Note de l'auteur : Découvrez comment PaperBanana produit des graphiques statistiques de recherche en générant du code Matplotlib exécutable plutôt que des images pixélisées. Cette approche élimine totalement le problème des hallucinations numériques et couvre 7 types de graphiques, notamment les diagrammes à barres, les graphiques linéaires et les nuages de points.
Les graphiques statistiques dans les articles de recherche portent les conclusions fondamentales des expériences : la hauteur d'une barre, la tendance d'une courbe, la distribution d'un nuage de points… chaque point de donnée doit être d'une précision chirurgicale. Cependant, lorsque vous utilisez des générateurs d'images généralistes comme DALL-E ou Midjourney pour créer ces graphiques, un problème fatal persiste : l'hallucination numérique (Numerical Hallucination). Des hauteurs de barres qui ne correspondent pas à l'échelle, des points de données décalés, des étiquettes d'axes erronées — ces graphiques qui "ont l'air corrects mais dont les données sont fausses" peuvent avoir des conséquences désastreuses s'ils figurent dans une publication scientifique.
Valeur ajoutée : À la fin de cet article, vous comprendrez pourquoi PaperBanana privilégie la génération de code plutôt que la génération d'images pour la visualisation de données académiques. Vous maîtriserez les méthodes de génération de code Matplotlib pour 7 types de graphiques et apprendrez comment réaliser des visualisations de données sans aucune hallucination à moindre coût grâce à l'API Nano Banana Pro via APIYI.

Points clés des graphiques statistiques scientifiques de Nano Banana Pro
| Point clé | Description | Valeur |
|---|---|---|
| Génération de code plutôt que de pixels | PaperBanana génère du code Matplotlib exécutable au lieu de rendre directement une image | Hauteur des barres, points de données et axes sont 100 % mathématiquement exacts |
| Élimination totale des hallucinations numériques | Le pilotage par code garantit que chaque point de données correspond exactement aux données originales | Élimine le problème critique des données qui "semblent correctes" mais sont fausses |
| Couverture de 7 types de graphiques | Histogrammes, courbes, nuages de points, cartes de chaleur, radars, camemberts, graphiques multi-panneaux | Répond à plus de 95 % des besoins en graphiques pour les articles de recherche |
| 240 tests ChartMimic | Validation sur des benchmarks standards : le code généré est fonctionnel et visuellement fidèle | 72,7 % de taux de réussite en évaluation aveugle (courbes/barres/nuages/multi-panneaux) |
| Modifiable et reproductible | Le code Python en sortie permet d'ajuster librement les couleurs, annotations et polices | Pas besoin de tout régénérer, on peut peaufiner directement jusqu'aux standards de publication |
Pourquoi les graphiques statistiques scientifiques ne peuvent pas être générés comme de simples images
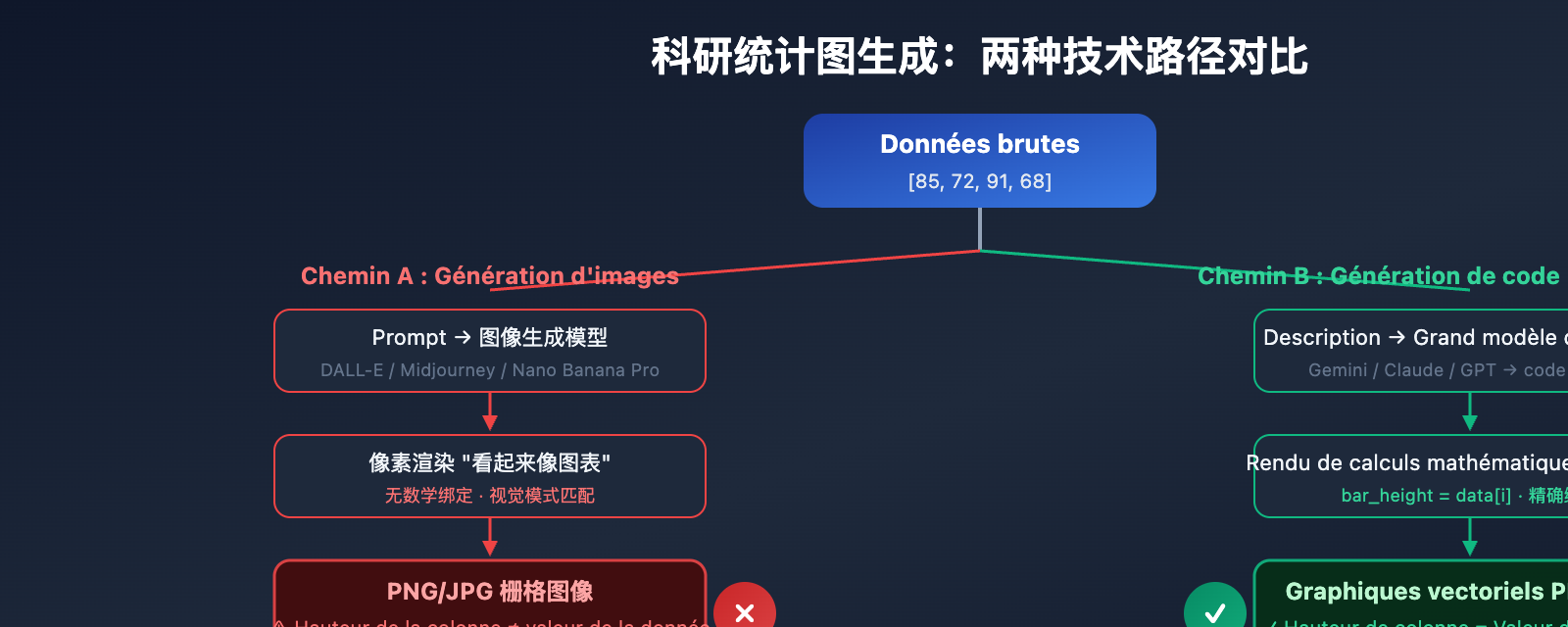
Les modèles de génération d'images IA traditionnels (comme DALL-E 3 ou Midjourney V7) présentent un défaut fondamental lorsqu'il s'agit de créer des graphiques scientifiques : ils rendent les graphiques sous forme de « pixels » plutôt que de les tracer à partir de « données ». Cela signifie que lorsqu'un modèle génère un histogramme, il ne calcule pas la hauteur des barres en fonction de valeurs comme [85, 72, 91, 68], mais remplit les pixels selon des motifs visuels qui « ressemblent à un histogramme ».
Le résultat ? Des hallucinations numériques : la hauteur des barres ne correspond pas à l'échelle de l'axe Y, les points de données sont décalés par rapport à leur position réelle, et les étiquettes des axes sont souvent illisibles ou erronées. Dans les évaluations de PaperBanana, lors de l'utilisation directe de modèles de génération d'images pour des graphiques statistiques, les « hallucinations numériques et répétitions d'éléments » sont les erreurs de fidélité les plus courantes.
PaperBanana adopte une stratégie radicalement différente : pour les graphiques statistiques, l'agent Visualizer n'utilise pas les capacités de génération d'images de Nano Banana Pro, mais génère du code Python Matplotlib exécutable. Cette approche « code-first » élimine fondamentalement les hallucinations numériques, car le code lie les données aux éléments visuels via des calculs mathématiques précis.
Analyse approfondie du problème d'hallucination numérique
Qu'est-ce que l'hallucination numérique dans les graphiques statistiques scientifiques ?
L'hallucination numérique désigne le phénomène par lequel les modèles de génération d'images par IA produisent des éléments visuels incohérents avec les données réelles lors de la création de graphiques statistiques. Les manifestations concrètes incluent :
- Décalage de la hauteur des barres : La hauteur des barres dans un histogramme ne correspond pas aux valeurs de l'axe Y.
- Dérive des points de données : Dans un nuage de points, les points s'écartent des coordonnées (x, y) correctes.
- Erreurs d'échelle : L'espacement des graduations sur les axes n'est pas uniforme ou les étiquettes numériques sont erronées.
- Confusion de la légende : Les couleurs de la légende ne correspondent pas aux séries de données réelles.
- Étiquettes illisibles : Apparition de fautes d'orthographe ou de chevauchements de texte sur les étiquettes des axes.
Causes fondamentales de l'hallucination numérique
L'objectif d'entraînement des modèles de génération d'images généralistes est de « générer des images visuellement réalistes » et non de « générer des graphiques mathématiquement précis ». Lorsqu'un modèle voit dans une invite « histogramme, valeurs [85, 72, 91, 68] », il ne construit pas une correspondance mathématique entre la valeur numérique et la hauteur en pixels. Il génère une apparence approximative basée sur les « motifs visuels » de nombreux histogrammes présents dans son jeu d'entraînement.
| Type de problème | Manifestation concrète | Fréquence | Gravité |
|---|---|---|---|
| Décalage de la hauteur | La hauteur ne correspond pas à la valeur | Très élevée | Fatale : modifie les conclusions |
| Dérive des points | Les points s'écartent des coordonnées | Élevée | Fatale : distorsion des données |
| Erreurs d'échelle | Graduations de l'axe non uniformes | Élevée | Grave : induit le lecteur en erreur |
| Confusion de la légende | Couleur ne correspond pas à la série | Moyenne | Grave : impossible de distinguer les données |
| Étiquettes illisibles | Chevauchement ou fautes d'orthographe | Moyenne | Modérée : affecte la lisibilité |
Comment la génération de code de PaperBanana élimine l'hallucination numérique
La solution de PaperBanana est aussi simple que radicale : pour les graphiques statistiques scientifiques, on ne génère pas d'image, mais du code.
Lorsque l'agent Visualizer de PaperBanana reçoit une tâche de graphique statistique, il convertit la description du graphique en code Python Matplotlib exécutable. Dans ce code, la hauteur de chaque barre, les coordonnées de chaque point et les graduations de chaque axe sont déterminées avec précision par des calculs mathématiques — et non "devinées" par un réseau de neurones.
Cette approche privilégiant le code apporte également une valeur ajoutée cruciale : l'éditabilité. Vous ne recevez pas une image matricielle figée, mais un bloc de code Python clair. Vous pouvez librement ajuster les couleurs, les polices, les annotations, la position de la légende, et même modifier les données sous-jacentes avant de relancer l'exécution — ce qui est particulièrement pratique lors des phases de révision par les pairs.
🎯 Conseil technique : La capacité de génération de code de PaperBanana est propulsée par un grand modèle de langage. Vous pouvez également appeler directement des modèles comme Nano Banana Pro via APIYI apiyi.com pour générer du code Matplotlib. La plateforme supporte les interfaces compatibles OpenAI et le coût par appel est extrêmement bas.
Génération de code pour 7 types de graphiques statistiques scientifiques avec Nano Banana Pro
PaperBanana a validé l'efficacité de la génération de code sur 240 cas de test de référence ChartMimic, couvrant les types courants tels que les graphiques linéaires, les histogrammes, les nuages de points et les graphiques multi-panneaux. Voici les modèles d'invite et exemples de code pour 7 catégories de graphiques scientifiques.
Type 1 : Histogramme (Bar Chart)
L'histogramme est l'un des types de graphiques les plus utilisés dans les publications pour comparer les résultats expérimentaux sous différentes conditions.
import matplotlib.pyplot as plt
import numpy as np
# 实验数据
models = ['GPT-4o', 'Claude 4', 'Gemini 2', 'Llama 3', 'Qwen 3']
accuracy = [89.2, 91.5, 87.8, 83.4, 85.1]
colors = ['#3b82f6', '#10b981', '#f59e0b', '#ef4444', '#8b5cf6']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(models, accuracy, color=colors, width=0.6, edgecolor='white')
# 添加数值标签
for bar, val in zip(bars, accuracy):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}%', ha='center', va='bottom', fontsize=10, fontweight='bold')
ax.set_ylabel('Accuracy (%)', fontsize=12)
ax.set_title('Model Performance Comparison on MMLU Benchmark', fontsize=14)
ax.set_ylim(75, 95)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('bar_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Type 2 : Graphique linéaire (Line Chart)
Le graphique linéaire montre les tendances en fonction du temps ou des conditions, idéal pour les courbes d'apprentissage et les études d'ablation.
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 21)
train_loss = 2.5 * np.exp(-0.15 * epochs) + 0.3 + np.random.normal(0, 0.02, 20)
val_loss = 2.5 * np.exp(-0.12 * epochs) + 0.45 + np.random.normal(0, 0.03, 20)
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(epochs, train_loss, 'o-', color='#3b82f6', label='Train Loss', linewidth=2, markersize=4)
ax.plot(epochs, val_loss, 's--', color='#ef4444', label='Val Loss', linewidth=2, markersize=4)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Loss', fontsize=12)
ax.set_title('Training and Validation Loss Curves', fontsize=14)
ax.legend(fontsize=11, frameon=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('line_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Type 3 : Nuage de points (Scatter Plot)
Utilisé pour montrer la corrélation entre deux variables ou la distribution de clusters.
Type 4 : Carte de chaleur (Heatmap)
Idéal pour présenter les matrices de confusion, les matrices de poids d'attention et les matrices de corrélation.
Type 5 : Graphique en radar (Radar Chart)
Utilisé pour la comparaison de capacités multidimensionnelles, fréquent dans l'évaluation globale des modèles.
Type 6 : Diagramme circulaire/en anneau (Pie/Donut Chart)
Présente les proportions de composition, adapté à l'analyse de la distribution des jeux de données et de l'allocation des ressources.
Type 7 : Graphique multi-panneaux (Multi-Panel)
Combine plusieurs sous-graphiques dans une seule figure, c'est la forme de graphique composite la plus courante dans les articles scientifiques.
| Type de graphique | Scénario d'application | Fonction Matplotlib clé | Utilisation courante |
|---|---|---|---|
| Histogramme | Comparaison discrète | ax.bar() |
Performance des modèles, ablation |
| Graphique linéaire | Évolution des tendances | ax.plot() |
Courbes d'entraînement, convergence |
| Nuage de points | Corrélation/Cluster | ax.scatter() |
Distribution de caractéristiques, embeddings |
| Carte de chaleur | Données matricielles | sns.heatmap() |
Matrice de confusion, poids d'attention |
| Graphique en radar | Comparaison multidim. | ax.plot() + polar |
Évaluation globale de modèle |
| Diagramme circulaire | Composition proportionnelle | ax.pie() |
Distribution de jeu de données |
| Multi-panneaux | Présentation composite | plt.subplots() |
Figure 1(a)(b)(c) |
💰 Optimisation des coûts : En utilisant APIYI apiyi.com pour appeler de grands modèles de langage afin de générer du code Matplotlib, le coût par appel est bien inférieur à celui de la génération d'images. Générer 50 lignes de code Matplotlib ne coûte qu'environ 0,01 $, et le code peut être modifié et exécuté à plusieurs reprises sans nouvel appel API. Nous recommandons également l'outil en ligne Image.apiyi.com pour vérifier rapidement les effets de visualisation.
Prise en main rapide des graphiques statistiques scientifiques avec Nano Banana Pro
Exemple minimaliste : générer le code d'un graphique à barres précis avec l'IA
Voici la manière la plus simple d'utiliser un grand modèle de langage via API pour laisser l'IA générer automatiquement le code Matplotlib basé sur vos données :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # 使用 APIYI 统一接口
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{
"role": "user",
"content": """Generate publication-ready Python Matplotlib code for a grouped bar chart.
Data:
- Models: ['Method A', 'Method B', 'Method C', 'Ours']
- BLEU Score: [32.1, 35.4, 33.8, 38.7]
- ROUGE-L: [41.2, 43.8, 42.1, 47.3]
Requirements:
- Grouped bars with distinct colors (blue and green)
- Value labels on top of each bar
- Clean academic style, no top/right spines
- Title: 'Translation Quality Comparison'
- Save as PDF at 300 dpi
- Figsize: (8, 5)"""
}]
)
print(response.choices[0].message.content)
Voir l’outil complet de génération de code pour graphiques statistiques
import openai
from typing import Dict, List, Optional
def generate_chart_code(
chart_type: str,
data: Dict,
title: str,
style: str = "academic",
figsize: str = "(8, 5)",
save_format: str = "pdf"
) -> str:
"""
使用 AI 生成科研统计图的 Matplotlib 代码
Args:
chart_type: 图表类型 - bar/line/scatter/heatmap/radar/pie/multi-panel
data: 数据字典,包含标签和数值
title: 图表标题
style: 风格 - academic/minimal/detailed
figsize: 图表尺寸
save_format: 导出格式 - pdf/png/svg
Returns:
可执行的 Matplotlib Python 代码
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI统一接口
)
style_guide = {
"academic": "Clean academic style: no top/right spines, "
"serif fonts, 300 dpi, tight layout",
"minimal": "Minimal style: grayscale-friendly, thin lines, "
"no grid, compact layout",
"detailed": "Detailed style: with grid, annotations, "
"error bars where applicable"
}
prompt = f"""Generate publication-ready Python Matplotlib code.
Chart type: {chart_type}
Data: {data}
Title: {title}
Style: {style_guide.get(style, style_guide['academic'])}
Figure size: {figsize}
Export: Save as {save_format} at 300 dpi
Requirements:
- All data values must be mathematically precise
- Include proper axis labels and legend
- Use colorblind-friendly palette
- Code must be executable without modification
- Add value annotations where appropriate"""
try:
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:生成模型性能对比柱状图
code = generate_chart_code(
chart_type="grouped_bar",
data={
"models": ["GPT-4o", "Claude 4", "Gemini 2", "Ours"],
"accuracy": [89.2, 91.5, 87.8, 93.1],
"f1_score": [87.5, 90.1, 86.3, 92.4]
},
title="Model Performance on SQuAD 2.0",
style="academic"
)
print(code)
🚀 Démarrage rapide : Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour appeler des modèles d'IA afin de générer le code de vos graphiques scientifiques. La plateforme supporte de nombreux modèles tels que Gemini, Claude et GPT, tous capables de produire du code Matplotlib de haute qualité. Inscrivez-vous pour obtenir un crédit gratuit et générez votre premier graphique en moins de 5 minutes.
Génération de code vs Génération d'images : comparaison de la qualité des graphiques scientifiques
Pourquoi PaperBanana a-t-il abandonné la génération d'images de Nano Banana Pro pour les graphiques scientifiques au profit de la génération de code ? Les données comparatives suivantes expliquent tout.
Problèmes liés à la génération directe d'images
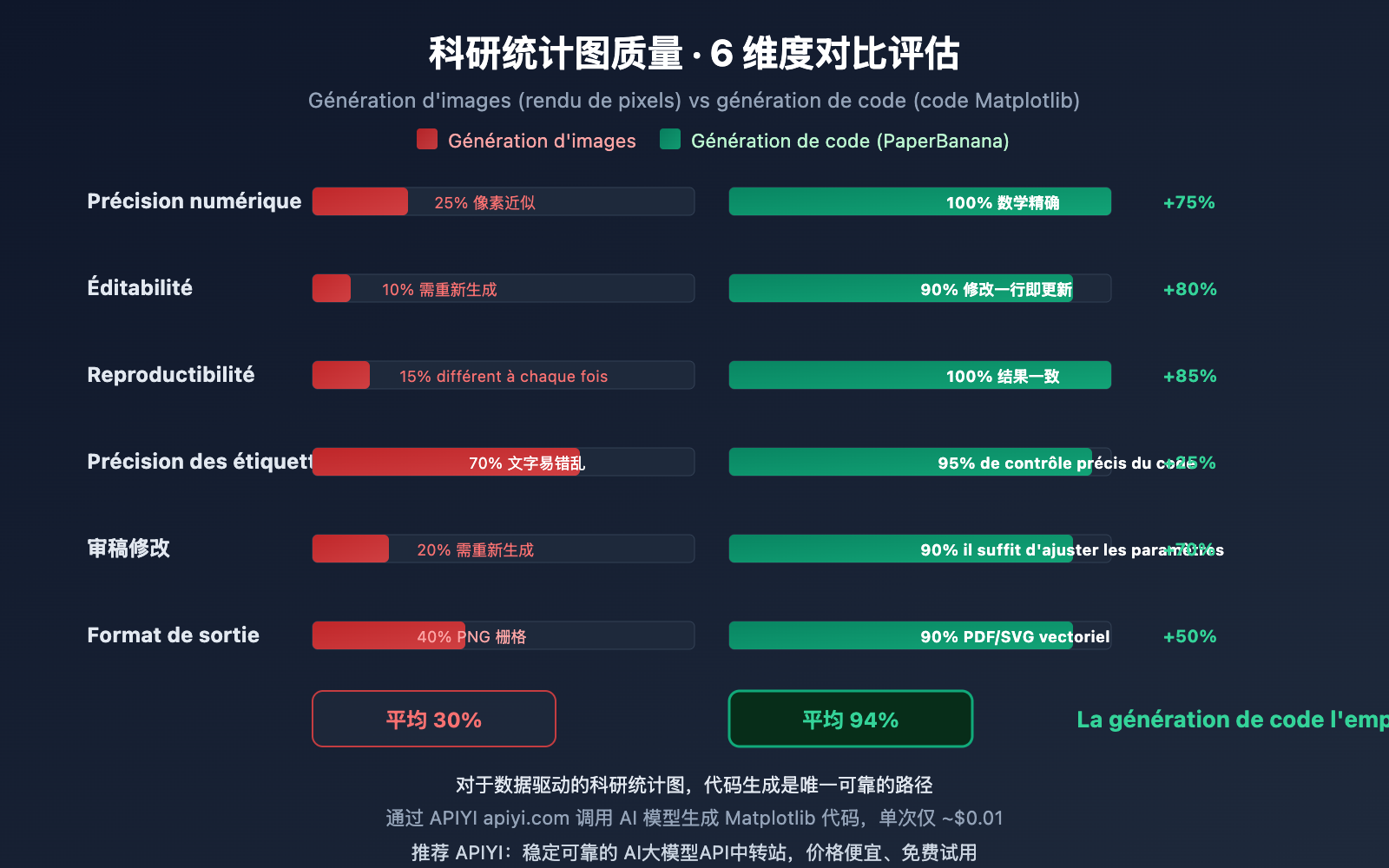
Lorsque vous utilisez Nano Banana Pro, DALL-E 3 ou Midjourney pour générer directement un graphique statistique, le modèle tente de "dessiner" avec des pixels une image qui ressemble à un graphique. Bien que l'effet visuel puisse être séduisant, les problèmes suivants sont presque inévitables :
- Imprécision numérique : Il n'y a aucun lien mathématique entre la hauteur des barres et les données réelles.
- Non éditabilité : Le résultat est une image matricielle (raster), impossible de modifier un seul point de donnée.
- Non reproductibilité : Impossible d'obtenir exactement le même graphique en réexécutant un code.
- Labels erronés : Les étiquettes des axes sont sujettes à des fautes d'orthographe ou des erreurs de valeurs.
Avantages de la génération de code
L'approche de génération de code de PaperBanana est radicalement différente :
- Liaison mathématique : Chaque élément visuel est calculé précisément à partir des valeurs dans le code.
- Éditabilité : Une simple modification d'une ligne de code permet de mettre à jour les couleurs, les labels ou les données.
- Reproductibilité : Le même bloc de code produira un résultat identique quel que soit l'environnement d'exécution.
- Adapté aux révisions : Si un relecteur demande une modification, il suffit d'ajuster les paramètres du code.
| Dimension | Génération d'images (Nano Banana Pro, etc.) | Génération de code (Méthode PaperBanana) |
|---|---|---|
| Précision numérique | Faible : approximation par pixels, risque d'hallucinations | Élevée : précision mathématique, zéro hallucination |
| Éditabilité | Nulle : image matricielle non modifiable | Forte : modification du code pour mise à jour |
| Reproductibilité | Faible : chaque génération est différente | Élevée : exécution du code constante |
| Précision des labels | Moyenne : env. 78-94% de précision textuelle | Élevée : contrôle précis du texte via le code |
| Révisions (Peer Review) | Nécessite de régénérer toute l'image | Ajustement des paramètres et réexécution |
| Format de sortie | Image matricielle PNG/JPG | Image vectorielle PDF/SVG/EPS |
🎯 Conseil de choix : Pour les graphiques statistiques nécessitant une précision rigoureuse (barres, courbes, nuages de points, etc.), nous recommandons vivement la génération de code. Si votre graphique est principalement conceptuel (schéma méthodologique, diagramme d'architecture), la génération d'images de Nano Banana Pro sera plus appropriée. Via la plateforme APIYI (apiyi.com), vous pouvez appeler indifféremment des modèles de génération d'images ou de texte pour une flexibilité totale.
Nano Banana Pro : Techniques de Prompt Engineering pour les graphiques statistiques de recherche
La clé pour obtenir d'un IA un code Matplotlib de haute qualité réside dans la structuration de votre invite. Voici 5 techniques de base éprouvées.
Technique 1 : Les données doivent être fournies explicitement
Ne laissez jamais l'IA « inventer » des données. Fournissez clairement les valeurs complètes dans votre invite, y compris les étiquettes, les valeurs numériques et les unités.
✅ Correct : Data: models=['A','B','C'], accuracy=[89.2, 91.5, 87.8]
❌ Incorrect : Génère un graphique à barres comparant trois modèles
Technique 2 : Spécifier les contraintes de style académique
Les graphiques académiques ont des exigences de mise en page strictes. Précisez les contraintes suivantes dans votre invite :
- Supprimer les bordures supérieure et droite (
spines['top'].set_visible(False)) - Hiérarchie des tailles de police : Titre 14pt, étiquettes d'axes 12pt, graduations 10pt
- Palette de couleurs adaptée aux daltoniens (éviter le combo rouge-vert)
- Exportation au format PDF/EPS avec une résolution de 300+ dpi
Technique 3 : Demander l'ajout d'annotations numériques
Ajoutez des étiquettes de valeur précises au-dessus des barres pour que le lecteur puisse lire les données sans avoir à se référer aux axes — c'est aussi un moyen important d'éliminer toute « ambiguïté visuelle ».
Technique 4 : Exiger l'exécutabilité
Demandez explicitement que le code généré puisse être « exécuté directement sans aucune modification ». Cela poussera l'IA à inclure toutes les instructions d'importation nécessaires, les définitions de données et les commandes de sauvegarde.
Technique 5 : Prévoir de la flexibilité pour les révisions des relecteurs
Demandez à l'IA de placer les définitions de données et les paramètres de style séparément en haut du code, afin de faciliter les modifications rapides ultérieures.
| Technique | Point clé | Impact sur la qualité du code |
|---|---|---|
| 1 | Données explicites | Élimine l'invention de données, garantit la précision |
| 2 | Style académique | Conforme aux exigences de mise en page des revues |
| 3 | Annotations numériques | Améliore la lisibilité du graphique |
| 4 | Exécutabilité | Code prêt à l'emploi |
| 5 | Séparation des paramètres | Efficacité doublée pour les modifications post-relecture |
🎯 Conseil pratique : Combinez ces 5 techniques pour créer votre modèle d'invite standard. Utilisez APIYI (apiyi.com) pour appeler différents modèles et itérer jusqu'à trouver le style de code qui convient le mieux à votre domaine de recherche. La plateforme permet de basculer entre Gemini, Claude, GPT, etc., pour comparer facilement les résultats.
Questions Fréquentes
Q1 : La génération de code par PaperBanana est-elle plus lente que la génération d’images ?
Bien au contraire, la génération de code est généralement plus rapide. Générer un bloc de code Matplotlib de 50 à 80 lignes ne prend que 2 à 5 secondes, alors que la génération d'une image prend 10 à 30 secondes. Plus important encore, une fois le code généré, il peut être exécuté localement et modifié à volonté, sans avoir à appeler l'API à chaque ajustement. En utilisant APIYI (apiyi.com) pour générer du code, le coût par appel est d'environ 0,01 $, ce qui est bien inférieur aux 0,05 $ de la génération d'images.
Q2 : Quelle est la qualité du code Matplotlib généré ? Nécessite-t-il beaucoup de modifications ?
Dans les 240 tests de référence ChartMimic de PaperBanana, le code Python généré était directement exécutable et le rendu visuel correspondait à la description originale. En pratique, il suffit généralement de peaufiner quelques paramètres de style comme les couleurs ou les polices. Nous vous recommandons d'utiliser les modèles Claude ou Gemini via la plateforme APIYI (apiyi.com) pour générer du code, car ces deux modèles excellent particulièrement dans ce domaine. L'outil en ligne Image.apiyi.com permet également de prévisualiser rapidement le résultat.
Q3 : Comment commencer rapidement à générer des codes de graphiques statistiques avec l’IA ?
Voici le parcours recommandé pour débuter :
- Rendez-vous sur APIYI (apiyi.com) pour créer un compte, obtenir votre clé API et vos crédits de test gratuits.
- Préparez vos données expérimentales (noms des modèles, valeurs des indicateurs, etc.).
- Utilisez le modèle d'invite de cet article en remplaçant les données par les vôtres.
- Appelez l'API pour générer le code Matplotlib et exécutez-le localement pour voir le résultat.
- Ajustez les paramètres de style selon les exigences de votre revue, puis exportez en PDF.
Résumé
Points clés de la méthode de génération de code pour les graphiques statistiques de recherche de Nano Banana Pro :
- Le code avant les pixels : PaperBanana utilise la génération de code Matplotlib pour les graphiques statistiques plutôt que le rendu d'image, éliminant ainsi radicalement les hallucinations numériques.
- Couverture complète de 7 types de graphiques : Histogrammes, graphiques linéaires, nuages de points, cartes de chaleur (heatmaps), graphiques radar, diagrammes circulaires et graphiques multi-panneaux, répondant à tous les besoins de visualisation de données pour les articles scientifiques.
- Modifiable et reproductible : La sortie sous forme de code permet des modifications libres et une reproduction précise. Pour les révisions demandées par les relecteurs, il suffit d'ajuster les paramètres au lieu de tout régénérer.
- 5 astuces d'invites (prompts) : Données explicites, contraintes académiques, annotations numériques, exécutabilité et séparation des paramètres, garantissant un code généré de haute qualité et prêt à l'emploi.
Face aux exigences de précision des graphiques statistiques de recherche, le concept de « le code est le graphique » est la seule voie fiable. En utilisant l'IA pour générer du code Matplotlib, vous bénéficiez de l'efficacité de l'IA tout en conservant la précision du code — le meilleur des deux mondes.
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour tester rapidement la génération de code de graphiques statistiques assistée par l'IA. La plateforme propose des crédits gratuits et un choix de plusieurs modèles. Vous pouvez également utiliser l'outil en ligne Image.apiyi.com pour prévisualiser les résultats.
📚 Ressources
⚠️ Format des liens : Tous les liens externes utilisent le format
Nom de la ressource : domain.com, ce qui facilite le copier-coller sans lien cliquable, évitant ainsi la perte de poids SEO.
-
Page d'accueil du projet PaperBanana : Page de publication officielle, incluant l'article et la démo.
- Lien :
dwzhu-pku.github.io/PaperBanana/ - Description : Comprendre les principes fondamentaux de la génération de code de graphiques PaperBanana et consulter les données d'évaluation.
- Lien :
-
Article PaperBanana : Texte intégral du pré-tirage arXiv.
- Lien :
arxiv.org/abs/2601.23265 - Description : Comprendre en profondeur le choix technique entre génération de code et génération d'image, ainsi que le benchmark ChartMimic.
- Lien :
-
Documentation officielle de Matplotlib : Bibliothèque de visualisation de données Python.
- Lien :
matplotlib.org/stable/ - Description : Référence de l'API Matplotlib pour comprendre et modifier le code des graphiques générés par l'IA.
- Lien :
-
Documentation officielle de Nano Banana Pro : Présentation du modèle Google DeepMind.
- Lien :
deepmind.google/models/gemini-image/pro/ - Description : Découvrir les capacités de génération d'images de Nano Banana Pro dans le contexte des schémas méthodologiques.
- Lien :
-
Outil de génération d'images en ligne APIYI : Aperçu de graphiques sans code.
- Lien :
Image.apiyi.com - Description : Prévisualisation rapide du rendu des graphiques statistiques de recherche générés par l'IA.
- Lien :
Auteur : Équipe APIYI
Échanges techniques : N'hésitez pas à partager vos modèles d'invites pour graphiques statistiques et vos astuces Matplotlib dans les commentaires. Pour plus d'actualités sur les modèles d'IA, visitez la communauté technique d'APIYI sur apiyi.com.