Anmerkung des Autors: Detaillierte Erklärung, wie PaperBanana wissenschaftliche Statistikdiagramme durch die Generierung von ausführbarem Matplotlib-Code anstelle von Pixelbildern erstellt. Dies eliminiert das Problem der numerischen Halluzinationen vollständig und deckt 7 Diagrammtypen ab, darunter Balkendiagramme, Liniendiagramme und Streudiagramme.
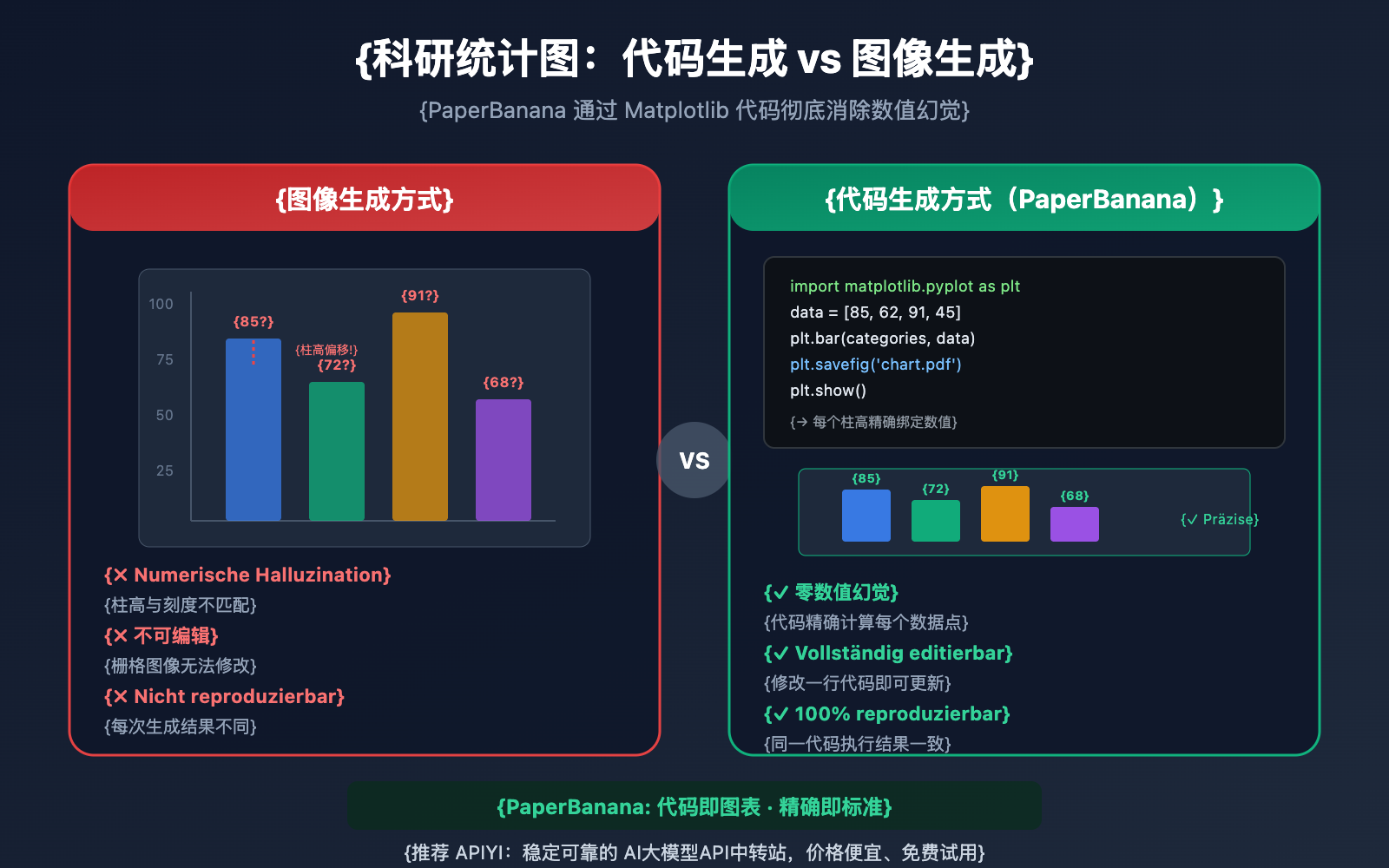
Statistische Diagramme in wissenschaftlichen Arbeiten tragen die Kernschlussfolgerungen von Experimenten – die Höhe eines Balkens, der Trend einer Linie, die Verteilung von Streupunkten; jeder Datenpunkt muss präzise und fehlerfrei sein. Wenn Sie jedoch allgemeine Bildgeneratoren wie DALL-E oder Midjourney verwenden, um Statistikdiagramme zu erstellen, bleibt ein kritisches Problem bestehen: Numerische Halluzinationen (Numerical Hallucination). Balkenhöhen, die nicht mit der Skala übereinstimmen, verschobene Datenpunkte, falsche Achsenbeschriftungen – diese „optisch korrekt, aber datentechnisch falsch“ wirkenden Diagramme können in einer Publikation fatale Folgen haben.
Kernwert: Nach der Lektüre dieses Artikels werden Sie verstehen, warum PaperBanana auf Codegenerierung statt Bildgenerierung setzt, um wissenschaftliche Diagramme zu erstellen. Sie werden die Methoden zur Matplotlib-Codegenerierung für 7 Arten von Statistikdiagrammen beherrschen und erfahren, wie Sie mit der Nano Banana Pro API kostengünstig eine wissenschaftliche Datenvisualisierung ohne numerische Halluzinationen realisieren.
Nano Banana Pro 科研统计图核心要点
| 要点 | 说明 | 价值 |
|---|---|---|
| 代码生成而非像素 | PaperBanana 生成可执行 Matplotlib 代码,而非直接渲染图像 | 柱高、数据点、坐标轴 100% 数学精确 |
| 彻底消除数值幻觉 | 代码驱动确保每个数据点的数值与原始数据完全一致 | 杜绝"看起来对但数据错"的致命问题 |
| 7 类图表全覆盖 | 柱状图、折线图、散点图、热力图、雷达图、饼图、多面板图 | 满足 95% 以上论文统计图需求 |
| 240 个 ChartMimic 测试 | 在标准基准上验证生成代码可运行且视觉匹配 | 72.7% 盲评胜率,覆盖 line/bar/scatter/multi-panel |
| 可编辑可复现 | 输出的 Python 代码可自由调整颜色、注释、字体 | 不必重新生成,直接精修到发表标准 |
为什么科研统计图不能用图像生成
传统 AI 图像生成模型(如 DALL-E 3、Midjourney V7)在制作科研统计图时面临一个根本性缺陷:它们将图表作为「像素」来渲染,而非基于「数据」来绘制。这意味着模型在生成柱状图时,并不是根据 [85, 72, 91, 68] 这样的数值来计算柱高,而是根据"看起来像柱状图"的视觉模式来填充像素。
结果就是数值幻觉——柱高与 Y 轴刻度不匹配、数据点偏离实际位置、坐标轴标签出现乱码或错误。在 PaperBanana 的评测中,直接使用图像生成模型制作统计图时,「数值幻觉和元素重复」是最常见的忠实度错误。
PaperBanana 采用了截然不同的策略:对于统计图表,Visualizer 智能体不调用 Nano Banana Pro 的图像生成能力,而是生成可执行的 Python Matplotlib 代码。这种「代码优先」的方式从根本上消除了数值幻觉——因为代码会按照精确的数学计算来绑定数据与视觉元素。
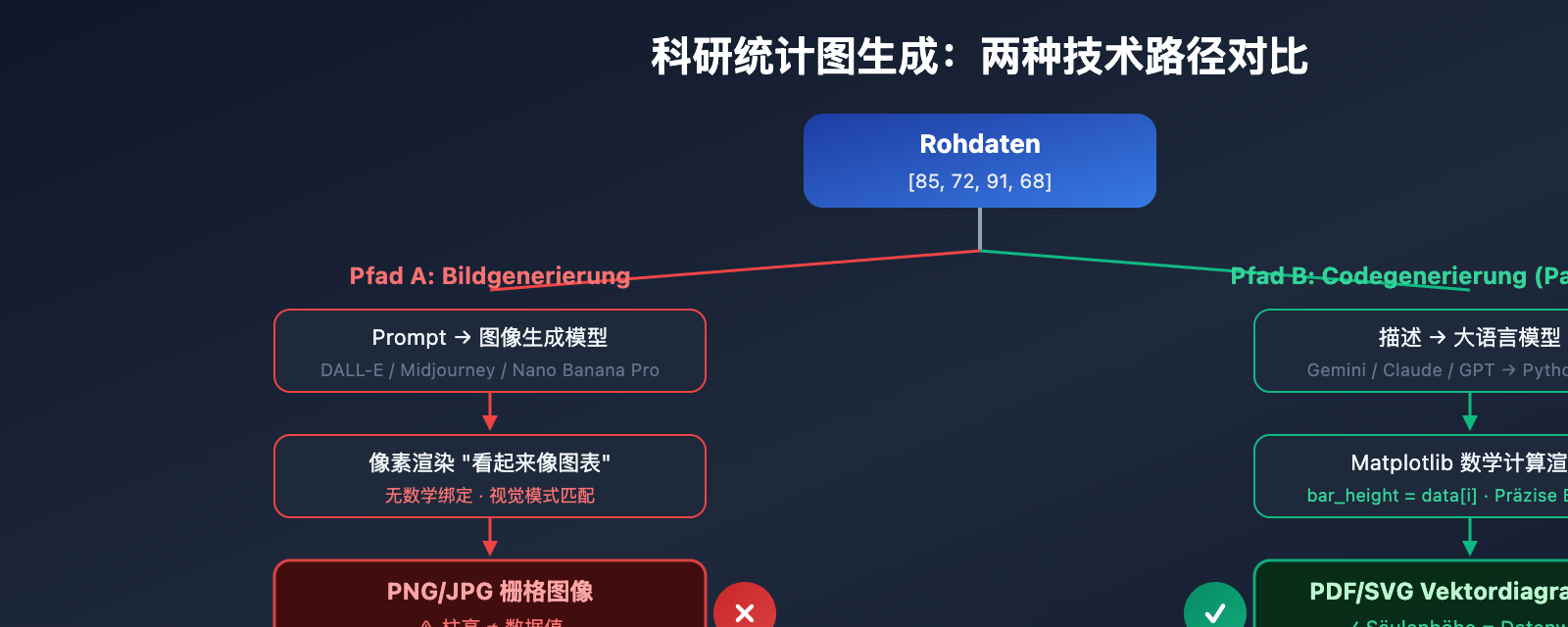
Tiefenanalyse numerischer Halluzinationen
Was sind numerische Halluzinationen in wissenschaftlichen Diagrammen?
Numerische Halluzinationen bezeichnen das Phänomen, dass KI-Bildgenerierungsmodelle bei der Erstellung statistischer Diagramme visuelle Elemente erzeugen, die nicht mit den tatsächlichen Daten übereinstimmen. Konkrete Ausprägungen sind unter anderem:
- Abweichung der Säulenhöhe: Die Höhe der Balken in einem Säulendiagramm entspricht nicht den Werten auf der Y-Achse.
- Drift von Datenpunkten: Punkte in einem Streudiagramm weichen von den korrekten (x, y)-Koordinaten ab.
- Skalierungsfehler: Die Abstände der Achsenskalierung sind ungleichmäßig oder die Wertebeschriftungen sind falsch.
- Unstimmige Legenden: Die Farben in der Legende stimmen nicht mit den tatsächlichen Datenserien überein.
- Fehlerhafte Beschriftungen: Achsenbeschriftungen weisen Rechtschreibfehler auf oder Texte überlappen sich.
Die Ursache numerischer Halluzinationen
Das Trainingsziel allgemeiner Bildgenerierungsmodelle besteht darin, „visuell realistische Bilder“ zu erzeugen, nicht jedoch „datengetreue Diagramme“. Wenn ein Modell in einer Eingabeaufforderung „Säulendiagramm, Werte [85, 72, 91, 68]“ sieht, erstellt es keine mathematische Zuordnung von Zahlenwerten zu Pixelhöhen. Stattdessen generiert es basierend auf einer Vielzahl von „visuellen Mustern“ aus dem Trainingsset ein annähernd passendes Erscheinungsbild.
| Problemtyp | Konkrete Ausprägung | Häufigkeit | Schweregrad |
|---|---|---|---|
| Säulenhöhen-Abweichung | Balkenhöhe stimmt nicht mit Wert überein | Extrem hoch | Fatal: Verfälscht wissenschaftliche Schlussfolgerungen |
| Drift von Datenpunkten | Punkte weichen von korrekten Koordinaten ab | Hoch | Fatal: Datenverfälschung |
| Skalierungsfehler | Achsenskalierung ist ungleichmäßig | Hoch | Schwerwiegend: Irreführung des Lesers |
| Unstimmige Legenden | Farben passen nicht zu den Serien | Mittel | Schwerwiegend: Daten nicht unterscheidbar |
| Fehlerhafte Beschriftungen | Textüberlappung oder Rechtschreibfehler | Mittel | Mittel: Beeinträchtigt die Lesbarkeit |
Wie die Codegenerierung von PaperBanana numerische Halluzinationen eliminiert
Die Lösung von PaperBanana ist ebenso einfach wie effektiv: Für wissenschaftliche Diagramme werden keine Bilder generiert, sondern Code.
Wenn der Visualizer-Agent von PaperBanana eine Aufgabe für ein statistisches Diagramm erhält, wandelt er die Diagrammbeschreibung in ausführbaren Python-Matplotlib-Code um. In diesem Code wird die Höhe jedes Balkens, die Koordinate jedes Datenpunkts und jede Skalierung der Achsen durch mathematische Berechnungen präzise festgelegt – und nicht durch ein neuronales Netzwerk „erraten“.
Dieser Code-First-Ansatz bietet zudem einen wichtigen Mehrwert: Editierbarkeit. Sie erhalten keine unveränderliche Rastergrafik, sondern klaren Python-Code. Sie können Farben, Schriftarten, Anmerkungen und Legendenpositionen frei anpassen oder sogar die zugrunde liegenden Daten ändern und den Code neu ausführen – was besonders bei Überarbeitungen während des Peer-Review-Prozesses äußerst praktisch ist.
🎯 Technischer Hinweis: Die Codegenerierungsfähigkeit von PaperBanana wird im Hintergrund von einem Großen Sprachmodell gesteuert. Sie können auch direkt über APIYI (apiyi.com) Modelle wie Nano Banana Pro aufrufen, um Matplotlib-Code zu generieren. Die Plattform unterstützt OpenAI-kompatible Schnittstellen bei extrem niedrigen Aufrufkosten.
Nano Banana Pro: Codegenerierung für 7 Arten wissenschaftlicher Diagramme
PaperBanana hat die Effektivität der Codegenerierung in 240 ChartMimic-Benchmark-Tests validiert, die gängige Typen wie Linien-, Säulen-, Streudiagramme und Multi-Panel-Grafiken abdecken. Hier sind die vollständigen Eingabeaufforderung-Vorlagen und Codebeispiele für 7 Arten wissenschaftlicher Diagramme.
Typ 1: Säulendiagramm (Bar Chart)
Säulendiagramme gehören zu den am häufigsten verwendeten Diagrammtypen in wissenschaftlichen Arbeiten, um experimentelle Ergebnisse unter verschiedenen Bedingungen zu vergleichen.
import matplotlib.pyplot as plt
import numpy as np
# Experimentelle Daten
models = ['GPT-4o', 'Claude 4', 'Gemini 2', 'Llama 3', 'Qwen 3']
accuracy = [89.2, 91.5, 87.8, 83.4, 85.1]
colors = ['#3b82f6', '#10b981', '#f59e0b', '#ef4444', '#8b5cf6']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(models, accuracy, color=colors, width=0.6, edgecolor='white')
# Numerische Labels hinzufügen
for bar, val in zip(bars, accuracy):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}%', ha='center', va='bottom', fontsize=10, fontweight='bold')
ax.set_ylabel('Accuracy (%)', fontsize=12)
ax.set_title('Model Performance Comparison on MMLU Benchmark', fontsize=14)
ax.set_ylim(75, 95)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('bar_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Typ 2: Liniendiagramm (Line Chart)
Liniendiagramme zeigen Trends über Zeit oder Bedingungen hinweg und eignen sich ideal für Trainingskurven und Ablationsstudien.
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 21)
train_loss = 2.5 * np.exp(-0.15 * epochs) + 0.3 + np.random.normal(0, 0.02, 20)
val_loss = 2.5 * np.exp(-0.12 * epochs) + 0.45 + np.random.normal(0, 0.03, 20)
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(epochs, train_loss, 'o-', color='#3b82f6', label='Train Loss', linewidth=2, markersize=4)
ax.plot(epochs, val_loss, 's--', color='#ef4444', label='Val Loss', linewidth=2, markersize=4)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Loss', fontsize=12)
ax.set_title('Training and Validation Loss Curves', fontsize=14)
ax.legend(fontsize=11, frameon=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('line_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Typ 3: Streudiagramm (Scatter Plot)
Streudiagramme werden verwendet, um Korrelationen zwischen zwei Variablen oder Cluster-Verteilungen darzustellen.
Typ 4: Heatmap
Heatmaps eignen sich zur Darstellung von Konfusionsmatrizen, Attention-Gewichtsmatrizen und Korrelationskoeffizienten-Matrizen.
Typ 5: Netzdiagramm (Radar Chart)
Netzdiagramme werden für den multidimensionalen Vergleich von Fähigkeiten verwendet, häufig bei der umfassenden Bewertung von Modellen.
Typ 6: Kreis-/Donut-Diagramm (Pie/Donut Chart)
Kreisdiagramme zeigen proportionale Zusammensetzungen und eignen sich für die Analyse der Datensatzverteilung oder Ressourcenallokation.
Typ 7: Multi-Panel-Kombinationsgrafik (Multi-Panel)
Multi-Panel-Grafiken kombinieren mehrere Teilgrafiken in einer Abbildung (Figure) und sind die am häufigsten vorkommende Form komplexer Diagramme in wissenschaftlichen Publikationen.
| Diagrammtyp | Anwendungsszenario | Wichtige Matplotlib-Funktion | Häufige Verwendung |
|---|---|---|---|
| Säulendiagramm | Diskreter Vergleich | ax.bar() |
Modellvergleich, Ablationsstudien |
| Liniendiagramm | Trendverlauf | ax.plot() |
Trainingskurven, Konvergenzanalyse |
| Streudiagramm | Korrelation/Clustering | ax.scatter() |
Merkmalsverteilung, Embedding-Visualisierung |
| Heatmap | Matrixdaten | sns.heatmap() |
Konfusionsmatrix, Attention-Gewichte |
| Netzdiagramm | Multidimensionaler Vergleich | ax.plot() + polar |
Umfassende Modellbewertung |
| Kreisdiagramm | Proportionale Zusammensetzung | ax.pie() |
Datensatzverteilung |
| Multi-Panel-Grafik | Kombinierte Darstellung | plt.subplots() |
Abbildung 1(a)(b)(c) |
💰 Kostenoptimierung: Durch den Aufruf eines Großen Sprachmodells über APIYI (apiyi.com) zur Generierung von Matplotlib-Code sind die Kosten pro Aufruf weitaus geringer als bei der Bildgenerierung. Die Erstellung eines 50-zeiligen Matplotlib-Codes kostet nur etwa 0,01 $, wobei der Code beliebig oft geändert und ausgeführt werden kann, ohne die API erneut aufrufen zu müssen. Zudem wird die Verwendung des Online-Tools Image.apiyi.com empfohlen, um Visualisierungseffekte schnell zu validieren.
Nano Banana Pro: Schnelleinstieg in wissenschaftliche Statistikdiagramme
Minimalbeispiel: Präzise Balkendiagramm-Codes mit KI generieren
Hier ist der einfachste Weg, ein Großes Sprachmodell über eine API aufzurufen, damit die KI automatisch Matplotlib-Code basierend auf Ihren Daten generiert:
import openai
client = openai.OpenAI(
api_key="IHR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Nutzung der einheitlichen APIYI-Schnittstelle
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{
"role": "user",
"content": """Generate publication-ready Python Matplotlib code for a grouped bar chart.
Data:
- Models: ['Method A', 'Method B', 'Method C', 'Ours']
- BLEU Score: [32.1, 35.4, 33.8, 38.7]
- ROUGE-L: [41.2, 43.8, 42.1, 47.3]
Requirements:
- Grouped bars with distinct colors (blue and green)
- Value labels on top of each bar
- Clean academic style, no top/right spines
- Title: 'Translation Quality Comparison'
- Save as PDF at 300 dpi
- Figsize: (8, 5)"""
}]
)
print(response.choices[0].message.content)
Vollständiges Tool zur Codegenerierung für wissenschaftliche Statistikdiagramme anzeigen
import openai
from typing import Dict, List, Optional
def generate_chart_code(
chart_type: str,
data: Dict,
title: str,
style: str = "academic",
figsize: str = "(8, 5)",
save_format: str = "pdf"
) -> str:
"""
Verwendet KI, um Matplotlib-Code für wissenschaftliche Statistikdiagramme zu generieren.
Args:
chart_type: Diagrammtyp - bar/line/scatter/heatmap/radar/pie/multi-panel
data: Daten-Dictionary mit Labels und Werten
title: Titel des Diagramms
style: Stil - academic/minimal/detailed
figsize: Diagrammgröße
save_format: Exportformat - pdf/png/svg
Returns:
Ausführbarer Matplotlib Python-Code
"""
client = openai.OpenAI(
api_key="IHR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
style_guide = {
"academic": "Clean academic style: no top/right spines, "
"serif fonts, 300 dpi, tight layout",
"minimal": "Minimal style: grayscale-friendly, thin lines, "
"no grid, compact layout",
"detailed": "Detailed style: with grid, annotations, "
"error bars where applicable"
}
prompt = f"""Generate publication-ready Python Matplotlib code.
Chart type: {chart_type}
Data: {data}
Title: {title}
Style: {style_guide.get(style, style_guide['academic'])}
Figure size: {figsize}
Export: Save as {save_format} at 300 dpi
Requirements:
- All data values must be mathematically precise
- Include proper axis labels and legend
- Use colorblind-friendly palette
- Code must be executable without modification
- Add value annotations where appropriate"""
try:
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Fehler: {str(e)}"
# Anwendungsbeispiel: Balkendiagramm für Modellvergleich generieren
code = generate_chart_code(
chart_type="grouped_bar",
data={
"models": ["GPT-4o", "Claude 4", "Gemini 2", "Ours"],
"accuracy": [89.2, 91.5, 87.8, 93.1],
"f1_score": [87.5, 90.1, 86.3, 92.4]
},
title="Model Performance on SQuAD 2.0",
style="academic"
)
print(code)
🚀 Schnellstart: Wir empfehlen die Nutzung der Plattform APIYI (apiyi.com), um KI-Modelle für die Generierung von Code für wissenschaftliche Statistikdiagramme aufzurufen. Die Plattform unterstützt verschiedene Modelle wie Gemini, Claude und GPT, die alle hochwertigen Matplotlib-Code erzeugen können. Nach der Registrierung erhalten Sie ein kostenloses Guthaben und können in nur 5 Minuten Ihren ersten Diagramm-Code generieren.
Codegenerierung vs. Bildgenerierung: Qualitätsvergleich bei wissenschaftlichen Diagrammen
Warum verzichtet PaperBanana bei wissenschaftlichen Statistikdiagrammen auf die direkte Bildgenerierung von Nano Banana Pro und setzt stattdessen auf Codegenerierung? Die folgenden Vergleichsdaten verdeutlichen die Gründe.
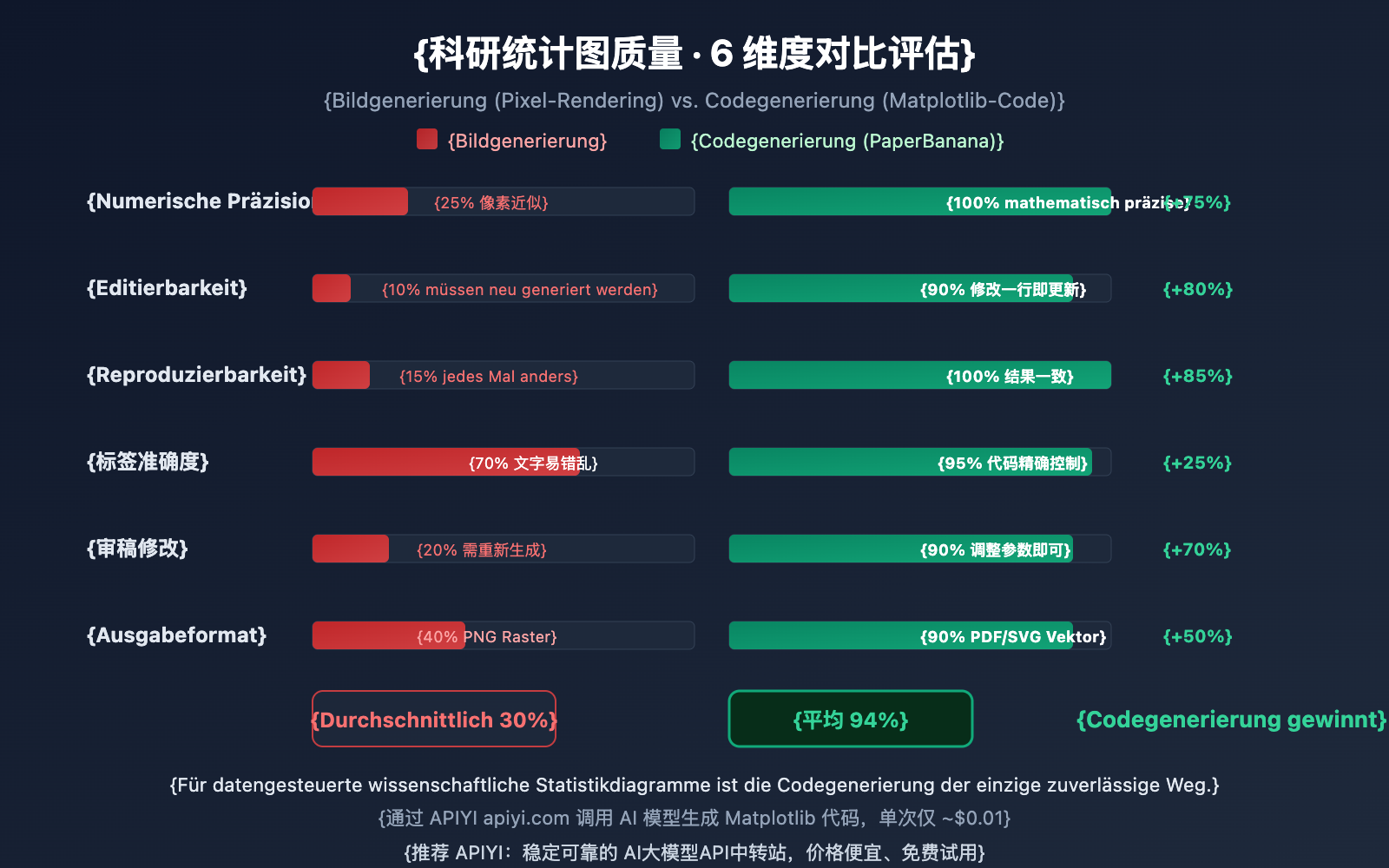
Probleme bei der direkten Bildgenerierung
Wenn Sie Nano Banana Pro, DALL-E 3 oder Midjourney verwenden, um wissenschaftliche Statistikdiagramme direkt zu generieren, versucht das Modell, ein Bild zu "zeichnen", das wie ein Diagramm aussieht. Obwohl das visuelle Ergebnis ansprechend sein kann, sind folgende Probleme fast unvermeidlich:
- Ungenaue Werte: Die Höhe der Balken ist nicht mathematisch an die tatsächlichen Daten gebunden.
- Nicht editierbar: Die Ausgabe ist ein Rasterbild, bei dem einzelne Datenpunkte nicht mehr geändert werden können.
- Nicht reproduzierbar: Es ist unmöglich, durch erneute Ausführung exakt dasselbe Diagramm zu erhalten.
- Fehleranfällige Labels: Achsenbeschriftungen weisen oft Rechtschreibfehler oder falsche Werte auf.
Vorteile der Codegenerierung
Der Ansatz der Codegenerierung von PaperBanana ist völlig anders:
- Mathematische Bindung: Jedes visuelle Element wird präzise aus den Werten im Code berechnet.
- Editierbar: Eine einzige Codezeile genügt, um Farben, Labels oder Daten zu aktualisieren.
- Reproduzierbar: Derselbe Code liefert in jeder Umgebung das exakt gleiche Ergebnis.
- Reviewer-freundlich: Wenn Gutachter Änderungen am Diagramm verlangen, müssen lediglich die Parameter im Code angepasst werden.
| Vergleichsdimension | Bildgenerierung (Nano Banana Pro etc.) | Codegenerierung (PaperBanana-Methode) |
|---|---|---|
| Numerische Genauigkeit | Niedrig: Pixel-Approximation, Halluzinationen | Hoch: Mathematisch präzise, null Halluzinationen |
| Editierbarkeit | Keine: Rasterbild nicht modifizierbar | Stark: Codeänderung aktualisiert Grafik |
| Reproduzierbarkeit | Niedrig: Jedes Ergebnis ist anders | Hoch: Code-Ausführung ist konsistent |
| Label-Genauigkeit | Mittel: Ca. 78-94 % Textgenauigkeit | Hoch: Präzise Textsteuerung per Code |
| Revisionen | Gesamtes Bild muss neu generiert werden | Parameter anpassen und neu ausführen |
| Ausgabeformat | PNG/JPG Rasterbild | PDF/SVG/EPS Vektorgrafik |
🎯 Empfehlung zur Auswahl: Für wissenschaftliche Statistikdiagramme, die präzise Werte erfordern (Balken-, Linien-, Streudiagramme etc.), wird die Codegenerierung dringend empfohlen. Wenn Ihr Diagramm eher visuelle Konzepte darstellt (Methodik-Diagramme, Architektur-Skizzen), ist die Bildgenerierung von Nano Banana Pro besser geeignet. Über die Plattform APIYI (apiyi.com) können Sie flexibel zwischen Bild- und Textgenerierungsmodellen wechseln.
Nano Banana Pro Prompt-Engineering-Techniken für wissenschaftliche Statistikdiagramme
Der Schlüssel zur Generierung von hochwertigem Matplotlib-Code durch KI liegt in der Strukturierung der Eingabeaufforderung (Prompt). Hier sind 5 bewährte Kerntechniken.
Technik 1: Daten müssen explizit angegeben werden
Lassen Sie die KI niemals Daten „erfinden“. Geben Sie in der Eingabeaufforderung explizit vollständige Datenwerte an, einschließlich Labels, Werten und Einheiten.
✅ Richtig: Data: models=['A','B','C'], accuracy=[89.2, 91.5, 87.8]
❌ Falsch: Generate a bar chart comparing three models
Technik 2: Akademische Stilvorgaben festlegen
Wissenschaftliche Diagramme haben strenge Layout-Anforderungen. Definieren Sie im Prompt folgende Einschränkungen:
- Entfernen der oberen und rechten Rahmenlinien (
spines['top'].set_visible(False)) - Schriftgrößen-Hierarchie: Titel 14pt, Achsenbeschriftungen 12pt, Skalen 10pt
- Farbenblind-freundliche Farbpaletten (Rot-Grün-Kombinationen vermeiden)
- Ausgabe im PDF/EPS-Format mit 300+ dpi
Technik 3: Numerische Beschriftungen anfordern
Fügen Sie präzise Zahlenwerte über den Balken hinzu, damit Leser die Daten erfassen können, ohne auf die Achsen schauen zu müssen – dies ist auch ein wichtiges Mittel, um „visuelle Unschärfe“ zu vermeiden.
Technik 4: Ausführbarkeit sicherstellen
Verlangen Sie explizit, dass der generierte Code „ohne Änderungen direkt ausführbar“ ist. Dies veranlasst die KI, alle notwendigen Import-Anweisungen, Datendefinitionen und Speicherbefehle einzufügen.
Technik 5: Flexibilität für Korrekturen durch Reviewer einplanen
Bitten Sie die KI, Datendefinitionen und Stilparameter getrennt am Anfang des Codes zu platzieren, um spätere schnelle Anpassungen zu erleichtern.
| Technik | Kernpunkt | Auswirkung auf die Codequalität |
|---|---|---|
| 1 | Daten explizit angeben | Verhindert Halluzinationen, sichert Präzision |
| 2 | Akademische Stilvorgaben | Entspricht den Layout-Vorgaben von Fachzeitschriften |
| 3 | Numerische Beschriftung | Verbessert die Lesbarkeit des Diagramms |
| 4 | Ausführbarkeit | Code ist sofort einsatzbereit (Out-of-the-box) |
| 5 | Parametertrennung | Verdoppelt die Effizienz bei Korrekturen nach dem Review |
🎯 Praxistipp: Kombinieren Sie diese 5 Techniken zu Ihrer Standard-Prompt-Vorlage. Nutzen Sie APIYI (apiyi.com), um verschiedene Modelle iterativ zu testen und den besten Codestil für Ihr Forschungsgebiet zu finden. Die Plattform unterstützt den Wechsel zwischen Modellen wie Gemini, Claude und GPT, was den Vergleich der Ergebnisse erleichtert.
Häufig gestellte Fragen
Q1: Ist die Codegenerierung bei PaperBanana langsamer als die Bildgenerierung?
Ganz im Gegenteil, die Codegenerierung ist meist schneller. Die Erstellung eines 50-80 Zeilen langen Matplotlib-Codes dauert nur 2-5 Sekunden, während die Bildgenerierung 10-30 Sekunden benötigt. Wichtiger ist jedoch, dass der Code lokal ausgeführt und wiederholt angepasst werden kann, ohne jedes Mal die API neu aufrufen zu müssen. Über APIYI (apiyi.com) kostet die Generierung pro Aufruf etwa 0,01 $, was deutlich günstiger ist als die 0,05 $ für die Bildgenerierung.
Q2: Wie ist die Qualität des generierten Matplotlib-Codes? Sind viele Änderungen nötig?
In den 240 ChartMimic-Benchmarks von PaperBanana war der generierte Python-Code direkt ausführbar und die visuelle Ausgabe entsprach der ursprünglichen Beschreibung. In der Praxis müssen meist nur Stilparameter wie Farben und Schriftarten feinjustiert werden. Wir empfehlen, Claude- oder Gemini-Modelle über die APIYI-Plattform (apiyi.com) zu nutzen, da diese bei der Codequalität besonders gut abschneiden. Das Online-Tool Image.apiyi.com unterstützt zudem eine schnelle Vorschau der Ergebnisse.
Q3: Wie fange ich am besten an, KI für wissenschaftliche Diagramme zu nutzen?
Empfohlener Schnellstart:
- Besuchen Sie APIYI (apiyi.com), registrieren Sie sich und erhalten Sie Ihren API-Key sowie kostenloses Testguthaben.
- Bereiten Sie Ihre Experimentaldaten vor (Modellnamen, Metriken etc.).
- Nutzen Sie die Prompt-Vorlage aus diesem Artikel und ersetzen Sie die Platzhalter durch Ihre echten Daten.
- Rufen Sie die API auf, um Matplotlib-Code zu generieren, und führen Sie ihn lokal aus.
- Passen Sie die Stilparameter gemäß den Anforderungen Ihrer Fachzeitschrift an und exportieren Sie das PDF.
Zusammenfassung
Die Kernpunkte der Codegenerierung für wissenschaftliche Statistikdiagramme mit Nano Banana Pro:
- Code vor Pixeln: PaperBanana nutzt Matplotlib-Codegenerierung anstelle von Bild-Rendering für wissenschaftliche Diagramme, um numerische Halluzinationen von Grund auf zu eliminieren.
- Abdeckung von 7 Diagrammtypen: Balkendiagramme, Liniendiagramme, Streudiagramme, Heatmaps, Netzdiagramme (Radar-Charts), Tortendiagramme und Multi-Panel-Diagramme decken alle Anforderungen an die Datenvisualisierung in wissenschaftlichen Arbeiten ab.
- Editierbar und reproduzierbar: Die Code-Ausgabe ermöglicht freie Anpassungen und präzise Reproduzierbarkeit. Bei Korrekturen für Reviewer müssen lediglich Parameter angepasst werden, anstatt das Diagramm komplett neu zu generieren.
- 5 Prompt-Techniken: Explizite Daten, akademische Constraints, numerische Beschriftungen, Ausführbarkeit und Parametertrennung stellen sicher, dass der generierte Code hochwertig und sofort einsatzbereit ist.
Angesichts der Präzisionsanforderungen bei wissenschaftlichen Diagrammen ist „Code als Diagramm“ der einzige zuverlässige Weg. Durch die KI-gestützte Generierung von Matplotlib-Code erhalten Sie sowohl die Effizienz der KI als auch die Präzision des Codes – das Beste aus beiden Welten.
Wir empfehlen APIYI (apiyi.com), um die KI-gestützte Codegenerierung für wissenschaftliche Diagramme schnell auszuprobieren. Die Plattform bietet Gratis-Guthaben und eine Auswahl an verschiedenen Modellen. Nutzen Sie auch das Online-Tool Image.apiyi.com für eine schnelle Vorschau der Ergebnisse.
📚 Referenzen
⚠️ Hinweis zum Linkformat: Alle externen Links verwenden das Format
Name der Quelle: domain.com. Dies erleichtert das Kopieren, verhindert jedoch anklickbare Sprünge, um den Verlust von SEO-Autorität zu vermeiden.
-
PaperBanana Projekt-Homepage: Offizielle Release-Seite, inklusive Paper und Demo
- Link:
dwzhu-pku.github.io/PaperBanana/ - Beschreibung: Erfahren Sie mehr über die Kernprinzipien der Diagramm-Codegenerierung und die Evaluierungsdaten von PaperBanana.
- Link:
-
PaperBanana Paper: Volltext des arXiv-Preprints
- Link:
arxiv.org/abs/2601.23265 - Beschreibung: Vertiefen Sie Ihr Verständnis für die technologische Wahl zwischen Codegenerierung vs. Bildgenerierung und den ChartMimic-Benchmark.
- Link:
-
Matplotlib Offizielle Dokumentation: Python-Bibliothek für Datenvisualisierung
- Link:
matplotlib.org/stable/ - Beschreibung: Matplotlib API-Referenz zum Verständnis und zur Anpassung von KI-generiertem Diagrammcode.
- Link:
-
Nano Banana Pro Offizielle Dokumentation: Vorstellung des Google DeepMind Modells
- Link:
deepmind.google/models/gemini-image/pro/ - Beschreibung: Erfahren Sie mehr über die Bildgenerierungsfähigkeiten von Nano Banana Pro im Kontext von Methodik-Diagrammen.
- Link:
-
APIYI Online-Tool zur Diagrammerstellung: No-Code Diagramm-Vorschau
- Link:
Image.apiyi.com - Beschreibung: Schnelle Vorschau der Ergebnisse von KI-generierten wissenschaftlichen Diagrammen.
- Link:
Autor: APIYI Team
Technischer Austausch: Teilen Sie gerne Ihre Eingabeaufforderung-Vorlagen für wissenschaftliche Diagramme und Matplotlib-Tricks in den Kommentaren. Weitere Informationen zu KI-Modellen finden Sie in der APIYI (apiyi.com) Tech-Community.