A solo un día de la conferencia principal del Google I/O 2026, Google ya no puede ocultar sus cartas. El Gemini 3.2 Flash fue descubierto por desarrolladores el 5 de mayo en la aplicación de Gemini para iOS y en Google AI Studio, junto con la filtración de la interfaz "Liquid Glass" (vidrio líquido) para la versión web. Entre los escenarios más impactantes capturados por los testers internacionales destacan: la generación de 2200 líneas de código ejecutable en una sola indicación, la creación desde cero de un demo interactivo del escritorio de Windows 98 mediante una sola instrucción, y un rendimiento en tareas de programación que deja al modelo insignia de la casa, el Gemini 3.1 Pro, muy por detrás.
Este artículo, basado en fuentes en inglés disponibles antes del 18 de mayo de 2026, analiza sistemáticamente la información filtrada en cinco dimensiones: especificaciones principales, capacidades de programación, estrategia de precios, señales de interfaz y agentes, e impacto en los desarrolladores, ofreciendo además recomendaciones para una posible migración.
Valor central: Entiende en 3 minutos el verdadero potencial y la disrupción de precios del Gemini 3.2 Flash, y decide si debes preparar tu infraestructura técnica antes del lanzamiento en el I/O.

Resumen de información clave de Gemini 3.2 Flash
Antes de que Google publique cualquier blog oficial, la versión filtrada ya ha sido probada exhaustivamente por los desarrolladores. La siguiente tabla resume los hechos clave verificables hasta el 18 de mayo de 2026.
| Elemento de información | Detalles |
|---|---|
| Fecha de descubrimiento | 5 de mayo de 2026, visto en pruebas A/B de la App Gemini para iOS y Google AI Studio |
| Lanzamiento oficial previsto | Google I/O 2026, conferencia principal del 19-20 de mayo |
| Posicionamiento del modelo | Gama media de la serie Flash, enfocado en igualar la capacidad de programación del Gemini 3.1 Pro |
| Precio de entrada | $0.25 / millón de tokens (igual que Gemini 3.1 Flash-Lite) |
| Precio de salida | $2.00 / millón de tokens (33% menos que los $3.00 del Gemini 3 Flash) |
| Ventana de contexto | Se estima en 1M de tokens (no confirmado oficialmente) |
| Corte de conocimiento | Se especula actualizado a enero de 2026 |
| Latencia de respuesta | Algunas indicaciones por debajo de 200 ms |
| Interfaz de usuario | Interfaz "Liquid Glass", cuadro de entrada en forma de píldora |
| Señales de nuevas funciones | Pestaña "Agents (Beta)" detectada en iOS |
Los dos números más llamativos de esta tabla son: primero, que el precio de salida se ha reducido drásticamente, y segundo, que el rendimiento apunta no a la generación anterior de Flash, sino al 3.1 Pro. Estos dos puntos determinan el impacto que tendrá en el stack tecnológico de los desarrolladores.
🎯 Consejo de verificación rápida: Antes de que la API oficial esté abierta, te sugerimos reservar tu espacio de acceso para la serie Gemini en APIYI (apiyi.com). Al unificar el
base_url, cambiar entre diferentes versiones de Gemini solo requiere modificar el campomodel, lo que te permitirá realizar pruebas de carga con escenarios reales de tu negocio con el 3.2 Flash desde la misma noche del I/O.
Análisis del rendimiento de codificación de Gemini 3.2 Flash: Superando expectativas
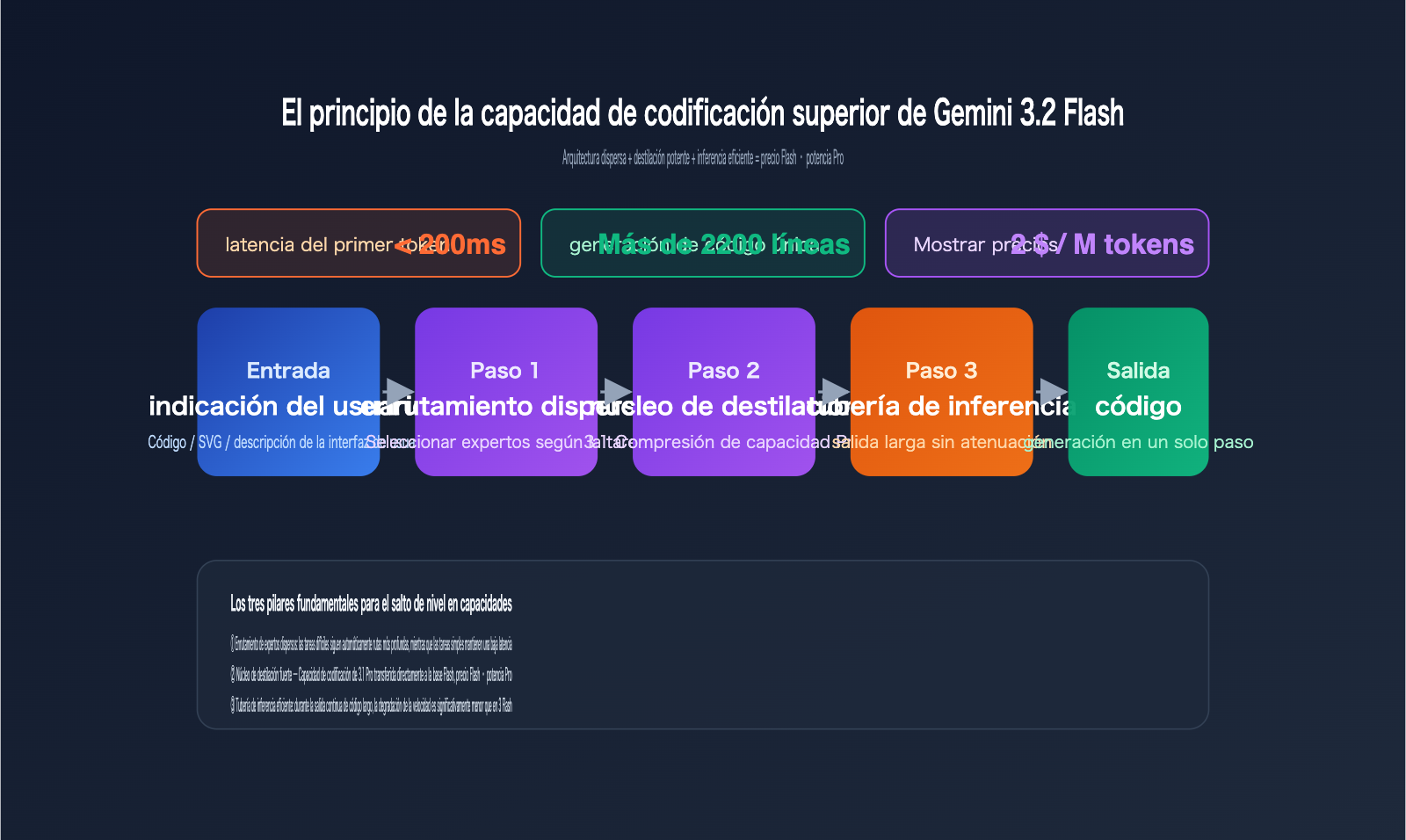
Lo más disruptivo de esta filtración, y que ha superado las expectativas de los desarrolladores, es cómo el modelo de la categoría Flash ha logrado "saltarse niveles" en tareas de programación. La comunidad internacional ha realizado numerosas pruebas a ciegas utilizando el modo Canvas de AI Studio, y la conclusión es unánime: en escenarios de UI generativa, SVG complejos y HTML Canvas, Gemini 3.2 Flash ya supera de forma estable a Gemini 3.1 Pro.
Comparativa de Gemini 3.2 Flash en tres escenarios de codificación
La siguiente tabla resume los resultados de las tres pruebas comparativas más citadas en la comunidad, basadas en muestras públicas de LM Arena y AI Studio.
| Tarea de prueba | Gemini 3 Flash | Gemini 3.1 Pro | Gemini 3.2 Flash |
|---|---|---|---|
| Animación urbana ASCII en HTML a pantalla completa | Código no ejecutable | ~5 min, código con errores | ~2 min, versión funcional directa |
| Generación de demo de escritorio Windows 98 con un solo prompt | Solo carcasa estática | Lógica dispersa, requiere parches | ~2200 líneas de código a la primera, ventanas y menús interactivos |
| Ilustración vectorial SVG compleja | Rutas caóticas, colores erróneos | Visualmente aceptable, requiere ajuste manual | Visualmente perfecto, cero errores |
Las tres tareas comparten un punto común: requieren que el modelo complete una "planificación de estructura + salida continua de código largo" en una sola inferencia, que es precisamente donde los modelos Flash solían fallar. La estabilidad de 3.2 Flash en estos escenarios de salida extensa demuestra que su arquitectura base ha mejorado significativamente en coherencia de contexto largo y restricciones de sintaxis de código.
¿Por qué Gemini 3.2 Flash puede "superar a modelos superiores"?
A juzgar por las pistas técnicas públicas, este salto no se debe simplemente a una acumulación de parámetros, sino a una combinación de optimizaciones de ingeniería. Los análisis internacionales apuntan generalmente a cuatro direcciones:
- Destilación de IA más agresiva: las capacidades de 3.1 Pro se han destilado directamente en una base Flash más pequeña y rápida.
- Optimización de arquitectura dispersa: el enrutamiento de expertos es más preciso; no todos los parámetros se activan durante la generación de código largo.
- Sistema de enrutamiento interno mejorado: las tareas difíciles siguen automáticamente rutas de inferencia más profundas, mientras que las sencillas mantienen una latencia baja.
- Pipeline de inferencia eficiente: la latencia del primer token se mantiene estable por debajo de los 200 ms, con una menor degradación de velocidad durante las salidas largas.
Para los desarrolladores, la sensación inmediata es clara: al escribir componentes de React/Vue, ejecutar una explicación de SQL o generar código de visualización ejecutable, Flash ya puede reemplazar a Pro como opción predeterminada, dejando a Pro solo para tareas que requieran razonamiento pesado o planificación compleja de múltiples pasos.
🚀 Consejo de prueba: Si quieres verificar de primera mano la capacidad real de codificación de 3.2 Flash, te recomendamos acceder a través de la plataforma APIYI (apiyi.com) utilizando la interfaz compatible con OpenAI. Sugerimos preparar un conjunto de "prompts pesados" (como HTML largo, SVG complejos o reescritura de código de página completa) y utilizar el mismo script para comparar la calidad y estabilidad de la salida entre 3.2 Flash y 3.1 Pro.
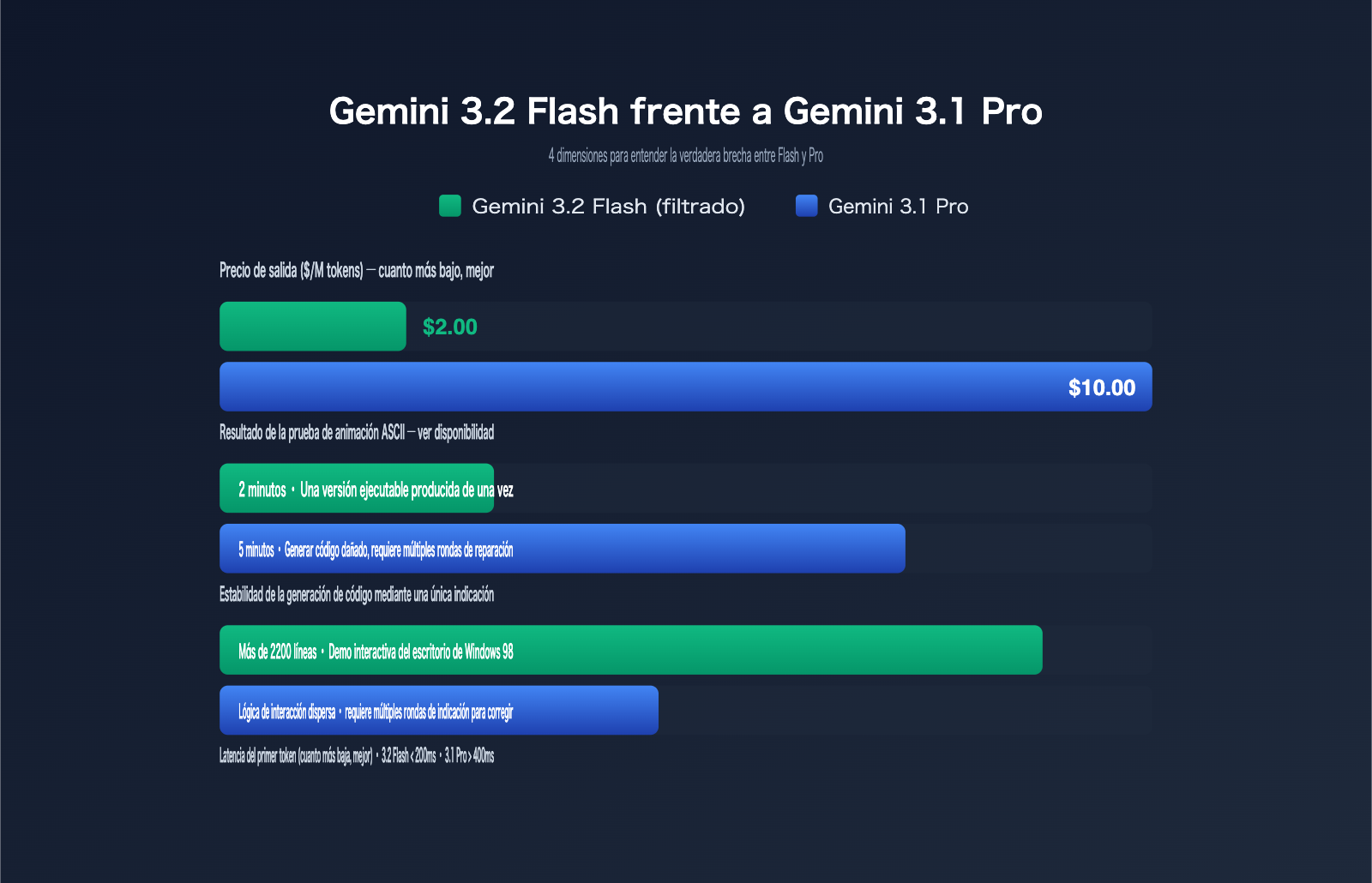
Estrategia de precios y estimación de costes de Gemini 3.2 Flash
La serie Flash siempre ha sido el arma secreta de Google para competir en precios, y con Gemini 3.2 Flash, han llevado esto a un nuevo nivel. Un precio de salida de 2,00 $ por millón de tokens significa que, en escenarios comunes de programación o generación de textos largos, su coste por unidad ya se acerca al nivel "mini" de GPT-5.5 Instant, pero con unas capacidades que rozan las de la versión Pro.
Comparativa de precios: Gemini 3.2 Flash vs. serie Gemini
La siguiente tabla compara los precios actuales de la serie Gemini visibles en AI Studio. Todos los datos provienen de páginas públicas o metadatos filtrados; los precios del nivel Pro se basan en la tarifa estándar de Vertex AI.
| Modelo | Entrada ($/M) | Salida ($/M) | Escenarios de uso |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | 0,25 | 1,50 | Tareas masivas de alta concurrencia y bajo coste |
| Gemini 3 Flash | 0,50 | 3,00 | Chat estándar / Código medio |
| Gemini 3.2 Flash (filtrado) | 0,25 | 2,00 | Generación de código largo / UI compleja / SVG |
| Gemini 3.1 Pro | 1,25 | 10,00 | Razonamiento complejo / Planificación multietapa |
Como se puede observar, el 3.2 Flash iguala al Flash-Lite en el precio de entrada, mientras que en el precio de salida reduce el coste del 3 Flash en un tercio, todo ello ofreciendo capacidades comparables al 3.1 Pro, que cuesta 10 $ por millón de tokens de salida. Para una tarea de código complejo que requiera 1 millón de tokens de salida, usar 3.2 Flash ahorra aproximadamente un 80 % en comparación con el 3.1 Pro. Los cuatro modelos mencionados ofrecen una interfaz compatible con OpenAI a través de APIYI (apiyi.com), lo que permite distribuir el tráfico dinámicamente según el negocio en un mismo proyecto, evitando tener que integrar diferentes SDK para cada nivel.
Ejemplo de estimación de costes mensuales para Gemini 3.2 Flash
Para visualizar mejor estas cifras, hagamos una estimación con un caso de uso real: imagina que estás desarrollando una herramienta de asistencia a la programación con IA que procesa 5000 solicitudes de generación de código al día, con una media de 1k tokens de entrada y 3k tokens de salida.
| Modelo seleccionado | Coste diario ($) | Coste mensual ($) | Nota |
|---|---|---|---|
| Gemini 3.1 Pro | 156,25 | 4687,50 | Gran razonamiento, pero excesivo para código |
| Gemini 3 Flash | 47,50 | 1425,00 | Solución estándar actual |
| Gemini 3.2 Flash (estimado) | 31,25 | 937,50 | Rendimiento cercano a Pro, coste reducido |
💰 Consejo de optimización de costes: Para proyectos con presupuestos ajustados, considera utilizar la API de la serie Gemini a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece pago por uso y una bolsa de créditos unificada, ideal para que equipos pequeños se integren rápidamente una vez que el 3.2 Flash esté disponible, sin necesidad de gestionar facturas de múltiples proveedores.
La interfaz "Liquid Glass" y las señales de Agents en Gemini 3.2 Flash
El modelo en sí no es la única novedad de esta filtración. Junto con Gemini 3.2 Flash, ha aparecido una nueva interfaz de usuario denominada "Liquid Glass", así como una pestaña oculta de "Agents (Beta)". Estos dos elementos revelan mucho más sobre la estrategia general de Google para el I/O 2026 que el propio modelo.
Puntos clave de la interfaz web de Gemini 3.2 Flash
"Liquid Glass" supone un cambio de estilo importante respecto al diseño plano anterior, caracterizado por:
- Caja de entrada de indicación con forma de píldora y reflejos degradados suaves.
- Capas de fondo semitransparentes que pulsan al ritmo de la conversación.
- Selector de modelos trasladado a un menú desplegable en la esquina superior izquierda, destacando la acción de "cambiar de modelo".
- Burbujas de chat con un uso más contrastado del espacio en blanco y bloques de código largos desplegados por defecto.
Esta interfaz sitúa la capacidad de "cambiar de modelo" en un lugar visualmente prominente, preparando el terreno para la matriz de modelos de la serie Gemini. Se educa al usuario para que "elija el modelo según la tarea", un concepto que encaja perfectamente con la filosofía de las plataformas de agregación de múltiples proveedores.
La estrategia agentic sugerida por Gemini 3.2 Flash y Agents (Beta)
Lo que resulta más interesante para los desarrolladores es la aparición de una pestaña incompleta de "Agents (Beta)" en la aplicación de Gemini para iOS. Si tenemos en cuenta la inversión constante de Google durante el último año en Gemini CLI, Agent Builder y Vertex AI Agent, es razonable deducir que el I/O 2026 presentará una línea estratégica dedicada a los agentes, donde Gemini 3.2 Flash se posicionará probablemente como el "cerebro predeterminado para agentes": con la velocidad suficiente para soportar bucles de varios pasos y el coste necesario para gestionar un alto consumo de tokens.
🎯 Recomendación de arquitectura: Si estás desarrollando tu propio marco de trabajo para agentes, te sugiero que utilices APIYI (apiyi.com) para situar la serie Gemini detrás de la misma capa de orquestación que los modelos de Claude o GPT. Así, cuando el 3.2 Flash esté disponible, solo tendrás que cambiar el campo
modelpara verificar si supera a las soluciones actuales como "cerebro de agente", evitando así depender de un único proveedor.
Ejemplo de integración y API unificada para Gemini 3.2 Flash
Aunque la API oficial de 3.2 Flash aún no se ha publicado, se espera que sus especificaciones de interfaz sean totalmente consistentes con la serie Gemini 3.x. A continuación, presento un ejemplo minimalista utilizando la interfaz unificada de APIYI, diseñado para que el cambio a 3.2 Flash en el futuro requiera prácticamente cero modificaciones.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.2-flash", # Reemplazar por el ID oficial del modelo tras su lanzamiento
messages=[
{"role": "user", "content": "Implementa un escritorio interactivo de Windows 98 usando solo HTML + Canvas en una página"}
],
)
print(response.choices[0].message.content)
Ver código completo con streaming y reintento de errores
from openai import OpenAI
from openai import APIError, RateLimitError
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
PROMPT = """Implementa una demo de un escritorio interactivo de Windows 98 usando solo HTML + Canvas,
requisitos: ventanas arrastrables, menú de inicio emergente en la esquina inferior izquierda, iconos de escritorio que abran ventanas al hacer doble clic."""
def call_gemini_3_2_flash(prompt: str, retries: int = 3):
for attempt in range(retries):
try:
stream = client.chat.completions.create(
model="gemini-3.2-flash",
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=8192,
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
return
except RateLimitError:
time.sleep(2 ** attempt)
except APIError as e:
print(f"\n[Error de API] {e}")
return
if __name__ == "__main__":
call_gemini_3_2_flash(PROMPT)
)
El diseño clave de este código reside en el desacoplamiento entre base_url y model: para cambiar entre Flash y Pro, solo necesitas modificar una línea en el campo model. El código de negocio, el manejo de errores y la lógica de streaming se reutilizan por completo, lo que resulta ideal para realizar evaluaciones A/B tras el lanzamiento.
Análisis del impacto de Gemini 3.2 Flash en desarrolladores y la industria
La razón por la que esta filtración ha generado tanto debate en la comunidad internacional no es simplemente porque "haya salido otro Flash", sino porque rompe el consenso tácito de que "Flash es barato pero solo sirve para tareas ligeras, mientras que Pro es caro pero necesario para código complejo".
Impacto en desarrolladores independientes y equipos pequeños
Para los desarrolladores independientes sensibles al presupuesto, 3.2 Flash supone un cambio radical. Tareas que antes requerían obligatoriamente un modelo Pro para completarse con estabilidad, como la "generación de código de páginas completas" o la "visualización compleja", ahora pueden delegarse a Flash, lo que podría reducir los costes mensuales de modelos entre un 50% y un 80%.
En cuanto a los equipos pequeños, el impacto se refleja en la forma del producto: funciones como asistentes de programación por IA, plataformas de visualización low-code o generadores de informes automatizados, que antes se limitaban por el alto coste de invocación de Pro, ahora pueden rediseñarse como capacidades residentes activadas bajo demanda.
Impacto en equipos grandes y arquitecturas multimodelo
Para equipos grandes con arquitecturas multimodelo ya establecidas, 3.2 Flash no reemplazará inmediatamente a Pro, pero obligará a que la estrategia de selección de modelos sea más granular: la capa de enrutamiento deberá elegir dinámicamente entre Flash o Pro según el tipo de tarea, en lugar de usar un único modelo para todo. Esto exige mayores capacidades en cuanto a pasarelas de modelos, facturación unificada y registro de logs. Es muy probable que las pasarelas simplificadas diseñadas para un solo modelo necesiten una actualización arquitectónica tras el I/O.
En concreto, los equipos grandes deberían planificar en tres niveles: primero, establecer una medición de tokens observable para separar el consumo real entre Flash y Pro; segundo, desacoplar las indicaciones de los modelos mediante un sistema de plantillas en lugar de codificar el modelo de forma rígida; y tercero, preparar mecanismos de cambio gradual (canary deployment) para migrar por módulos de negocio cuando 3.2 Flash esté oficialmente disponible, reduciendo así los riesgos en producción.
Impacto en la competencia
OpenAI lanzó el mismo día GPT-5.5 Instant, centrado en "reducir alucinaciones y fortalecer la veracidad". Esto se posiciona directamente frente a la estrategia de Google de "bajar precios + mejorar capacidades de codificación": OpenAI apuesta por escenarios verticales de alto valor, mientras que Google apuesta por la codificación masiva y escenarios de agentes. Por su parte, Anthropic aún no ha respondido directamente a esta filtración, pero la "prima de capacidad de codificación" que la serie Claude ha mantenido durante mucho tiempo se verá presionada por los precios de la categoría Flash.
Preguntas frecuentes sobre Gemini 3.2 Flash
Q1: ¿Cuándo estará disponible oficialmente la API de Gemini 3.2 Flash?
Siguiendo las pistas filtradas y el ritmo de lanzamientos de Google en eventos I/O anteriores, es muy probable que Gemini 3.2 Flash se anuncie oficialmente durante el discurso principal del I/O 2026, entre el 19 y 20 de mayo, y que esté disponible a través de Vertex AI y AI Studio ese mismo día o al siguiente. Las plataformas de agregación de terceros suelen completar la integración en un plazo de 24 a 48 horas. Te recomendamos estar atento a los anuncios de nuevos modelos en APIYI apiyi.com para que puedas realizar pruebas con una interfaz unificada en cuanto esté disponible.
Q2: ¿Reemplazará Gemini 3.2 Flash a Gemini 3.1 Pro?
No lo reemplazará por completo a corto plazo. El modelo 3.2 Flash supera las expectativas en tareas de codificación, generación de código extenso y manejo de SVG / Canvas, pero en tareas de razonamiento de cadena larga, planificación compleja de múltiples pasos o escenarios financieros/legales que requieren cadenas causales estrictas, el modelo Pro sigue siendo más estable. La estrategia lógica es el enrutamiento por tareas: usa 3.2 Flash para codificación e interfaz de usuario, y 3.1 Pro para razonamiento profundo y decisiones de alto riesgo. Puedes gestionar la distribución del modelo en la capa de puerta de enlace (gateway) usando el mismo código, sin necesidad de reescribir tu lógica de negocio.
Q3: ¿Es real la generación de 2200 líneas de código de Gemini 3.2 Flash?
El "demo de escritorio de Windows 98 de 2200 líneas" que circula en la comunidad de desarrolladores internacional proviene de muestras reales probadas en el modo Canvas de AI Studio. Lo que se puede verificar de forma independiente es que la estabilidad de 3.2 Flash al generar código ejecutable extremadamente largo en una sola indicación es, efectivamente, muy superior a la de 3 Flash y 3.1 Pro. Aunque la réplica completa requiere que la API oficial esté abierta, esta mejora en la "estabilidad de salida larga" ha sido confirmada repetidamente por múltiples evaluadores independientes.
Q4: ¿Cuál es la ventana de contexto de Gemini 3.2 Flash?
Aunque los metadatos filtrados no muestran una cifra directa, al analizar las especificaciones de la serie Gemini 3.x, es muy probable que 3.2 Flash mantenga la ventana de contexto de 1M de tokens. Esto es fundamental para procesar repositorios de código extensos, documentos completos y transcripciones de video, y es la base física que le permite generar de forma estable más de 2000 líneas de código.
Q5: ¿Cómo pueden los desarrolladores acceder a Gemini 3.2 Flash lo más rápido posible?
Una vez lanzado oficialmente, la ruta más estable para los desarrolladores es a través de plataformas de agregación accesibles localmente. Recomendamos usar APIYI apiyi.com para acceder a Gemini 3.2 Flash; esta plataforma utiliza una interfaz compatible con OpenAI, lo que permite reutilizar el código existente sin problemas. Solo necesitas modificar los campos base_url y model para invocar Gemini, Claude, GPT y otros modelos dentro del mismo proyecto, facilitando la evaluación y el cambio entre ellos.
Resumen: ¿Qué significa la filtración anticipada de Gemini 3.2 Flash?
Volviendo a la frase inicial: "La conferencia aún no ha comenzado y Google ya no puede ocultarlo". Desde el lanzamiento silencioso en AI Studio el 5 de mayo hasta hoy, la comunidad internacional ha desglosado Gemini 3.2 Flash en todos sus aspectos: ID del modelo, interfaz Liquid Glass, etiquetas de agentes y el demo de 2200 líneas de código. Esto no es solo una filtración de producto, sino que envía tres señales claras:
- La categoría Flash sube de nivel: Google está redefiniendo la clasificación de modelos con una combinación de "bajo costo + alta capacidad de codificación".
- La estrategia de Agentes sale a la luz: Es muy probable que 3.2 Flash se convierta en la base predeterminada para aplicaciones de agentes.
- El valor de la agregación multimodelo se amplifica: Quien pueda integrar y evaluar modelos más rápido, capturará la ventana de oportunidad.
Para los desarrolladores, lo importante no es apostar por los detalles específicos del lanzamiento en el I/O, sino preparar con antelación una infraestructura de ingeniería unificada para la integración, evaluación y facturación, de modo que puedan realizar pruebas de carga en cuanto 3.2 Flash esté disponible. Recomendamos usar APIYI apiyi.com para validar resultados rápidamente y obtener datos reales de tus escenarios de negocio la misma noche en que termine el discurso principal del I/O, en lugar de esperar a los benchmarks de la comunidad.
Autor: Equipo técnico de APIYI — Especialistas en ingeniería de API para Modelos de Lenguaje Grande. Si deseas conocer más sobre los datos de costo y rendimiento de las series Gemini, Claude y GPT en escenarios de negocio reales, visita APIYI apiyi.com para obtener los informes de evaluación más recientes y cuotas de prueba gratuitas.