Récemment, de nombreux développeurs ont rencontré le message d'erreur suivant lors de l'invocation de l'API Gemini :
{
"error": {
"code": 503,
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"status": "UNAVAILABLE"
}
}
En termes simples, cela signifie : ce modèle est actuellement trop populaire, les serveurs sont surchargés, veuillez réessayer plus tard.
Ce problème est particulièrement grave avec les nouveaux modèles Gemini 3.1 Pro Preview et Gemini 3.1 Flash Image Preview (Nano Banana 2). Cet article expliquera en détail la nature de cette erreur, ses différences avec d'autres erreurs courantes, et 5 solutions testées et efficaces.
Valeur essentielle : Après avoir lu cet article, vous comprendrez précisément la cause profonde de l'erreur 503 "high demand", et vous maîtriserez 5 solutions directement applicables pour ne plus être bloqué dans votre développement par cette erreur.
Que signifie réellement l'erreur Gemini API 503 High Demand ?
Pour comprendre ce problème, utilisons une analogie simple :
Imaginez que les serveurs Gemini de Google sont un restaurant très populaire. En temps normal, les affaires sont bonnes et il y a suffisamment de places. Puis, un jour, le restaurant fait le buzz (un nouveau modèle est lancé), et toute la ville se précipite pour faire la queue. La capacité du restaurant est limitée, une fois qu'il est plein, il est plein. À ce moment-là, si vous arrivez à l'entrée, le serveur vous dira : "Désolé, il y a trop de monde en ce moment, les heures de pointe sont généralement temporaires, veuillez revenir un peu plus tard."
C'est l'essence de This model is currently experiencing high demand – ce n'est pas un problème avec votre code, ni avec votre clé API, c'est que la puissance de calcul des serveurs de Google est insuffisante.
3 faits clés sur l'erreur Gemini 503
| Fait | Explication | Impact |
|---|---|---|
| Problème côté serveur | Le 503 indique une capacité insuffisante des serveurs Google, sans rapport avec votre code ou votre configuration. | La mise à niveau vers un forfait payant ne résoudra pas le problème. |
| Tous les utilisateurs sont affectés | Les utilisateurs gratuits, payants et les clients d'entreprise peuvent tous rencontrer ce problème. | Ce n'est pas un problème qui se résout en "payant plus". |
| Généralement temporaire | Environ 70 % des erreurs 503 pendant les heures de pointe se résolvent d'elles-mêmes en 60 minutes. | Nécessite un mécanisme de réessai plutôt qu'une correction de code. |
Pourquoi Gemini 3.1 Pro et Nano Banana 2 sont-ils particulièrement sujets aux erreurs 503 ?
L'explosion des erreurs 503 en février 2026 a une chronologie claire :
- 19 février : Google lance Gemini 3.1 Pro Preview, attirant un grand nombre de développeurs pour les tests.
- 26 février : Lancement de Nano Banana 2 (
gemini-3.1-flash-image-preview), entraînant une augmentation massive de la demande en génération d'images. - 17-21 février : StatusGator enregistre des avertissements de dégradation du service Gemini pendant toute une semaine.
- Taux d'échec d'environ 45 % pendant les heures de pointe : Les données de la communauté montrent que le taux d'échec des requêtes approche la moitié pendant les périodes de pointe.
La raison fondamentale : Les nouveaux modèles viennent d'être lancés, et la puissance de calcul allouée par Google (clusters GPU) n'a pas encore été mise à l'échelle en fonction de la demande. Les ressources des serveurs pour les modèles en état de Preview sont intrinsèquement limitées, et lorsque des développeurs du monde entier se précipitent simultanément pour tester, une situation de surdemande se produit.

Différence essentielle entre Gemini 503 High Demand et 429 Rate Limit
Beaucoup de développeurs confondent les erreurs 503 et 429, mais les causes de ces deux erreurs sont totalement différentes, tout comme leurs solutions. Se tromper de direction ne fera que vous faire perdre du temps.
| Critère de comparaison | 503 High Demand | 429 Rate Limit |
|---|---|---|
| Message d'erreur | "This model is currently experiencing high demand" | "Resource has been exhausted" |
| Cause fondamentale | Manque de puissance de calcul sur les serveurs Google | Votre fréquence de requêtes personnelle a dépassé la limite |
| Portée de l'impact | Tous les utilisateurs sont affectés | Seul vous êtes affecté |
| Mise à niveau résout-elle le problème ? | ❌ La mise à niveau vers un forfait payant ne résout pas le problème | ✅ La mise à niveau vers le Tier 1 peut résoudre le problème |
| La nouvelle tentative est-elle efficace ? | ✅ Attendre un peu permet généralement de récupérer | ❌ Ne pas réduire la fréquence continuera à générer des erreurs |
| Caractéristiques des périodes de pointe | Fréquent pendant les heures de travail nord-américaines (9h-17h PT) | Indépendant de l'heure, l'erreur se produit dès que la limite est dépassée |
| Solution fondamentale | Nouvelle tentative + modèle de secours + décalage des heures de pointe | Réduire la fréquence des requêtes ou mettre à niveau le forfait |
Méthode de diagnostic rapide
- Si vous voyez un 503 → C'est un problème Google, attendez un peu ou changez de modèle
- Si vous voyez un 429 → Vous faites trop de requêtes, ralentissez ou mettez à niveau votre forfait
🎯 Conseil technique: Gérer simultanément les erreurs 503 et 429 en environnement de production est une compétence fondamentale en intégration d'API. En utilisant la plateforme APIYI apiyi.com pour invoquer les modèles de la série Gemini, la plateforme intègre des mécanismes de nouvelle tentative intelligente et d'équilibrage de charge, ce qui peut réduire considérablement la fréquence des erreurs 503 perçues par les utilisateurs finaux.
Solution 1 : Nouvelle tentative avec recul exponentiel (la plus fondamentale)
Puisque 503 signifie "réessayez plus tard", la réponse la plus directe est la nouvelle tentative automatique. Cependant, il ne faut pas réessayer aveuglément – il est nécessaire d'utiliser une stratégie de "recul exponentiel", où l'intervalle entre chaque nouvelle tentative double, afin d'éviter d'aggraver la pression sur le serveur.
Code de nouvelle tentative avec recul exponentiel pour Gemini 503
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
def call_gemini_with_retry(messages, model="gemini-3.1-pro-preview", max_retries=5):
"""Invocation de l'API Gemini avec recul exponentiel"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
return response
except openai.APIStatusError as e:
if e.status_code == 503:
# Recul exponentiel : 2s, 4s, 8s, 16s, 32s + jitter aléatoire
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ 503 High Demand - {attempt+1}ème tentative, attente de {wait_time:.1f}s...")
time.sleep(wait_time)
elif e.status_code == 429:
# 429 Rate Limit : attente plus longue
wait_time = 60 + random.uniform(0, 10)
print(f"🚫 429 Rate Limit - Attente de {wait_time:.1f}s...")
time.sleep(wait_time)
else:
raise # Lève directement les autres erreurs
raise Exception(f"Échec après {max_retries} tentatives")
# Exemple d'utilisation
response = call_gemini_with_retry(
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
print(response.choices[0].message.content)
Paramètres clés pour la nouvelle tentative avec recul exponentiel
| Paramètre | Valeur recommandée | Description |
|---|---|---|
| Nombre maximal de tentatives | 5 fois | Plus de 5 tentatives indique généralement que ce n'est pas un problème temporaire |
| Attente initiale | 2 secondes | Trop court aggraverait la pression sur le serveur |
| Multiplicateur de recul | 2x | Double à chaque fois : 2s → 4s → 8s → 16s → 32s |
| Jitter aléatoire | 0-1 seconde | Évite que de nombreux clients ne réessayent simultanément |
| Attente maximale | 32 secondes | Au-delà de 32 secondes, il faudrait passer à une solution de secours |
💡 Conseil pratique: Le jitter aléatoire est très important. Si tous les clients réessayent précisément après 2 secondes, cela créera un "effet d'estampage" – toutes les requêtes afflueront simultanément vers le serveur, entraînant une nouvelle série d'erreurs 503. L'ajout d'un jitter aléatoire permet de disperser les requêtes de nouvelle tentative.
Solution 2 : Dégradation du modèle / Basculement automatique vers un modèle de secours
Lorsque Gemini 3.1 Pro Preview renvoie constamment des erreurs 503, la solution la plus pratique est de basculer automatiquement vers un modèle de secours plus stable.
Stratégie de dégradation du modèle Gemini 503
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Chaîne de dégradation du modèle : prioriser le plus puissant, puis dégrader si nécessaire
FALLBACK_MODELS = [
"gemini-3.1-pro-preview", # Priorité 1 : le plus récent et le plus puissant
"gemini-3.0-pro", # Secours 1 : la génération Pro précédente, plus stable
"gemini-2.5-flash-image-preview", # Secours 2 : version Flash, rapide
"gemini-2.5-flash", # Ultime recours : le Flash le plus stable
]
def call_with_fallback(messages):
"""Appel API avec dégradation du modèle"""
for model in FALLBACK_MODELS:
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
if model != FALLBACK_MODELS[0]:
print(f"⚠️ Dégradation vers le modèle de secours : {model}")
return response
except openai.APIStatusError as e:
if e.status_code in (503, 429):
print(f"❌ {model} a renvoyé {e.status_code}, tentative avec le modèle suivant...")
continue
raise
raise Exception("Tous les modèles sont indisponibles")
response = call_with_fallback(
messages=[{"role": "user", "content": "Analyser les goulots d'étranglement de performance de ce code"}]
)
Classement de la stabilité des modèles Gemini
| Modèle | Stabilité | Fréquence 503 | Scénarios adaptés |
|---|---|---|---|
gemini-2.5-flash |
⭐⭐⭐⭐⭐ | Très faible | Ultime recours pour environnements de production à haute disponibilité |
gemini-3.0-pro |
⭐⭐⭐⭐ | Faible | Scénarios stables nécessitant les capacités Pro |
gemini-2.5-flash-image-preview |
⭐⭐⭐ | Moyenne | Secours pour la génération d'images |
gemini-3.1-pro-preview |
⭐⭐ | Assez élevée | Nécessite les dernières capacités mais accepte les échecs occasionnels |
gemini-3.1-flash-image-preview |
⭐⭐ | Assez élevée | Génération d'images Nano Banana 2 |
🚀 Démarrage rapide : Via la plateforme APIYI apiyi.com, vous pouvez invoquer tous les modèles du tableau ci-dessus avec une seule clé API. Le changement de modèle ne nécessite que la modification du paramètre
model, sans reconfigurer l'authentification. Il est très facile d'implémenter une chaîne de dégradation de modèle dans votre code.
Solution 3 : Appels hors pointe (solution à coût zéro)
La forte demande (503 high demand) présente des schémas horaires clairs. Les données de la communauté montrent :
- Période de pointe (9h-17h PT) : Taux d'échec d'environ 45 %
- Période creuse (2h-7h PT) : Taux d'échec inférieur à 5 %
Converti en heure de Pékin :
| Plage horaire (heure de Pékin) | Heure du Pacifique correspondante | Fréquence Gemini 503 | Recommandation |
|---|---|---|---|
| 1h00 – 10h00 du matin | 9h00-18h00 PT (jour précédent) | 🔴 Pointe | Éviter ou utiliser un modèle de secours |
| 10h00 – 15h00 de l'après-midi | 18h00-23h00 PT (jour précédent) | 🟡 Moyenne | Appeler avec un mécanisme de réessai |
| 15h00 – 23h00 du soir | 23h00-7h00 PT | 🟢 Creuse | Meilleure fenêtre d'appel |
| 23h00 – 1h00 du matin | 7h00-9h00 PT | 🟡 Moyenne | Commence à monter en puissance |
Scénarios adaptés aux appels hors pointe
- Traitement de données par lots : Tâches ne nécessitant pas de réponse en temps réel, à planifier pendant les heures creuses.
- Tâches planifiées : Configurer des tâches cron pour une exécution pendant les heures creuses.
- Génération de contenu : Articles, images, etc., qui peuvent être générés à l'avance et publiés ultérieurement.
Solution quatre : Stratégie combinée (recommandée pour la production)
Dans un environnement de production réel, une solution unique est souvent insuffisante. Il est recommandé de combiner les 3 solutions précédentes :
Schéma d'invocation de l'API Gemini de niveau production
import openai
import time
import random
from datetime import datetime
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
FALLBACK_MODELS = [
"gemini-3.1-pro-preview",
"gemini-3.0-pro",
"gemini-2.5-flash",
]
def smart_gemini_call(messages, max_retries=3):
"""
Invocation de l'API Gemini de niveau production
Stratégie : nouvelle tentative avec backoff exponentiel + dégradation du modèle + classification des erreurs
"""
for model in FALLBACK_MODELS:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
return response, model
except openai.APIStatusError as e:
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ {model} 503 - Nouvelle tentative {attempt+1}/{max_retries}, attente {wait:.1f}s")
time.sleep(wait)
else:
print(f"⚠️ {model} 503 persistant, dégradation vers le modèle suivant")
break # Sortir de la boucle de nouvelle tentative, changer de modèle
elif e.status_code == 429:
wait = 60
print(f"🚫 {model} 429 Limite de débit - Attente {wait}s")
time.sleep(wait)
else:
raise
except openai.APITimeoutError:
print(f"⏰ {model} Requête expirée, tentative avec le modèle suivant")
break
raise Exception("Tous les modèles et tentatives ont échoué, veuillez vérifier le réseau ou réessayer plus tard")
# Utilisation
response, used_model = smart_gemini_call(
messages=[{"role": "user", "content": "你好"}]
)
print(f"✅ Modèle utilisé : {used_model}")
print(response.choices[0].message.content)
Voir l’encapsulation complète de niveau production (avec logs, monitoring, cache)
import openai
import time
import random
import hashlib
import json
import logging
from datetime import datetime
from functools import lru_cache
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("gemini_client")
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Cache de requêtes simple
_cache = {}
def get_cache_key(messages, model):
"""Génère la clé de cache pour la requête"""
content = json.dumps(messages, sort_keys=True) + model
return hashlib.md5(content.encode()).hexdigest()
def gemini_call_production(
messages,
models=None,
max_retries=3,
cache_ttl=3600,
enable_cache=True
):
"""
Encapsulation de l'invocation de l'API Gemini de niveau production
Caractéristiques :
- Nouvelle tentative avec backoff exponentiel (gestion des 503)
- Dégradation automatique du modèle
- Cache de réponse (réduit les requêtes répétées)
- Logs structurés
"""
if models is None:
models = ["gemini-3.1-pro-preview", "gemini-3.0-pro", "gemini-2.5-flash"]
# Vérification du cache
if enable_cache:
cache_key = get_cache_key(messages, models[0])
if cache_key in _cache:
cached_time, cached_response = _cache[cache_key]
if time.time() - cached_time < cache_ttl:
logger.info("Cache hit, invocation de l'API ignorée")
return cached_response, "cache"
errors = []
for model in models:
for attempt in range(max_retries):
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
elapsed = time.time() - start_time
logger.info(f"Succès | model={model} | durée={elapsed:.2f}s")
# Écriture dans le cache
if enable_cache:
_cache[cache_key] = (time.time(), response)
return response, model
except openai.APIStatusError as e:
errors.append(f"{model}:{e.status_code}")
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
logger.warning(f"503 | model={model} | tentative={attempt+1} | attente={wait:.1f}s")
time.sleep(wait)
else:
logger.warning(f"503 persistant | model={model} | dégradation vers le modèle suivant")
break
elif e.status_code == 429:
logger.warning(f"429 Limite de débit | model={model}")
time.sleep(60)
else:
raise
except Exception as e:
logger.error(f"Erreur | model={model} | erreur={e}")
break
raise Exception(f"Tous ont échoué : {errors}")
Solution cinq : Utiliser le routage intelligent d'une plateforme proxy
Si vous préférez ne pas implémenter vous-même les logiques complexes de nouvelle tentative et de dégradation mentionnées ci-dessus, il existe une option plus simple : utiliser une plateforme proxy API dotée de capacités de routage intelligent.
Comment une plateforme proxy résout le problème Gemini 503
Une plateforme proxy API professionnelle offre généralement les fonctionnalités suivantes :
- Rotation multi-clés : La plateforme détient plusieurs clés API Google et bascule automatiquement si une seule clé est soumise à une limitation de débit.
- Nouvelles tentatives intelligentes : La plateforme implémente des nouvelles tentatives avec recul exponentiel, de manière transparente pour le développeur.
- Équilibrage de charge : Les requêtes sont réparties sur plusieurs comptes et régions Google.
- Détection de panne : Si la fréquence des erreurs 503 pour un modèle donné augmente, la plateforme réduit automatiquement la proportion de requêtes allouées à ce modèle.
🎯 Conseil technique : La plateforme APIYI apiyi.com offre ces capacités de routage intelligent pour les modèles de la série Gemini. En utilisant une invocation via une interface compatible OpenAI, la plateforme gère automatiquement les nouvelles tentatives en cas de 503 et l'équilibrage de charge multi-clés en arrière-plan, évitant ainsi aux développeurs d'implémenter des logiques de tolérance aux pannes complexes.
Exemple de code minimaliste pour la solution de plateforme proxy
import openai
# Utilisation de la plateforme proxy APIYI, la gestion des erreurs 503 est assurée par la plateforme
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# C'est aussi simple que ça, pas besoin de gérer les erreurs 503 soi-même
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
Processus complet de dépannage des erreurs API Gemini
Lorsque vous rencontrez une erreur API Gemini, suivez ce processus pour localiser rapidement le problème :
Première étape : Examiner le code d'erreur
| Code d'erreur | Message d'erreur | Type | Action immédiate |
|---|---|---|---|
| 503 | "high demand" / "overloaded" | Capacité de calcul du serveur insuffisante | Attendre une nouvelle tentative ou changer de modèle |
| 429 | "resource exhausted" | Limitation de débit personnelle | Réduire la fréquence des requêtes ou mettre à niveau le forfait |
| 400 | "invalid request" | Paramètres de requête invalides | Vérifier le format et les paramètres de la requête |
| 401 | "unauthorized" | Échec de l'authentification | Vérifier la clé API |
| 500 | "internal error" | Erreur interne du serveur | Attendre une nouvelle tentative |
Deuxième étape : Distinguer 503 et 429
- Plusieurs clés API signalent une erreur → 503, c'est un problème de serveur Google.
- Seule votre clé signale une erreur → 429, c'est un problème de limite personnelle.
Troisième étape : Choisir la solution correspondante
- 503 : Nouvelle tentative avec recul exponentiel → Dégradation du modèle → Appel hors période de pointe.
- 429 : Réduire la fréquence des requêtes → Activer la facturation pour passer au Tier 1 (couche gratuite 5-15 RPM, Tier 1 est 150-300 RPM).
Questions fréquentes
Q1: Pourquoi est-ce que je rencontre toujours une erreur 503 High Demand même après avoir payé ?
L'erreur 503 n'a absolument rien à voir avec le fait que vous ayez payé ou non. C'est un problème de capacité de calcul insuffisante des serveurs de Google, que vous soyez un utilisateur gratuit ou un client d'entreprise. C'est différent de la limitation de débit 429 – une erreur 429 peut être résolue en améliorant votre forfait, mais pas une 503. Lorsque vous rencontrez une 503, il est recommandé d'utiliser une nouvelle tentative avec un délai d'attente exponentiel ou de passer à une version de modèle plus stable. L'invocation du modèle via la plateforme APIYI apiyi.com peut réduire la fréquence perçue des 503 grâce à l'équilibrage de charge multi-clés.
Q2: Quand l’erreur 503 de Gemini 3.1 Pro Preview sera-t-elle résolue ?
Selon l'expérience passée, le pic d'erreurs 503 après le lancement d'un nouveau modèle dure généralement 1 à 3 semaines, et s'améliore considérablement à mesure que Google augmente progressivement sa capacité. Gemini 3.0 Pro a également connu une vague similaire de 503 lors de son lancement, et est maintenant très stable. Pendant cette période d'attente, il est conseillé de mettre en œuvre une stratégie de dégradation du modèle, en revenant automatiquement à gemini-3.0-pro ou gemini-2.5-flash en cas de 503.
Q3: « high demand » et « model is overloaded » sont-ils la même erreur ?
Essentiellement, ce sont des formulations différentes du même problème. "This model is currently experiencing high demand" et "The model is overloaded" sont tous deux des codes d'état 503, indiquant une capacité de calcul insuffisante des serveurs de Google. Le premier est plus courant dans les versions d'API plus récentes, tandis que le second apparaissait davantage dans les versions antérieures. La méthode de traitement est exactement la même.
Q4: Y a-t-il un moyen de savoir à l’avance si l’API Gemini va rencontrer une erreur 503 ?
Il n'y a pas d'alerte officielle préalable. Cependant, vous pouvez surveiller quelques signaux : (1) Les 1 à 2 semaines suivant le lancement d'un nouveau modèle par Google sont une période à haut risque ; (2) La fréquence des 503 est plus élevée pendant les heures de travail nord-américaines (du petit matin à la fin de matinée, heure de Pékin) ; (3) Les forums communautaires discuss.ai.google.dev fournissent généralement des retours en temps réel. Il est recommandé de toujours inclure une logique de nouvelle tentative et de dégradation dans votre code, plutôt que d'attendre de rencontrer un problème pour l'ajouter temporairement. La plateforme APIYI apiyi.com offre une surveillance de l'état de disponibilité des modèles, ce qui peut vous aider à anticiper.
Q5: Devrais-je gérer les erreurs 503 et 429 simultanément dans mon code ?
Absolument. En environnement de production, vous rencontrerez à la fois des erreurs 503 et 429. Les stratégies de traitement sont différentes mais tout aussi importantes. Pour les 503, utilisez une nouvelle tentative avec un délai d'attente exponentiel + dégradation du modèle ; pour les 429, réduisez la fréquence des requêtes + mettez en file d'attente les requêtes limitées. Le code de la « Solution quatre : Stratégie combinée » de cet article gère ces deux types d'erreurs simultanément et peut être directement utilisé en production.
Résumé
L'essence de l'erreur 503 This model is currently experiencing high demand est très simple : la capacité de calcul des serveurs de Google est temporairement insuffisante. Cela est presque inévitable, surtout pour les nouveaux modèles comme Gemini 3.1 Pro Preview ou Nano Banana 2, au début de leur lancement.
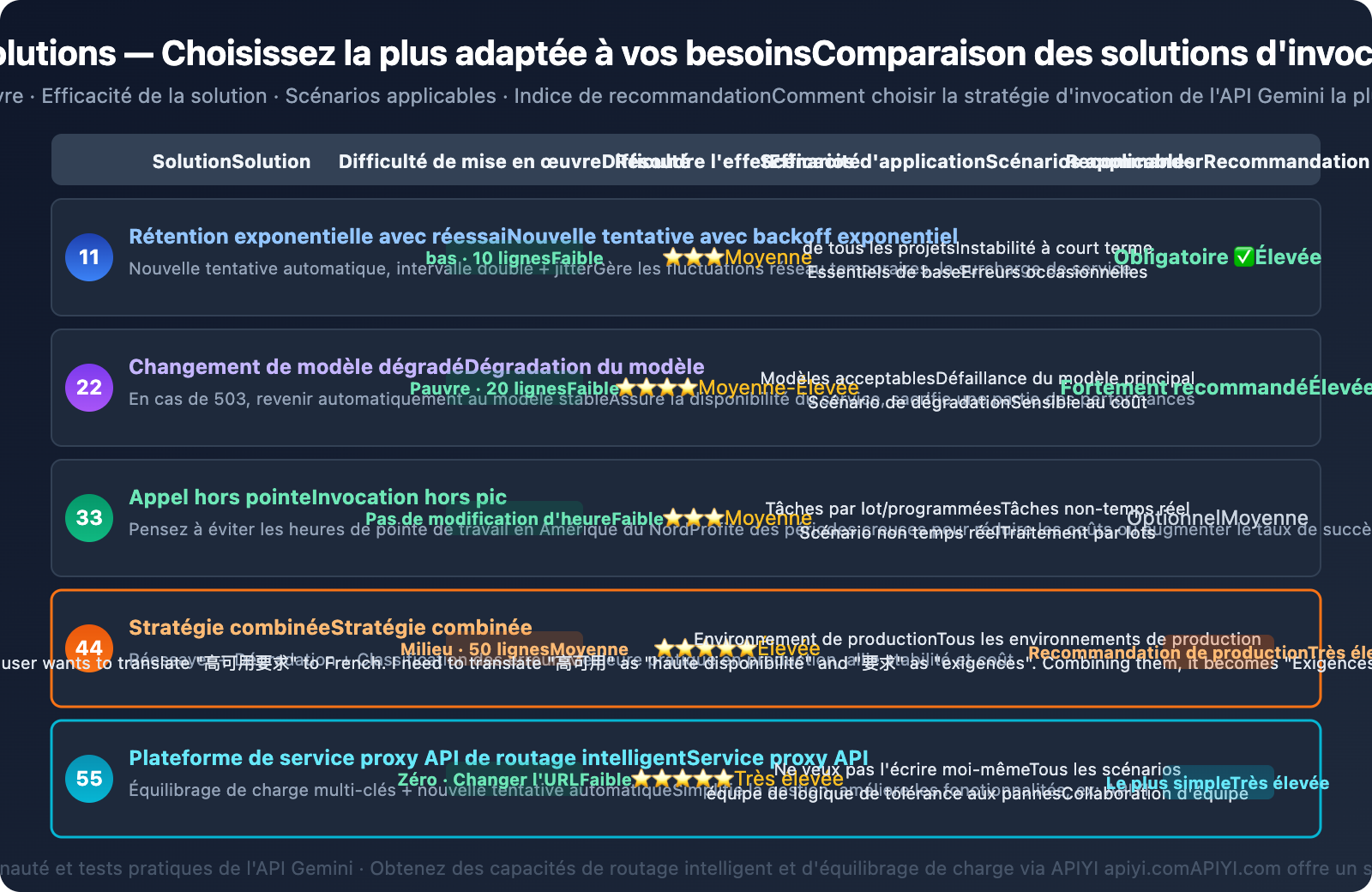
Voici 5 solutions, classées par ordre de priorité recommandé :
- Nouvelle tentative avec un délai d'attente exponentiel — La base, chaque projet devrait l'avoir.
- Chaîne de dégradation du modèle — Bascule automatiquement vers un modèle plus stable en cas de 503.
- Invocation décalée — Planifiez les tâches non urgentes pendant les périodes de faible affluence.
- Stratégie combinée — Recommandée pour les environnements de production : nouvelle tentative + dégradation + classification des erreurs.
- Routage intelligent via plateforme proxy — Le plus simple, la plateforme gère la logique de tolérance aux pannes.
Quelle que soit la solution choisie, le principe fondamental est : l'erreur 503 n'est pas de votre faute, mais vous devez la gérer avec élégance. Nous vous recommandons d'intégrer rapidement les modèles de la série Gemini via APIYI apiyi.com pour bénéficier du routage intelligent et des capacités de nouvelle tentative intégrées.
Références
-
Google AI Developers Forum – 503 Error Discussions
- Lien :
discuss.ai.google.dev - Description : Discussions communautaires et réponses officielles concernant l'erreur 503 de l'API Gemini
- Lien :
-
Google Gemini API – Rate Limits Documentation
- Lien :
ai.google.dev/gemini-api/docs/rate-limits - Description : Règles officielles de limitation de débit et explications des quotas par niveau (Tier)
- Lien :
-
Google Gemini API – Troubleshooting Guide
- Lien :
ai.google.dev/gemini-api/docs/troubleshooting - Description : Guide officiel de dépannage des erreurs
- Lien :
📝 Auteur : Équipe APIYI | Pour les échanges techniques et l'intégration d'API, veuillez visiter apiyi.com