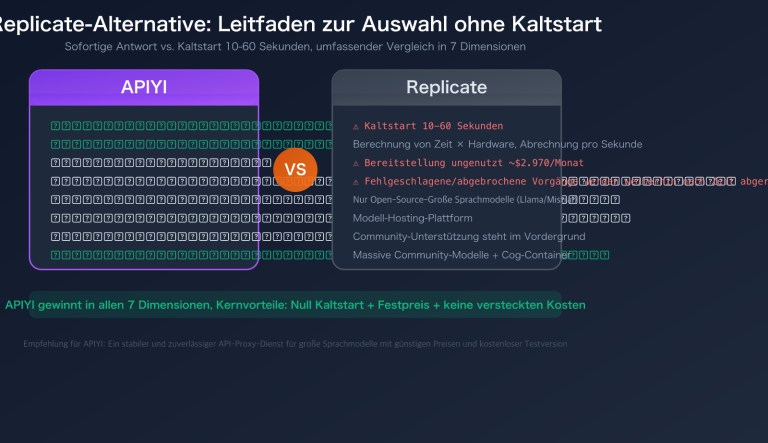
Autorenhinweis: Tiefgehende Analyse des 1M-Kontextfensters von GPT-5.4, des 272K-Token-Preissprungs, des optimalen Leistungsbereichs von 127K-272K, vollständiger Preisvergleich und Sparstrategien
GPT-5.4 wirbt mit einem ultralangen Kontext von 1,05 Millionen Token, aber viele Entwickler wissen nicht: Ab 272K Token verdoppelt sich der Preis und die Genauigkeit nimmt ab. Dies ist keine einfache "je größer, desto besser"-Geschichte.
Kernaussage: Dieser Artikel analysiert detailliert die Leistungskurve des GPT-5.4-Kontexts, den Mechanismus des 272K-Preissprungs und wie Sie GPT-5.4 mit den niedrigsten Kosten über APIYI effizient nutzen können.

GPT-5.4 Kontextpreise: Die Kernpunkte
| Punkt | Erklärung | Praktische Auswirkung |
|---|---|---|
| Gesamtkontext | 1.050.000 Tokens (1,05 Millionen) | Theoretisch können extrem lange Dokumente verarbeitet werden |
| 272K Grenzwert | Darüber verdoppelt sich der Eingabepreis ($2,50→$5,00) | Kosten halbieren, indem man unter 272K bleibt |
| Optimaler Leistungsbereich | 127K-272K Tokens | Genauigkeit ~97%, beste Preis-Leistung |
| Leistungsabfallbereich | Ab 256K Tokens beginnt die Genauigkeit zu sinken | Im Bereich 512K-1M kann die Genauigkeit auf ~36% fallen |
| Vergleich mit GPT-5.2 | Eingabe 43% teurer, Ausgabe 7% teurer | Verbraucht aber weniger Tokens für Schlussfolgerungen, daher ist der reale Unterschied geringer |
Die entscheidende Erkenntnis zu GPT-5.4 Kontext: Unterstützung heißt nicht optimale Nutzung
Dies ist sehr wichtig: Nur weil GPT-5.4 einen Kontext von 1,05 Millionen Tokens unterstützt, heißt das nicht, dass man ihn vollstopfen sollte. Den öffentlichen Evaluierungsdaten von OpenAI zufolge:
- 16K-32K Tokens: Needle-in-a-Haystack Abrufgenauigkeit ~97%
- 127K-272K Tokens: Genauigkeit bleibt stabil hoch und ist der Standardpreisbereich
- Ab 256K Tokens: Genauigkeit beginnt zu sinken
- 512K-1M Tokens: Genauigkeit kann auf etwa 36% einbrechen
GPT-5.2 erreichte zuvor in 4-Needle MRCR-Tests im Bereich von 256K Tokens eine Genauigkeit nahe 100%, was bestätigt, dass 256K ein kritischer Punkt für Leistungszuverlässigkeit ist.
Praktischer Tipp: Für die meisten Anwendungsfälle ist es die klügste Strategie, die Eingabe unter 272K zu halten – das gewährleistet Genauigkeit und vermeidet Preisverdopplung. Wenn Sie GPT-5.4 über APIYI (apiyi.com) nutzen, gelten die offiziellen Preise, und durch Teilnahme an der Aufladeaktion können Sie bis zu 20% sparen.
Vollständige Aufschlüsselung der GPT-5.4 Kontextpreise
GPT-5.4 Standard-Edition Preise (pro Million Tokens)
Hier ist das vollständige gestaffelte Preissystem für GPT-5.4:
| Verarbeitungsmodus | Eingabe (≤272K) | Eingabe (>272K) | Cache-Eingabe (≤272K) | Cache-Eingabe (>272K) | Ausgabe (≤272K) | Ausgabe (>272K) |
|---|---|---|---|---|---|---|
| Standard | $2,50 | $5,00 | $0,25 | $0,50 | $15,00 | $22,50 |
| Batch | $1,25 | $2,50 | $0,13 | $0,26 | $7,50 | $11,25 |
| Flex | $1,25 | $2,50 | $0,13 | $0,26 | $7,50 | $11,25 |
| Priority | $5,00 | — | $0,50 | — | $30,00 | — |
Drei wichtige Details zu den GPT-5.4 Kontextpreisen
Erstens: Über 272K bedeutet pauschale Preissteigerung. Wenn Ihre Eingabe 272K Tokens überschreitet, gilt der Aufpreismechanismus für die gesamte Sitzung, nicht nur für den überschüssigen Teil. Das bedeutet: Sobald die Grenze überschritten ist, werden alle Tokens zum doppelten Preis berechnet.
Zweitens: Auch die Ausgabepreise steigen. Nicht nur die Eingabe wird teurer, sondern auch der Ausgabepreis steigt von $15,00 auf $22,50 (plus 50%) bei über 272K. Das hat große Auswirkungen auf ausgabelastige Aufgaben (z.B. Code-Generierung, langes Schreiben).
Drittens: Cache-Eingabe ist ein Kostensparer. Die Cache-Eingabe im Standardbereich kostet nur $0,25/M Tokens – ein Zehntel des Originalpreises. Wenn Ihre Aufgabe wiederholte System-Eingabeaufforderungen oder festen Kontext beinhaltet, kann die geschickte Nutzung des Caches die Kosten erheblich senken.
GPT-5.4 vs. GPT-5.2 Preisvergleichsanalyse
Die Frage, die viele Entwickler am meisten beschäftigt: Wie viel teurer wird der Wechsel von GPT-5.2 zu GPT-5.4?

Kernunterschiede in der Preisgestaltung: GPT-5.4 vs. GPT-5.2
| Preisposition | GPT-5.2 | GPT-5.4 Standard | GPT-5.4 Extended | Standard-Anstieg |
|---|---|---|---|---|
| Eingabe | $1,75/M | $2,50/M | $5,00/M | +43% |
| Cache-Eingabe | $0,175/M | $0,25/M | $0,50/M | +43% |
| Ausgabe | $14,00/M | $15,00/M | $22,50/M | +7% |
| Pro-Eingabe | $21,00/M | $30,00/M | $60,00/M | +43% |
| Pro-Ausgabe | $168,00/M | $180,00/M | $270,00/M | +7% |
GPT-5.4 ist teurer, aber die tatsächliche Kostenlücke ist gering
OpenAI bezeichnet GPT-5.4 offiziell als das "effizienteste Inferenzmodell" – es löst dieselben Probleme mit weniger Inferenz-Tokens. Das bedeutet: Obwohl der Stückpreis steigt, könnte die Gesamtzahl der pro Aufruf verbrauchten Tokens geringer sein.
Allerdings ist zu beachten: Die Antwortlänge von GPT-5.4 ist im Durchschnitt etwa 24% länger als bei GPT-5.2, was einen Teil des Effizienzgewinns wieder zunichtemachen kann.
Best Practices für die Kontextnutzung mit GPT-5.4
Drei goldene Regeln
Regel 1: Möglichst unter 272K halten. Das ist der Bereich mit dem besten Preis-Leistungs-Verhältnis – hohe Genauigkeit bei niedrigem Preis. Für die allermeisten Anwendungsfälle reichen 272K Tokens für mehrfache Dialogrunden, lange Dokumentenanalysen oder die Prüfung großer Codebasen aus.
Regel 2: 127K–272K ist die optimale Zone. In diesem Bereich bleibt die Abrufgenauigkeit des Modells stabil bei etwa 97%, während gleichzeitig der Vorteil des langen Kontextfensters von GPT-5.4 voll ausgenutzt wird. Das ist doppelt so groß wie das Standardfenster von GPT-5.2 (128K) und reicht aus, um die meisten "vorher nicht passenden" Aufgaben zu bewältigen.
Regel 3: Über 272K muss gut überlegt sein. Es sei denn, Ihre Aufgabe erfordert wirklich die einmalige Verarbeitung eines extrem langen Dokuments (z.B. Analyse einer kompletten Codebase, Prüfung eines großen Rechtstextes), wird ein Überschreiten von 272K nicht empfohlen – denn bei einer Verdopplung des Preises sinkt auch die Genauigkeit, das Preis-Leistungs-Verhältnis verschlechtert sich drastisch.
Optimierungstechniken für den GPT-5.4-Kontext
| Technik | Erklärung | Einsparung |
|---|---|---|
| Cache-Eingabe nutzen | Wiederholte System-Eingabeaufforderungen aus dem Cache verwenden, nur $0,25/M | Spart 90% der Eingabekosten |
| Tool Search | Tool-Definitionen nach Bedarf laden, nicht alle auf einmal einfügen | Spart 47% Tokens |
| Segmentierte Verarbeitung | Sehr lange Dokumente in Abschnitte aufteilen, jeder unter 272K | Vermeidet verdoppelte Preise |
| Zusammenfassung/Kompression | Zuerst mit einem günstigen Modell eine Zusammenfassung extrahieren, dann mit GPT-5.4 tiefgehend analysieren | Reduziert die Eingabemenge erheblich |
APIYI GPT-5.4: Vorteile der Integration im Detail
APIYI (apiyi.com) bietet nun auch GPT-5.4 an, mit identischer Preisgestaltung wie der offizielle Anbieter. Hier sind die Kernvorteile von APIYI im Vergleich zur direkten Verbindung zu OpenAI:
APIYI vs. OpenAI Direktverbindung im Vergleich
| Vergleichsdimension | OpenAI Direkt | APIYI apiyi.com |
|---|---|---|
| Registrierungshürde | US-Kreditkarte erforderlich | ❌ Nicht nötig, sofort nach Registrierung nutzbar |
| Mindestaufladung | Ausländische Zahlungsmethoden nötig | ✅ Ab 35 CNY (ca. 5 USD) aufladbar |
| Nebenläufigkeitslimit | Geschwindigkeitsbegrenzung nach Tier-Level (RPM/TPM) | ✅ Keine Begrenzung der Nebenläufigkeit |
| Batch-API | ✅ Unterstützt (zum halben Preis) | ❌ Batch/Flex nicht unterstützt |
| Standard-Preise | $2.50 Input / $15.00 Output | Identische Preise |
| Tatsächlicher Rabatt | Keine Aufladeaktionen | ✅ Aufladeaktionen, bis zu 20% Rabatt möglich |
| Einstiegshürde | VPN + Auslandzahlung nötig | ✅ Sofort einsatzbereit, Integration in 5 Minuten |
Für wen ist APIYI GPT-5.4 geeignet?
Neugierige Nutzer: Bereits ab 35 CNY können Sie die gesamte Leistungsfähigkeit von GPT-5.4 (inklusive Computer Use) testen, ohne hohe Vorauszahlungen.
Langfristige Nutzer: Durch Aufladeaktionen erhalten Sie bei größeren Beträgen zusätzliches Guthaben. Die tatsächlichen Nutzungskosten können so auf bis zu 80% reduziert werden. Bei stabilen monatlichen Verbräuchen summiert sich dieser Vorteil erheblich.
Entwickler in China: Keine US-Kreditkarte, kein VPN und keine komplizierten Auslandzahlungen nötig. Einfach ein Konto auf APIYI apiyi.com registrieren → Guthaben aufladen → API-Schlüssel erhalten → base_url in einer Zeile ändern und loslegen.
Hochparallele Szenarien: OpenAI begrenzt offiziell RPM und TPM nach Tier-Level (Tier 1 ca. 1000 RPM). APIYI setzt keine Grenzen für Nebenläufigkeit und ist damit ideal für Produktionsumgebungen mit vielen parallelen Aufrufen.
Hinweis: APIYI unterstützt derzeit nicht die Batch-API und den Flex-Verarbeitungsmodus von OpenAI. Wenn Ihr Workflow auf die halbpreisige Stapelverarbeitung angewiesen ist, sollten Sie die Eignung prüfen. Für Echtzeit-Interaktionen und Standard-API-Aufrufe ist APIYI die bequemere Wahl.
GPT-5.4: Schnelleinstieg ins Kontextfenster
Minimalbeispiel
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Standardbereich-Aufruf (≤272K, Standardpreis)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": "Du bist ein Experte für Code-Reviews"},
{"role": "user", "content": "Analysiere bitte den folgenden Code..."}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Beispiel für lange Kontexte und Kostenschätzung anzeigen
from openai import OpenAI
import tiktoken
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def estimate_cost(input_tokens, output_tokens):
"""Kosten für einen GPT-5.4-Aufruf schätzen"""
if input_tokens <= 272000:
input_cost = (input_tokens / 1_000_000) * 2.50
output_cost = (output_tokens / 1_000_000) * 15.00
else:
input_cost = (input_tokens / 1_000_000) * 5.00 # Verdoppelt
output_cost = (output_tokens / 1_000_000) * 22.50 # 1.5x
return input_cost + output_cost
# Beispiel: Analyse einer großen Datei
with open("large_codebase.txt", "r") as f:
code_content = f.read()
# Anzahl der Tokens schätzen
enc = tiktoken.encoding_for_model("gpt-4o")
token_count = len(enc.encode(code_content))
print(f"Eingabe-Tokens: {token_count}")
if token_count > 272000:
print(f"⚠️ Über der 272K-Grenze, Preis verdoppelt sich!")
print(f"Empfehlung: Segmentierte Verarbeitung oder komprimierte Zusammenfassung in Betracht ziehen")
estimated = estimate_cost(token_count, 4000)
print(f"Geschätzte Kosten: ${estimated:.4f}")
# Tatsächlicher Aufruf
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": f"Analysiere folgende Codebasis auf Sicherheitslücken:\n{code_content}"}
],
max_tokens=8000
)
print(response.choices[0].message.content)
Empfehlung: Greifen Sie über APIYI apiyi.com auf GPT-5.4 zu. Die Preise sind identisch mit den offiziellen, und durch Aufladeaktionen sind bis zu 20% Rabatt möglich. Mindestaufladung ab 35 CNY, sofort nach Registrierung nutzbar, keine US-Kreditkarte erforderlich.
GPT-5.4: Szenariobasierte Kostenschätzung für das Kontextfenster
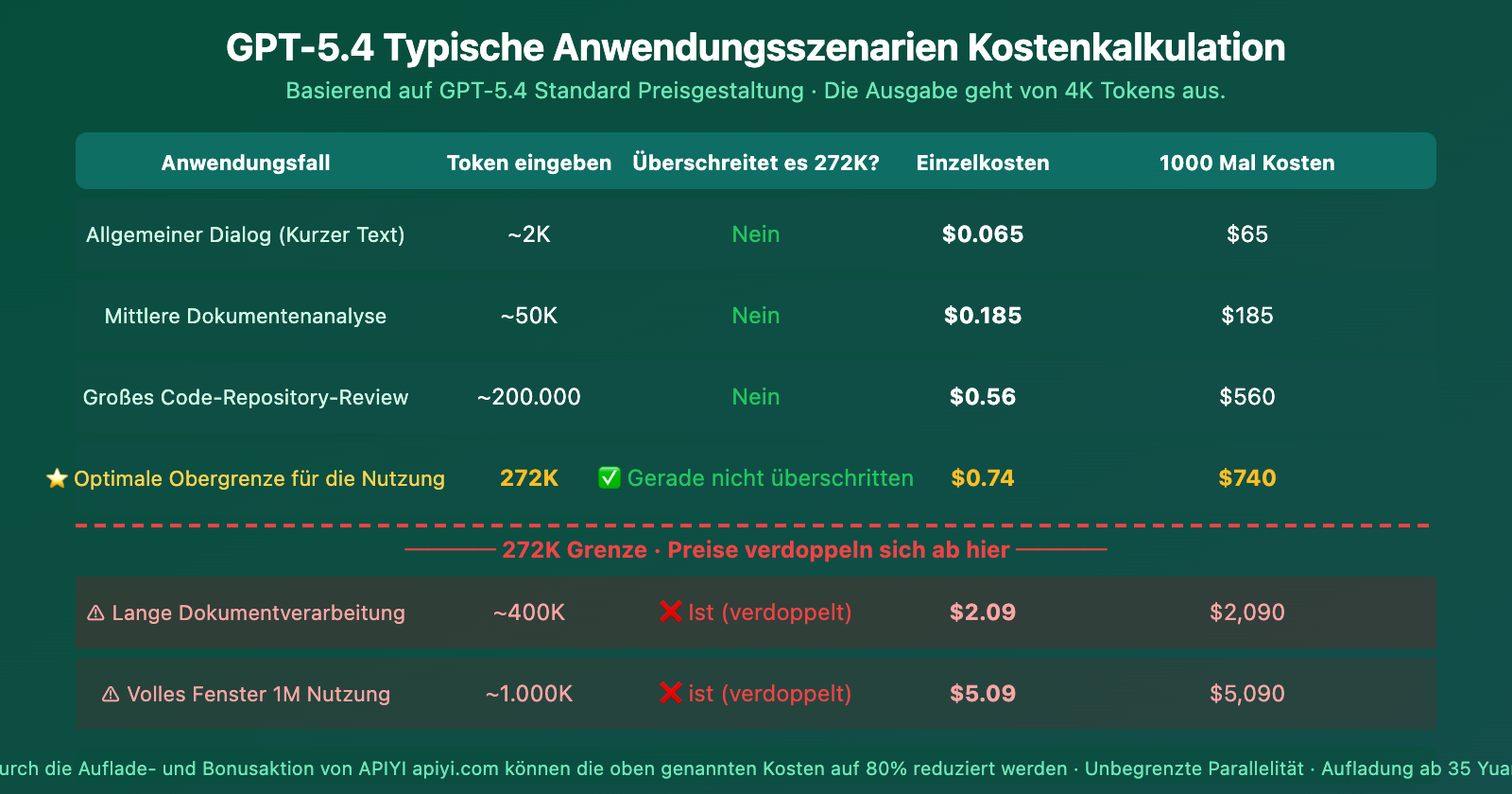
Die Kostenschätzung zeigt deutlich: 272K ist eine harte Kostenklippe. Bei nur 128K mehr Eingabe (von 272K auf 400K) steigen die Kosten pro Anfrage von $0,74 auf $2,09 – fast eine Verdreifachung.
Häufig gestellte Fragen
F1: Werden bei GPT-5.4 nach Überschreiten von 272K nur die überschüssigen Tokens teurer berechnet oder alle?
Alle. Sobald Ihre Eingabe-Tokens den Schwellenwert von 272K überschreiten, werden alle Tokens der gesamten Sitzung zum erweiterten Tarif berechnet (Eingabe $5,00/M, Ausgabe $22,50/M), nicht nur die überschüssigen. Daher ist es entscheidend für die Kostenkontrolle, unter 272K zu bleiben.
F2: APIYI unterstützt keine Batch-API. Ist das nicht zu teuer?
APIYI unterstützt tatsächlich nicht die Batch- und Flex-Verarbeitungsmodi von OpenAI (diese sind etwa halb so teuer wie der Standardtarif). Der Vorteil von APIYI liegt jedoch anderswo: Keine US-Kreditkarte nötig, Aufladung ab 35 Yuan, keine Beschränkung der Parallelanfragen, sofort einsatzbereit. Durch Aktionen mit Aufladungsbonus erreicht man effektiv einen Rabatt von etwa 20 %, was in Standardszenarien bereits nahe an den Batch-Rabatten liegt. Wenn Ihr Workflow auf Echtzeit-Interaktion statt Batch-Verarbeitung ausgelegt ist, ist APIYI die bequemere Wahl.
F3: Wie kann ich schnell abschätzen, ob meine Aufgabe 272K überschreiten wird?
Einfache Faustregel: 1 englisches Wort ≈ 1,3 Tokens, 1 chinesisches Zeichen ≈ 2-3 Tokens. 272K Tokens entsprechen etwa 200.000 englischen Wörtern oder 90.000-130.000 chinesischen Zeichen. Wenn Ihre Eingabe plus System-Eingabeaufforderung und Verlauf diese Menge nicht übersteigt, bleiben Sie sicher im Standardtarif. Es wird empfohlen, in Ihren Code eine Token-Zählprüfung einzubauen, um frühzeitig gewarnt zu werden. Diese Logik gilt auch für Modellaufrufe über APIYI (apiyi.com).
Zusammenfassung
Die Kernpunkte der GPT-5.4-Kontextpreisgestaltung:
- 272K ist die kritische Grenze: Bei über 272K Token verdoppelt sich der Eingabepreis ($2,50→$5,00), der Ausgabepreis steigt um 50% ($15,00→$22,50) und gilt für alle Token.
- 127K-272K ist das optimale Intervall: Die Genauigkeit bleibt stabil bei etwa 97%, liegt im Standardpreisbereich und bietet das beste Preis-Leistungs-Verhältnis.
- Über 256K nimmt die Genauigkeit ab: Im Bereich von 512K-1M kann die Genauigkeit auf etwa 36% sinken – verwenden Sie diesen Bereich mit Vorsicht.
- Teurer als GPT-5.2, aber effizienter: Im Standardbereich ist die Eingabe 43% teurer, die Ausgabe 7% teurer, aber es werden weniger Inferenz-Token benötigt.
Kosteneinsparungsstrategie: Halten Sie die Eingabe unter 272K, nutzen Sie Cached Input (spart 90%) und Tool Search (spart 47%). Über APIYI apiyi.com erhalten Sie Zugang mit offiziell synchronisierten Preisen. Mit den Aufladeaktionen sind Rabatte von bis zu 20% möglich. Mindestaufladung ab 35 CNY, keine US-Kreditkarte erforderlich, keine Beschränkung der Parallelität, sofort nach der Registrierung nutzbar – ideal zum Ausprobieren und für den langfristigen Einsatz.
📚 Referenzen
-
OpenAI API-Preisseite: Vollständige Preisgestaltung für GPT-5.4 und Erläuterung zur kontextbasierten Staffelpreisberechnung
- Link:
developers.openai.com/api/docs/pricing - Beschreibung: Offizielle, autoritative Preisquelle, enthält Preise für alle Modi (Standard/Batch/Flex/Priority)
- Link:
-
OpenAI GPT-5.4 Modelldokumentation: Technische Spezifikationen wie Kontextfenster, Ausgabelimits
- Link:
developers.openai.com/api/docs/models/gpt-5.4 - Beschreibung: Offizielle Modellspezifikationsdokumentation
- Link:
-
OpenAI GPT-5.4 Veröffentlichungsankündigung: Kernfähigkeiten und Benchmark-Daten
- Link:
openai.com/index/introducing-gpt-5-4/ - Beschreibung: Enthält Leistungsbenchmarks, Designphilosophie und Erläuterungen zur Preisstrategie
- Link:
-
OpenAI-Entwickler-Community-Diskussion: Detaillierte Erläuterungen zu GPT-5.4-Preisen, Kontextlimits und Tool Search
- Link:
community.openai.com/t/gpt-5-4-deep-dive-pricing-context-limits-and-tool-search-explained/ - Beschreibung: Tiefgehende Diskussion von Entwicklern zur Preisstruktur und Kontextleistung
- Link:
Autor: APIYI-Technologie-Team
Technischer Austausch: Diskutieren Sie gerne in den Kommentaren Ihre Erfahrungen mit dem GPT-5.4-Kontext und Kostenoptimierungstechniken. Weitere Materialien finden Sie im APIYI-Dokumentationscenter unter docs.apiyi.com.