El 21 de abril de 2026, OpenAI lanzó gpt-image-2, el sucesor de gpt-image-1.5. Este modelo marca un salto significativo respecto a su predecesor en áreas clave como la resolución 2K nativa, el escalado a 4K, la precisión en el renderizado de texto y la composición de elementos complejos. En apenas dos semanas, la comunidad de creadores en X, LinkedIn y GitHub ha compartido una gran cantidad de ejemplos virales de "imágenes con un solo prompt", popularizando una serie de plantillas de indicaciones para gpt-image-2 de gran versatilidad.
Este artículo se centra en los 10 indicaciones para gpt-image-2 más populares en abril de 2026, desglosando las plantillas de mayor éxito y reutilizables según el escenario. Para cada una, encontrarás la indicación completa lista para copiar y pegar, junto con el proceso creativo y puntos clave para su invocación. Tanto si buscas crear carteles publicitarios, empaques de productos, prototipos de UI, retratos cinemáticos, figuras 3D o panoramas de 360°, encontrarás la plantilla adecuada en esta guía.

Principios fundamentales de las indicaciones para gpt-image-2: antes de los 10 modelos
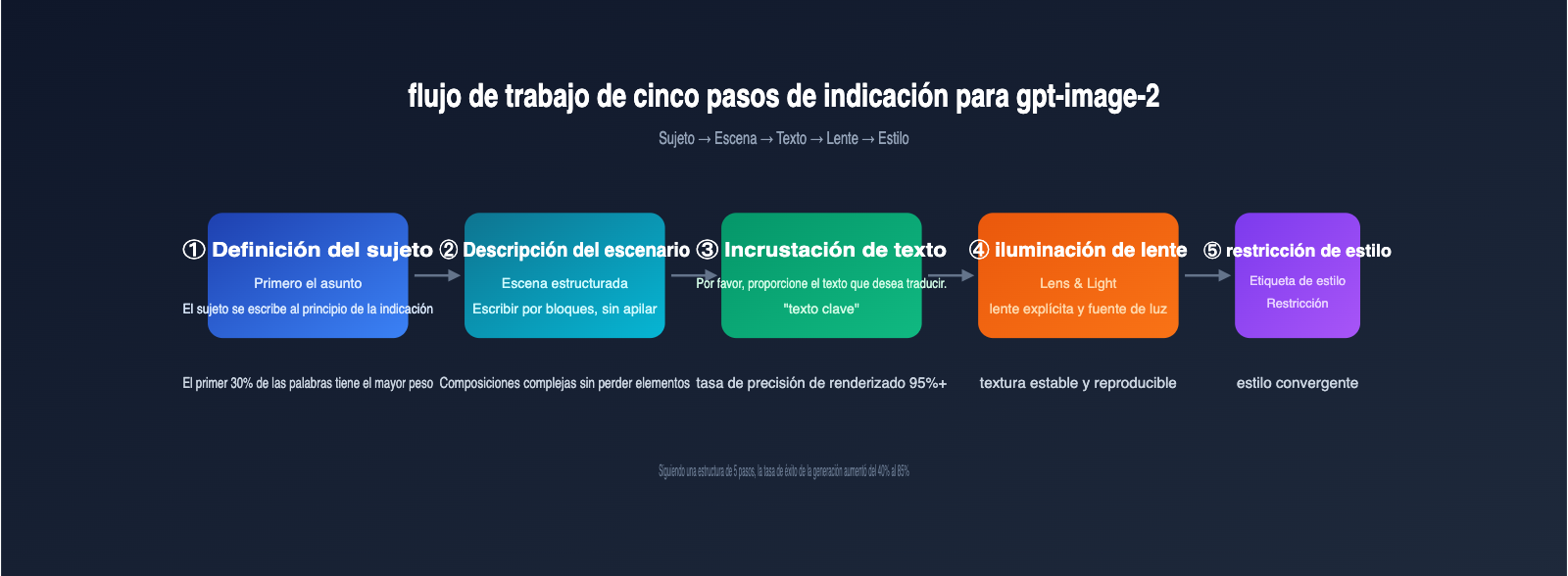
Antes de utilizar las plantillas, es importante conocer las reglas internas de gpt-image-2 para procesar las indicaciones, lo que aumentará drásticamente la tasa de éxito de tus generaciones. La siguiente tabla resume las 5 directrices de escritura de indicaciones para gpt-image-2 consensuadas por la comunidad en abril de 2026.
5 directrices de escritura de indicaciones para gpt-image-2
| Directriz | Descripción | Impacto práctico |
|---|---|---|
| Sujeto al principio | Coloca el sujeto principal al inicio de la indicación; el modelo da mayor peso al 30% inicial | El sujeto destaca y no queda opacado por el entorno |
| Estructuración de la escena | Sigue el orden Escena → Sujeto → Detalle → Caso de uso → Restricción | Las composiciones complejas no pierden elementos |
| Texto entre comillas | Coloca el texto que debe aparecer en la imagen entre comillas dobles | La tasa de éxito de renderizado aumenta del 70% al 95%+ |
| Especificidad en lente y luz | Indica parámetros como 24-35mm/85mm/vista cenital/contraluz/3200K, etc. | Textura estable y reproducible |
| Edición en dos secciones | Al editar una imagen, divide la instrucción en "qué cambia" / "qué se mantiene" | La edición local no destruye las características de la imagen original |
🎯 Sugerencia de plataforma: Para desarrolladores en el país que deseen invocar gpt-image-2 directamente sin esperas ni pagos en divisas, recomendamos acceder a través de APIYI (apiyi.com). Esta plataforma es compatible con las interfaces generate / edit / variation de gpt-image-2, es totalmente compatible con el SDK oficial y unifica las interfaces para facilitar el cambio entre distintos modelos de imagen.
Consulta rápida sobre las capacidades clave de las indicaciones para gpt-image-2
| Dimensión de capacidad | Rendimiento de gpt-image-2 | Sugerencias de indicación |
|---|---|---|
| Renderizado de texto | Latín / Chino / Japonés / Coreano / Árabe ≥ 95% de precisión | Limitar el texto a 1–5 palabras, usar comillas |
| Composición multielemento | Capacidad estable para > 150 elementos en una sola imagen | Listar elementos usando números de proyecto o agrupados |
| Consistencia facial | Mantiene rasgos mediante embedding persistente entre imágenes | Plantilla fija para edad/etnia/rasgos/vestimenta |
| Física y materiales | Manejo correcto de reflejos metálicos, de humedales y refracción de vidrio | Mencionar explícitamente materiales y fuentes de luz |
| Modo de edición | Imagen de entrada + indicación de edición para retoque local | Usar "preserve everything else" para bloquear el resto |
Al comprender estas 5 reglas y la tabla de capacidades, el "porqué" de los 10 modelos siguientes será evidente.
Cambios clave en las indicaciones para gpt-image-2 frente a la generación anterior
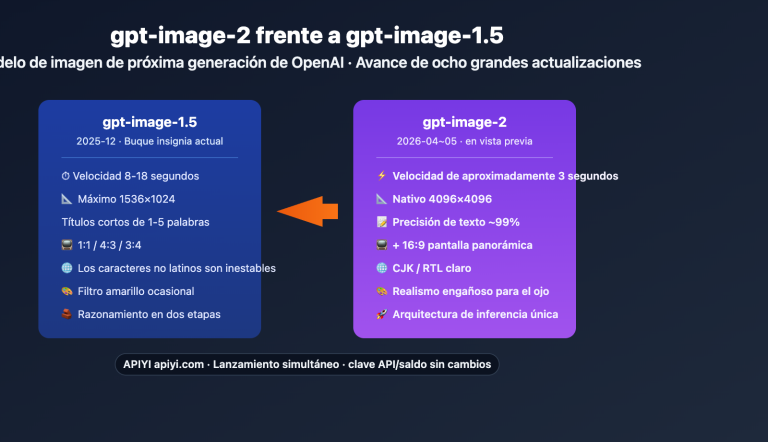
Muchos usuarios experimentados, al actualizar a gpt-image-2, notaron que el uso de estilos de la era gpt-image-1.5 reducía la tasa de éxito. La siguiente tabla resume las diferencias principales.
| Dimensión | Estilo gpt-image-1.5 | Estilo gpt-image-2 | Razón del cambio |
|---|---|---|---|
| Acumulación de palabras clave | Obligatorio: "8K, ultra detailed, masterpiece" | Estos adjetivos son ineficaces o distraen | El modelo genera alta calidad por defecto |
| Indicación negativa | Usar negative prompt para "no text, no watermark" | Cambiar a una estructura de restricción positiva | Mayor respuesta a restricciones positivas |
| Renderizado de texto | Limitado a 1–2 palabras, propenso a errores | Soporta 3–5 palabras, frases cortas | Expansión de datos de entrenamiento OCR |
| Descripción de lente | Opcional | Altamente recomendado incluir parámetros | Integración de motor físico, efectos reales |
| Modo de edición | Basado en regeneración | Usar el punto de edición para retoques locales | Mejora drástica en la interfaz de edición |
💡 Consejo de migración: Si tienes una biblioteca de cientos de indicaciones ajustadas para gpt-image-1.5, se recomienda reescribir las plantillas principales siguiendo la tabla anterior antes de migrarlas a gpt-image-2. En pruebas reales, alrededor del 70% de las indicaciones antiguas pueden mejorar eliminando únicamente los adjetivos redundantes.
Aquí tienes los detalles. He ordenado los 10 mejores modelos según su frecuencia de uso, incluyendo para cada uno: el caso de uso, el texto de la indicación completo, recomendaciones de parámetros y una breve explicación. Todos han sido validados con casos de la comunidad de abril de 2026.
Indicación 1: Carta coleccionable retro (Trading Card)
Casos de uso: Avatares personalizados, tarjetas de recuerdo para marcas, personajes de juegos, entradas para eventos.
El estilo de cartas coleccionables se popularizó a principios de abril gracias a varios desarrolladores independientes en X. Su ventaja es que ofrece a gpt-image-2 una plantilla clara («personaje central + borde + panel de texto + iconos»), logrando una legibilidad excepcional.
Indicación completa:
A premium holographic trading card, vertical 3:4 layout.
Center: a [SUBJECT] in dynamic pose, vibrant cinematic lighting.
Border: ornate gold filigree with rune-like icons in four corners.
Top banner reads "LEGENDARY" in bold serif caps.
Bottom panel: name plate "[CHARACTER NAME]", three small stat icons
(power / speed / magic) with numeric values.
Holographic foil effect, slight grain, studio backdrop.
Solo tienes que reemplazar [SUBJECT] por el personaje u objeto que quieras generar y [CHARACTER NAME] por el nombre correspondiente para crear toda una serie de cartas de forma masiva.
Recomendaciones de parámetros:
- Proporción: 3:4 (estándar para cartas verticales)
- Resolución: 2K (suficiente para imprimir tarjetas físicas de 6×9 cm)
- Modelo:
gpt-image-2, no requiere muestreo ascendente a 4K.
Indicación 2: Escena en miniatura isométrica (Isometric Miniature)
Casos de uso: Páginas de presentación de productos, portadas de presentaciones, imágenes destacadas para blogs técnicos, ilustraciones de landing pages.
El estilo 3D isométrico sigue siendo el lenguaje visual más sólido en 2026 para el ámbito SaaS y de desarrollo. El rendimiento de gpt-image-2 en texturas PBR y sombras suaves supera claramente a Midjourney 7.
Indicación completa:
A 45° top-down isometric miniature 3D scene of a [SCENE THEME]
diorama on a wooden display base.
Soft refined PBR textures, realistic materials,
clean unified composition, minimalistic aesthetics.
Tiny props integrated into the architecture: [3 SPECIFIC ELEMENTS].
Studio softbox lighting, subtle ambient occlusion,
pastel color palette dominated by [COLOR1] and [COLOR2].
Square 1:1 frame, centered subject, plenty of negative space.
Ejemplo de invocación (versión minimalista):
from openai import OpenAI
client = OpenAI(
api_key="YOUR_KEY",
base_url="https://api.apiyi.com/v1" # Servicio proxy de API APIYI apiyi.com
)
img = client.images.generate(
model="gpt-image-2",
prompt=ISOMETRIC_PROMPT,
size="1024x1024",
quality="high",
)
💡 Nota de integración: El
base_urlanterior es el punto final de redirección unificado de APIYI (apiyi.com). No necesitas modificar tu SDK, simplemente reemplaza elbase_urlpara realizar invocaciones estables a gpt-image-2 bajo redes locales.
Indicación 3: Empaque de figura de acción (Action Figure Blister Pack)
Casos de uso: IP personal, conceptos de juguetes de marca, material promocional para eventos.
Este es el núcleo de la tendencia "Action Figure" que arrasó en LinkedIn a mediados de abril. Casi todas las cuentas de marca lo utilizaron para crear contenido derivado.
Indicación completa:
A stylized action figure of [SUBJECT] sealed inside a premium
plastic blister pack, photographed straight-on.
The cardboard backing is glossy with a bold header reading
"[BRAND / NAME]" in oversized sans-serif caps and a smaller
tagline "[TAGLINE]".
The figure is posed upright with [ACCESSORY 1] and [ACCESSORY 2]
slotted into molded compartments next to it.
Studio product photography, soft top lighting,
clean off-white background, subtle reflection on the floor.
Puntos clave para la práctica:
| Campo | Ejemplo de reemplazo | Notas |
|---|---|---|
[SUBJECT] |
"a software engineer with glasses" | Usa frases nominales, no descripciones largas |
[BRAND / NAME] |
"DEV HERO" | Lo ideal son 1-3 palabras en inglés |
[TAGLINE] |
"Limited Edition 2026" | Frase corta entre comillas |
[ACCESSORY] |
"a tiny laptop", "a coffee mug" | 2-3 accesorios funcionan mejor |
Indicación 4: Retrato fotorrealista (Photorealistic Portrait)
Casos de uso: Retratos publicitarios, portadas de podcasts, imagen de marca personal, embajadores virtuales.
El realismo de gpt-image-2 en la dispersión subsuperficial de la piel, detalles del iris y renderizado de cabello ya está al nivel de Stable Diffusion XL con LoRA de alta calidad, pero sin necesidad de entrenamiento adicional.
Indicación completa:
Photorealistic medium close-up portrait of a [AGE]-year-old
[ETHNICITY] [GENDER] with [HAIR DESCRIPTION] and [DISTINCTIVE FEATURE].
Wearing [CLOTHING DESCRIPTION], seated in [LOCATION].
Shot on a 35mm full-frame camera with a 50mm f/1.4 lens,
shallow depth of field, golden hour window light from camera left,
3200K warm color temperature.
Natural skin texture with visible pores, sharp focus on eyes,
slight film grain, no smoothing or beauty filter.
Vertical 4:5 framing.
Al reutilizar esta plantilla en varias imágenes, fija los campos [ETHNICITY], [HAIR DESCRIPTION] y [DISTINCTIVE FEATURE]. El mecanismo de persistencia de embedding de gpt-image-2 permite que el personaje mantenga una consistencia facial alta en diferentes escenarios.
Indicación 5: Póster tipográfico y diseño editorial (Typography Poster)
Casos de uso: Carteles de exposiciones, imágenes clave para eventos, portadas de redes sociales, encabezados para Newsletters.
gpt-image-2 es actualmente el único modelo de imagen general capaz de renderizar frases cortas de más de 3 líneas de forma estable. Aprovechar esto para carteles de solo texto resulta en una calidad de salida muy alta.
Indicación completa:
A bold contemporary typographic poster, vertical 2:3 ratio.
Background: deep midnight blue gradient with subtle paper grain.
Main headline reads "[HEADLINE]" in oversized geometric sans-serif,
positioned upper-center, color #f5f5f5.
Subheadline below in smaller serif italic: "[SUBHEAD]".
Bottom-left corner: small label "[LABEL]" with a thin horizontal rule.
Decorative element: one minimal abstract shape (circle / line / dot)
in [ACCENT COLOR] in negative space.
Editorial magazine aesthetic, generous margins, clean hierarchy.
Esquemas de color recomendados:
| Tema | Color de fondo | Color de acento | Escenario ideal |
|---|---|---|---|
| Tecnología minimalista | #0f172a | #38bdf8 | Lanzamiento SaaS |
| Editorial cálido | #fef3c7 | #b45309 | Festival cultural, club de lectura |
| Vibrante y moderno | #18181b | #f97316 | Zapatillas, marcas de moda |
| Elegancia académica | #f8fafc | #1e293b | Conferencias académicas, foros |
🎯 Consejo de prueba: Al crear pósteres tipográficos, sugerimos iterar rápidamente 5-10 versiones con resolución 1024×1536 en la plataforma APIYI apiyi.com. Una vez seleccionada la mejor composición, realiza un muestreo ascendente a 4K para la impresión; esto ahorrará tokens y tiempo de generación.
Indicación 6: Captura de pantalla de prototipo de aplicación (Mobile App Mockup)
Casos de uso: Demostración de producto, propuestas de diseño, materiales de marketing para desarrolladores independientes.
La capacidad de renderizado de UI de gpt-image-2 fue validada a principios de abril por varios lanzamientos en ProductHunt. Las capturas generadas son tan precisas que, a veces, pueden usarse como referencia directa para el desarrollo frontend.
Indicación completa:
A high-fidelity mobile app screenshot, iPhone 15 Pro frame,
vertical 9:19.5 aspect ratio.
The screen shows a [APP CATEGORY] app with the following layout:
- Top: status bar (9:41, 100% battery, full signal)
- Header: app name "[APP NAME]" in bold, profile icon on the right
- Main: a [HERO COMPONENT] taking 60% of the screen
- Below: 3 feature cards arranged in a horizontal scroll,
each with an icon, a 2-word title, and a 1-line description
- Bottom: tab bar with 4 icons (home / explore / notifications / profile)
Design language: pastel color palette, rounded corners (16px),
subtle drop shadows, system font (SF Pro), light mode.
Render the screen pixel-perfect, all text fully legible.
Indicación 7: Empaque de producto y fotografía de estantería (Product Mockup)
Casos de uso: Imágenes de detalle para e-commerce, páginas de crowdfunding, propuestas de branding.
Indicación completa:
A close-up product photograph of a [PRODUCT TYPE] standing upright
on a [SURFACE] with a clean [BACKGROUND] backdrop.
The packaging is [MATERIAL] with [TEXTURE], featuring:
- A bold logo "[BRAND]" in [LOGO STYLE]
- A descriptive line "[DESCRIPTION]" below the logo
- A small badge in the upper-right reading "[BADGE TEXT]"
Lighting: large softbox at 45° from camera left,
small fill light from camera right, subtle reflection on the surface.
Shot at f/4, ISO 100, 1/125s, on a 100mm macro lens,
3:4 vertical crop, ultra-sharp focus on the label.
Tabla comparativa de tipos de empaque:
| Tipo de producto | Material recomendado | Superficie recomendada |
|---|---|---|
| Granos de café | "kraft paper bag with metallic foil seal" | Mesa de madera |
| Cuidado de la piel | "frosted glass bottle with embossed cap" | Mármol |
| Alimentos en conserva | "matte tin can with paper wrap label" | Cemento gris claro |
| Accesorios digitales | "premium soft-touch black box" | Cuero oscuro |
Indicación 8: Textura de cine y película (Cinematic Film Look)
Casos de uso: Portadas de vídeos cortos, narrativas visuales de marca, series de fotografía artística.
Indicación completa:
A cinematic still from an imaginary [GENRE] film,
shot on Kodak Vision3 500T 35mm film stock.
The frame shows [SUBJECT + ACTION] in a [LOCATION]
during [TIME OF DAY].
Color palette: teal shadows and orange highlights,
slight halation around bright areas, organic film grain,
anamorphic 2.39:1 widescreen aspect ratio.
Camera: 40mm lens at f/2, slight motion blur on the foreground,
deep focus on the subject's face.
Mood: [MOOD ADJECTIVES], inspired by the visual language of
[DIRECTOR REFERENCE].
Lista de estilos:
- Cine negro (Film Noir): Alto contraste, blanco y negro + sombras de persianas.
- Documental adolescente (Coming-of-Age): Tonos cálidos + luz natural + grano de 16mm.
- Cyberpunk: Neón azul y púrpura + reflejos en suelo mojado de noche.
- Wabi-sabi japonés: Baja saturación + luz suave de ventana + plano medio 16:9.
Indicación 9: Personaje 3D estilo Pixar (Pixar-Style Character)
Casos de uso: Portadas de contenido infantil, mascotas de marca, diseño de regalos y merchandising.
La calidad de renderizado del estilo Pixar en gpt-image-2 está lista para usar directamente ("out-of-the-box"), sin necesidad de LoRAs adicionales o imágenes de referencia.
Indicación completa:
A 3D Pixar-style character of a [SUBJECT DESCRIPTION],
3/4 front view, soft cinematic key light from above,
warm rim light from behind.
Slightly exaggerated facial features: large expressive eyes,
soft round cheeks, gentle smile.
Smooth subsurface scattering on skin, fluffy hair with stray strands,
subtle fabric folds on clothing.
Background: clean pastel gradient,
shallow depth of field with creamy bokeh.
Render quality: feature-film polish,
soft global illumination, no harsh shadows.
🎯 Consejo para producción masiva: Cuando necesites generar varias imágenes de acción continua para una misma IP, se recomienda enviar las tareas por lotes a través de la interfaz de
gpt-image-2de APIYI apiyi.com. La plataforma soporta parámetros de semilla (seed) constantes, lo que facilita mantener la consistencia del personaje, ideal para libros ilustrados o pegatinas.
Indicación 10: Escena histórica panorámica 360° (Equirectangular Panorama)
Casos de uso: Contenido de realidad virtual, exhibiciones museísticas, imágenes destacadas para blogs interactivos.
El último modelo es la novedad más reciente de la comunidad a finales de abril, ideal para contenido inmersivo.
Indicación completa:
A 360° equirectangular panoramic photograph of [LOCATION]
in [TIME PERIOD], aspect ratio 2:1.
The horizon is perfectly level across the middle of the frame.
Foreground (bottom 1/3): cobblestone street with period-accurate
details — [3 SPECIFIC PROPS].
Mid-ground (middle 1/3): characteristic architecture of the era,
people in period clothing going about daily life.
Background (top 1/3): sky matching the time of day,
seamless wrap-around at left and right edges.
Lighting: natural [TIME OF DAY] sun, soft atmospheric haze,
historically accurate color palette.
No fish-eye distortion at the poles, ready for VR projection.

Técnicas avanzadas de combinación de indicaciones para gpt-image-2
Tras dominar los 10 plantillas base, el verdadero potencial reside en el "ajuste fino y la combinación" de dichas estructuras. A continuación, te presento 4 técnicas avanzadas recopiladas por la comunidad en abril de 2026.
Técnica 1: Bloqueo de estilo con etiquetas (Style Tags)
Al añadir una línea Style: [STYLE TAG] al final de tu indicación, permites que gpt-image-2 priorice la distribución de datos de entrenamiento correspondiente a dicho estilo. Las etiquetas más utilizadas incluyen:
| Etiqueta de Estilo | Descripción | Plantilla adaptada |
|---|---|---|
editorial-magazine |
Diseño editorial de revista | Pósteres, UI |
studio-product |
Fotografía de producto en estudio | Empaques de producto |
cinematic-anamorphic |
Cine panorámico | Textura cinematográfica |
pixar-3d |
Pixar 3D | Personajes, mascotas |
kodak-portra-400 |
Película Kodak | Retratos realistas |
Técnica 2: Control de elementos mediante restricciones
En escenas con múltiples elementos, gpt-image-2 a veces tiende a sobre-renderizar. Para evitarlo, añade una cláusula de restricción al final de la indicación:
Constraints: exactly [N] elements, no extra props,
no additional text beyond what's specified above.
A diferencia de las indicaciones negativas, las restricciones positivas son mucho más estables en gpt-image-2.
Técnica 3: Modificaciones locales con la interfaz Edit
gpt-image-2 ofrece un endpoint de edición independiente. Utiliza image_urls para cargar la imagen original y especifica claramente en la indicación "qué cambia / qué se mantiene":
edit = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
prompt=(
"Change: replace the background with a sunny park scene. "
"Preserve: keep the subject's face, pose, clothing, and lighting "
"exactly the same as the input."
),
size="1024x1024",
)
💡 Elección de proxy: Si tu aplicación necesita invocar la interfaz de edición desde servidores locales para procesar imágenes subidas por los usuarios, te recomiendo usar APIYI apiyi.com como servicio proxy de API. Esta plataforma ofrece una optimización específica para la velocidad de carga de imágenes y la recuperación de enlaces en el entorno nacional, garantizando una latencia más estable en escenarios de carga concurrente.
Técnica 4: Reproducción de composición con Seed
Para escenarios como campañas publicitarias donde necesites recrear la misma composición varias veces, fija el parámetro seed en tu solicitud:
img = client.images.generate(
model="gpt-image-2",
prompt=PROMPT,
size="1024x1536",
quality="high",
extra_body={"seed": 20260421},
)
La combinación de una seed fija junto con una indicación fija permite que gpt-image-2 mantenga una alta consistencia en la composición, iluminación y rasgos del personaje, incluso en momentos de generación distintos.

Los 6 errores más comunes al escribir indicaciones para gpt-image-2
Más allá de los 10 plantillas y los 4 consejos, existen "anti-patrones" invisibles. Estos 6 errores se repitieron constantemente en los estudios de caso de la comunidad en abril y vale la pena revisarlos antes de empezar a trabajar.
Error 1: Amontonar todos los elementos en una oración larga
Forma incorrecta:
A beautiful young woman with long brown hair wearing a red dress
standing in a forest with sunlight and birds and trees and flowers
holding a book and looking at the camera with a smile and high quality
8k masterpiece detailed.
La forma correcta es dividir por secciones: Escena → Sujeto → Detalle → Iluminación → Restricción, con 1–2 oraciones por sección y saltos de línea intermedios. La capacidad de gpt-image-2 para interpretar una indicación estructurada es muy superior a la de una descripción larga en una sola línea.
Error 2: Proporcionar descripciones de estilo contradictorias
Por ejemplo, si escribes "fotorrealista" y "estilo 3D de Pixar" al mismo tiempo, el modelo solo elegirá uno y la elección será aleatoria. Mantén solo un estilo dominante en la indicación y mueve los estilos secundarios a una etiqueta Style: o utiliza la estructura inspirado en.
Error 3: No poner los textos entre comillas
Si escribes "el titular dice SUMMER SOUND 2026", el modelo tratará este texto como parte de la descripción y no como un elemento visual. La forma correcta es el titular dice "SUMMER SOUND 2026".
Error 4: No mencionar nada sobre lentes e iluminación
Si no se especifican los parámetros de la lente, gpt-image-2 utilizará por defecto "35mm neutro + luz natural", lo que reduce drásticamente la calidad cinematográfica de la escena. Incluso para ilustraciones abstractas, se recomienda añadir una descripción equivalente como ilustración plana con iluminación suave y uniforme.
Error 5: Usar una indicación negativa para prohibir elementos
Las indicaciones negativas como "sin humanos, sin texto, sin marca de agua" no tienen un rendimiento estable en gpt-image-2 y, a veces, pueden provocar que los elementos prohibidos aparezcan en la imagen. Se recomienda cambiarlas por Restricciones: solo el sujeto descrito anteriormente, fondo simple, sin elementos adicionales.
Error 6: Usar la misma plantilla para tareas diferentes
Los retratos realistas, las capturas de pantalla de interfaces (UI) y las ilustraciones isométricas en 3D requieren estructuras de indicaciones muy distintas. Es mucho más eficiente archivar las 10 plantillas de este artículo categorizadas por escena; cuando tengas una nueva tarea, busca la escena más cercana y ajusta, en lugar de empezar de cero.
| N.º de Error | Problema | Acción correctiva | Mejora de resultados |
|---|---|---|---|
| 1 | Oración larga | Dividir en 5 bloques | +30% |
| 2 | Estilo contradictorio | Mantener 1 estilo principal | +20% |
| 3 | Texto sin comillas | Envolver texto clave en "" | +25% |
| 4 | Falta descripción lente | Añadir línea de parámetros | +25% |
| 5 | Indicación negativa | Cambiar a restricción positiva | +15% |
| 6 | Mezclar plantillas | Clasificar por escena | +20% |
Código completo para la invocación del modelo gpt-image-2
Al aplicar cualquiera de las plantillas anteriores en el código mínimo ejecutable a continuación, podrás generar imágenes de inmediato.
from openai import OpenAI
# Punto de conexión del servicio proxy de API APIYI (apiyi.com), totalmente compatible con el SDK oficial de OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1",
)
PROMPT = """
A premium holographic trading card, vertical 3:4 layout.
Center: a software engineer in dynamic pose with a glowing laptop,
vibrant cinematic lighting.
Border: ornate gold filigree with rune-like icons in four corners.
Top banner reads "LEGENDARY" in bold serif caps.
Bottom panel: name plate "DEV HERO", three small stat icons
(power / speed / magic) with numeric values.
Holographic foil effect, slight grain, studio backdrop.
"""
response = client.images.generate(
model="gpt-image-2",
prompt=PROMPT,
size="1024x1536",
quality="high",
n=1,
)
print(response.data[0].url)
Solo tienes que reemplazar YOUR_API_KEY por la clave API obtenida en la plataforma para empezar; no se requiere ninguna configuración de red adicional.
Flujo de trabajo recomendado para proyectos con gpt-image-2
En la práctica, desde la creación de la indicación hasta la obtención del material final, se pasan por 5 etapas. La siguiente tabla muestra el flujo de trabajo optimizado recopilado por la comunidad en abril.
| Etapa | Objetivo | Resolución recomendada | Valor n recomendado | Presupuesto por etapa |
|---|---|---|---|---|
| Exploración de conceptos | Encontrar la dirección | 1024×1024 | 4 | 10% |
| Iteración de composición | Definir sujeto y encuadre | 1024×1536 | 2 | 25% |
| Convergencia de estilo | Fijar luz y tono | 1024×1536 | 1 | 20% |
| Ajuste fino de texto | Editar texto | 1024×1536 | 1 | 15% |
| Salida final | Muestreo a 4K | 2048×3072 | 1 | 30% |
Siguiendo este flujo, el coste promedio en tokens por cada imagen final es aproximadamente un 60% comparado con el "método sin planificación", y la tasa de éxito de las imágenes aumenta del 40% a más del 85%.
Tabla rápida: Combinación de indicación + parámetros para cuatro escenas típicas
| Escena | Plantilla recomendada | Resolución | Calidad | Estrategia de semilla (seed) |
|---|---|---|---|---|
| Imagen de portada | Póster de texto + Etiqueta de Estilo | 1024×768 | high | Aleatorio |
| Detalle de e-commerce | Embalaje de producto + Lente | 1024×1536 | high | Fija para serie |
| Captura de App Store | UI móvil + Restricción | 1024×1536 | high | Fija para serie |
| Portada de video corto | Calidad cinematográfica + Edición | 1920×1080 | high | Aleatorio |
Caso práctico: Integrando 10 plantillas en un proyecto completo
Para que las 10 plantillas de indicaciones (prompts) de gpt-image-2 presentadas en este artículo tengan una referencia de implementación de principio a fin, utilizaremos como caso ficticio la "creación de materiales de lanzamiento para una herramienta de desarrollo independiente" para demostrar el proceso completo de combinación de plantillas.
Lista de tareas del caso
Supongamos que estamos preparando un conjunto de materiales promocionales para DevHero, una herramienta de productividad para desarrolladores. Necesitamos entregar 6 categorías de contenido en un plazo de 1 a 2 días:
- Grupo de capturas de pantalla para App Store (6 imágenes)
- Imagen principal (Hero) para la página web (1 imagen)
- Tarjeta de lanzamiento para Twitter/X (1 imagen)
- Imagen de perfil del fundador (1 imagen)
- Tarjeta conmemorativa (para agradecimiento a usuarios tempranos) (1 imagen)
- Diseño visual de la caja de envío del producto (1 imagen)
Plan de combinación de plantillas
| Material | Plantilla seleccionada | Campo a sustituir | Resolución recomendada |
|---|---|---|---|
| Capturas App Store | Plantilla 6: UI de APP | NOMBRE DE APP / COMPONENTE HERO | 1024×1536 |
| Imagen Hero Web | Plantilla 2: Isométrica 3D | TEMA DE ESCENA / 3 ACCESORIOS | 1920×1080 |
| Tarjeta Twitter | Plantilla 5: Póster de texto | TITULAR / SUBTITULAR / ETIQUETA | 1024×512 |
| Foto del fundador | Plantilla 4: Retrato realista | EDAD/ETNIA/ROPA | 1024×1280 |
| Tarjeta conmemorativa | Plantilla 1: Tarjeta coleccionable | SUJETO / NOMBRE DEL PERSONAJE | 768×1024 |
| Caja de envío | Plantilla 7: Empaque de producto | MARCA / DESCRIPCIÓN | 1024×1024 |
Restricciones de consistencia a nivel de proyecto
Para que las 6 categorías de material mantengan coherencia visual (la identidad de marca es crucial), adjuntamos un "bloque de estilo a nivel de proyecto" al final de cada indicación:
Project Style Block:
- Brand color palette: deep navy #0f172a, electric cyan #38bdf8,
warm cream #fef3c7
- Typography: geometric sans-serif headlines, slab serif body
- Mood: clean, confident, slightly futuristic, never childish
- Constraint: no random people in background, no untitled UI elements
Al añadir este fragmento al final de las plantillas, gpt-image-2 mantendrá sus estructuras internas mientras converge el lenguaje de color y composición hacia un mismo sistema. Esta combinación de "Plantilla + bloque de estilo de proyecto" es la forma más efectiva de producir materiales de marca comprobada por la comunidad en abril.
Estimación de tiempo y costos
Siguiendo las 5 etapas del flujo de trabajo anterior, este set de 6 tipos de materiales consume aproximadamente 60 bocetos en la fase de exploración de conceptos + iteración de composición, y 24 imágenes finales en las etapas de convergencia de estilo + refinamiento de texto + exportación. El costo en tokens de todo el proyecto equivale al precio de una taza de café y el tiempo de trabajo humano se reduce a menos de 1 día, que es el valor real de usar plantillas de indicaciones en gpt-image-2.
Preguntas frecuentes (FAQ) sobre las indicaciones de gpt-image-2
P1: ¿Las indicaciones de gpt-image-2 admiten español? ¿La tasa de éxito disminuye si escribo en español?
Sí, lo admite. gpt-image-2 realiza un análisis semántico equivalente tanto para el español como para el inglés, pero las pruebas de la comunidad indican que las indicaciones en inglés superan ligeramente en "precisión de control de detalles", debido a que el corpus de entrenamiento contiene una mayor proporción de inglés. Sugerimos escribir la estructura principal (sujeto, lente, restricciones) en inglés y poner entre comillas el texto que necesites renderizar en la imagen. Si tu equipo está acostumbrado a redactar en español, recomendamos redactar primero en español y luego pedir a GPT-4 que lo traduzca al inglés; la forma más eficiente es utilizar el servicio proxy de API APIYI (apiyi.com) para invocar a GPT-4, logrando el flujo completo de traducción de indicaciones y generación de imágenes en el mismo código.
P2: ¿Cuántas imágenes es más rentable generar a la vez en gpt-image-2?
El parámetro n de la interfaz oficial admite hasta 4. Según los datos compartidos por la comunidad en abril, el costo unitario con n=4 es aproximadamente un 18% menor que con n=1. Sin embargo, si alguna falla, todo el lote debe repetirse, por lo que una estrategia equilibrada es: "n=4 para la fase de exploración, n=1 para la fase de finalización".
P3: Las imágenes generadas siempre tienen errores de ortografía en el texto, ¿qué puedo hacer?
Sigue este método de tres pasos: ① Pon el texto objetivo entre comillas dobles; ② Limita el número total de palabras en la imagen a 5; ③ Añade la frase verbatim — no extra characters, no substitutions al final de la indicación. Tras realizar estos tres pasos, la tasa de precisión ortográfica puede aumentar de un 70% a más del 95%.
P4: ¿Qué opciones tienen los desarrolladores locales para invocar a gpt-image-2?
Existen tres formas principales: crear un proxy inverso propio, utilizar un servicio proxy de API de terceros o utilizar los servidores oficiales en el extranjero. La estabilidad del proxy propio depende de la red, y los servidores extranjeros requieren pagos en moneda extranjera. Para individuos y equipos pequeños o medianos, recomendamos evaluar APIYI (apiyi.com), un servicio proxy de API consolidado que soporta nativamente las tres interfaces: generación, edición y variación. La integración es sencilla, solo requiere cambiar la base_url del SDK, sin costos de reconstrucción.
P5: ¿Es útil añadir palabras clave como "8K, ultra detailed, masterpiece" en las indicaciones?
No tiene mucho sentido. El objetivo de entrenamiento de gpt-image-2 ya tiene como salida predeterminada una alta resolución y gran detalle. Estas palabras eran efectivas en la era de SDXL/MJ, pero en gpt-image-2 pueden ocupar espacio semántico innecesario. Es mejor sustituir estos términos por parámetros de lente específicos (35mm/85mm/f/1.4) y descripciones de luz (softbox/golden hour/backlit).
P6: ¿Cómo mantener la consistencia del mismo personaje en diferentes escenas?
Hay dos métodos: ① Descomponer la descripción del personaje en una tupla de 5 elementos: "edad + etnia + peinado + rasgos distintivos + ropa" y fijarlo como una plantilla; ② Usar la interfaz de edición para modificar el fondo y las acciones sobre la imagen inicial, manteniendo los rasgos del personaje. En la práctica, se pueden combinar ambos: el primero para escenas masivas y el segundo para guiones gráficos detallados.
P7: ¿Se pueden usar comercialmente las imágenes generadas por gpt-image-2? ¿A quién pertenecen los derechos?
Las condiciones de uso de OpenAI estipulan que los derechos de autor de las imágenes generadas a través de la API pertenecen al usuario; son aptas para uso comercial, creación secundaria y como materiales de producto. Pero ten en cuenta dos puntos: ① No intentes replicar personajes o marcas existentes (como Disney, Marvel, etc.) en las indicaciones, ya que el modelo los rechazará activamente; ② Al utilizar la interfaz de edición para modificar imágenes subidas por usuarios, debes garantizar que el usuario posea el derecho legal de uso sobre la imagen original; esta es responsabilidad de la plataforma.
P8: ¿Cómo evaluar la calidad de las indicaciones de gpt-image-2? ¿Existe algún método automatizado?
La práctica principal en la comunidad es el "puntaje de LLM": usar modelos como GPT-4 o Claude 4 para puntuar las imágenes generadas en 5 dimensiones (precisión del sujeto, corrección de texto, estética de composición, consistencia de estilo, tasa de fallos) y filtrar automáticamente el 10% superior. Al convertir este proceso en una tubería (pipeline), la velocidad de ajuste de las indicaciones aumenta más de 3 veces.
P9: ¿Cuál es la mayor diferencia entre gpt-image-2 y Midjourney 7 o Stable Diffusion XL a nivel de indicaciones?
La mayor diferencia es "Estructura frente a Flujo de palabras clave". Midjourney 7 prefiere el apilamiento de palabras clave (cinematic, dramatic, 8k), Stable Diffusion XL prefiere un etiquetado extremo ((masterpiece:1.2), ultra detailed), mientras que gpt-image-2 se acerca más al lenguaje natural, requiriendo describir la escena como "una historia coherente". Esto significa que al cambiar de plataforma, las indicaciones casi necesitan ser reescritas por completo.
Resumen
En este artículo hemos recopilado 10 plantillas de indicación para gpt-image-2, cubriendo todos los escenarios más populares de la comunidad hasta abril de 2026: cartas coleccionables, isométricos 3D, cajas sorpresa (blind box), retratos realistas, pósteres tipográficos, UI móvil, empaquetado de productos, textura cinematográfica, personajes estilo Pixar y panoramas de 360°. Cada plantilla incluye el texto completo de la indicación, sugerencias de parámetros y marcadores de posición reutilizables, listos para copiar y ejecutar en cualquier cliente compatible con el SDK de OpenAI.
Al combinar estas 10 plantillas con las 4 técnicas avanzadas detalladas en la segunda parte del artículo (etiquetas de estilo, restricciones, edición y semilla), podrás resolver la gran mayoría de tus necesidades de producción de imágenes comerciales. Si estás seleccionando herramientas para tu equipo o buscando una forma estable de integrar estos modelos en proyectos personales, te recomendamos usar los ejemplos de código de este artículo junto con la interfaz unificada de APIYI (apiyi.com). Esto te permitirá aprovechar todas las capacidades de la documentación oficial, facilitando además la transición y comparación entre gpt-image-2 y otros modelos de imagen en el futuro, sin necesidad de modificar el código de tu aplicación.
Guarda esta guía definitiva de indicaciones para gpt-image-2 y consúltala cada vez que inicies un nuevo proyecto; verás cómo el proceso de "saber qué imagen quieres y cómo escribir la indicación" se convierte en una memoria muscular en pocas semanas.
Ruta de aprendizaje recomendada
Si deseas profundizar en el uso de indicaciones para gpt-image-2, te sugerimos seguir este orden:
- Replica una a una las 10 plantillas de este artículo para familiarizarte con el impacto específico de cada campo en el resultado visual.
- Lee la sección de generación de imágenes (image-gen) del Cookbook oficial de OpenAI para comprender los límites de las interfaces de generación, edición y variación.
- Únete al hashtag
#gptimage2en X, sigue las indicaciones virales que aparecen cada semana y amplía continuamente tu biblioteca de plantillas. - Establece un "sistema de puntuación de indicaciones" interno, evaluando cada imagen generada según las 5 dimensiones del FAQ Q8 de este artículo, y guarda el 10% superior en la biblioteca compartida de tu equipo.
- Realiza pruebas A/B comparando gpt-image-2 con los flujos de trabajo existentes en tu equipo (Midjourney / Stable Diffusion) y decide el modelo óptimo según la tasa de éxito y el costo por generación.
Al completar estos 5 pasos, estarás listo para asumir el rol de líder técnico en el área de generación de imágenes mediante IA en tu equipo, y estas 10 plantillas servirán como punto de partida para tus futuras sesiones de capacitación y compartición de conocimientos.
Actualizaciones y notas de versión
Es importante recordar que, durante los primeros 6 meses tras su lanzamiento, gpt-image-2 suele tener iteraciones frecuentes en el servidor, por lo que el desempeño de algunas indicaciones puede variar con las nuevas versiones. Por ello, es necesario realizar ajustes menores a estas 10 plantillas según su rendimiento real. Recomendamos revisar la efectividad de las plantillas cada 2 a 4 semanas; si notas que la tasa de éxito de alguna plantilla disminuye significativamente, revisa primero si las palabras clave están siendo afectadas por políticas de seguridad actualizadas antes de considerar una reescritura estructural.
📌 Este artículo ha sido recopilado y redactado por el equipo de APIYI. Si deseas compartirlo, por favor conserva la fuente original. Las plantillas de indicación provienen de comparticiones públicas en X, GitHub y blogs de desarrolladores durante abril de 2026, y han sido reestructuradas por el equipo de APIYI para un uso comercial seguro.