
Detalhes de custos e consumo de tokens por resolução do Nano Banana 2
Entender o consumo de tokens ajuda a controlar melhor os custos:
| Resolução | Consumo de tokens de saída | Preço padrão | Preço Batch (50% de desc.) | Custo por 100 imagens |
|---|---|---|---|---|
| 512px | 747 tokens | $0,045 | $0,022 | $4,50 / $2,20 |
| 1K | 1.120 tokens | $0,067 | $0,034 | $6,70 / $3,40 |
| 2K | 1.680 tokens | $0,101 | $0,050 | $10,10 / $5,00 |
| 4K | 2.520 tokens | $0,151 | $0,076 | $15,10 / $7,60 |
🚀 Comece agora: Utilize o Nano Banana 2 através da plataforma APIYI (apiyi.com). Os preços são iguais aos oficiais, sem limite de concorrência e com suporte a 1000 RPM por usuário. Registre-se e ganhe créditos para testes.
Comparativo: Nano Banana 2 vs. modelos anteriores
| Item de comparação | Nano Banana | Nano Banana Pro | Nano Banana 2 |
|---|---|---|---|
| ID do modelo | gemini-2.5-flash (imagem) | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview |
| Resolução máx. | 1024×1024 | 4K | 4K |
| Preço unitário 1K | $0,039 | $0,134 | $0,067 |
| Preço unitário 4K | Não suportado | $0,240 | $0,151 |
| Velocidade de geração | 2-4 segundos | 5-8 segundos | 3-5 segundos |
| API Batch | Não suportado | Não suportado | Suportado (50% de desc.) |
| Limite de imagem de referência | 5 imagens | 10 imagens | 14 imagens |
| Disponível na APIYI | ✅ | ✅ | ✅ |
Comparado à versão Pro, o Nano Banana 2 oferece uma redução de 37% no preço para 4K, um aumento de 40% na velocidade e, além disso, adiciona suporte à API Batch.
Monitoramento de desempenho de concorrência da API Nano Banana 2
Ao executar tarefas simultâneas na prática, recomendo monitorar os seguintes indicadores:
import psutil
import time
class PerformanceMonitor:
"""Monitor de desempenho de concorrência"""
def __init__(self):
self.start_time = time.time()
self.request_count = 0
self.total_bytes = 0
self.errors = 0
def record(self, success: bool, size_bytes: int = 0):
self.request_count += 1
if success:
self.total_bytes += size_bytes
else:
self.errors += 1
def report(self):
elapsed = time.time() - self.start_time
mem = psutil.Process().memory_info().rss / (1024**2)
print(f"--- Relatório de Desempenho ---")
print(f"Tempo de execução: {elapsed:.1f}s")
print(f"Requisições concluídas: {self.request_count}")
print(f"Taxa de sucesso: {(self.request_count-self.errors)/max(1,self.request_count)*100:.1f}%")
print(f"Throughput: {self.request_count/elapsed:.2f} req/s")
print(f"Volume de dados: {self.total_bytes/(1024**2):.1f} MB")
print(f"Uso de banda: {self.total_bytes/(1024**2)/elapsed:.1f} MB/s")
print(f"Uso de memória: {mem:.0f} MB")
Perguntas frequentes
Q1: A plataforma APIYI impõe limites de concorrência para o Nano Banana 2?
A plataforma APIYI não limita o número de conexões simultâneas para o Nano Banana 2. O RPM (requisições por minuto) suporta, por padrão, 1.000 requisições por usuário; caso precise de mais, entre em contato com o suporte para solicitar um aumento de cota. O gargalo real da concorrência dependerá da sua largura de banda local e memória. Recomendo realizar testes práticos através da plataforma APIYI (apiyi.com) para encontrar o nível ideal de concorrência para o seu ambiente.
Q2: Por que a API de imagens do Gemini suporta apenas transferência em Base64?
Esta é uma escolha de design atual da API do Google Gemini. A codificação Base64 permite incorporar dados de imagem diretamente na resposta JSON, eliminando a necessidade de armazenamento de arquivos ou distribuição via CDN. A desvantagem é que o volume de dados aumenta em cerca de 33%, o que não é ideal para banda e memória. A comunidade de desenvolvedores já enviou feedbacks ao Google solicitando a inclusão de formatos JPEG e opções de download via URL temporária, mas isso ainda não foi implementado.
Q3: Existe uma grande diferença de qualidade entre as resoluções 1K e 4K?
Depende do seu caso de uso. Para imagens em redes sociais, exibição na web ou interfaces de aplicativos, a resolução 1K é perfeitamente suficiente e, a olho nu, quase não se nota diferença. O 4K é indicado principalmente para impressão, pôsteres, papéis de parede de alta definição e outros cenários que exigem zoom para verificar detalhes. Sugiro testar primeiro com 1K e, caso confirme a necessidade de maior nitidez, mudar para 4K. Através da APIYI (apiyi.com), você pode alternar entre resoluções de forma flexível e ajustar conforme necessário.
Q4: O que fazer ao encontrar erros 429 frequentes?
O erro 429 indica que você atingiu o limite de taxa (rate limit). Soluções: (1) reduza o número de requisições simultâneas; (2) utilize um limitador de taxa (token bucket) para distribuir as requisições uniformemente; (3) implemente uma estratégia de repetição com backoff exponencial; (4) para tarefas em lote, utilize a Batch API. Se encontrar problemas de limitação na plataforma APIYI, entre em contato com o suporte para aumentar sua cota de RPM.
Q5: Como estimar o custo total de uma geração em lote?
Use a fórmula: Custo Total = Quantidade de Imagens × Preço Unitário. Por exemplo, para gerar 1.000 imagens em 1K: no modo padrão, 1.000 × $0,067 = $67; no modo Batch, 1.000 × $0,034 = $34. Os preços na APIYI (apiyi.com) são iguais aos oficiais e oferecem recargas flexíveis, ideais para uso sob demanda.
Resumo: Encontre o melhor esquema de concorrência para a API Nano Banana 2
A otimização de concorrência da API Nano Banana 2 não depende de "quanto a plataforma permite", mas sim de "quanto o seu pipeline consegue processar". Lembre-se destes 3 pontos fundamentais:
- A resolução decide tudo: Ao reduzir de 4K para 1K, a capacidade de concorrência aumenta 10 vezes e o custo cai 56%.
- A largura de banda é o verdadeiro gargalo: A codificação Base64 torna cada imagem 33% maior que o tamanho real; a pressão sobre a largura de banda é muito maior que a pressão sobre a CPU.
- Ajuste gradualmente, do menor para o maior: Comece com 5 conexões simultâneas, monitore o tempo de resposta e a taxa de erro, e aumente gradualmente até atingir o valor ideal.
Recomendamos utilizar a API Nano Banana 2 através da plataforma APIYI (apiyi.com), que não possui limites de concorrência, oferece 1000 RPM por usuário e mantém preços iguais aos oficiais. Assim, você pode focar em otimizar o desempenho do seu pipeline sem se preocupar com as restrições da plataforma.
Referências
-
Gemini 3.1 Flash Image Preview: Especificações do modelo e documentação da API
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview
- Link:
-
Gemini Image Generation API: Guia de uso da API de geração de imagens
- Link:
ai.google.dev/gemini-api/docs/image-generation
- Link:
-
Gemini API Rate Limits: Documentação oficial sobre limites de taxa
- Link:
ai.google.dev/gemini-api/docs/rate-limits
- Link:
-
Documentação de integração do APIYI Nano Banana 2: Instruções da interface de API unificada
- Link:
api.apiyi.com
- Link:
📝 Autor: Equipe APIYI | A equipe técnica da APIYI é especialista na área de API de geração de imagens com IA, oferecendo aos desenvolvedores acesso à API Nano Banana 2 via apiyi.com, com concorrência ilimitada e cobrança flexível.