Vous développez un projet avec Google AI Studio et soudain, vous recevez une erreur 429 RESOURCE_EXHAUSTED ? Vous n'êtes pas seul : après la réduction drastique des quotas gratuits par Google en décembre 2025, des dizaines de milliers de projets de développeurs dans le monde se sont retrouvés à l'arrêt du jour au lendemain.
Cet article analyse en détail le mécanisme de limitation de Google AI Studio et propose 5 solutions éprouvées pour relancer rapidement votre développement.
Analyse détaillée des limites de Google AI Studio
Qu'est-ce que la limite de Google AI Studio ?
Google AI Studio impose des restrictions multidimensionnelles sur les appels à l'API Gemini, notamment :
| Dimension de limitation | Signification | Temps de réinitialisation |
|---|---|---|
| RPM (Requests Per Minute) | Nombre de requêtes par minute | Réinitialisation glissante chaque minute |
| RPD (Requests Per Day) | Nombre de requêtes par jour | Minuit, heure du Pacifique |
| TPM (Tokens Per Minute) | Nombre de tokens traités par minute | Réinitialisation glissante chaque minute |
| IPM (Images Per Minute) | Nombre d'images traitées par minute | Réinitialisation glissante chaque minute |
🔑 Information clé : Les limites sont calculées par projet (Project), et non par clé API. Créer plusieurs clés API n'augmentera pas votre quota.
Dernières limites de quota gratuit Google AI Studio (2026)
Le 7 décembre 2025, Google a considérablement réduit les quotas de la version gratuite de l'API Gemini (de 50 % à 92 %). Voici les limites actuelles pour chaque modèle :
| Modèle | Limite RPM | Limite RPD | Limite TPM |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250 000 |
| Gemini 2.5 Flash | 10 | 250 | 250 000 |
| Gemini 2.5 Flash-Lite | 15 | 1 000 | 250 000 |
| Gemini 3 Pro Preview | 10-50* | 100+* | 250 000 |
*Les limites pour Gemini 3 Pro Preview s'ajustent dynamiquement selon l'ancienneté du compte et la région.

Pourquoi l'erreur 429 se déclenche-t-elle sur Google AI Studio ?
L'erreur 429 se déclenche dès qu'une seule dimension est dépassée. Scénarios courants :
- RPM dépassé : Trop de requêtes envoyées en peu de temps.
- RPD épuisé : Le nombre total de requêtes quotidiennes a atteint son maximum.
- TPM dépassé : La longueur des tokens d'une seule requête est trop importante ou il y a trop de requêtes simultanées.
- État du compte anormal : Même après un passage au Tier 1, certains utilisateurs signalent être toujours limités aux quotas de la version gratuite.
# Réponse d'erreur 429 typique
{
"error": {
"code": 429,
"message": "You exceeded your current quota, please check your plan and billing details.",
"status": "RESOURCE_EXHAUSTED"
}
}
5 méthodes pour résoudre les limites de Google AI Studio
Solution 1 : Attendre la réinitialisation des quotas (Gratuit mais chronophage)
Cas d'utilisation : Tests légers, projets non urgents.
Règles de réinitialisation des quotas de Google AI Studio :
- RPM/TPM : Réinitialisation automatique sur une fenêtre glissante de 60 secondes.
- RPD : Réinitialisation à minuit, heure du Pacifique (soit 16h00 à Pékin / 9h00 ou 10h00 en Europe selon l'heure d'été).
Implémentation d'un mécanisme de backoff exponentiel :
import time
import random
def call_with_retry(func, max_retries=5):
"""Mécanisme de tentative avec backoff exponentiel"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Quota dépassé, attente de {wait_time:.1f} secondes avant de réessayer...")
time.sleep(wait_time)
else:
raise
raise Exception("Nombre maximal de tentatives épuisé")
| Avantages | Inconvénients |
|---|---|
| ✅ Entièrement gratuit | ❌ Nécessite d'attendre plusieurs heures |
| ✅ Aucune configuration requise | ❌ Quotas toujours très limités |
| ✅ Idéal pour l'apprentissage et les tests | ❌ Inadapté au développement professionnel |
Solution 2 : Passer au niveau payant Tier 1
Cas d'utilisation : Développeurs disposant d'une carte de crédit internationale.
Augmentation des quotas après le passage au Tier 1 :
| Indicateur | Niveau gratuit | Tier 1 |
|---|---|---|
| RPM | 5-15 | 150-300 |
| RPD | 100-1000 | Pratiquement illimité |
| Délai d'activation | – | Immédiat |
Étapes pour la mise à niveau :
- Accédez à la console Google AI Studio.
- Allez sur la page "API Keys".
- Cliquez sur le bouton "Set up Billing" (Configurer la facturation).
- Associez un compte de facturation Google Cloud.
- Sélectionnez le forfait Tier 1.
Référence des tarifs Tier 1 :
- Gemini 2.5 Flash : 0,075 $ / million de tokens d'entrée.
- Gemini 2.5 Pro : 1,25 $ / million de tokens d'entrée.
- Génération d'image 4K : 0,24 $ / image.
| Avantages | Inconvénients |
|---|---|
| ✅ RPM augmenté à 150-300 | ❌ Nécessite une carte de crédit internationale |
| ✅ Limites RPD pratiquement levées | ❌ Certains modèles restent limités |
| ✅ Activation immédiate | ❌ Difficulté de liaison de carte pour certains pays |
Solution 3 : Utiliser le service relais APIYI (Recommandé)
Cas d'utilisation : Tous les développeurs, particulièrement ceux cherchant une solution simple et flexible.
🎯 Solution recommandée : Appelez l'API Gemini via la plateforme APIYI (apiyi.com). Plus besoin de vous soucier des limites de quota, avec un support pour les paiements locaux (Alipay/WeChat).
Comparaison des avantages APIYI :
| Élément de comparaison | Google Officiel | APIYI |
|---|---|---|
| Limite RPM | 5-300 | Illimitée |
| Limite RPD | 100-Illimité | Illimitée |
| Prix image 4K | 0,24 $/image | 0,05 $/image |
| Mode de paiement | Carte de crédit internationale | Alipay/WeChat |
| Accessibilité | Nécessite souvent un proxy | Accès direct |
| Support technique | Anglais | Chinois/Anglais |

Code d'accès rapide :
import openai
# Configuration de l'accès via APIYI
client = openai.OpenAI(
api_key="votre-cle-apiyi", # À obtenir sur api.apiyi.com
base_url="https://api.apiyi.com/v1"
)
# Appel du modèle Gemini
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[
{"role": "user", "content": "Bonjour, présente-toi s'il te plaît."}
]
)
print(response.choices[0].message.content)
💡 Conseil : Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour vos développements et tests. Elle propose une interface unifiée pour plus de 200 modèles d'IA majeurs, avec des tarifs environ 80 % moins chers que les tarifs officiels.
Solution 4 : Créer plusieurs projets Google Cloud
Cas d'utilisation : Développeurs ayant de bonnes compétences techniques.
Comme les limites sont calculées par projet, il est théoriquement possible d'augmenter son quota total en créant plusieurs projets :
import random
class MultiProjectClient:
"""Client avec rotation (round-robin) multi-projets"""
def __init__(self, api_keys: list):
self.api_keys = api_keys
self.current_index = 0
def get_next_key(self):
"""Récupère la clé API suivante par rotation"""
key = self.api_keys[self.current_index]
self.current_index = (self.current_index + 1) % len(self.api_keys)
return key
def call_api(self, prompt):
"""Appelle l'API en utilisant la clé sélectionnée"""
api_key = self.get_next_key()
# Utiliser cette clé pour appeler l'API Gemini
pass
# Exemple d'utilisation
client = MultiProjectClient([
"cle_projet_1",
"cle_projet_2",
"cle_projet_3"
])
| Avantages | Inconvénients |
|---|---|
| ✅ Augmentation gratuite du quota | ❌ Gestion complexe |
| ✅ Pas de frais supplémentaires | ❌ Risque de violation des ToS |
| – | ❌ Risque de détection et bannissement par Google |
⚠️ Avertissement : Cette méthode présente un risque de violation des conditions d'utilisation (ToS) de Google. Elle n'est pas recommandée pour des environnements de production.
Solution 5 : Optimiser la stratégie de requête
Cas d'utilisation : Tous les développeurs.
Même avec un quota limité, une stratégie optimisée permet d'en tirer le meilleur parti :
1. Implémenter une file d'attente avec limitation de débit :
import asyncio
from collections import deque
class RateLimitedQueue:
"""File d'attente de requêtes avec limitation de débit"""
def __init__(self, rpm_limit=5):
self.rpm_limit = rpm_limit
self.queue = deque()
self.request_times = deque()
async def add_request(self, request_func):
"""Ajoute une requête à la file"""
self.queue.append(request_func)
await self._process_queue()
async def _process_queue(self):
"""Traite les requêtes dans la file"""
now = asyncio.get_event_loop().time()
# Nettoyer les enregistrements de plus de 60 secondes
while self.request_times and now - self.request_times[0] > 60:
self.request_times.popleft()
# Vérifier si on peut envoyer une requête
if len(self.request_times) < self.rpm_limit and self.queue:
request_func = self.queue.popleft()
self.request_times.append(now)
await request_func()
2. Traitement par lots (Batching) :
def batch_prompts(prompts: list, batch_size: int = 5):
"""Combine plusieurs invites en une seule requête groupée"""
combined_prompt = "\n\n---\n\n".join([
f"Question {i+1}: {p}" for i, p in enumerate(prompts)
])
return combined_prompt
# Fusionne 5 requêtes indépendantes en 1 seule
prompts = ["Question 1", "Question 2", "Question 3", "Question 4", "Question 5"]
batch_prompt = batch_prompts(prompts)
# Ne consomme qu'une seule unité de quota RPM
3. Mise en cache des requêtes répétitives :
import hashlib
import json
class ResponseCache:
"""Cache de réponses"""
def __init__(self):
self.cache = {}
def get_cache_key(self, prompt, model):
"""Génère une clé de cache"""
content = f"{model}:{prompt}"
return hashlib.md5(content.encode()).hexdigest()
def get(self, prompt, model):
"""Récupère du cache"""
key = self.get_cache_key(prompt, model)
return self.cache.get(key)
def set(self, prompt, model, response):
"""Définit dans le cache"""
key = self.get_cache_key(prompt, model)
self.cache[key] = response
Comparatif des solutions pour les limites de Google AI Studio
En synthétisant les 5 approches précédentes, voici un comparatif détaillé :
| Solution | Coût | Augmentation du quota | Difficulté | Indice de recommandation |
|---|---|---|---|---|
| Attendre la réinitialisation | Gratuit | Aucune | ⭐ | ⭐⭐ |
| Passer au Tier 1 | Paiement à l'usage | 10 à 60 fois | ⭐⭐ | ⭐⭐⭐ |
| Relais APIYI | -80% du prix officiel | Illimité | ⭐ | ⭐⭐⭐⭐⭐ |
| Rotation multi-projets | Gratuit | Multiple du nombre de projets | ⭐⭐⭐⭐ | ⭐⭐ |
| Stratégies d'optimisation | Gratuit | Amélioration indirecte | ⭐⭐⭐ | ⭐⭐⭐ |
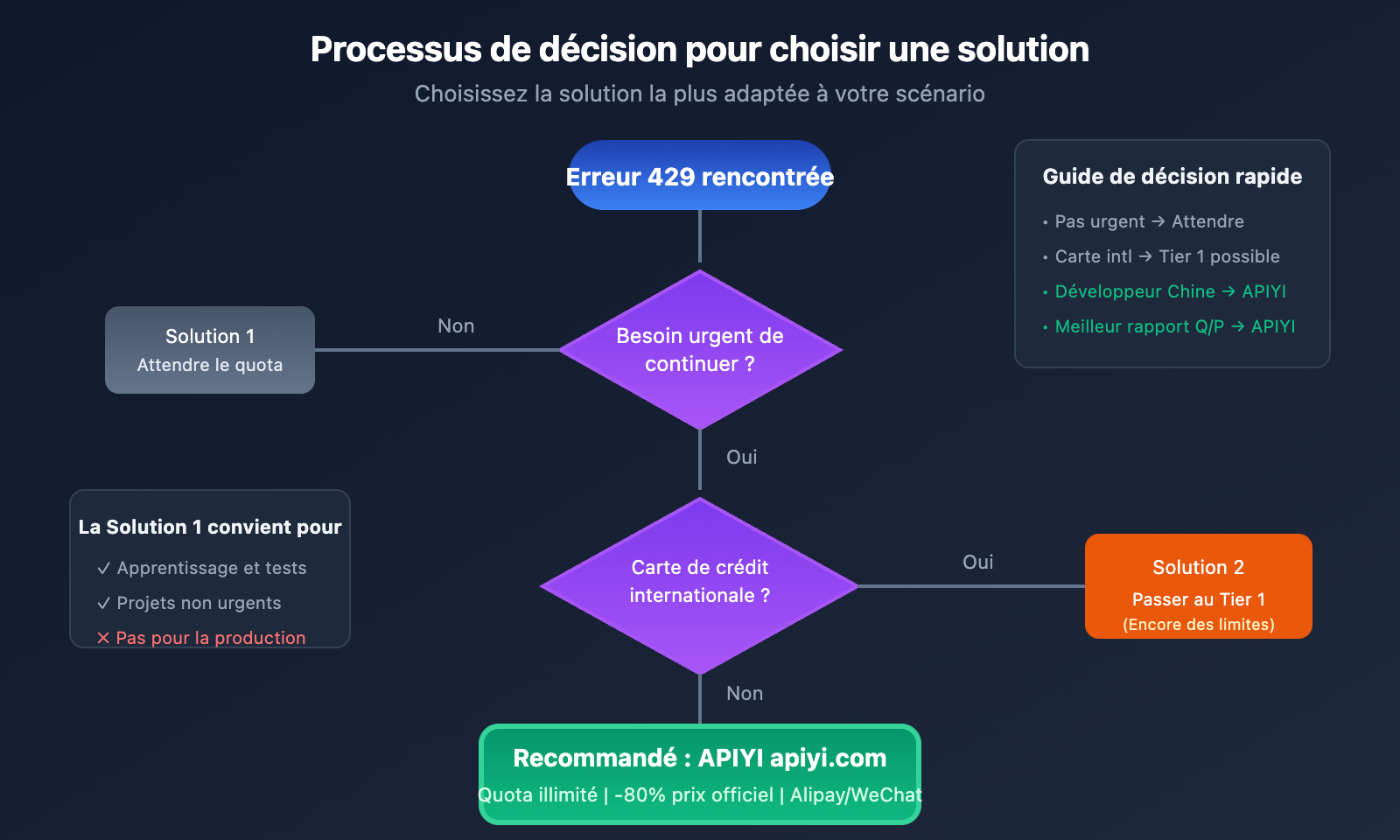
🎯 Conseil de choix : Pour la majorité des développeurs, nous recommandons d'utiliser APIYI (apiyi.com) comme solution principale. Cette plateforme permet non seulement de s'affranchir des limites de quota, mais offre également un avantage tarifaire de -80% par rapport au prix officiel, avec un support technique en chinois.
Foire aux questions (FAQ)
Q1 : Pourquoi l'erreur 429 persiste-t-elle après le passage au Tier 1 ?
C'est un problème connu de Google AI Studio. Certains utilisateurs rapportent que même après avoir lié un compte de paiement, le système continue d'appliquer les limites de la version gratuite.
Solutions possibles :
- Allez dans AI Studio et vérifiez que tous vos projets ont bien été mis à niveau.
- Générez une nouvelle clé API.
- Attendez 24 heures pour que la synchronisation du système soit effective.
Si le problème persiste, il est conseillé de passer par une plateforme tierce comme APIYI (apiyi.com) pour éviter ces tracas de quota.
Q2 : À quel moment le quota RPD est-il réinitialisé ?
Le quota RPD (Requêtes Par Jour) de Google AI Studio est réinitialisé à minuit, heure du Pacifique (PST/PDT), ce qui correspond généralement à l'après-midi en Europe ou en Asie selon le décalage horaire.
Q3 : Pourquoi les limites de Gemini 3 Pro Preview ne sont-elles pas fixes ?
En tant que modèle en version préliminaire, les limites de Gemini 3 Pro Preview sont ajustées dynamiquement en fonction de plusieurs facteurs :
- L'ancienneté du compte
- La région d'utilisation
- L'historique d'utilisation
- La charge actuelle des serveurs de Google
Q4 : Comment consulter l'utilisation actuelle de mon quota ?
- Connectez-vous à Google AI Studio.
- Allez dans la page "API Keys".
- Consultez les statistiques d'utilisation dans la section "Quota".
Q5 : Quels modèles Gemini sont supportés par APIYI ?
APIYI supporte tous les principaux modèles Gemini publiés par Google, notamment :
- Gemini 2.5 Pro / Flash / Flash-Lite
- Gemini 3 Pro Preview
- Ainsi que plus de 200 autres modèles d'IA (Claude, GPT, Llama, etc.)
Visitez apiyi.com pour consulter la liste complète des modèles et les tarifs en temps réel.
Q6 : La rotation multi-projets risque-t-elle de faire bannir mon compte par Google ?
Il existe un risque. Les conditions d'utilisation de Google interdisent de créer plusieurs comptes pour contourner les limitations. Bien qu'aucun bannissement massif n'ait été signalé à ce jour, cette méthode n'est pas recommandée pour un environnement de production.
Résumé
Après que Google AI Studio a considérablement réduit ses quotas gratuits fin 2025, les développeurs font face à des limites de RPM/RPD plus strictes. Les 5 solutions présentées dans cet article ont chacune leurs avantages et inconvénients :
- Attendre la réinitialisation du quota : Idéal pour l'apprentissage et les tests, mais trop peu efficace.
- Passer au Tier 1 : Augmentation significative du quota, mais nécessite une carte de crédit internationale.
- Relais APIYI : Aucune limite de quota, prix plus bas, supporte Alipay/WeChat, recommandé.
- Rotation multi-projets : Risque de bannissement, non recommandé.
- Optimisation de la stratégie de requête : Vaut la peine d'être apprise, peut être combinée avec d'autres solutions.
Pour les développeurs, nous recommandons d'utiliser directement la plateforme APIYI (apiyi.com), une solution tout-en-un pour résoudre les trois problèmes majeurs : limites de quota, difficultés de paiement et accès réseau.
📝 Auteur : APIYI Team
🔗 Site officiel d'APIYI : apiyi.com – Plateforme de relais API pour grands modèles de langage stable et fiable, supportant plus de 200 modèles, avec des prix jusqu'à 80 % moins chers que les tarifs officiels.