Am 6. Mai 2026 versendete xAI eine offizielle E-Mail an alle API-Nutzer mit dem Betreff „Grok 4.3 release and xAI API model retirement“. Darin wurden zwei für Entwickler entscheidende Nachrichten übermittelt: Grok 4.3 ist ab sofort vollständig über die API verfügbar, während gleichzeitig acht ältere Modelle – darunter grok-4-fast, grok-4-0709, grok-3, grok-code-fast-1 und grok-imagine-image-pro – zum 15. Mai 2026 um 12:00 Uhr PT abgeschaltet werden. Diese Ankündigung markiert nicht nur ein bedeutendes Versions-Update, sondern auch einen Countdown für eine Migration, die innerhalb von nur 9 Tagen abgeschlossen sein muss.

Das bemerkenswerteste an der Veröffentlichung von Grok 4.3 ist nicht die Namensänderung, sondern die Kombination aus einem 1M-Token-Kontextfenster, einer Preisgestaltung von 1,25 $ / 2,50 $ für Input/Output sowie drei einstellbaren Stufen für die Schlussfolgerungsintensität. Mit diesem Preissegment tritt Grok 4.3 direkt in den Wettbewerb mit Mainstream-Modellen wie Gemini 3.1 Pro und GPT-5.4, behält jedoch den für xAI typischen Vorteil des hohen Token-Durchsatzes bei. Wir empfehlen Teams, die auf die Grok-Serie angewiesen sind, so früh wie möglich über die Plattform APIYI (apiyi.com) Tests durchzuführen. Die einheitliche OpenAI-kompatible Schnittstelle minimiert den Migrationsaufwand beim Wechsel zwischen verschiedenen Modellen.
Umfassende Analyse der Kernspezifikationen und Preise von Grok 4.3
Grok 4.3 ist das neueste Flaggschiff-Modell, das von xAI in der E-Mail explizit als „das schnellste und intelligenteste Modell, das wir je gebaut haben“ bezeichnet wurde. Es führt die Ranglisten für agentenbasiertes Tool-Calling und Befolgung von Anweisungen (Instruction Following) an und ist als universelles Flaggschiff für Code, Agenten und komplexe Schlussfolgerungen positioniert. Von den Spezifikationen her hat Grok 4.3 das Kontextfenster von den 256K der Grok-4-Ära auf 1M Token erweitert – gleichauf mit Gemini 3 Pro und Claude 4.7. Dies bedeutet, dass komplette Codebasen oder umfangreiche technische Dokumentationen in einem Durchgang verarbeitet werden können.
Die folgende Tabelle fasst die Kernparameter von Grok 4.3 in der xAI-API zusammen. Alle Daten stammen aus der offiziellen xAI-E-Mail und den Messungen von Artificial Analysis.
| Parameter | Grok 4.3 Wert | Anmerkungen |
|---|---|---|
| Kontextfenster | 1.000.000 Token | Input + Output geteilt |
| Input-Preis | 1,25 $ / 1M Token | 50 % günstiger als GPT-5.4, gleichauf mit Gemini 3.1 Pro |
| Output-Preis | 2,50 $ / 1M Token | Ca. 83 % günstiger als die 15 $ der Grok-4-Ära |
| Schlussfolgerungsintensität | low / medium / high (3 Stufen) | Steuerung der Tiefe der Schlussfolgerung per Parameter |
| Input-Modalität | Text + Bild | Unterstützt visuelles Verständnis |
| Output-Modalität | Text | Keine direkte Bilderzeugung |
| Tool-Aufruf | Natives Function Calling | Unterstützt strukturierte Ausgabe und parallele Aufrufe |
| Output-Geschwindigkeit | ca. 207 Token/s | Messung durch Artificial Analysis |
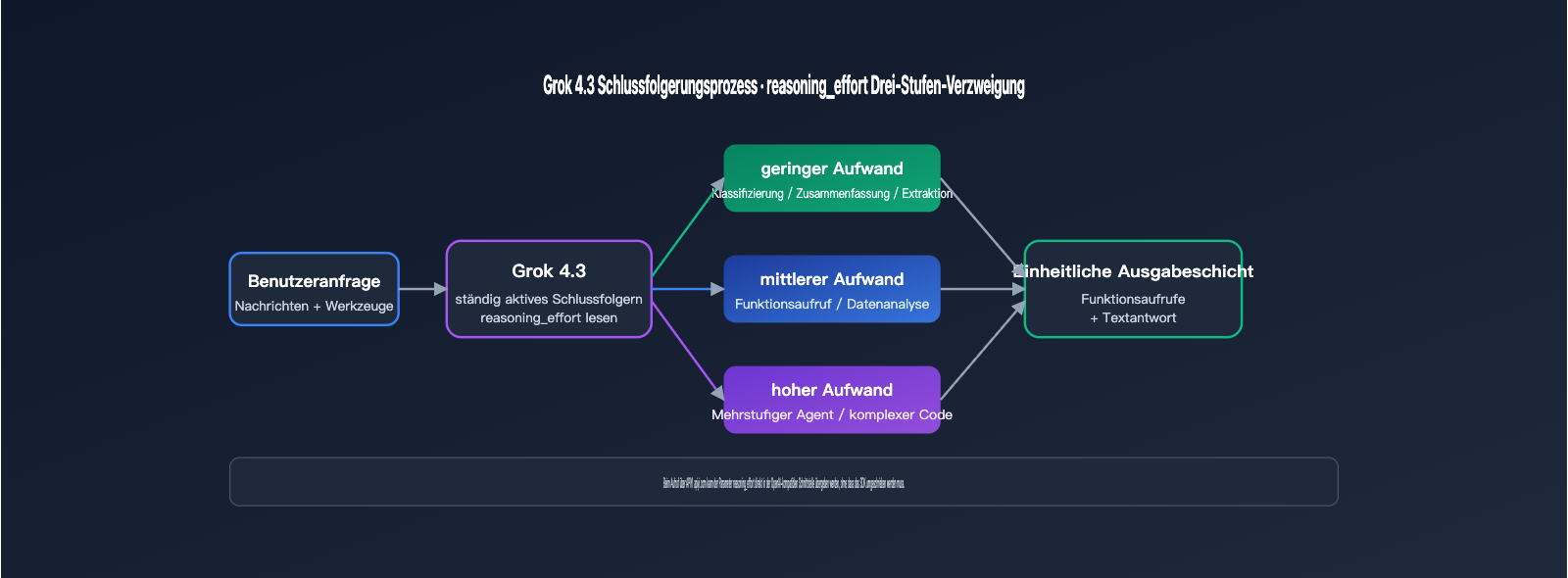
Die drei Stufen der Schlussfolgerungsintensität (reasoning effort) sind ein wesentliches neues Merkmal von Grok 4.3, das es Entwicklern ermöglicht, die „Denktiefe“ des Modells je nach Aufgabenkomplexität anzupassen, was sich direkt auf Latenz und Kosten auswirkt. Dieser Mechanismus lehnt sich an das reasoning_effort-Design von OpenAI an, wobei xAI das Schlussfolgern selbst als „always-on“-Zustand beibehält, jedoch die Anpassung der Tiefe erlaubt. Die folgende Tabelle zeigt die typischen Einsatzszenarien und Auswirkungen der drei Stufen.
| Schlussfolgerungsintensität | Typische Szenarien | Latenzverhalten | Kostenauswirkung |
|---|---|---|---|
| low | Einfache Klassifizierung, Zusammenfassungen, regelbasierte Extraktion | Nahe an Nicht-Schlussfolgerungsmodellen | Geringste Anzahl an Output-Token |
| medium | Funktionsaufrufe, Datenanalyse, Code-Vervollständigung | Ausgewogen zwischen Latenz und Qualität | Standard-Empfehlung |
| high | Multi-Step-Agenten, komplexe Mathematik, langer Code | Längere „Thinking“-Phase | Deutlich erhöhte Output-Token |
🎯 Empfehlung zur Anbindung: Für Teams, die sich bei der Wahl der Stufe unsicher sind, empfehlen wir, zunächst auf der Plattform APIYI (apiyi.com) eine Reihe realer Geschäftsbeispiele mit der Stufe „medium“ zu testen und dann basierend auf Genauigkeit und Kosten-Nutzen-Verhältnis zu entscheiden, ob ein Upgrade auf „high“ sinnvoll ist. Durch die einheitliche Schnittstelle kann der Parameter
reasoning_effortzwischen verschiedenen Modellen mit einem Klick gewechselt werden, ohne das SDK neu schreiben zu müssen.
Grok 4.3: Testergebnisse in Agentic- und Instruction-Following-Rankings
Dass xAI in seiner E-Mail explizit betont, dass Grok 4.3 „die Bestenlisten bei agentischen Werkzeugaufrufen und der Befolgung von Anweisungen anführt“, basiert auf Kerndaten von Drittanbietern wie Artificial Analysis, τ²-Bench, IFBench und GDPval-AA. Der Artificial Analysis Intelligence Index vergibt einen Gesamtscore von 53,2, wobei die Kosten für den vollständigen Testlauf bei etwa 395 $ liegen – das sind rund 20 % weniger als bei Grok 4.20. In der τ²-Bench Telecom (einem Benchmark für bidirektionale Werkzeugaufrufe in der Telekommunikations-Kundenbetreuung), der den realen Agent-Szenarien am nächsten kommt, erreichte Grok 4.3 ein Ergebnis von 98 %. Das entspricht einer Steigerung von 5 Prozentpunkten gegenüber Grok 4.20 und liegt gleichauf mit GLM-5.1.
Für Entwickler ist insbesondere der GDPval-AA-Benchmark interessant, der den tatsächlichen wirtschaftlichen Wert von Workflows misst. Grok 4.3 erreichte hier 1500 ELO, was eine deutliche Steigerung um 321 Punkte gegenüber dem Vorgänger Grok 4.20 0309 v2 (1179 ELO) darstellt. Damit übertrifft es Modelle wie Gemini 3.1 Pro Preview, Muse Spark, GPT-5.4 mini (xhigh) und Kimi K2.5. Im Bereich Instruction Following hält Grok 4.3 mit 81 % auf IFBench das Niveau von Grok 4.20 0309 v2.
| Benchmark | Grok 4.3 Ergebnis | Vergleich | Fokus |
|---|---|---|---|
| AA Intelligence Index | 53,2 | Besser als 98 % der Modelle | Allgemeine Intelligenz |
| AA Coding Index | 41,0 | Besser als 89 % der Modelle | Codierung & Refactoring |
| τ²-Bench Telecom | 98 % | Gleichauf mit GLM-5.1 | Werkzeugaufruf + Nutzerinteraktion |
| IFBench | 81 % | Gleichauf mit Grok 4.20 | Komplexe Befolgung von Anweisungen |
| GDPval-AA | ELO 1500 | Übertrifft Gemini 3.1 Pro Preview | Echter Workflow-Wert |
Es ist wichtig zu beachten, dass die Stärken von Grok 4.3 in agentischen Workflows und Werkzeugaufrufen liegen, nicht in reinen Algorithmen-Wettbewerben. Für Anwendungen wie Code-Agents, Browser-Agents oder Kundenservice-Bots, die eine stabile JSON-Ausgabe und mehrstufige Werkzeugaufrufe erfordern, bietet Grok 4.3 eine deutlich höhere Zuverlässigkeit als die Vorgängergeneration. Sollte der Kernbereich Ihres Teams jedoch die reine Code-Synthese (ähnlich wie bei SWE-bench) sein, empfehlen wir, Grok 4.3, Claude 4.7 Opus und GPT-5.4 auf der Plattform APIYI (apiyi.com) mit demselben Testdatensatz zu vergleichen, um basierend auf der Erfolgsquote das optimale Hauptmodell zu wählen.
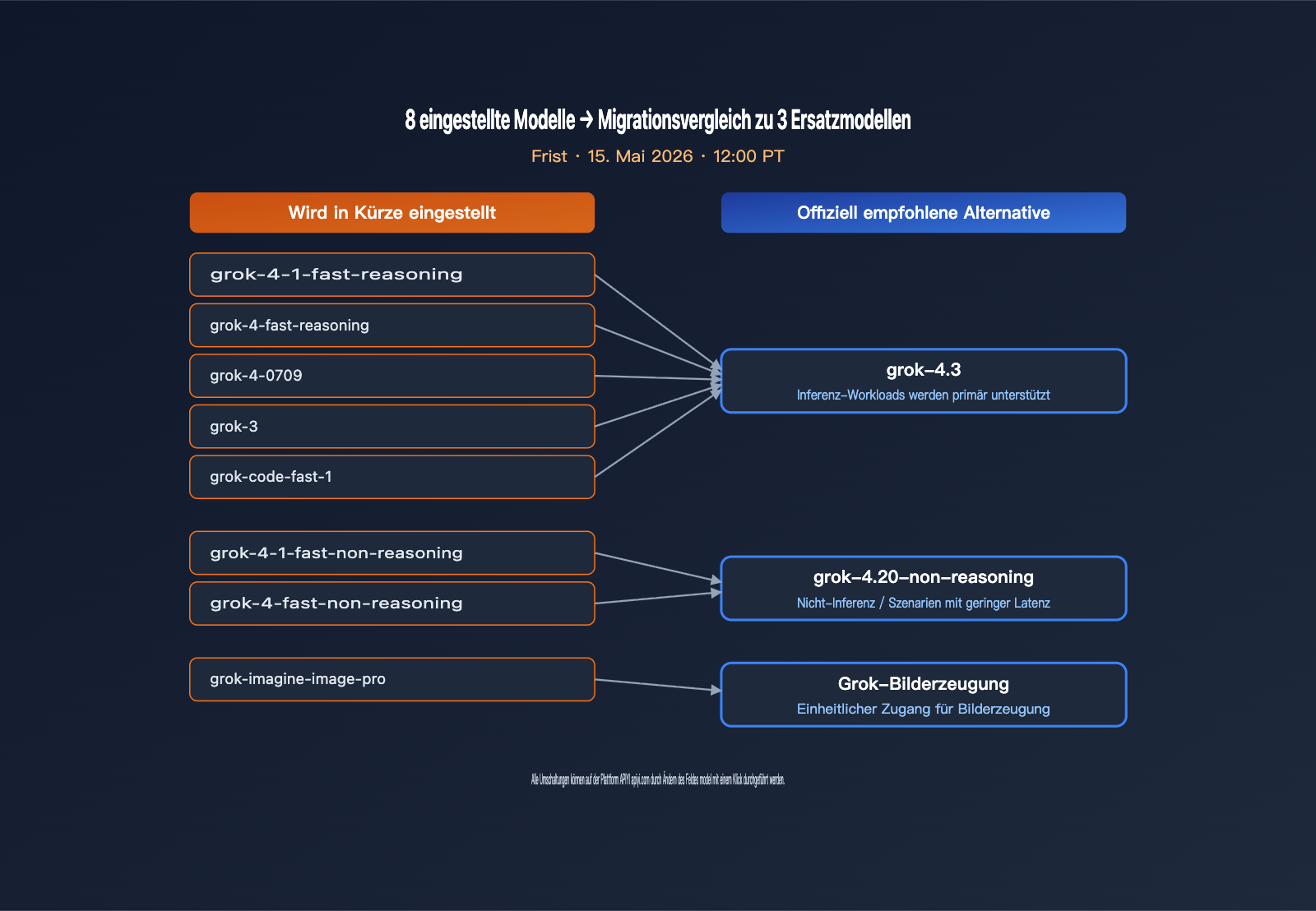
Liste der eingestellten xAI-Modelle und Migrationsvorschläge
xAI stellt mit diesem Schritt acht Modelle ein, die von Text-Reasoning über Code-Modelle bis hin zur Bilderzeugung reichen, und bereinigt damit im Grunde das gesamte SKU-Portfolio der Grok-4-Ära. Für Teams, die Modellnamen direkt im Code („hard-coded“) hinterlegt haben, ist dies eine verbindliche Frist, die eine Code-Anpassung innerhalb von 9 Tagen erfordert. Die folgende Tabelle fasst alle betroffenen Modelle und die offiziellen Empfehlungen für den Umstieg zusammen.
| Modell (wird eingestellt) | Typ | Offizielle Alternative | Migrationshinweis |
|---|---|---|---|
| grok-4-1-fast-reasoning | Reasoning | grok-4.3 | Bessere Qualität, geringere Kosten |
| grok-4-1-fast-non-reasoning | Non-Reasoning | grok-4.20-non-reasoning | Geringe Latenz bleibt erhalten |
| grok-4-fast-reasoning | Reasoning | grok-4.3 | Zusätzlich 1M Kontextfenster |
| grok-4-fast-non-reasoning | Non-Reasoning | grok-4.20-non-reasoning | API-Kompatibilität bleibt gewahrt |
| grok-4-0709 | Reasoning | grok-4.3 | Früher Grok-4-Snapshot wird entfernt |
| grok-code-fast-1 | Code | grok-4.3 | Code-Szenarien werden auf 4.3 vereinheitlicht |
| grok-3 | Allgemein | grok-4.3 | Ende der Grok-3-Ära |
| grok-imagine-image-pro | Bilderzeugung | grok-imagine-image | Vereinfachung der Bilderzeugungs-SKUs |
Das Einstellungsdatum ist der 15. Mai 2026, 12:00 Uhr PT (16. Mai, 03:00 Uhr MESZ). Nach Ablauf dieser Frist führen Anfragen an diese acht Modell-IDs zu Fehlern. Ausgehend vom Versand der E-Mail am 6. Mai bleiben Entwicklern 9 Tage Zeit – ein sehr enger Zeitplan für mittelgroße bis große Projekte. Wir empfehlen, die Migration in drei Schritten durchzuführen: Erstens alle hard-coded Modell-IDs im Code identifizieren, zweitens einen Gray-Box-Test auf der Plattform APIYI (apiyi.com) durchführen und drittens das Modell-Feld über Umgebungsvariablen steuern, anstatt die Geschäftslogik direkt zu ändern.
Ein wichtiger Hinweis: grok-code-fast-1 war in den letzten sechs Monaten das Standardmodell für viele Code-Agent-Projekte. Die Einstellung bedeutet, dass alle Cursor-ähnlichen Tools, IDE-Plugins und CLI-Agents, die von dieser ID abhängen, auf grok-4.3 umgestellt werden müssen. Im Bereich Code ist die Stabilität der Werkzeugaufrufe bei Grok 4.3 besser als bei grok-code-fast-1, allerdings sind die Kosten pro Token etwas höher, weshalb das Aufrufbudget neu bewertet werden sollte.
Grok 4.3 im Vergleich zu GPT-5.4, Claude 4.7 und Gemini 3.1 Pro
Zum Zeitpunkt der Einführung von Grok 4.3 im zweiten Quartal 2026 befindet sich der Markt für Spitzenmodelle in einer Phase des historisch intensivsten Wettbewerbs. Claude Opus 4.7 führt bei SWE-bench Verified mit 87,6 %, Gemini 3.1 Pro erreicht 94,3 % bei GPQA Diamond, und GPT-5.4 bleibt der Maßstab für Stabilität bei der Schlussfolgerung langer Texte. Grok 4.3 positioniert sich als Modell mit „mittlerer Intelligenz, extrem niedrigem Preis und einer leistungsstarken Agent-Toolchain“, was es ideal für kostenintensive Szenarien mit hoher Abruffrequenz macht.
Die folgende Tabelle vergleicht die wichtigsten Daten der vier Flaggschiff-Modelle in gängigen Dimensionen. Die Preise sind in US-Dollar pro Million Token angegeben.
| Modell | Eingabepreis | Ausgabepreis | Kontextfenster | Hauptanwendungsgebiete |
|---|---|---|---|---|
| Grok 4.3 | $1,25 | $2,50 | 1M | Agent-Toolchain, häufige Aufrufe, mittlere Schlussfolgerung |
| GPT-5.4 | $2,50 | $15,00 | 400K | Konsistenz bei langen Texten, komplexe Planung |
| Claude 4.7 Opus | $15,00 | $75,00 | 1M | Erstklassige Programmierung, Dokumentenerstellung, Tiefenanalyse |
| Gemini 3.1 Pro | $2,00 | $12,00 | 2M | multimodal, Videoverständnis, extrem lange Dokumente |
Aus dieser Vergleichstabelle lässt sich eine klare Tatsache ablesen: Der Preis für Ausgabe-Token bei Grok 4.3 ist 30-mal günstiger als bei Claude 4.7 Opus und etwa 4,8-mal günstiger als bei Gemini 3.1 Pro. Für geschäftliche Anwendungen wie KI-Kundenservice-Agenten, Code-Linter oder die Stapelverarbeitung von Daten wird der Kostenvorteil von Grok 4.3 massiv spürbar. Wenn es jedoch um höchste Code-Qualität oder multimodales Verständnis geht, bleiben Claude 4.7 Opus und Gemini 3.1 Pro unersetzlich.
🎯 Empfehlung zur Multi-Modell-Strategie: Wir empfehlen, Grok 4.3 für die allgemeine Ebene mit hoher Abruffrequenz zu nutzen, Claude 4.7 Opus für komplexe Code- und Dokumentenausgaben und Gemini 3.1 Pro für multimodale Aufgaben. Durch die Nutzung der einheitlichen Schnittstelle von APIYI (apiyi.com) für das Modell-Routing profitieren Sie sowohl von den Kostenvorteilen von Grok 4.3 als auch von der Leistungsfähigkeit spezialisierter Modelle an kritischen Punkten.
Migrationsleitfaden für die Grok 4.3 API und Codebeispiele
Die Migration auf Grok 4.3 ist auf technischer Ebene sehr unkompliziert. xAI stellt eine OpenAI-kompatible Chat-Completions-Schnittstelle bereit, sodass sich der Großteil der Arbeit auf die Anpassung von base_url und model beschränkt. Für Projekte, die bereits das OpenAI SDK verwenden, zeigt das folgende minimalistische Python-Beispiel den vollständigen Integrationscode.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Erkläre reasoning effort in einem Satz."},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
Nachdem die base_url auf die Plattform APIYI (apiyi.com) verwiesen wurde, steht Ihnen ein einheitlicher Zugriffspunkt für Grok 4.3, Claude 4.7, GPT-5.4 und Gemini 3.1 Pro zur Verfügung. Ein späterer Modellwechsel erfordert lediglich die Anpassung des model-Parameters, ohne dass Authentifizierungs- oder Routing-Code neu geschrieben werden muss. Diese einheitliche Abstraktion kann das Migrationsrisiko vor dem Stichtag am 15. Mai erheblich senken.
Für die Migration älterer Modelle haben wir eine Übersicht der minimalen Änderungen zusammengestellt, die Sie direkt in Ihren Code übernehmen können.
| Altes Modell-Feld | Neues Modell-Feld | Weitere Parameter erforderlich? |
|---|---|---|
| grok-3 | grok-4.3 | Optional: reasoning_effort hinzufügen |
| grok-4-0709 | grok-4.3 | Optional: reasoning_effort hinzufügen |
| grok-4-fast-reasoning | grok-4.3 | Optional: reasoning_effort hinzufügen |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | Keine weiteren Änderungen |
| grok-code-fast-1 | grok-4.3 | Empfohlen: reasoning_effort=high |
| grok-imagine-image-pro | grok-imagine-image | Bild-API-Endpunkt bleibt gleich |
Grok 4.3 – Häufig gestellte Fragen (FAQ)
F1: Unterstützt Grok 4.3 wirklich ein Kontextfenster von 1 Mio. Token? Nimmt die Leistung bei langen Texten ab?
Ja, Grok 4.3 bietet über die xAI-API offiziell ein Kontextfenster von 1 Mio. Token und liegt damit auf Augenhöhe mit Claude 4.7 Opus. Wie bei allen Modellen mit großem Kontextfenster kann jedoch das Verständnis für Anforderungen ab 600.000 Token leicht nachlassen. Wir empfehlen daher, wichtige Informationen in der ersten Hälfte des Dokuments zu platzieren. Sie können über die Plattform APIYI (apiyi.com) zunächst einen Test zur Abrufgenauigkeit mit Ihren realen, langen Geschäftsdokumenten durchführen, bevor Sie Grok 4.3 als Hauptmodell für lange Texte festlegen.
F2: Wie wähle ich zwischen den Inferenzstärken low / medium / high?
Verwenden Sie „low“ für risikoarme Aufgaben (Klassifizierung, Zusammenfassungen, Regelextraktion), „medium“ für Standardanwendungen (Kundenservice, Funktionsaufrufe, Datenanalyse) und „high“ für komplexe Schlussfolgerungen (mehrstufige Agenten, lange Code-Ketten, komplexe Mathematik). Die Stufe „high“ erhöht die Anzahl der ausgegebenen Token und die Latenz erheblich. Wir empfehlen, dies unter Berücksichtigung Ihres Budgets und der Latenz-SLAs zu bewerten.
F3: Können alte Modelle nach dem 15. Mai, 12:00 Uhr PT, weiterhin verwendet werden?
Nein. xAI hat in einer E-Mail ausdrücklich darauf hingewiesen: „After May 15, 2026, requests to these models will no longer work“. Anfragen an abgelaufene Modelle führen direkt zu Fehlermeldungen. Alle hartcodierten Modell-IDs im Code müssen vor diesem Stichtag aktualisiert werden.
F4: Wie lassen sich die Migrationskosten minimieren?
Der sicherste Weg besteht darin, das Modell-Feld in Ihrer Anwendung als Umgebungsvariable oder Konfigurationsoption zu abstrahieren, anstatt es fest im Code zu hinterlegen. In Kombination mit der OpenAI-kompatiblen Schnittstelle von APIYI (apiyi.com) erfordert die Migration lediglich eine einzige Konfigurationsänderung und einen Regressionstest.
F5: Eignet sich Grok 4.3 für Coding-Agenten?
Ja, sehr gut. Grok 4.3 erreichte 98 % im τ²-Bench Telecom. Die Stabilität bei Funktionsaufrufen und mehrstufigen Dialogen ist besser als bei grok-code-fast-1. Zudem sind die Stückkosten extrem niedrig, was es ideal für häufig aufgerufene IDE-Plugins, CLI-Agenten und automatisierte Wartungsskripte macht.
Zusammenfassung: Wichtige Punkte zum Start von Grok 4.3 und zur xAI-API-Migration
Das Highlight der Veröffentlichung von Grok 4.3 ist nicht nur, dass es „leistungsfähiger“ ist, sondern dass es „günstiger und gleichzeitig leistungsfähiger“ ist. Mit einer Preisgestaltung von $1,25/$2,50 bringt xAI ein 1-Mio.-Token-Kontextfenster und hochwertige Agenten-Funktionsaufrufe in die gleiche Preisklasse wie Gemini 3.1 Pro und definiert damit den Standard für das Preis-Leistungs-Verhältnis bei hochfrequenten, allgemeinen Anwendungen neu. Gleichzeitig erinnert die Abschaltung von acht alten Modellen zum 15. Mai alle Teams daran: Modell-IDs sollten nicht hartcodiert im Geschäftscode stehen, sondern hinter einer konfigurierbaren Routing-Schicht abstrahiert werden.
Wir empfehlen, Grok 4.3 als Hauptmodell für häufige Aufrufe und Agenten-Toolchains einzusetzen. Nutzen Sie die einheitliche Schnittstelle von APIYI (apiyi.com), um die Migrationskosten zu minimieren. So behalten Sie die Flexibilität, zwischen verschiedenen Modellen wie Claude 4.7 Opus, GPT-5.4 und Gemini 3.1 Pro zu wählen und diese dynamisch je nach Aufgabe zu steuern, um das optimale Gleichgewicht zwischen Kosten und Qualität zu erzielen.
APIYI Technik-Team · Fokus auf praktische Inhalte zu KI-Modell-APIs und Entwicklertools. Weitere technische Artikel finden Sie unter apiyi.com