title: "تحليل عميق لنافذة السياق 1M في GPT-5.4: نقطة التقسيم السعري عند 272K رمزًا، وأفضل نطاق أداء بين 127K-272K، مع مقارنة أسعار كاملة واستراتيجيات توفير"
description: "كشف تفاصيل أداء نافذة السياق في GPT-5.4، آلية تسعير 272K رمزًا، وكيفية استخدام APIYI للحصول على أفضل تكلفة."
date: 2024-11-22
tags: [GPT-5.4, APIYI, نافذة السياق, تسعير النماذج الكبيرة, استدعاء النموذج, خدمة وكيل API]
يدّعي GPT-5.4 دعمه لنافذة سياق طويلة جدًا تصل إلى 1,050,000 رمزًا، لكن ما لا يعرفه الكثير من المطورين هو: أن السعر يتضاعف مباشرة بعد تجاوز 272 ألف رمز، كما أن الدقة تبدأ في الانخفاض. هذه ليست قصة بسيطة من نوع "كلما كان أكبر كان أفضل".
القيمة الأساسية: يشرح هذا المقال بالتفصيل منحنى أداء سياق GPT-5.4، وآلية نقطة التقسيم السعري عند 272 ألف رمز، وكيفية استخدام APIYI لاستخدام GPT-5.4 بكفاءة وبأقل تكلفة.

النقاط الأساسية لتسعير سياق GPT-5.4
| النقطة | الشرح | التأثير العملي |
|---|---|---|
| إجمالي السياق | 1,050,000 رمز (1.05 مليون) | يمكنه نظريًا معالجة مستندات طويلة جدًا |
| نقطة التقسيم 272K | بعدها يتضاعف سعر الإدخال ($2.50→$5.00) | التحكم في أقل من 272K يوفر نصف تكلفة الإدخال |
| نطاق الأداء الأمثل | 127K-272K رمز | دقة تقريبًا 97%، أفضل نسبة سعر/أداء |
| منطقة انخفاض الأداء | فوق 256K رمز تبدأ الدقة في الانخفاض | في نطاق 512K-1M قد تنخفض الدقة إلى ~36% |
| مقارنة بـ GPT-5.2 | الإدخال أغلى بنسبة 43%، الإخراج أغلى بنسبة 7% | لكنه يستخدم رموز استدلال أقل، لذا يقل الفرق الفعلي |
الفهم الأساسي لسياق GPT-5.4: الدعم لا يعني الكفاءة
هذه النقطة مهمة جدًا: دعم GPT-5.4 لسياق 1.05 مليون رمز لا يعني أنه يجب عليك ملئه بالكامل. من بيانات التقييم المعلنة من OpenAI:
- 16K-32K رمز: دقة استرجاع "إبرة في كومة قش" حوالي 97%
- 127K-272K رمز: الدقة لا تزال مستقرة عند مستوى عالٍ، وهي نطاق التسعير القياسي
- فوق 256K رمز: تبدأ الدقة في الانخفاض
- 512K-1M رمز: قد تنخفض الدقة فجأة إلى حوالي 36%
في اختبارات MRCR ذات 4 إبر، حقق GPT-5.2 سابقًا دقة قريبة من 100% ضمن نطاق 256K رمز، مما يؤكد أن 256K هي نقطة محورية لموثوقية الأداء.
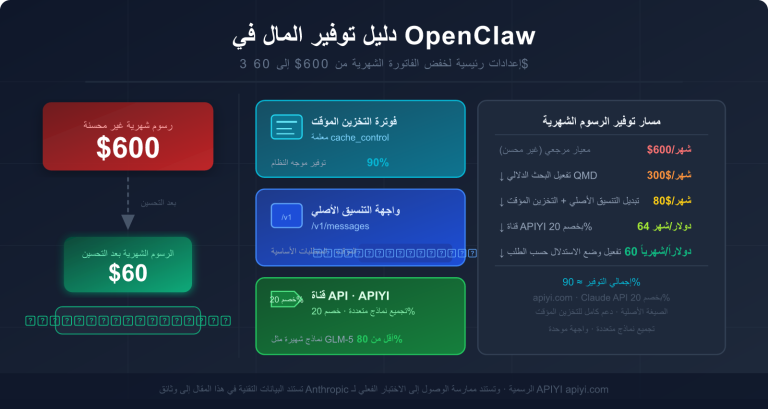
نصيحة عملية: بالنسبة لمعظم حالات الاستخدام، فإن التحكم في الإدخال ضمن 272K هو الاستراتيجية الأكثر حكمة – فهي تضمن الدقة وتجنب تضاعف السعر. من خلال الوصول إلى GPT-5.4 عبر APIYI apiyi.com، يكون التسعير متزامنًا مع الرسمي، والمشاركة في أنشطة إعادة الشحن مع المكافآت يمكن أن تصل إلى خصم 20%.
تحليل مفصل لتسعير سياق GPT-5.4
تسعير الإصدار القياسي لـ GPT-5.4 (لكل مليون رمز)
إليك نظام التسعير المتدرج الكامل لـ GPT-5.4:
| نمط المعالجة | الإدخال (≤272K) | الإدخال (>272K) | إدخال الذاكرة المؤقتة (≤272K) | إدخال الذاكرة المؤقتة (>272K) | الإخراج (≤272K) | الإخراج (>272K) |
|---|---|---|---|---|---|---|
| Standard | $2.50 | $5.00 | $0.25 | $0.50 | $15.00 | $22.50 |
| Batch | $1.25 | $2.50 | $0.13 | $0.26 | $7.50 | $11.25 |
| Flex | $1.25 | $2.50 | $0.13 | $0.26 | $7.50 | $11.25 |
| Priority | $5.00 | — | $0.50 | — | $30.00 | — |
ثلاث تفاصيل رئيسية في تسعير سياق GPT-5.4
أولاً، التسعير فوق 272K ينطبق على الكمية بأكملها. عندما يتجاوز إدخالك 272K رمز، تنطبق آلية الزيادة على الجلسة بأكملها، وليس فقط على الجزء المتجاوز. هذا يعني أنه بمجرد تجاوز الحد، يتم حساب جميع الرموز بسعر مضاعف.
ثانيًا، سعر الإخراج يرتفع أيضًا. ليس فقط الإدخال يتضاعف، بل يرتفع سعر الإخراج أيضًا من $15.00 إلى $22.50 بعد تجاوز 272K، بزيادة 50%. هذا له تأثير كبير على المهام المكثفة في الإخراج (مثل توليد الكود، كتابة النصوص الطويلة).
ثالثًا، إدخال الذاكرة المؤقتة هو أداة لتوفير التكلفة. إدخال الذاكرة المؤقتة في النطاق القياسي يكلف فقط $0.25 لكل مليون رمز، أي عُشر السعر الأصلي. إذا كانت مهمتك تتضمن موجهات نظام متكررة أو سياقًا ثابتًا، فإن الاستخدام الجيد للذاكرة المؤقتة يمكن أن يخفض التكلفة بشكل كبير.
تحليل مقارنة التسعير بين GPT-5.4 و GPT-5.2
السؤال الأكثر شيوعًا بين المطورين: كم ستكلفني عملية الانتقال من GPT-5.2 إلى GPT-5.4؟

الاختلافات الأساسية في التسعير بين GPT-5.4 و GPT-5.2
| عنصر التسعير | GPT-5.2 | GPT-5.4 القياسي | GPT-5.4 الموسع | نسبة الزيادة القياسية |
|---|---|---|---|---|
| الإدخال | 1.75 دولار/مليون | 2.50 دولار/مليون | 5.00 دولار/مليون | +43% |
| الإدخال المخزن مؤقتًا | 0.175 دولار/مليون | 0.25 دولار/مليون | 0.50 دولار/مليون | +43% |
| الإخراج | 14.00 دولار/مليون | 15.00 دولار/مليون | 22.50 دولار/مليون | +7% |
| إدخال Pro | 21.00 دولار/مليون | 30.00 دولار/مليون | 60.00 دولار/مليون | +43% |
| إخراج Pro | 168.00 دولار/مليون | 180.00 دولار/مليون | 270.00 دولار/مليون | +7% |
تسعير GPT-5.4 أغلى، لكن الفعلي في التكلفة ليس كبيرًا
أشارت OpenAI رسميًا إلى أن GPT-5.4 هو "أكثر نموذج كفاءة في الاستدلال" – فهو يحل المشكلات نفسها باستخدام عدد أقل من وحدات Token للاستدلال. هذا يعني أنه على الرغم من ارتفاع السعر لكل وحدة، فإن إجمالي وحدات Token المستهلكة في كل استدعاء قد يكون أقل.
ولكن يجب الانتباه: متوسط طول استجابة GPT-5.4 أطول بنحو 24% من GPT-5.2، مما يلغي جزئيًا مكاسب كفاءة الاستدلال.
أفضل الممارسات لاستخدام سياق GPT-5.4
القواعد الذهبية الثلاث
القاعدة الأولى: حاول البقاء تحت 272 ألف وحدة. هذه هي النطاق الأمثل من حيث الجدوى الاقتصادية – دقة عالية وسعر منخفض. بالنسبة لمعظم سيناريوهات التطبيق، 272 ألف وحدة Token كافية لتغطية محادثات متعددة الجولات، وتحليل المستندات الطويلة، ومراجعة مستودعات التعليمات البرمجية الكبيرة.
القاعدة الثانية: النطاق 127 ألف – 272 ألف وحدة هو الأفضل. ضمن هذا النطاق، تظل دقة استرجاع النموذج مستقرة عند حوالي 97%، مع الاستفادة الكاملة من ميزة السياق الطويل في GPT-5.4. هذا النطاق أكبر بمرتين من نافذة السياق القياسية لـ GPT-5.2 البالغة 128 ألف وحدة، وهو كافٍ بالفعل للتعامل مع معظم المهام التي كانت "لا تتسع سابقًا".
القاعدة الثالثة: فكر مليًا قبل تجاوز 272 ألف وحدة. ما لم تكن مهمتك تتطلب بالفعل معالجة مستندات فائقة الطول دفعة واحدة (مثل تحليل مستودع تعليمات برمجية كامل، أو مراجعة نصوص قانونية كبيرة)، لا يُنصح بتجاوز 272 ألف وحدة – لأن السعر يتضاعف بينما تنخفض الدقة، مما يؤدي إلى انخفاض حاد في الجدوى الاقتصادية.
نصائح لتحسين استخدام سياق GPT-5.4
| النصيحة | الشرح | نسبة التوفير |
|---|---|---|
| الاستفادة من الإدخال المخزن مؤقتًا | استخدم التخزين المؤقت للتعليمات النظامية المتكررة، بسعر 0.25 دولار/مليون فقط | توفير 90% من تكلفة الإدخال |
| Tool Search | قم بتحميل تعريفات الأدوات حسب الحاجة، ولا تضعها جميعًا مرة واحدة | توفير 47% من وحدات Token |
| المعالجة المجزأة | قم بتقسيم المستندات الطويلة ومعالجة كل جزء تحت 272 ألف وحدة | تجنب تسعير التكلفة المضاعفة |
| الضغط والملخص | استخدم نموذجًا رخيصًا أولاً لاستخراج ملخص، ثم استخدم GPT-5.4 للتحليل العميق | تقليل كبير في حجم الإدخال |
شرح مزايا استخدام APIYI للوصول إلى GPT-5.4
أطلقت APIYI (apiyi.com) نموذج GPT-5.4، مع تسعير مطابق تمامًا للتسعير الرسمي. فيما يلي المزايا الأساسية لاستخدام APIYI مقارنة بالاتصال المباشر مع OpenAI الرسمي:
مقارنة بين APIYI والاتصال المباشر مع OpenAI الرسمي
| بُعد المقارنة | OpenAI الرسمي | APIYI apiyi.com |
|---|---|---|
| عتبة التسجيل | تتطلب بطاقة ائتمان أمريكية | ❌ غير مطلوبة، يمكنك البدء فور التسجيل |
| الحد الأدنى للشحن | يتطلب وسيلة دفع دولية | ✅ بداية من 35 يوان (حوالي 5 دولارات) |
| حدود التزامن | محدودة حسب مستوى المستخدم (RPM/TPM) | ✅ غير محدود |
| Batch API | ✅ مدعوم (بنصف السعر) | ❌ غير مدعوم |
| التسعير القياسي | 2.50 دولار للإدخال / 15.00 دولار للإخراج | نفس التسعير |
| الخصم الفعلي | لا توجد عروض شحن | ✅ عروض إضافة رصيد إضافي تصل إلى خصم 20% |
| سهولة البدء | يتطلب VPN + وسيلة دفع دولية | ✅ جاهز للاستخدام، يمكن دمجه في 5 دقائق |
من هم المستخدمون المناسبون لـ GPT-5.4 عبر APIYI؟
المستخدمون الفضوليون: يمكنك تجربة جميع قدرات GPT-5.4 (بما في ذلك Computer Use) بمبلغ يبدأ من 35 يوان فقط، دون الحاجة إلى دفع مقدم كبير.
المستخدمون طويلو الأمد: من خلال عروض إضافة الرصيد الإضافي، يمكنك الحصول على رصيد إضافي عند شحن مبالغ كبيرة، مما يخفض التكلفة الفعلية للاستخدام إلى 80% من السعر الأصلي. إذا كان استهلاكك الشهري مستقرًا عند مستوى معين، فإن ميزة هذا الخصم تصبح كبيرة جدًا مع مرور الوقت.
المطورون الصينيون: لا تحتاج إلى بطاقة ائتمان أمريكية، ولا تحتاج إلى VPN، ولا تحتاج إلى إعدادات دفع دولية معقدة. سجل حسابًا على APIYI apiyi.com → اشحن الرصيد → احصل على مفتاح API → غيّر سطرًا واحدًا من base_url وستتمكن من الاستدعاء.
سيناريوهات التزامن العالي: يحدد OpenAI الرسمي معدلات RPM وTPM حسب مستوى المستخدم (Tier 1 حوالي 1000 RPM)، بينما لا يفرض APIYI أي حدود على التزامن، مما يجعله مناسبًا لبيئات الإنتاج التي تتطلب عددًا كبيرًا من الاستدعاءات المتزامنة.
ملاحظة: لا يدعم APIYI حاليًا Batch API ووضع Flex الخاص بـ OpenAI. إذا كان سير عملك يعتمد على قدرة المعالجة المجمعة بنصف السعر، فتحقق مما إذا كان مناسبًا لك. بالنسبة للتفاعل في الوقت الفعلي واستدعاءات API القياسية، يعد APIYI خيارًا أكثر ملاءمة.
بدء سريع مع سياق GPT-5.4
مثال بسيط للغاية
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# استدعاء ضمن النطاق القياسي (≤272K، السعر القياسي)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": "أنت خبير في مراجعة الأكواد"},
{"role": "user", "content": "يرجى تحليل الكود التالي..."}
],
max_tokens=4096
)
print(response.choices[0].message.content)
عرض مثال استخدام السياق الطويل وتقدير التكلفة
from openai import OpenAI
import tiktoken
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def estimate_cost(input_tokens, output_tokens):
"""تقدير تكلفة استدعاء GPT-5.4"""
if input_tokens <= 272000:
input_cost = (input_tokens / 1_000_000) * 2.50
output_cost = (output_tokens / 1_000_000) * 15.00
else:
input_cost = (input_tokens / 1_000_000) * 5.00 # الضعف
output_cost = (output_tokens / 1_000_000) * 22.50 # 1.5x
return input_cost + output_cost
# مثال: تحليل ملف كبير
with open("large_codebase.txt", "r") as f:
code_content = f.read()
# تقدير عدد الرموز (Tokens)
enc = tiktoken.encoding_for_model("gpt-4o")
token_count = len(enc.encode(code_content))
print(f"عدد رموز الإدخال: {token_count}")
if token_count > 272000:
print(f"⚠️ تجاوز نقطة الـ 272K، سيتضاعف السعر!")
print(f"اقتراح: فكر في المعالجة المجزأة أو استخدام الضغط الملخص")
estimated = estimate_cost(token_count, 4000)
print(f"التكلفة المتوقعة: ${estimated:.4f}")
# الاستدعاء الفعلي
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": f"حلل نقاط الضعف الأمنية في الكود التالي:\n{code_content}"}
],
max_tokens=8000
)
print(response.choices[0].message.content)
اقتراح: استخدم APIYI apiyi.com للوصول إلى GPT-5.4، حيث يتطابق التسعير مع التسعير الرسمي، ويمكن لعروض إضافة الرصيد الإضافي أن تمنحك خصمًا يصل إلى 20%. ابدأ بالشحن من 35 يوان، وابدأ الاستخدام فور التسجيل دون الحاجة إلى بطاقة ائتمان أمريكية.
تقدير التكاليف حسب السيناريو لسياسة تسعير سياق GPT-5.4
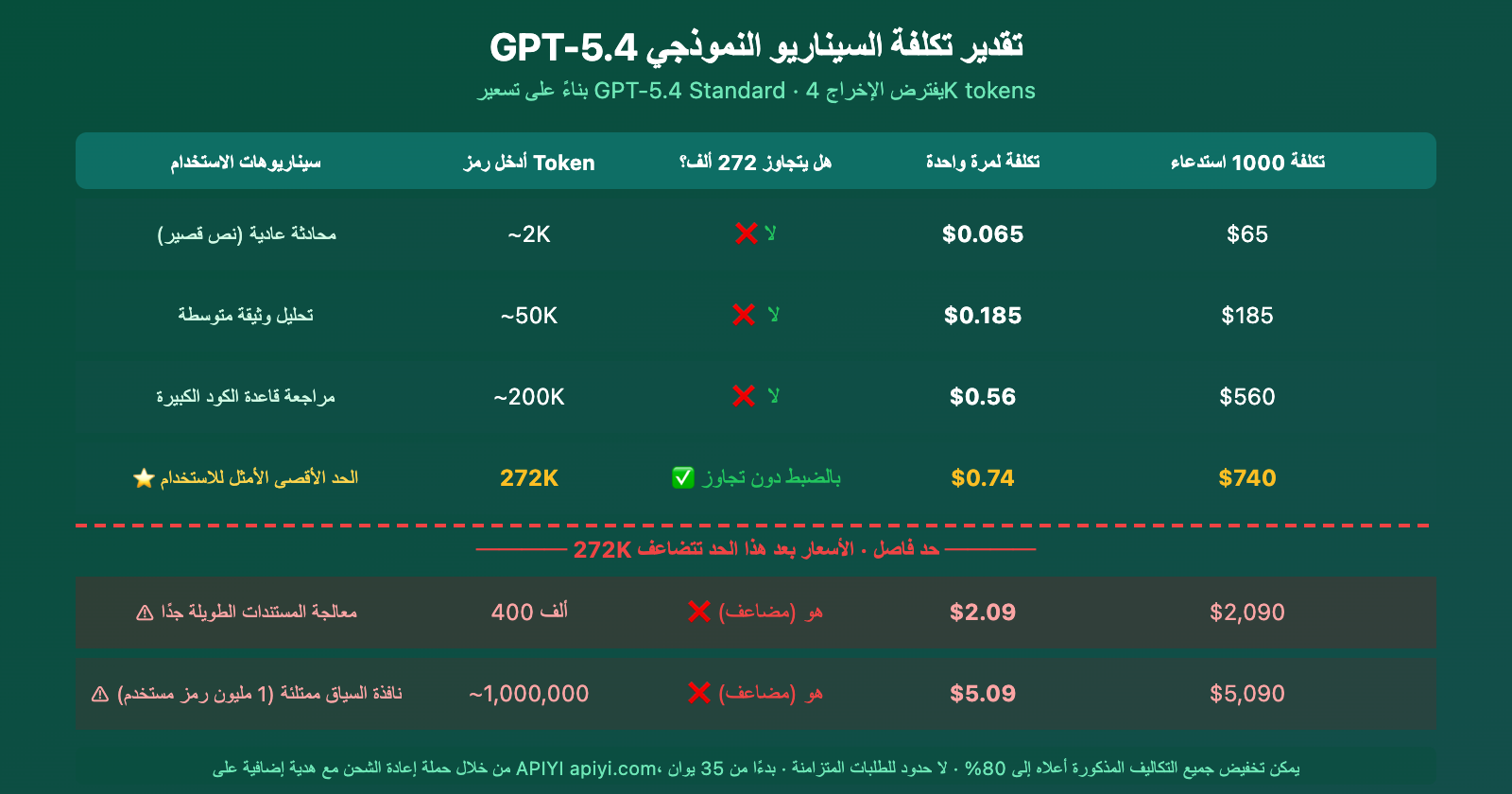
من تقدير التكاليف، يمكننا أن نرى بوضوح: 272K هو حافة تكلفة صلبة. لنفس الزيادة البالغة 128K في المدخلات (من 272K إلى 400K)، ترتفع التكلفة للاستدعاء الواحد من 0.74 دولار إلى 2.09 دولار – أي قفزة تقترب من 3 أضعاف.
الأسئلة الشائعة
س1: هل يتم فرض رسوم إضافية على GPT-5.4 بعد تجاوز 272K على الجزء الزائد فقط أم على الكل؟
على الكل. بمجرد أن تتجاوز رموز الإدخال الخاصة بك عتبة 272K، يتم احتساب جميع الرموز في الجلسة بأكملها وفقًا لتسعير التمديد (5.00 دولار / مليون للإدخال، 22.50 دولار / مليون للإخراج)، وليس فقط الجزء الزائد. لذا، فإن التحكم في حدود 272K هو مفتاح التوفير.
س2: APIYI لا يدعم Batch API، هل هذا يجعلها باهظة الثمن؟
صحيح أن APIYI لا تدعم وضعي المعالجة Batch و Flex من OpenAI (والتي يكون تسعيرها نصف السعر القياسي). لكن ميزة APIYI تكمن في: عدم الحاجة إلى بطاقة ائتمان أمريكية، وبدء الشحن من 35 يوان، وعدم وجود قيود على التزامن، والجاهزية للاستخدام فورًا. بالإضافة إلى ذلك، يمكن تحقيق خصم فعلي بنسبة 20٪ من خلال أنشطة إعادة الشحن مع الهدايا، مما يقترب من مستوى خصم Batch في سيناريوهات الاستدعاء القياسية. إذا كان سير عملك يعتمد على التفاعل في الوقت الفعلي وليس المعالجة الدفعية، فإن APIYI أكثر ملاءمة.
س3: كيف يمكنني تحديد ما إذا كانت مهمتي ستتجاوز 272K بسرعة؟
تقدير بسيط: كلمة إنجليزية واحدة تساوي تقريبًا 1.3 رمزًا، وحرف صيني واحد يساوي 2-3 رموز. 272K رمز تعادل تقريبًا 200,000 كلمة إنجليزية أو 90,000 إلى 130,000 حرف صيني. إذا كان إدخالك بالإضافة إلى الموجه النظامي ومحفوظات المحادثة لا يتجاوز هذا الحجم، فيمكنك الاستمتاع بالتسعير القياسي بأمان. يُنصح بإضافة فحص عد الرموز في الكود للتحذير المبكر. عند الاستدعاء عبر APIYI على apiyi.com، ينطبق نفس منطق الحساب هذا.
ملخص
النقاط الأساسية لتسعير سياق GPT-5.4:
- 272 ألف رمز هي الحد الفاصل الحرج: بعد تجاوز 272 ألف رمز، يتضاعف سعر الإدخال (من 2.50 دولار إلى 5.00 دولار)، ويرتفع سعر الإخراج بنسبة 50% (من 15.00 دولار إلى 22.50 دولار)، وينطبق هذا على جميع الرموز الكاملة.
- النطاق من 127 ألف إلى 272 ألف رمز هو الأفضل: تبقى الدقة مستقرة عند حوالي 97%، وتقع ضمن نطاق التسعير القياسي، مما يوفر أفضل قيمة مقابل المال.
- الدقة تتراجع بعد 256 ألف رمز: في نطاق 512 ألف إلى 1 مليون رمز، قد تنخفض الدقة إلى حوالي 36%، لذا يجب استخدامه بحذر.
- أغلى من GPT-5.2 ولكنه أكثر كفاءة: في النطاق القياسي، الإدخال أغلى بنسبة 43% والإخراج أغلى بنسبة 7%، لكنه يستخدم رموز استدلال أقل.
استراتيجيات التوفير: احتفظ بالإدخال تحت 272 ألف رمز، واستخدم ذاكرة التخزين المؤقت للإدخال (توفر 90%)، واستفد من Tool Search (توفر 47%). يمكنك الوصول عبر APIYI على apiyi.com، حيث التسعير متزامن مع الرسمي، وتوجد عروض إضافية عند الشحن تصل إلى خصم 20%. الحد الأدنى للشحن هو 35 يوان، ولا حاجة لبطاقة ائتمان أمريكية، ولا حدود للتزامن، ويمكنك البدء فور التسجيل – مثالي للتجربة والاستخدام طويل الأمد.
📚 مراجع
-
صفحة تسعير OpenAI API: التسعير الكامل لـ GPT-5.4 وشرح التسعير المتدرج للسياق
- الرابط:
developers.openai.com/api/docs/pricing - الشرح: المصدر الرسمي والموثوق للتسعير، يتضمن التسعير لجميع أوضاع Standard/Batch/Flex/Priority
- الرابط:
-
وثائق نموذج OpenAI GPT-5.4: نافذة السياق، قيود الإخراج، المواصفات الفنية
- الرابط:
developers.openai.com/api/docs/models/gpt-5.4 - الشرح: وثائق المواصفات الرسمية للنموذج
- الرابط:
-
إعلان إصدار OpenAI GPT-5.4: القدرات الأساسية وبيانات الاختبار المعيارية
- الرابط:
openai.com/index/introducing-gpt-5-4/ - الشرح: يتضمن معايير الأداء، فلسفة التصميم، وشرح استراتيجية التسعير
- الرابط:
-
مناقشة مجتمع مطوري OpenAI: شرح مفصل لتسعير GPT-5.4، قيود السياق، و Tool Search
- الرابط:
community.openai.com/t/gpt-5-4-deep-dive-pricing-context-limits-and-tool-search-explained/ - الشرح: مناقشة مطورين متعمقة حول بنية التسعير وأداء السياق
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بمناقشة تجارب استخدام سياق GPT-5.4 وتقنيات تحسين التكلفة في قسم التعليقات. للمزيد من المواد، تفضل بزيارة مركز وثائق APIYI على docs.apiyi.com