La série Grok 4.20 Beta de xAI est désormais officiellement disponible sur la plateforme APIYI. Nous ajoutons 4 nouveaux modèles d'un coup, couvrant tous les besoins, de la réponse rapide à la recherche approfondie multi-agents. Avec un tarif de 2 $ en entrée et 6 $ en sortie par million de tokens, c'est l'un des meilleurs rapports qualité-prix parmi les modèles phares actuels.
Ces 4 modèles ne sont pas de simples mises à jour de version, mais reposent sur des architectures distinctes : certains privilégient la vitesse de réponse, d'autres le raisonnement profond, et l'un d'entre eux permet à 4 agents IA de collaborer simultanément, réduisant le taux d'hallucination de 65 %.
Valeur ajoutée : En lisant cet article, vous comprendrez le positionnement et les cas d'usage optimaux de chaque modèle Grok 4.20 Beta, apprendrez à les appeler via l'API et pourrez prendre la meilleure décision pour vos projets.
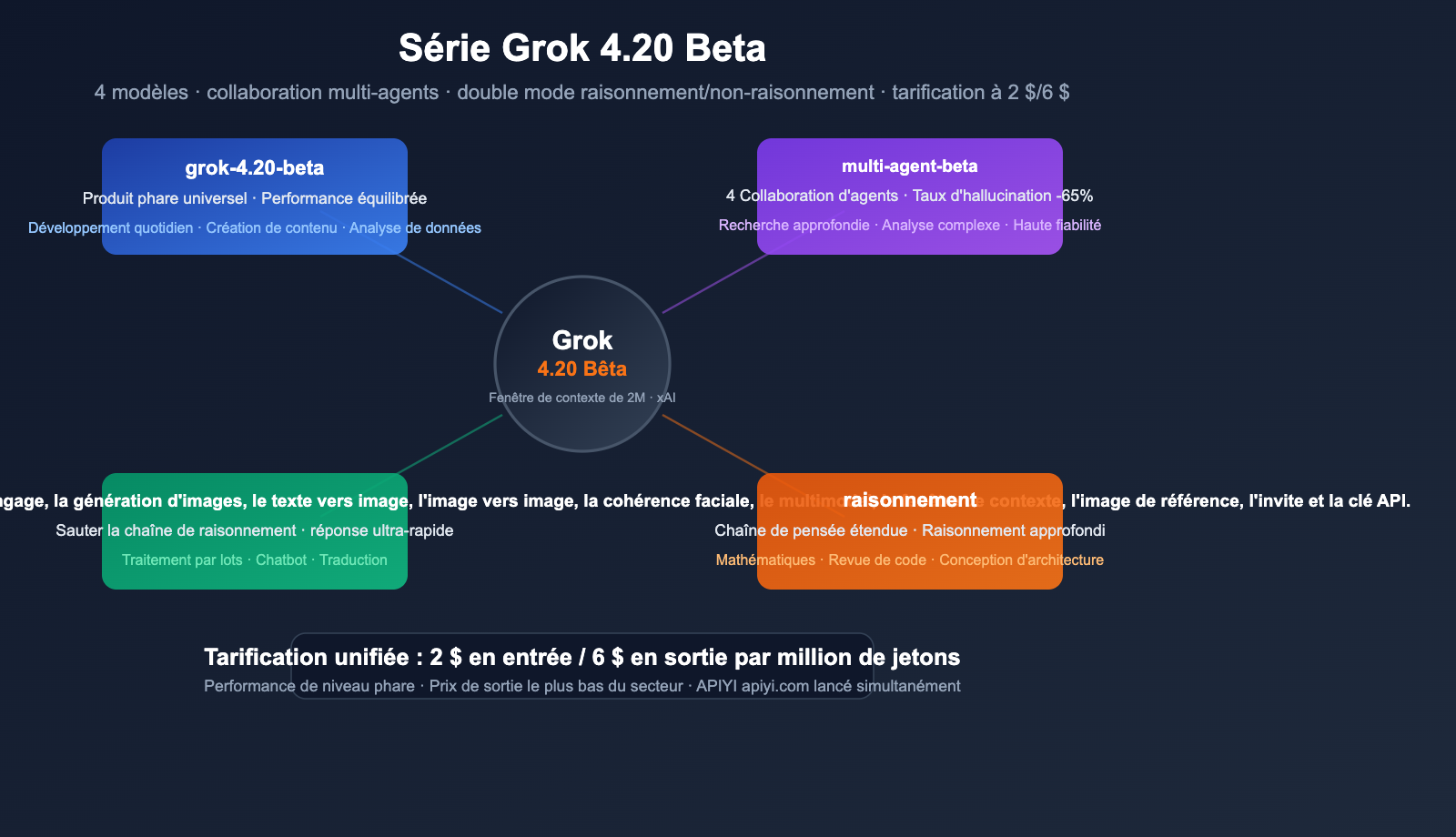
Aperçu des 4 modèles : Guide rapide des différences clés
Matrice des modèles
| ID du modèle | Positionnement | Caractéristiques principales | Cas d'usage idéal |
|---|---|---|---|
grok-4.20-beta |
Flagship généraliste | Équilibre performance/vitesse | Développement quotidien, tâches générales |
grok-4.20-multi-agent-beta-0309 |
Collaboration multi-agents | 4 agents travaillant en parallèle | Recherche approfondie, analyse complexe |
grok-4.20-beta-0309-non-reasoning |
Réponse rapide | Sans chaîne de réflexion, faible latence | Traitement par lots, questions simples |
grok-4.20-beta-0309-reasoning |
Raisonnement profond | Chaîne de pensée étendue | Mathématiques, analyse de code, logique |
Tarification unifiée
| Poste de facturation | Prix |
|---|---|
| Token d'entrée | 2,00 $ / million de tokens |
| Token de sortie | 6,00 $ / million de tokens |
| Fenêtre de contexte | 2 millions de tokens (2M) |
| Remise par lots | 50 % |
Comparaison des prix avec la concurrence :
| Modèle | Prix entrée | Prix sortie | Rapport qualité-prix |
|---|---|---|---|
| Grok 4.20 Beta | 2,00 $ | 6,00 $ | 🟢 Optimal |
| Gemini 3.1 Pro | 2,00 $ | 12,00 $ | Bon |
| GPT-5.4 | 2,50 $ | 15,00 $ | Moyen |
| Claude Sonnet 4.6 | 3,00 $ | 15,00 $ | Moyen |
| Claude Opus 4.6 | 15,00 $ | 75,00 $ | Élevé |
Le prix de sortie de Grok 4.20 ne représente que 40 % de celui de Claude Sonnet 4.6 et 8 % de celui de Claude Opus 4.6. Pour les tâches intensives en sortie (génération de code, textes longs), l'avantage en termes de coûts est extrêmement significatif.
🎯 Note sur la tarification : La série Grok 4.20 Beta disponible sur APIYI (apiyi.com) suit la même tarification que le site officiel de xAI (2 $ entrée / 6 $ sortie), avec des remises supplémentaires via les offres de recharge de la plateforme. Une seule clé API permet d'appeler plus de 200 modèles, dont Grok, Claude et GPT.
Analyse approfondie de 4 modèles
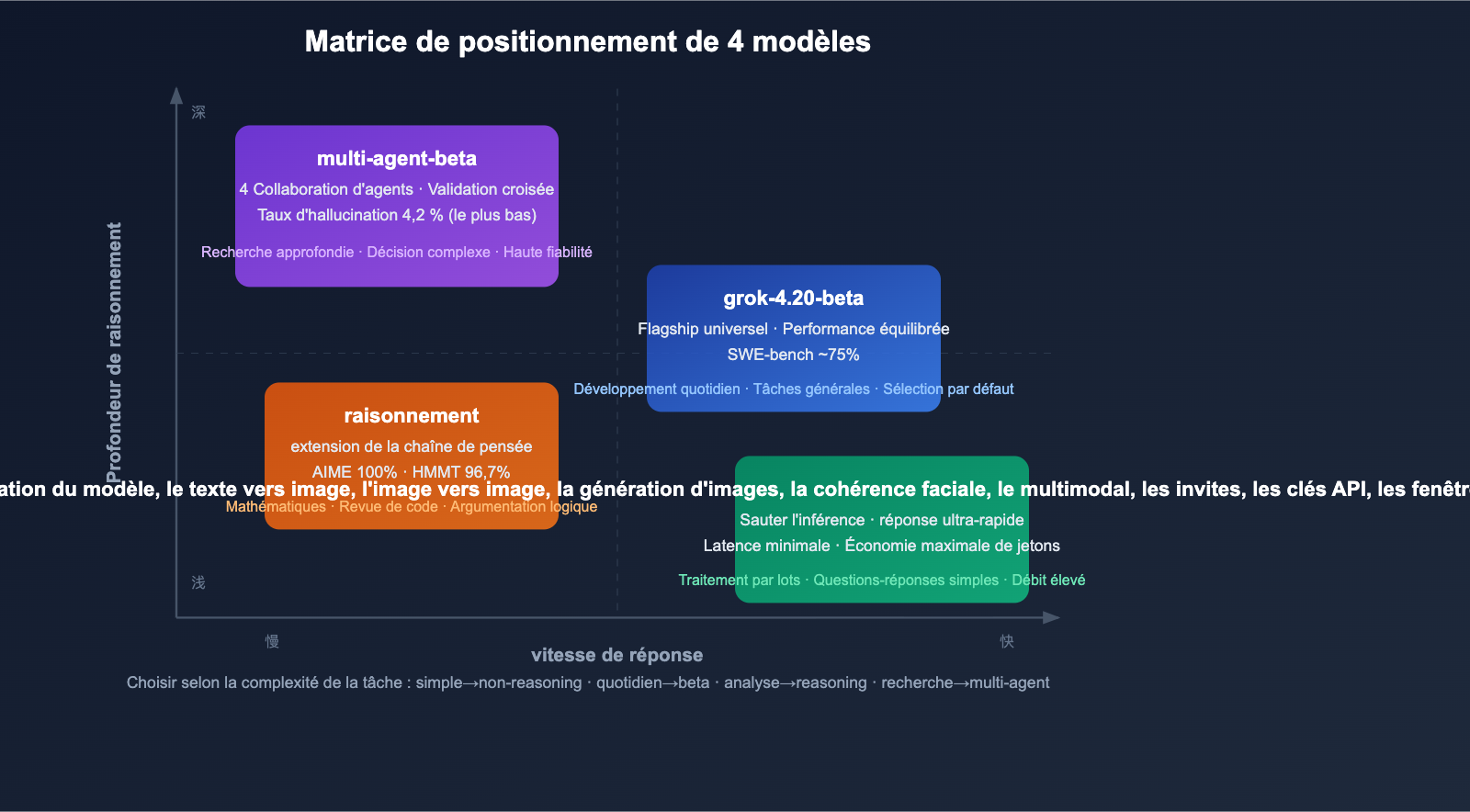
Modèle 1 : grok-4.20-beta (Flagship généraliste)
Il s'agit du point d'entrée par défaut de la série Grok 4.20, offrant un équilibre optimal entre performance, vitesse et coût.
Caractéristiques principales :
- Hérite de toutes les capacités de la famille Grok 4
- Fenêtre de contexte de 2 millions de jetons — la plus large parmi les modèles occidentaux de pointe
- Supporte les entrées images (JPG/PNG)
- Amélioration continue hebdomadaire basée sur des retours réels
Performances de référence :
- SWE-bench : ~75 % (proche des 74,9 % de GPT-5)
- GPQA (niveau master) : 88,4 %
- Arena Elo : ~1 505-1 535
Cas d'usage : Aide à la programmation au quotidien, création de contenu, analyse de données, conversation générale.
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "Implémente un cache LRU en Python"}
]
)
print(response.choices[0].message.content)
Modèle 2 : grok-4.20-multi-agent-beta-0309 (Multi-agents)
C'est la variante la plus innovante de Grok 4.20 : 4 agents IA collaborent simultanément pour traiter votre requête.
Les 4 agents et leurs rôles :
| Agent | Rôle | Spécialité |
|---|---|---|
| Grok (Capitaine) | Coordinateur | Décomposition de tâches, gestion de flux, agrégation des résultats |
| Harper | Chercheur | Recherche de données en temps réel, vérification des faits (accès aux données X/Twitter) |
| Benjamin | Analyste | Raisonnement logique, calculs mathématiques, analyse de code |
| Lucas | Challenger | Synthèse créative, position contradictoire intégrée — remet en question les conclusions des autres agents |
Flux de travail :
Question utilisateur
↓
Grok décompose la tâche → distribue aux 4 agents
↓
Harper collecte les données | Benjamin analyse la logique | Lucas conteste
↓
Débat interne entre agents + vérification croisée
↓
Grok agrège le consensus → renvoie la réponse finale
Point fort : réduction du taux d'hallucination de 65 % :
| Indicateur | Base modèle unique | Mode multi-agents | Amélioration |
|---|---|---|---|
| Taux d'hallucination | ~12 % | ~4,2 % | -65 % |
| Taux de "je ne sais pas" | — | 78 % | Meilleur du secteur |
La "position contradictoire intégrée" de Lucas est cruciale : son rôle est de trouver les failles dans les conclusions des autres. Cette collaboration antagoniste rend le résultat final beaucoup plus fiable.
Cas d'usage : Rapports de recherche approfondis, analyse de décisions complexes, besoins de haute fiabilité.
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "Analyse le paysage concurrentiel et les tendances du marché des outils de programmation IA en 2026"}
]
)
Modèle 3 : grok-4.20-beta-0309-non-reasoning (Non-raisonnement)
Une variante optimisée pour la vitesse et le débit. Il ignore la chaîne de pensée interne (Chain-of-Thought) pour générer une réponse directe.
Caractéristiques principales :
- Faible latence, débit élevé
- Aucun jeton de raisonnement interne généré, économie sur les coûts de sortie
- Idéal pour les tâches simples et directes
Cas d'usage :
- Appels API haute fréquence (traitement de données par lots)
- Chatbots / Systèmes de service client
- Classification de contenu, extraction d'étiquettes
- Complétion de code simple
- Traduction, résumé
Non recommandé pour : Déductions mathématiques complexes, analyse logique multi-étapes, conception d'architecture nécessitant une réflexion profonde.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "Convertis le JSON suivant au format CSV : ..."}
]
)
Modèle 4 : grok-4.20-beta-0309-reasoning (Raisonnement)
La variante dédiée au raisonnement approfondi. Elle active une chaîne de pensée étendue (Extended Chain-of-Thought) pour effectuer une réflexion interne poussée avant de répondre.
Caractéristiques principales :
- Jetons de raisonnement étendus pour une analyse profonde des problèmes
- Excellentes performances en mathématiques et logique (AIME 2025 : 100 %, HMMT25 : 96,7 %)
- Indice d'intelligence Artificial Analysis : 48
Cas d'usage :
- Preuves et déductions mathématiques
- Revue de code et analyse de bugs
- Arbitrages de conception d'architecture
- Argumentation logique complexe
- Analyse de publications académiques
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "Analyse les risques de conditions de concurrence et d'interblocage dans ce code concurrent"}
]
)
💡 Conseil de sélection : Pour la plupart des tâches quotidiennes,
grok-4.20-betasuffit. Utilisez la version multi-agents pour une haute fiabilité, la version non-raisonnement pour le traitement par lots, et la version raisonnement pour les analyses complexes. Grâce à APIYI (apiyi.com), une seule clé API suffit pour appeler ces 4 modèles et basculer selon vos besoins.
Arbre de décision pour la sélection de modèles
Choisir selon le type de tâche
| Type de tâche | Modèle recommandé | Raison |
|---|---|---|
| Assistance à la programmation quotidienne | grok-4.20-beta |
Équilibre entre performance et coût |
| Traitement de données par lots | non-reasoning |
Vitesse maximale, latence minimale |
| Revue de code / Analyse de bugs | reasoning |
Nécessite un raisonnement approfondi |
| Rédaction de rapports de recherche | multi-agent |
Validation croisée par 4 agents |
| Analyse de données en temps réel | multi-agent |
Harper accède aux données X en temps réel |
| Déduction mathématique/logique | reasoning |
100 % de réussite au AIME |
| Chatbot | non-reasoning |
Réponse rapide avec faible latence |
| Traduction/Résumé de contenu | non-reasoning |
Tâches simples sans besoin de raisonnement |
| Conception d'architecture | reasoning ou multi-agent |
Nécessite une analyse comparative |
Choisir selon la sensibilité au coût
Économies extrêmes → non-reasoning (pas de jetons de raisonnement, sortie minimale)
↓
Rapport qualité-prix quotidien → grok-4.20-beta (équilibre général)
↓
Qualité prioritaire → reasoning (raisonnement approfondi, plus de jetons de sortie)
↓
Fiabilité maximale → multi-agent (4 agents, sortie la plus détaillée)
🚀 Démarrage rapide : Nous recommandons de commencer par
grok-4.20-beta. Inscrivez-vous via APIYI sur apiyi.com pour obtenir votre clé API. La tarification est identique à celle du site officiel de xAI (2 $ en entrée / 6 $ en sortie), avec des remises appliquées lors des recharges.
Comparatif : Grok 4.20 vs Modèles dominants
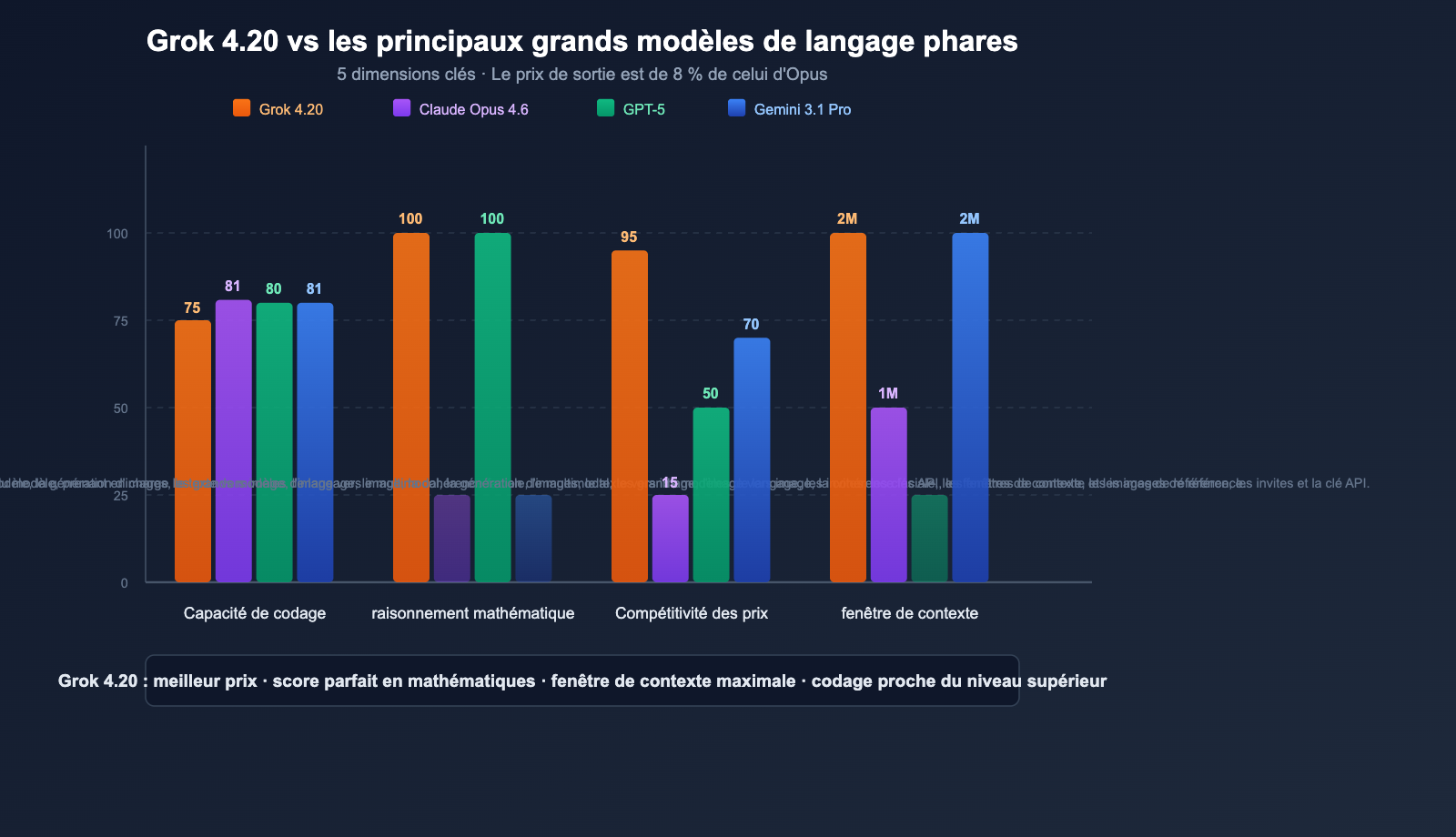
Comparaison multidimensionnelle
| Dimension | Grok 4.20 Beta | Claude Opus 4.6 | Série GPT-5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81,4% | ~80% | ~80,6% |
| Mathématiques (AIME) | 100% | — | 100% | — |
| GPQA | 88,4% | — | — | — |
| Fenêtre de contexte | 2 millions | 1 million | Variable | 2 millions |
| Prix entrée | 2 $ | 15 $ | 2,50 $ | 2 $ |
| Prix sortie | 6 $ | 75 $ | 15 $ | 12 $ |
| Multi-agent | ✅ 4 agents | ❌ | ❌ | ❌ |
| Données temps réel | ✅ X/Twitter | ❌ | ✅ Recherche | ✅ Recherche |
| Contrôle des hallucinations | 4,2% (le plus bas) | Faible | Faible | Moyen |
| Entrée image | ✅ JPG/PNG | ✅ Multi-format | ✅ Multi-format | ✅ Multi-format |
Meilleurs cas d'usage par modèle
- Grok 4.20: Excellent rapport qualité-prix, recherche approfondie (multi-agent), analyse de données en temps réel.
- Claude Opus 4.6: Ingénierie logicielle (meilleur score SWE-bench), sorties très longues (128K), sécurité entreprise.
- GPT-5: Mathématiques (score parfait), automatisation de bureau, écosystème utilisateur le plus vaste.
- Gemini 3.1 Pro: Intégration écosystème Google, 2 millions de jetons de contexte, coût modéré.
💰 Analyse du rapport qualité-prix : Le prix de sortie de Grok 4.20 (6 $/MTok) ne représente que 8 % de celui de Claude Opus 4.6 (75 $/MTok). Pour les tâches intensives en sortie (génération de code long, rapports de recherche), l'utilisation de Grok 4.20 permet de réduire les coûts de plus de 90 %. Via APIYI sur apiyi.com, vous pouvez accéder à l'ensemble des modèles Grok, Claude et GPT, et basculer entre eux selon les besoins de vos tâches.
Pratique de l'invocation d'API
Exemple d'invocation de base
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
# Tâche générale → Version de base
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "Vous êtes un développeur Python expérimenté."},
{"role": "user", "content": "Implémentez une file d'attente de tâches asynchrones"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Sélection automatique du modèle selon la tâche
def choose_grok_model(task_type):
"""Sélectionne automatiquement le meilleur modèle Grok selon le type de tâche"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# Exemple d'utilisation
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Analysez les goulots d'étranglement de performance de ce code..."}]
)
Voir le code de test comparatif multi-modèles
import openai
import time
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Implémentez un tri rapide en Python et analysez la complexité temporelle"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" Durée: {elapsed:.1f}s | Tokens: {tokens}")
print(f" Aperçu: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | Erreur: {e}")
time.sleep(1)
🎯 Conseil pratique : Je vous recommande d'effectuer un test de référence avec
grok-4.20-beta, puis de comparer la qualité de sortie sur des tâches complexes avec la versionreasoning. En utilisant APIYI (apiyi.com) pour invoquer les 4 modèles, vous bénéficiez de tarifs alignés sur le site officiel, avec des remises via les promotions de recharge.
Questions fréquentes
Q1 : Les 4 modèles ont-ils la même tarification ?
Oui, les 4 modèles ont une tarification unifiée : 2 $ en entrée / 6 $ en sortie par million de tokens. Cependant, le coût réel varie selon le modèle — les modèles de raisonnement génèrent plus de tokens de réflexion (comptabilisés comme sortie), et la version multi-agents peut consommer davantage de tokens en raison de la collaboration entre les 4 agents. La version sans raisonnement est la plus économique car elle ignore la chaîne de réflexion, minimisant ainsi les tokens de sortie. Via APIYI (apiyi.com), la tarification est identique à celle du site officiel d'xAI, avec des remises appliquées lors des recharges.
Q2 : Quelle est la différence entre la version multi-agents et la version de raisonnement ?
La version de raisonnement repose sur un seul agent effectuant une réflexion approfondie — idéale pour les tâches d'analyse avec des réponses précises (mathématiques, revue de code). La version multi-agents implique 4 agents collaborant par discussion — adaptée aux questions ouvertes nécessitant une analyse sous plusieurs angles (études de marché, aide à la décision). L'avantage majeur de la version multi-agents est la vérification croisée, réduisant le taux d'hallucination (de 12 % à 4,2 %).
Q3 : Grok 4.20 peut-il remplacer Claude pour la revue de code ?
Dans certains scénarios, oui. La version de raisonnement de Grok 4.20 atteint environ 75 % sur SWE-bench, contre 81,4 % pour Claude Opus 4.6, mais pour un coût représentant seulement 8 % de ce dernier. Pour une revue de code quotidienne non critique, Grok 4.20 est un choix au rapport qualité-prix élevé. Pour les audits de sécurité et les revues d'architecture complexes, Claude Opus 4.6 reste plus fiable. Via APIYI (apiyi.com), vous pouvez accéder aux deux modèles et basculer entre eux selon vos besoins.
Q4 : À quoi sert concrètement une fenêtre de contexte de 2 millions de tokens ?
2 millions de tokens correspondent environ à un livre technique de 1 500 pages. Applications réelles : (1) Charger et analyser l'intégralité d'une base de code moyenne ou grande en une seule fois ; (2) Traiter des documents extrêmement longs (contrats juridiques, recueils d'articles académiques) ; (3) Maintenir une mémoire de conversation très longue. Il s'agit actuellement de l'une des plus grandes fenêtres de contexte parmi les modèles occidentaux de pointe.
Q5 : Comment invoquer ces modèles sur la plateforme APIYI ?
Après vous être inscrit sur apiyi.com et avoir obtenu votre clé, utilisez simplement le format compatible OpenAI. Il suffit de définir base_url sur https://api.apiyi.com/v1 et model sur l'identifiant correspondant (ex: grok-4.20-beta). Voir les exemples de code ci-dessus. La tarification des 4 modèles est alignée sur le site officiel, avec des remises via les activités de recharge.
Résumé : Stratégies d'utilisation optimales pour les 4 modèles
La série Grok 4.20 Beta offre une sélection de modèles précise pour différents scénarios. La stratégie fondamentale consiste à faire correspondre le modèle à la complexité de la tâche :
| Complexité | Modèle recommandé | Coût |
|---|---|---|
| 🟢 Simple/Haute fréquence | non-reasoning |
Le plus bas |
| 🟡 Usage quotidien | grok-4.20-beta |
Modéré |
| 🟠 Analyse approfondie | reasoning |
Élevé |
| 🔴 Fiabilité maximale | multi-agent |
Le plus élevé |
Avec une tarification de 2 $/6 $, Grok 4.20 s'impose comme le modèle phare au coût de sortie le plus bas du marché actuel. Associé à une fenêtre de contexte de 2 millions de jetons et à un système multi-agents, il est extrêmement compétitif pour la recherche, l'analyse et les scénarios à haut débit.
Nous vous recommandons d'accéder à toute la gamme Grok 4.20 Beta via APIYI (apiyi.com). La tarification est identique à celle du site officiel, avec des remises appliquées lors des recharges. Une seule clé API permet d'utiliser plus de 200 modèles, dont Grok, Claude et GPT.
Références
-
Documentation officielle de xAI : Modèles Grok et explications tarifaires
- Lien :
docs.x.ai/developers/models
- Lien :
-
Artificial Analysis : Évaluation comparative de Grok 4.20 Beta
- Lien :
artificialanalysis.ai/models/grok-4-20
- Lien :
-
Documentation multi-agents de xAI : Détails sur les capacités multi-agents
- Lien :
docs.x.ai/developers/model-capabilities/text/multi-agent
- Lien :
-
OpenRouter : Page du modèle Grok 4.20 Beta
- Lien :
openrouter.ai
- Lien :
Auteur : Équipe APIYI | Nous intégrons les derniers modèles d'IA dès leur sortie. N'hésitez pas à visiter APIYI (apiyi.com) pour tester la gamme complète Grok 4.20 Beta.