La lentitud en las invocaciones de la API de Qwen3.5 de Alibaba Cloud es uno de los temas más comentados en la comunidad de desarrolladores últimamente. Si bien se esperaría que Qwen3.5-Plus y Qwen3.5-Flash, modelos desarrollados internamente por Alibaba, tuvieran un rendimiento excelente en su propia infraestructura, la experiencia real ha desconcertado a muchos desarrolladores. Es confuso que los modelos propios de la empresa funcionen lentamente en su propia plataforma, y que las llamadas a modelos de terceros como GLM-5, Kimi-K2.5 y MiniMax-M2.5 a través de la API de Alibaba Cloud sean aún más lentas.
Valor principal: Este artículo analizará en profundidad las causas fundamentales de la lenta respuesta de la API de Alibaba Cloud desde tres perspectivas: suministro de potencia computacional, diseño de arquitectura y estrategia de programación. Además, presentaremos tres soluciones alternativas verificadas para ayudarte a obtener una experiencia de inferencia más rápida en tus proyectos reales.
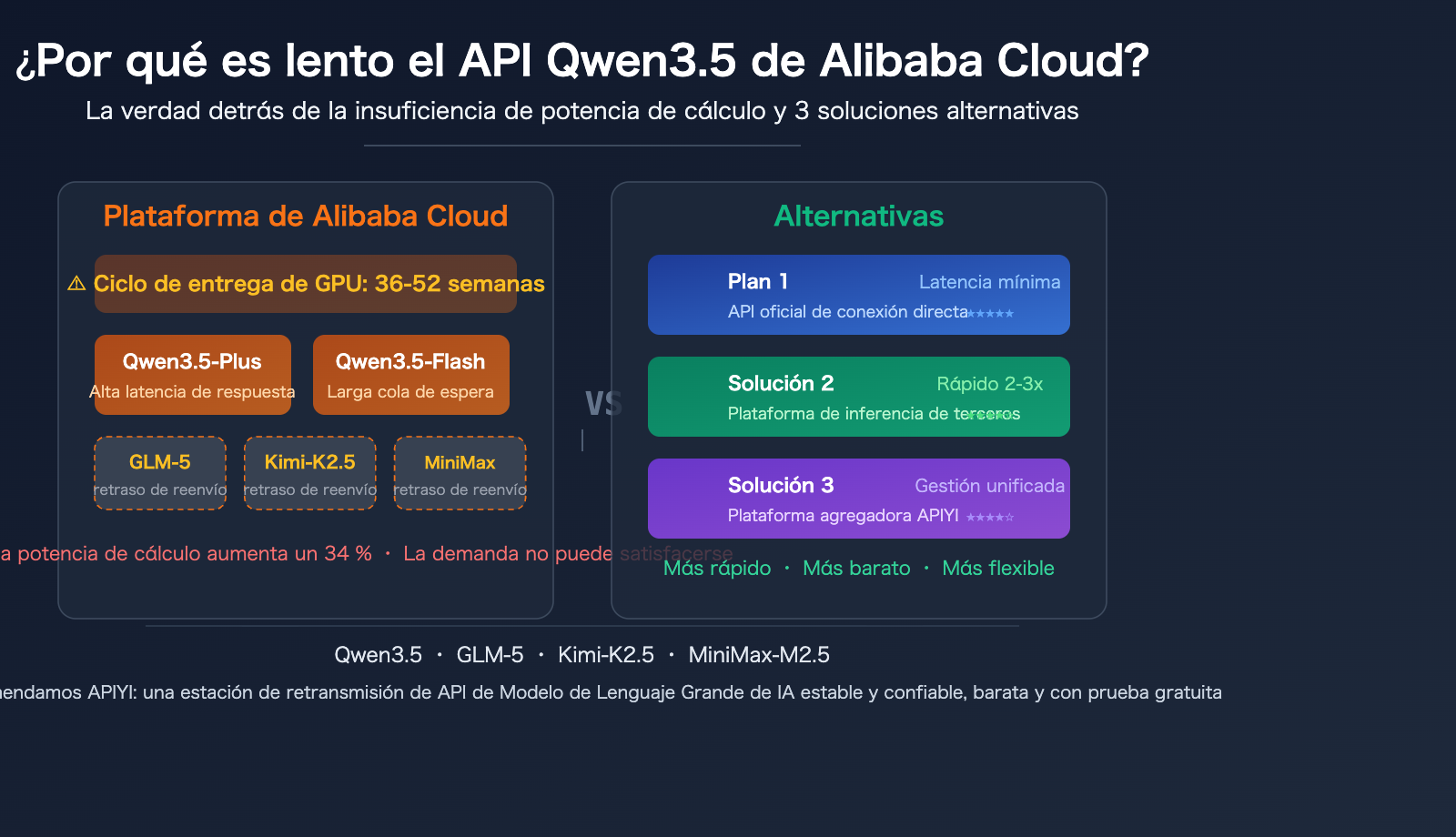
Análisis de las 5 principales razones de la lentitud de la API Qwen3.5 de Alibaba Cloud
Razón 1: Grave escasez de suministro global de potencia de cálculo de GPU
Este no es solo un problema de Alibaba Cloud, sino una contradicción estructural en toda la industria. El ciclo de entrega de GPU de nivel de centro de datos para 2026 se ha extendido a 36-52 semanas. Los ejecutivos de Alibaba Cloud han admitido públicamente que la escasez generalizada de fabricantes de semiconductores, chips de memoria y dispositivos de memoria convertirá la cadena de suministro en un "cuello de botella importante" en los próximos 2-3 años.
| Indicador de suministro de potencia de cálculo | 2025 | 2026 | Tendencia de cambio |
|---|---|---|---|
| Ciclo de entrega de GPU | 12-24 semanas | 36-52 semanas | ↑ Extensión significativa |
| Crecimiento de ingresos de IA de Alibaba Cloud | — | 34% | Explosión de la demanda |
| Ajuste de precios de potencia de cálculo de Alibaba Cloud | Precio base | Aumento máximo del 34% | ↑ A partir del 18 de abril de 2026 |
| Proporción del gasto global en inferencia de IA | 42% | 55% | Supera el entrenamiento por primera vez |
Alibaba Cloud ha anunciado oficialmente que aumentará los precios de la potencia de cálculo de IA a partir del 18 de abril de 2026, con un aumento de hasta el 34%. La razón directa es la "explosión de la demanda global de IA y el aumento de los precios de la cadena de suministro". Los ingresos de Alibaba Cloud han aumentado un 34%, pero han declarado públicamente que aún no pueden satisfacer la demanda, este es el contexto macro de la lentitud de la API Qwen3.5.
Razón 2: Consumo de potencia de cálculo de la arquitectura del modelo Qwen3.5
La familia Qwen3.5 adopta la arquitectura MoE (Mixture of Experts). La versión insignia Qwen3.5-397B-A17B tiene un total de 397 mil millones de parámetros, activando 17 mil millones de parámetros en cada inferencia. Incluso el Qwen3.5-Flash, diseñado para ser ligero (basado en 35B-A3B), admite de forma nativa una ventana de contexto de 1 millón de tokens y entrada multimodal (texto + imagen + video).
| Versión del modelo | Parámetros totales | Parámetros activados | Contexto predeterminado | Soporte multimodal |
|---|---|---|---|---|
| Qwen3.5-397B-A17B (Insignia) | 397 mil millones | 17 mil millones | 262K → 1M | Texto + Imagen + Video |
| Qwen3.5-Plus (versión API) | No revelado | No revelado | 1M | Texto + Imagen + Video |
| Qwen3.5-Flash (versión API) | 35 mil millones | 3 mil millones | 1M | Texto + Imagen + Video |
| Qwen3.5-122B-A10B | 122 mil millones | 10 mil millones | 262K | Texto + Imagen + Video |
Estos modelos utilizan una arquitectura multimodal de fusión temprana (early-fusion) desde la etapa de entrenamiento, admitiendo de forma nativa el procesamiento unificado de texto, imágenes y videos. El precio de esta potente funcionalidad es: el costo computacional de cada solicitud es mucho mayor que el de los modelos de solo texto. Sumado a la ventana de contexto de nivel de millón de tokens, la ocupación de memoria y potencia de cálculo de una sola inferencia aumenta significativamente.
Razón 3: Retraso adicional de Alibaba Cloud en la reventa de modelos de terceros
Al llamar a modelos de terceros como GLM-5 (Zhipu AI), Kimi-K2.5 (Moonshot AI) y MiniMax-M2.5 a través de la plataforma DashScope de Alibaba Cloud, la ruta de la solicitud se convierte en:
Tu aplicación → Pasarela API de Alibaba Cloud → Capa de programación DashScope → Servicio de modelo de terceros
Cada capa de reenvío adicional introduce una capa de latencia. Lo que es más importante, cuando Alibaba Cloud revende estos modelos, la prioridad de asignación de recursos de GPU puede ser menor que la de los modelos propios, después de todo, la potencia de cálculo en sí es insuficiente. Los comentarios generales de los desarrolladores en el círculo son: la llamada a GLM-5, Kimi-K2.5, MiniMax-M2.5 a través de Alibaba Cloud es notablemente más lenta que la API oficial.
Razón 4: Optimización insuficiente de la estrategia de programación de inferencia
Las plataformas de inferencia de terceros especializadas (como SiliconFlow, Fireworks AI, Together AI) tienen ventajas significativas en eficiencia de inferencia a través de medios técnicos como núcleos CUDA personalizados, mecanismos de atención fusionados y programación de granularidad fina. Los datos de pruebas reales muestran:
- SiliconFlow: la velocidad de inferencia es hasta 2.3 veces más rápida que la de las plataformas en la nube de propósito general, y la latencia se reduce en un 32%.
- Fireworks AI: la tecnología FireAttention v2 afirma un aumento de velocidad de hasta 8 veces, con pruebas prácticas de aproximadamente 747 TPS.
- Together AI: a través de la decodificación especulativa y la cuantificación FP4, la velocidad de inferencia de modelos de código abierto se duplica.
Alibaba Cloud, como plataforma en la nube de propósito general, su programación de inferencia se centra más en la generalidad y la estabilidad, en lugar de la optimización extrema de la velocidad de inferencia. Esto tiene poco impacto cuando la potencia de cálculo es suficiente, pero la brecha se amplifica cuando la GPU es escasa.
Razón 5: Lucha por recursos multi-inquilinos
Como el mayor proveedor de servicios en la nube de China, Alibaba Cloud sirve a una gran cantidad de usuarios simultáneamente en su clúster de inferencia de IA. Durante los períodos pico, la lucha por los recursos de GPU conduce directamente a un aumento del tiempo de espera. Aunque el sistema de agrupación de recursos Aegaeon desarrollado por Alibaba Cloud afirma haber aumentado la utilización de GPU en un 82%, esto es esencialmente "cortar el pastel limitado en trozos más pequeños" y no puede resolver fundamentalmente la insuficiencia de la cantidad total de potencia de cálculo.
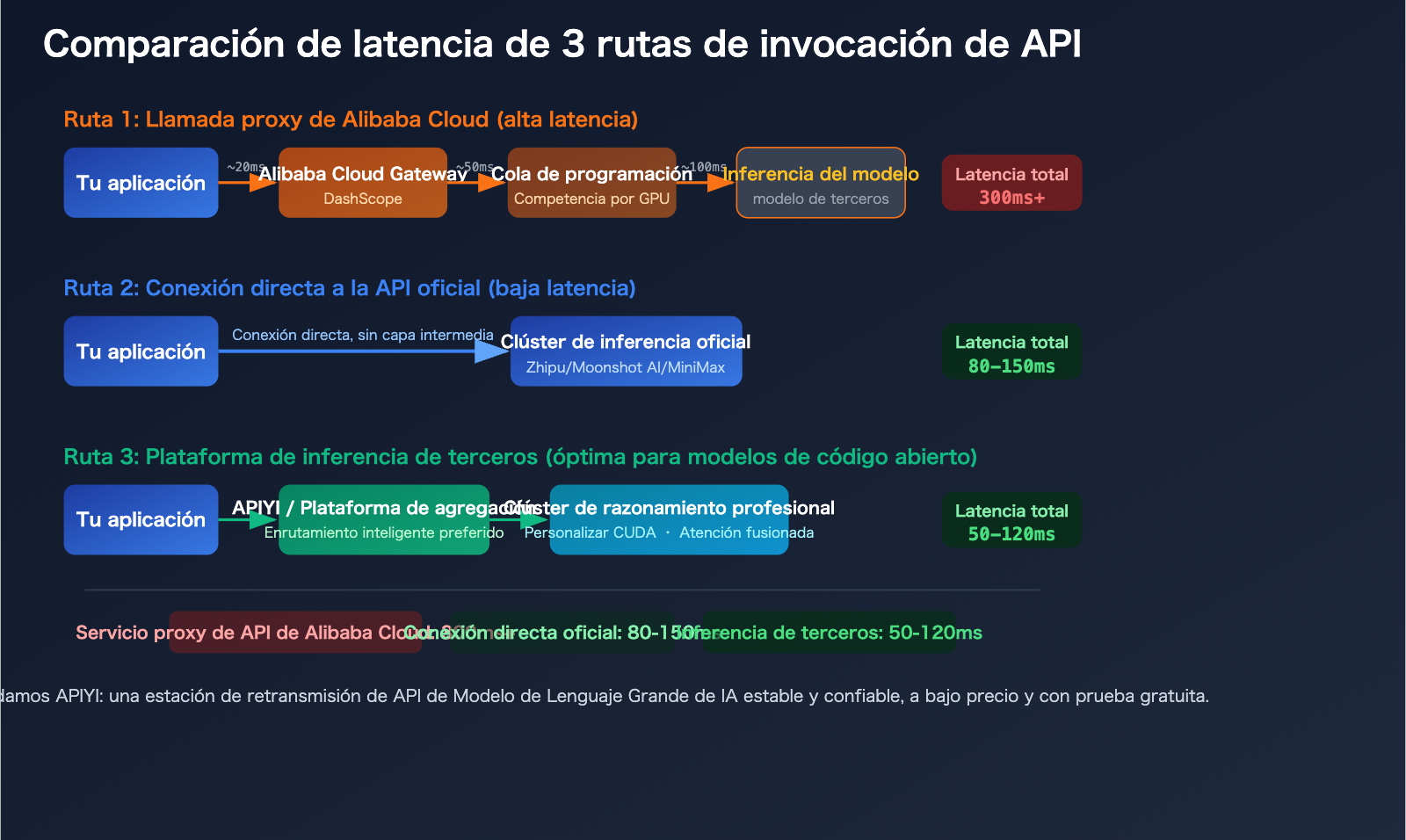
GLM-5、Kimi-K2.5、MiniMax-M2.5: Comparativa de latencia entre llamadas a través de Alibaba Cloud y API oficial
Una vez entendidas las razones, veamos escenarios concretos de invocación de modelos. A continuación, se presenta un análisis de las diferencias de experiencia entre 3 modelos populares en distintas plataformas.
Análisis de latencia de llamadas API para GLM-5 (Zhipu AI)
GLM-5 es el modelo insignia lanzado por Zhipu AI en febrero de 2026, con 744.000 millones de parámetros totales y 40.000 millones de parámetros activos, utilizando una arquitectura MoE. Fue entrenado en chips Ascend de Huawei, soporta 200.000 tokens de contexto y ya es de código abierto (licencia MIT).
Hecho clave: GLM-5 soporta de forma nativa el modo Agent, pudiendo descomponer tareas en subtareas de forma autónoma y generar directamente documentos de oficina profesionales (.docx, .pdf, .xlsx). Su precio es de $1.00/M tokens para entrada y $3.20/M tokens para salida.
Al invocar GLM-5 a través de Alibaba Cloud, las solicitudes deben pasar por capas adicionales de gateway y orquestación, lo que aumenta significativamente la latencia. En cambio, al conectarse directamente a la API oficial de Zhipu AI (bigmodel.cn), las solicitudes llegan directamente al clúster de inferencia propio de Zhipu, obteniendo una respuesta más rápida.
Análisis de latencia de llamadas API para Kimi-K2.5 (Moonshot AI)
Kimi-K2.5, lanzado en enero de 2026, es un modelo MoE de 1 billón de parámetros, activando solo 32.000 millones de parámetros por solicitud. Fue preentrenado con 15 billones de tokens mixtos de texto y visión, siendo multimodal de forma nativa.
Mayor atractivo: Función Agent Swarm, que puede coordinar hasta 100 Agents de IA especializados para trabajar juntos simultáneamente, reduciendo el tiempo de ejecución en 4.5 veces. Supera a Gemini 3 Pro en SWE-Bench Verified, y Cursor AI ha confirmado que su función Composer 2 se basa en la tecnología Kimi.
Al invocar Kimi-K2.5 a través del servicio proxy de API de Alibaba Cloud, la ruta de retransmisión adicional empeora la experiencia de este modelo de billones de parámetros que ya requiere una gran cantidad de cómputo. Se recomienda usar directamente la API oficial de Moonshot AI (platform.moonshot.ai).
Análisis de latencia de llamadas API para MiniMax-M2.5
MiniMax-M2.5, lanzado en febrero de 2026, tiene 230.000 millones de parámetros totales y 10.000 millones de parámetros activos. Obtuvo una puntuación de 80.2% en SWE-Bench Verified, con una velocidad de finalización un 37% más rápida que M2.1, a la par con Claude Opus 4.6.
Ventaja de coste destacada: Se promociona como el primer modelo de vanguardia "del que los usuarios no tienen que preocuparse por el coste", con un coste de solo ~1 dólar por hora de ejecución continua a 100 tokens/segundo. Ya está disponible en código abierto en Hugging Face, y se recomienda su despliegue con vLLM o SGLang.
| Modelo | Fecha de lanzamiento | Parámetros totales | Parámetros activos | Forma de invocación recomendada | Estado de código abierto |
|---|---|---|---|---|---|
| GLM-5 | 2026.02.11 | 7440 亿 | 400 亿 | API oficial de Zhipu | MIT Código abierto |
| Kimi-K2.5 | 2026.01.27 | 1 billón | 320 亿 | API oficial de Moonshot AI | Código abierto |
| MiniMax-M2.5 | 2026.02.12 | 2300 亿 | 100 亿 | Oficial de MiniMax / Terceros | MIT Modificada |
🎯 Recomendación práctica: Para modelos de terceros de código cerrado o semiabierto como GLM-5, Kimi-K2.5 y MiniMax-M2.5, se recomienda conectarse directamente a las APIs oficiales de cada proveedor para obtener la mejor experiencia. Si necesitas gestionar centralizadamente las interfaces API de varios modelos, puedes hacerlo a través de la plataforma APIYI apiyi.com, que permite invocar múltiples modelos con una sola clave API, disfrutando además de mejores precios.
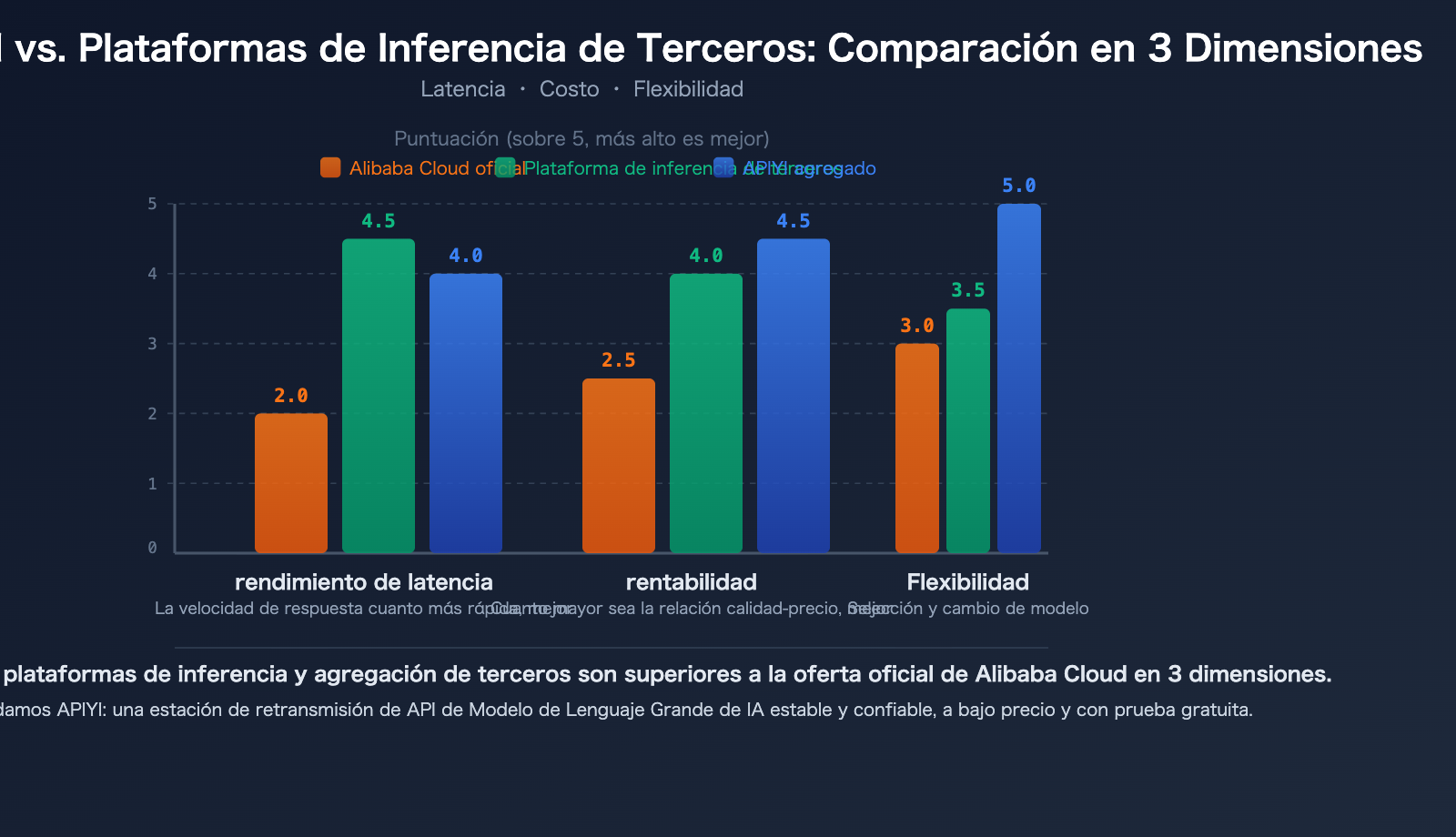
Plataformas de inferencia de terceros vs. Alibaba Cloud: 3 ventajas clave para el despliegue de modelos de código abierto
Para modelos de código abierto como Qwen3.5, además de la API oficial de Alibaba Cloud, los desarrolladores tienen más opciones. Las plataformas de inferencia de terceros especializadas a menudo ofrecen un rendimiento igual o superior al de los proveedores originales en el despliegue de modelos de código abierto.
Ventaja 1: Mayor velocidad de inferencia
La velocidad es la principal ventaja competitiva de las plataformas de inferencia especializadas. A través de optimizaciones de motores de inferencia personalizados, logran una menor latencia en el mismo modelo:
| Tipo de plataforma | Latencia típica | Rendimiento | Ventaja de velocidad |
|---|---|---|---|
| Plataforma cloud general (Alibaba Cloud, etc.) | 100-300ms | Base | — |
| SiliconFlow | Reducción del 32% | Aumento 2.3x | Núcleos CUDA personalizados |
| Fireworks AI | ~0.17s | ~747 TPS | FireAttention v2 |
| Together AI | — | Aumento 2x | Decodificación especulativa + cuantización FP4 |
| APIYI apiyi.com | Selección multicanal | Enrutamiento inteligente | Selección automática del canal más rápido |
Ventaja 2: Menor coste
En 2026, el gasto en inferencia de IA superó por primera vez al gasto en entrenamiento, representando el 55% del gasto total en infraestructura cloud de IA. En este contexto, la optimización de los costes de inferencia se vuelve crucial:
- La invocación de modelos de código abierto a través de APIs de terceros suele costar menos de $1/M tokens, ahorrando un 70-90% en comparación con los modelos de código cerrado.
- Las plataformas de inferencia especializadas utilizan hardware de nueva generación como NVIDIA Blackwell para reducir los costes de inferencia de IA hasta en 10 veces.
- No es necesario construir clústeres de GPU propios; se paga por uso, lo que es ideal para equipos pequeños y medianos y desarrolladores individuales.
Ventaja 3: Mayor flexibilidad en la elección de modelos
Las plataformas de terceros suelen admitir tanto modelos de código abierto como de código cerrado, ofreciendo interfaces API unificadas y precios transparentes. Esto significa:
- Sin dependencia de un proveedor: No estás atado a ningún proveedor de servicios en la nube.
- Cambio rápido: Invoca múltiples modelos con una sola interfaz, compara resultados y elige el óptimo.
- Optimización personalizada: Los modelos de código abierto admiten operaciones personalizadas como cuantización, ajuste fino y fusión.
💡 Sugerencia de elección: Para modelos de código abierto como Qwen3.5, el rendimiento de despliegue de las plataformas de inferencia de terceros puede ser mejor que la API oficial de Alibaba Cloud. Recomendamos realizar pruebas comparativas reales a través de la plataforma APIYI apiyi.com, que agrega múltiples canales de inferencia y selecciona automáticamente la ruta de menor latencia para ti.
Llamada Rápida a la API de Modelos de Código Abierto: Guía de Inicio Rápido en 5 Minutos
Tomando como ejemplo Qwen3.5-Flash, se muestra cómo llamar rápidamente a la API de modelos de código abierto a través de plataformas de terceros.
Ejemplo de Código Minimalista
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="qwen3.5-flash",
messages=[
{"role": "user", "content": "Analiza las ventajas de la arquitectura MoE de Qwen3.5"}
]
)
print(response.choices[0].message.content)
Ver código completo (incluye cambio de modelo y manejo de errores)
import openai
import time
# Inicializar cliente - llamada unificada a múltiples modelos a través de APIYI
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1"
)
# Lista de modelos soportados
models = [
"qwen3.5-flash", # Alibaba Qwen3.5-Flash
"qwen3.5-plus", # Alibaba Qwen3.5-Plus
"glm-5", # Zhipu GLM-5
"kimi-k2.5", # Moonshot Kimi-K2.5
"minimax-m2.5", # MiniMax-M2.5
]
prompt = "Explica en 3 frases las ventajas de la arquitectura MoE en la inferencia de Modelos de Lenguaje Grandes"
for model_name in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}],
max_tokens=500,
temperature=0.7
)
elapsed = time.time() - start
content = response.choices[0].message.content
print(f"\n[{model_name}] Tiempo transcurrido: {elapsed:.2f}s")
print(f"Respuesta: {content[:200]}...")
except Exception as e:
print(f"\n[{model_name}] Fallo al llamar: {e}")
🚀 Inicio Rápido: Se recomienda usar la plataforma APIYI apiyi.com para probar rápidamente los modelos anteriores. Al registrarte, recibirás crédito gratuito, y con una sola clave API podrás llamar a modelos populares como Qwen3.5, GLM-5, Kimi-K2.5, MiniMax-M2.5, etc., sin necesidad de registrarte en múltiples plataformas.
Recomendaciones de Soluciones de Llamada a Modelos para Diferentes Escenarios
Según tus necesidades reales, elige la forma de llamada más adecuada:
Escenario 1: Necesidad de llamar a modelos cerrados/semicerrados
Si utilizas principalmente las versiones cerradas de modelos como GLM-5, Kimi-K2.5 (no auto-desplegados), se recomienda:
- Opción preferida: Conexión directa a las APIs oficiales de cada proveedor, la latencia es mínima.
- Opción secundaria: Llamada unificada a través de plataformas agregadoras como APIYI apiyi.com, sacrificando un poco de latencia a cambio de conveniencia en la gestión.
Escenario 2: Necesidad de desplegar modelos de código abierto
Si utilizas modelos de código abierto como Qwen3.5, la versión de código abierto de GLM-5, la versión de código abierto de MiniMax-M2.5, etc.:
- Presupuesto holgado: Elige plataformas de inferencia especializadas como SiliconFlow, Together AI, etc., la latencia es óptima.
- Prioridad en la relación calidad-precio: Llamada agregada a través de APIYI apiyi.com, que enruta automáticamente al canal óptimo.
- Control total: Utiliza vLLM o SGLang para construir tu propio servicio de inferencia, lo que requiere recursos propios de GPU.
Escenario 3: Necesidad de pruebas comparativas de múltiples modelos
Cuando necesitas comparar rápidamente el rendimiento de varios modelos en las primeras etapas de desarrollo:
- Recomendado: Utiliza una interfaz de API unificada (como APIYI apiyi.com), con un solo registro puedes cambiar y probar múltiples modelos.
- Evita registrar cuentas por separado y gestionar múltiples claves API para cada modelo.
💰 Sugerencia de optimización de costes: Para proyectos sensibles al presupuesto, llamar a las APIs de modelos de código abierto a través de la plataforma APIYI apiyi.com es la solución más rentable. La plataforma ofrece formas de pago flexibles, y el coste de llamar a modelos de código abierto es mucho menor que el precio oficial de los modelos cerrados.
Preguntas Frecuentes
P1: Qwen3.5-Flash se anuncia como un modelo ligero, ¿por qué la API sigue siendo lenta?
Aunque Qwen3.5-Flash solo activa 3 mil millones de parámetros por inferencia, admite de forma predeterminada una ventana de contexto de 1 millón de tokens y ha integrado de forma nativa capacidades de procesamiento multimodal (texto + imágenes + video) y llamadas a herramientas integradas. Estos "costos ocultos" hacen que su consumo real de potencia de cálculo sea mucho mayor que el de un modelo de texto puro con una cantidad de parámetros similar. Sumado al contexto de escasez de recursos de GPU en Alibaba Cloud, el tiempo de espera aumenta aún más la latencia percibida.
P2: Si se implementan modelos de código abierto en plataformas de terceros, ¿se verá afectado el rendimiento?
No. Las plataformas de inferencia profesionales de terceros (como SiliconFlow, Together AI) utilizan los pesos originales de código abierto, junto con motores de inferencia optimizados, por lo que el rendimiento es el mismo que el de los fabricantes originales, e incluso la velocidad de inferencia es más rápida. A través de la plataforma APIYI apiyi.com, se puede comparar rápidamente la calidad y velocidad de inferencia de diferentes canales para elegir la mejor opción.
P3: ¿Cuándo se aliviará el problema de la potencia de cálculo de Alibaba Cloud?
Según las declaraciones públicas de los ejecutivos de Alibaba Cloud, se espera que la escasez de suministro de GPU continúe durante 2-3 años. A corto plazo, Alibaba Cloud prefiere aumentar la utilización de las GPU existentes a través de tecnologías de agrupación de recursos como Aegaeon, en lugar de una expansión significativa. Se recomienda a los desarrolladores que no esperen a la optimización de la plataforma, sino que elijan activamente soluciones de llamada más adecuadas: la conexión directa a la API oficial o las plataformas de inferencia de terceros son alternativas viables en la actualidad. Puede probar gratuitamente la velocidad de llamada de diferentes modelos a través de APIYI apiyi.com.
Resumen: Estrategias para abordar la lentitud de la API Qwen3.5 de Alibaba Cloud
La razón fundamental de la lenta respuesta de la API Qwen3.5 de Alibaba Cloud es la insuficiencia global de suministro de potencia de cálculo de GPU, sumada a factores como el alto consumo de potencia de cálculo de la arquitectura del modelo y la competencia por recursos entre múltiples inquilinos. Para los problemas de lentitud al llamar a modelos de terceros como GLM-5, Kimi-K2.5, MiniMax-M2.5 a través de Alibaba Cloud, la esencia es la misma: Alibaba Cloud prioriza la potencia de cálculo para sus propios modelos, y la asignación de recursos para modelos de terceros ocupa una posición secundaria.
3 recomendaciones clave:
- Conexión directa a la oficial para modelos cerrados: Use la API de Zhipu para GLM-5, la API de Moonshot para Kimi-K2.5, la API de MiniMax para MiniMax-M2.5, evitando la latencia de reenvío de capas intermedias.
- Elija terceros para modelos de código abierto: El rendimiento de modelos de código abierto como Qwen3.5 en plataformas de inferencia profesionales puede ser superior a la API oficial de Alibaba Cloud.
- Gestión unificada con plataformas de agregación: Si necesita usar varios modelos simultáneamente, se recomienda utilizar APIYI apiyi.com para llamar a todos los modelos a través de una única interfaz, garantizando eficiencia y facilidad de gestión.
La escasez de potencia de cálculo será la norma en toda la industria durante los próximos 2-3 años. En lugar de esperar pasivamente a que las plataformas en la nube amplíen su capacidad, es mejor optimizar activamente las estrategias de llamada: elegir la combinación de plataforma y modelo más adecuada es la mejor ruta para mejorar la experiencia de las aplicaciones de IA.
Autor: Equipo APIYI | Para más trucos sobre llamadas a API de modelos de IA, bienvenido a visitar APIYI apiyi.com para obtener los tutoriales más recientes y créditos de prueba gratuitos.
📚 Material de Referencia
-
Documentación oficial de la serie de modelos Qwen3.5: Especificaciones técnicas del modelo Tongyi Qianwen de Alibaba Cloud.
- Enlace:
github.com/QwenLM/Qwen3.5 - Descripción: Incluye parámetros completos del modelo, pruebas de referencia y guías de uso.
- Enlace:
-
Anuncio de ajuste de precios de capacidad de cómputo de Alibaba Cloud: Aumento de precios de la capacidad de cómputo de IA a partir de abril de 2026.
- Enlace:
www.alibabacloud.com - Descripción: Explicación oficial sobre la contradicción entre la oferta y la demanda de capacidad de cómputo.
- Enlace:
-
Informe técnico de GLM-5: Detalles técnicos del modelo insignia de Zhipu AI.
- Enlace:
github.com/THUDM/GLM-5 - Descripción: Explicación de la arquitectura MoE de 744 mil millones de parámetros y el modo Agente.
- Enlace:
-
Documentación oficial de Kimi-K2.5: Modelo de billones de parámetros de Moonshot AI.
- Enlace:
platform.moonshot.ai/docs/guide/kimi-k2-5-quickstart - Descripción: Guía de la función Agent Swarm y acceso a la API.
- Enlace:
-
Blog técnico de MiniMax-M2.5: Explicación detallada de modelos de código abierto de vanguardia.
- Enlace:
www.minimax.io/news/minimax-m25 - Descripción: Pruebas de referencia de rendimiento, sugerencias de implementación y análisis de costos.
- Enlace: