Note de l'auteur : Décryptage approfondi de la fenêtre de contexte de 1M de GPT-5.4, du point de rupture tarifaire à 272K tokens qui double le prix, de la plage de performance optimale 127K-272K, et d'une analyse complète des coûts avec des solutions pour économiser.
GPT-5.4 annonce prendre en charge un contexte ultra-long de 1,05 million de tokens, mais ce que beaucoup de développeurs ignorent, c'est que : au-delà de 272K tokens, le prix double et la précision commence à chuter. Ce n'est pas une simple histoire de "plus c'est grand, mieux c'est".
Valeur clé : Cet article décompose en détail la courbe de performance contextuelle de GPT-5.4, le mécanisme du point de rupture tarifaire à 272K, et comment utiliser GPT-5.4 de manière efficace au coût le plus bas via APIYI.

Points clés de la tarification contextuelle de GPT-5.4
| Point clé | Explication | Impact pratique |
|---|---|---|
| Contexte total | 1 050 000 tokens (1,05 million) | Peut théoriquement traiter des documents très longs |
| Point de rupture à 272K | Le prix d'entrée double au-delà ($2,50 → $5,00) | Contrôler en dessous de 272K permet d'économiser la moitié du coût d'entrée |
| Plage de performance optimale | 127K-272K tokens | Précision ~97%, meilleur rapport qualité-prix |
| Zone de baisse de performance | La précision commence à baisser au-delà de 256K | La précision peut chuter à ~36% dans l'intervalle 512K-1M |
| vs GPT-5.2 | Entrée 43% plus chère, sortie 7% plus chère | Mais moins de tokens de raisonnement, l'écart réel se réduit |
Comprendre le contexte de GPT-5.4 : "Pouvoir" ne signifie pas "Devoir"
C'est un point crucial : Le fait que GPT-5.4 prenne en charge 1,05 million de tokens de contexte ne signifie pas que vous devez le saturer. D'après les données d'évaluation publiques d'OpenAI :
- 16K-32K tokens : Précision de récupération "Needle-in-a-Haystack" d'environ 97%
- 127K-272K tokens : La précision reste stable à un niveau élevé, et c'est la plage de tarification standard
- Au-delà de 256K : La précision commence à décliner
- 512K-1M tokens : La précision peut chuter brutalement à environ 36%
GPT-5.2 atteignait auparavant une précision proche de 100% dans les tests MRCR à 4 aiguilles sur 256K tokens, ce qui confirme que 256K est un seuil critique pour la fiabilité des performances.
Conseil pratique : Pour la plupart des cas d'utilisation, limiter l'entrée à moins de 272K tokens est la stratégie la plus judicieuse — elle garantit la précision et évite le doublement des coûts. En accédant à GPT-5.4 via APIYI (apiyi.com), les tarifs sont alignés sur ceux d'OpenAI, et vous pouvez bénéficier de réductions allant jusqu'à 20% avec les offres de recharge.
Décryptage complet de la tarification contextuelle de GPT-5.4
Tarification standard de GPT-5.4 (par million de tokens)
Voici la structure de tarification complète et graduelle de GPT-5.4 :
| Mode de traitement | Entrée (≤272K) | Entrée (>272K) | Entrée mise en cache (≤272K) | Entrée mise en cache (>272K) | Sortie (≤272K) | Sortie (>272K) |
|---|---|---|---|---|---|---|
| Standard | 2,50 $ | 5,00 $ | 0,25 $ | 0,50 $ | 15,00 $ | 22,50 $ |
| Batch | 1,25 $ | 2,50 $ | 0,13 $ | 0,26 $ | 7,50 $ | 11,25 $ |
| Flex | 1,25 $ | 2,50 $ | 0,13 $ | 0,26 $ | 7,50 $ | 11,25 $ |
| Priority | 5,00 $ | — | 0,50 $ | — | 30,00 $ | — |
Trois détails clés de la tarification contextuelle de GPT-5.4
Premièrement, le dépassement de 272K entraîne une majoration complète. Lorsque votre entrée dépasse 272 000 tokens, le mécanisme de majoration s'applique à l'ensemble de la session, et non pas uniquement à la partie dépassée. Cela signifie qu'une fois le seuil franchi, tous les tokens sont facturés au tarif doublé.
Deuxièmement, le prix de sortie augmente également. Ce n'est pas seulement l'entrée qui double ; au-delà de 272K, le prix de sortie passe de 15,00 $ à 22,50 $, soit une hausse de 50 %. Cela a un impact significatif sur les tâches intensives en sortie (comme la génération de code ou la rédaction de longs textes).
Troisièmement, l'entrée mise en cache est un outil d'économie. L'entrée mise en cache dans la plage standard ne coûte que 0,25 $/M tokens, soit un dixième du prix d'origine. Si vos tâches impliquent des invites système répétitives ou un contexte fixe, une utilisation judicieuse du cache peut réduire considérablement les coûts.
Analyse comparative des tarifs : GPT-5.4 vs GPT-5.2
La question qui préoccupe le plus les développeurs : Combien coûte la migration de GPT-5.2 vers GPT-5.4 ?

Différences fondamentales de tarification : GPT-5.4 vs GPT-5.2
| Élément tarifaire | GPT-5.2 | GPT-5.4 Standard | GPT-5.4 Étendu | Hausse standard |
|---|---|---|---|---|
| Entrée | 1,75 $/M | 2,50 $/M | 5,00 $/M | +43 % |
| Entrée en cache | 0,175 $/M | 0,25 $/M | 0,50 $/M | +43 % |
| Sortie | 14,00 $/M | 15,00 $/M | 22,50 $/M | +7 % |
| Entrée Pro | 21,00 $/M | 30,00 $/M | 60,00 $/M | +43 % |
| Sortie Pro | 168,00 $/M | 180,00 $/M | 270,00 $/M | +7 % |
La tarification de GPT-5.4 est plus élevée, mais l'écart de coût réel est faible
OpenAI indique officiellement que GPT-5.4 est "le modèle d'inférence le plus efficace" – il résout les mêmes problèmes avec moins de tokens d'inférence. En d'autres termes, bien que le prix unitaire ait augmenté, le nombre total de tokens consommés par invocation pourrait être moindre.
Cependant, il faut noter : la longueur moyenne des réponses de GPT-5.4 est environ 24 % plus longue que celle de GPT-5.2, ce qui peut compenser partiellement les gains d'efficacité en inférence.
Meilleures pratiques pour l'utilisation du contexte GPT-5.4
Les trois règles d'or
Règle n°1 : Essayez de rester sous 272K tokens. C'est la plage optimale en termes de rapport qualité-prix – haute précision et faible coût. Pour la grande majorité des cas d'utilisation, 272K tokens suffisent pour couvrir des conversations multi-tours, l'analyse de longs documents ou la revue de vastes bases de code.
Règle n°2 : L'intervalle 127K-272K est la zone idéale. Dans cette plage, la précision de récupération du modèle reste stable à environ 97%, tout en tirant pleinement parti de l'avantage du long contexte de GPT-5.4. C'est le double de la fenêtre standard de 128K de GPT-5.2, ce qui est déjà suffisant pour traiter la plupart des tâches "qui ne tenaient pas auparavant".
Règle n°3 : Réfléchissez à deux fois avant de dépasser 272K. À moins que votre tâche ne nécessite réellement de traiter des documents extrêmement longs en une seule fois (comme l'analyse d'une base de code complète ou la revue de grands textes juridiques), il n'est pas recommandé de dépasser 272K – car le prix double tandis que la précision diminue, ce qui réduit considérablement le rapport qualité-prix.
Techniques d'optimisation du contexte GPT-5.4
| Technique | Explication | Économie réalisée |
|---|---|---|
| Utilisez bien le cache d'entrée | Mettez en cache les invites système répétitives, seulement $0.25/M | Économise 90% du coût d'entrée |
| Tool Search | Chargez les définitions d'outils à la demande, ne les insérez pas toutes en une fois | Économise 47% de Tokens |
| Traitement par segments | Traitez les documents très longs par segments, en limitant chaque segment à 272K tokens | Évite le doublement du prix |
| Résumé et compression | Extrayez d'abord un résumé avec un modèle peu coûteux, puis analysez en profondeur avec GPT-5.4 | Réduit considérablement la quantité d'entrée |
Détails des avantages de l'intégration GPT-5.4 via APIYI
APIYI (apiyi.com) a déjà déployé GPT-5.4, avec une tarification identique à celle de l'officiel. Voici les avantages clés d'APIYI par rapport à une connexion directe à OpenAI :
Comparatif APIYI vs Connexion directe à OpenAI
| Dimension de comparaison | OpenAI officiel | APIYI apiyi.com |
|---|---|---|
| Barrière à l'inscription | Nécessite une carte de crédit américaine | ❌ Non requis, utilisation immédiate après inscription |
| Recharge minimale | Nécessite un moyen de paiement à l'étranger | ✅ Minimum 35 yuans (environ 5 $) |
| Limite de concurrence | Limitation de débit selon le niveau Tier (RPM/TPM) | ✅ Concurrence illimitée |
| Batch API | ✅ Supporté (moitié prix) | ❌ Batch/Flex non supporté |
| Tarification Standard | $2.50 entrée / $15.00 sortie | Tarification identique |
| Remise réelle | Pas de promotion sur la recharge | ✅ Activités de recharge avec bonus, pouvant atteindre 20% de réduction |
| Difficulté de prise en main | Nécessite un VPN + paiement à l'étranger | ✅ Prêt à l'emploi, intégration en 5 minutes |
À quels utilisateurs convient APIYI GPT-5.4 ?
Utilisateurs souhaitant essayer : Pour seulement 35 yuans minimum, vous pouvez commencer à expérimenter toutes les capacités de GPT-5.4 (y compris Computer Use), sans prépaiement important.
Utilisateurs à long terme : Grâce aux activités de recharge avec bonus, les recharges importantes offrent un crédit supplémentaire, réduisant le coût réel d'utilisation jusqu'à 20%. Si votre consommation mensuelle est stable à un certain niveau, cet avantage s'accumule de manière significative avec le temps.
Développeurs en Chine : Pas besoin de carte de crédit américaine, pas besoin de VPN, pas besoin de configuration de paiement à l'étranger complexe. Inscrivez-vous sur APIYI apiyi.com → rechargez → obtenez votre clé API → modifiez une ligne de base_url pour effectuer l'appel.
Scénarios à haute concurrence : OpenAI officiel limite les RPM et TPM selon le niveau Tier (Tier 1 environ 1000 RPM), tandis qu'APIYI n'impose aucune limite de concurrence, ce qui convient aux environnements de production nécessitant un grand nombre d'appels simultanés.
Remarque : APIYI ne supporte actuellement pas le Batch API d'OpenAI ni le mode de traitement Flex. Si votre flux de travail dépend de la capacité de traitement par lots à moitié prix, évaluez si cela vous convient. Pour les interactions en temps réel et les appels API standard, APIYI est un choix plus pratique.
Démarrage rapide avec le contexte GPT-5.4
Exemple minimaliste
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://vip.apiyi.com/v1"
)
# Appel dans la plage standard (≤272K, tarif standard)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": "Vous êtes un expert en revue de code"},
{"role": "user", "content": "Veuillez analyser le code suivant..."}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Voir l’exemple d’utilisation de contexte long et l’estimation des coûts
from openai import OpenAI
import tiktoken
client = OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://vip.apiyi.com/v1"
)
def estimate_cost(input_tokens, output_tokens):
"""Estime le coût d'un appel à GPT-5.4"""
if input_tokens <= 272000:
input_cost = (input_tokens / 1_000_000) * 2.50
output_cost = (output_tokens / 1_000_000) * 15.00
else:
input_cost = (input_tokens / 1_000_000) * 5.00 # Doublé
output_cost = (output_tokens / 1_000_000) * 22.50 # 1.5x
return input_cost + output_cost
# Exemple : analyser un gros fichier
with open("large_codebase.txt", "r") as f:
code_content = f.read()
# Estimer le nombre de tokens
enc = tiktoken.encoding_for_model("gpt-4o")
token_count = len(enc.encode(code_content))
print(f"Nombre de tokens en entrée : {token_count}")
if token_count > 272000:
print(f"⚠️ Dépassement du seuil de 272K, le prix va doubler !")
print(f"Suggestion : envisagez un traitement par segments ou une compression par résumé")
estimated = estimate_cost(token_count, 4000)
print(f"Coût estimé : ${estimated:.4f}")
# Appel réel
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": f"Analysez les vulnérabilités de sécurité dans le code suivant :\n{code_content}"}
],
max_tokens=8000
)
print(response.choices[0].message.content)
Conseil : Accédez à GPT-5.4 via APIYI (apiyi.com). Les tarifs sont alignés sur ceux de l'éditeur, et les activités de recharge avec bonus peuvent offrir une réduction de 20 %. Rechargez à partir de 35 CNY, utilisez-le dès l'inscription, sans besoin de carte de crédit américaine.
Estimation des coûts par scénario pour le contexte GPT-5.4
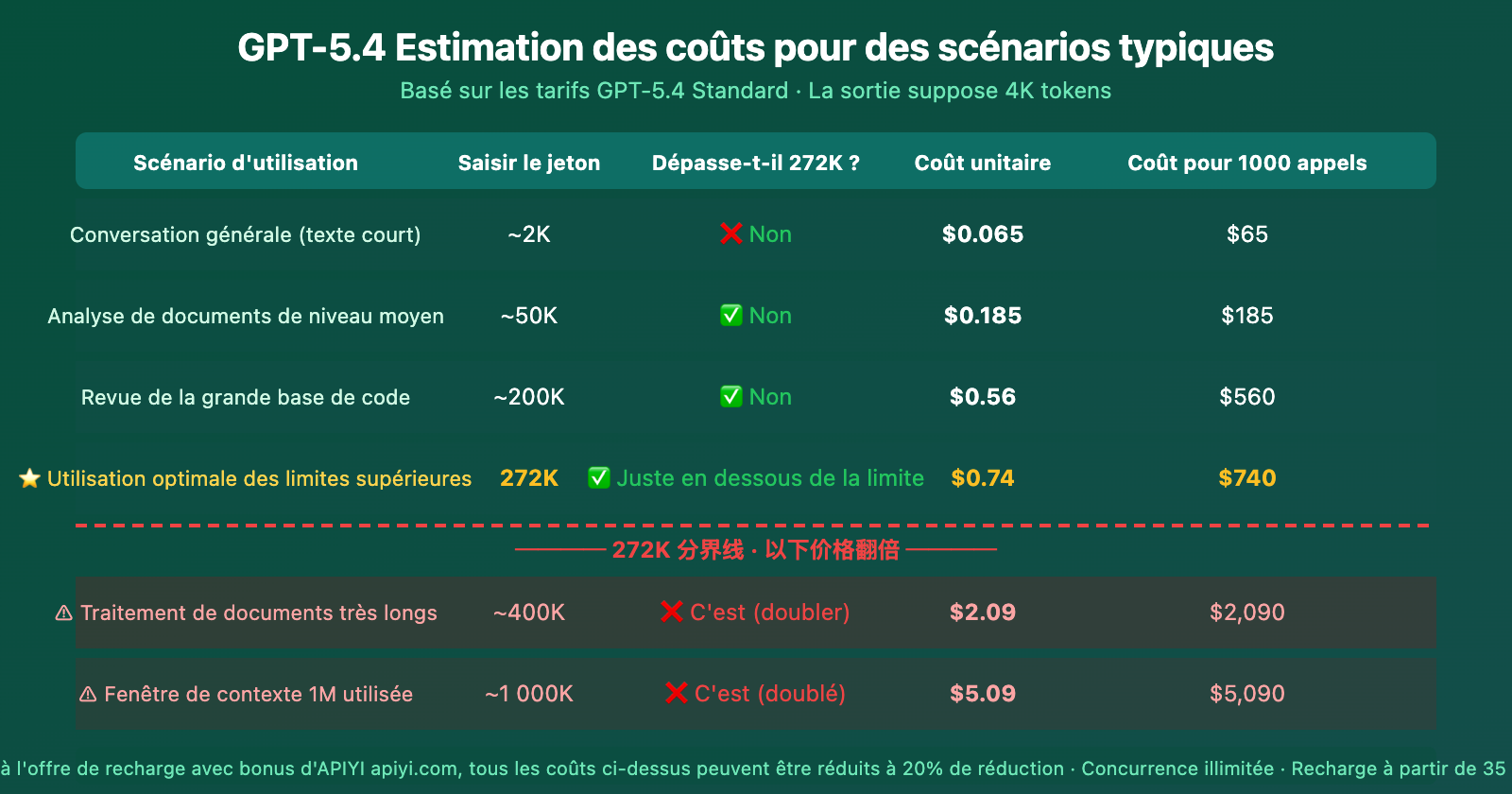
L'estimation des coûts montre clairement que 272K représente une véritable falaise de coûts. Pour la même augmentation de 128K en entrée (de 272K à 400K), le coût par appel passe de 0,74 $ à 2,09 $ — une augmentation de près de 3 fois.
Questions fréquentes
Q1 : Avec GPT-5.4, le tarif supérieur au-delà de 272K s’applique-t-il uniquement à la partie dépassée ou à la totalité ?
C'est la totalité. Dès que vos tokens d'entrée dépassent le seuil de 272K, tous les tokens de la session entière sont facturés au tarif étendu (entrée à 5,00 $/M, sortie à 22,50 $/M), et pas seulement la partie dépassée. Il est donc crucial de rester sous les 272K pour économiser.
Q2 : APIYI ne supporte pas l’API Batch, est-ce que cela devient trop cher ?
Il est vrai qu'APIYI ne supporte pas les modes de traitement Batch et Flex d'OpenAI (qui sont facturés à moitié prix). Cependant, les avantages d'APIYI sont : pas besoin de carte bancaire américaine, recharge à partir de 35 yuans, concurrence illimitée, prêt à l'emploi. De plus, grâce aux activités de recharges avec bonus, vous pouvez obtenir une réduction effective de 20%, ce qui, dans des scénarios d'invocation standard, se rapproche déjà du niveau de remise de Batch. Si votre flux de travail est basé sur des interactions en temps réel plutôt que sur du traitement par lots, APIYI est plus pratique.
Q3 : Comment estimer rapidement si ma tâche va dépasser 272K tokens ?
Estimation simple : 1 mot anglais ≈ 1,3 token, 1 caractère chinois ≈ 2-3 tokens. 272K tokens correspondent à environ 200 000 mots anglais ou 90 000 à 130 000 caractères chinois. Si votre entrée, combinée à l'invite système et à l'historique de conversation, ne dépasse pas ce volume, vous pourrez bénéficier du tarif standard en toute sécurité. Il est recommandé d'ajouter une vérification du comptage de tokens dans votre code pour une alerte précoce. Cette logique de calcul s'applique également lors de l'invocation via APIYI sur apiyi.com.
Résumé
Points clés de la tarification du contexte pour GPT-5.4 :
- 272K est le seuil critique : Au-delà de 272K tokens, le prix d'entrée double (2,50 $ → 5,00 $) et celui de sortie augmente de 50% (15,00 $ → 22,50 $), et ce tarif s'applique à la totalité des tokens.
- La plage 127K-272K est optimale : La précision reste stable à environ 97%, tout en restant dans la fourchette de tarification standard, offrant le meilleur rapport qualité-prix.
- La précision diminue au-delà de 256K : Dans la plage 512K-1M, la précision peut chuter à environ 36%, à utiliser avec prudence.
- Plus cher que GPT-5.2 mais plus efficace : Dans la plage standard, l'entrée est 43% plus chère et la sortie 7% plus chère, mais il consomme moins de tokens pour le raisonnement.
Stratégies d'économie : Contrôlez l'entrée sous 272K, utilisez judicieusement la mise en cache d'entrée (économise 90%), et exploitez la recherche d'outils (économise 47%). En passant par APIYI sur apiyi.com, la tarification est synchronisée avec l'officielle, et les activités de recharges avec bonus peuvent offrir une réduction de 20%. Recharge minimale à partir de 35 yuans, pas besoin de carte bancaire américaine, concurrence illimitée, utilisation immédiate après inscription — particulièrement adapté pour des tests d'expérience et une utilisation à long terme.
📚 Références
-
Page de tarification de l'API OpenAI : Tarifs complets de GPT-5.4 et explication de la facturation par niveau de contexte
- Lien :
developers.openai.com/api/docs/pricing - Description : Source officielle et faisant autorité pour les tarifs, incluant les prix pour tous les modes (Standard/Batch/Flex/Priority)
- Lien :
-
Documentation du modèle OpenAI GPT-5.4 : Spécifications techniques de la fenêtre de contexte, des limites de sortie, etc.
- Lien :
developers.openai.com/api/docs/models/gpt-5.4 - Description : Documentation officielle des spécifications du modèle
- Lien :
-
Annonce de lancement d'OpenAI GPT-5.4 : Capacités principales et données de tests de référence
- Lien :
openai.com/index/introducing-gpt-5-4/ - Description : Inclut les performances de référence, la philosophie de conception et l'explication de la stratégie tarifaire
- Lien :
-
Discussion de la communauté des développeurs OpenAI : Explication détaillée des tarifs, des limites de contexte et de Tool Search pour GPT-5.4
- Lien :
community.openai.com/t/gpt-5-4-deep-dive-pricing-context-limits-and-tool-search-explained/ - Description : Discussion approfondie des développeurs sur la structure tarifaire et les performances liées au contexte
- Lien :
Auteur : Équipe technique d'APIYI
Échanges techniques : N'hésitez pas à discuter de vos expériences d'utilisation du contexte GPT-5.4 et de vos astuces d'optimisation des coûts dans les commentaires. Pour plus de ressources, visitez le centre de documentation d'APIYI à docs.apiyi.com.