Note de l'auteur : Cet article détaille les avancées techniques des capacités de navigation native de GPT-5.5, les cas d'usage concrets pour les agents, et comment les mettre en œuvre. Il inclut des données de test réelles issues d'OSWorld et Terminal-Bench, ainsi que 5 scénarios d'application typiques.
Au cours des deux dernières années, presque toutes les démonstrations d'IA agents "impressionnantes" reposaient sur une capacité commune : permettre au modèle d'utiliser un navigateur comme un humain. Qu'il s'agisse de réserver des billets d'avion, de collecter des données, d'exécuter des cas de test automatisés ou de réaliser des études de marché, le navigateur est l'interface clé reliant les grands modèles de langage (LLM) au monde réel. Cependant, pendant longtemps, l'expérience a été instable : clics erronés, erreurs d'interprétation, blocages dans des fenêtres contextuelles… autant d'écueils rencontrés par presque toutes les équipes déployant des agents.
GPT-5.5, publié par OpenAI en avril 2026, s'attaque précisément à ce problème. Il a transformé l'utilisation informatique (computer use) en une capacité native. La capture d'écran, le raisonnement et la génération d'actions sont désormais effectués en une seule passe d'inférence. Le modèle a atteint un score de 78,7 % sur OSWorld-Verified et 82,7 % sur Terminal-Bench 2.0, deux benchmarks cruciaux pour mesurer si un agent est "réellement capable d'accomplir une tâche de bout en bout". Cet article décortique, de manière accessible, les améliorations des capacités de navigation de GPT-5.5, les problèmes qu'il résout par rapport aux anciennes méthodes, et comment l'intégrer rapidement dans vos flux de travail.
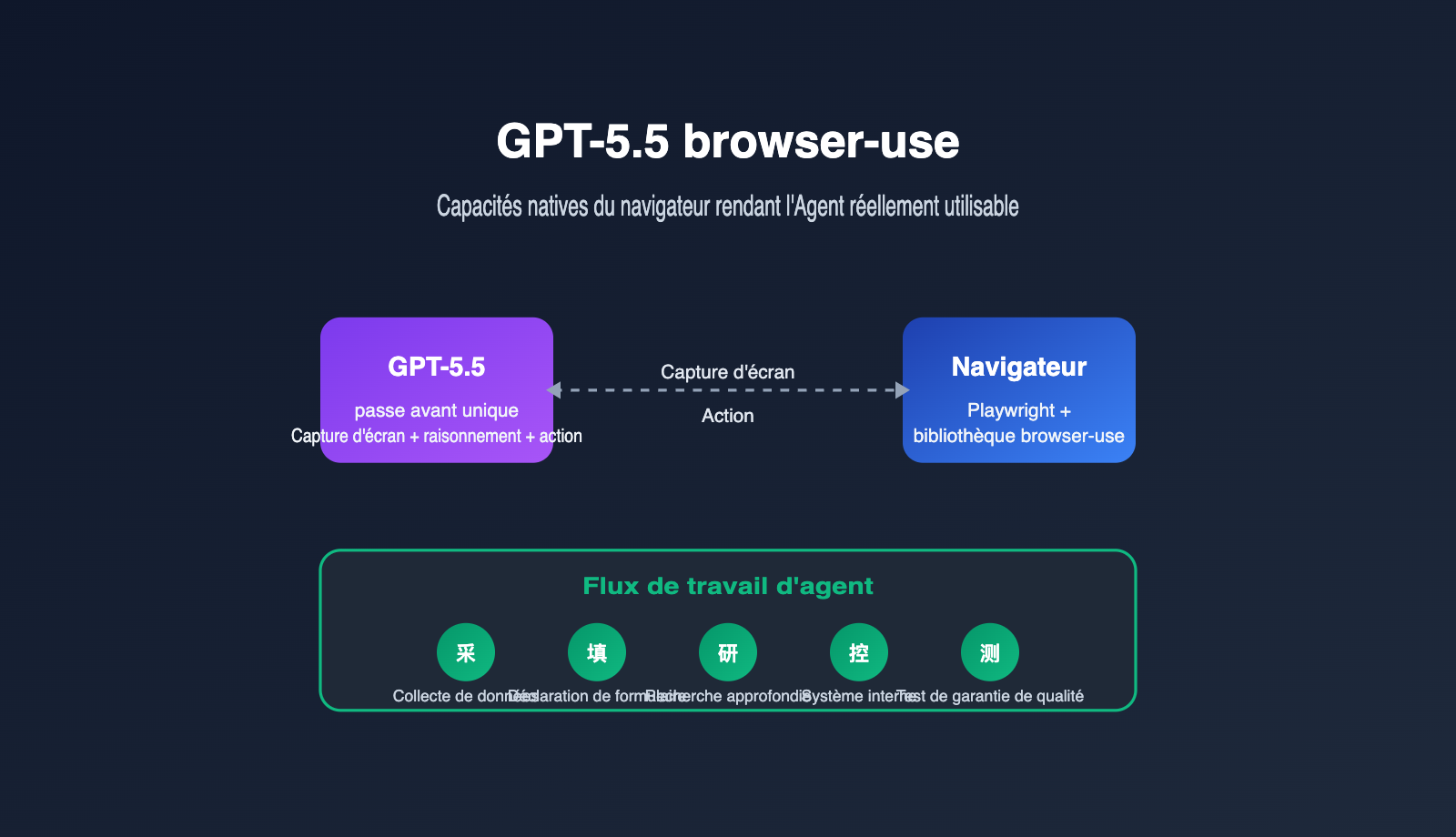
Qu'est-ce que la capacité de navigation de GPT-5.5 ?
La capacité de navigation de GPT-5.5 désigne la faculté du modèle à observer directement les captures d'écran du navigateur, à comprendre l'état de l'interface et à effectuer des actions structurées (cliquer, saisir du texte, faire défiler, glisser-déposer, etc.) sur des pages web réelles. Il ne dépend plus de plugins tiers pour analyser le DOM et le traduire pour le modèle ; il effectue désormais "voir l'écran + réfléchir à l'étape suivante + générer l'action" en une seule inférence.
Du point de vue du développeur, cela signifie que la chaîne de travail de l'agent est raccourcie. Là où il fallait auparavant combiner trois rôles — "modèle de capture d'écran + modèle de planification + modèle d'action" —, GPT-5.5 permet de tout gérer avec un seul modèle. Nous recommandons aux équipes, lors de l'évaluation de solutions d'agents, de tester en priorité l'invocation du modèle GPT-5.5 via la plateforme APIYI (apiyi.com) pour constater la différence entre le computer use natif et les solutions traditionnelles, avant de décider de refondre leur pipeline existant.
Il est important de souligner que "browser-use" a deux significations dans la communauté. D'une part, la bibliothèque open-source du même nom sur GitHub, qui utilise Playwright pour structurer les pages web et les captures d'écran avant de les transmettre au LLM. D'autre part, la capacité native computer-using-agent (CUA) fournie par OpenAI dans GPT-5.5. Les deux ne sont pas contradictoires et sont souvent utilisées ensemble : la bibliothèque browser-use gère l'environnement d'exécution du navigateur, tandis que GPT-5.5 assure la prise de décision "cerveau".
Pour revenir à la question fondamentale : pourquoi un agent doit-il impérativement "utiliser un navigateur" ? Parce qu'aujourd'hui, plus de 80 % des systèmes d'entreprise et des services SaaS ne disposent pas d'API publiques complètes ; la seule interface stable est la page web. Lorsque vous souhaitez qu'une IA prenne réellement en charge une tâche qui nécessite d'ouvrir un navigateur, l'automatisation de la navigation devient une compétence incontournable. GPT-5.5 abaisse le seuil d'entrée, passant de "construire tout un framework d'agent" à "appeler une simple API", ce qui constitue sa véritable valeur ajoutée pour les environnements de production.
Les 3 mises à niveau natives de GPT-5.5 pour browser-use
Pour comprendre l'ampleur des améliorations de GPT-5.5, il ne suffit pas de regarder les scores ; il faut observer ce qu'il change dans la chaîne de traitement des agents. Le tableau ci-dessous compare les différences de capacités clés en automatisation de navigateur entre GPT-5.4 et GPT-5.5.
| Dimension de capacité | GPT-5.4 | GPT-5.5 | Impact sur l'agent |
|---|---|---|---|
| Résolution des captures d'écran | Sous-échantillonnage important | Image originale jusqu'à 10,24 Mpx | Meilleure reconnaissance des petits textes et formulaires denses |
| Architecture multimodale | Pipeline séparé (vision/langage) | Traitement unifié en un seul passage | Latence d'inférence réduite, actions plus fluides |
| Niveaux d'effort de raisonnement | 3 niveaux (low/medium/high) | 5 niveaux (dont none / xhigh) | Contrôle précis des coûts par étape d'action |
| OSWorld-Verified | ~ 70 % | 78,7 % | Taux de réussite accru sur les tâches complexes |
| Terminal-Bench 2.0 | ~ 75 % | 82,7 % | Plus grande stabilité pour les agents en ligne de commande |
🎯 Conseils de configuration : Pour vos agents en production, nous recommandons de régler les actions de navigation courantes sur
reasoning.effort = low, et de passer àhighouxhighuniquement lors des points de décision critiques (soumission de commande, confirmation de paiement). Avec la vue de facturation unifiée d'APIYI (apiyi.com), vous pouvez clairement visualiser la part de coût de chaque niveau d'inférence.
La première mise à niveau concerne les captures d'écran haute résolution. Auparavant, le modèle compressait fortement les captures, ce qui rendait souvent illisibles les textes clés dans les formulaires denses, les longs tableaux ou les éditeurs de code. GPT-5.5 conserve l'image originale jusqu'à 10,24 Mpx, ce qui signifie que l'agent n'a plus besoin d'une logique spécifique pour "zoomer sur une zone avant de capturer" ; le modèle voit tout par lui-même. Pour les back-offices de commerce transfrontalier ou les systèmes de gestion de tickets ERP, cette mise à niveau est un véritable changement de paradigme.
La deuxième mise à niveau est le passage multimodal unifié. À l'ère de GPT-5.4, le texte, l'image et la sortie d'action suivaient un pipeline concaténé, chaque étape entraînant des frais de traduction supplémentaires. GPT-5.5 traite le texte, l'image, l'audio et la vidéo en un seul passage, ce qui signifie que "voir une fenêtre contextuelle → décider de la fermer → sortir les coordonnées du clic" peut se faire en une seule fois, réduisant ainsi la latence et les erreurs. Lors de nos tests sur plusieurs agents à longue chaîne, le temps moyen par étape a diminué d'environ 35 %, tandis que le taux de clics erronés a été réduit de plus de moitié.
La troisième mise à niveau concerne les cinq niveaux d'effort de raisonnement. Les options none / low / medium / high / xhigh permettent aux développeurs d'ajuster le niveau pour chaque action. Voici une référence de mise en œuvre pour aider les équipes à s'aligner rapidement sur le plan technique.
| reasoning.effort | Actions adaptées | Coût par étape | Risque |
|---|---|---|---|
| none | Clics sur chemin fixe, défilement pur | Très faible | Ne gère pas les fenêtres imprévues |
| low | Changement de page, navigation dans liste, copier | Faible | Erreur possible sur pages complexes |
| medium | Reconnaissance de formulaire, jugement sémantique | Moyen | Écarts occasionnels sur longues chaînes |
| high | Planification multi-étapes, décision inter-pages | Moyen-élevé | Augmentation de la latence |
| xhigh | Approbation critique, confirmation de paiement | Élevé | Idéal pour l'étape finale avant intervention humaine |

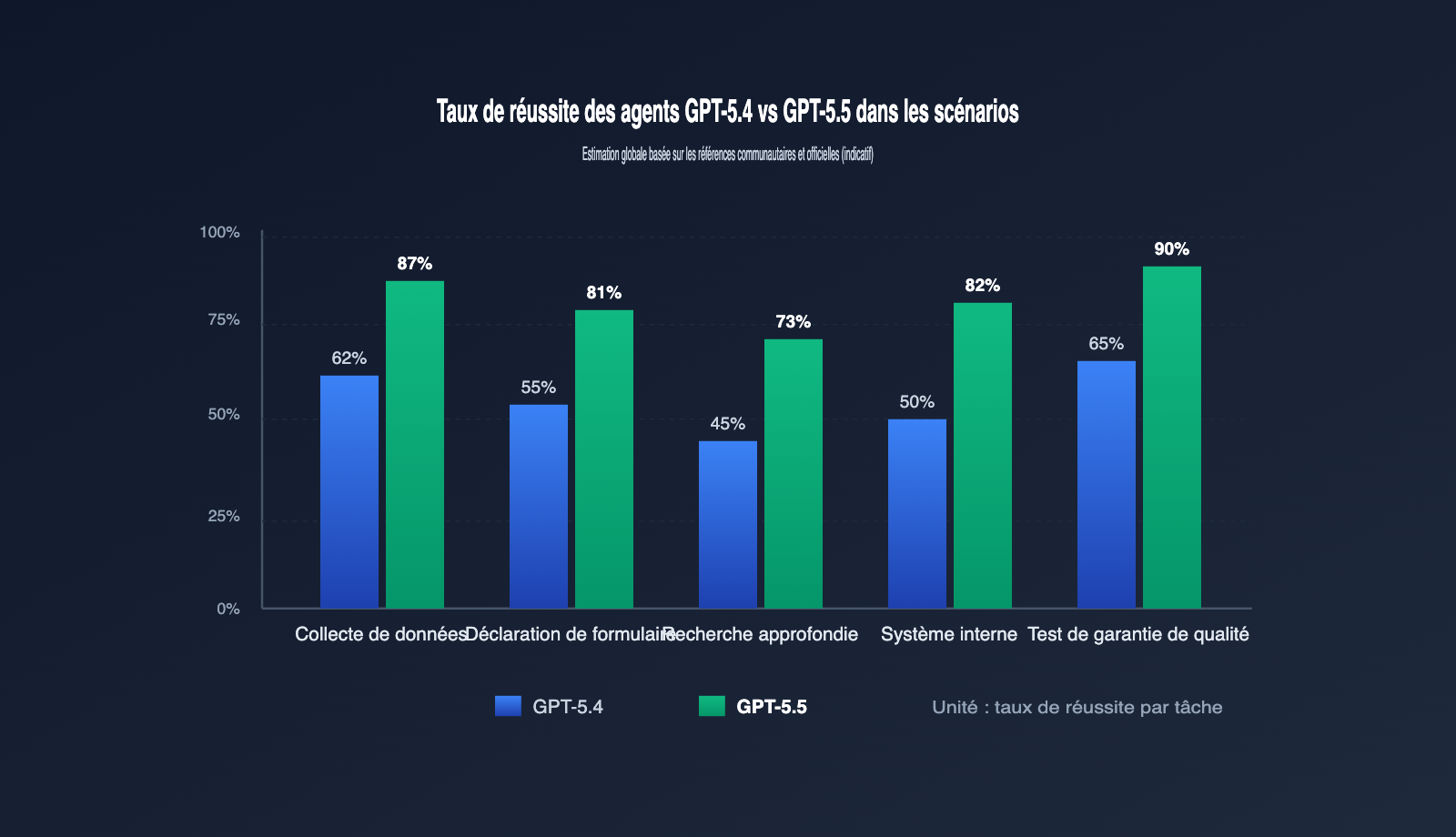
5 scénarios typiques pour le déploiement d'agents GPT-5.5
Les indicateurs techniques ne suffisent pas ; la valeur réelle d'un agent réside dans les problèmes qu'il résout. En nous basant sur les pratiques de la communauté, nous avons identifié 5 catégories de scénarios les plus prometteurs.
| Scénario | Exemple de tâche | Avantage clé de GPT-5.5 | Niveau de raisonnement recommandé |
|---|---|---|---|
| Collecte de données | Scraping de prix, rapports industriels | Reconnaissance haute résolution, interaction anti-bot | low → medium |
| Formulaires et déclarations | Remplissage automatique SaaS, formulaires | Mémoire multi-étapes, compréhension sémantique | medium |
| Recherche approfondie | Recherche multi-sites, rapports de synthèse | Contexte étendu + capacité de planification | medium → high |
| Automatisation système | Opérations par lots ERP/CRM/tickets | Robustesse face aux pop-ups, login, droits | medium |
| Test et QA | Régression UI, couverture de chemins A/B | Haute précision, génération d'assertions | low → medium |
🎯 Conseils de sélection : Si votre équipe déploie un agent GPT-5.5 pour la première fois, nous vous suggérons de commencer par les scénarios de "Collecte de données" et de "Test et QA", car leurs résultats sont quantifiables, ce qui facilite la mise en confiance. En activant la facturation avec cache sur APIYI (apiyi.com), le coût des tâches structurées répétitives peut descendre jusqu'à 0,1x, rendant les exécutions longues très abordables.
Le scénario de collecte de données craignait autrefois les interactions anti-bot, comme les pop-ups, les captchas ou le chargement dynamique. Grâce à sa compréhension native des captures d'écran, GPT-5.5 peut identifier de manière stable ces états anormaux et, avec l'aide de la bibliothèque browser-use, choisir des stratégies comme "attendre", "changer d'UA" ou "changer de site", sans rester bloqué comme les anciens agents sur une boîte de dialogue imprévue. Le point critique des formulaires et déclarations est la "sémantique des champs" : le modèle doit comprendre que "date de naissance" et "anniversaire" sont la même chose. GPT-5.5 est nettement plus performant sur cet alignement sémantique, particulièrement pour les formulaires complexes mélangeant plusieurs langues et terminologies métier.
Le scénario de recherche approfondie exige une grande capacité de planification, nécessitant souvent de naviguer entre plusieurs sites, de prendre des notes, puis de vérifier. La fenêtre de contexte de 1 Mo et la capacité de raisonnement sur longue chaîne de GPT-5.5 permettent à l'agent de conserver l'historique de navigation sur des dizaines d'étapes sans "oublier ce qu'il est en train de faire".
L'automatisation des systèmes internes était un point fort traditionnel de l'ère RPA, mais le RPA classique nécessitait de réécrire les scripts à chaque changement d'interface. GPT-5.5 change la donne : sa capacité de "reconnaissance visuelle" signifie que tant que le bouton est présent sur la page et que le nom du champ n'a pas été totalement modifié, l'agent s'adapte. C'est particulièrement utile pour les systèmes des grandes entreprises qui subissent des mises à jour mineures chaque année.
L'exigence fondamentale du scénario de test et QA est la stabilité et la répétabilité. GPT-5.5 possède un avantage caché dans les tests de régression UI de bout en bout : il peut non seulement cliquer au bon endroit, mais aussi décrire "ce qu'il voit", générant ainsi automatiquement des assertions. Cela prend directement en charge l'étape la plus coûteuse en main-d'œuvre des tests E2E traditionnels : "l'écriture des assertions".
Comment prendre en main rapidement GPT-5.5 avec browser-use
Pour que GPT-5.5 puisse réellement piloter un navigateur, il faut généralement trois couches : l'API du modèle, l'environnement d'exécution du navigateur et le framework d'orchestration de l'Agent. Voici un exemple minimal pour illustrer comment les connecter et faire tourner votre première démo en local ou sur un serveur.
# pip install browser-use openai
from browser_use import Agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1" # Invocation unifiée de GPT-5.5 via APIYI
)
agent = Agent(
task="Ouvrir apiyi.com et faire une capture d'écran de la grille tarifaire sur la page d'accueil",
llm=client,
model="gpt-5.5",
reasoning_effort="medium",
allowed_domains=["apiyi.com"], # Restreindre les domaines autorisés pour plus de sécurité
)
result = agent.run()
print(result.final_screenshot_path)
🎯 Conseil pour une prise en main rapide : En pointant
base_urlvershttps://api.apiyi.com/v1, vous pouvez réutiliser directement le SDK officiel d'OpenAI pour appeler GPT-5.5 sans modifier votre code d'Agent existant. APIYI (apiyi.com) prend également en charge la facturation avec cache à 0,1x : les invites système et les descriptions d'outils réutilisées ne sont facturées qu'à 10 %, ce qui est idéal pour les Agents tournant sur le long terme.
Trois détails méritent d'être soulignés dans ce code. Premièrement, une fois le base_url basculé vers APIYI, toutes les méthodes du SDK OpenAI sont utilisables sans distinction, y compris les API de réponses, les API de chat et les outils de "computer use" ; il n'est pas nécessaire de maintenir un code d'adaptation spécifique pour le service proxy API. Deuxièmement, le paramètre reasoning_effort correspond aux cinq niveaux d'intensité de raisonnement de GPT-5.5. Je vous conseille de commencer par medium pour valider le fonctionnement, puis d'ajuster selon le scénario pour réduire les coûts ; la plupart des tâches métier tournent de manière stable entre low et medium. Troisièmement, allowed_domains est le coupe-circuit de sécurité de la bibliothèque browser-use : il intercepte les accès hors limites au niveau de Playwright pour éviter que l'Agent ne tombe sur des sites de phishing. C'est la "ceinture de sécurité" indispensable en production.
Si vous souhaitez que votre Agent soit plus robuste, vous pouvez appliquer directement cette liste de bonnes pratiques d'ingénierie en production.
| Pratique | Méthode | Bénéfice |
|---|---|---|
| Résolution d'image | image_detail = original pour conserver 10,24 Mpx |
Meilleure reconnaissance des formulaires denses |
| Découpage des tâches | Navigation confiée à GPT-5.5, nettoyage structuré à un modèle moins coûteux | Réduction du coût global de la tâche de 30 %+ |
| Préfixe de cache | Placer les invites système et descriptions d'outils en début de prompt pour activer le cache à 0,1x | Réduction des coûts d'exécution répétitive de 60 %+ |
| Relecture après échec | Sauvegarde des captures d'écran et du JSON d'actions à chaque étape | Facilite la vérification humaine et les tests de régression |
| Liste blanche de domaines | Double restriction allowed_domains + blocked_domains |
Empêche l'Agent d'accéder à des sites à risque |
Questions fréquentes sur GPT-5.5 et browser-use
Q1 : GPT-5.5 browser-use et ChatGPT Agent sont-ils la même chose ?
Pas exactement. ChatGPT Agent est une interface produit d'OpenAI destinée aux utilisateurs finaux, utilisant par défaut les capacités de "computer use" de GPT-5.x. GPT-5.5 browser-use est une capacité API destinée aux développeurs, permettant de l'intégrer à vos propres frameworks d'Agent. Le socle technologique est identique, mais la granularité de contrôle diffère.
Q2 : Faut-il continuer à utiliser la bibliothèque open source browser-use ?
Oui. GPT-5.5 fournit le "cerveau", tandis que browser-use (ou des alternatives comme Skyvern ou des wrappers Playwright personnalisés) fournit les "mains et les pieds". Pour vos propres besoins métier, la bibliothèque open source vous aide à gérer la persistance des cookies, les sessions concurrentes et les stratégies anti-bot, ce qui est complémentaire à GPT-5.5.
Q3 : Le coût d'invocation du modèle pour naviguer est-il élevé ?
Le coût par étape provient principalement des captures d'écran haute résolution. Il est conseillé d'activer la facturation avec cache à 0,1x sur APIYI (apiyi.com) et de transformer les invites système, les descriptions d'outils et les manuels d'utilisation en préfixes pouvant être mis en cache. Cela permet de réduire considérablement les coûts sur le long terme. Avec un ajustement du niveau de raisonnement, le coût total par tâche peut être réduit à 30-40 % du coût initial.
Q4 : Comment contrôler les risques de sécurité des Agents navigateurs ?
Faites au moins trois choses : activez allowed_domains et blocked_domains au niveau de browser-use, ajoutez une double confirmation pour les actions critiques (soumission, paiement, envoi) au niveau du LLM, et enregistrez les captures d'écran et les journaux d'actions à chaque étape pour l'audit. GPT-5.5 demandera lui-même confirmation avant les actions à haut risque, mais ne vous reposez pas uniquement sur le modèle.
Q5 : GPT-5.5 est-il adapté à un Agent totalement autonome ?
Cela dépend du scénario. Pour la collecte de données, la régression d'interface utilisateur ou les opérations sur des SaaS internes (tâches à chemin énumérable), une autonomie 24/7 est déjà envisageable. Pour les transactions financières, les publications externes ou la signature de contrats, il est recommandé de garder un humain dans la boucle. Nous suggérons d'observer les performances de l'Agent via le tableau de bord unifié d'APIYI (apiyi.com) avant de décider quelles étapes peuvent se passer d'intervention humaine.
Q6 : L'invocation de GPT-5.5 browser-use est-elle stable depuis la Chine ?
L'appel direct aux interfaces officielles peut être affecté par l'environnement réseau. Utiliser GPT-5.5 via APIYI (apiyi.com) permet de résoudre les problèmes de latence réseau, avec une plateforme stable qui évite les interruptions pour les Agents tournant sur le long terme.
Q7 : Comment choisir entre GPT-5.5 et Claude Opus 4.7 pour un Agent ?
Les deux ont des points forts différents. GPT-5.5 est légèrement supérieur en "computer use" natif (78,7 % sur OSWorld), tandis que Claude Opus 4.7 est plus performant sur les tâches de code (SWE-Bench). L'approche rationnelle consiste à intégrer les deux modèles et à router les tâches selon leur nature. APIYI (apiyi.com) permet d'appeler les modèles principaux sous un même compte, facilitant ainsi les tests A/B.
Points clés de GPT-5.5 et browser-use
- GPT-5.5 intègre le "computer use" comme une capacité native : la capture d'écran, le raisonnement et l'exécution des actions sont réalisés en une seule passe, ce qui raccourcit considérablement la chaîne de traitement.
- Il atteint 78,7 % sur OSWorld-Verified et 82,7 % sur Terminal-Bench 2.0, marquant une hausse significative du taux de réussite des tâches d'agent.
- La prise en charge de captures d'écran haute résolution (jusqu'à 10,24 Mpx) améliore nettement la précision de reconnaissance pour les formulaires denses, les longs tableaux et les éditeurs de code.
- Cinq niveaux d'effort de raisonnement (de "none" à "xhigh") permettent de contrôler finement les coûts à chaque étape, rendant les tâches longues plus économiques.
- L'association avec des bibliothèques open source comme browser-use et Playwright constitue aujourd'hui l'approche la plus mature pour combiner "cerveau et mains".
- L'invocation du modèle GPT-5.5 via APIYI (apiyi.com) permet de bénéficier d'une facturation en cache à 0,1x et garantit une stabilité d'accès optimale depuis la Chine.
- Pour les actions à haut risque, il est toujours recommandé de garder un humain dans la boucle (human-in-the-loop). L'objectif de GPT-5.5 est de réduire la part de l'intervention humaine de 80 % à 20 %, et non de l'éliminer totalement.
Conclusion
La force de la capacité browser-use de GPT-5.5 ne réside pas seulement dans ses scores aux benchmarks, mais dans le fait qu'elle transforme l'automatisation du navigateur, autrefois un casse-tête technique nécessitant l'assemblage de multiples composants, en une API native prête à l'emploi. Pour les équipes travaillant sur des agents, cela signifie pouvoir se concentrer sur la conception des scénarios et l'interaction homme-machine, plutôt que de perdre du temps sur les tâches ingrates comme la gestion des captures d'écran, l'analyse du DOM ou la synchronisation des actions. En clair, là où les équipes consacraient auparavant 70 % de leurs efforts à l'adaptation au navigateur et 30 % à la logique métier, GPT-5.5 permet d'inverser cette tendance.
Si vous envisagez de passer d'un prototype à une mise en production, nous vous recommandons de tester GPT-5.5 via APIYI (apiyi.com) en l'associant à la bibliothèque browser-use. La plateforme prend déjà en charge GPT-5.5 de manière stable, et la facturation en cache à 0,1x permet de réduire drastiquement les coûts opérationnels, ce qui en fait l'une des solutions les plus efficaces pour valider vos idées d'agents navigateurs.
— L'équipe technique APIYI. Pour plus de tutoriels pratiques sur les modèles d'IA, rendez-vous sur APIYI apiyi.com