"¿Cuánta concurrencia debería abrir?" — Esta es la pregunta que más hacen los desarrolladores al realizar la generación de imágenes por lotes con la API de Nano Banana 2. La respuesta no reside en las limitaciones de la plataforma, sino en cuántos datos de imagen en Base64 pueden soportar tu ancho de banda y tu memoria.
Valor fundamental: Al terminar de leer este artículo, dominarás los cuellos de botella críticos de las llamadas concurrentes a la API de Nano Banana 2, aprenderás a calcular el número óptimo de concurrencia según las condiciones de tu servidor y obtendrás 5 consejos de optimización de rendimiento validados.

El problema central de la concurrencia en la API Nano Banana 2: el cuello de botella no es la plataforma, es tu canalización
La primera reacción de muchos desarrolladores es: "¿Cuánta concurrencia puede soportar la plataforma?". Pero, en realidad, la plataforma APIYI no limita la concurrencia; el RPM (solicitudes por minuto) puede soportar 1000 solicitudes por usuario sin problemas, y si necesitas más, podemos ampliar tu cuota por separado.
El verdadero cuello de botella es: La API de generación de imágenes de Gemini utiliza codificación Base64 para transmitir datos de imagen. Esto significa que la carga y descarga de cada imagen consiste en enormes textos JSON, en lugar de un flujo binario eficiente. Esto ejerce una presión enorme sobre tu ancho de banda y tu memoria.
Por qué Base64 es el cuello de botella central de la concurrencia
La API oficial de Gemini (incluida gemini-3.1-flash-image-preview para Nano Banana 2) solo admite la transmisión de imágenes mediante codificación Base64. La codificación Base64 expande los datos binarios en aproximadamente un 33%, lo que significa:
| Resolución | Tamaño original de la imagen | Tras codificación Base64 | Volumen de respuesta API por imagen |
|---|---|---|---|
| 512px (0.5K) | ~400 KB | ~530 KB | ~600 KB – 1 MB |
| 1K (predeterminado) | ~1.5 MB | ~2 MB | ~2 MB |
| 2K | ~4 MB | ~5.3 MB | ~5-8 MB |
| 4K | ~15 MB | ~20 MB | ~20 MB |
Una respuesta de API para una imagen 4K ocupa 20 MB. Si lanzas 10 solicitudes concurrentes de 4K al mismo tiempo, tendrás 200 MB de datos de respuesta fluyendo por tu red y memoria.
Tabla de parámetros del modelo API Nano Banana 2
| Parámetro | Valor |
|---|---|
| ID del modelo | gemini-3.1-flash-image-preview |
| Ventana de contexto de entrada | 131,072 tokens |
| Límite de salida | 32,768 tokens |
| Resoluciones admitidas | 512px / 1K / 2K / 4K |
| Relaciones de aspecto admitidas | 14 tipos, incluyendo 1:1, 3:2, 4:3, 16:9, 9:16, 21:9, etc. |
| Máximo de imágenes de referencia | 14 (10 objetos + 4 personajes) |
| Velocidad de generación | 3-5 segundos/imagen |
| RPM en APIYI | 1000/usuario (cuota ampliable) |
| Límite de concurrencia en APIYI | Sin límite |
🎯 Consejo técnico: La plataforma APIYI (apiyi.com) no limita la concurrencia para Nano Banana 2 y admite 1000 RPM por usuario. El cuello de botella está en tu entorno local: el ancho de banda y la memoria determinan cuánta concurrencia puedes ejecutar realmente.
Cálculo de la concurrencia de la API Nano Banana 2: elige la mejor solución según tu entorno
La cantidad de concurrencia no se decide al azar; debe calcularse según tu entorno real. Hay tres indicadores clave: ancho de banda, memoria y resolución objetivo.

Paso 1: Confirma tu ancho de banda
El ancho de banda determina cuántos datos se transmiten simultáneamente. Fórmula de cálculo:
Concurrencia máxima (ancho de banda) = Ancho de banda disponible (MB/s) ÷ Tamaño de respuesta por imagen (MB)
| Entorno de red | Ancho de banda disponible | Límite de concurrencia 1K | Límite de concurrencia 2K | Límite de concurrencia 4K |
|---|---|---|---|---|
| Banda ancha doméstica (100Mbps) | ~12 MB/s | 6 | 2 | 0-1 |
| Red empresarial (500Mbps) | ~60 MB/s | 30 | 10 | 3 |
| Servidor en la nube (1Gbps) | ~120 MB/s | 60 | 20 | 6 |
| Servidor de alto rendimiento (10Gbps) | ~1200 MB/s | 600 | 200 | 60 |
Paso 2: Confirma tu memoria disponible
Cada solicitud concurrente necesita mantener los datos de respuesta Base64 completos en la memoria hasta que se complete la decodificación y la escritura en el disco. Fórmula de cálculo de memoria:
Memoria necesaria = Concurrencia × Tamaño de respuesta por imagen × 2.5 (coeficiente de búfer de decodificación)
Multiplicamos por 2.5 porque, durante el proceso de decodificación Base64, la cadena original y los datos binarios decodificados existen simultáneamente en la memoria, además de la sobrecarga del análisis JSON.
| Memoria disponible | Límite de concurrencia 1K | Límite de concurrencia 2K | Límite de concurrencia 4K |
|---|---|---|---|
| 2 GB | 400 | 100 | 40 |
| 4 GB | 800 | 200 | 80 |
| 8 GB | 1600 | 400 | 160 |
Paso 3: Toma el valor menor de ambos
Concurrencia recomendada final = min(límite de concurrencia por ancho de banda, límite de concurrencia por memoria)
En la práctica, en la mayoría de los escenarios, el ancho de banda es el verdadero cuello de botella, no la memoria.
Concurrencia recomendada para escenarios reales
| Escenario | Resolución recomendada | Concurrencia recomendada | Rendimiento estimado |
|---|---|---|---|
| Desarrollo/Pruebas personales | 1K | 3-5 | ~1 imagen/seg |
| Generación por lotes para equipos pequeños | 1K | 10-20 | ~4 imágenes/seg |
| Entorno de producción empresarial | 1K-2K | 20-50 | ~10 imágenes/seg |
| Servicio de imágenes de alto rendimiento | 1K | 50-100 | ~20 imágenes/seg |
| Necesidad de imágenes HD 4K | 4K | 3-5 | ~1 imagen/seg |
💡 Consejo práctico: Si no estás seguro de cuánta concurrencia abrir, comienza con 5, aumenta gradualmente a 10, 20, y observa el tiempo de respuesta y la tasa de error. Si el tiempo de respuesta aumenta significativamente o aparecen tiempos de espera, significa que te estás acercando al cuello de botella. Al realizar pruebas en la plataforma APIYI (apiyi.com), no te preocupes por las limitaciones del lado de la plataforma, concéntrate en observar el rendimiento de tu entorno local.
Integración rápida de la API Nano Banana 2: 3 pasos para completar la integración
Paso 1: Instalar dependencias
pip install openai Pillow
Paso 2: Ejemplo de invocación minimalista
import openai
import base64
from pathlib import Path
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": "Generate a cute cat wearing sunglasses on a beach"
}
]
)
# Extraer datos de imagen en Base64 y guardar
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
img_bytes = base64.b64decode(part.image.data)
Path("output.png").write_bytes(img_bytes)
print("Imagen guardada: output.png")
Ver código completo para generación masiva concurrente
import openai
import base64
import asyncio
import aiohttp
import time
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
# Parámetros de configuración
MAX_CONCURRENCY = 10 # Concurrencia máxima, ajustar según tu ancho de banda
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
def generate_single_image(prompt: str, index: int) -> dict:
"""Genera una sola imagen y la guarda inmediatamente para liberar memoria"""
start = time.time()
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Decodificar y guardar inmediatamente para evitar que la cadena Base64 ocupe memoria
img_bytes = base64.b64decode(part.image.data)
filepath = OUTPUT_DIR / f"image_{index:04d}.png"
filepath.write_bytes(img_bytes)
elapsed = time.time() - start
size_mb = len(img_bytes) / (1024 * 1024)
return {
"index": index,
"success": True,
"time": elapsed,
"size_mb": size_mb,
"path": str(filepath)
}
except Exception as e:
return {
"index": index,
"success": False,
"error": str(e),
"time": time.time() - start
}
def batch_generate(prompts: list[str]):
"""Usa un pool de hilos para generar imágenes de forma concurrente"""
results = []
total = len(prompts)
completed = 0
with ThreadPoolExecutor(max_workers=MAX_CONCURRENCY) as executor:
futures = {
executor.submit(generate_single_image, p, i): i
for i, p in enumerate(prompts)
}
for future in futures:
result = future.result()
completed += 1
status = "OK" if result["success"] else "FAIL"
print(f"[{completed}/{total}] {status} - {result['time']:.1f}s")
results.append(result)
# Estadísticas
success = [r for r in results if r["success"]]
print(f"\nCompletado: {len(success)}/{total} exitosos")
if success:
avg_time = sum(r["time"] for r in success) / len(success)
total_size = sum(r["size_mb"] for r in success)
print(f"Tiempo promedio: {avg_time:.1f}s | Tamaño total: {total_size:.1f} MB")
# Ejemplo de uso
prompts = [
"A futuristic city at sunset",
"A cozy coffee shop interior",
"An underwater coral reef scene",
"A mountain landscape with aurora",
"A cute robot playing guitar",
]
batch_generate(prompts)
Paso 3: Subir imagen de referencia (imagen a imagen)
Los escenarios de imagen a imagen requieren subir una imagen de referencia, también codificada en Base64:
import base64
# Leer imagen local y convertir a Base64
with open("reference.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Convierte esta foto a un estilo de pintura de acuarela"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{img_base64}"
}
}
]
}
]
)
Nota: Al subir una imagen de referencia, el tamaño total del cuerpo de la solicitud no puede exceder los 20 MB. Si la imagen de referencia es grande, se recomienda comprimirla a una resolución inferior a 1K.
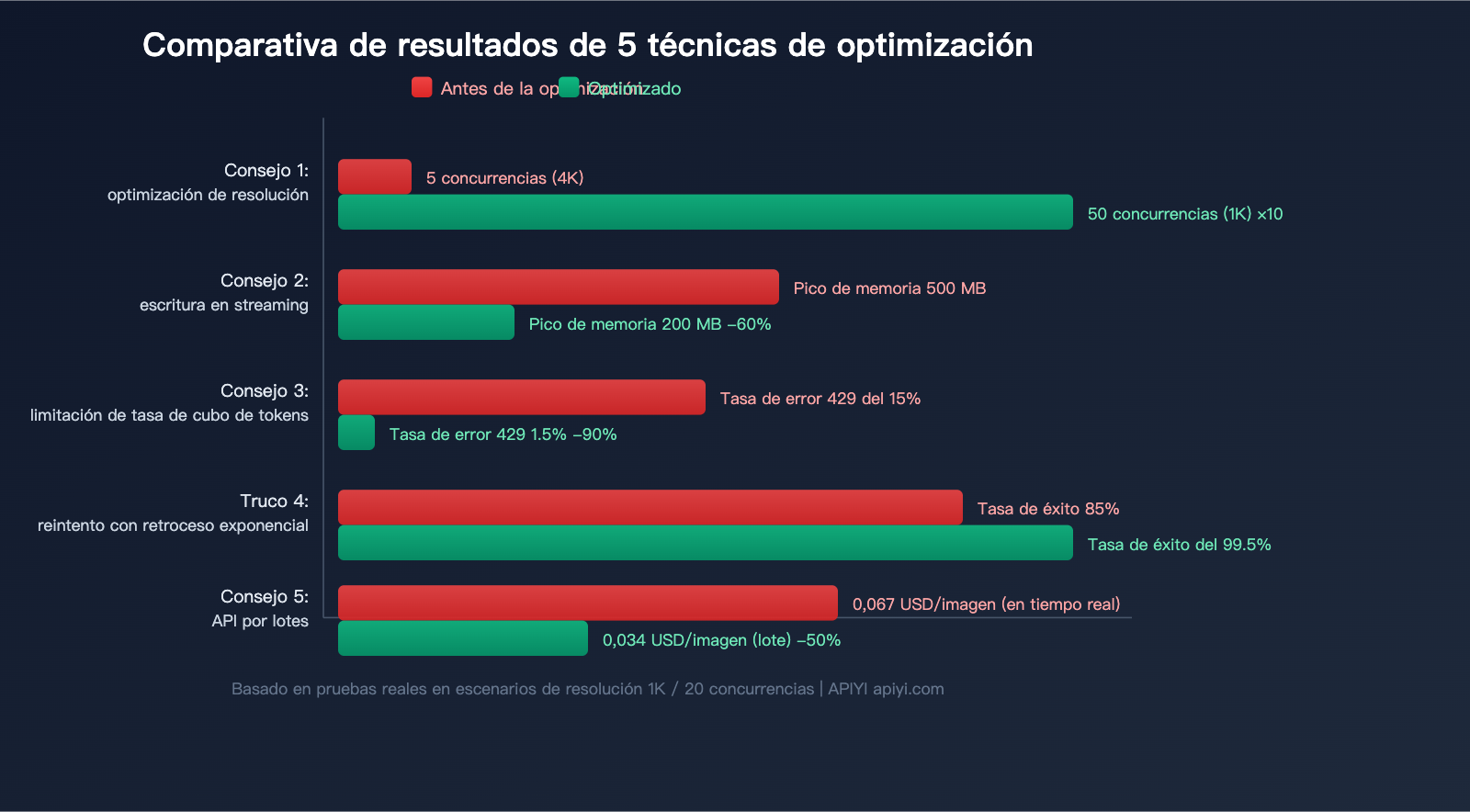
5 consejos prácticos para la optimización concurrente de la API Nano Banana 2
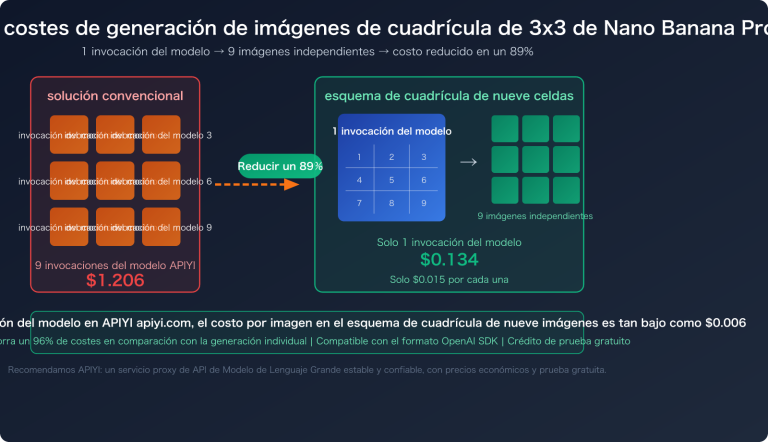
Consejo 1: Selecciona la resolución según tus necesidades, evita el 4K por defecto
Esta es la optimización más sencilla y efectiva. Muchos desarrolladores solicitan 4K por defecto, pero en escenarios reales, 1K suele ser suficiente:
| Escenario de uso | Resolución recomendada | Tamaño por imagen | Eficiencia concurrente |
|---|---|---|---|
| Redes sociales | 1K | ~2 MB | Alta |
| Imágenes de producto | 2K | ~6 MB | Media |
| Impresión/Póster | 4K | ~20 MB | Baja |
| Vista previa/Miniatura | 512px | ~0.7 MB | Muy alta |
Al cambiar de 4K a 1K, la capacidad de concurrencia aumenta aproximadamente 10 veces en las mismas condiciones.
Consejo 2: Recepción por streaming + escritura inmediata en disco
No esperes a que toda la respuesta JSON se reciba antes de procesarla. Utiliza la recepción por streaming para decodificar y escribir en el disco mientras recibes los datos:
import gc
def generate_and_save(prompt, filepath):
"""Genera la imagen y la guarda inmediatamente, liberando memoria activamente"""
response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{"role": "user", "content": prompt}]
)
for part in response.choices[0].message.content:
if hasattr(part, "image") and part.image:
# Decodificar inmediatamente
img_bytes = base64.b64decode(part.image.data)
# Eliminar la referencia a la cadena Base64 inmediatamente
del part.image.data
# Escribir en disco inmediatamente
Path(filepath).write_bytes(img_bytes)
del img_bytes
gc.collect() # Forzar la recolección de basura
Consejo 3: Limitador de concurrencia mediante Token Bucket
No envíes todas las solicitudes de una vez; utiliza el algoritmo de Token Bucket para distribuir las solicitudes de manera uniforme:
import threading
import time
class TokenBucket:
"""Limitador de tasa Token Bucket"""
def __init__(self, rate: float, capacity: int):
self.rate = rate # Tasa de recarga por segundo
self.capacity = capacity # Capacidad del bucket
self.tokens = capacity
self.lock = threading.Lock()
self.last_refill = time.monotonic()
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.rate
)
self.last_refill = now
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep(0.05)
# Uso: Máximo 10 solicitudes por segundo, pico de 20
limiter = TokenBucket(rate=10, capacity=20)
def rate_limited_generate(prompt, index):
limiter.acquire() # Esperar por un token
return generate_single_image(prompt, index)
Consejo 4: Reintento con retroceso exponencial para errores 429
Cuando encuentres una limitación de tasa (HTTP 429), utiliza una estrategia de retroceso exponencial:
import random
def generate_with_retry(prompt, index, max_retries=5):
"""Mecanismo de reintento con retroceso exponencial"""
for attempt in range(max_retries):
try:
return generate_single_image(prompt, index)
except openai.RateLimitError:
delay = min(60, (2 ** attempt)) + random.uniform(0, 0.5)
print(f"Límite de tasa alcanzado, esperando {delay:.1f}s antes de reintentar...")
time.sleep(delay)
return {"index": index, "success": False, "error": "max retries"}
Consejo 5: Utiliza Batch API para tareas masivas y ahorra un 50%
Para tareas masivas que no requieren resultados en tiempo real, Nano Banana 2 admite Batch API, lo que reduce los costos a la mitad:
| Modo | Precio unitario (1K) | Precio unitario (4K) | Latencia | Escenario ideal |
|---|---|---|---|---|
| API en tiempo real | $0.067 | $0.151 | 3-5 segundos | Aplicaciones interactivas |
| Batch API | $0.034 | $0.076 | Minutos-Horas | Generación masiva |
💰 Optimización de costos: Si tu escenario permite esperar, llamar a la Batch API a través de APIYI (apiyi.com) puede ahorrarte un 50% en costos. Es especialmente adecuado para la generación masiva de imágenes de productos de comercio electrónico, pre-producción de materiales de marketing, etc.
Desglose de costes y consumo de tokens por resolución en Nano Banana 2
Entender el consumo de tokens es clave para controlar mejor tus costes:
| Resolución | Consumo de tokens de salida | Precio estándar | Precio Batch (50% desc.) | Coste por 100 imágenes |
|---|---|---|---|---|
| 512px | 747 tokens | $0.045 | $0.022 | $4.50 / $2.20 |
| 1K | 1,120 tokens | $0.067 | $0.034 | $6.70 / $3.40 |
| 2K | 1,680 tokens | $0.101 | $0.050 | $10.10 / $5.00 |
| 4K | 2,520 tokens | $0.151 | $0.076 | $15.10 / $7.60 |
🚀 Inicio rápido: Invoca Nano Banana 2 a través de la plataforma APIYI (apiyi.com). Los precios son iguales a los oficiales, sin límites de concurrencia y con soporte de 1000 RPM por usuario. Regístrate y obtén saldo de prueba.
Comparativa de Nano Banana 2 con modelos anteriores
| Elemento de comparación | Nano Banana | Nano Banana Pro | Nano Banana 2 |
|---|---|---|---|
| ID del modelo | gemini-2.5-flash (imagen) | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview |
| Resolución máx. | 1024×1024 | 4K | 4K |
| Precio unitario 1K | $0.039 | $0.134 | $0.067 |
| Precio unitario 4K | No disponible | $0.240 | $0.151 |
| Velocidad de generación | 2-4 segundos | 5-8 segundos | 3-5 segundos |
| Batch API | No disponible | No disponible | Disponible (50% desc.) |
| Límite de imágenes de referencia | 5 imágenes | 10 imágenes | 14 imágenes |
| Disponible en APIYI | ✅ | ✅ | ✅ |
En comparación con la versión Pro, Nano Banana 2 reduce el precio en 4K en un 37%, mejora la velocidad en un 40% y añade soporte para Batch API.
Monitoreo del rendimiento de concurrencia de la API Nano Banana 2
Al ejecutar tareas concurrentes en la práctica, se recomienda monitorear los siguientes indicadores:
import psutil
import time
class PerformanceMonitor:
"""Monitor de rendimiento de concurrencia"""
def __init__(self):
self.start_time = time.time()
self.request_count = 0
self.total_bytes = 0
self.errors = 0
def record(self, success: bool, size_bytes: int = 0):
self.request_count += 1
if success:
self.total_bytes += size_bytes
else:
self.errors += 1
def report(self):
elapsed = time.time() - self.start_time
mem = psutil.Process().memory_info().rss / (1024**2)
print(f"--- Informe de rendimiento ---")
print(f"Tiempo de ejecución: {elapsed:.1f}s")
print(f"Solicitudes completadas: {self.request_count}")
print(f"Tasa de éxito: {(self.request_count-self.errors)/max(1,self.request_count)*100:.1f}%")
print(f"Rendimiento (throughput): {self.request_count/elapsed:.2f} req/s")
print(f"Volumen de datos: {self.total_bytes/(1024**2):.1f} MB")
print(f"Uso de ancho de banda: {self.total_bytes/(1024**2)/elapsed:.1f} MB/s")
print(f"Uso de memoria: {mem:.0f} MB")
Preguntas frecuentes
Q1: ¿La plataforma APIYI tiene límites de concurrencia para Nano Banana 2?
La plataforma APIYI no limita el número de conexiones concurrentes para Nano Banana 2. El límite de RPM (solicitudes por minuto) predeterminado es de 1000 por usuario; si tienes necesidades mayores, puedes contactar al servicio al cliente para solicitar una cuota adicional. El cuello de botella real de la concurrencia dependerá de tu ancho de banda local y tu memoria. Te recomendamos realizar pruebas reales a través de la plataforma APIYI (apiyi.com) para encontrar el nivel de concurrencia óptimo para tu entorno.
Q2: ¿Por qué la API de imágenes de Gemini solo admite transferencia en Base64?
Esta es una decisión de diseño actual de la API de Google Gemini. La codificación Base64 permite incrustar los datos de la imagen directamente en la respuesta JSON, eliminando la necesidad de almacenamiento de archivos adicional o distribución por CDN. La desventaja es que el tamaño de los datos aumenta aproximadamente un 33%, lo cual no es ideal para el ancho de banda y la memoria. La comunidad de desarrolladores ha enviado comentarios a Google solicitando la opción de salida en formato JPEG y URLs de descarga temporal, pero esto aún no se ha implementado.
Q3: ¿Es muy grande la diferencia de calidad entre las resoluciones 1K y 4K?
Depende del caso de uso. Para imágenes en redes sociales, visualización web o interfaces de aplicaciones, la resolución 1K es más que suficiente y, a simple vista, casi no se nota la diferencia. El 4K se utiliza principalmente para impresión, carteles, fondos de pantalla de alta definición y otros escenarios donde se necesite ampliar para ver detalles. Sugerimos probar primero con 1K y, si confirmas que necesitas mayor claridad, cambiar a 4K. A través de APIYI (apiyi.com) puedes alternar entre resoluciones de forma flexible y ajustarlas en cualquier momento.
Q4: ¿Qué hacer si recibo errores 429 frecuentes?
El error 429 indica que has alcanzado el límite de velocidad. Soluciones: (1) Reduce el número de conexiones concurrentes; (2) Utiliza un limitador de velocidad (token bucket) para distribuir las solicitudes de manera uniforme; (3) Implementa una estrategia de reintento con retroceso exponencial; (4) Para tareas por lotes, utiliza la Batch API. Si experimentas problemas de limitación de velocidad en la plataforma APIYI, contacta al servicio al cliente para aumentar tu cuota de RPM.
Q5: ¿Cómo estimar el costo total de una generación por lotes?
Utiliza la fórmula: Costo total = Cantidad de imágenes × Precio unitario. Por ejemplo, para generar 1000 imágenes en 1K: modo estándar 1000 × $0.067 = $67, modo Batch 1000 × $0.034 = $34. Los precios en APIYI (apiyi.com) son idénticos a los oficiales y admiten recargas flexibles, lo que los hace ideales para un uso bajo demanda.
Resumen: Encuentra tu mejor estrategia de concurrencia para la API de Nano Banana 2
La optimización de la concurrencia para la API de Nano Banana 2 no depende de "cuánto permite la plataforma", sino de "cuánto puede manejar tu canalización". Recuerda estos 3 puntos clave:
- La resolución lo es todo: Al pasar de 4K a 1K, la capacidad de concurrencia aumenta 10 veces y los costos se reducen en un 56%.
- El ancho de banda es el verdadero cuello de botella: La codificación Base64 hace que cada imagen sea un 33% más grande de lo real; la presión sobre el ancho de banda es mucho mayor que la ejercida sobre la CPU.
- Optimiza gradualmente de menor a mayor: Comienza con 5 solicitudes concurrentes, monitorea el tiempo de respuesta y la tasa de error, y aumenta gradualmente hasta alcanzar el valor óptimo.
Recomendamos realizar las llamadas a la API de Nano Banana 2 a través de la plataforma APIYI (apiyi.com), que no limita la concurrencia, ofrece 1000 RPM por usuario y mantiene precios iguales a los oficiales, permitiéndote concentrarte en optimizar el rendimiento de tu propia canalización sin preocuparte por las restricciones de la plataforma.

Referencias
-
Vista previa de imagen de Gemini 3.1 Flash: Especificaciones del modelo y documentación de la API
- Enlace:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview
- Enlace:
-
API de generación de imágenes de Gemini: Guía de uso de la API de generación de imágenes
- Enlace:
ai.google.dev/gemini-api/docs/image-generation
- Enlace:
-
Límites de tasa de la API de Gemini: Documentación oficial sobre límites de tasa
- Enlace:
ai.google.dev/gemini-api/docs/rate-limits
- Enlace:
-
Documentación de integración de APIYI Nano Banana 2: Descripción de la interfaz API unificada
- Enlace:
api.apiyi.com
- Enlace:
📝 Autor: Equipo de APIYI | El equipo técnico de APIYI se especializa en el campo de las API de generación de imágenes por IA, ofreciendo a los desarrolladores servicios de acceso a la API Nano Banana 2 sin límites de concurrencia y con una facturación flexible a través de apiyi.com.