作者注:詳解 PaperBanana 如何通過生成可執行 Matplotlib 代碼而非像素圖像來製作科研統計圖,徹底消除數值幻覺問題,覆蓋柱狀圖、折線圖、散點圖等 7 類圖表
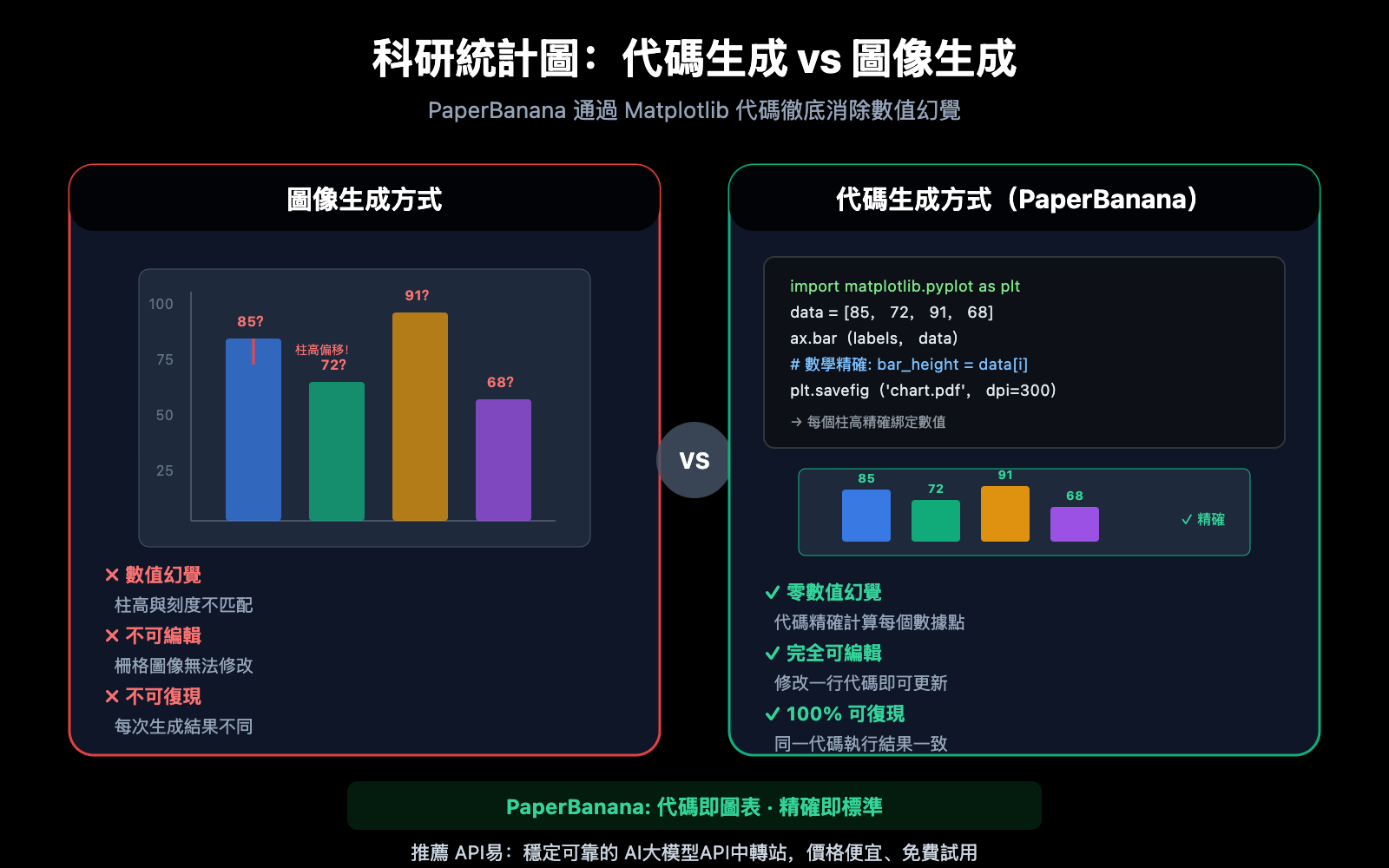
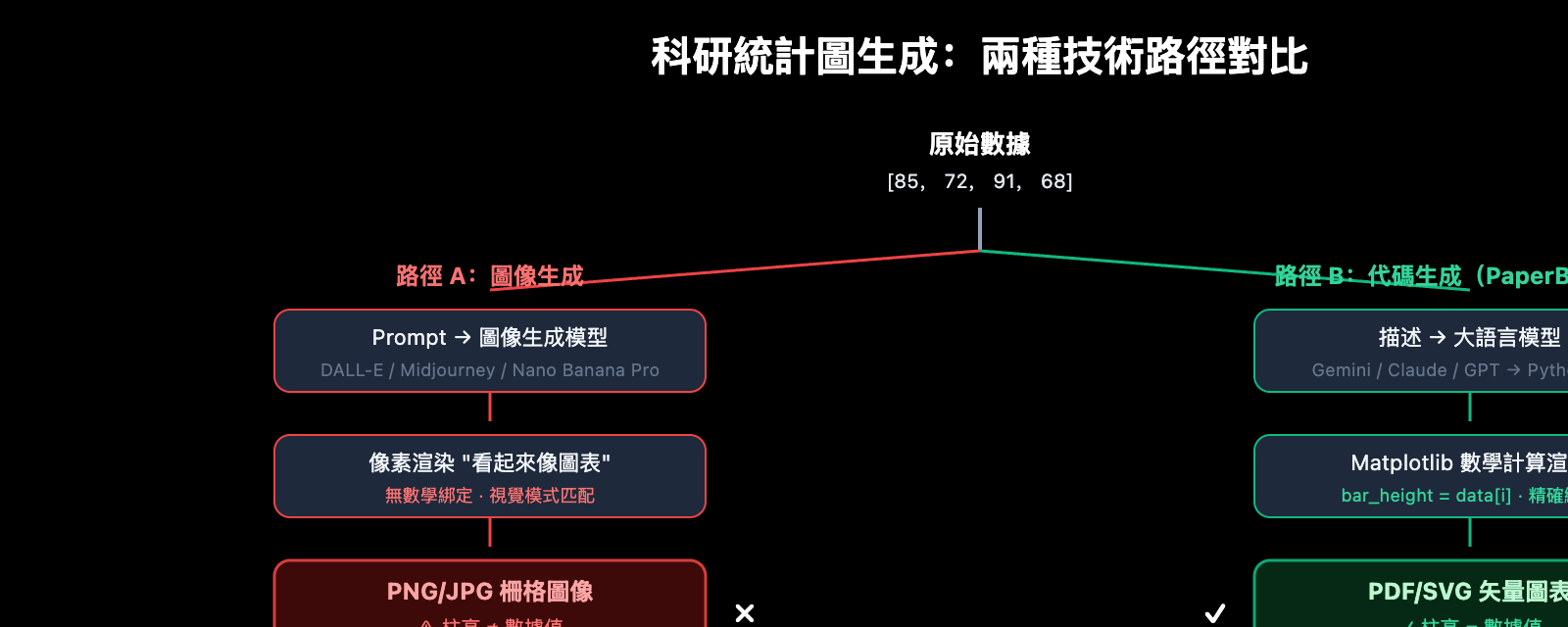
科研論文中的統計圖表承載着實驗的核心結論——柱狀圖的高度、折線圖的趨勢、散點圖的分佈,每一個數據點都必須精確無誤。然而,當你用 DALL-E、Midjourney 等通用圖像生成器製作統計圖時,一個致命問題始終存在:數值幻覺(Numerical Hallucination)。柱高與刻度不匹配、數據點偏移、座標軸標籤錯誤——這些"看起來正確但數據錯誤"的圖表,一旦出現在論文中,後果不堪設想。
核心價值: 讀完本文,你將理解 PaperBanana 爲何選擇代碼生成而非圖像生成來製作科研統計圖,掌握 7 類統計圖的 Matplotlib 代碼生成方法,以及如何通過 Nano Banana Pro API 低成本實現零數值幻覺的學術數據可視化。
Nano Banana Pro 科研統計圖核心要點
| 要點 | 說明 | 價值 |
|---|---|---|
| 代碼生成而非像素 | PaperBanana 生成可執行 Matplotlib 代碼,而非直接渲染圖像 | 柱高、數據點、座標軸 100% 數學精確 |
| 徹底消除數值幻覺 | 代碼驅動確保每個數據點的數值與原始數據完全一致 | 杜絕"看起來對但數據錯"的致命問題 |
| 7 類圖表全覆蓋 | 柱狀圖、折線圖、散點圖、熱力圖、雷達圖、餅圖、多面板圖 | 滿足 95% 以上論文統計圖需求 |
| 240 個 ChartMimic 測試 | 在標準基準上驗證生成代碼可運行且視覺匹配 | 72.7% 盲評勝率,覆蓋 line/bar/scatter/multi-panel |
| 可編輯可復現 | 輸出的 Python 代碼可自由調整顏色、註釋、字體 | 不必重新生成,直接精修到發表標準 |
爲什麼科研統計圖不能用圖像生成
傳統 AI 圖像生成模型(如 DALL-E 3、Midjourney V7)在製作科研統計圖時面臨一個根本性缺陷:它們將圖表作爲「像素」來渲染,而非基於「數據」來繪製。這意味着模型在生成柱狀圖時,並不是根據 [85, 72, 91, 68] 這樣的數值來計算柱高,而是根據"看起來像柱狀圖"的視覺模式來填充像素。
結果就是數值幻覺——柱高與 Y 軸刻度不匹配、數據點偏離實際位置、座標軸標籤出現亂碼或錯誤。在 PaperBanana 的評測中,直接使用圖像生成模型製作統計圖時,「數值幻覺和元素重複」是最常見的忠實度錯誤。
PaperBanana 採用了截然不同的策略:對於統計圖表,Visualizer 智能體不調用 Nano Banana Pro 的圖像生成能力,而是生成可執行的 Python Matplotlib 代碼。這種「代碼優先」的方式從根本上消除了數值幻覺——因爲代碼會按照精確的數學計算來綁定數據與視覺元素。
數值幻覺問題深度解析
什麼是科研統計圖中的數值幻覺
數值幻覺是指 AI 圖像生成模型在製作統計圖表時,生成的視覺元素與實際數據不一致的現象。具體表現包括:
- 柱高偏移: 柱狀圖的柱體高度與 Y 軸刻度值不對應
- 數據點漂移: 散點圖中的點偏離正確的 (x, y) 座標
- 刻度錯誤: 座標軸的刻度間距不均勻或數值標註錯誤
- 圖例混亂: 圖例顏色與實際數據系列不匹配
- 標籤亂碼: 座標軸標籤出現拼寫錯誤或文字重疊
數值幻覺的根本原因
通用圖像生成模型的訓練目標是「生成視覺上逼真的圖像」,而非「生成數據上精確的圖表」。當模型看到 Prompt 中的「柱狀圖,數值 [85, 72, 91, 68]」時,它並不會建立數值到像素高度的數學映射,而是基於訓練集中大量柱狀圖的「視覺模式」來生成近似的外觀。
| 問題類型 | 具體表現 | 發生頻率 | 嚴重程度 |
|---|---|---|---|
| 柱高偏移 | 柱體高度與數值不匹配 | 極高 | 致命:改變實驗結論 |
| 數據點漂移 | 散點偏離正確座標 | 高 | 致命:數據失真 |
| 刻度錯誤 | 座標軸刻度不均勻 | 高 | 嚴重:誤導讀者 |
| 圖例混亂 | 顏色與系列不匹配 | 中 | 嚴重:無法區分數據 |
| 標籤亂碼 | 文字重疊或拼寫錯誤 | 中 | 中等:影響可讀性 |
PaperBanana 代碼生成方式如何消除數值幻覺
PaperBanana 的解決方案簡潔而徹底:對於科研統計圖,不生成圖像,而是生成代碼。
當 PaperBanana 的 Visualizer 智能體接收到統計圖表任務時,它會將圖表描述轉換爲可執行的 Python Matplotlib 代碼。在這段代碼中,每一個柱體的高度、每一個數據點的座標、每一條座標軸的刻度,都是通過數學計算精確確定的——而非由神經網絡"猜測"的。
這種代碼優先的方式還帶來一個重要的附加價值:可編輯性。你收到的不是一張無法修改的柵格圖像,而是一段清晰的 Python 代碼。你可以自由調整顏色、字體、註釋、圖例位置,甚至修改底層數據後重新運行——這在期刊審稿階段的修改需求中尤爲實用。
🎯 技術建議: PaperBanana 的代碼生成能力底層由大語言模型驅動。你也可以直接通過 API易 apiyi.com 調用 Nano Banana Pro 等模型來生成 Matplotlib 代碼,平臺支持 OpenAI 兼容接口,每次調用成本極低。
Nano Banana Pro 科研統計圖 7 類圖表代碼生成
PaperBanana 在 240 個 ChartMimic 基準測試用例中驗證了代碼生成方式的有效性,覆蓋折線圖、柱狀圖、散點圖和多面板圖等常見類型。以下是 7 類科研統計圖的完整 Prompt 模板和代碼示例。
第 1 類:柱狀圖(Bar Chart)
柱狀圖是論文中最常用的圖表類型之一,用於對比不同條件下的實驗結果。
import matplotlib.pyplot as plt
import numpy as np
# 實驗數據
models = ['GPT-4o', 'Claude 4', 'Gemini 2', 'Llama 3', 'Qwen 3']
accuracy = [89.2, 91.5, 87.8, 83.4, 85.1]
colors = ['#3b82f6', '#10b981', '#f59e0b', '#ef4444', '#8b5cf6']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(models, accuracy, color=colors, width=0.6, edgecolor='white')
# 添加數值標籤
for bar, val in zip(bars, accuracy):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}%', ha='center', va='bottom', fontsize=10, fontweight='bold')
ax.set_ylabel('Accuracy (%)', fontsize=12)
ax.set_title('Model Performance Comparison on MMLU Benchmark', fontsize=14)
ax.set_ylim(75, 95)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('bar_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
第 2 類:折線圖(Line Chart)
折線圖展示隨時間或條件變化的趨勢,適合訓練曲線和消融實驗。
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 21)
train_loss = 2.5 * np.exp(-0.15 * epochs) + 0.3 + np.random.normal(0, 0.02, 20)
val_loss = 2.5 * np.exp(-0.12 * epochs) + 0.45 + np.random.normal(0, 0.03, 20)
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(epochs, train_loss, 'o-', color='#3b82f6', label='Train Loss', linewidth=2, markersize=4)
ax.plot(epochs, val_loss, 's--', color='#ef4444', label='Val Loss', linewidth=2, markersize=4)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Loss', fontsize=12)
ax.set_title('Training and Validation Loss Curves', fontsize=14)
ax.legend(fontsize=11, frameon=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('line_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
第 3 類:散點圖(Scatter Plot)
散點圖用於展示兩個變量之間的相關關係或聚類分佈。
第 4 類:熱力圖(Heatmap)
熱力圖適合展示混淆矩陣、注意力權重矩陣和相關係數矩陣。
第 5 類:雷達圖(Radar Chart)
雷達圖用於多維度能力對比,常見於模型綜合評測。
第 6 類:餅圖/環形圖(Pie/Donut Chart)
餅圖展示組成比例,適合數據集分佈和資源分配分析。
第 7 類:多面板組合圖(Multi-Panel)
多面板圖將多個子圖組合在一張 Figure 中,是論文中最常見的複合圖表形式。
| 圖表類型 | 適用場景 | 關鍵 Matplotlib 函數 | 常見用途 |
|---|---|---|---|
| 柱狀圖 | 離散對比 | ax.bar() |
模型性能對比、消融實驗 |
| 折線圖 | 趨勢變化 | ax.plot() |
訓練曲線、收斂分析 |
| 散點圖 | 相關/聚類 | ax.scatter() |
特徵分佈、嵌入可視化 |
| 熱力圖 | 矩陣數據 | sns.heatmap() |
混淆矩陣、注意力權重 |
| 雷達圖 | 多維對比 | ax.plot() + polar |
模型綜合評測 |
| 餅圖 | 比例構成 | ax.pie() |
數據集分佈 |
| 多面板圖 | 複合展示 | plt.subplots() |
Figure 1(a)(b)(c) |
💰 成本優化: 通過 API易 apiyi.com 調用大語言模型生成 Matplotlib 代碼,每次調用成本遠低於圖像生成。生成一段 50 行的 Matplotlib 代碼只需約 $0.01,而且代碼可反覆修改執行,無需重新調用 API。同時推薦使用在線工具 Image.apiyi.com 快速驗證可視化效果。
Nano Banana Pro 科研統計圖快速上手
極簡示例:用 AI 生成精確柱狀圖代碼
以下是通過 API 調用大語言模型,讓 AI 根據你的數據自動生成 Matplotlib 代碼的最簡方式:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # 使用 API易 統一接口
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{
"role": "user",
"content": """Generate publication-ready Python Matplotlib code for a grouped bar chart.
Data:
- Models: ['Method A', 'Method B', 'Method C', 'Ours']
- BLEU Score: [32.1, 35.4, 33.8, 38.7]
- ROUGE-L: [41.2, 43.8, 42.1, 47.3]
Requirements:
- Grouped bars with distinct colors (blue and green)
- Value labels on top of each bar
- Clean academic style, no top/right spines
- Title: 'Translation Quality Comparison'
- Save as PDF at 300 dpi
- Figsize: (8, 5)"""
}]
)
print(response.choices[0].message.content)
查看完整的科研統計圖代碼生成工具
import openai
from typing import Dict, List, Optional
def generate_chart_code(
chart_type: str,
data: Dict,
title: str,
style: str = "academic",
figsize: str = "(8, 5)",
save_format: str = "pdf"
) -> str:
"""
使用 AI 生成科研統計圖的 Matplotlib 代碼
Args:
chart_type: 圖表類型 - bar/line/scatter/heatmap/radar/pie/multi-panel
data: 數據字典,包含標籤和數值
title: 圖表標題
style: 風格 - academic/minimal/detailed
figsize: 圖表尺寸
save_format: 導出格式 - pdf/png/svg
Returns:
可執行的 Matplotlib Python 代碼
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # API易統一接口
)
style_guide = {
"academic": "Clean academic style: no top/right spines, "
"serif fonts, 300 dpi, tight layout",
"minimal": "Minimal style: grayscale-friendly, thin lines, "
"no grid, compact layout",
"detailed": "Detailed style: with grid, annotations, "
"error bars where applicable"
}
prompt = f"""Generate publication-ready Python Matplotlib code.
Chart type: {chart_type}
Data: {data}
Title: {title}
Style: {style_guide.get(style, style_guide['academic'])}
Figure size: {figsize}
Export: Save as {save_format} at 300 dpi
Requirements:
- All data values must be mathematically precise
- Include proper axis labels and legend
- Use colorblind-friendly palette
- Code must be executable without modification
- Add value annotations where appropriate"""
try:
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:生成模型性能對比柱狀圖
code = generate_chart_code(
chart_type="grouped_bar",
data={
"models": ["GPT-4o", "Claude 4", "Gemini 2", "Ours"],
"accuracy": [89.2, 91.5, 87.8, 93.1],
"f1_score": [87.5, 90.1, 86.3, 92.4]
},
title="Model Performance on SQuAD 2.0",
style="academic"
)
print(code)
🚀 快速開始: 推薦通過 API易 apiyi.com 平臺調用 AI 模型生成科研統計圖代碼。平臺支持 Gemini、Claude、GPT 等多種模型,均可生成高質量 Matplotlib 代碼。註冊即可獲取免費額度,5 分鐘完成首張統計圖的代碼生成。
代碼生成 vs 圖像生成:科研統計圖質量對比
爲什麼 PaperBanana 在科研統計圖場景下放棄了 Nano Banana Pro 的圖像生成能力,轉而使用代碼生成?以下對比數據說明了一切。

圖像生成方式的問題
使用 Nano Banana Pro、DALL-E 3 或 Midjourney 直接生成科研統計圖時,模型會嘗試用像素"畫出"一張看起來像圖表的圖像。雖然視覺效果可能不錯,但以下問題幾乎無法避免:
- 數值不精確: 柱高與實際數據之間沒有數學綁定
- 不可編輯: 輸出是柵格圖像,無法修改單個數據點
- 不可復現: 無法通過代碼重新執行獲得完全相同的圖表
- 標籤易錯: 座標軸標籤容易出現拼寫或數值錯誤
代碼生成方式的優勢
PaperBanana 的代碼生成方式則完全不同:
- 數學綁定: 每個視覺元素都由代碼中的數值精確計算
- 可編輯: 修改一行代碼即可更新顏色、標籤、數據
- 可復現: 同一段代碼在任何環境下執行結果完全一致
- 審稿友好: 審稿人要求修改圖表時,只需調整代碼參數
| 對比維度 | 圖像生成(Nano Banana Pro 等) | 代碼生成(PaperBanana 方式) |
|---|---|---|
| 數值精確度 | 低:像素近似,存在幻覺 | 高:數學精確,零幻覺 |
| 可編輯性 | 無:柵格圖像不可修改 | 強:修改代碼即可更新 |
| 可復現性 | 低:每次生成結果不同 | 高:代碼執行結果一致 |
| 標籤準確度 | 中:約 78-94% 文本準確率 | 高:代碼精確控制文本 |
| 審稿修改 | 需重新生成整張圖 | 調整參數重新運行 |
| 輸出格式 | PNG/JPG 柵格圖像 | PDF/SVG/EPS 矢量圖 |
🎯 選擇建議: 對於需要展示精確數值的科研統計圖(柱狀圖、折線圖、散點圖等),強烈建議使用代碼生成方式。如果你的圖表以視覺概念爲主(方法論圖、架構圖),則 Nano Banana Pro 的圖像生成能力更合適。通過 API易 apiyi.com 平臺,你可以同時調用圖像生成和文本生成模型,靈活切換。
Nano Banana Pro 科研統計圖 Prompt 工程技巧
讓 AI 生成高質量 Matplotlib 代碼的關鍵在於 Prompt 的結構化程度。以下是經過驗證的 5 條核心技巧。
技巧 1:數據必須顯式給出
永遠不要讓 AI "編造"數據。在 Prompt 中明確提供完整的數據值,包括標籤、數值和單位。
✅ 正確: Data: models=['A','B','C'], accuracy=[89.2, 91.5, 87.8]
❌ 錯誤: Generate a bar chart comparing three models
技巧 2:指定學術風格約束
學術圖表有嚴格的排版要求。在 Prompt 中明確以下約束:
- 移除頂部和右側邊框(
spines['top'].set_visible(False)) - 字體大小層級:標題 14pt、軸標籤 12pt、刻度 10pt
- 色盲友好配色(避免紅綠搭配)
- 輸出 300+ dpi 的 PDF/EPS 格式
技巧 3:要求添加數值標註
在柱狀圖上方添加精確數值標籤,讓讀者無需參照座標軸就能讀取數據——這也是消除「視覺模糊性」的重要手段。
技巧 4:指定可執行性
明確要求生成的代碼可以「不做任何修改直接運行」。這會促使 AI 包含所有必要的 import 語句、數據定義和保存命令。
技巧 5:爲審稿修改預留靈活性
要求 AI 將數據定義和樣式參數分開放置在代碼頂部,方便後續快速修改。
| 技巧 | 核心要點 | 對代碼質量的影響 |
|---|---|---|
| 1 | 顯式給出數據 | 消除數據編造,確保精確性 |
| 2 | 學術風格約束 | 符合期刊排版要求 |
| 3 | 數值標註 | 提升圖表可讀性 |
| 4 | 可執行性 | 代碼開箱即用 |
| 5 | 參數分離 | 審稿修改效率翻倍 |
🎯 實踐建議: 將以上 5 條技巧組合爲你的標準 Prompt 模板。通過 API易 apiyi.com 調用不同模型反覆迭代,找到最適合你研究領域的代碼風格。平臺支持 Gemini、Claude、GPT 等多模型切換,便於對比生成效果。
常見問題
Q1: PaperBanana 的代碼生成方式比圖像生成慢嗎?
恰恰相反,代碼生成通常更快。生成一段 50-80 行的 Matplotlib 代碼只需 2-5 秒,而圖像生成需要 10-30 秒。更重要的是,代碼生成後可以本地執行和反覆修改,無需每次修改都重新調用 API。通過 API易 apiyi.com 調用模型生成代碼,單次成本約 $0.01,遠低於圖像生成的 $0.05。
Q2: 生成的 Matplotlib 代碼質量如何?是否需要大量修改?
在 PaperBanana 的 240 個 ChartMimic 基準測試中,生成的 Python 代碼均可直接運行且視覺輸出匹配原始描述。實際使用中,通常只需微調配色和字體等風格參數。建議通過 API易 apiyi.com 平臺調用 Claude 或 Gemini 模型來生成代碼,這兩個模型在代碼生成質量方面表現尤爲出色。在線工具 Image.apiyi.com 也支持快速預覽效果。
Q3: 如何快速開始使用 AI 生成科研統計圖代碼?
推薦以下快速上手路徑:
- 訪問 API易 apiyi.com 註冊賬號,獲取 API Key 和免費測試額度
- 準備好你的實驗數據(模型名稱、指標數值等)
- 使用本文的 Prompt 模板,將數據替換爲你的真實數據
- 調用 API 生成 Matplotlib 代碼,本地執行查看效果
- 根據期刊要求微調樣式參數後導出 PDF
總結
Nano Banana Pro 科研統計圖代碼生成方式的核心要點:
- 代碼優先於像素: PaperBanana 對科研統計圖採用 Matplotlib 代碼生成而非圖像渲染,從根本上消除數值幻覺
- 7 類圖表全覆蓋: 柱狀圖、折線圖、散點圖、熱力圖、雷達圖、餅圖、多面板圖,滿足論文數據可視化的全部需求
- 可編輯可復現: 代碼輸出支持自由修改和精確復現,審稿修改只需調整參數而非重新生成
- 5 條 Prompt 技巧: 顯式數據、學術約束、數值標註、可執行性、參數分離,確保生成的代碼高質量可用
在科研統計圖的精確性要求面前,「代碼即圖表」是唯一可靠的路徑。通過 AI 輔助生成 Matplotlib 代碼,你既獲得了 AI 的效率,又保留了代碼的精確性——兩全其美。
推薦通過 API易 apiyi.com 快速體驗 AI 輔助科研統計圖代碼生成,平臺提供免費額度和多模型選擇。也可使用在線工具 Image.apiyi.com 預覽效果。
📚 參考資料
⚠️ 鏈接格式說明: 所有外鏈使用
資料名: domain.com格式,方便複製但不可點擊跳轉,避免 SEO 權重流失。
-
PaperBanana 項目主頁: 官方發佈頁面,包含論文和 Demo
- 鏈接:
dwzhu-pku.github.io/PaperBanana/ - 說明: 瞭解 PaperBanana 統計圖代碼生成的核心原理和評測數據
- 鏈接:
-
PaperBanana 論文: arXiv 預印本全文
- 鏈接:
arxiv.org/abs/2601.23265 - 說明: 深入理解代碼生成 vs 圖像生成的技術選擇和 ChartMimic 基準測試
- 鏈接:
-
Matplotlib 官方文檔: Python 數據可視化庫
- 鏈接:
matplotlib.org/stable/ - 說明: Matplotlib API 參考,用於理解和修改 AI 生成的圖表代碼
- 鏈接:
-
Nano Banana Pro 官方文檔: Google DeepMind 模型介紹
- 鏈接:
deepmind.google/models/gemini-image/pro/ - 說明: 瞭解 Nano Banana Pro 在方法論圖場景下的圖像生成能力
- 鏈接:
-
API易 在線出圖工具: 零代碼圖表預覽
- 鏈接:
Image.apiyi.com - 說明: 快速預覽 AI 生成的科研統計圖效果
- 鏈接:
作者: APIYI Team
技術交流: 歡迎在評論區分享你的科研統計圖 Prompt 模板和 Matplotlib 技巧,更多 AI 模型資訊可訪問 API易 apiyi.com 技術社區