Lors du développement d'applications d'IA avec Qwen3-Max, rencontrer fréquemment l'erreur 429 You exceeded your current quota est un problème majeur pour de nombreux développeurs. Cet article analyse en profondeur le mécanisme de limitation de Qwen3-Max d'Alibaba Cloud et propose 5 solutions pratiques pour vous aider à surmonter définitivement les contraintes de quota.
Valeur ajoutée : En lisant cet article, vous comprendrez les principes de limitation de Qwen3-Max, maîtriserez diverses solutions et choisirez la méthode la plus adaptée pour appeler ce grand modèle de langage aux billions de paramètres de manière stable.
Aperçu des problèmes de limitation de débit de Qwen3-Max
Message d'erreur typique
Lorsque votre application appelle fréquemment l'API Qwen3-Max, vous pouvez rencontrer l'erreur suivante :
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
Cette erreur signifie que vous avez atteint les limites de quota imposées par Model Studio d'Alibaba Cloud.
Impact des problèmes de limitation de débit de Qwen3-Max
| Scénario d'impact | Manifestation concrète | Sévérité |
|---|---|---|
| Développement d'Agents | Interruptions fréquentes des dialogues multi-tours | Élevée |
| Traitement par lots | Tâches impossibles à terminer | Élevée |
| Applications en temps réel | Expérience utilisateur dégradée | Élevée |
| Génération de code | Sortie de code long tronquée | Moyenne |
| Tests et débogage | Baisse de productivité | Moyenne |
Détails du mécanisme de limitation de débit de Qwen3-Max
Limites de quotas officiels d'Alibaba Cloud
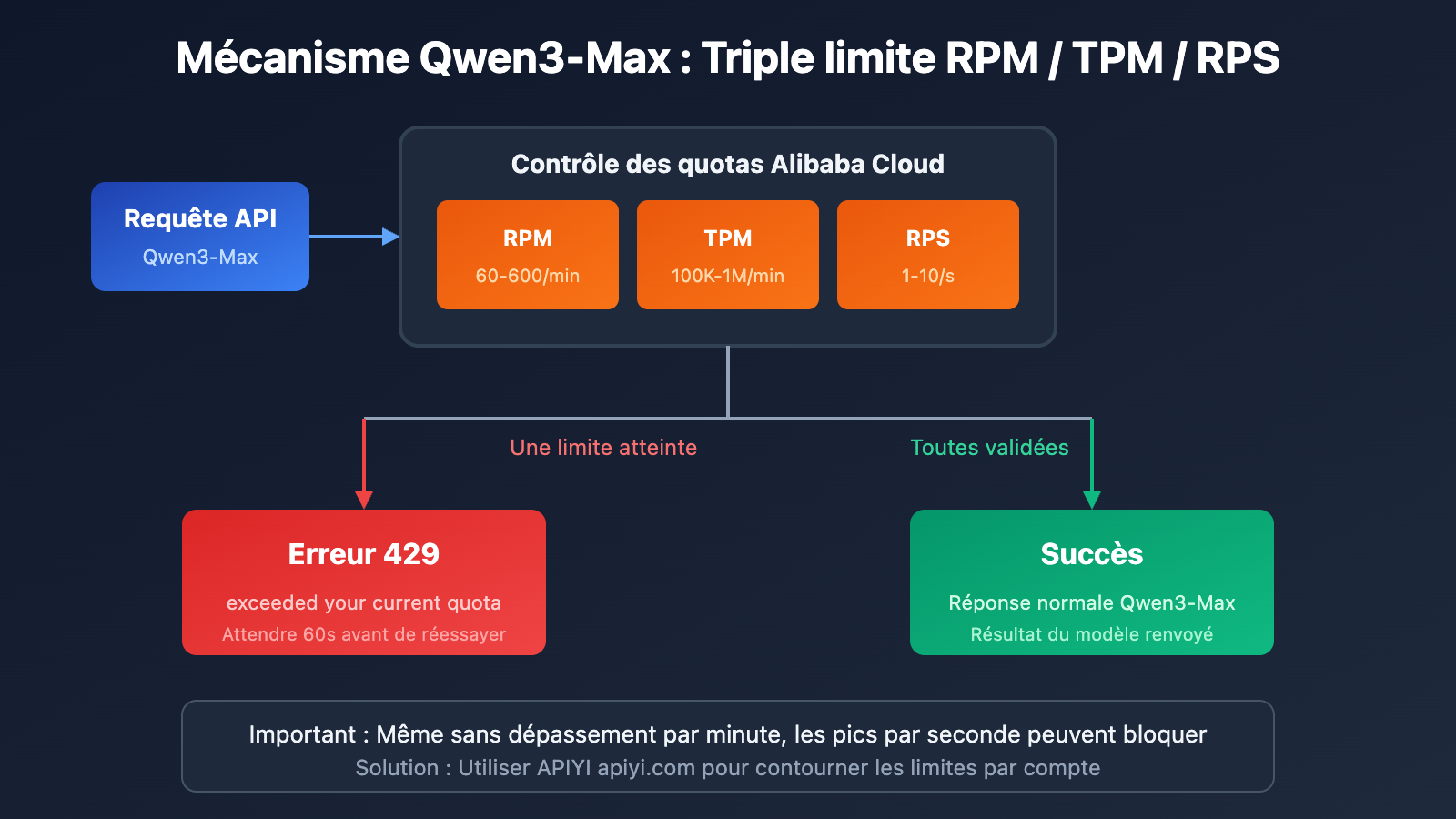
Selon la documentation officielle d'Alibaba Cloud Model Studio, les limites de quotas pour Qwen3-Max sont les suivantes :
| Version du modèle | RPM (Requêtes/min) | TPM (Jetons/min) | RPS (Requêtes/s) |
|---|---|---|---|
| qwen3-max | 600 | 1 000 000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100 000 | 1 |
Les 4 situations déclenchant la limitation de Qwen3-Max
Alibaba Cloud applique un mécanisme de double contrainte pour Qwen3-Max. L'activation de l'une de ces conditions renverra une erreur 429 :
| Type d'erreur | Message d'erreur | Cause du déclenchement |
|---|---|---|
| Fréquence de requêtes dépassée | Requests rate limit exceeded | RPM/RPS dépasse la limite |
| Consommation de jetons dépassée | You exceeded your current quota | TPM/TPS dépasse la limite |
| Protection contre les pics de trafic | Request rate increased too quickly | Augmentation soudaine des requêtes |
| Quota gratuit épuisé | Free allocated quota exceeded | Fin du crédit d'essai |
Formule de calcul de la limite
Limite réelle = min(Limite RPM, RPS × 60)
= min(Limite TPM, TPS × 60)
Note importante : Même si vous ne dépassez pas la limite sur une minute entière, des requêtes groupées en une seule seconde peuvent déclencher la limitation de débit.
5 solutions aux problèmes de limitation de Qwen3-Max
Aperçu comparatif des solutions
| Solution | Difficulté | Efficacité | Coût | Scénario recommandé |
|---|---|---|---|---|
| Service de relais API | Faible | Résolution totale | Plus économique | Tous les scénarios |
| Stratégie de lissage | Moyenne | Atténuation | Gratuit | Limitation légère |
| Rotation multi-comptes | Haute | Atténuation | Élevé | Utilisateurs entreprise |
| Rétrogradation (Fallback) | Moyenne | Sécurité | Moyen | Tâches non critiques |
| Demande d'augmentation | Faible | Limitée | Gratuit | Utilisateurs long terme |
Solution 1 : Utiliser un service de relais API (Recommandé)
C'est la solution la plus directe et efficace pour régler les problèmes de limitation de Qwen3-Max. En passant par une plateforme de relais API, vous contournez les quotas limités au niveau du compte individuel Alibaba Cloud.
Pourquoi le relais API résout la limitation
| Point de comparaison | Direct Alibaba Cloud | Via APIYI |
|---|---|---|
| Limite de quota | Quotas RPM/TPM par compte | Pool de ressources partagé |
| Fréquence de blocage | Erreurs 429 fréquentes | Quasiment aucun blocage |
| Prix | Tarif officiel | Réduction massive (env. 90%) |
| Stabilité | Dépend du quota du compte | Garantie par canaux multiples |
Exemple de code minimaliste
from openai import OpenAI
# Utilisation du service APIYI pour dire adieu aux limitations
client = OpenAI(
api_key="votre-cle-apiyi",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "Explique-moi le fonctionnement de l'architecture MoE."}
]
)
print(response.choices[0].message.content)
🎯 Recommandation : En appelant Qwen3-Max via APIYI (apiyi.com), non seulement vous résolvez radicalement les problèmes de débit, mais vous profitez également de tarifs préférentiels. APIYI collabore avec Alibaba Cloud pour offrir un service plus stable à un coût réduit.
Voir le code complet (avec gestion des erreurs et tentatives)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Client Qwen3-Max via APIYI, sans soucis de débit"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Interface de relais APIYI
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
Envoie un message et récupère la réponse.
Via APIYI, les problèmes de limitation sont rarissimes.
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# APIYI ne déclenche normalement pas cette exception
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Requête limitée, nouvel essai dans {wait_time}s...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"Erreur API : {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""Traitement par lots, sans crainte de limitation"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# Exemple d'utilisation
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="votre-cle-apiyi")
# Appel unique
response = client.chat("Écris un algorithme de tri rapide en Python")
print(response)
# Appels en série - Aucun souci avec APIYI
questions = [
"Explique ce qu'est l'architecture MoE",
"Compare Transformer et RNN",
"Qu'est-ce que le mécanisme d'attention ?"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"Q: {q}\nA: {a}\n")
Solution 2 : Stratégie de lissage des requêtes
Si vous tenez à utiliser une connexion directe avec Alibaba Cloud, vous pouvez atténuer le problème en lissant vos appels.
Reprise exponentielle (Exponential Backoff)
import time
import random
def call_with_backoff(func, max_retries=5):
"""Stratégie de reprise exponentielle"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# Attente exponentielle + variation aléatoire (jitter)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Limitation active, attente de {wait_time:.2f}s avant essai...")
time.sleep(wait_time)
else:
raise e
File d'attente tampon
import asyncio
from collections import deque
class RequestQueue:
"""File d'attente pour lisser la fréquence d'appel à Qwen3-Max"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # Intervalle entre requêtes
self.last_request = 0
async def throttled_request(self, request_func):
"""Requête avec contrôle de débit"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
Attention : Le lissage ne fait qu'atténuer le problème, il ne le règle pas. Pour les scénarios à haute concurrence, le passage par APIYI reste préférable.
Solution 3 : Rotation multi-comptes
Les entreprises peuvent augmenter leur quota global en faisant tourner plusieurs comptes.
from itertools import cycle
class MultiAccountClient:
"""Client avec rotation multi-comptes"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| Nombre de comptes | RPM équivalent | TPM équivalent | Complexité de gestion |
|---|---|---|---|
| 1 | 600 | 1 000 000 | Faible |
| 3 | 1 800 | 3 000 000 | Moyenne |
| 5 | 3 000 | 5 000 000 | Haute |
| 10 | 6 000 | 10 000 000 | Très haute |
💡 Conseil : Gérer plusieurs comptes est complexe et coûteux. Il est bien plus simple d'utiliser le relais APIYI (apiyi.com) qui offre un quota mutualisé massif sans gestion administrative.
Solution 4 : Rétrogradation vers un modèle de secours (Fallback)
Dès que Qwen3-Max atteint sa limite, vous pouvez automatiquement basculer vers un modèle plus léger.
class FallbackClient:
"""Client Qwen avec gestion du repli"""
MODEL_PRIORITY = [
"qwen3-max", # Premier choix
"qwen-plus", # Secours 1
"qwen-turbo", # Secours 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Utilisation d'APIYI
)
def chat(self, message: str) -> tuple[str, str]:
"""Retourne (contenu de la réponse, modèle réellement utilisé)"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"Limite atteinte pour {model}, passage au modèle inférieur...")
continue
raise e
raise Exception("Aucun modèle n'est disponible actuellement")
Solution 5 : Demander une augmentation de quota
Pour les utilisateurs ayant des besoins stables à long terme, il est possible de demander une extension de quota auprès d'Alibaba Cloud.
Procédure :
- Connectez-vous à la console Alibaba Cloud.
- Allez dans la section de gestion des quotas de Model Studio.
- Soumettez une demande d'augmentation de quota.
- Attendez la validation (généralement 1 à 3 jours ouvrés).
Conditions requises :
- Compte avec identité vérifiée.
- Aucun historique d'impayés.
- Justification détaillée du scénario d'utilisation.
Comparaison des coûts et des limitations de débit pour Qwen3-Max
Analyse comparative des prix
| Prestataire | Prix Input (0-32K) | Prix Output | État des limitations (Rate Limits) |
|---|---|---|---|
| Alibaba Cloud (Direct) | 1,20 $/M | 6,00 $/M | Limites strictes RPM/TPM |
| APIYI (Remise 12%) | 1,06 $/M | 5,28 $/M | Pratiquement aucune limitation |
| Différence | Économie de 12% | Économie de 12% | – |
Calcul du coût total
Supposons un volume d'appels mensuel de 10 millions de tokens (moitié input, moitié output) :
| Solution | Frais mensuels | Impact des limitations | Évaluation globale |
|---|---|---|---|
| Alibaba Cloud (Direct) | 36,00 $ | Interruptions fréquentes, nécessite des tentatives | Coût réel plus élevé |
| Relais APIYI | 31,68 $ | Stable et sans interruption | Meilleur rapport qualité-prix |
| Solution multi-comptes | 36,00 $+ | Coût de gestion élevé | Non recommandé |
💰 Optimisation des coûts : APIYI (apiyi.com) bénéficie d'un partenariat de distribution avec Alibaba Cloud. Non seulement le prix est réduit de 12% par défaut, mais cela permet aussi de résoudre radicalement les problèmes de limitation de débit. Pour les scénarios d'utilisation à fréquence moyenne ou élevée, le coût global est nettement inférieur.
Questions fréquentes
Q1 : Pourquoi suis-je déjà limité sur Qwen3-Max alors que je viens de commencer ?
Alibaba Cloud Model Studio offre un quota gratuit limité pour les nouveaux comptes, et les quotas pour la nouvelle version qwen3-max-2025-09-23 sont encore plus bas (60 RPM, 100 000 TPM). Si vous utilisez une version "snapshot", les limitations sont encore plus strictes.
Il est conseillé de passer par APIYI (apiyi.com) pour vos appels, ce qui permet de contourner les restrictions de quota au niveau du compte individuel.
Q2 : Combien de temps faut-il attendre pour que le débit soit rétabli après une limitation ?
La limitation d'Alibaba Cloud repose sur un mécanisme de fenêtre glissante :
- Limite RPM (Requêtes Par Minute) : attente d'environ 60 secondes.
- Limite TPM (Tokens Par Minute) : attente d'environ 60 secondes.
- Protection contre les pics (Burst) : peut nécessiter une attente plus longue.
L'utilisation de la plateforme APIYI permet d'éviter ces attentes fréquentes et d'améliorer l'efficacité du développement.
Q3 : Comment la stabilité du service de relais APIYI est-elle garantie ?
APIYI entretient un partenariat avec Alibaba Cloud et utilise un mode de quota par "pool" au niveau plateforme :
- Équilibrage de charge multi-canaux.
- Basculement automatique (failover).
- Garantie de disponibilité de 99,9 %.
Par rapport aux limitations de quota d'un compte personnel, le service au niveau plateforme est beaucoup plus stable et fiable.
Q4 : L’utilisation d’APIYI nécessite-t-elle de modifier beaucoup de code ?
Presque aucune modification n'est nécessaire. APIYI est entièrement compatible avec le format du SDK OpenAI. Vous n'avez qu'à modifier deux lignes :
# Avant modification (Direct Alibaba Cloud)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# Après modification (Relais APIYI)
client = OpenAI(
api_key="your-apiyi-key", # Remplacez par votre clé APIYI
base_url="https://api.apiyi.com/v1" # Remplacez par l'adresse APIYI
)
Le nom du modèle et le format des paramètres restent identiques, aucun autre changement n'est requis.
Q5 : En plus de Qwen3-Max, quels autres modèles sont supportés par APIYI ?
La plateforme APIYI permet d'appeler de manière unifiée plus de 200 grands modèles de langage (LLM) courants, notamment :
- Série Qwen complète : qwen3-max, qwen-plus, qwen-turbo, qwen-vl, etc.
- Série Claude : claude-3-opus, claude-3-sonnet, claude-3-haiku.
- Série GPT : gpt-4o, gpt-4-turbo, gpt-3.5-turbo.
- Autres : Gemini, DeepSeek, Moonshot, etc.
Tous les modèles utilisent une interface unique : une seule clé API pour les appeler tous.
Synthèse des solutions au problème de limitation de débit (Rate Limit) de Qwen3-Max
Arbre de décision pour choisir une solution
Erreur Qwen3-Max 429 rencontrée
│
├─ Besoin d'une solution radicale → Utiliser le relais APIYI (recommandé)
│
├─ Limitation légère → Lissage des requêtes + exponential backoff
│
├─ Appels à grande échelle (entreprise) → Rotation de comptes ou APIYI Entreprise
│
└─ Tâches non critiques → Basculement vers un modèle de secours
Récapitulatif des points clés
| Point clé | Description |
|---|---|
| Cause de la limitation | Triple restriction Alibaba Cloud : RPM / TPM / RPS |
| Solution optimale | Service de relais APIYI, pour une résolution définitive |
| Avantage de coût | Tarifs ultra-compétitifs, bien plus économique qu'en direct |
| Coût de migration | Minimal : il suffit de modifier base_url et api_key |
Nous recommandons d'utiliser APIYI (apiyi.com) pour résoudre rapidement les problèmes de limitation de Qwen3-Max, tout en profitant d'un service stable et de tarifs avantageux.
Ressources complémentaires
-
Documentation Alibaba Cloud sur les limites de débit : Spécifications officielles des limitations
- Lien :
alibabacloud.com/help/en/model-studio/rate-limit
- Lien :
-
Documentation Alibaba Cloud sur les codes d'erreur : Détails des codes d'erreur
- Lien :
alibabacloud.com/help/en/model-studio/error-code
- Lien :
-
Documentation du modèle Qwen3-Max : Spécifications techniques officielles
- Lien :
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- Lien :
Support technique : Si vous rencontrez des difficultés avec l'utilisation de Qwen3-Max, n'hésitez pas à solliciter l'assistance technique via APIYI sur apiyi.com.