Anfang April 2026 tauchte ein mysteriöses KI-Videomodell namens HappyHorse völlig überraschend in den Blindtest-Ranglisten der Artificial Analysis Video Arena auf. Die Versionen V1 und V2 verbesserten fast zeitgleich die Elo-Scores in den Kategorien Text-zu-Bild und Bild-zu-Bild und ließen dabei Branchengrößen wie Seedance 2.0, Kling 3.0 und PixVerse V6 hinter sich. Doch nur wenige Tage später verschwand HappyHorse 1.0 ebenso plötzlich wieder von der Bildfläche – zurück blieben nur einige wenige Screenshots und eine vage gehaltene offizielle Webseite.
Die Spekulationen um das HappyHorse-Modell lösten in der englischsprachigen KI-Community sofort hitzige Debatten aus: Handelt es sich um eine getarnte Version von Wan 2.7? Ist es ein Experiment der nächsten Generation des Seedance-Teams von ByteDance? Oder hat ein bisher unbekanntes asiatisches Labor plötzlich die Karten auf den Tisch gelegt? Dieser Artikel analysiert auf Basis öffentlich verifizierbarer Daten die Architektur, Leistung, den Open-Source-Status und die mögliche Herkunft von HappyHorse 1.0, um Ihnen bei der Entscheidung zu helfen, ob dieses „Dark Horse“ einen Platz in Ihrem Tech-Stack für die Videogenerierung verdient.

Überblick über die Kerninformationen des HappyHorse-Modells
Bevor wir die technischen Details aufschlüsseln, haben wir die bekannten Informationen in der folgenden Tabelle zusammengefasst, um Ihnen einen schnellen Überblick zu ermöglichen.
| Dimension | Bekannte Informationen zu HappyHorse 1.0 |
|---|---|
| Modelltyp | Text-zu-Video- und Bild-zu-Video-Modell (kombinierte Bild- und Audiogenerierung) |
| Architektur | 40-Layer Single-Stream Self-Attention Transformer, ohne Cross-Attention |
| Inferenzschritte | Nur 8 Entrauschungsschritte erforderlich, kein CFG (Classifier-Free Guidance) |
| Sprachunterstützung | Chinesisch, Englisch, Japanisch, Koreanisch, Deutsch, Französisch |
| Veröffentlichung | Basismodell / Destilliertes Modell / Upscaling-Modell / Inferenzcode (laut offiziellen Angaben vollständig Open Source) |
| Fundort | Artificial Analysis Video Arena (einige Quellen erwähnen auch die LMArena-Videokategorie) |
| Aktueller Status | V1/V2 aus der öffentlichen Rangliste entfernt, Webseite online, aber GitHub/Model Hub mit "Coming Soon" markiert |
| Vermutete Herkunft | Von einem asiatischen Team; Community vermutet Verbindung zur Wan 2.7- / Seedance-Architektur, jedoch nicht offiziell bestätigt |
🎯 Empfehlung für schnelle Tests: Da die offiziellen Gewichte des HappyHorse-Modells noch nicht auf den gängigen Inferenzplattformen verfügbar sind, empfehlen wir Ihnen, falls Sie Videomodelle der gleichen Klasse (wie Seedance 2.0, Kling 3.0, Veo 3.1) in Ihrer Produktionsumgebung vergleichen möchten, diese zunächst über eine einheitliche API-Proxy-Dienst-Plattform wie APIYI (apiyi.com) parallel aufzurufen. So können Sie nahtlos auf HappyHorse umsteigen, sobald es offiziell veröffentlicht wird, und vermeiden aufwendige Umrüstungen.
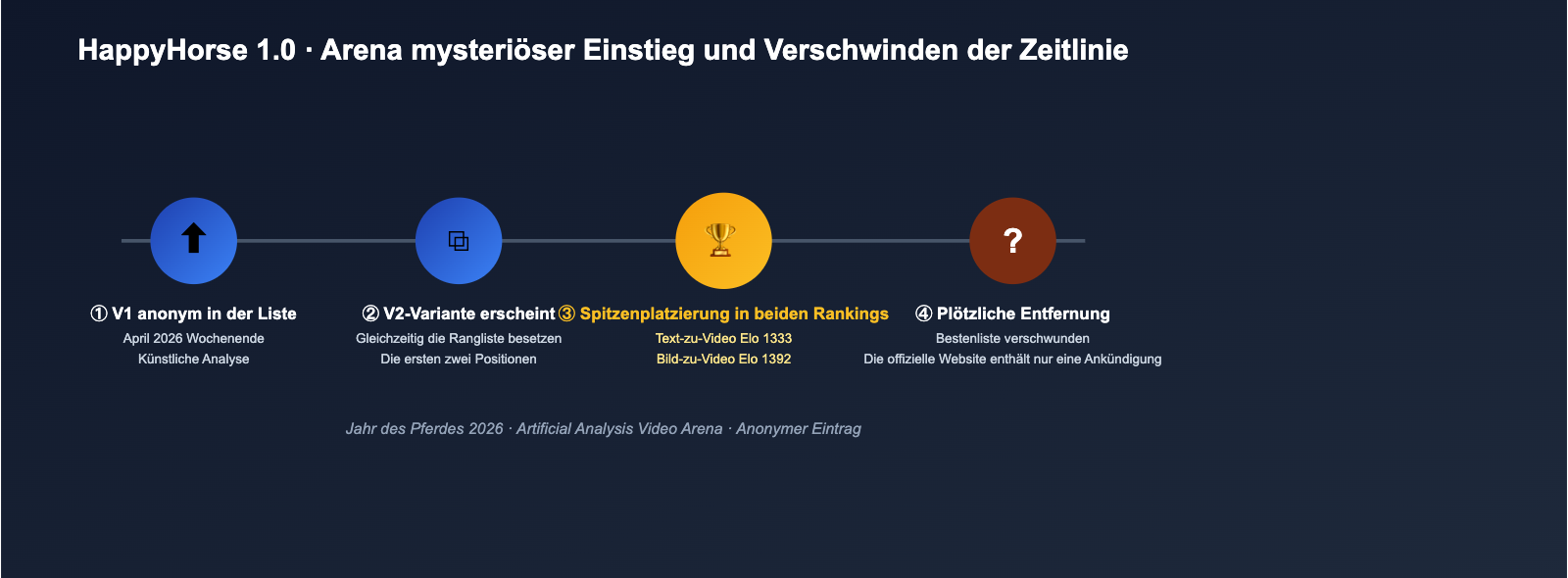
Die Timeline des HappyHorse-Modells
Um zu verstehen, warum dieses „glückliche Pferd“ die internationale KI-Szene so aufgewirbelt hat, müssen wir uns die zeitliche Abfolge genauer ansehen.
Das Jahr des Pferdes und ein glücklicher Zufall
2026 ist im chinesischen Kalender das Jahr des Pferdes. Seit dem Frühlingsfest im Februar berichteten internationale Medien und Fachpublikationen wie UX Tigers wiederholt darüber, dass die chinesische KI-Szene eine Reihe von Veröffentlichungen rund um das Thema „Pferd“ vorbereitet. Die Benennung „HappyHorse“ spielt sowohl auf das Tierkreiszeichen an als auch auf ein anderes Modell, das zeitgleich unter dem Kürzel „The Horse“ auftauchte. Dies war für die Community eines der wichtigsten Indizien dafür, dass das Modell aus einem asiatischen Team stammt.
Aufstieg und Verschwinden in der Arena
Laut Screenshots und Berichten von KI-Video-Testern wie Brent Lynch auf X (ehemals Twitter) Anfang April, verlief der Start von HappyHorse 1.0 in etwa so:
- Erstes Auftauchen: Die V1-Version erschien als anonymer Eintrag in der Artificial Analysis Video Arena und schaffte es innerhalb weniger Stunden in die Top 3 der Text-zu-Video-Blindtests.
- V2-Version online: Fast zeitgleich erschien eine V2-Variante; beide Versionen belegten zeitweise gleichzeitig Platz 1 und 2 der Bild-zu-Video-Rangliste.
- Spitzenreiter: In der Kategorie ohne Audio ließ HappyHorse 1.0 führende Modelle wie Seedance 2.0 720p, Kling 3.0 und PixVerse V6 hinter sich.
- Verschwinden: Innerhalb weniger Tage wurden V1 und V2 von der öffentlichen Rangliste entfernt. Zurück blieben nur Screenshots und Aufzeichnungen Dritter. Die offizielle Seite veröffentlichte erst danach den Hinweis: „Basis-Modell wird bald Open Source“.
Dieses Muster – „plötzlicher Aufstieg, Dominanz, stilles Verschwinden“ – deutet meist auf zwei Dinge hin: Entweder führt ein Labor anonyme A/B-Tests durch, oder der Hersteller bereitet den offiziellen Launch vor und hat das Modell nach dem ersten Traffic-Schub vorsorglich offline genommen. Beide Erklärungen haben den mysteriösen Status des HappyHorse-Modells weiter gesteigert.
Analyse der Architektur: Wie der 40-Layer Single-Stream Transformer überzeugt
Obwohl noch kein offizielles Paper vorliegt, lassen die Beschreibungen auf happyhorse-ai.com und der Mirror-Seite happy-horse.net einige Rückschlüsse auf die Architektur von HappyHorse 1.0 zu.
Single-Stream Self-Attention statt komplexer Multi-Stream-Strukturen
Herkömmliche Modelle zur Bilderzeugung (insbesondere multimodale Modelle, die Audio, Text und Bild gleichzeitig verarbeiten) nutzen meist eine Multi-Stream-Architektur. Dabei haben Text, Video und Audio jeweils eigene Encoder, die über Cross-Attention miteinander interagieren. Diese Struktur ist flexibel, verschwendet aber massiv Parameter und erfordert beim Inferenz-Prozess ständiges Hin- und Her-Verschieben von Tensoren zwischen den Zweigen.
HappyHorse 1.0 vereinfacht dies zu einer einzigen Pipeline: Ein 40-schichtiger Self-Attention Transformer verarbeitet Text-, Video- und Audio-Token gleichzeitig. Es gibt keine Cross-Attention und keine spezialisierten Sub-Netzwerke für einzelne Modalitäten. Alle Modalitäten werden in eine einheitliche Token-Sequenz kodiert und direkt im selben Aufmerksamkeitsraum modelliert. Dieses Design bietet theoretische Vorteile:
- Hohe Parameterauslastung: Keine redundanten Parameter mehr für die Trennung der Modalitäten.
- Kurzer Inferenzpfad: Keine zusätzliche Datenbewegung zwischen Modalitäten, was den Kernel effizienter macht.
- Einheitliches Trainingsziel: Text, Bild und Audio teilen sich dieselbe Verlustfunktion, was End-to-End-Optimierungen erleichtert.
- Native Audio-Video-Synchronisation: Da Ton und Bild in derselben Sequenz liegen, ist die Synchronisation systembedingt gegeben.
8-Schritte-Denoising + CFG-freie Inferenz
Für Entwickler, die mit Stable Video Diffusion, Sora oder Kling gearbeitet haben, sind „Dutzende Schritte Denoising + Classifier-Free Guidance (CFG)“ fast schon ein Muskelgedächtnis. Die offizielle Beschreibung von HappyHorse 1.0 ist jedoch radikal: Nur 8 Schritte Denoising und kein CFG reichen aus, um die erstklassige Bildqualität zu liefern, die den Arena-Spitzenplatz rechtfertigt.
Dies deutet darauf hin, dass während des Trainings Techniken wie Consistency Distillation, Rectified Flow oder Progressive Distillation eingesetzt wurden, um die mehrstufige Abtastung auf wenige Schritte zu komprimieren. Zusammen mit den offiziell angekündigten „Destillations-“ und „Upscaling-Modellen“ ist der gesamte Inferenz-Stack stark auf „Edge-freundlich + hoher Durchsatz im Backend“ ausgelegt.
Mögliche Parametergröße und VRAM-Anforderungen
Da die Gewichte noch nicht öffentlich sind, lässt sich die Parameterzahl des HappyHorse-Modells nicht direkt verifizieren. Angesichts der 40 Schichten, des Single-Stream-Designs und der Unterstützung von 6 Sprachen sowie der Arena-Performance ist jedoch davon auszugehen, dass es sich in der Größenordnung von Wan 2.x, Seedance 1.x oder Hunyuan Video bewegt – wahrscheinlich im Bereich von 10B bis 30B Parametern. Das bedeutet, dass für ein lokales Deployment mindestens eine Profi-Grafikkarte mit viel VRAM nötig ist; für normale Consumer-GPUs muss man auf INT8/FP8-quantisierte Versionen warten.
🎯 Empfehlung zur Architekturwahl: Wenn Sie für Ihr Team die „nächste Generation der Video-Generierungs-Infrastruktur“ evaluieren, empfehlen wir, das Paradigma „Single-Stream Transformer + extrem wenige Inferenzschritte“ von HappyHorse 1.0 genau zu beobachten. Bis es vollständig Open Source ist, können Sie den API-Proxy-Dienst von APIYI (apiyi.com) nutzen, um mit Modellen wie Seedance, Kling oder Veo zu experimentieren, Ihre Prompts, Skripte und Post-Processing-Pipelines zu optimieren und dann bei Verfügbarkeit der HappyHorse-Gewichte nahtlos zu wechseln.
HappyHorse-Modell: Analyse der Arena-Bestenlisten
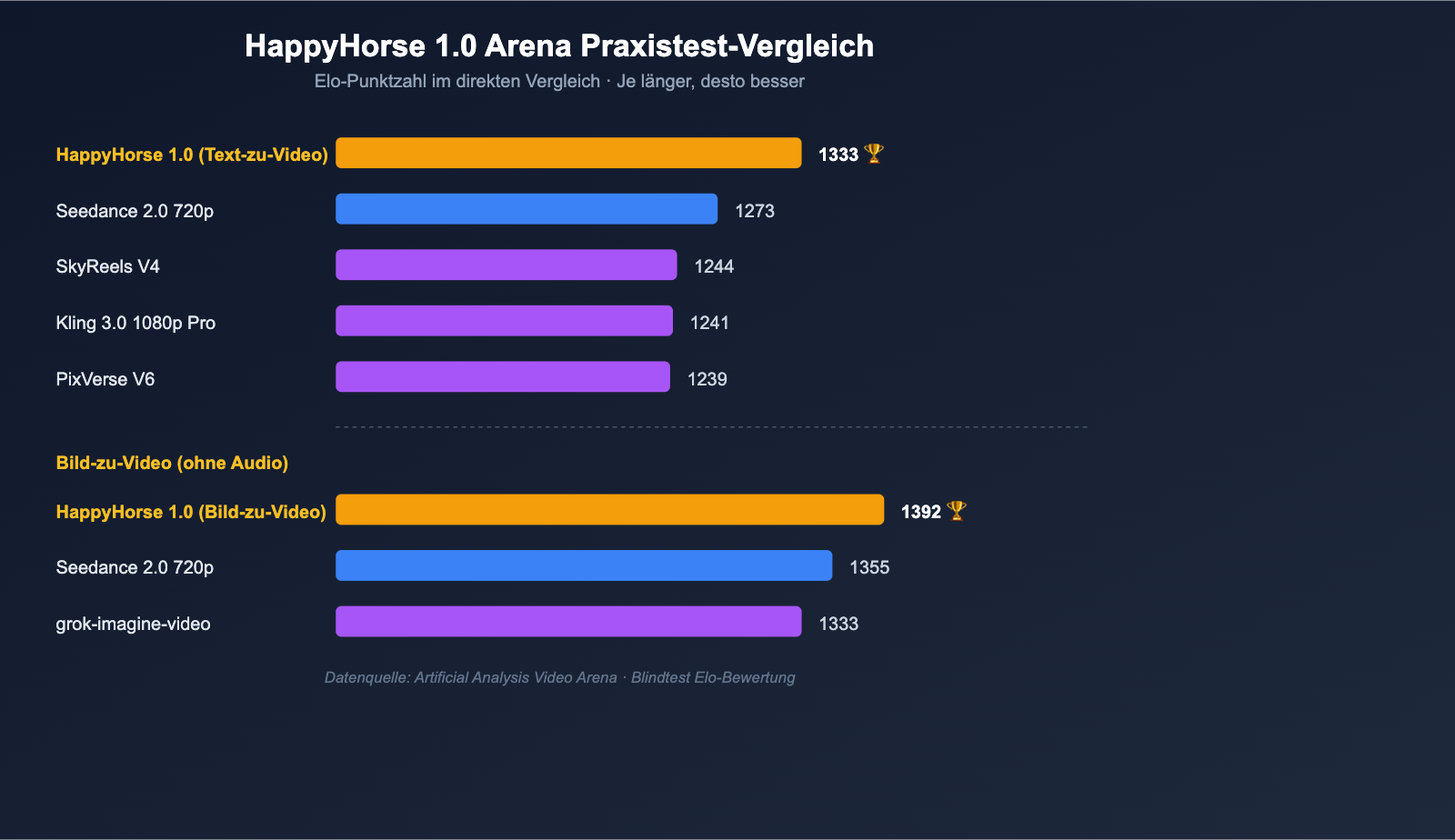
Nachdem wir die Architektur beleuchtet haben, sind es letztlich die Zahlen, die ein professionelles Team überzeugen. Die folgende Tabelle fasst die Elo-Werte aus den öffentlichen Aufzeichnungen der Artificial Analysis Video Arena für HappyHorse 1.0 zusammen und zeigt, wo die wichtigsten Wettbewerber stehen.
Elo-Vergleich: Text-zu-Video / Bild-zu-Video
| Kategorie | Rang | Modell | Elo-Wert |
|---|---|---|---|
| Text-zu-Video (ohne Audio) | 1 | HappyHorse-1.0 | 1333 |
| Text-zu-Video (ohne Audio) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| Text-zu-Video (ohne Audio) | 3 | SkyReels V4 | 1244 |
| Text-zu-Video (ohne Audio) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| Text-zu-Video (ohne Audio) | 5 | PixVerse V6 | 1239 |
| Text-zu-Video (mit Audio) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| Text-zu-Video (mit Audio) | 2 | HappyHorse-1.0 | 1205 |
| Bild-zu-Video (ohne Audio) | 1 | HappyHorse-1.0 | 1392 |
| Bild-zu-Video (ohne Audio) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| Bild-zu-Video (ohne Audio) | 3 | PixVerse V6 | 1338 |
| Bild-zu-Video (ohne Audio) | 4 | grok-imagine-video | 1333 |
| Bild-zu-Video (ohne Audio) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
Wichtige Erkenntnisse:
- Größter Vorsprung bei Bild-zu-Video: Mit 1392 zu 1355 Punkten liegt das Modell fast 40 Elo-Punkte vorn – ein Bereich, in dem Nutzer den Unterschied in Blindtests stabil wahrnehmen können.
- Spitzenreiter bei reinem Text-zu-Video: Mit 1333 zu 1273 Punkten führt das Modell mit 60 Punkten Vorsprung. Das bedeutet, dass das HappyHorse-Modell selbst ohne Referenzbild bei Bildkomposition und Bewegungsabläufen bereits vor Seedance 2.0 liegt.
- Vorläufig Platz 2 bei Audio: Seedance 2.0 führt bei der Audio-Bild-Synchronisation weiterhin, was auf die gezielte Optimierung für "KI-Regisseure" und längere Erzählformate zurückzuführen ist.
- V2-Variante: V2 tauchte in einigen Screenshots kurzzeitig an der Spitze auf, aber offiziell wurde bisher nur 1.0 veröffentlicht. Ob V2 die "verschwundene" Version ist, bleibt unklar.
Mehrsprachigkeit und menschenzentrierte Szenarien
Offiziell unterstützt HappyHorse 1.0 nativ 6 Sprachen: Chinesisch, Englisch, Japanisch, Koreanisch, Deutsch und Französisch. Besonders hervorgehoben wird die Leistung in "menschenzentrierten" Szenarien:
- Detaillierte Mimik (facial performance);
- Natürliche Sprachkoordination (speech coordination);
- Realistische Körperbewegungen (body motion);
- Präzise Lippensynchronisation (lip sync).
Diese Beschreibung positioniert das HappyHorse-Modell klar im Bereich "Virtuelle Menschen / Digitale Inhalte / Kurzserien" und nicht nur für "Landschaftsaufnahmen". Dies erklärt auch den Vorsprung bei Bild-zu-Video (Animation von Porträtfotos) – eine Kernanforderung für digitale Avatare.
Herkunft des HappyHorse-Modells: WAN 2.7? Seedance? Oder ein neuer Herausforderer?
Als die Screenshots von HappyHorse 1.0 in der englischsprachigen KI-Szene kursierten, war die Frage nach der Herkunft das Hauptthema. Basierend auf Hinweisen aus der Community haben wir die Theorien in der folgenden Tabelle zusammengefasst.
Vergleich der drei Haupttheorien
| Vermutung | Hauptargumente | Gegenargumente |
|---|---|---|
| Alibaba Wan 2.7 Alias | Wan 2.7 erschien zeitgleich; Alibaba Tongyi Lab agiert im Videobereich aggressiv; "Horse" passt zum Jahr des Pferdes | Die offizielle Beschreibung von Wan 2.7 fokussiert auf Bild/Denkmodi, was nicht zur Single-Flow-Architektur von HappyHorse passt |
| ByteDance Seedance-Experiment | Seedance 2.0 ist ein führender chinesischer Akteur in der Arena; ByteDance hat ein Motiv für anonyme Tests | Seedance 2.0 führt bei Audio noch vor HappyHorse; ByteDance hätte keinen Grund, eine "stärkere Version" unter anderem Namen hochzuladen |
| Unbekanntes Labor / Konsortium | Veröffentlichung als "Open Source + Destillationsmodell + Upscaler" wirkt wie Forschungsarbeit; schrulliger Name, minimalistische Website | Die Modellqualität erreicht kommerzielles Niveau; reine akademische Teams trainieren selten Modelle dieser Größenordnung |
Wir halten die dritte Hypothese für immer wahrscheinlicher: HappyHorse 1.0 stammt vermutlich von einem neuen Team, das durch eine Open-Source-Strategie schnell bekannt werden will. Die anonyme Teilnahme an der Arena diente dazu, Vertrauen durch Blindtest-Daten aufzubauen, bevor das offizielle Release erfolgt. Diese Strategie – erst Ranking, dann Open Source, dann Produkt – hat sich in den letzten 18 Monaten bei mehreren asiatischen Laboren bewährt.
Dies bleibt jedoch Spekulation. Bevor das GitHub-Repository und der Model Hub offiziell live sind, sollte keine Vermutung als Fakt gelten. Für Entwickler ist es pragmatischer: Achten Sie auf die Leistungskurve, nicht auf den Namen.
🎯 Vorsichtiger Rat: Solange die Gewichte des HappyHorse-Modells nicht öffentlich zugänglich und die Quellen nicht bestätigt sind, sollten Sie keine Produktionsumgebungen darauf aufbauen. Nutzen Sie stattdessen bewährte Plattformen wie APIYI (apiyi.com), um kommerzielle Modelle wie Seedance 2.0, Kling 3.0 oder Veo 3.1 für Ihre Projekte zu integrieren, während Sie die Open-Source-Entwicklung von HappyHorse intern parallel evaluieren.
Die dreistufigen Auswirkungen des HappyHorse-Modells auf die Branche
Auch wenn sich HappyHorse 1.0 letztendlich nur als eine sorgfältig geplante Marketing-Aktion herausstellen sollte, hat es bereits drei bemerkenswerte Auswirkungen auf den gesamten Bereich der KI-Videogenerierung hinterlassen.
Ebene 1: Signale für das Architektur-Paradigma
In den letzten zwei Jahren haben sich die führenden Videomodelle weiterhin auf den Pfad von Multi-Stream-Diffusion und Cross-Attention konzentriert. Das HappyHorse-Modell hat mit seinem ersten Platz in der Arena direkt bewiesen, dass der Weg über „Single-Stream Self-Attention + minimale Inferenzschritte“ ebenfalls zum SOTA (State-of-the-Art) führen kann – und das technisch deutlich sauberer. Dies wird viele Teams dazu bewegen, ihre Strategie zu überdenken: Ist es an der Zeit, die „Komplexitätssteuer“ der Cross-Attention einzusparen?
Ebene 2: Die Evolution der Open-Source-Strategie
HappyHorse wählte den Rhythmus „anonymes Erscheinen in der Rangliste → öffentliche Ankündigung der Open-Source-Veröffentlichung → Bereitstellung der Gewichte“, anstatt den traditionellen Weg über „erst Paper, dann Gewichte“ zu gehen. Dies ist ein Ansatz, der eher einer Veröffentlichung von Konsumgütern gleicht und die „nutzerzentrierten Daten“ vor die wissenschaftliche Publikation stellt. Sollte es wie versprochen Open Source werden, könnte HappyHorse 1.0 nach Wan, Hunyuan Video und Open-Sora zu einem weiteren grundlegenden Videomodell werden, das intensiv weiterentwickelt wird.
Ebene 3: Die Glaubwürdigkeit von Blindtests
Aus einer anderen Perspektive betrachtet, war das „plötzliche Auftauchen und Verschwinden“ von HappyHorse ein Weckruf für Blindtest-Plattformen wie Artificial Analysis oder LMArena. Da die Zahl der anonymen Einträge zunimmt, wird die Unterscheidung zwischen „echten neuen Modellen“ und „einem bestimmten Checkpoint eines bestehenden Modells“ zu einer Herausforderung, der sich die Betreiber der Ranglisten stellen müssen. Für Entwickler bedeutet dies, dass wir beim Lesen von Elo-Rankings mehr Wert auf eine Kombination aus „Modellkarte + Inferenzbeispielen + realen Geschäftsdaten“ legen müssen, anstatt nur auf eine einzelne Zahl zu schauen.
Wie Entwickler auf „Überraschungsangriffe“ wie das HappyHorse-Modell reagieren sollten
Für Engineering-Teams und Content-Ersteller ist es sinnvoller, ein standardisiertes Vorgehen für solche Überraschungsereignisse zu etablieren, anstatt sich in Spekulationen darüber zu verlieren, wer dahintersteckt oder wann es veröffentlicht wird.
Empfohlener vierstufiger Prozess
| Schritt | Aktion | Ziel |
|---|---|---|
| 1 | Etablierung einer einheitlichen Schnittstelle für bestehende Videogenerierung | Sicherstellung eines nahtlosen Wechsels bei Erscheinen neuer Modelle |
| 2 | Sammlung typischer Geschäfts-Eingabeaufforderungen und Referenzbilder | Aufbau eines internen „Benchmark-Sets“, unabhängig von öffentlichen Arenen |
| 3 | Durchführung interner Benchmarks unmittelbar nach Verfügbarkeit des neuen Modells | Validierung der Arena-Ergebnisse mit eigenen Daten |
| 4 | Bewertung der Gesamtkosten (API-Preise / Inferenzlatenz / Compliance) | Entscheidung über den Austausch des Hauptmodells |
Der Kern dieses Prozesses ist: Lassen Sie sich nicht vom Veröffentlichungsrhythmus eines einzelnen Modells abhängig machen, sondern machen Sie die „schnelle Anbindung neuer Modelle“ zu einer grundlegenden Fähigkeit. HappyHorse 1.0 war nur der Anfang; es ist absehbar, dass in der zweiten Jahreshälfte 2026 weitere anonyme Modelle in verschiedenen Video-Arenen auftauchen werden.
🎯 Engineering-Empfehlung: Für Teams, die das HappyHorse-Modell sowie Wettbewerber wie Seedance, Kling oder Veo langfristig verfolgen möchten, empfehlen wir die Anbindung der Videogenerierung über einen API-Proxy-Dienst wie APIYI (apiyi.com), der den parallelen Aufruf mehrerer Modelle unterstützt. So muss bei einem neuen Spitzenreiter lediglich ein Modell-Parameter umgestellt werden, um Vergleiche durchzuführen und ein Canary-Deployment zu starten.
FAQ zum HappyHorse-Modell
F1: Kann man HappyHorse 1.0 bereits herunterladen und verwenden?
Aktuell (Anfang April 2026) markiert die offizielle Seite von HappyHorse 1.0 sowohl das GitHub-Repository als auch den Model Hub noch mit „Coming Soon“. Das bedeutet: Die Gewichte und der Inferenz-Code sind noch nicht öffentlich zugänglich. Seien Sie vorsichtig bei allen Quellen, die behaupten, das Modell bereits zum Download oder zur Bereitstellung anzubieten. Wir empfehlen, die offizielle Website im Auge zu behalten und bis zur Veröffentlichung der Gewichte auf Plattformen wie APIYI (apiyi.com) auf bereits kommerziell verfügbare Modelle wie Seedance 2.0 oder Kling 3.0 zurückzugreifen.
F2: Warum ist das HappyHorse-Modell aus der Arena-Bestenliste verschwunden?
Es gibt keine offizielle Erklärung für das Verschwinden. In der Community kursieren zwei Haupttheorien: Erstens könnten die Entwickler das Modell freiwillig zurückgezogen haben, um die Ergebnisse vor einer offiziellen Veröffentlichung neu zu strukturieren. Zweitens könnte die Plattform das Modell aufgrund des unklaren Status des anonymen Eintrags vorübergehend entfernt haben. In jedem Fall sollte dies nicht als „Leistungsschwäche“ interpretiert werden – der Elo-Wert vor dem Verschwinden basierte auf echten Blindtest-Daten.
F3: Sind HappyHorse 1.0 und Wan 2.7 dasselbe Modell?
Es gibt keine offiziellen Informationen, die dies bestätigen. Wan 2.7 ist ein im April 2026 von Alibabas Tongyi Lab veröffentlichtes Bild-/Videomodell, das sich auf einen „Denkmodus“ und die Darstellung langer Texte konzentriert. Das HappyHorse-Modell hingegen setzt auf einen 40-schichtigen Single-Stream-Transformer und eine 8-stufige Entrauschungs-Inferenz. Die technischen Beschreibungen unterscheiden sich deutlich. Einige in der Community vermuten einen gemeinsamen Ursprung, doch aktuell sieht es eher nach zwei konkurrierenden Produkten aus demselben Zeitraum aus, statt nach einer bloßen Umbenennung.
F4: Kann das HappyHorse-Modell Audio und Video gleichzeitig generieren?
Ja. Offiziellen Angaben zufolge verarbeitet HappyHorse 1.0 Text-, Video- und Audio-Token in einem einzigen 40-schichtigen Transformer und unterstützt daher nativ die Eingabe „Text → Ausgabe als vertonter Kurzfilm“. In der Arena-Kategorie für Audio-Video-Inhalte liegt es aktuell auf dem zweiten Platz hinter Seedance 2.0 und gehört damit weiterhin zur ersten Riege.
F5: Wie sollte ich mich als Entwickler vorbereiten?
Der effizienteste Weg ist eine tool-neutrale Strategie: Integrieren Sie Ihre Videogenerierung in eine einheitliche Plattform wie APIYI (apiyi.com), die den parallelen Aufruf mehrerer Modelle unterstützt. Bereiten Sie Ihre Eingabeaufforderung, Kamera-Skripte und Prüfprozesse vor. Sobald das HappyHorse-Modell offiziell als Open Source verfügbar ist oder über eine API bereitgestellt wird, müssen Sie lediglich den Modell-Parameter anpassen, um das neue „Dark Horse“ ohne Code-Neuschreibung einzubinden.
F6: Für welche Geschäftsszenarien eignet sich das HappyHorse-Modell?
Basierend auf dem offiziellen Fokus auf „menschliche Szenarien, Mimik, Lippensynchronisation und Mehrsprachigkeit“ eignet sich das HappyHorse-Modell besonders für: Virtuelle Moderatoren / KI-Kurzvideos, KI-Miniserien, mehrsprachige Werbefilme und Charakter-Szenen in der Werbung. Wenn Ihr Fokus auf Landschaftsaufnahmen oder Produktvideos liegt, sind Seedance 2.0, Veo 3.1 oder Kling 3.0 weiterhin die stabilere Wahl.
Fazit: Was wir vom HappyHorse-Modell lernen können
Zusammengenommen ist HappyHorse 1.0 nicht nur wegen seines beeindruckenden Elo-Werts in der Artificial Analysis Video Arena eine Analyse wert. Es repräsentiert einen Paradigmenwechsel bei der Veröffentlichung von Videomodellen im Jahr 2026: Single-Stream-Transformer ersetzen komplexe Multi-Stream-Strukturen, minimale Inferenzschritte ersetzen langwierige Entrauschungsprozesse, anonyme Einträge ersetzen Vorab-Publikationen und Open-Source-Versprechen ersetzen geschlossene APIs. Auch wenn diese Änderungen einzeln nicht revolutionär wirken, deuten sie in der Summe auf ein neues Tempo bei der Iteration von Videomodellen hin.
Unser Rat an Entwicklungsteams ist simpel: Verlieren Sie sich nicht im Rätselraten um die Herkunft, sondern nutzen Sie es als Stresstest für Ihre Technik. Kann Ihre Videogenerierungs-Pipeline ein neues Modell am Tag seines Erscheinens integrieren und bewerten? Wenn ja, profitieren Sie davon – egal, ob HappyHorse nun wirklich Open Source wird, sich als Zweitmarke eines Herstellers entpuppt oder für immer in der Versenkung verschwindet.
🎯 Empfehlung: Wenn Sie alle führenden KI-Videomodelle (Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6 etc.) sofort testen und die Flexibilität behalten wollen, später mit einem Klick auf HappyHorse zu wechseln, empfehlen wir die Nutzung einer zentralen API-Proxy-Dienst-Plattform wie APIYI (apiyi.com). So vermeiden Sie die redundante Anbindung der SDKs jedes einzelnen Anbieters und minimieren den Migrationsaufwand bei neuen Modellveröffentlichungen.
Autor: APIYI Team | Wir konzentrieren uns auf die Implementierung und technische Praxis von KI-Großen Sprachmodellen. Weitere Bewertungen zu Video- und multimodalen Modellen finden Sie unter APIYI (apiyi.com).