Nota del autor: Basado en información filtrada de las pruebas de escala de grises en LM Arena, presento un análisis completo de las 8 mejoras clave de gpt-image-2 frente a gpt-image-1.5, incluyendo comparativas en renderizado de texto, realismo, salida 4K, velocidad y generación de capturas de pantalla de UI.
A principios de abril de 2026, tres modelos de imagen anónimos, maskingtape-alpha, gaffertape-alpha y packingtape-alpha, aparecieron discretamente en la plataforma de evaluación LM Arena. Múltiples probadores tempranos informaron que su precisión en el renderizado de texto se acerca al 99%, la velocidad de generación es de solo unos 3 segundos y cuentan con soporte nativo para salida 4K; la comunidad coincide en que se trata del próximo gpt-image-2 de OpenAI.
Esto no es vaporware (producto humo): los registros de pruebas públicas de LM Arena, las capturas de pantalla comparativas de múltiples evaluadores independientes y el ciclo histórico de pruebas de OpenAI (que suele preceder al lanzamiento oficial en 2-4 semanas) apuntan a la misma conclusión. Este artículo comparará sistemáticamente las ocho mejoras clave de gpt-image-2 frente a gpt-image-1.5.
Valor central: Al terminar de leer este artículo, comprenderás claramente los avances específicos de gpt-image-2 en dimensiones como texto, realismo, 4K, velocidad y restauración de UI, así como la forma de migrar sin problemas desde el primer día en que se abra la API.

Puntos clave de gpt-image-2
| Dimensión de mejora | Estado actual gpt-image-1.5 | Mejora en gpt-image-2 |
|---|---|---|
| Renderizado de texto | Útil para títulos cortos (1-5 palabras) | Precisión a nivel de carácter ~99% |
| Velocidad de generación | 8-18 segundos | ~3 segundos (3-5 veces más rápido) |
| Resolución máxima | 1536×1024 | 2048×2048 / 4096×4096 |
| Soporte panorámico | Solo 1:1, 4:3, 3:4 | Nuevo formato panorámico 16:9 |
| Realismo | Existe un "filtro amarillo de IA" | Retratos/productos indistinguibles |
El significado general de la actualización a gpt-image-2
El texto ya no es un punto débil. En la era de gpt-image-1.5, la mayoría de los modelos de imagen fallaban al renderizar texto de más de 5-6 palabras. Sin embargo, los evaluadores de LM Arena informan que las etiquetas de UI, letreros y textos en carteles generados por gpt-image-2 casi no requieren retoques posteriores. Esto significa que la creatividad publicitaria localizada, los mockups de UI y las imágenes para redes sociales ya no necesitarán maquetación manual.
Del razonamiento en dos etapas al razonamiento en una sola etapa. Mientras que gpt-image-1.5 todavía se basa en una canalización de dos etapas, gpt-image-2, según los evaluadores, se ha desacoplado como un modelo de imagen independiente que utiliza una arquitectura de inferencia única. Este es el soporte subyacente para la velocidad de 3 segundos, lo que también implica que el rendimiento de las canalizaciones por lotes podría aumentar en un orden de magnitud.

Análisis detallado de las 8 grandes mejoras de gpt-image-2 frente a gpt-image-1.5
Mejora 1: Renderizado de texto casi perfecto
Los evaluadores de LM Arena informan que la precisión a nivel de carácter de gpt-image-2 es de aproximadamente el 99%, logrando que el texto se integre de forma natural en la escena (como en interfaces de usuario, carteles o letreros), en lugar de parecer "flotante" sobre la imagen como ocurría con los modelos anteriores.
Este era un problema persistente que afectaba a todos los modelos de imagen principales (Midjourney, Stable Diffusion, Imagen, Flux), y finalmente ha sido resuelto de manera sistemática en gpt-image-2.
Mejora 2: Realismo capaz de engañar al ojo humano
Varios evaluadores han reportado que los retratos, selfies en la playa y primeros planos de productos generados por gpt-image-2 son tan realistas que resulta difícil determinar si fueron creados por una IA:
- Anatomía de las manos correcta: Las proporciones de los cinco dedos y los ángulos de las articulaciones son naturales.
- Reflejos precisos en gafas de sol: El contenido reflejado coincide perfectamente con el entorno.
- Desaparición del filtro amarillo: El "tono de IA" que impregnaba la era de gpt-image-1 ha desaparecido por completo.
Mejora 3: Conocimiento profundo del mundo
Cuando los evaluadores solicitaron "una tienda IKEA de noche", "una captura de pantalla de la página de inicio de YouTube" o "una escena de Minecraft con la interfaz de juego correcta", la capacidad de gpt-image-2 para recrear marcas, interfaces y entornos reales fue suficiente para "hacerse pasar" por una fotografía real.
Esto significa que el modelo comprende realmente las convenciones visuales del mundo real, y no solo la distribución estadística de los píxeles.
Mejora 4: Salida nativa en 4K
La salida máxima de gpt-image-1.5 era de solo 1536×1024, mientras que se espera que gpt-image-2 soporte de forma nativa 2048×2048 y 4096×4096, además de pantallas panorámicas 16:9.
| Escenario de aplicación | Experiencia gpt-image-1.5 | Experiencia gpt-image-2 |
|---|---|---|
| Impresión comercial | Requiere escalado posterior | 4K nativo, listo para imprimir |
| Visuales de marketing | Resolución insuficiente | Satisface necesidades de cartelería |
| Imágenes de producto en alta resolución | Requiere superresolución | Generación directa en una pasada |
| Miniaturas de video | Falta de formato 16:9 | Soporte nativo para pantalla panorámica |
Mejora 5: Generación más rápida (aprox. 3 segundos)
Los observadores de Arena han registrado tiempos de generación de aproximadamente 3 segundos, superando con creces los 10-20 segundos (o incluso los 35-55 segundos de la era gpt-image-1) que eran la norma en los modelos de imagen insignia anteriores.
Tanto para la UX interactiva (reducción significativa del tiempo de espera del usuario) como para las tuberías de procesamiento por lotes (aumento de 3 a 5 veces en la producción en el mismo tiempo), los beneficios serán directos.
Mejora 6: Renderizado de texto multilingüe
En las vistas previas, el renderizado de alfabetos latinos, CJK (chino, japonés, coreano) y escrituras de derecha a izquierda (árabe, hebreo) se muestra claro y legible.
Si se mantiene este rendimiento en el lanzamiento, la creación de anuncios localizados y maquetas de UI multilingües ya no requerirá maquetación manual, lo cual es una gran noticia para equipos de expansión internacional, comercio transfronterizo y gestión de contenido multilingüe.
Mejora 7: Generación de UI y capturas de pantalla
Los evaluadores destacaron especialmente la capacidad de recreación de interfaces de usuario: páginas web, interfaces de aplicaciones y ventanas del sistema operativo, con una precisión sorprendente. Es ideal para los siguientes escenarios:
- Exploración de diseño: Generación rápida de borradores conceptuales de UI.
- Material didáctico: Generación de capturas de pantalla de ejemplo para documentación técnica.
- Borradores conceptuales: Mostrar a los clientes interfaces de productos aún no desarrollados.
- Material para pruebas A/B: Generación masiva de diferentes estilos de interfaz para elegir.
Mejora 8: API disponible desde el lanzamiento
Tan pronto como OpenAI abra la API, APIYI la tendrá disponible de inmediato. Tus claves, saldo y facturación actuales en apiyi.com permanecen intactos: no necesitas registrar nuevas cuentas, cambiar el SDK ni modificar tu código de negocio.
Sugerencia de migración: Antes del lanzamiento oficial de gpt-image-2, puedes probar el actual gpt-image-1.5 a través de APIYI apiyi.com para familiarizarte con la configuración de
base_urly la estructura de parámetros. El día del lanzamiento oficial, solo tendrás que sustituir el campomodelpara completar la migración.
Guía de inicio rápido de gpt-image-2 (Guía de migración de API)
Ejemplo minimalista (basado en gpt-image-1.5, solo sustituye el nombre del modelo en la versión final)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-1.5", # Sustituir por "gpt-image-2" tras el lanzamiento oficial
prompt="A modern cafe menu board with hand-lettered text 'Today Special: Espresso $4.50'",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Ver código de implementación completo (incluye 4K, 16:9 y manejo de errores)
from openai import OpenAI
from typing import Optional, Literal
def generate_image(
prompt: str,
model: str = "gpt-image-1.5",
size: Literal["1024x1024", "1536x1024", "1024x1536", "2048x2048", "4096x4096"] = "1024x1024",
quality: Literal["low", "medium", "high", "auto"] = "high",
n: int = 1
) -> Optional[str]:
"""
Genera imágenes, compatible con gpt-image-1.5 y el futuro gpt-image-2
Args:
prompt: Indicación de texto (máximo 2000 tokens)
model: Nombre del modelo (se puede cambiar a gpt-image-2 tras el lanzamiento)
size: Tamaño de salida (gpt-image-2 soportará 2K/4K)
quality: Nivel de calidad
n: Cantidad de imágenes a generar (actualmente solo soporta 1)
Returns:
URL temporal de la imagen generada (válida por 24 horas)
"""
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality,
n=n
)
return response.data[0].url
except Exception as e:
print(f"Error en la generación de imagen: {e}")
return None
url = generate_image(
prompt="Product hero shot: sleek wireless earbuds on marble, 'AuraPods Pro' label visible",
model="gpt-image-1.5",
size="1536x1024",
quality="high"
)
print(f"URL de la imagen: {url}")
Sugerencia de la plataforma: Obtén saldo de prueba gratuito a través de APIYI apiyi.com para experimentar al instante con las capacidades más recientes de gpt-image-1.5. El día del lanzamiento oficial de gpt-image-2, podrás cambiar de modelo sin necesidad de realizar ningún cambio en tu código.
Comparativa de soluciones: gpt-image-2 frente a gpt-image-1.5
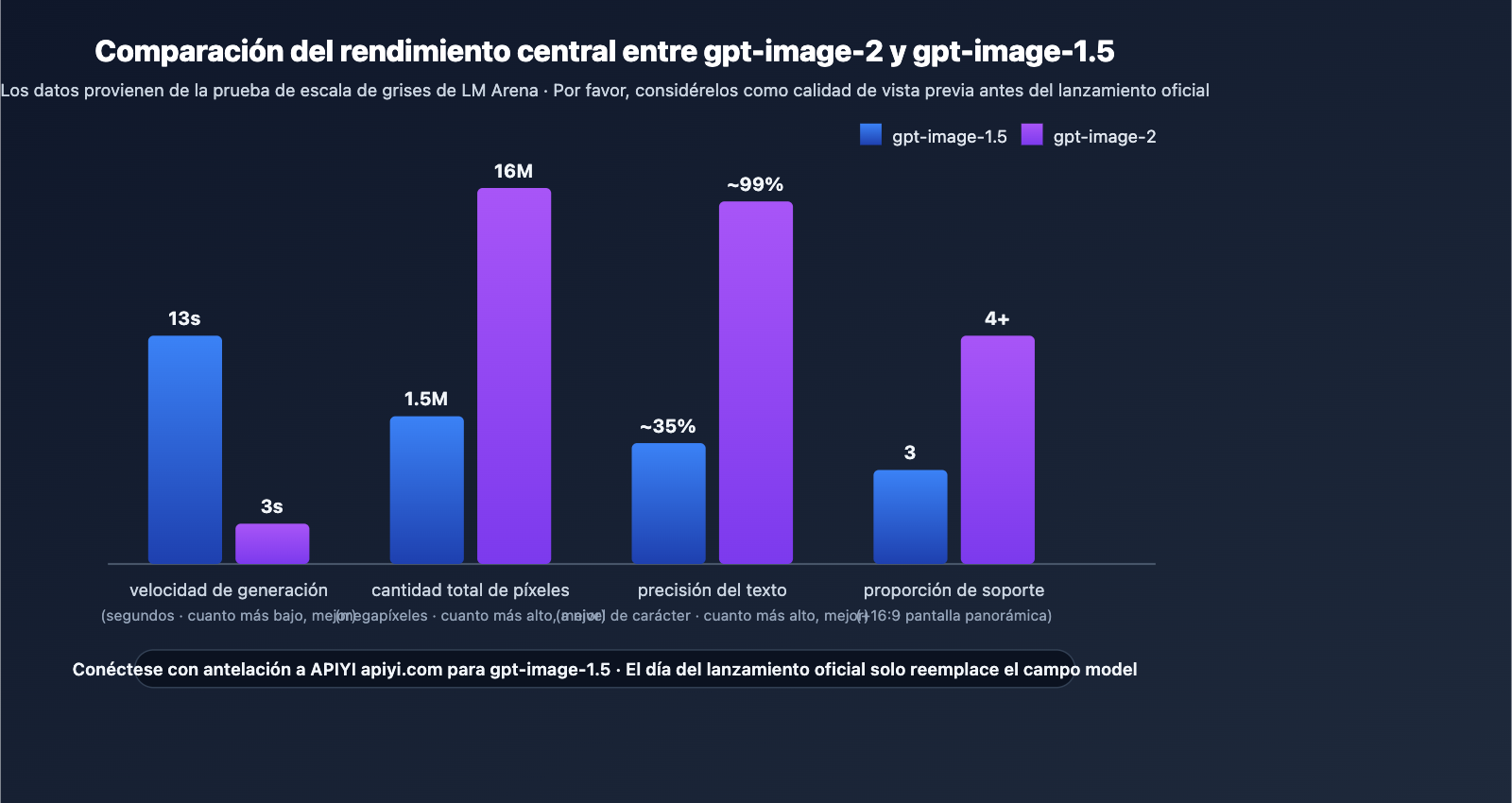
| Dimensión | gpt-image-1.5 (dic-2025) | gpt-image-2 (est. abr-may 2026) | Significado de la diferencia |
|---|---|---|---|
| Arquitectura | Inferencia en dos etapas | Inferencia de un solo paso | Aumento drástico en el rendimiento |
| Velocidad | 8-18 segundos | ~3 segundos | 3-5 veces más rápido |
| Resolución máx. | 1536×1024 | 4096×4096 | Listo para impresión comercial |
| Relación aspecto | 1:1/3:4/4:3 | + 16:9 panorámico | Ideal para miniaturas de video |
| Precisión texto | Títulos cortos (1-5 palabras) | ~99% a nivel de carácter | Adiós a la composición manual |
| Multilingüe | Inestable en no latinos | CJK/RTL claro y legible | Beneficia al contenido localizado |
| Fidelidad UI | Regular | "Simula" capturas reales | Útil para diseño y tutoriales |
Análisis de actualización
Comparado con Midjourney: Midjourney sigue liderando en la generación de estilos artísticos. Sin embargo, su acceso vía API es limitado y su renderizado de texto ha sido históricamente débil. En contraste, gpt-image-2 ofrece una API estándar y una precisión de texto del 99%, siendo ideal para integrarse en flujos de trabajo automatizados.
Comparado con Imagen 2: Google Imagen 2 tiene ventaja en el realismo fotográfico. No obstante, su ecosistema de API es relativamente cerrado y el soporte para idiomas distintos al inglés es limitado. Por el contrario, gpt-image-2 es más equilibrado en texto multilingüe, fidelidad de UI y velocidad, lo que lo hace perfecto para equipos con proyección internacional.
Comparado con nano-banana-pro: nano-banana-pro destaca por su relación calidad-precio. Sin embargo, su capacidad de salida en 4K y su fidelidad de marca no alcanzan las expectativas de lo que será gpt-image-2. Para escenarios de impresión comercial y marketing de marca, gpt-image-2 sigue siendo la opción más sólida.
Nota sobre la comparativa: Algunos de los datos anteriores provienen de pruebas públicas en LM Arena y otros de comentarios de probadores tempranos. Por favor, considera gpt-image-2 como una vista previa antes de su lanzamiento oficial. Te recomendamos probar gpt-image-1.5 en APIYI (apiyi.com) para familiarizarte con la estructura de parámetros.
Escenarios de aplicación de gpt-image-2
Considera actualizar a gpt-image-2 si te encuentras en estos escenarios:
- Escenario 1 — Impresión comercial: La salida nativa en 4K resuelve los cuellos de botella de resolución para carteles, catálogos y publicidad a gran escala.
- Escenario 2 — Publicidad localizada: El renderizado de texto multilingüe permite que los creativos se olviden de la composición manual, aumentando significativamente la eficiencia de los equipos globales.
- Escenario 3 — Exploración de diseño UI: Permite a gestores de producto y diseñadores generar rápidamente borradores conceptuales y materiales para tutoriales.
- Escenario 4 — Imágenes principales de e-commerce: El realismo a nivel de retrato y la precisión en el texto del producto son ideales para la imagen visual de marketing.
- Escenario 5 — Contenido de video: El soporte para formato panorámico 16:9 facilita la generación masiva de miniaturas para YouTube y videos cortos.
Sugerencia de uso: Si actualmente estás evaluando una API de imágenes, te recomendamos integrarte primero con gpt-image-1.5 a través de APIYI (apiyi.com). Una vez que se lance la versión oficial, solo tendrás que reemplazar el campo
modelpara realizar una actualización sin problemas.
Preguntas frecuentes (FAQ)
Q1: ¿Qué es gpt-image-2?
gpt-image-2 es el modelo de generación de imágenes de próxima generación de OpenAI, cuyo lanzamiento está previsto para abril o mayo de 2026. Según las pruebas beta en LM Arena, este modelo utiliza una arquitectura de inferencia de una sola pasada, cuenta con una precisión de renderizado de texto de aproximadamente el 99 %, una velocidad de unos 3 segundos y soporte nativo para salida 4K. Es una actualización importante tras el lanzamiento de gpt-image-1 (abril de 2025) y gpt-image-1.5 (diciembre de 2025).
Q2: ¿Cuál es la diferencia entre gpt-image-2 y gpt-image-1.5?
Las diferencias clave se resumen en ocho dimensiones: renderizado de texto (de 5 palabras a 99 % de precisión), velocidad (de 8-18 segundos a 3 segundos), resolución (de 1536×1024 a 4096×4096), relación de aspecto (se añade 16:9), realismo (eliminación del filtro amarillento), conocimiento del mundo (precisión en marcas/UI), multilingüismo (claridad en CJK/RTL) y fidelidad de UI (capacidad para simular capturas de pantalla reales). Aunque gpt-image-1.5 sigue siendo suficiente para títulos cortos y relaciones de aspecto estándar, se recomienda esperar a gpt-image-2 para impresión comercial, localización y escenarios de UI.
Q3: ¿Cuándo se lanzará gpt-image-2?
Hasta el 17 de abril de 2026, OpenAI no ha realizado un anuncio oficial. Basándose en los ciclos históricos de pruebas beta (que suelen durar de 2 a 4 semanas antes del lanzamiento oficial), la industria estima una ventana de lanzamiento entre finales de abril y mediados de mayo de 2026. Los tres modelos con nombre en clave en LM Arena (maskingtape-alpha, gaffertape-alpha y packingtape-alpha) se encuentran actualmente en pruebas A/B.
Q4: ¿Para qué casos de uso es más adecuado gpt-image-2?
Es ideal para los siguientes escenarios específicos:
- Pósteres/catálogos de calidad de impresión comercial: La salida nativa en 4K elimina la necesidad de realizar un escalado posterior.
- Imágenes para redes sociales localizadas: El renderizado de texto multilingüe evita tener que usar Photoshop para maquetar.
- Borradores de diseño de UI: Generación de capturas de pantalla de ejemplo para exploración de productos y tutoriales.
- Imágenes principales de marketing para comercio electrónico: Retratos realistas combinados con texto de producto preciso.
- Miniaturas para plataformas de vídeo: Generación por lotes con relación de aspecto nativa 16:9.
Q5: ¿Cómo puedo invocar gpt-image-2 rápidamente a través de la API?
Se recomienda realizar la integración previa a través de APIYI (apiyi.com) para estar listo en cuanto se lance gpt-image-2:
- Visita apiyi.com para registrar una cuenta y obtener tu clave API.
- Utiliza
base_url=https://vip.apiyi.com/v1para realizar llamadas con los parámetros de gpt-image-1.5 con los que ya estás familiarizado. - El día del lanzamiento de gpt-image-2, solo tendrás que cambiar el campo
modeldegpt-image-1.5agpt-image-2.
APIYI lanza los nuevos modelos al mismo tiempo que OpenAI, por lo que tus claves API, saldo y facturación actuales se mantienen, sin necesidad de registrar una cuenta nueva o cambiar el SDK.
Q6: ¿Qué limitaciones o incertidumbres tiene gpt-image-2?
Las principales incertidumbres se deben a que aún no se ha realizado el lanzamiento oficial:
- Precios desconocidos: gpt-image-1.5 redujo su precio en un 20 % respecto a gpt-image-1; el precio de gpt-image-2 está pendiente de confirmación oficial.
- Límites de velocidad: Es posible que existan cuotas de llamada durante el periodo de lanzamiento inicial; se recomienda utilizar un servicio proxy de API para evitar problemas de arranque en frío.
- Posibles ajustes en capacidades: Puede haber diferencias entre la versión de prueba de LM Arena y la versión final; por favor, considéralo como una vista previa de la calidad.
- Plan de contingencia: Si tu proyecto es urgente, gpt-image-1.5 sigue siendo una opción insignia estable y disponible.
Q7: ¿Reemplazará gpt-image-2 a DALL-E 3?
Siguiendo el ritmo de lanzamientos de OpenAI, se espera que DALL-E 3 se retire gradualmente tras el lanzamiento oficial de gpt-image-2. En cuanto a la ruta de migración, la serie gpt-image se ha convertido en la apuesta principal de la compañía y la estructura de parámetros de su API ya es estable. Se recomienda que los nuevos proyectos adopten directamente gpt-image-1.5 o esperen a gpt-image-2 para evitar invertir demasiado trabajo de personalización en DALL-E 3.
Q8: ¿Los modelos de la serie «tape» en LM Arena son definitivamente gpt-image-2?
No hay confirmación oficial, pero cuatro evidencias apuntan fuertemente a OpenAI:
- El estilo de nomenclatura (serie "tape") coincide con los hábitos históricos de nombres en clave de OpenAI.
- Sus capacidades de renderizado de texto (99 %) y conocimiento del mundo superan a todos los modelos públicos actuales.
- El periodo de prueba coincide con el ritmo habitual de pruebas beta de OpenAI.
- El estilo de salida del modelo es consistente con la serie gpt-image (no sigue el estilo de Midjourney/Imagen).
Se recomienda seguir atento a los anuncios oficiales y esperar al lanzamiento sincronizado en APIYI (apiyi.com).
Puntos clave de gpt-image-2
- Modelo de próxima generación: El buque insignia de imagen de OpenAI para 2026, reemplaza a gpt-image-1.5; la arquitectura pasa de dos etapas a una sola inferencia.
- Ocho grandes mejoras: Texto al 99 %, velocidad de 3 segundos, 4K nativo, 16:9, realismo, conocimiento del mundo, multilingüismo y fidelidad de UI.
- Escenarios de aplicación: Prioridad de actualización para impresión comercial, publicidad localizada, borradores de UI, imágenes principales de comercio electrónico y miniaturas de vídeo.
- Ritmo de lanzamiento: Previsto entre finales de abril y mediados de mayo de 2026; el nombre en clave actual de la beta es la serie "tape".
- Migración fluida: Integra gpt-image-1.5 con antelación a través de APIYI (apiyi.com) y, el día del lanzamiento, solo tendrás que sustituir el campo
model.
Resumen
Puntos clave de la comparativa entre gpt-image-2 y gpt-image-1.5:
- Salto cualitativo: Los tres indicadores principales (texto, velocidad y resolución) alcanzan o superan los estándares de producción; ya no se trata de herramientas que "funcionan pero requieren retoques posteriores".
- Nuevos escenarios: Se habilitan por primera vez escenarios de uso real como la impresión comercial, la localización multilingüe y la recreación de interfaces de usuario (UI), reduciendo significativamente los costes de postprocesamiento manual.
- Migración sin fricciones: La estructura de parámetros de la API es compatible con gpt-image-1.5, por lo que los equipos que se preparen con antelación podrán realizar la transición el mismo día del lanzamiento sin realizar cambios.
Para la toma de decisiones en los equipos, recomendamos integrar gpt-image-1.5 a través de APIYI (apiyi.com) para familiarizarse con los parámetros y el flujo de trabajo. La plataforma ofrece cuotas gratuitas y una interfaz unificada; el día del lanzamiento de gpt-image-2, solo tendrá que cambiar el campo model para disfrutar de las ocho mejoras principales.
Lecturas recomendadas
Si te interesa gpt-image-2, te recomendamos seguir leyendo:
- 📘 Guía completa de invocación de la API de gpt-image-1.5: Domina los parámetros y las mejores prácticas del modelo de imagen insignia actual.
- 📊 Comparativa de precios y calidad: gpt-image-2 vs nano-banana-pro: Conoce la estructura de costes de las principales API de imagen.
- 🚀 Optimización de invocaciones por lotes en entornos de producción para la API de generación de imágenes: Explora estrategias de tuberías (pipelines) por lotes, concurrencia y caché.
📚 Referencias
-
Análisis de MindStudio: Interpretación integral de "What Is GPT Image 2"
- Enlace:
mindstudio.ai/blog/what-is-gpt-image-2 - Descripción: Recopilación sistemática de la matriz de capacidades de gpt-image-2 realizada por un blog internacional de alto ranking.
- Enlace:
-
Análisis de filtraciones de getimg.ai: Rumores, filtraciones y fecha de lanzamiento de GPT Image 2
- Enlace:
getimg.ai/blog/gpt-image-2-rumours-leaks-release-date-2026 - Descripción: Observaciones de primera mano sobre el rendimiento de los tres modelos con nombre en clave "tape" en LM Arena.
- Enlace:
-
Blog oficial de OpenAI: Anuncio de la actualización de las funciones de imagen de ChatGPT
- Enlace:
openai.com/index/new-chatgpt-images-is-here - Descripción: Explicación oficial y autorizada sobre la ruta de evolución de la serie gpt-image.
- Enlace:
-
Documentación de parámetros de gpt-image-1.5: Recopilado por EvoLink
- Enlace:
evolink.ai/blog/gpt-image-1-5-guide-features-comparison-access - Descripción: Parámetros detallados sobre la velocidad, resolución y niveles de calidad de gpt-image-1.5.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más información, visita el centro de documentación de APIYI en docs.apiyi.com.