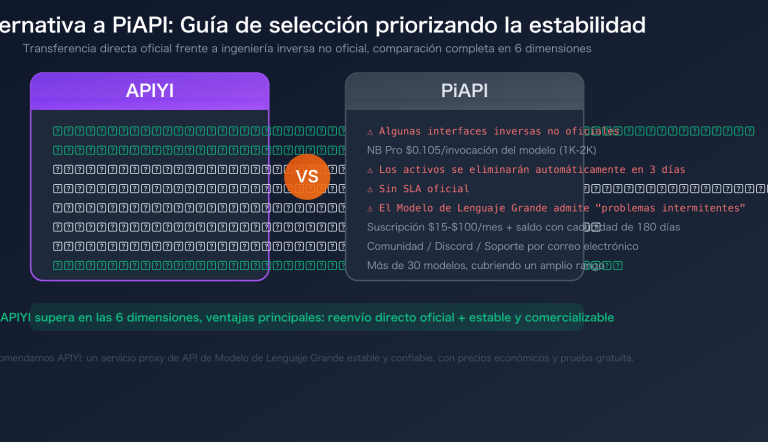
Nota del autor: Análisis en profundidad de la ventana de contexto de 1M tokens de GPT-5.4, el punto de corte de precios en 272K tokens que duplica el costo, el rango óptimo de rendimiento entre 127K-272K, comparación completa de precios y estrategias para ahorrar.
GPT-5.4 presume de una ventana de contexto súper larga de 1.05 millones de tokens, pero lo que muchos desarrolladores no saben es: al superar los 272K tokens, el precio se duplica directamente y la precisión también comienza a disminuir. Esta no es una historia simple de "cuanto más grande, mejor".
Valor central: Este artículo desglosa en detalle la curva de rendimiento del contexto de GPT-5.4, el mecanismo del punto de corte de precios en 272K, y cómo usar GPT-5.4 de manera eficiente y al menor costo posible a través de APIYI.

Puntos clave sobre los precios del contexto en GPT-5.4
| Punto clave | Descripción | Impacto práctico |
|---|---|---|
| Contexto total | 1,050,000 tokens (1.05M) | Teóricamente puede procesar documentos muy largos |
| Punto de corte en 272K | Al superarlo, el precio de entrada se duplica ($2.50→$5.00) | Mantenerse por debajo de 272K puede ahorrar la mitad del costo de entrada |
| Rango de rendimiento óptimo | 127K-272K tokens | Precisión ~97%, mejor relación costo-rendimiento |
| Zona de rendimiento decreciente | La precisión comienza a caer por encima de 256K | En el rango 512K-1M la precisión puede bajar a ~36% |
| vs GPT-5.2 | Entrada 43% más cara, salida 7% más cara | Pero usa menos tokens de razonamiento, reduciendo la diferencia real |
La idea clave sobre el contexto de GPT-5.4: Que pueda no significa que deba
Esto es muy importante: que GPT-5.4 admita un contexto de 1.05 millones de tokens no significa que debas llenarlo por completo. Según los datos de evaluación públicos de OpenAI:
- 16K-32K tokens: Precisión de recuperación "Needle-in-a-Haystack" ~97%
- 127K-272K tokens: La precisión se mantiene estable en niveles altos, y es el rango de precio estándar
- Por encima de 256K: La precisión comienza a disminuir
- 512K-1M tokens: La precisión puede caer drásticamente a ~36%
GPT-5.2 anteriormente mostró una precisión cercana al 100% en pruebas MRCR de 4 agujas dentro de 256K tokens, lo que refuerza que 256K es un punto clave para la fiabilidad del rendimiento.
Consejo práctico: Para la mayoría de los casos de uso, mantener la entrada por debajo de 272K es la estrategia más inteligente: garantiza precisión y evita que el precio se duplique. Al acceder a GPT-5.4 a través de APIYI (apiyi.com), los precios están sincronizados con los oficiales, y participando en las promociones de recarga puedes obtener descuentos de hasta el 20%.
Precios de contexto de GPT-5.4 desglosados
Precios de la versión estándar de GPT-5.4 (por millón de tokens)
Aquí está el sistema completo de precios por niveles de GPT-5.4:
| Modo de procesamiento | Entrada (≤272K) | Entrada (>272K) | Entrada en caché (≤272K) | Entrada en caché (>272K) | Salida (≤272K) | Salida (>272K) |
|---|---|---|---|---|---|---|
| Standard | $2.50 | $5.00 | $0.25 | $0.50 | $15.00 | $22.50 |
| Batch | $1.25 | $2.50 | $0.13 | $0.26 | $7.50 | $11.25 |
| Flex | $1.25 | $2.50 | $0.13 | $0.26 | $7.50 | $11.25 |
| Priority | $5.00 | — | $0.50 | — | $30.00 | — |
Tres detalles clave sobre los precios de contexto de GPT-5.4
Primero, más de 272K significa un recargo completo. Cuando tu entrada supera los 272K tokens, el mecanismo de recargo se aplica a toda la sesión, no solo a la parte que excede el límite. Esto significa que una vez que cruzas la línea, todos los tokens se calculan al precio duplicado.
Segundo, el precio de salida también sube. No solo se duplica la entrada, sino que después de 272K el precio de salida también sube de $15.00 a $22.50, un aumento del 50%. Esto tiene un gran impacto en tareas intensivas en salida (como generación de código, escritura de textos largos).
Tercero, la entrada en caché es una herramienta para ahorrar. La entrada en caché en el rango estándar cuesta solo $0.25/M tokens, una décima parte del precio original. Si tus tareas involucran indicaciones de sistema repetidas o contexto fijo, usar bien la caché puede reducir enormemente los costos.
Análisis comparativo de precios: GPT-5.4 vs GPT-5.2
La pregunta que más preocupa a muchos desarrolladores: ¿Cuánto más costará migrar de GPT-5.2 a GPT-5.4?

Diferencias principales en precios: GPT-5.4 vs GPT-5.2
| Elemento de precio | GPT-5.2 | GPT-5.4 Estándar | GPT-5.4 Extendido | Aumento Estándar |
|---|---|---|---|---|
| Entrada | $1.75/M | $2.50/M | $5.00/M | +43% |
| Entrada en caché | $0.175/M | $0.25/M | $0.50/M | +43% |
| Salida | $14.00/M | $15.00/M | $22.50/M | +7% |
| Entrada Pro | $21.00/M | $30.00/M | $60.00/M | +43% |
| Salida Pro | $168.00/M | $180.00/M | $270.00/M | +7% |
Aunque los precios de GPT-5.4 son más altos, la diferencia de costo real no es grande
OpenAI señala oficialmente que GPT-5.4 es "el modelo de inferencia más eficiente": resuelve el mismo problema con menos tokens de inferencia. Es decir, aunque el precio unitario subió, la cantidad total de tokens consumidos por cada invocación puede ser menor.
Sin embargo, hay que tener en cuenta: la longitud de respuesta de GPT-5.4 es en promedio un 24% mayor que la de GPT-5.2, lo que compensa en parte la mejora en eficiencia de inferencia.
Mejores prácticas para el uso del contexto en GPT-5.4
Tres reglas de oro
Regla uno: Mantenerse preferiblemente por debajo de 272K. Este es el rango con la mejor relación costo-beneficio: alta precisión y bajo precio. Para la gran mayoría de los escenarios de aplicación, 272K tokens son suficientes para cubrir conversaciones de múltiples turnos, análisis de documentos largos y revisión de grandes bases de código.
Regla dos: 127K-272K es el rango óptimo. Dentro de este rango, la precisión de recuperación del modelo se mantiene estable en aproximadamente un 97%, al tiempo que aprovecha la ventaja del contexto largo de GPT-5.4. Esto es el doble de la ventana estándar de 128K de GPT-5.2, suficiente para manejar la mayoría de las tareas que "antes no cabían".
Regla tres: Pensarlo dos veces al superar los 272K. A menos que tu tarea realmente requiera procesar documentos extremadamente largos de una sola vez (como análisis de un repositorio de código completo, revisión de grandes textos legales), no se recomienda superar los 272K. El precio se duplica mientras la precisión disminuye, reduciendo drásticamente la relación costo-beneficio.
Técnicas de optimización de contexto para GPT-5.4
| Técnica | Explicación | Ahorro estimado |
|---|---|---|
| Aprovechar la entrada en caché | Usar caché para indicaciones del sistema repetidas, solo $0.25/M | Ahorra 90% del costo de entrada |
| Tool Search | Cargar definiciones de herramientas bajo demanda, no todas a la vez | Ahorra 47% de Tokens |
| Procesamiento por segmentos | Dividir documentos muy largos, cada segmento controlado dentro de 272K | Evita la duplicación de precios |
| Compresión por resumen | Primero extraer resúmenes con un modelo económico, luego análisis profundo con GPT-5.4 | Reduce significativamente el volumen de entrada |
Ventajas detalladas de la integración de GPT-5.4 en APIYI
APIYI (apiyi.com) ya ha implementado GPT-5.4, con precios idénticos a los oficiales. A continuación, las ventajas clave de APIYI frente a la conexión directa con OpenAI:
Comparativa: APIYI vs Conexión oficial de OpenAI
| Dimensión de comparación | OpenAI Oficial | APIYI apiyi.com |
|---|---|---|
| Umbral de registro | Requiere tarjeta de crédito estadounidense | ❌ No requiere, usar tras registrarse |
| Recarga mínima | Requiere métodos de pago en el extranjero | ✅ Mínimo desde 35 CNY (aprox. 5 USD) |
| Límite de concurrencia | Limitado por nivel de Tier (RPM/TPM) | ✅ Concurrencia ilimitada |
| Batch API | ✅ Soportado (mitad de precio) | ❌ No soporta Batch/Flex |
| Precio Standard | $2.50 entrada / $15.00 salida | Precios idénticos |
| Descuento real | Sin beneficios por recarga | ✅ Actividades de recarga con bonificación, hasta 20% de descuento |
| Dificultad de inicio | Requiere VPN + pago en el extranjero | ✅ Listo para usar, integración en 5 minutos |
¿Para qué usuarios es ideal APIYI GPT-5.4?
Usuarios que quieren probar: Con un mínimo de 35 CNY puedes comenzar a experimentar todas las capacidades de GPT-5.4 (incluyendo Computer Use), sin necesidad de pagos anticipados grandes.
Usuarios de uso prolongado: A través de actividades de recarga con bonificación, recargas grandes obtienen crédito adicional, reduciendo el costo real hasta en un 20%. Si tu consumo mensual es estable, esta ventaja se acumula considerablemente con el tiempo.
Desarrolladores en China: No requiere tarjeta de crédito estadounidense, ni VPN, ni configuraciones complejas de pago en el extranjero. Regístrate en APIYI apiyi.com → recarga → obtén tu clave API → cambia una línea de base_url y ya puedes realizar llamadas.
Escenarios de alta concurrencia: OpenAI oficial limita RPM y TPM por nivel de Tier (Tier 1 ~1000 RPM), APIYI no limita la concurrencia, ideal para entornos de producción que requieren muchas llamadas concurrentes.
Nota: APIYI actualmente no soporta Batch API ni el modo de procesamiento Flex de OpenAI. Si tu flujo de trabajo depende de la capacidad de procesamiento por lotes a mitad de precio, evalúa si es adecuado. Para interacción en tiempo real y llamadas API estándar, APIYI es una opción más conveniente.
Guía rápida del contexto de GPT-5.4
Ejemplo mínimo
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Llamada en rango estándar (≤272K, precio estándar)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "system", "content": "Eres un experto en revisión de código"},
{"role": "user", "content": "Analiza el siguiente código..."}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Ver ejemplo de uso de contexto largo y estimación de costos
from openai import OpenAI
import tiktoken
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def estimate_cost(input_tokens, output_tokens):
"""Estima el costo de una llamada a GPT-5.4"""
if input_tokens <= 272000:
input_cost = (input_tokens / 1_000_000) * 2.50
output_cost = (output_tokens / 1_000_000) * 15.00
else:
input_cost = (input_tokens / 1_000_000) * 5.00 # Se duplica
output_cost = (output_tokens / 1_000_000) * 22.50 # 1.5x
return input_cost + output_cost
# Ejemplo: Analizar un archivo grande
with open("large_codebase.txt", "r") as f:
code_content = f.read()
# Estimar la cantidad de tokens
enc = tiktoken.encoding_for_model("gpt-4o")
token_count = len(enc.encode(code_content))
print(f"Número de Tokens de entrada: {token_count}")
if token_count > 272000:
print(f"⚠️ ¡Supera el límite de 272K, el precio se duplicará!")
print(f"Sugerencia: Considera procesar por segmentos o usar compresión por resumen")
estimated = estimate_cost(token_count, 4000)
print(f"Costo estimado: ${estimated:.4f}")
# Llamada real
response = client.chat.completions.create(
model="gpt-5.4",
messages=[
{"role": "user", "content": f"Analiza las siguientes vulnerabilidades de seguridad en el código:\n{code_content}"}
],
max_tokens=8000
)
print(response.choices[0].message.content)
Recomendación: Accede a GPT-5.4 a través de APIYI apiyi.com, con precios sincronizados con los oficiales. Las actividades de recarga con bonificación pueden ofrecer un descuento del 20%. Recarga mínima desde 35 yuanes, regístrate y úsalo al instante, no se requiere tarjeta de crédito estadounidense.
Estimación de costos por escenario para el contexto de GPT-5.4
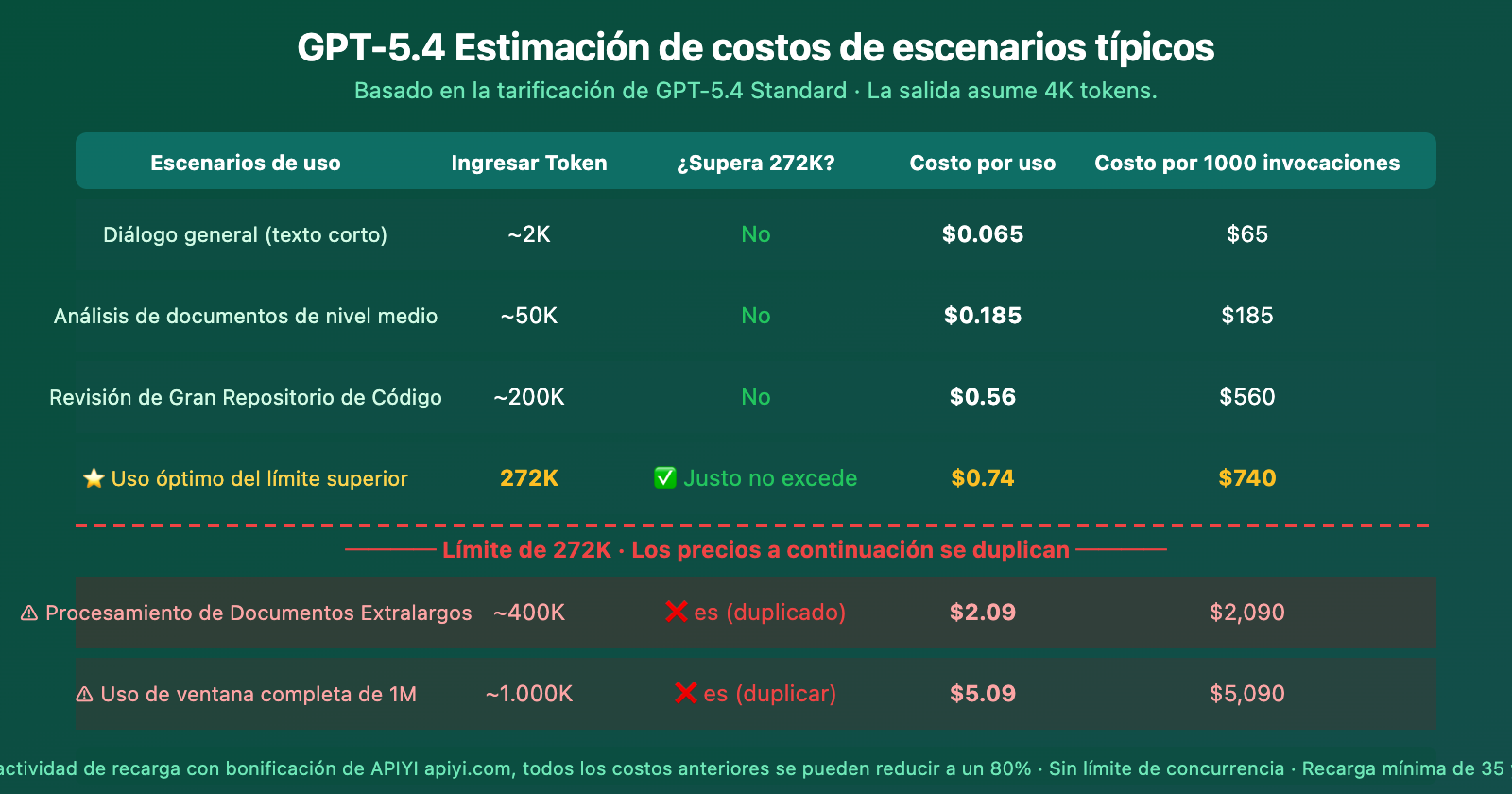
De la estimación de costos se puede ver claramente: Los 272K son un precipicio de costos abrupto. Con la misma entrada adicional de 128K (de 272K a 400K), el costo por llamada salta de $0.74 a $2.09 — un aumento de casi 3 veces.
Preguntas Frecuentes
P1: ¿El recargo de GPT-5.4 por superar los 272K se aplica solo a la parte excedente o a todo?
Se aplica a todo. Una vez que tus tokens de entrada superan el umbral de 272K, todos los tokens de la sesión completa se calculan según el precio extendido (entrada $5.00/M, salida $22.50/M), no solo la parte excedente. Por lo tanto, mantener el total por debajo de 272K es clave para ahorrar.
P2: ¿No es demasiado caro si APIYI no soporta Batch API?
Es cierto que APIYI no soporta los modos de procesamiento Batch y Flex de OpenAI (que tienen un precio aproximadamente la mitad del estándar). Sin embargo, las ventajas de APIYI son: no requiere tarjeta de crédito estadounidense, recarga mínima de 35 yuanes, concurrencia ilimitada y listo para usar. Además, con las actividades de recarga con bonificación puedes conseguir un descuento real del 20%, lo que en escenarios de invocación estándar se acerca al descuento de Batch. Si tu flujo de trabajo es de interacción en tiempo real y no de procesamiento por lotes, APIYI es más conveniente.
P3: ¿Cómo puedo determinar rápidamente si mi tarea superará los 272K?
Estimación simple: 1 palabra en inglés ≈ 1.3 tokens, 1 carácter chino ≈ 2-3 tokens. 272K tokens equivalen aproximadamente a 200,000 palabras en inglés o 90,000-130,000 caracteres chinos. Si tu entrada, más las indicaciones del sistema y el historial de conversación, no superan este volumen, podrás disfrutar del precio estándar de forma segura. Se recomienda agregar una verificación del conteo de tokens en tu código para alertas tempranas. Esta lógica de cálculo también se aplica al realizar llamadas a través de APIYI en apiyi.com.
Resumen
Puntos clave sobre la política de precios de contexto de GPT-5.4:
- 272K es el punto de inflexión crítico: Superar los 272K tokens duplica el precio de entrada ($2.50→$5.00) y aumenta la salida un 50% ($15.00→$22.50), aplicándose a la totalidad de tokens.
- 127K-272K es el rango óptimo: La precisión se mantiene estable en ~97%, dentro del rango de precios estándar, ofreciendo la mejor relación calidad-precio.
- La precisión disminuye después de 256K: En el rango de 512K-1M, la precisión puede caer hasta ~36%, úsalo con precaución.
- Más caro que GPT-5.2 pero más eficiente: En el rango estándar, la entrada es un 43% más cara y la salida un 7%, pero utiliza menos tokens de razonamiento.
Estrategias para ahorrar: Mantén la entrada por debajo de 272K, aprovecha la entrada en caché (ahorra 90%) y utiliza la Búsqueda de Herramientas (ahorra 47%). Al acceder a través de APIYI en apiyi.com, los precios están sincronizados con los oficiales y las actividades de recarga con bonificación pueden ofrecer un descuento del 20%. Recarga mínima de 35 yuanes, sin necesidad de tarjeta de crédito estadounidense, concurrencia ilimitada, listo para usar tras registrarse. Ideal tanto para probar como para uso a largo plazo.
📚 Referencias
-
Página de precios de OpenAI API: Especificaciones completas de precios y facturación por niveles de contexto de GPT-5.4
- Enlace:
developers.openai.com/api/docs/pricing - Descripción: Fuente oficial y autorizada de precios, incluye precios para todos los modos: Standard/Batch/Flex/Priority
- Enlace:
-
Documentación del modelo OpenAI GPT-5.4: Ventana de contexto, límites de salida y otras especificaciones técnicas
- Enlace:
developers.openai.com/api/docs/models/gpt-5.4 - Descripción: Documentación oficial de especificaciones del modelo
- Enlace:
-
Anuncio de lanzamiento de OpenAI GPT-5.4: Capacidades principales y datos de pruebas de referencia
- Enlace:
openai.com/index/introducing-gpt-5-4/ - Descripción: Incluye métricas de rendimiento, filosofía de diseño y explicación de la estrategia de precios
- Enlace:
-
Discusión en la comunidad de desarrolladores de OpenAI: Análisis detallado de precios, límites de contexto y Tool Search de GPT-5.4
- Enlace:
community.openai.com/t/gpt-5-4-deep-dive-pricing-context-limits-and-tool-search-explained/ - Descripción: Debate profundo entre desarrolladores sobre la estructura de precios y el rendimiento del contexto
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Bienvenidos a discutir en los comentarios las experiencias de uso del contexto de GPT-5.4 y técnicas de optimización de costos. Para más recursos, visiten el centro de documentación de APIYI en docs.apiyi.com