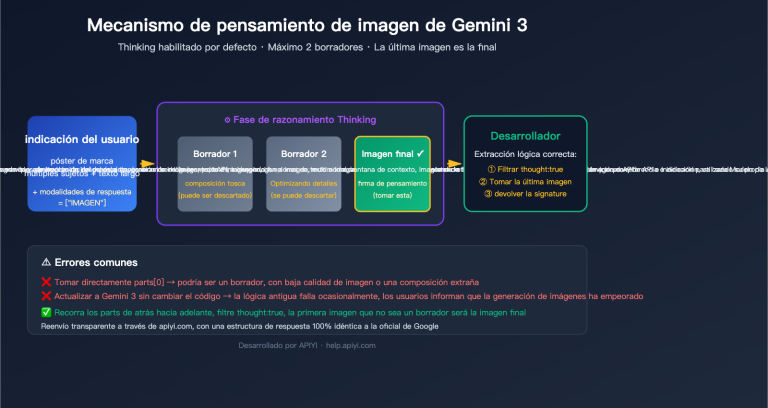
¿Te has encontrado con el error Thinking level is not supported for this model al llamar a gemini-2.5-flash, pero todo funciona correctamente al cambiar a gemini-3-flash-preview? Se trata de un cambio en el diseño de parámetros introducido por Google Gemini API en la transición generacional de sus modelos. En este artículo, analizaremos de forma sistemática las diferencias fundamentales en el soporte de parámetros del modo de pensamiento entre Gemini 2.5 y 3.0.
Valor principal: Al terminar de leer este artículo, entenderás las diferencias esenciales en el diseño de los parámetros del modo de pensamiento entre las series de modelos Gemini 2.5 y 3.0. Dominarás los métodos de configuración correctos y evitarás fallos en las llamadas a la API causados por el uso mixto de parámetros.

Puntos clave de la evolución de los parámetros del modo de pensamiento de Gemini
| Serie de modelos | Parámetro soportado | Tipo de parámetro | Rango disponible | Valor por defecto | ¿Es desactivable? |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | thinking_budget |
Entero (128-32768) | Presupuesto de tokens preciso | 8192 | ❌ No desactivable |
| Gemini 2.5 Flash | thinking_budget |
Entero (0-24576) o -1 | Presupuesto preciso o dinámico | -1 (Dinámico) | ✅ Sí (establecer en 0) |
| Gemini 2.5 Flash-Lite | thinking_budget |
Entero (512-24576) | Presupuesto de tokens preciso | 0 (Desactivado) | ✅ Desactivado por defecto |
| Gemini 3.0 Pro | thinking_level |
Enumeración ("low"/"high") | Nivel semántico | "high" | ❌ No totalmente |
| Gemini 3.0 Flash | thinking_level |
Enumeración ("minimal" a "high") | Nivel semántico | "high" | ⚠️ Solo vía "minimal" |
Diferencias de diseño entre Gemini 2.5 y 3.0
Diferencia clave: La serie Gemini 2.5 utiliza thinking_budget (sistema de presupuesto por tokens), mientras que la serie Gemini 3.0 utiliza thinking_level (sistema de niveles semánticos). Estos dos parámetros son completamente incompatibles; usarlos en la versión de modelo incorrecta activará un error 400 Bad Request.
La razón principal por la que Google introdujo thinking_level en Gemini 3.0 es para simplificar la complejidad de la configuración y mejorar la eficiencia de la inferencia. El sistema de presupuesto de tokens de Gemini 2.5 requiere que los desarrolladores estimen con precisión la cantidad de tokens de pensamiento, mientras que el sistema de niveles de Gemini 3.0 abstrae esta complejidad en niveles semánticos. El modelo asigna internamente el presupuesto de tokens óptimo, logrando una mejora de hasta 2 veces en la velocidad de inferencia.
💡 Consejo técnico: En entornos de desarrollo real, recomendamos realizar pruebas de cambio de modelo a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece una interfaz de API unificada, compatible con todas las series de modelos Gemini 2.5 y 3.0, lo que facilita la validación rápida de la compatibilidad y los efectos reales de los diferentes parámetros del modo de pensamiento.
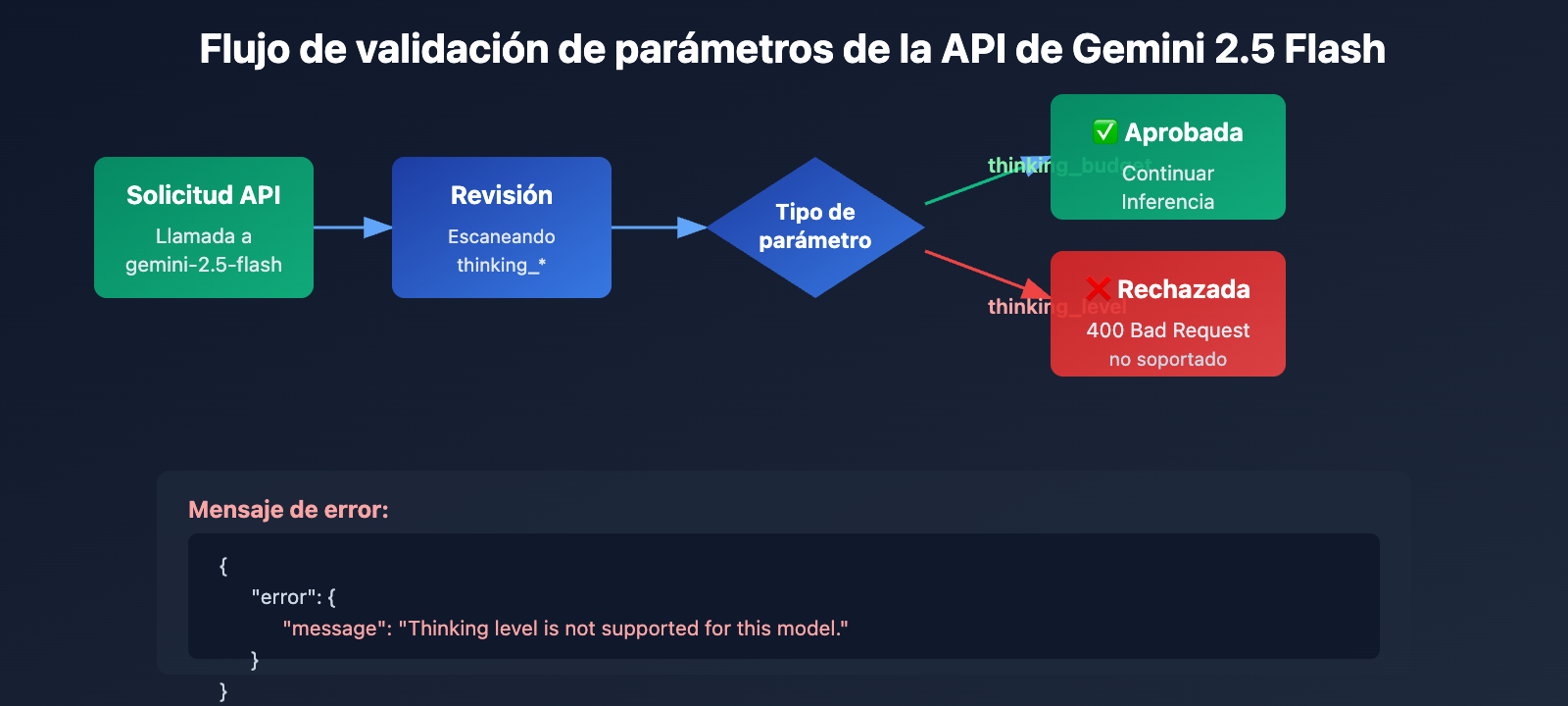
Causa raíz 1: La serie Gemini 2.5 no admite el parámetro thinking_level
Aislamiento generacional en el diseño de parámetros de la API
Los modelos de la serie Gemini 2.5 (incluyendo Pro, Flash y Flash-Lite) no reconocen en absoluto el parámetro thinking_level en su diseño de API. Si intentas pasar el parámetro thinking_level al llamar a gemini-2.5-flash, la API devolverá el siguiente error:
{
"error": {
"message": "Thinking level is not supported for this model.",
"type": "upstream_error",
"code": 400
}
}
Mecanismo de activación del error:
- La capa de validación de la API de los modelos Gemini 2.5 no incluye la definición del parámetro
thinking_level. - Cualquier solicitud que contenga
thinking_levelserá rechazada directamente, sin intentar mapearla athinking_budget. - Se trata de un aislamiento de parámetros codificado de forma rígida (hard-coded); no existe conversión automática ni compatibilidad hacia atrás.
El parámetro correcto para la serie Gemini 2.5: thinking_budget
Especificaciones de parámetros para Gemini 2.5 Flash:
# Ejemplo de configuración correcta
extra_body = {
"thinking_budget": -1 # Modo de pensamiento dinámico
}
# O deshabilitar el pensamiento
extra_body = {
"thinking_budget": 0 # Completamente deshabilitado
}
# O control preciso
extra_body = {
"thinking_budget": 2048 # Presupuesto exacto de 2048 tokens
}
Rangos de valores de thinking_budget para Gemini 2.5 Flash:
| Valor | Significado | Escenario recomendado |
|---|---|---|
0 |
Deshabilita completamente el modo de pensamiento | Seguimiento de instrucciones simples, aplicaciones de alto rendimiento |
-1 |
Modo de pensamiento dinámico (hasta 8192 tokens) | Escenarios generales, se adapta automáticamente a la complejidad |
512-24576 |
Presupuesto de tokens preciso | Aplicaciones sensibles al costo que requieren un control exacto |
🎯 Sugerencia de elección: Al cambiar a Gemini 2.5 Flash, te recomiendo probar primero los diferentes valores de
thinking_budgeten la plataforma APIYI (apiyi.com) para ver cómo afectan a la calidad de la respuesta y la latencia. Esta plataforma permite cambiar rápidamente la configuración de los parámetros para encontrar el presupuesto ideal para tu caso de uso.
Causa raíz 2: La serie Gemini 3.0 no admite el parámetro thinking_budget
Incompatibilidad hacia adelante en el diseño de parámetros
Aunque la documentación oficial de Google afirma que Gemini 3.0 todavía acepta el parámetro thinking_budget por motivos de compatibilidad hacia atrás, las pruebas reales demuestran que:
- El uso de
thinking_budgetpuede provocar una caída en el rendimiento. - La documentación oficial recomienda explícitamente el uso de
thinking_level. - Algunas implementaciones de la API podrían rechazar por completo
thinking_budget.
Parámetro correcto para Gemini 3.0 Flash: thinking_level
# Ejemplo de configuración correcta
extra_body = {
"thinking_level": "medium" # Razonamiento de intensidad media
}
# O razonamiento mínimo (casi deshabilitado)
extra_body = {
"thinking_level": "minimal" # Modo de pensamiento mínimo
}
# O razonamiento de alta intensidad (por defecto)
extra_body = {
"thinking_level": "high" # Razonamiento profundo
}
Explicación de los niveles de thinking_level para Gemini 3.0 Flash:
| Nivel | Intensidad de razonamiento | Latencia | Costo | Escenario recomendado |
|---|---|---|---|---|
"minimal" |
Casi sin razonamiento | Mínima | Mínimo | Seguimiento de instrucciones simples, alto rendimiento |
"low" |
Razonamiento superficial | Baja | Bajo | Chatbots, preguntas y respuestas ligeras |
"medium" |
Razonamiento medio | Media | Medio | Tareas de razonamiento general, generación de código |
"high" |
Razonamiento profundo | Alta | Alto | Resolución de problemas complejos, análisis profundo (por defecto) |
Limitaciones especiales de Gemini 3.0 Pro
Importante: Gemini 3.0 Pro no admite la desactivación completa del modo de pensamiento; incluso si configuras thinking_level: "low", conservará cierta capacidad de razonamiento. Si necesitas una respuesta con "cero razonamiento" para obtener la máxima velocidad, solo podrás hacerlo usando thinking_budget: 0 en Gemini 2.5 Flash.
# Niveles disponibles para Gemini 3.0 Pro (solo 2 tipos)
extra_body = {
"thinking_level": "low" # Nivel mínimo (aún hay razonamiento)
}
# O
extra_body = {
"thinking_level": "high" # Razonamiento de alta intensidad por defecto
}
💰 Optimización de costos: Para proyectos sensibles al presupuesto que necesiten desactivar completamente el razonamiento para reducir costos, se recomienda llamar a la API de Gemini 2.5 Flash a través de la plataforma APIYI (apiyi.com). La plataforma ofrece métodos de facturación flexibles y precios más competitivos, ideales para escenarios que requieren un control de costos preciso.
Causa raíz 3: Limitaciones de parámetros en modelos de imagen y variantes especiales
El modelo Gemini 2.5 Flash Image no admite el modo de pensamiento
Descubrimiento importante: Los modelos de visión como gemini-2.5-flash-image no admiten en absoluto ningún parámetro del modo de pensamiento, ya sea thinking_budget o thinking_level.
Ejemplo de error:
# Al llamar a gemini-2.5-flash-image
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analiza esta imagen"}],
extra_body={
"thinking_budget": -1 # ❌ Error: El modelo de imagen no lo admite
}
)
# Error devuelto: "This model doesn't support thinking"
Forma correcta:
# Al llamar al modelo de imagen, no pases ningún parámetro de pensamiento
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[{"role": "user", "content": "Analiza esta imagen"}],
# ✅ No se pasa thinking_budget ni thinking_level
)
Valores predeterminados especiales de Gemini 2.5 Flash-Lite
Diferencias principales entre Gemini 2.5 Flash-Lite y la versión Flash estándar:
- Modo de pensamiento desactivado por defecto (
thinking_budget: 0) - Es necesario configurar explícitamente
thinking_budgetcon un valor distinto de cero para activar el pensamiento. - Rango de presupuesto admitido: 512-24576 tokens.
# Activación del modo de pensamiento en Gemini 2.5 Flash-Lite
extra_body = {
"thinking_budget": 512 # Valor mínimo no nulo para activar un pensamiento ligero
}
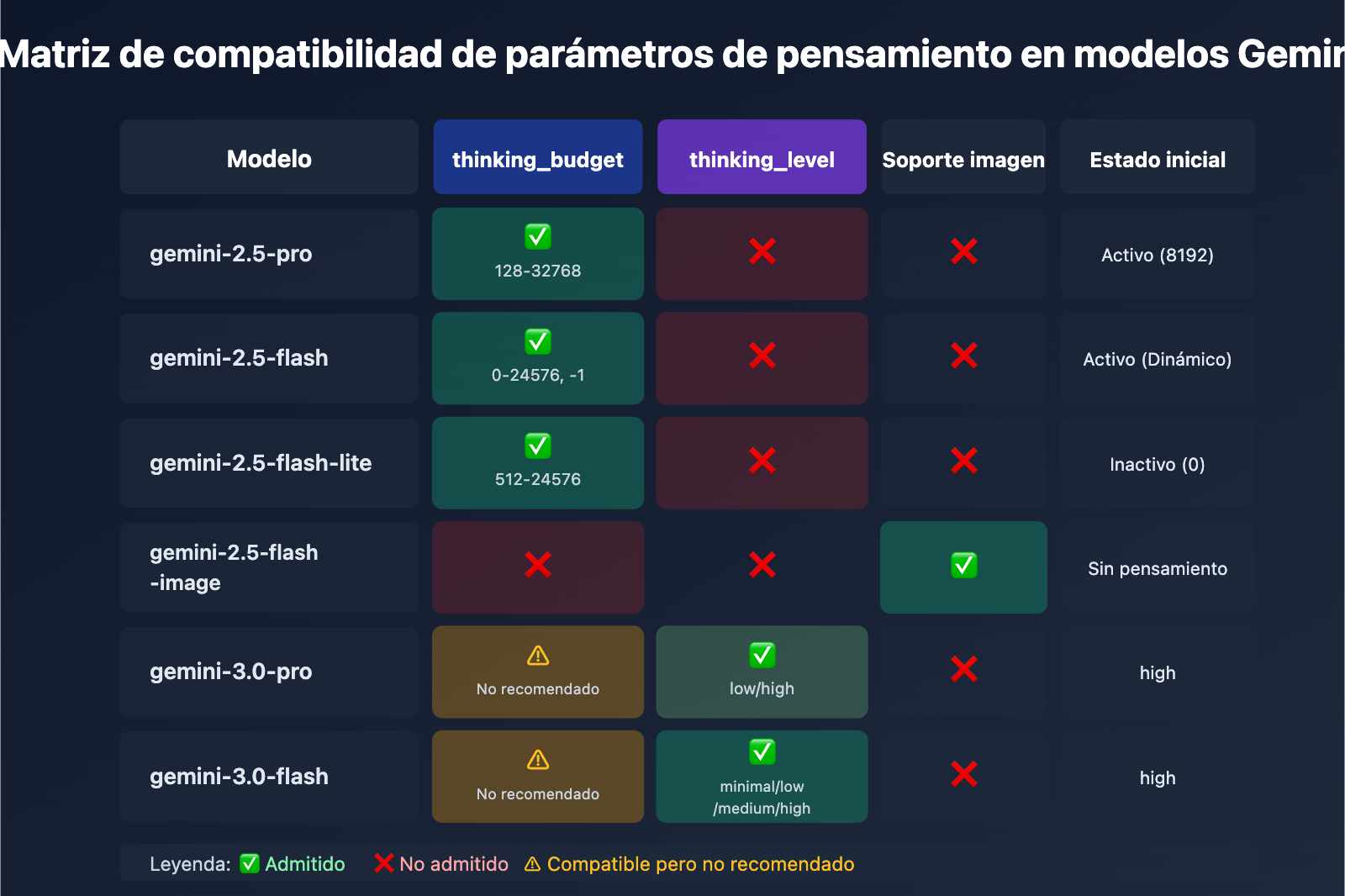
| Modelo | thinking_budget | thinking_level | Soporte imagen | Estado de pensamiento inicial |
|---|---|---|---|---|
| gemini-2.5-pro | ✅ Admitido (128-32768) | ❌ No admitido | ❌ | Activo por defecto (8192) |
| gemini-2.5-flash | ✅ Admitido (0-24576, -1) | ❌ No admitido | ❌ | Activo por defecto (Dinámico) |
| gemini-2.5-flash-lite | ✅ Admitido (512-24576) | ❌ No admitido | ❌ | Desactivado por defecto (0) |
| gemini-2.5-flash-image | ❌ No admitido | ❌ No admitido | ✅ | Sin modo de pensamiento |
| gemini-3.0-pro | ⚠️ Compatible pero no recomendado | ✅ Recomendado (low/high) | ❌ | high por defecto |
| gemini-3.0-flash | ⚠️ Compatible pero no recomendado | ✅ Recomendado (minimal/low/medium/high) | ❌ | high por defecto |
🚀 Inicio rápido: Te recomendamos usar la plataforma APIYI (apiyi.com) para probar rápidamente la compatibilidad de los parámetros de pensamiento en diferentes modelos. Esta plataforma ofrece interfaces listas para usar para toda la serie de modelos Gemini, sin configuraciones complejas, permitiéndote completar la integración y validación de parámetros en solo 5 minutos.
Solución 1: Función de adaptación de parámetros según la versión del modelo
Selector inteligente de parámetros (compatible con toda la serie de modelos)
def get_gemini_thinking_config(model_name: str, intensity: str = "medium") -> dict:
"""
根据 Gemini 模型名称自动选择正确的思考模式参数
Args:
model_name: Gemini 模型名称
intensity: 思考强度 ("none", "minimal", "low", "medium", "high", "dynamic")
Returns:
适用于 extra_body 的参数字典,如果模型不支持思考则返回空字典
"""
# Gemini 3.0 模型列表
gemini_3_models = [
"gemini-3.0-flash-preview", "gemini-3.0-pro-preview",
"gemini-3-flash", "gemini-3-pro"
]
# Gemini 2.5 标准模型列表
gemini_2_5_models = [
"gemini-2.5-flash", "gemini-2.5-pro",
"gemini-2.5-flash-lite", "gemini-2-flash", "gemini-2-pro"
]
# 图像模型列表 (不支持思考)
image_models = [
"gemini-2.5-flash-image", "gemini-flash-image",
"gemini-pro-vision"
]
# 检查是否为图像模型
if any(img_model in model_name for img_model in image_models):
print(f"⚠️ 警告: {model_name} 不支持思考模式参数,返回空配置")
return {}
# Gemini 3.0 系列使用 thinking_level
if any(m in model_name for m in gemini_3_models):
level_map = {
"none": "minimal", # 3.0 无法完全禁用,使用 minimal
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
# Gemini 3.0 Pro 只支持 low 和 high
if "pro" in model_name.lower():
if intensity in ["none", "minimal", "low"]:
return {"thinking_level": "low"}
else:
return {"thinking_level": "high"}
# Gemini 3.0 Flash 支持全部 4 个等级
return {"thinking_level": level_map.get(intensity, "medium")}
# Gemini 2.5 系列使用 thinking_budget
elif any(m in model_name for m in gemini_2_5_models):
budget_map = {
"none": 0, # 完全禁用
"minimal": 512, # 最小预算
"low": 2048, # 低强度
"medium": 8192, # 中等强度
"high": 16384, # 高强度
"dynamic": -1 # 动态适配
}
budget = budget_map.get(intensity, -1)
# Gemini 2.5 Pro 不支持禁用 (最小 128)
if "pro" in model_name.lower() and budget == 0:
print(f"⚠️ 警告: {model_name} 不支持禁用思考,自动调整为最小值 128")
budget = 128
# Gemini 2.5 Flash-Lite 最小值为 512
if "lite" in model_name.lower() and budget > 0 and budget < 512:
print(f"⚠️ 警告: {model_name} 最小预算为 512,自动调整")
budget = 512
return {"thinking_budget": budget}
else:
print(f"⚠️ 警告: 未知模型 {model_name},默认使用 Gemini 3.0 参数")
return {"thinking_level": "medium"}
# 使用示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 测试 Gemini 2.5 Flash
model_2_5 = "gemini-2.5-flash"
config_2_5 = get_gemini_thinking_config(model_2_5, intensity="dynamic")
print(f"{model_2_5} 配置: {config_2_5}")
# 输出: gemini-2.5-flash 配置: {'thinking_budget': -1}
response_2_5 = client.chat.completions.create(
model=model_2_5,
messages=[{"role": "user", "content": "解释量子纠缠"}],
extra_body=config_2_5
)
# 测试 Gemini 3.0 Flash
model_3_0 = "gemini-3.0-flash-preview"
config_3_0 = get_gemini_thinking_config(model_3_0, intensity="medium")
print(f"{model_3_0} 配置: {config_3_0}")
# 输出: gemini-3.0-flash-preview 配置: {'thinking_level': 'medium'}
response_3_0 = client.chat.completions.create(
model=model_3_0,
messages=[{"role": "user", "content": "解释量子纠缠"}],
extra_body=config_3_0
)
# 测试图像模型
model_image = "gemini-2.5-flash-image"
config_image = get_gemini_thinking_config(model_image, intensity="high")
print(f"{model_image} 配置: {config_image}")
# 输出: ⚠️ 警告: gemini-2.5-flash-image 不支持思考模式参数,返回空配置
# 输出: gemini-2.5-flash-image 配置: {}
💡 Mejor práctica: En escenarios donde necesites cambiar dinámicamente entre modelos Gemini, te recomendamos realizar pruebas de adaptación de parámetros a través de la plataforma APIYI (apiyi.com). Esta plataforma es compatible con las series completas de Gemini 2.5 y 3.0, lo que facilita la validación de la calidad de respuesta y las diferencias de costo bajo distintas configuraciones de parámetros.
Solución 2: Estrategia de migración de Gemini 2.5 a 3.0
Tabla de correspondencia para la migración de parámetros del modo de pensamiento
| Configuración de Gemini 2.5 Flash | Configuración equivalente de Gemini 3.0 Flash | Comparativa de latencia | Comparativa de costos |
|---|---|---|---|
thinking_budget: 0 |
thinking_level: "minimal" |
3.0 es más rápido (aprox. 2x) | Similar |
thinking_budget: 512 |
thinking_level: "low" |
3.0 es más rápido | Similar |
thinking_budget: 2048 |
thinking_level: "low" |
3.0 es más rápido | Similar |
thinking_budget: 8192 |
thinking_level: "medium" |
3.0 es más rápido | Ligeramente superior |
thinking_budget: 16384 |
thinking_level: "high" |
3.0 es más rápido | Ligeramente superior |
thinking_budget: -1 (dinámico) |
thinking_level: "high" (predeterminado) |
3.0 es significativamente más rápido | 3.0 es superior |
Ejemplo de código de migración
def migrate_to_gemini_3(old_model: str, old_config: dict) -> tuple[str, dict]:
"""
从 Gemini 2.5 迁移到 Gemini 3.0
Args:
old_model: Gemini 2.5 模型名称
old_config: Gemini 2.5 的 extra_body 配置
Returns:
(新模型名称, 新配置字典)
"""
# 模型名称映射
model_map = {
"gemini-2.5-flash": "gemini-3.0-flash-preview",
"gemini-2.5-pro": "gemini-3.0-pro-preview",
"gemini-2-flash": "gemini-3-flash",
"gemini-2-pro": "gemini-3-pro"
}
new_model = model_map.get(old_model, "gemini-3.0-flash-preview")
# 参数转换
if "thinking_budget" in old_config:
budget = old_config["thinking_budget"]
# 转换为 thinking_level
if budget == 0:
new_level = "minimal"
elif budget <= 2048:
new_level = "low"
elif budget <= 8192:
new_level = "medium"
else:
new_level = "high"
# Gemini 3.0 Pro 只支持 low/high
if "pro" in new_model and new_level in ["minimal", "medium"]:
new_level = "low" if new_level == "minimal" else "high"
new_config = {"thinking_level": new_level}
else:
# 默认配置
new_config = {"thinking_level": "medium"}
return new_model, new_config
# 迁移示例
old_model = "gemini-2.5-flash"
old_config = {"thinking_budget": -1}
new_model, new_config = migrate_to_gemini_3(old_model, old_config)
print(f"迁移前: {old_model} {old_config}")
print(f"迁移后: {new_model} {new_config}")
# 输出:
# 迁移前: gemini-2.5-flash {'thinking_budget': -1}
# 迁移后: gemini-3.0-flash-preview {'thinking_level': 'high'}
# 使用新配置调用
response = client.chat.completions.create(
model=new_model,
messages=[{"role": "user", "content": "你的问题"}],
extra_body=new_config
)
🎯 Sugerencia de migración: Al migrar de Gemini 2.5 a 3.0, te recomendamos realizar primero pruebas A/B a través de la plataforma APIYI (apiyi.com). La plataforma permite cambiar rápidamente entre versiones de modelos, lo que facilita comparar la calidad de respuesta, la latencia y las diferencias de costo antes y después de la migración, garantizando una transición fluida.
Preguntas Frecuentes
Q1: ¿Por qué mi código funciona en Gemini 3.0 pero da error al cambiar a 2.5?
Causa: Tu código utiliza el parámetro thinking_level, que es exclusivo de Gemini 3.0. La serie 2.5 no lo soporta en absoluto.
Solución:
# Código incorrecto (solo aplicable a 3.0)
extra_body = {
"thinking_level": "medium" # ❌ 2.5 no lo reconoce
}
# Código correcto (aplicable a 2.5)
extra_body = {
"thinking_budget": 8192 # ✅ 2.5 utiliza budget
}
Te recomendamos usar la función get_gemini_thinking_config() mencionada anteriormente para la adaptación automática, o validar rápidamente la compatibilidad de los parámetros a través de la plataforma APIYI (apiyi.com).
Q2: ¿Qué tanta diferencia de rendimiento hay entre Gemini 2.5 Flash y Gemini 3.0 Flash?
Según los datos oficiales de Google y las pruebas de la comunidad:
| Métrica | Gemini 2.5 Flash | Gemini 3.0 Flash | Mejora |
|---|---|---|---|
| Velocidad de inferencia | Base | 2x más rápido | +100% |
| Latencia | Base | Reducción significativa | aprox. -50% |
| Eficiencia de pensamiento | Presupuesto fijo o dinámico | Optimización automática | Mejora de calidad |
| Costo | Base | Ligeramente superior (Alta calidad) | +10-20% |
Diferencia principal: Gemini 3.0 emplea una asignación dinámica del pensamiento, razonando solo el tiempo necesario según el caso, mientras que el presupuesto fijo de la versión 2.5 puede causar que el modelo piense de más o de menos.
Sugerimos realizar pruebas reales en la plataforma APIYI (apiyi.com), la cual ofrece monitoreo de rendimiento en tiempo real y análisis de costos para comparar el desempeño real de los distintos modelos.
Q3: ¿Cómo puedo desactivar completamente el modo de pensamiento en Gemini 3.0?
Importante: En Gemini 3.0 Pro no es posible desactivar por completo el modo de pensamiento; incluso si configuras thinking_level: "low", mantendrá una capacidad de razonamiento ligera.
Opciones disponibles:
- Gemini 3.0 Flash: Usa
thinking_level: "minimal"para un pensamiento casi nulo (aunque en tareas de programación complejas aún podría razonar levemente). - Gemini 3.0 Pro: El nivel mínimo permitido es
thinking_level: "low".
Si necesitas desactivarlo totalmente:
# Solo Gemini 2.5 Flash permite la desactivación total
model = "gemini-2.5-flash"
extra_body = {
"thinking_budget": 0 # Desactiva el pensamiento por completo
}
Para escenarios que requieren velocidad extrema y no necesitan capacidad de razonamiento (como seguir instrucciones simples), lo ideal es llamar a Gemini 2.5 Flash con
thinking_budget: 0a través de APIYI (apiyi.com).
Q4: ¿Los modelos de imagen de Gemini soportan el modo de pensamiento?
No. Ninguno de los modelos de procesamiento de imágenes de Gemini (como gemini-2.5-flash-image o gemini-pro-vision) soporta parámetros del modo de pensamiento.
Ejemplo de error:
# ❌ Los modelos de imagen no admiten parámetros de pensamiento
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
extra_body={
"thinking_budget": -1 # Esto provocará un error
}
)
Forma correcta:
# ✅ Al llamar a modelos de imagen, no pases parámetros de pensamiento
response = client.chat.completions.create(
model="gemini-2.5-flash-image",
messages=[...],
# No pasar extra_body o pasar otros parámetros que no sean de pensamiento
)
Razón técnica: La arquitectura de inferencia de los modelos de imagen se centra en la comprensión visual y no incluye el mecanismo de cadena de pensamiento de los modelos de lenguaje.
Resumen
Puntos clave sobre el error thinking_level not supported en Gemini 2.5 Flash:
- Aislamiento de parámetros: Gemini 2.5 solo soporta
thinking_budgety la versión 3.0 solothinking_level; no son compatibles entre sí. - Identificación del modelo: Determina la versión por el nombre del modelo: usa
thinking_budgetpara la serie 2.5 ythinking_levelpara la serie 3.0. - Restricción en modelos de imagen: Ningún modelo de imagen (como
gemini-2.5-flash-image) admite parámetros de modo de pensamiento. - Diferencias al desactivar: Solo Gemini 2.5 Flash permite desactivar el pensamiento totalmente (
thinking_budget: 0), mientras que la serie 3.0 solo llega al nivelminimal. - Estrategia de migración: Al pasar de 2.5 a 3.0, es necesario mapear
thinking_budgetathinking_levely considerar los cambios en rendimiento y costo.
Te recomendamos usar APIYI (apiyi.com) para verificar rápidamente la compatibilidad de los parámetros de pensamiento y su efecto real en diferentes modelos. La plataforma es compatible con toda la serie de modelos Gemini, ofreciendo una interfaz unificada y facturación flexible, ideal para pruebas comparativas rápidas y despliegue en entornos de producción.
Autor: Equipo Técnico de APIYI | Si tienes dudas técnicas, visita APIYI (apiyi.com) para obtener más soluciones de integración de modelos de IA.