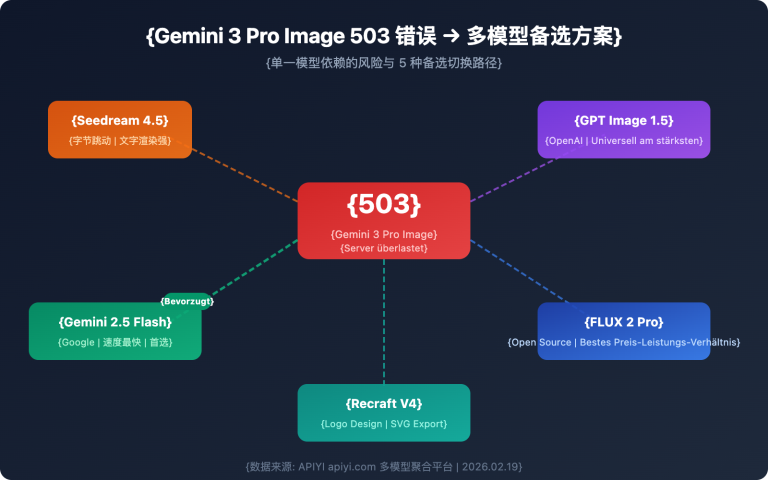
Bist du verwirrt über die Fehlermeldung "You've reached your rate limit. Please try again later."? Gestern hat noch alles einwandfrei funktioniert, die Token-Limits wurden nicht überschritten, und plötzlich geht gar nichts mehr?
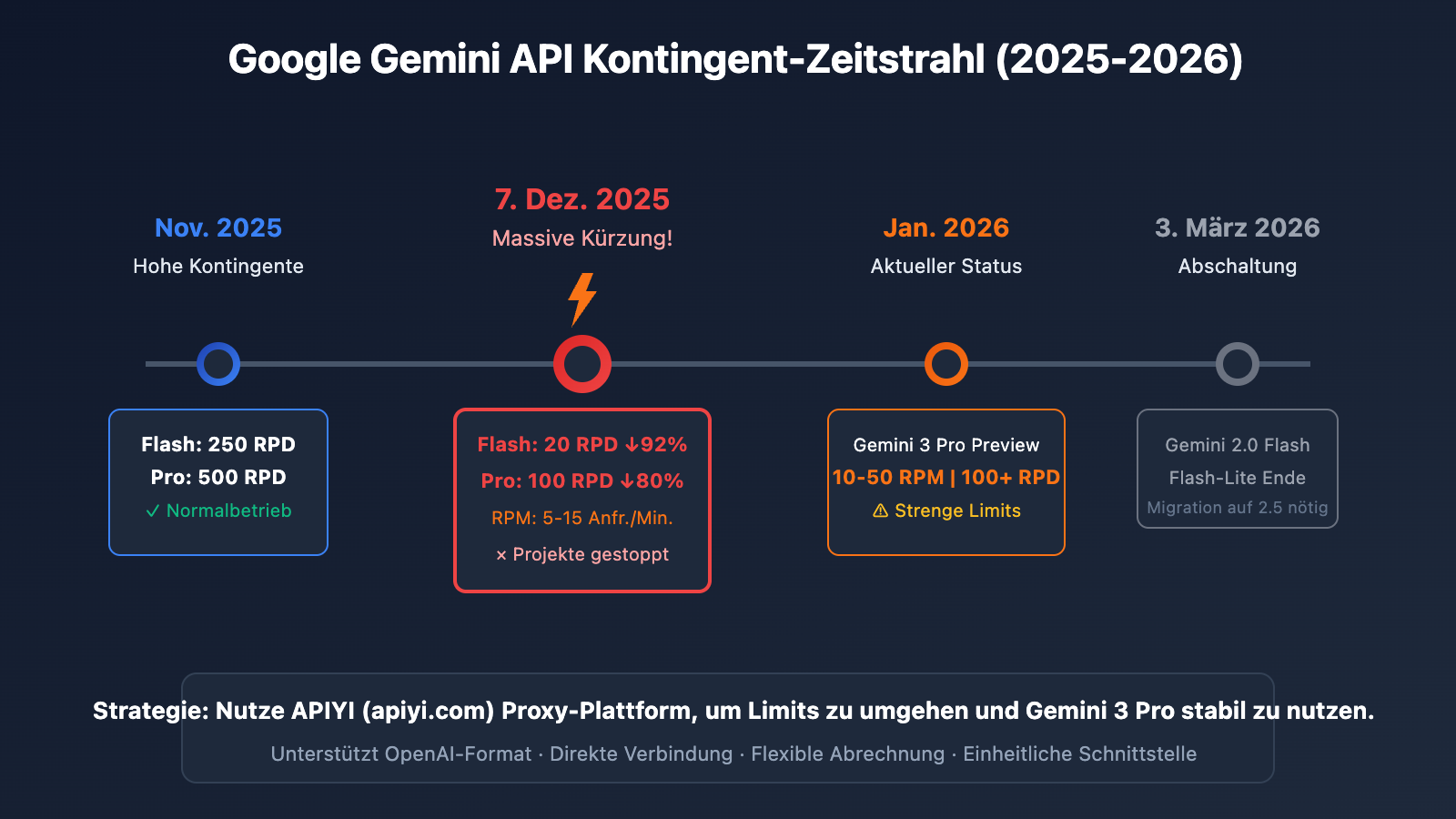
Wenn du ein privater Nutzer bist, der Gemini 3 Pro im AI Studio für die Texterstellung nutzt, bist du nicht allein. Am 7. Dezember 2025 hat Google die kostenlosen Kontingente für die Gemini-API heimlich um 50 % bis 92 % gekürzt. Diese Änderung hat dazu geführt, dass weltweit zehntausende Entwicklerprojekte über Nacht zum Stillstand kamen.
Kernpunkte: Nach der Lektüre dieses Artikels wirst du die wahren Gründe für die Kontingentkürzung verstehen, 5 Wege zur Überwindung der Rate-Limits kennenlernen und erfahren, wie du Gemini 3 Pro stabil über eine API-Proxy-Plattform nutzen kannst.

Kernpunkte der Gemini 3 Pro Rate Limits
Bevor wir das Problem lösen, müssen wir verstehen, welche Anpassungen Google vorgenommen hat.
| Anpassung | Vorher (Nov. 2025) | Nachher (7. Dez. 2025) | Reduktion |
|---|---|---|---|
| Flash-Modell RPD | 250 Anfragen/Tag | 20 Anfragen/Tag | -92% |
| Pro-Modell RPD | 500 Anfragen/Tag | 100 Anfragen/Tag | -80% |
| Pro-Modell RPM | 15 Anfragen/Min. | 5 Anfragen/Min. | -67% |
| Gemini 3 Pro Preview | Unbegrenzt | 10-50 RPM, 100+ RPD | Neue Limits |
Die 4 Dimensionen der Gemini 3 Pro Rate Limits
Das Rate-Limit-System von Google steuert die Nutzung über 4 Dimensionen:
| Dimension | Bezeichnung | Beschreibung | Aktueller Wert (Free Tier) |
|---|---|---|---|
| RPM | Requests Per Minute | Anfragen pro Minute | 5-15 Mal |
| TPM | Tokens Per Minute | Token pro Minute | 250.000 |
| RPD | Requests Per Day | Anfragen pro Tag | 20-100 Mal |
| IPM | Images Per Minute | Bilder pro Minute | Gilt für Multimodalität |
🔑 Kerninformation: Da Gemini 3 Pro eine Preview-Version ist, liegen die aktuellen Limits im Free Tier bei ca. 10-50 RPM und 100+ RPD. In der Praxis berichten viele Nutzer jedoch von deutlich strengeren Einschränkungen als in der Dokumentation angegeben.
Warum hat Google die Kontingente so drastisch gekürzt?
Laut offizieller Mitteilung von Google basieren die Anpassungen auf folgenden Gründen:
- Explosiver Nachfragezuwachs: Der Einsatz von KI-Anwendungen ist 2025 sprunghaft angestiegen, die API-Aufrufe übertrafen alle Erwartungen.
- Infrastrukturbelastung: Die Gemini 2.0/3.0-Modelle stellen extrem hohe Anforderungen an die Rechenleistung.
- Schutz der Nutzererfahrung für zahlende Kunden: Die Servicequalität für zahlende Nutzer soll vorrangig gesichert werden.
- Anpassung der Geschäftsstrategie: Entwickler sollen gezielt zu den kostenpflichtigen Modellen geführt werden.
5 Lösungen für Gemini 3 Pro Ratenbeschränkungen (Rate Limits)
Hier sind 5 bewährte Lösungen für die Ratenbeschränkungen (Rate Limits) in AI Studio:
Lösung 1: Wechsel zu anderen Gemini-Modellen
Dies ist die einfachste temporäre Lösung. Verschiedene Modelle haben unterschiedliche Kontingentbeschränkungen:
| Modell | RPM | RPD | Empfohlenes Szenario |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | 15 | 1.000 | Erste Wahl für leichtgewichtige Aufgaben |
| Gemini 2.5 Flash | 10 | 500 | Ausgewogene Leistung |
| Gemini 2.5 Pro | 5 | 100 | Komplexe logische Schlussfolgerungen |
| Gemini 3 Pro Preview | 10-50 | 100+ | Stärkste Fähigkeiten, strengere Beschränkungen |
💡 Praktischer Tipp: Wenn Ihre Aufgabe nicht die volle Leistung von Gemini 3 Pro erfordert, bietet der Wechsel zu Gemini 2.5 Flash-Lite ein Kontingent von bis zu 1.000 RPD, was für das tägliche Lernen völlig ausreicht.
Lösung 2: Auf die Zurücksetzung des Kontingents warten
Das RPD-Kontingent (Anfragen pro Tag) der Gemini API wird um Mitternacht Pazifischer Zeit zurückgesetzt.
Vergleichstabelle für die Kontingent-Rücksetzung:
- Peking-Zeit: 16:00 Uhr (Sommerzeit) / 17:00 Uhr (Winterzeit)
- Tokio-Zeit: 17:00 Uhr (Sommerzeit) / 18:00 Uhr (Winterzeit)
- Mitteleuropäische Zeit (MEZ): 09:00 Uhr
Lösung 3: Upgrade auf den kostenpflichtigen Tarif (Paid Tier)
Wenn Sie Gemini 3 Pro stabil nutzen müssen, ist das Upgrade auf den kostenpflichtigen Tarif der offizielle Weg:
| Stufe | Anforderung | RPM | RPD | Durchschnittliche monatliche Kosten |
|---|---|---|---|---|
| Kostenlose Stufe | Keine | 5-15 | 20-100 | $0 |
| Tier 1 | Kreditkarte hinterlegen | 150-300 | Unbegrenzt | Pay-as-you-go |
| Tier 2 | Kumulierte Ausgaben $250 + 30 Tage | 1.000+ | Unbegrenzt | Pay-as-you-go |
Gemini 3 Pro Preise:
- Input: $2,00 / Million Token (≤200K Kontext)
- Output: $12,00 / Million Token (≤200K Kontext)
- Extralanger Kontext (>200K): Preis verdoppelt sich
Lösung 4: Verwendung einer API-Relay-Plattform (Empfohlen)
Für Einzelpersonen zu Lernzwecken und kleine bis mittlere Teams ist die Nutzung einer API-Relay-Plattform die kosteneffizienteste Wahl:
# Gemini 3 Pro Aufruf über APIYI - Minimalbeispiel
import openai
client = openai.OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{"role": "user", "content": "Bitte erklären Sie, was die Transformer-Architektur ist."}
],
max_tokens=2000
)
print(response.choices[0].message.content)
🚀 Schnellstart: Es wird empfohlen, die Plattform APIYI (apiyi.com) für den schnellen Zugriff auf Gemini 3 Pro zu nutzen. Die Plattform bietet eine einheitliche Schnittstelle im OpenAI-Format, sodass Sie sich keine Sorgen um Kontingentbeschränkungen machen müssen. Die Integration ist in 5 Minuten erledigt.
Vollständiges Code-Beispiel anzeigen (inkl. Fehlerbehandlung)
# Vollständiges Gemini 3 Pro Aufrufbeispiel - über APIYI
import openai
from openai import OpenAI
import time
def call_gemini_3_pro(prompt: str, max_retries: int = 3) -> str:
"""
Ruft das Gemini 3 Pro Modell auf
Args:
prompt: Benutzereingabe
max_retries: Maximale Anzahl an Versuchen
Returns:
Inhalt der Modellantwort
"""
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{
"role": "system",
"content": "Du bist ein professioneller KI-Assistent. Bitte antworte auf Deutsch."
},
{
"role": "user",
"content": prompt
}
],
max_tokens=4000,
temperature=0.7
)
return response.choices[0].message.content
except openai.RateLimitError as e:
print(f"Anfrage zu häufig, warte auf erneuten Versuch... ({attempt + 1}/{max_retries})")
time.sleep(2 ** attempt) # Exponentieller Backoff
except openai.APIError as e:
print(f"API-Fehler: {e}")
raise
raise Exception("Maximale Anzahl an Versuchen erreicht")
# Anwendungsbeispiel
if __name__ == "__main__":
result = call_gemini_3_pro("Erkläre die Funktionsweise von Großen Sprachmodellen in 100 Wörtern")
print(result)

Vorteile der Nutzung einer API-Relay-Plattform:
| Vergleichsaspekt | AI Studio Direkt | APIYI Relay |
|---|---|---|
| Kontingentlimit | Streng (20-100 RPD) | Flexibel, Pay-as-you-go |
| Netzwerkstabilität | VPN erforderlich | Direkte Verbindung |
| Schnittstellenformat | Google-spezifisch | OpenAI-kompatibel |
| Modellwechsel | Nur Gemini-Serie | GPT/Claude/Gemini etc. |
| Zahlungsmethoden | Externe Kreditkarte | Bequeme lokale Optionen |
Lösung 5: Sinnvolle Planung der Abfragestrategie
Wenn Sie die kostenlose Stufe nutzen müssen, können folgende Strategien die Ausnutzung des Kontingents maximieren:
1. Batch-Verarbeitung von Anfragen
# Mehrere kleine Fragen zu einer Anfrage zusammenfassen
combined_prompt = """
Bitte beantworte nacheinander die folgenden Fragen:
1. Was ist der Unterschied zwischen list und tuple in Python?
2. Was sind Dekoratoren?
3. Wie implementiert man das Singleton-Muster?
"""
2. Verwendung von Caching-Mechanismen
import hashlib
import json
# Einfacher lokaler Cache
cache = {}
def cached_query(prompt: str) -> str:
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
result = call_gemini_3_pro(prompt) # Tatsächlicher API-Aufruf
cache[cache_key] = result
return result
3. Nutzung außerhalb der Stoßzeiten
- Vermeiden Sie Spitzenzeiten (US-Arbeitszeiten).
- Nutzen Sie die Zeit direkt nach der Rücksetzung des Kontingents um Mitternacht Pazifischer Zeit.
Gemini 3 Pro Rate-Limit: Häufig gestellte Fragen (FAQ)
Q1: Warum erreiche ich das Rate-Limit bereits nach wenigen Nachrichten?
Dies ist ein häufiges Problem nach den Kontingent-Anpassungen vom Dezember 2025. Die Beschränkungen für die kostenlose Stufe (Free Tier) von Gemini 3 Pro Preview sind derzeit sehr streng und können unter den in der offiziellen Dokumentation angegebenen Werten liegen. Einige Nutzer berichten, dass die tatsächlichen RPM (Anfragen pro Minute) nur die Hälfte der Dokumentation betragen.
Lösung: Wenn Sie eine kontinuierliche Nutzung benötigen, empfiehlt es sich, den Zugriff über eine Relay-Plattform wie APIYI (apiyi.com) zu steuern. So vermeiden Sie die direkten Beschränkungen der kostenlosen Google-Ebene.
Q2: Löst ein Upgrade auf die kostenpflichtige Stufe alle Limit-Probleme?
Nach dem Upgrade auf die kostenpflichtige Stufe (Tier 1) steigen die RPM auf 150–300, und die täglichen Limits (RPD) werden im Grunde aufgehoben. Beachten Sie jedoch:
- Eine Kreditkarte für Fremdwährungen ist erforderlich.
- Die Abrechnung erfolgt nach Token-Verbrauch.
- Die Preise für Gemini 3 Pro sind relativ hoch ($2–12 pro Mio. Token).
Für Einzelnutzer oder Lernende ist die Nutzung von Plattformen wie APIYI (apiyi.com) oft wirtschaftlicher, da sie zudem lokale Zahlungsmethoden unterstützen.
Q3: Ist die Nutzung eines API-Relays sicher?
Die Wahl einer seriösen API-Relay-Plattform ist sicher. Am Beispiel von APIYI:
- Dialoginhalte werden nicht gespeichert.
- Die Übertragung erfolgt über HTTPS-Verschlüsselung.
- Es werden vollständige API-Aufrufprotokolle zur Kontrolle bereitgestellt.
Wir empfehlen, Plattformen mit gutem Ruf und längerer Betriebsdauer zu wählen.
Q4: Was ist der Unterschied zwischen Gemini 3 Pro und 2.5 Pro?
| Vergleichspunkt | Gemini 3 Pro | Gemini 2.5 Pro |
|---|---|---|
| Schlussfolgerungsfähigkeit | Höchste | Hoch |
| Kontextlänge | 200K+ | 1M |
| Multimodale Fähigkeiten | Erweitert | Standard |
| Kostenloses Kontingent | Sehr streng | 100 RPD |
| Preisgestaltung | $2-12/M Token | $1.25-5/M Token |
Wenn Ihre Aufgabe nicht die allerneuesten Funktionen erfordert, bietet Gemini 2.5 Pro ein besseres Preis-Leistungs-Verhältnis.
Q5: Wird das Kontingent im Jahr 2026 weiter angepasst?
Gemäß der Ankündigung von Google werden die Modelle Gemini 2.0 Flash und Flash-Lite am 3. März 2026 eingestellt. Unsere Empfehlungen:
- Migrieren Sie frühzeitig auf die Gemini 2.5-Serie.
- Verfolgen Sie die neuesten Updates im Google AI Developer Forum.
- Nutzen Sie Plattformen wie APIYI (apiyi.com), die mehrere Modelle unterstützen, um einen schnellen Wechsel zu ermöglichen.
Vergleich der Lösungen für Gemini 3 Pro Rate-Limits
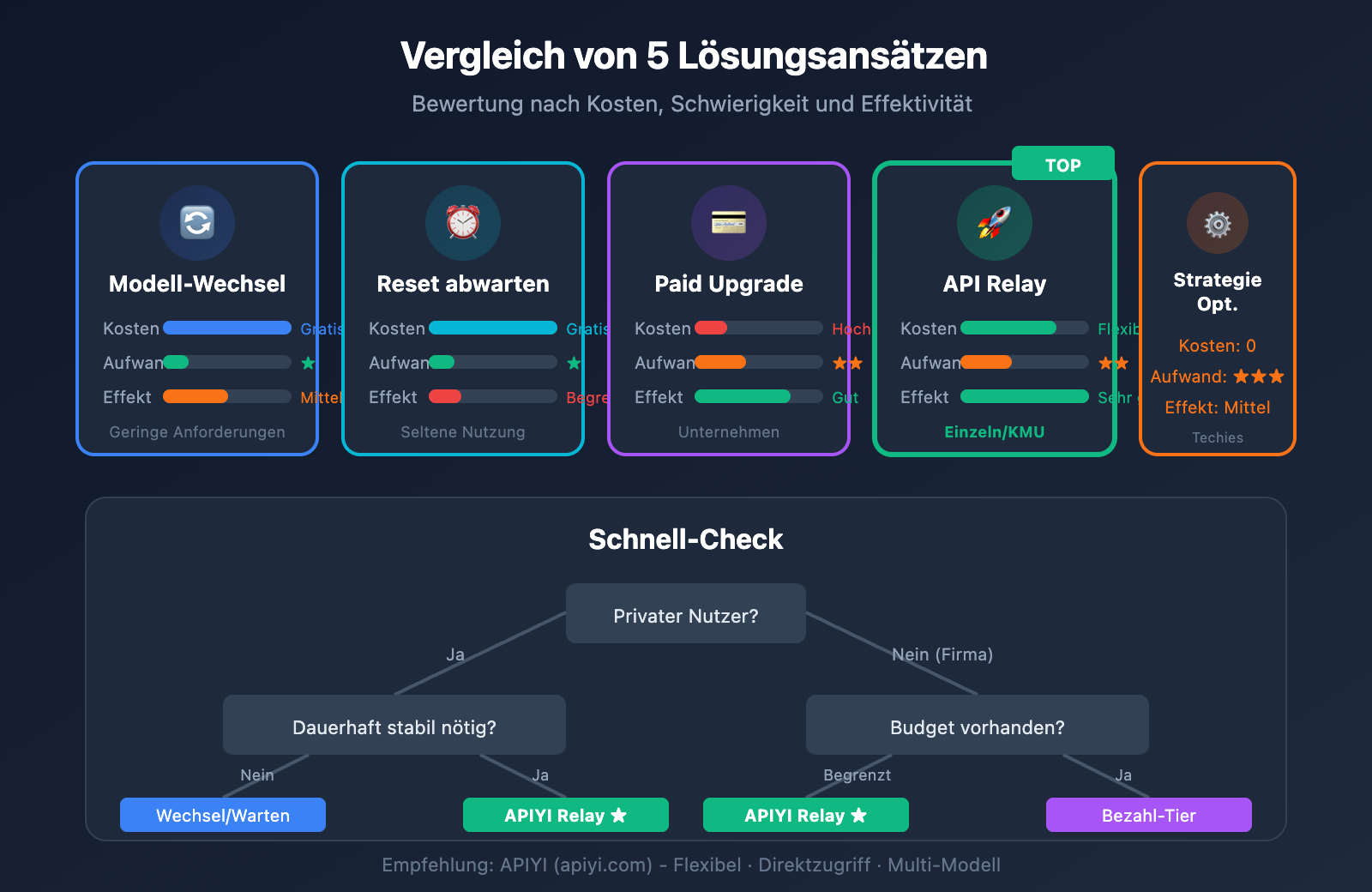
| Lösung | Kosten | Aufwand | Effekt | Empfohlenes Szenario |
|---|---|---|---|---|
| Modell wechseln | Gratis | ⭐ | Mittel | Geringe Anforderungen |
| Auf Reset warten | Gratis | ⭐ | Begrenzt | Gelegentliche Nutzung |
| Kostenpflichtiges Abo | Hoch | ⭐⭐ | Gut | Unternehmen |
| API-Relay-Plattform | Flexibel | ⭐⭐ | Sehr gut | Einzelnutzer / KMU |
| Anfrage-Optimierung | Gratis | ⭐⭐⭐ | Mittel | Technik-affine Nutzer |
💡 Empfehlung: Für private Nutzer und Lernende raten wir dazu, zuerst den Modell-Wechsel zu testen oder direkt eine API-Relay-Plattform zu nutzen. APIYI (apiyi.com) bietet flexible Abrechnungsmodelle und Pay-as-you-go Optionen. Damit müssen Sie sich keine Sorgen um Kontingente machen und erhalten eine effiziente Lösung gegen Rate-Limits.
Zusammenfassung
Die Fehlermeldung „You've reached your rate limit“ in AI Studio ist auf die massiven Kürzungen der Quoten im kostenlosen Tarif durch Google im Dezember 2025 zurückzuführen. Die in diesem Artikel vorgestellten 5 Lösungen haben jeweils ihre Vor- und Nachteile:
- Modell wechseln – Am einfachsten, ideal für temporäre Anforderungen.
- Auf Zurücksetzung warten – Kostenlos, aber wenig effizient.
- Kostenpflichtiges Upgrade – Sehr effektiv, aber mit höheren Kosten verbunden.
- API-Proxy – Ausgezeichnetes Preis-Leistungs-Verhältnis, empfohlen für Privatanwender.
- Optimierungsstrategien – Erfordert technisches Know-how.
Für die meisten Anwender im Bereich Lernen und Forschung empfehlen wir die Nutzung von APIYI (apiyi.com), um Ratenbeschränkungen schnell zu umgehen. Die Plattform unterstützt den einheitlichen Zugriff auf gängige Modelle wie Gemini 3 Pro, GPT-4 und Claude 3.5 und bietet einen stabilen Zugriff sowie flexible Zahlungsmodelle.
Referenzen
-
Google AI – Offizielle Dokumentation zu Rate Limits
- Link:
ai.google.dev/gemini-api/docs/rate-limits - Beschreibung: Offizielle Erläuterung der Gemini API Ratenbeschränkungen.
- Link:
-
Google AI Developers Forum – Diskussion über Rate Limits
- Link:
discuss.ai.google.dev/t/youve-reached-your-rate-limit/35201 - Beschreibung: Community-Diskussionen über Ratenbeschränkungen.
- Link:
-
Gemini API Pricing – Offizielle Preisgestaltung
- Link:
ai.google.dev/gemini-api/docs/pricing - Beschreibung: Informationen zu Preisen und Kontingenten der einzelnen Modelle.
- Link:
📝 Autor: APIYI Team
🔗 Technischer Support: APIYI (apiyi.com) – Ihre All-in-One-Plattform für API-Proxies großer Sprachmodelle
📅 Aktualisiert am: 24.01.2026