Autorennotiz: Echte Testdaten enthüllen den Grundgrund, warum Gemini und DeepSeek beim Übersetzen desselben Artikels einen Token-Verbrauch von 2-2,5x Unterschied aufweisen — Tokenizer-Codierungseffizienzunterschiede und bieten Kostenoptimierungsempfehlungen für mehrsprachige Szenarien
Derselbe chinesische Artikel wird mit Gemini und DeepSeek jeweils ins Englische, Japanische und Französische übersetzt, wobei die Übersetzungsqualität und Vollständigkeit völlig identisch sind — aber die von der API zurückgegebenen Completion Token unterscheiden sich um 2-2,5x. Ist das ein API-Abrechnungsfehler? Oder gibt es tiefere technische Gründe?
Kernwert: Durch echte Testdaten verstehen Sie, wie Tokenizer-Unterschiede die API-Kosten beeinflussen, und beherrschen die Methode, um in mehrsprachigen Übersetzungsszenarien das kostengünstigste Modell auszuwählen.

Gemini vs DeepSeek Tokenizer — Kernvergleichsdaten
| Vergleichsdimension | Gemini 3 Flash | DeepSeek V3.2 | Unterschiedsfaktor |
|---|---|---|---|
| Englische Übersetzung Completion Token | 1.631 | 636 | Gemini 2,56x höher |
| Japanische Übersetzung Completion Token | 2.141 | 856 | Gemini 2,50x höher |
| Französische Übersetzung Completion Token | 1.630 | 812 | Gemini 2,01x höher |
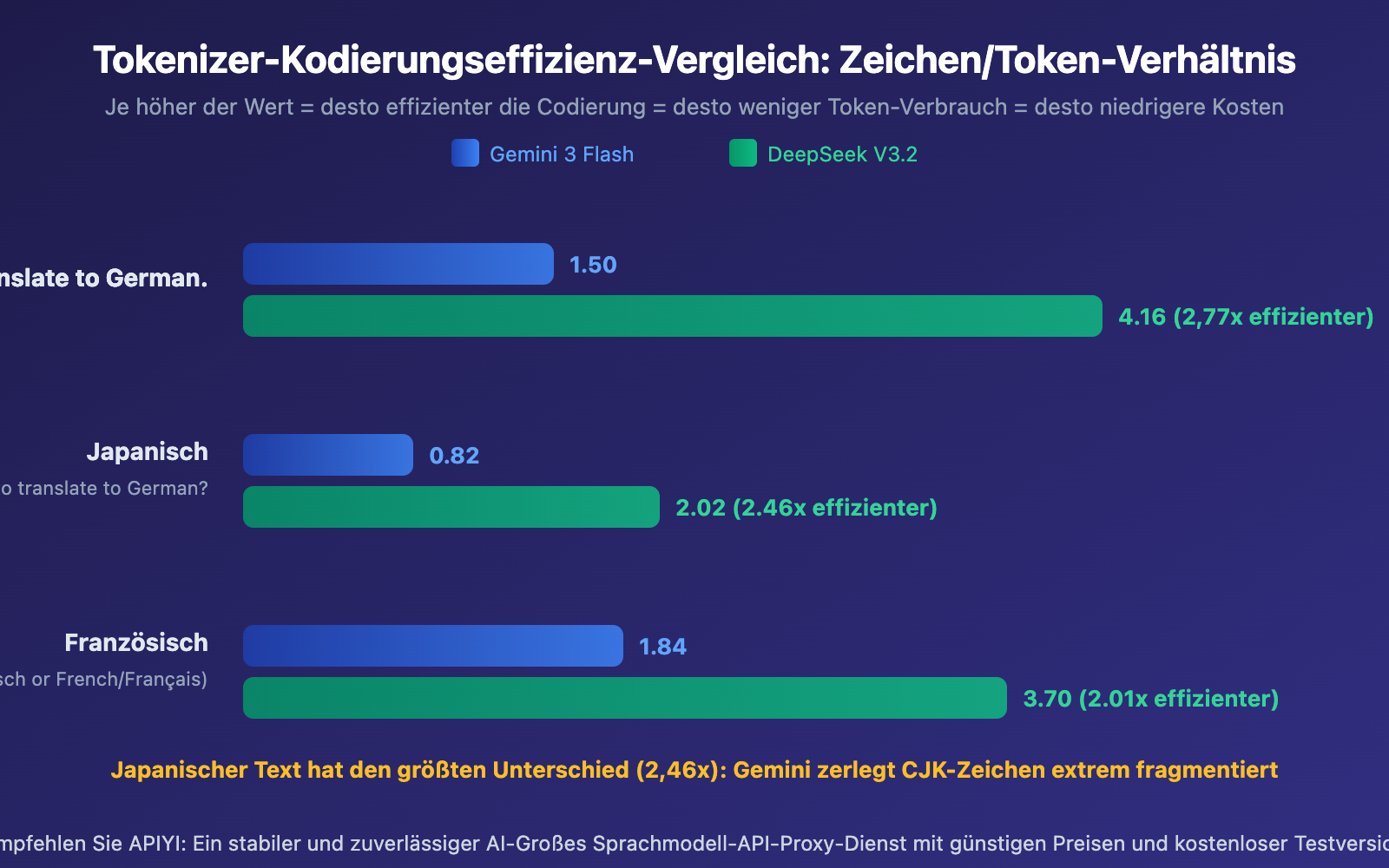
| Codierungseffizienz (Zeichen/Token) | 0,82–1,84 | 2,02–4,16 | DeepSeek 2–2,8x höher |
| Übersetzungsausgabe Zeilenanzahl | 64 Zeilen | 64 Zeilen | Völlig identisch |
Die Grundursachen der Tokenizer-Unterschiede zwischen Gemini und DeepSeek
Wir verwendeten denselben 1.403 Zeichen langen chinesischen Testtext (mit Markdown-Tabellen, Code-Blöcken, SVG-Platzhaltern und CTA), riefen gemini-3-flash-preview und deepseek-v3.2 auf, um ihn ins Englische, Japanische und Französische zu übersetzen, und verglichen dann die von der API zurückgegebenen Token-Statistiken und tatsächlichen Ausgabeinhalte.
Das Ergebnis ist sehr eindeutig: Die Ausgabezeichenanzahl ist fast identisch (Unterschied unter 1%), aber die Token-Anzahl unterscheidet sich um 2–2,5x. Dies beweist, dass das Problem im Tokenizer (Tokenisierungsprogramm) liegt, nicht in der Ausgabestrategie des Modells.
Die technischen Prinzipien der Tokenizer von Gemini und DeepSeek
Was ist ein Tokenizer? Einfach ausgedrückt ist ein Tokenizer ein Werkzeug, das Text in die kleinsten Einheiten zerlegt, die das Modell verstehen kann (Token). Verschiedene Modelle verwenden unterschiedliche Tokenizer — wie unterschiedliche Kompressionssoftware: Dieselbe Datei hat unterschiedliche Größen, wenn sie mit ZIP oder RAR komprimiert wird, aber der Inhalt nach dem Entpacken ist völlig identisch.
Geminis SentencePiece Tokenizer: Verwendet ein Unigram-Sprachmodell mit einer Vokabulargröße von etwa 256.000 Token. Neigt dazu, CJK-Zeichen (Chinesisch, Japanisch, Koreanisch) in kleinere Subwort-Einheiten zu zerlegen. In unseren Tests betrug die Codierungseffizienz der japanischen Ausgabe nur 0,82 Zeichen/Token, was bedeutet, dass durchschnittlich jedes japanische Zeichen 1,2 Token benötigt, um dargestellt zu werden.
DeepSeeks Byte-level BPE Tokenizer: Hat eine Vokabulargröße von etwa 128.000 Token, wurde aber speziell für mehrsprachige Szenarien optimiert. Führt kombinierte Interpunktions- und Zeilenumbruch-Token ein, um die Kompressionseffizienz von CJK-Text zu verbessern. Die japanische Ausgabe erreicht 2,02 Zeichen/Token — eine Effizienz, die 2,46x höher ist als bei Gemini.
Gemini vs DeepSeek Tokenizer – Kostenauswirkungsanalyse
Nachdem wir die Unterschiede in der Tokenizer-Effizienz verstanden haben, stellt sich die entscheidende Frage: Bedeutet mehr Token automatisch höhere Kosten? Nicht unbedingt. Die endgültigen Kosten hängen von der Formel Token-Anzahl × Einzelpreis ab.
Gemini vs DeepSeek – Übersetzungskosten in der Praxis
Nehmen wir als Beispiel die Übersetzung eines typischen technischen Blogartikels (etwa 30.000 Prompt Token) in 11 Sprachen:
| Kostenfaktor | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Geschätztes Completion Token pro Sprache | ~80.000 | ~30.000 |
| Completion Token für 11 Sprachen gesamt | ~880.000 | ~330.000 |
| Output-Preis (pro Million Token) | $3,00 | $0,42 |
| Gesamtkosten Output für 11 Sprachen | $2,64 | $0,14 |
| Input-Preis (pro Million Token) | $0,50 | $0,28 |
| Gesamtkosten Input für 11 Durchläufe | $0,17 | $0,09 |
| Gesamtkosten für Artikelübersetzung | $2,81 | $0,23 |
Die praktischen Kostenergebnisse zeigen einen deutlichen Vorteil von DeepSeek im Mehrsprachenszenario – für die gleiche Übersetzungsaufgabe kostet DeepSeek nur etwa 1/12 von Gemini. Dieser Unterschied ergibt sich aus zwei überlagerten Faktoren: Tokenizer-Effizienz (2–2,5x) × Preisunterschied pro Token (5–7x).
Gemini vs DeepSeek – Übersetzungsgeschwindigkeit und Qualität
Kosten sind jedoch nicht der einzige Faktor:
| Metrik | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Inferenzgeschwindigkeit | 145–189 Token/s | 12–26 Token/s |
| Geschwindigkeitsvorteil | 6–10x schneller | Baseline |
| Übersetzungsqualität | Ausgezeichnet | Ausgezeichnet |
| Übersetzungsvollständigkeit | 100% (64 Zeilen) | 100% (64 Zeilen) |
| Markdown-Formatbeibehaltung | Gut | Gut |
Gemini ist 6–10 mal schneller als DeepSeek. Wenn Sie schnelle Massenübersetzungen benötigen und die Zeitkosten höher sind als die Token-Kosten, ist Gemini immer noch die bessere Wahl.
🎯 Auswahlempfehlung: Bei großen Übersetzungsmengen und zeitlicher Flexibilität bietet DeepSeek erhebliche Kosteneinsparungen. Wenn schnelle Lieferung erforderlich ist, hat Gemini klare Geschwindigkeitsvorteile. Mit APIYI unter apiyi.com können Sie beide Modelle über eine einheitliche Schnittstelle nutzen und flexibel wechseln, um das optimale Gleichgewicht für Ihren Anwendungsfall zu finden.
Auswirkungen der Tokenizer-Effizienz auf verschiedene Sprachen
Die Tokenizer-Effizienz wirkt sich bei verschiedenen Sprachen sehr unterschiedlich aus. CJK-Sprachen (Chinesisch, Japanisch, Koreanisch) sind am stärksten betroffen, während lateinische Schriftsysteme relativ weniger beeinträchtigt sind.

Aus den Daten wird deutlich:
- Japanisch ist am stärksten betroffen: Bei Gemini beträgt die Kodierungseffizienz für Japanisch nur 0,82 Zeichen/Token. Dies erklärt, warum die Token-Nutzung bei der Übersetzung von Artikeln mit großem Anteil an chinesischen oder japanischen Zeichen erheblich ansteigt
- Französisch hat die kleinsten Unterschiede: Sprachen mit lateinischem Schriftsystem zeigen relativ kleine Tokenizer-Unterschiede (nur 2,01x), da die meisten Tokenizer hauptsächlich mit englischsprachigen Daten trainiert wurden und lateinische Sprachen davon profitieren
- Chinesisch liegt in der Mitte: Etwa 1,76 mal höher als der englische Baseline-Wert, aber bei Verwendung von chinesisch-optimierten Modellen wie DeepSeek oder Qwen wird der Unterschied kleiner
🎯 Empfehlung für Mehrsprachenübersetzung: Wenn Ihre Übersetzungsaufgaben CJK-Sprachen wie Japanisch oder Koreanisch umfassen, kann die Wahl eines Modells mit höherer Tokenizer-Effizienz (wie DeepSeek oder Qwen) die Kosten erheblich senken. Mit der einheitlichen Schnittstelle von APIYI unter apiyi.com können Sie bequem zwischen verschiedenen Modellen wechseln und testen.
Gemini vs DeepSeek Tokenizer Szenarioauswahl-Leitfaden
| Anwendungsszenario | Empfohlenes Modell | Kerngrund |
|---|---|---|
| Massenhafte mehrsprachige Übersetzung | DeepSeek V3.2 | Hohe Token-Effizienz + niedrige Einzelpreise, Kosten nur 1/12 |
| Dringende Übersetzungslieferung | Gemini 3 Flash | 6-10x schneller, ideal für zeitkritische Szenarien |
| CJK-sprachintensive Übersetzung | DeepSeek V3.2 | CJK-Tokenizer-Effizienzvorteile erreichen 2,5x |
| Lateinische Sprachfamilien-Übersetzung | Geringer Unterschied | Effizienzunterschied zwischen beiden nur 2x, Auswahl nach Einzelpreis |
| Echtzeit-Dialogszenario | Gemini 3 Flash | Niedrige Latenz, besseres Benutzererlebnis |
| Kostenempfindliche Batch-Verarbeitung | DeepSeek V3.2 | Niedrigste Gesamtkosten |
🎯 Praktischer Tipp: In realen Projekten müssen Sie oft Kosten und Geschwindigkeit berücksichtigen. Wir empfehlen, Gemini und DeepSeek gleichzeitig über APIYI apiyi.com zu integrieren und Modelle je nach Aufgabendringlichkeit dynamisch zu wechseln. Die Plattform unterstützt einheitliche Key-Aufrufe für alle gängigen Modelle.
Häufig gestellte Fragen
F1: Ist der hohe Gemini Token-Verbrauch ein API-Abrechnungsfehler?
Nein. Dies ist ein normales Phänomen, das durch Unterschiede in der Tokenizer-Codierungseffizienz verursacht wird. Ähnlich wie eine Datei mit ZIP und RAR unterschiedlich komprimiert wird, generieren verschiedene Modell-Tokenizer unterschiedliche Token-Mengen für denselben Text, verarbeiten aber denselben Inhalt. Unsere praktischen Tests zeigten Unterschiede in der Ausgabezeichenanzahl von weniger als 1%.
F2: Bedeutet eine höhere Token-Anzahl bessere Übersetzungsqualität?
Nein. Die Token-Anzahl spiegelt nur die Codierungsmethode des Tokenizers wider und hat nichts mit der Übersetzungsqualität zu tun. In praktischen Tests zeigten beide Modelle hervorragende Übersetzungsqualität und Vollständigkeit, mit identischer Ausgabezeilenzahl (64 Zeilen). Bei der Modellauswahl sollten Sie sich auf Übersetzungsqualität, Geschwindigkeit und Gesamtkosten konzentrieren, nicht nur auf die Token-Anzahl.
F3: Wie optimiere ich die Token-Kosten für mehrsprachige Übersetzung in meinem Projekt?
Wir empfehlen die folgenden Strategien:
- Für CJK-Sprachen (Chinesisch, Japanisch, Koreanisch) bevorzugt Modelle mit hoher Tokenizer-Effizienz wie DeepSeek verwenden
- Für lateinische Sprachfamilien flexibel wählen, da die Unterschiede gering sind
- Mehrere Modelle über APIYI apiyi.com integrieren und mit einheitlicher API automatisches Routing nach Sprache implementieren
- Bei der Token-Verbrauchsüberwachung unterschiedliche Schwellenwerte für verschiedene Modelle setzen, um Fehlalarme zu vermeiden
Zusammenfassung
Die Kernerkenntnisse des Vergleichs der Tokenizer-Effizienz zwischen Gemini und DeepSeek:
- Token-Unterschiede stammen vom Tokenizer, nicht von Bugs: Bei demselben Text ist die Kodierungseffizienz des DeepSeek-Tokenizers 2–2,8-mal höher als die von Gemini, wobei die Unterschiede bei CJK-Sprachen am deutlichsten sind
- Kostenunterschiede verstärken sich gegenseitig: Tokenizer-Effizienzunterschiede (2–2,5x) × Token-Preisunterschiede (5–7x) = tatsächliche Kostenunterschiede können bis zu 12-mal betragen
- Abwägung zwischen Geschwindigkeit und Kosten: Gemini ist 6–10-mal schneller, aber Token-Kosten sind höher; DeepSeek hat niedrigere Kosten, aber langsamere Geschwindigkeit – wählen Sie flexibel je nach Szenario
Das Verständnis der Tokenizer-Effizienzunterschiede ist ein Schlüsselschritt zur Optimierung der Kosten für die Nutzung von AI-APIs. Bei Token-intensiven Szenarien wie mehrsprachigen Übersetzungen können Sie durch die Wahl des richtigen Modells erhebliche Kosten sparen.
Wir empfehlen, über APIYI (apiyi.com) mehrere Modelle einheitlich zu integrieren und mit einem einzigen API-Schlüssel flexibel zwischen ihnen zu wechseln, um die beste Kosteneffizienz für jedes Szenario zu finden.
📚 Referenzmaterialien
-
Tokenizer-Performance-Benchmark: Umfassender Vergleich der Tokenizer-Effizienz führender Modelle
- Link:
llm-calculator.com/blog/tokenization-performance-benchmark - Beschreibung: Enthält Tokenizer-Effizienzdaten für GPT-4o, DeepSeek, Qwen und andere Modelle
- Link:
-
CJK-Text und Best Practices für große Sprachmodelle: Tokenizer-Verarbeitungsmechanismus für CJK-Zeichen
- Link:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - Beschreibung: Tiefgehende Analyse der Token-Verbrauchsunterschiede bei CJK-Sprachen unter verschiedenen Tokenizern
- Link:
-
Gemini-Tokenizer-Analyse: Funktionsweise des SentencePiece-Tokenizers von Google Gemini
- Link:
dejan.ai/blog/gemini-toknizer - Beschreibung: Detaillierte Analyse des Kodierungsmechanismus und der Effizienzmerkmale des 256K-Vokabulars von Gemini
- Link:
-
DeepSeek V3 Technischer Bericht: Mehrsprachige Optimierung des Byte-Level-BPE-Tokenizers
- Link:
arxiv.org/html/2412.19437v1 - Beschreibung: Designprinzipien des 128K-Vokabulars von DeepSeek und Kompressionseffizienz für mehrere Sprachen
- Link:
Autor: APIYI-Technikteam
Technischer Austausch: Diskussionen sind in den Kommentaren willkommen. Weitere Materialien finden Sie im Dokumentationszentrum von APIYI unter docs.apiyi.com