作者注:深度对比 2026 年 2 月同期发布的 MiniMax-M2.5 和 GLM-5 两大开源模型,从编码、推理、智能体、速度、价格和架构 6 个维度解析各自擅长领域
2026 年 2 月 11-12 日,两大中国 AI 公司几乎同时发布了各自的旗舰模型:智谱 GLM-5(744B 参数)和 MiniMax-M2.5(230B 参数)。两者都采用 MoE 架构、MIT 开源协议,但在能力侧重上形成了鲜明的差异化定位。
核心价值: 看完本文,你将清楚了解 GLM-5 擅长推理和知识可靠性,MiniMax-M2.5 擅长编码和智能体工具调用,从而在具体场景中做出最优选择。

Aperçu des différences clés entre MiniMax-M2.5 et GLM-5
| Dimension de comparaison | MiniMax-M2.5 | GLM-5 | Avantage |
|---|---|---|---|
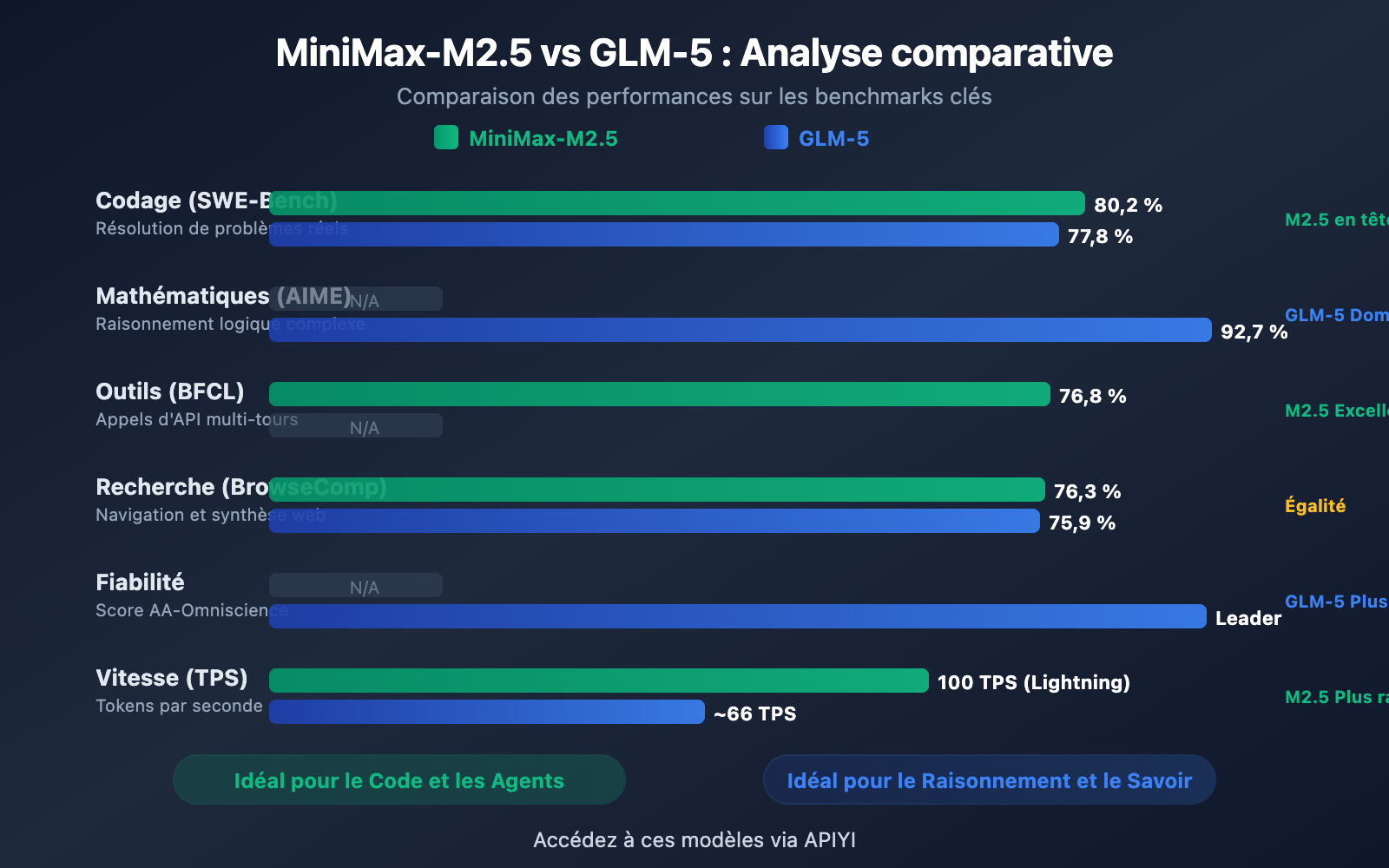
| Codage SWE-Bench | 80,2 % | 77,8 % | M2.5 mène de 2,4 % |
| Raisonnement mathématique AIME | — | 92,7 % | GLM-5 excelle |
| Appel d'outils BFCL | 76,8 % | — | M2.5 excelle |
| Recherche BrowseComp | 76,3 % | 75,9 % | Quasiment identique |
| Prix de sortie / M tokens | 1,20 $ | 3,20 $ | M2.5 est 2,7 fois moins cher |
| Vitesse de sortie | 50-100 TPS | ~66 TPS | M2.5 Lightning est plus rapide |
| Paramètres totaux | 230B | 744B | GLM-5 est plus grand |
| Paramètres activés | 10B | 40B | M2.5 est plus léger |
Les points forts de MiniMax-M2.5 : Codage et Agents
Le MiniMax-M2.5 se distingue particulièrement sur les benchmarks de programmation. Son score de 80,2 % sur SWE-Bench Verified non seulement devance les 77,8 % du GLM-5, mais surpasse également les 80,0 % de GPT-5.2, se plaçant juste derrière les 80,8 % de Claude Opus 4.6. Dans le test Multi-SWE-Bench, qui évalue la collaboration sur plusieurs fichiers, il obtient 51,3 %, et atteint même 76,8 % dans le test BFCL Multi-Turn pour l'appel d'outils.
L'architecture MoE (Mélange d'experts) du M2.5 n'active que 10 milliards de paramètres (soit 4,3 % du total de 230B), ce qui en fait le choix le plus "léger" parmi les modèles de Tier 1, avec une efficacité d'inférence extrêmement élevée. La version Lightning peut atteindre 100 TPS, ce qui en fait l'un des modèles de pointe les plus rapides actuellement disponibles.
Les points forts de GLM-5 : Raisonnement et fiabilité des connaissances
Le GLM-5 possède un avantage significatif dans les tâches de raisonnement et de connaissances. Il affiche un score de 92,7 % en raisonnement mathématique sur AIME 2026, 86,0 % en raisonnement scientifique sur GPQA-Diamond, et son score de 50,4 sur Humanity's Last Exam (avec outils) surpasse les 43,4 points de Claude Opus 4.5.
La capacité la plus remarquable du GLM-5 est la fiabilité de ses connaissances : il atteint un niveau leader du secteur dans l'évaluation des hallucinations AA-Omniscience, avec une amélioration de 35 points par rapport à la génération précédente. Pour les scénarios nécessitant une production de faits de haute précision, comme la rédaction de documents techniques, l'assistance à la recherche académique ou la construction de bases de connaissances, le GLM-5 est le choix le plus fiable. De plus, ses 744 milliards de paramètres et ses 28,5 billions de tokens de données d'entraînement lui confèrent une réserve de connaissances bien plus profonde.
MiniMax-M2.5 vs GLM-5 : Comparaison détaillée des capacités de codage
Les capacités de codage sont aujourd'hui l'un des critères les plus scrutés par les développeurs lors du choix d'un modèle d'IA. Sur ce terrain, l'écart entre les deux modèles est significatif.
| Benchmark de codage | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (Réf.) |
|---|---|---|---|
| SWE-Bench Verified | 80,2 % | 77,8 % | 80,8 % |
| Multi-SWE-Bench | 51,3 % | — | 50,3 % |
| SWE-Bench Multilingual | — | 73,3 % | 77,5 % |
| Terminal-Bench 2.0 | — | 56,2 % | 65,4 % |
| BFCL Multi-Turn | 76,8 % | — | 63,3 % |
MiniMax-M2.5 devance GLM-5 de 2,4 points de pourcentage sur SWE-Bench Verified (80,2 % contre 77,8 %). Dans le domaine des benchmarks de codage, une telle différence est notable : les capacités de codage de M2.5 se situent au niveau d'un Opus 4.6, tandis que GLM-5 se rapproche davantage d'un Gemini 3 Pro.
GLM-5 dispose de données sur le codage multilingue (SWE-Bench Multilingual 73,3 %) et le codage en environnement terminal (Terminal-Bench 56,2 %), montrant ses capacités sous différents angles. Cependant, sur le benchmark de référence SWE-Bench Verified, l'avantage de M2.5 est clair.
M2.5 se distingue également par son efficacité : il ne lui faut que 22,8 minutes pour accomplir une tâche unique sur SWE-Bench, soit une amélioration de 37 % par rapport à la génération précédente M2.1. Cela est dû à son style de codage unique "Spec-writing" — qui consiste à décomposer l'architecture avant de passer à une implémentation efficace, réduisant ainsi les cycles d'essais-erreurs inutiles.
🎯 Conseil pour le codage : Si votre besoin principal est l'assistance au codage par IA (correction de bugs, revue de code, implémentation de fonctionnalités), MiniMax-M2.5 est le meilleur choix. Via APIYI (apiyi.com), vous pouvez accéder aux deux modèles simultanément pour effectuer vos propres tests comparatifs.
MiniMax-M2.5 vs GLM-5 : Comparaison détaillée des capacités de raisonnement
Le raisonnement est l'atout majeur de GLM-5, particulièrement dans les domaines mathématiques et scientifiques.
| Benchmark de raisonnement | MiniMax-M2.5 | GLM-5 | Description |
|---|---|---|---|
| AIME 2026 | — | 92,7 % | Raisonnement mathématique de niveau olympique |
| GPQA-Diamond | — | 86,0 % | Raisonnement scientifique de niveau doctorat |
| Humanity's Last Exam (w/tools) | — | 50,4 | Surpasse les 43,4 d'Opus 4.5 |
| HMMT Nov. 2025 | — | 96,9 % | Proche des 97,1 % de GPT-5.2 |
| τ²-Bench | — | 89,7 % | Raisonnement dans le domaine des télécoms |
| Fiabilité AA-Omniscience | — | Leader du secteur | Taux d'hallucination le plus bas |
GLM-5 utilise une nouvelle méthode d'entraînement appelée SLIME (infrastructure d'apprentissage par renforcement asynchrone), qui améliore considérablement l'efficacité du post-entraînement. Cela a permis à GLM-5 de faire un bond qualitatif dans les tâches de raisonnement :
- Score de 92,7 % sur AIME 2026, proche des 93,3 % de Claude Opus 4.5, et bien au-delà du niveau de l'ère GLM-4.5.
- 86,0 % sur GPQA-Diamond, affichant des capacités de raisonnement scientifique de niveau doctorat, proches des 87,0 % d'Opus 4.5.
- 50,4 points sur Humanity's Last Exam (avec outils), surpassant les 43,4 points d'Opus 4.5 et les 45,5 points de GPT-5.2.
La capacité la plus unique de GLM-5 est la fiabilité de ses connaissances. Dans l'évaluation des hallucinations AA-Omniscience, GLM-5 a progressé de 35 points par rapport à la génération précédente, atteignant un niveau de leader dans le secteur. Cela signifie que GLM-5 "invente" beaucoup moins de contenu lorsqu'il répond à des questions factuelles, ce qui est extrêmement précieux pour les scénarios nécessitant une sortie d'informations de haute précision.
MiniMax-M2.5 a publié moins de données sur le raisonnement pur, son entraînement par renforcement (RL) étant concentré sur le codage et les scénarios d'agents intelligents. Le framework Forge RL de M2.5 met l'accent sur la décomposition des tâches et l'optimisation des appels d'outils dans plus de 200 000 environnements réels, plutôt que sur le raisonnement pur.
Note comparative : Si votre besoin principal concerne le raisonnement mathématique, l'analyse scientifique ou des questions-réponses nécessitant une haute fiabilité des connaissances, GLM-5 est plus avantageux. Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour tester concrètement la différence de performance entre les deux modèles sur vos tâches de raisonnement spécifiques.
MiniMax-M2.5 vs GLM-5 : Capacités d'Agent et de Recherche
| Benchmark d'Agent | MiniMax-M2.5 | GLM-5 | Avantage |
|---|---|---|---|
| BFCL Multi-Turn | 76,8% | — | M2.5 (Appels d'outils) |
| BrowseComp (w/context) | 76,3% | 75,9% | Quasiment identique |
| MCP Atlas | — | 67,8% | GLM-5 (Coordination multi-outils) |
| Vending Bench 2 | — | 4 432 $ | GLM-5 (Planification long terme) |
| τ²-Bench | — | 89,7% | GLM-5 (Raisonnement métier) |
Les deux modèles présentent des différences marquées dans leurs capacités d'agent :
MiniMax-M2.5 excelle en tant qu'agent d'exécution : il est particulièrement performant dans les scénarios nécessitant des appels d'outils fréquents, des itérations rapides et une exécution efficace. Un score de 76,8 % au BFCL signifie que le M2.5 peut effectuer avec précision des appels de fonctions, des opérations sur les fichiers et des interactions API, tout en réduisant le nombre de tours d'appels d'outils de 20 % par rapport à la génération précédente. En interne chez MiniMax, 80 % du nouveau code est déjà généré par M2.5, et il accomplit 30 % des tâches quotidiennes.
GLM-5 excelle en tant qu'agent de décision : il a l'avantage dans les scénarios exigeant un raisonnement approfondi, une planification à long terme et des prises de décision complexes. Son score de 67,8 % sur MCP Atlas démontre sa capacité de coordination d'outils à grande échelle. Les 4 432 $ de revenus simulés sur Vending Bench 2 illustrent sa capacité de planification commerciale sur de longues périodes, tandis que son score de 89,7 % sur τ²-Bench témoigne d'un raisonnement profond dans des domaines spécifiques.
Les deux sont presque à égalité en matière de navigation et de recherche web — 76,3 % contre 75,9 % sur BrowseComp — s'imposant tous deux comme leaders dans ce domaine.
🎯 Conseils pour vos scénarios d'agent : Choisissez M2.5 pour les appels d'outils haute fréquence et le codage automatique ; optez pour GLM-5 pour les décisions complexes et la planification à long terme. La plateforme APIYI (apiyi.com) prend en charge les deux modèles, vous permettant de basculer de l'un à l'autre selon vos besoins.
MiniMax-M2.5 vs GLM-5 : Comparaison de l'architecture et des coûts
| Architecture et Coûts | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| Paramètres totaux | 230B | 744B |
| Paramètres activés | 10B | 40B |
| Ratio d'activation | 4,3% | 5,4% |
| Données d'entraînement | — | 28,5 billions de Tokens |
| Fenêtre de contexte | 205K | 200K |
| Sortie maximale | — | 131K |
| Prix d'entrée | 0,15 $/M (Standard) | 1,00 $/M |
| Prix de sortie | 1,20 $/M (Standard) | 3,20 $/M |
| Vitesse de sortie | 50-100 TPS | ~66 TPS |
| Puces d'entraînement | — | Huawei Ascend 910 |
| Framework d'entraînement | Forge RL | SLIME Asynchrone RL |
| Mécanisme d'attention | — | DeepSeek Sparse Attention |
| Licence Open Source | MIT | MIT |
Analyse des avantages de l'architecture MiniMax-M2.5
L'atout majeur de l'architecture du M2.5 réside dans sa "légèreté extrême" : avec seulement 10B de paramètres activés, il atteint des capacités de codage proches d'Opus 4.6. Cela permet :
- Un coût d'inférence extrêmement bas : Le prix de sortie de 1,20 $/M ne représente que 37 % de celui du GLM-5.
- Une vitesse d'inférence ultra-rapide : La version Lightning atteint 100 TPS, soit 52 % de plus que les ~66 TPS du GLM-5.
- Un seuil de déploiement réduit : Avec 10B de paramètres activés, un déploiement sur des GPU grand public devient envisageable.
Analyse des avantages de l'architecture GLM-5
Les 744B de paramètres totaux et les 40B de paramètres activés du GLM-5 lui confèrent une plus grande base de connaissances et une meilleure profondeur de raisonnement :
- Une réserve de connaissances plus vaste : 28,5 billions de tokens de données d'entraînement, dépassant de loin la génération précédente.
- Une capacité de raisonnement accrue : Les 40B de paramètres activés supportent des chaînes de raisonnement plus complexes.
- Souveraineté technologique : Entièrement entraîné sur des puces Huawei Ascend, garantissant une indépendance en matière de puissance de calcul.
- DeepSeek Sparse Attention : Gestion efficace des contextes longs jusqu'à 200K.
Conseil : Pour les scénarios d'appels fréquents sensibles aux coûts, l'avantage tarifaire du M2.5 est flagrant (prix de sortie à seulement 37 % de celui du GLM-5). Nous vous suggérons de tester concrètement le rapport qualité-prix des deux modèles pour vos tâches spécifiques via la plateforme APIYI (apiyi.com).
Intégration rapide des API MiniMax-M2.5 vs GLM-5
Grâce à la plateforme APIYI, vous pouvez appeler les deux modèles via une interface unifiée pour une comparaison rapide :
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# Test de tâche de codage - M2.5 est plus performant
code_task = "Implémenter une file d'attente concurrente sans verrou en Rust"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# Test de tâche de raisonnement - GLM-5 est plus performant
reason_task = "Prouver que tout nombre pair supérieur à 2 peut être représenté comme la somme de deux nombres premiers (approche de vérification de la conjecture de Goldbach)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
Conseil : Obtenez des crédits de test gratuits sur APIYI (apiyi.com) pour tester les deux modèles selon vos besoins spécifiques. Essayez le M2.5 pour le code et le GLM-5 pour le raisonnement afin de trouver la solution qui vous convient le mieux.
Questions Fréquemment Posées
Q1 : Quelles sont les spécialités respectives de MiniMax-M2.5 et GLM-5 ?
MiniMax-M2.5 excelle dans le codage et l'appel d'outils pour agents — avec un score SWE-Bench de 80,2 % (proche des 84,6 % d'Opus), et 76,8 % au BFCL, ce qui le place au premier rang du secteur. GLM-5 se distingue par ses capacités de raisonnement et la fiabilité de ses connaissances — AIME 92,7 %, GPQA 86,0 %, et le taux d'hallucination le plus bas du marché. Pour faire simple : choisissez M2.5 pour écrire du code et GLM-5 pour les tâches de raisonnement.
Q2 : Quelle est la différence de prix entre les deux modèles ?
Le prix de sortie de MiniMax-M2.5 Standard est de 1,20 $/M tokens, tandis que celui de GLM-5 est de 3,20 $/M tokens ; M2.5 est donc environ 2,7 fois moins cher. Si vous optez pour la version haute vitesse M2.5 Lightning (2,40 $/M), le prix se rapproche de celui de GLM-5 mais avec une rapidité d'exécution bien supérieure. En passant par la plateforme APIYI (apiyi.com), vous pouvez également bénéficier de tarifs préférentiels sur vos recharges.
Q3 : Comment comparer rapidement les performances réelles des deux modèles ?
Nous vous recommandons d'utiliser l'accès unifié via la plateforme APIYI (apiyi.com) :
- Créez un compte pour obtenir votre clé API et vos crédits gratuits.
- Préparez deux types de tâches de test : une axée sur le codage et l'autre sur le raisonnement.
- Appelez MiniMax-M2.5 et GLM-5 pour la même tâche.
- Comparez la qualité des réponses, la vitesse de réaction et la consommation de tokens.
- Grâce à l'interface compatible OpenAI, il vous suffit de modifier le paramètre
modelpour basculer de l'un à l'autre.
Conclusion
Voici les points clés de la comparaison entre MiniMax-M2.5 et GLM-5 :
- M2.5, le premier choix pour le codage : SWE-Bench 80,2 % contre 77,8 % (soit une avance de 2,4 %), et n°1 du secteur pour l'appel d'outils avec 76,8 % au BFCL.
- GLM-5, le premier choix pour le raisonnement : AIME 92,7 %, GPQA 86,0 %, et un score de 50,4 au "Humanity's Last Exam", surpassant Opus 4.5.
- Fiabilité des connaissances supérieure pour GLM-5 : Leader du secteur selon l'évaluation d'hallucinations AA-Omniscience, ses sorties factuelles sont plus dignes de confiance.
- Meilleur rapport qualité-prix pour M2.5 : Son prix de sortie ne représente que 37 % de celui de GLM-5, et la version Lightning offre une vitesse accrue.
Bien que les deux modèles soient sous licence MIT et basés sur une architecture MoE, leurs positionnements sont radicalement différents : M2.5 est le "roi du codage et des agents d'exécution", tandis que GLM-5 est le "pionnier du raisonnement et de la fiabilité". Nous vous suggérons de basculer entre les deux selon vos besoins réels via la plateforme APIYI (apiyi.com) pour profiter des meilleurs tarifs.
📚 Références
-
Annonce officielle de MiniMax M2.5 : Capacités de codage de base de M2.5 et détails de l'entraînement Forge RL
- Lien :
minimax.io/news/minimax-m25 - Description : Données de référence complètes incluant SWE-Bench 80,2 %, BFCL 76,8 %, etc.
- Lien :
-
Lancement officiel de GLM-5 : Architecture MoE de 744B et technologie d'entraînement SLIME de Zhipu GLM-5
- Lien :
docs.z.ai/guides/llm/glm-5 - Description : Comprend des données de référence de raisonnement telles que AIME 92,7 %, GPQA 86,0 %, etc.
- Lien :
-
Évaluation indépendante d'Artificial Analysis : Tests de référence standardisés et classements des deux modèles
- Lien :
artificialanalysis.ai/models/glm-5 - Description : Données indépendantes sur l'Intelligence Index, tests de vitesse réels, comparaison des prix, etc.
- Lien :
-
Analyse approfondie de BuildFastWithAI : Tests de référence complets de GLM-5 et comparaison avec la concurrence
- Lien :
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - Description : Tableaux comparatifs détaillés avec Opus 4.5 et GPT-5.2.
- Lien :
-
MiniMax HuggingFace : Poids du modèle open-source M2.5
- Lien :
huggingface.co/MiniMaxAI - Description : Licence MIT, supporte le déploiement via vLLM/SGLang.
- Lien :
Auteur : Équipe APIYI
Échanges techniques : N'hésitez pas à partager vos résultats de tests comparatifs de modèles dans l'espace commentaires. Pour plus de tutoriels sur l'intégration des API de grands modèles de langage, visitez la communauté technique APIYI sur apiyi.com.