「どれくらいの並行処理が適切か?」——これは Nano Banana 2 API を使用して画像をバッチ生成する際、開発者から最も多く寄せられる質問です。その答えはプラットフォームの制限ではなく、あなたの帯域幅とメモリがどれだけの Base64 画像データに耐えられるかにかかっています。
核心的価値: 本記事を読めば、Nano Banana 2 API の並行呼び出しにおけるボトルネックを把握し、自身のサーバー環境に基づいて最適な並行数を計算する方法を習得できます。さらに、実証済みのパフォーマンス最適化テクニックを 5 つ紹介します。
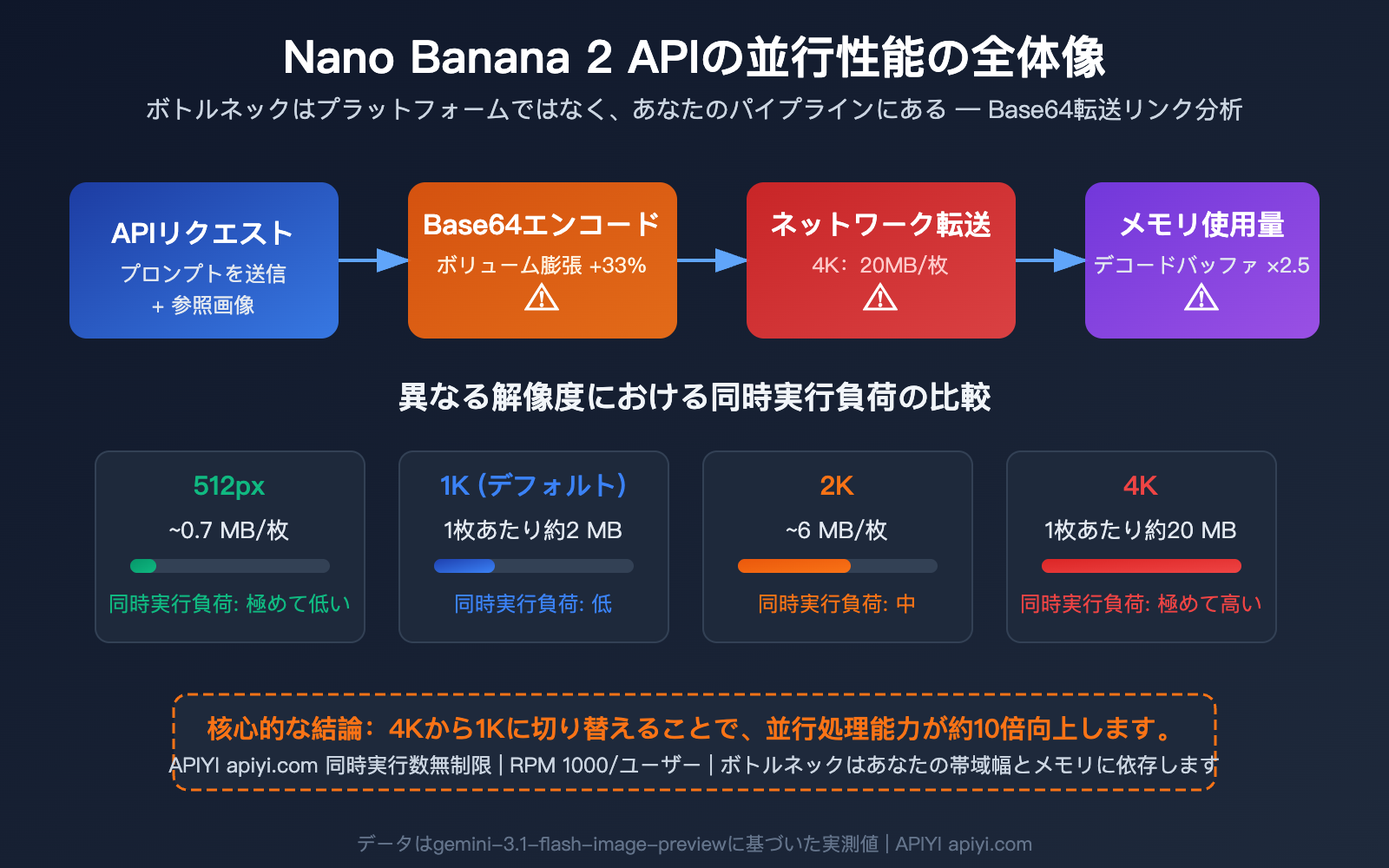
Nano Banana 2 API の並行処理における核心的な問題:ボトルネックはプラットフォームではなく、あなたのパイプラインにあります
多くの開発者が最初に抱く疑問は「プラットフォームはどれくらいの並行処理をサポートしているのか?」というものです。しかし実際には、APIYIプラットフォームは並行処理を制限しておらず、RPM(1分あたりのリクエスト数)はユーザーあたり1000回まで問題なくサポートしており、必要に応じてクォータ(割り当て)を追加することも可能です。
真のボトルネックはここにあります:Geminiの画像生成APIは、画像データの転送に Base64エンコーディング を使用しています。つまり、画像のアップロードとダウンロードは、効率的なバイナリストリームではなく、巨大なJSONテキストとして行われます。これが、あなたの帯域幅とメモリに多大な負荷をかけているのです。
なぜBase64が並行処理の核心的なボトルネックなのか
Gemini公式API(Nano Banana 2に対応する gemini-3.1-flash-image-preview を含む)は、画像の転送にBase64エンコーディング方式のみをサポートしています。Base64エンコーディングはバイナリデータを約 33% 膨張させます。つまり、以下のようになります。
| 解像度 | 元の画像サイズ | Base64エンコード後 | APIレスポンスの単体サイズ |
|---|---|---|---|
| 512px (0.5K) | ~400 KB | ~530 KB | ~600 KB – 1 MB |
| 1K (デフォルト) | ~1.5 MB | ~2 MB | ~2 MB |
| 2K | ~4 MB | ~5.3 MB | ~5-8 MB |
| 4K | ~15 MB | ~20 MB | ~20 MB |
4K画像のAPIレスポンスは 20 MB にも達します。もし10個の4K並行リクエストを同時に送信した場合、レスポンスデータだけで 200 MB がネットワークとメモリ上を流れることになります。
Nano Banana 2 API モデルパラメータ早見表
| パラメータ | 値 |
|---|---|
| モデルID | gemini-3.1-flash-image-preview |
| 入力コンテキスト | 131,072 トークン |
| 出力上限 | 32,768 トークン |
| サポート解像度 | 512px / 1K / 2K / 4K |
| サポートアスペクト比 | 1:1, 3:2, 4:3, 16:9, 9:16, 21:9 など14種類 |
| 最大参照画像数 | 14枚 (物体10枚 + キャラクター4枚) |
| 生成速度 | 3-5 秒/枚 |
| APIYI RPM | 1000/ユーザー (クォータ追加可能) |
| APIYI 並行制限 | 無制限 |
🎯 技術アドバイス: APIYI apiyi.com プラットフォームでは、Nano Banana 2 の並行処理を制限しておらず、RPMはユーザーあたり1000回をサポートしています。ボトルネックはあなたのローカル環境にあります。帯域幅とメモリが、実際に実行可能な並行数を決定します。
Nano Banana 2 API 並行数の計算:環境に応じた最適なプランの選択
並行数をいくつにするかは、勘で決めるものではなく、実際の環境に基づいて計算する必要があります。重要な指標は、帯域幅、メモリ、ターゲット解像度の3つです。
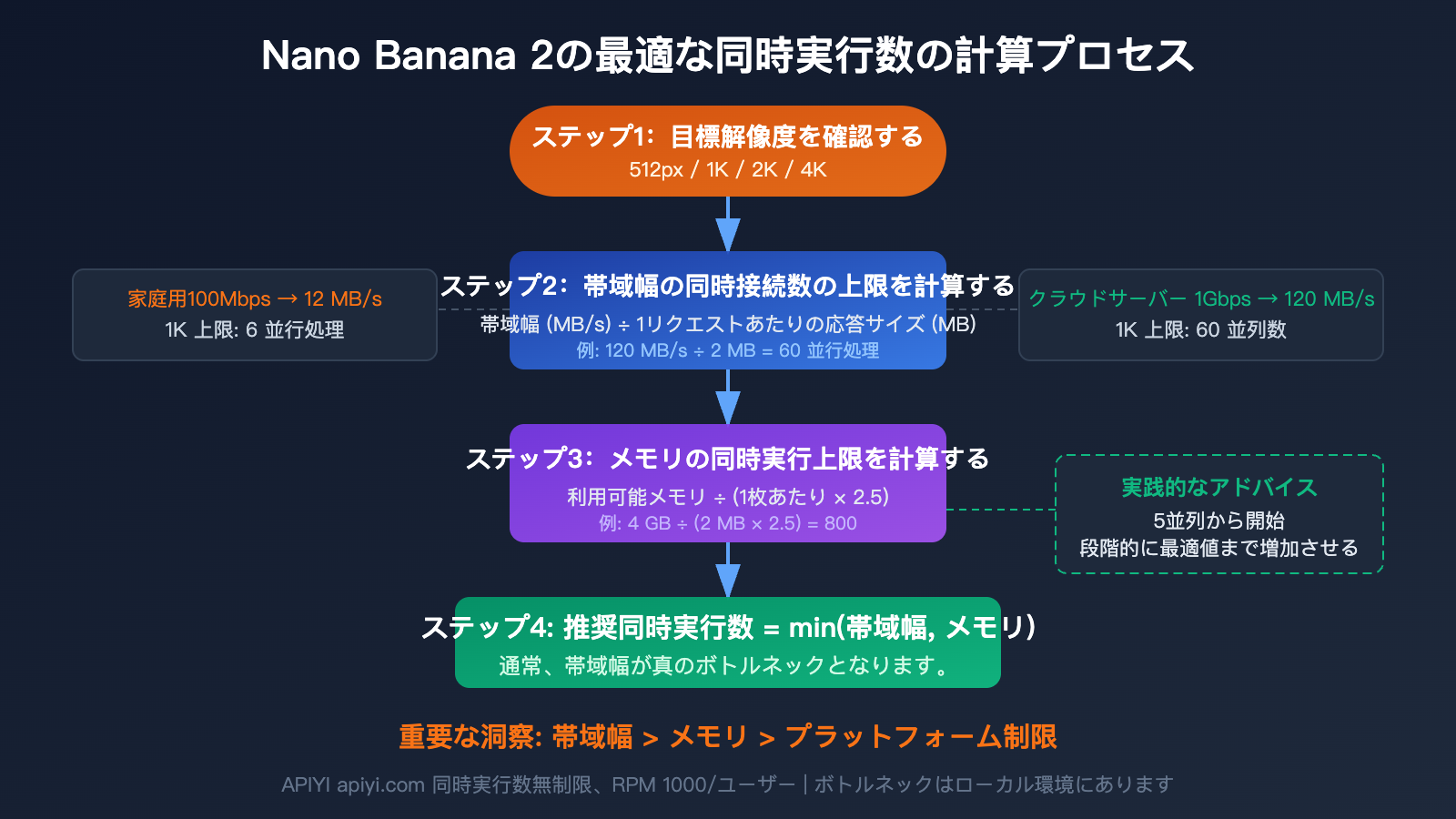
第一步:帯域幅を確認する
帯域幅は、同時に転送できるデータ量を決定します。計算式は以下の通りです:
最大並行数 (帯域幅) = 利用可能な帯域幅 (MB/s) ÷ 単体レスポンスサイズ (MB)
| ネットワーク環境 | 利用可能な帯域幅 | 1K 並行上限 | 2K 並行上限 | 4K 並行上限 |
|---|---|---|---|---|
| 家庭用ブロードバンド (100Mbps) | ~12 MB/s | 6 | 2 | 0-1 |
| 企業ネットワーク (500Mbps) | ~60 MB/s | 30 | 10 | 3 |
| クラウドサーバー (1Gbps) | ~120 MB/s | 60 | 20 | 6 |
| 高性能サーバー (10Gbps) | ~1200 MB/s | 600 | 200 | 60 |
第二步:利用可能なメモリを確認する
各並行リクエストは、デコードとディスクへの書き込みが完了するまで、Base64レスポンスデータをメモリ内に完全に保持する必要があります。メモリの計算式は以下の通りです:
必要なメモリ = 並行数 × 単体レスポンスサイズ × 2.5 (デコードバッファ係数)
2.5を掛けているのは、Base64デコードの過程で、元の文字列とデコード後のバイナリデータがメモリ上に同時に存在するためであり、さらにJSON解析のオーバーヘッドも考慮しているためです。
| 利用可能なメモリ | 1K 並行上限 | 2K 並行上限 | 4K 並行上限 |
|---|---|---|---|
| 2 GB | 400 | 100 | 40 |
| 4 GB | 800 | 200 | 80 |
| 8 GB | 1600 | 400 | 160 |
第三步:両者の小さい方の値をとる
最終的な推奨並行数 = min(帯域幅による並行上限, メモリによる並行上限)
実際の運用において、ほとんどのシナリオで 帯域幅が真のボトルネック であり、メモリではありません。
実際のシナリオにおける推奨並行数
| シナリオ | 推奨解像度 | 推奨並行数 | 予想スループット |
|---|---|---|---|
| 個人開発/テスト | 1K | 3-5 | ~1 枚/秒 |
| 小規模チームのバッチ生成 | 1K | 10-20 | ~4 枚/秒 |
| 企業向け本番環境 | 1K-2K | 20-50 | ~10 枚/秒 |
| 高スループット画像サービス | 1K | 50-100 | ~20 枚/秒 |
| 4K高精細画像が必要な場合 | 4K | 3-5 | ~1 枚/秒 |
💡 実践的なアドバイス: 並行数をいくつにするか迷った場合は、5から開始し、10、20と段階的に増やして、レスポンス時間とエラー率を観察してください。レスポンス時間が明らかに上昇したり、タイムアウトが発生したりする場合は、ボトルネックに近づいていることを意味します。APIYI apiyi.com プラットフォームでテストする際は、プラットフォーム側の制限を心配する必要はありません。ローカル環境のパフォーマンスに集中してください。
Nano Banana 2 API クイックスタート:3ステップで統合完了
ステップ1: 依存関係のインストール
pip install openai Pillow
ステップ2: シンプルな呼び出しサンプル
import openai
import base64
from pathlib import Path
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": "Generate a cute cat wearing sunglasses on a beach"
}
]
)
# Base64画像データを抽出して保存
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
img_bytes = base64.b64decode(part.image.data)
Path("output.png").write_bytes(img_bytes)
print("画像を保存しました: output.png")
並行バッチ生成の完全なコードを表示
import openai
import base64
import asyncio
import aiohttp
import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
# 設定パラメータ
MAX_CONCURRENCY = 10 # 最大並行数、帯域幅に合わせて調整してください
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
def generate_single_image(prompt: str, index: int) -> dict:
"""単一画像を生成して即座に保存し、メモリを解放する"""
start = time.time()
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# 即座にデコードして保存し、Base64文字列によるメモリ占有を防ぐ
img_bytes = base64.b64decode(part.image.data)
filepath = OUTPUT_DIR / f"image_{index:04d}.png"
filepath.write_bytes(img_bytes)
elapsed = time.time() - start
size_mb = len(img_bytes) / (1024 * 1024)
return {
"index": index,
"success": True,
"time": elapsed,
"size_mb": size_mb,
"path": str(filepath)
}
except Exception as e:
return {
"index": index,
"success": False,
"error": str(e),
"time": time.time() - start
}
def batch_generate(prompts: list[str]):
"""スレッドプールを使用して画像を並行生成する"""
results = []
total = len(prompts)
completed = 0
with ThreadPoolExecutor(max_workers=MAX_CONCURRENCY) as executor:
futures = {
executor.submit(generate_single_image, p, i): i
for i, p in enumerate(prompts)
}
for future in futures:
result = future.result()
completed += 1
status = "OK" if result["success"] else "FAIL"
print(f"[{completed}/{total}] {status} - {result['time']:.1f}s")
results.append(result)
# 集計
success = [r for r in results if r["success"]]
print(f"\n完了: {len(success)}/{total} 成功")
if success:
avg_time = sum(r["time"] for r in success) / len(success)
total_size = sum(r["size_mb"] for r in success)
print(f"平均処理時間: {avg_time:.1f}s | 合計サイズ: {total_size:.1f} MB")
# 使用例
prompts = [
"A futuristic city at sunset",
"A cozy coffee shop interior",
"An underwater coral reef scene",
"A mountain landscape with aurora",
"A cute robot playing guitar",
]
batch_generate(prompts)
ステップ3: 参照画像のアップロード (画像から画像生成)
画像から画像生成を行う場合は、参照画像をアップロードする必要があります。こちらもBase64エンコードを使用します:
import base64
# ローカル画像を読み込んでBase64に変換
with open("reference.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "この写真を水彩画風に変換してください"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{img_base64}"
}
}
]
}
]
)
注意: 参照画像をアップロードする際、リクエスト全体のサイズは 20 MB を超えてはいけません。参照画像が大きい場合は、事前に1K解像度以下に圧縮することをお勧めします。
Nano Banana 2 API 並行処理最適化の5つの実践テクニック
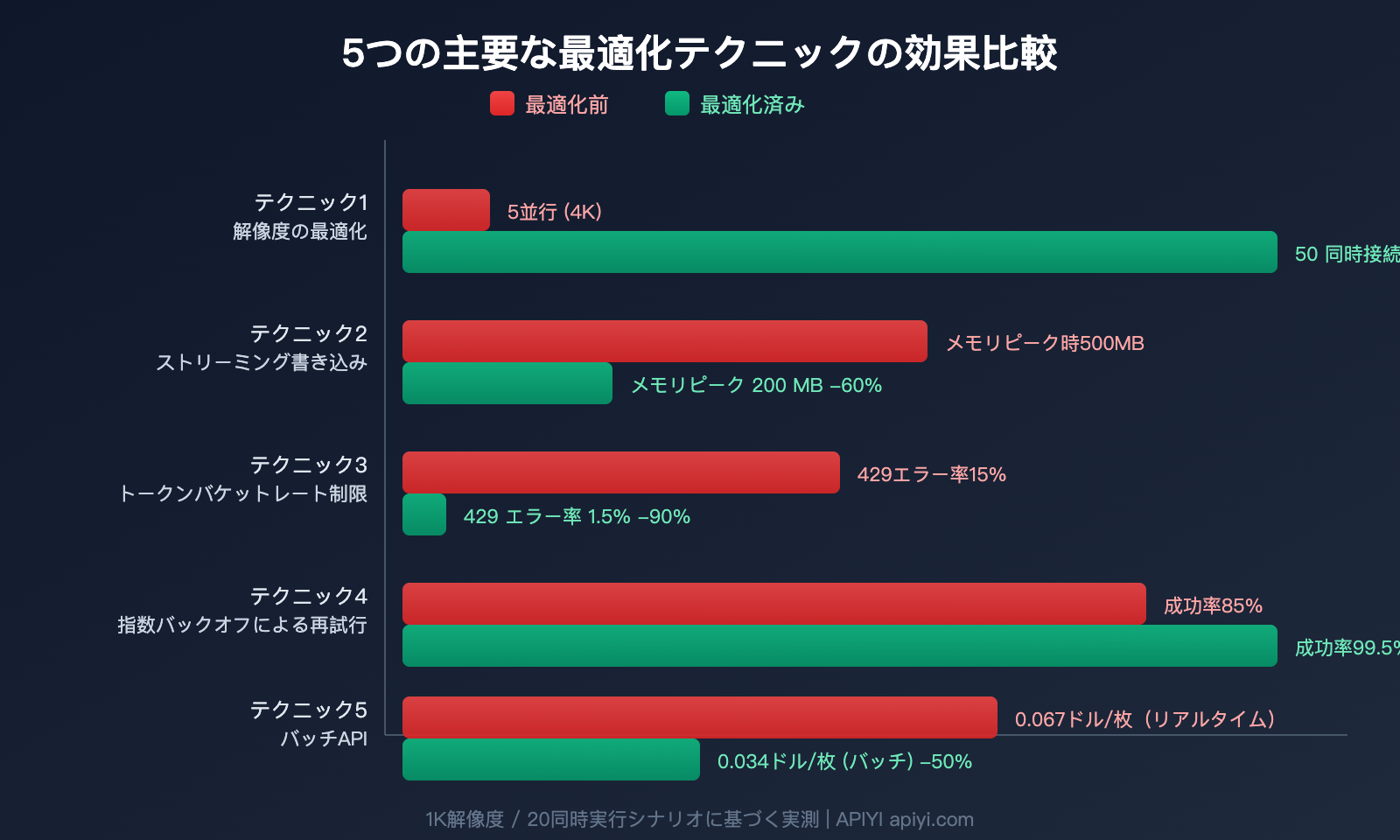
技巧1:用途に合わせて解像度を選択し、デフォルトの4Kを避ける
これは最もシンプルで効果的な最適化です。多くの開発者がデフォルトで4Kをリクエストしますが、実際の用途では1Kで十分な場合がほとんどです:
| 用途 | 推奨解像度 | 1枚あたりの容量 | 並行効率 |
|---|---|---|---|
| SNS用画像 | 1K | ~2 MB | 高 |
| EC商品画像 | 2K | ~6 MB | 中 |
| 印刷/ポスター | 4K | ~20 MB | 低 |
| プレビュー/サムネイル | 512px | ~0.7 MB | 極めて高 |
4Kから1Kに切り替えるだけで、同条件下での並行処理能力が約10倍向上します。
技巧2:ストリーミング受信と即時書き込み
JSONレスポンス全体が到着するのを待ってから処理してはいけません。ストリーミング受信を利用し、受信しながらデコードし、即座にディスクへ書き込みます:
import gc
def generate_and_save(prompt, filepath):
"""画像を生成して即座に保存し、メモリを積極的に解放する"""
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# 即座にデコード
img_bytes = base64.b64decode(part.image.data)
# Base64文字列の参照を即座に削除
del part.image.data
# 即座にディスクへ書き込み
Path(filepath).write_bytes(img_bytes)
del img_bytes
gc.collect() # ガベージコレクションを明示的に実行
技巧3:トークンバケットによる並行処理のペース制御
すべてのリクエストを一度に送信せず、トークンバケットアルゴリズムを使用してリクエストを均等に分散させます:
import threading
import time
class TokenBucket:
"""トークンバケットによるレートリミッター"""
def __init__(self, rate: float, capacity: int):
self.rate = rate # 1秒あたりの補充レート
self.capacity = capacity # バケット容量
self.tokens = capacity
self.lock = threading.Lock()
self.last_refill = time.monotonic()
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.rate
)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep(0.05)
# 使用例: 1秒あたり最大10リクエスト、バースト時最大20
limiter = TokenBucket(rate=10, capacity=20)
def rate_limited_generate(prompt, index):
limiter.acquire() # トークンを待機
return generate_single_image(prompt, index)
技巧4:指数バックオフによる429エラーへの対応
レート制限(HTTP 429)が発生した場合は、指数バックオフ戦略を使用します:
import random
def generate_with_retry(prompt, index, max_retries=5):
"""指数バックオフを用いたリトライ機構"""
for attempt in range(max_retries):
try:
return generate_single_image(prompt, index)
except openai.RateLimitError:
delay = min(60, (2 ** attempt)) + random.uniform(0, 0.5)
print(f"レート制限のため、{delay:.1f}秒待機してリトライします...")
time.sleep(delay)
return {"index": index, "success": False, "error": "最大リトライ回数超過"}
技巧5:バッチ処理にはBatch APIを使用してコストを50%削減
リアルタイム性が不要なバッチタスクについては、Nano Banana 2のBatch APIを利用することでコストを半分に抑えられます:
| モード | 1K画像単価 | 4K画像単価 | 遅延 | 適した用途 |
|---|---|---|---|---|
| リアルタイムAPI | $0.067 | $0.151 | 3-5秒 | インタラクティブなアプリ |
| Batch API | $0.034 | $0.076 | 数分〜数時間 | 大量の一括生成 |
💰 コスト最適化: 待ち時間が許容される場合、APIYI apiyi.com を通じてBatch APIを呼び出すことでコストを50%削減できます。ECサイトの商品画像の一括生成や、マーケティング素材の事前作成などに最適です。
Nano Banana 2 API の解像度別コストとトークン消費の詳細
トークン消費量を理解することで、コストをより効率的に管理できるようになります。
| 解像度 | 出力トークン消費量 | 標準価格 | Batch価格 (50%OFF) | 100枚あたりのコスト |
|---|---|---|---|---|
| 512px | 747トークン | $0.045 | $0.022 | $4.50 / $2.20 |
| 1K | 1,120トークン | $0.067 | $0.034 | $6.70 / $3.40 |
| 2K | 1,680トークン | $0.101 | $0.050 | $10.10 / $5.00 |
| 4K | 2,520トークン | $0.151 | $0.076 | $15.10 / $7.60 |
🚀 クイックスタート: APIYI (apiyi.com) プラットフォームを通じて Nano Banana 2 を呼び出すことができます。価格は公式と同等で、同時実行数制限なし、RPMはユーザーあたり1000まで対応しています。登録するだけでテスト用クレジットを獲得可能です。
Nano Banana 2 と旧世代モデルの比較
| 比較項目 | Nano Banana | Nano Banana Pro | Nano Banana 2 |
|---|---|---|---|
| モデルID | gemini-2.5-flash (画像) | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview |
| 最大解像度 | 1024×1024 | 4K | 4K |
| 1K 単価 | $0.039 | $0.134 | $0.067 |
| 4K 単価 | 非対応 | $0.240 | $0.151 |
| 生成速度 | 2-4 秒 | 5-8 秒 | 3-5 秒 |
| Batch API | 非対応 | 非対応 | 対応 (50%OFF) |
| 参照画像上限 | 5 枚 | 10 枚 | 14 枚 |
| APIYIで利用可能 | ✅ | ✅ | ✅ |
Nano Banana 2 は Pro バージョンと比較して、4K の価格が 37% 低減、速度が 40% 向上しており、さらに Batch API にも新たに対応しています。
Nano Banana 2 API 並行パフォーマンス監視
並行タスクを実際に実行する際は、以下の指標を監視することをお勧めします。
import psutil
import time
class PerformanceMonitor:
"""並行パフォーマンス監視ツール"""
def __init__(self):
self.start_time = time.time()
self.request_count = 0
self.total_bytes = 0
self.errors = 0
def record(self, success: bool, size_bytes: int = 0):
self.request_count += 1
if success:
self.total_bytes += size_bytes
else:
self.errors += 1
def report(self):
elapsed = time.time() - self.start_time
mem = psutil.Process().memory_info().rss / (1024**2)
print(f"--- パフォーマンスレポート ---")
print(f"実行時間: {elapsed:.1f}s")
print(f"完了リクエスト数: {self.request_count}")
print(f"成功率: {(self.request_count-self.errors)/max(1,self.request_count)*100:.1f}%")
print(f"スループット: {self.request_count/elapsed:.2f} req/s")
print(f"データ量: {self.total_bytes/(1024**2):.1f} MB")
print(f"帯域幅使用量: {self.total_bytes/(1024**2)/elapsed:.1f} MB/s")
print(f"メモリ使用量: {mem:.0f} MB")
よくある質問
Q1: APIYIプラットフォームで Nano Banana 2 の並行数に制限はありますか?
APIYIプラットフォームでは、Nano Banana 2 の並行数に制限を設けていません。RPM(1分あたりのリクエスト数)はデフォルトでユーザーあたり1000回までサポートしており、それ以上の要件がある場合はカスタマーサポートまでご連絡いただければ個別にクォータを追加可能です。実際の並行処理のボトルネックは、お客様のローカル帯域幅とメモリに依存します。APIYI(apiyi.com)プラットフォームを通じて実際にテストを行い、ご自身の環境における最適な並行数を見つけることをお勧めします。
Q2: Gemini 画像 API が Base64 転送のみに対応しているのはなぜですか?
これは Google Gemini API の現在の設計によるものです。Base64 エンコーディングを使用することで、画像データを JSON レスポンスに直接埋め込むことができ、追加のファイルストレージや CDN 配信が不要になります。欠点として、データサイズが約33%増加するため、帯域幅やメモリ消費の面で効率的ではありません。開発者コミュニティからは JPEG 形式の出力や一時的な URL ダウンロードオプションの追加を Google に要望していますが、現時点では未実装です。
Q3: 1K と 4K 解像度で効果に大きな違いはありますか?
使用シーンによります。SNS 用の画像、Web 表示、アプリのインターフェースなどの用途であれば、1K 解像度で十分であり、肉眼で違いを感じることはほとんどありません。4K は主に印刷物、ポスター、高精細な壁紙など、細部を拡大して確認する必要があるシーン向けです。まずは 1K で効果をテストし、より高い鮮明度が必要だと判断した場合に 4K に切り替えることをお勧めします。APIYI(apiyi.com)を通じて解像度を柔軟に切り替え、いつでも調整可能です。
Q4: 頻繁に 429 エラーが発生する場合はどうすればよいですか?
429 エラーはレート制限に達したことを示しています。解決策として以下をお試しください:(1) 並行数を減らす、(2) トークンバケットアルゴリズムなどのレートリミッターを使用してリクエストを均等に分散させる、(3) 指数バックオフによる再試行を実装する、(4) 大量タスクの場合は Batch API に切り替える。APIYI プラットフォームでレート制限に遭遇した場合は、カスタマーサポートに連絡して RPM クォータの増量を依頼してください。
Q5: 大量生成の総コストを概算するにはどうすればよいですか?
「総コスト = 画像枚数 × 単価」の計算式を使用します。例えば 1K 画像を 1000 枚生成する場合:標準モードでは 1000 × $0.067 = $67、Batch モードでは 1000 × $0.034 = $34 となります。APIYI(apiyi.com)の価格は公式と同一であり、柔軟なチャージに対応しているため、必要な分だけ利用するのに適しています。
まとめ: Nano Banana 2 API の最適な並行処理戦略を見つける
Nano Banana 2 API の並行処理最適化において重要なのは、「プラットフォームがどれだけ許可しているか」ではなく、「あなたのパイプラインがどれだけ処理できるか」です。以下の3つのポイントを覚えておきましょう。
- 解像度がすべてを決める: 4K から 1K に下げるだけで、並行処理能力は10倍向上し、コストは56%削減できます。
- 帯域幅が真のボトルネック: Base64 エンコーディングは各画像を実サイズより33%大きくするため、CPUよりも帯域幅への負荷がはるかに大きくなります。
- 小さく始めて段階的に調整: 5並行から開始し、応答時間とエラー率を監視しながら、最適な値まで徐々に引き上げてください。
APIYI (apiyi.com) プラットフォーム経由での Nano Banana 2 API 呼び出しを推奨します。並行数制限なし、RPM 1000/ユーザー、価格は公式と同等です。プラットフォーム側の制限を気にすることなく、自身のパイプライン性能の最適化に集中できます。

参考資料
-
Gemini 3.1 Flash Image Preview: モデル仕様および API ドキュメント
- リンク:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview
- リンク:
-
Gemini Image Generation API: 画像生成 API 利用ガイド
- リンク:
ai.google.dev/gemini-api/docs/image-generation
- リンク:
-
Gemini API Rate Limits: 公式レート制限ドキュメント
- リンク:
ai.google.dev/gemini-api/docs/rate-limits
- リンク:
-
APIYI Nano Banana 2 接続ドキュメント: 統合 API インターフェース仕様
- リンク:
api.apiyi.com
- リンク:
📝 著者: APIYI Team | APIYI 技術チームは AI 画像生成 API 分野に深く注力しており、apiyi.com を通じて開発者の皆様に、同時接続数無制限かつ柔軟な料金体系の Nano Banana 2 API 接続サービスを提供しています。