Elegir un modelo de IA que sea rápido y económico es el desafío principal al que se enfrentan todos los desarrolladores en escenarios de invocación de alta frecuencia. Google lanzó oficialmente el 3 de marzo de 2026 el Gemini 3.1 Flash Lite Preview, el modelo más rápido y rentable de la serie Gemini 3, diseñado específicamente para escenarios de alto rendimiento como traducción, resumen y clasificación.
Valor principal: Al terminar de leer este artículo, comprenderás a fondo los parámetros técnicos, las ventajas de rendimiento y los mejores casos de uso de Gemini 3.1 Flash Lite, y podrás empezar a utilizarlo rápidamente mediante código práctico.

Resumen de parámetros clave de Gemini 3.1 Flash Lite
Antes de profundizar en Gemini 3.1 Flash Lite, echemos un vistazo a las especificaciones técnicas clave de este modelo:
| Parámetro | Especificación de Gemini 3.1 Flash Lite | Nota |
|---|---|---|
| ID del modelo | gemini-3.1-flash-lite-preview |
Actualmente en versión preliminar |
| Ventana de contexto | 1,000,000 tokens | Contexto largo de nivel millonario |
| Salida máxima | 64,000 tokens | Admite generación de texto largo |
| Precio de entrada | $0.25 / millón de tokens | Costo extremadamente bajo |
| Precio de salida | $1.50 / millón de tokens | Salida de alta rentabilidad |
| Velocidad de salida | ~382 tokens/segundo | Respuesta ultrarrápida |
| Modalidad de entrada | Texto, imagen, audio, video | Multimodal nativo |
| Modalidad de salida | Texto | Generación de texto |
| Fecha de lanzamiento | 3 de marzo de 2026 | Lanzamiento más reciente |
🚀 Inicio rápido: Gemini 3.1 Flash Lite Preview ya está disponible en la plataforma APIYI (apiyi.com), admite la invocación mediante interfaces compatibles con OpenAI y se puede integrar rápidamente sin configuraciones adicionales.
Las 5 ventajas principales de Gemini 3.1 Flash Lite
Ventaja 1: Velocidad 2.5 veces mayor
Gemini 3.1 Flash Lite ha dado un salto cualitativo en cuanto a velocidad. Según los datos de referencia de Artificial Analysis:
- Tiempo hasta el primer token (TTFT): 2.5 veces más rápido que Gemini 2.5 Flash.
- Velocidad de salida: Alcanza los 382 tokens/segundo, un aumento del 64% frente a los 232 tokens/segundo de Gemini 2.5 Flash.
- Rendimiento global: Mejora aproximadamente un 45%.
Esto significa que, en escenarios sensibles a la latencia como traducciones en tiempo real, chatbots y resúmenes de contenido, los usuarios obtendrán una experiencia de respuesta casi instantánea.
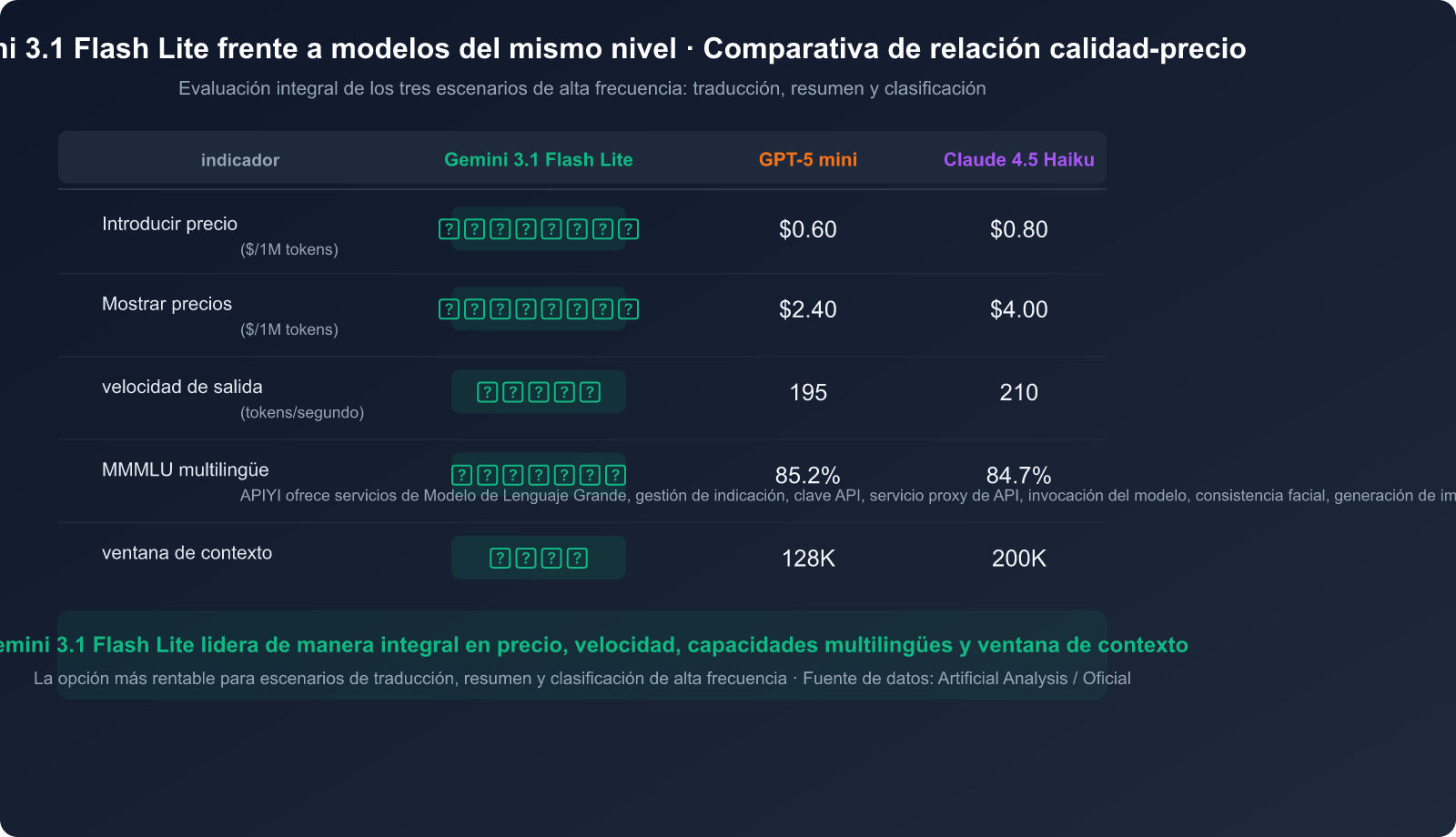
Ventaja 2: Relación calidad-precio extrema
La estrategia de precios de Gemini 3.1 Flash Lite es sumamente competitiva:
| Comparativa de precios | Precio de entrada ($/1M tokens) | Precio de salida ($/1M tokens) | Coste total |
|---|---|---|---|
| Gemini 3.1 Flash Lite | $0.25 | $1.50 | ⭐ El más bajo |
| Gemini 3 Flash | $1.00 | $4.00 | Medio |
| Gemini 3 Pro | $2.50 | $15.00 | Alto |
| Claude 4.5 Haiku | $0.80 | $4.00 | Medio |
| GPT-5 mini | $0.60 | $2.40 | Medio |
Calculando un procesamiento de 1 millón de tokens al día, el coste mensual de usar Gemini 3.1 Flash Lite es de solo $52.50, lo que supone un ahorro de más del 80% en comparación con Gemini 3 Pro.
Ventaja 3: Ventana de contexto de un millón de tokens
Gemini 3.1 Flash Lite admite una ventana de contexto de 1M de tokens, algo extremadamente raro en modelos de este rango de precio. Esto te permite:
- Procesar la traducción o el resumen de libros enteros de una sola vez.
- Analizar transcripciones de grabaciones de reuniones de varias horas.
- Gestionar la comprensión y generación de documentación de bases de código a gran escala.
- Realizar traducciones comparativas multilingües de documentos extensos.
Ventaja 4: Soporte multimodal nativo
Aunque se posiciona como un modelo ligero, Gemini 3.1 Flash Lite conserva capacidades completas de entrada multimodal:
- Texto: Comprensión y generación de texto estándar.
- Imagen: Reconocimiento y comprensión de imágenes.
- Audio: Procesamiento de contenido de voz.
- Vídeo: Comprensión de contenido de vídeo.
Esto lo hace apto no solo para tareas de solo texto, sino también para escenarios multimodales como traducciones de imágenes con texto o generación de subtítulos para vídeos.
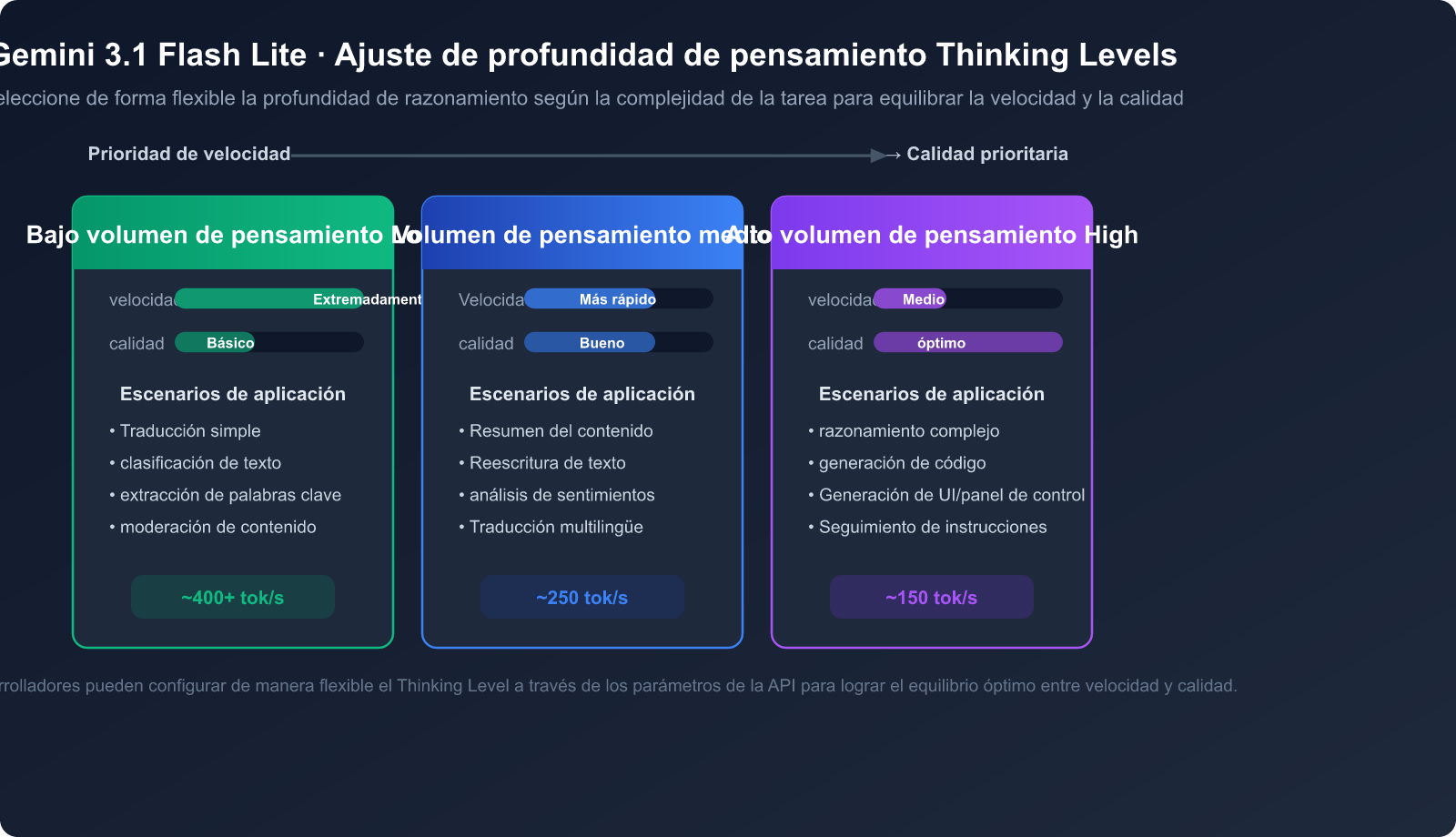
Ventaja 5: Profundidad de pensamiento ajustable
Gemini 3.1 Flash Lite admite la función Thinking Levels (niveles de pensamiento), lo que permite a los desarrolladores ajustar de forma flexible la profundidad de razonamiento del modelo según la complejidad de la tarea:
- Bajo nivel de pensamiento: Ideal para traducciones sencillas, clasificaciones y tareas que requieren máxima velocidad.
- Nivel de pensamiento medio: Adecuado para resúmenes, reescritura de contenido y tareas que requieren un nivel moderado de comprensión.
- Alto nivel de pensamiento: Recomendado para razonamientos complejos, generación de código y tareas que requieren una reflexión profunda.
Evaluación de rendimiento de Gemini 3.1 Flash Lite
Gemini 3.1 Flash Lite ha obtenido una puntuación Elo de 1432 puntos en el ranking de Arena.ai, destacando notablemente entre los modelos de su misma categoría.
| Prueba de referencia | Gemini 3.1 Flash Lite | Descripción |
|---|---|---|
| GPQA Diamond | 86.9% | Razonamiento científico |
| MMMU-Pro | 76.8% | Razonamiento multimodal |
| MMMLU | 88.9% | Preguntas y respuestas multilingües |
| LiveCodeBench | 72.0% | Generación de código |
| Video-MMMU | 84.8% | Comprensión de video |
| SimpleQA | 43.3% | Conocimiento parametrizado |
| MRCR v2 (128k) | 60.1% | Comprensión de ventana de contexto larga |
Cabe destacar que, en 6 pruebas de referencia como GPQA Diamond y MMMLU, Gemini 3.1 Flash Lite superó a GPT-5 mini y Claude 4.5 Haiku, demostrando que los modelos ligeros también pueden ofrecer un rendimiento inteligente de vanguardia.
🎯 Consejo técnico: Los datos de estas pruebas indican que Gemini 3.1 Flash Lite destaca especialmente en el procesamiento multilingüe (88.9% en MMMLU), lo que lo hace ideal para escenarios de traducción entre idiomas. Puedes realizar pruebas rápidas de tareas multilingües invocando este modelo a través de APIYI en apiyi.com.
Primeros pasos con Gemini 3.1 Flash Lite
Ejemplo de código minimalista
Utilizando la interfaz compatible con OpenAI, solo necesitas unas pocas líneas de código para invocar a Gemini 3.1 Flash Lite:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
# Ejemplo de escenario de traducción
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "Eres un traductor profesional. Por favor, traduce el texto en chino ingresado por el usuario al inglés, manteniendo el significado y el tono original."},
{"role": "user", "content": "人工智能正在深刻改变我们的工作方式和生活方式。"}
],
temperature=0.3
)
print(response.choices[0].message.content)
Ver código completo: Traducción por lotes + Escenario de resumen
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="English"):
"""Traducir texto al idioma objetivo"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Translate the following text to {target_lang}. Keep the original meaning and tone."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""Generar resumen de texto"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Por favor, resume los puntos clave del siguiente contenido en no más de {max_words} palabras."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""Clasificación de texto"""
cats = "、".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Clasifica el siguiente texto en una de estas categorías: {cats}. Devuelve solo el nombre de la categoría."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# Ejemplo de uso
texts = [
"量子计算将在未来十年彻底改变密码学领域",
"新款电动汽车续航里程突破1000公里",
"央行宣布下调基准利率25个基点"
]
categories = ["Tecnología", "Automóviles", "Finanzas", "Deportes", "Entretenimiento"]
for text in texts:
# Traducción
translated = translate_text(text)
# Clasificación
category = classify_text(text, categories)
# Resumen
summary = summarize_text(text, max_words=30)
print(f"Original: {text}")
print(f"Traducción: {translated}")
print(f"Categoría: {category}")
print(f"Resumen: {summary}")
print("---")
💰 Optimización de costos: Para escenarios de alta frecuencia como traducción, resumen y clasificación, el precio extremadamente bajo de Gemini 3.1 Flash Lite (entrada a solo $0.25 por millón de tokens) puede reducir significativamente los costos operativos. Al realizar la invocación a través de la plataforma APIYI (apiyi.com), también puedes obtener ventajas de precio adicionales y cuotas de prueba gratuitas.
Mejores casos de uso para Gemini 3.1 Flash Lite
Escenario 1: Traducción masiva de alta frecuencia
Gemini 3.1 Flash Lite alcanza una puntuación impresionante del 88.9% en el benchmark multilingüe MMMLU. Gracias a sus costos de invocación extremadamente bajos y su velocidad de respuesta ultrarrápida, es la opción ideal para tareas de traducción a gran escala:
- Traducción de descripciones de productos de comercio electrónico: Traducción multilingüe de decenas de miles de productos al día.
- Traducción de comentarios de usuarios: Traducción en tiempo real de los comentarios de clientes internacionales.
- Internacionalización de documentación técnica: Generación de versiones multilingües para documentación masiva.
- Traducción de subtítulos: Conversión rápida y multilingüe de subtítulos para videos.
Escenario 2: Resumen de contenido en tiempo real
Su velocidad de salida de 382 tokens por segundo lo hace perfecto para escenarios de resumen en tiempo real:
- Generación de resúmenes de noticias: Extracción automática de resúmenes de grandes volúmenes de noticias.
- Minutas de reuniones: Resumen rápido de grabaciones de reuniones largas.
- Revisiones bibliográficas: Generación masiva de resúmenes de artículos académicos.
- Resumen de correos electrónicos: Clasificación y resumen automático de correos corporativos.
Escenario 3: Moderación y clasificación de contenido a gran escala
Sus características de baja latencia y bajo costo lo convierten en la opción ideal para flujos de trabajo de moderación de contenido:
- Moderación de contenido generado por el usuario: Filtrado de seguridad en plataformas sociales.
- Clasificación automática de tickets: Enrutamiento inteligente para sistemas de atención al cliente.
- Análisis de sentimiento: Monitoreo en tiempo real de la reputación de la marca.
- Generación automática de etiquetas: Etiquetado automático para sistemas de gestión de contenido.
Guía de decisión para la elección de escenarios
| Caso de uso | Razón recomendada | Ventaja clave | Costo mensual estimado |
|---|---|---|---|
| Traducción masiva | Capacidad multilingüe MMMLU 88.9% | Bajo precio + alta calidad | ~$50 (1 millón de tokens/día) |
| Resumen en tiempo real | Salida ultrarrápida de 382 tokens/s | Baja latencia + rapidez | ~$30 (500 mil tokens/día) |
| Moderación de contenido | Alta precisión y respuesta rápida | Bajo costo + procesamiento masivo | ~$20 (300 mil tokens/día) |
| Chatbots | TTFT 2.5 veces más rápido | Respuesta instantánea | ~$80 (2 millones de tokens/día) |
| Procesamiento de documentos largos | Ventana de contexto de 1M de tokens | Procesamiento de libros completos | Pago por uso |
💡 Consejo de selección: Si tu caso de negocio implica tareas de procesamiento de texto de alta frecuencia, masivas y sensibles al costo, Gemini 3.1 Flash Lite es actualmente la opción con mejor relación calidad-precio. Recomendamos realizar pruebas en escenarios reales a través de la plataforma APIYI (apiyi.com), la cual permite cambiar de modelo con un solo clic para comparar resultados.
Notas sobre el uso de Gemini 3.1 Flash Lite
Limitaciones actuales
Al tratarse de un modelo en versión preliminar, ten en cuenta lo siguiente:
- Fase de vista previa: El modelo aún se encuentra en estado Preview, por lo que la interfaz de la API y su comportamiento pueden sufrir ajustes.
- Límite de salida: La salida máxima es de 64K tokens; las tareas de generación muy largas deben procesarse por segmentos.
- Rendimiento con contexto ultra largo: Su desempeño en escenarios de contexto extremo de 1M de tokens es moderado (solo un 12.3% en la prueba MRCR v2 1M). Se recomienda mantenerlo dentro de los 128K para obtener los mejores resultados.
- Límites de seguridad: Las puntuaciones de seguridad de imagen a texto aún están en proceso de mejora; se recomienda añadir una capa de revisión al tratar contenido sensible.
Recomendaciones de uso
- Parámetro de temperatura: Para tareas de traducción se recomienda
temperature=0.3, y para tareas de resumen,temperature=0.5. - Indicación del sistema: Proporcionar una definición de rol clara y requisitos de formato de salida puede mejorar significativamente la calidad de los resultados.
- Procesamiento por lotes: Utiliza llamadas asíncronas para aumentar el rendimiento y aprovechar al máximo la velocidad del modelo.
- Control de contexto: Aunque admite un contexto de 1M, se recomienda limitar las tareas habituales a 128K para obtener la mejor relación costo-beneficio.
Preguntas frecuentes
Q1: ¿Cuál es la diferencia entre Gemini 3.1 Flash Lite y Gemini 3 Flash?
Gemini 3.1 Flash Lite es la versión ligera de la serie Gemini 3, optimizada para escenarios de alta frecuencia y bajo costo. En comparación con Gemini 3 Flash, su precio de entrada es un 75% menor ($0.25 frente a $1.00) y su velocidad de salida es aproximadamente un 64% más rápida, aunque su capacidad en tareas de razonamiento complejo es ligeramente inferior. En resumen: elige Flash Lite si buscas la mejor relación costo-beneficio, y Flash si necesitas una mayor capacidad de razonamiento. A través de la plataforma APIYI (apiyi.com) puedes probar ambos modelos y encontrar rápidamente el que mejor se adapte a tu caso de uso.
Q2: ¿Es Gemini 3.1 Flash Lite adecuado para traducciones?
Es muy adecuado. Gemini 3.1 Flash Lite obtuvo una puntuación alta del 88.9% en el benchmark multilingüe MMMLU, situándose a la cabeza entre los modelos de su categoría. Sumado a su precio de entrada ultra bajo de $0.25 por millón de tokens y una velocidad de salida de 382 tokens/segundo, es uno de los modelos con mejor relación costo-beneficio para tareas de traducción masiva. Te sugerimos obtener créditos de prueba gratuitos en APIYI (apiyi.com) para verificar la calidad de la traducción en la práctica.
Q3: ¿Cómo puedo invocar Gemini 3.1 Flash Lite a través de una interfaz compatible con OpenAI?
Solo necesitas configurar la base_url con la dirección de la interfaz de APIYI y utilizar gemini-3.1-flash-lite-preview en el parámetro model. No es necesario modificar la estructura de tu código existente del SDK de OpenAI, permitiendo una transición fluida. Consulta los ejemplos de código en la sección "Inicio rápido" de este artículo para más detalles.
Q4: ¿Es realmente útil la ventana de contexto de 1M de Gemini 3.1 Flash Lite?
Tiene un excelente desempeño dentro del rango de 128K tokens (puntuación de 60.1% en MRCR v2 128K), pero su rendimiento disminuye notablemente en escenarios extremos de 1M de tokens (puntuación de 12.3% en MRCR v2 1M). Recomendamos mantener el uso diario dentro de los 128K y emplear estrategias de segmentación cuando necesites procesar documentos extremadamente largos.
Resumen
Gemini 3.1 Flash Lite Preview se posiciona como el rey de la relación calidad-precio para 2026 en escenarios de alta frecuencia como traducción, resumen y clasificación, gracias a su precio ultra bajo de $0.25 por millón de tokens de entrada, una velocidad de salida vertiginosa de 382 tokens/segundo, una ventana de contexto de 1M de tokens y un rendimiento sobresaliente en pruebas de referencia como el procesamiento multilingüe (MMMLU 88.9%) y el razonamiento científico (GPQA Diamond 86.9%).
Ya sea que necesites procesar millones de tokens diarios para traducciones masivas o construir un servicio de resumen en tiempo real de baja latencia, Gemini 3.1 Flash Lite es una opción que deberías considerar prioritariamente.
Te recomendamos acceder rápidamente a Gemini 3.1 Flash Lite Preview a través de APIYI (apiyi.com). Esta plataforma ofrece una interfaz compatible con OpenAI y permite cambiar entre múltiples modelos principales con un solo clic, facilitando la validación rápida de resultados y la comparación de modelos.
Referencias
-
Google DeepMind – Ficha técnica del modelo Gemini 3.1 Flash-Lite: Especificaciones técnicas oficiales del modelo y datos de pruebas de referencia.
- Enlace:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- Enlace:
-
Google AI for Developers – Gemini 3.1 Flash-Lite Preview: Documentación oficial de la API y guía para desarrolladores.
- Enlace:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- Enlace:
-
Artificial Analysis – Evaluación de rendimiento: Pruebas de referencia independientes sobre velocidad y rendimiento.
- Enlace:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- Enlace:
📝 Autor: Equipo técnico de APIYI | Para más guías de uso de modelos de IA y tutoriales técnicos, visita el centro de ayuda de APIYI en help.apiyi.com