Seed 2.0 Modell: Pro, Lite oder Mini? Dies ist die zentrale Entscheidung für viele Entwickler bei der Anbindung der neuesten großen Sprachmodelle von ByteDance. In diesem Vergleich von Seed 2.0 Pro, Seed 2.0 Lite und Seed 2.0 Mini analysieren wir Benchmarks, Kosten und Kontextkapazität, um Ihnen eine fundierte Entscheidungshilfe zu bieten.
Kernbotschaft: Nach der Lektüre dieses Artikels wissen Sie genau, welche Seed 2.0 Variante für verschiedene Geschäftsszenarien am besten geeignet ist und wie Sie durch eine Tiering-Strategie das beste Preis-Leistungs-Verhältnis erzielen.

Seed 2.0 Modellfamilie im Überblick
Das Seed-Team von ByteDance hat am 14. Februar 2026 offiziell die Seed 2.0-Serie veröffentlicht. Dabei handelt es sich um die neue Generation multimodaler Basismodelle von ByteDance, die bereits die Nutzerbasis von Produkten wie Doubao im dreistelligen Millionenbereich unterstützen und in verschiedenen globalen öffentlichen Benchmarks Spitzenplätze belegen.
Die Seed 2.0-Familie besteht aus drei Kernmitgliedern, die jeweils eine klare Positionierung und spezifische Einsatzszenarien haben:
| Modell | Positionierung | Kernvorteile | Zielgruppe |
|---|---|---|---|
| Seed 2.0 Pro | Flaggschiff-Modell | Maximale Performance und höchste Intelligenz | Hochkomplexe, wertvolle professionelle Aufgaben |
| Seed 2.0 Lite | Effizienz-Benchmark | Ausgewogenes Verhältnis von Leistung, Geschwindigkeit und Kosten | Universelles Produktionsmodell für Unternehmen |
| Seed 2.0 Mini | Lightweight-Pionier | Hohe Parallelität und geringe Latenz | Anwendungen mit schneller Reaktion und hohem Durchsatz |
Alle drei Modelle wurden systematisch optimiert und verfügen über starke multimodale Verarbeitungsfähigkeiten (Unterstützung von Text-, Bild- und Video-Input). Gleichzeitig wurden sie in den Bereichen logisches Denken (Reasoning), Codegenerierung und Agent-Tool-Aufrufe umfassend verbessert.
Globale Benchmark-Ergebnisse von Seed 2.0 Pro Preview
Die Preview-Version von Seed 2.0 Pro hat in den weltweit renommiertesten Bewertungssystemen bereits Spitzenwerte erzielt:
- LMSYS Chatbot Arena: Platz 6 im Text Arena Gesamtranking, Platz 3-4 in der Vision Arena (Stand: Februar 2026).
- Mathematik-Wettbewerbe: 98,3 Punkte bei AIME 2025, 97,3 Punkte bei HMMT Feb; Goldmedaillen-Niveau bei ICPC, IMO und CMO-Wettbewerben.
- Über 100 öffentliche Benchmarks: In umfassenden Tests, die sprachliches Reasoning, visuelles Verständnis und Agent-Fähigkeiten abdecken, gehört das Modell zur globalen Spitzenklasse.
🎯 Technischer Tipp: Seed 2.0 Mini ist bereits als erstes Modell über die BytePlus-Plattform verfügbar. Als Partner von BytePlus hat APIYI dieses Modell umgehend integriert. Entwickler können die vollständigen Funktionen von Seed 2.0 Mini schnell über die Plattform APIYI (apiyi.com) ausprobieren. Die Pro- und Lite-Versionen werden in Kürze folgen.
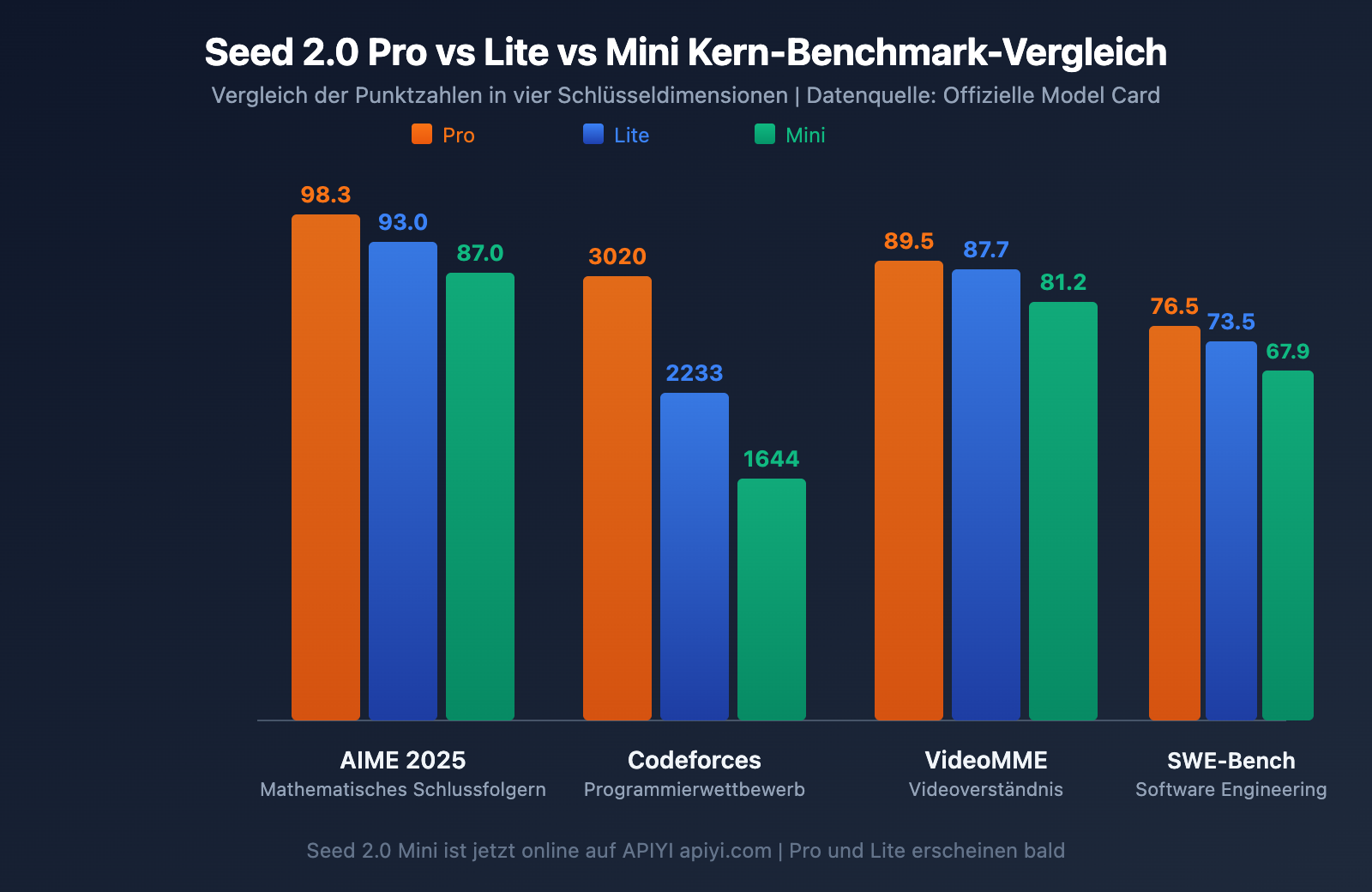
Kern-Benchmark-Vergleich: Seed 2.0 Pro vs. Lite vs. Mini
Hier ist ein vollständiger Vergleich der drei Modelle in den wichtigsten Bewertungsdimensionen. Die Daten stammen aus der offiziellen Seed 2.0 Model Card von ByteDance sowie von Drittanbieter-Tests.
Seed 2.0 Mathematik- und Reasoning-Fähigkeiten im Vergleich
| Testpunkt | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Beschreibung |
|---|---|---|---|---|
| AIME 2025 | 98,3 | 93,0 | 87,0 | American Invitational Mathematics Examination |
| AIME 2026 | 94,2 | 88,3 | 86,7 | Aktuellster jährlicher Mathematik-Wettbewerb |
| GPQA Diamond | 88,9 | 85,1 | 79,0 | Fragen auf Postgraduierten-Niveau |
| MMLU-Pro | 87,0 | 87,7 | 83,6 | Verständnis von Fachwissen |
| HMMT Feb | 97,3 | 90,0 | 70,0 | Harvard-MIT Mathematics Tournament |
| MathVision | 88,8 | 86,4 | 78,1 | Visuelles mathematisches Reasoning |
Betrachtet man die Daten zum mathematischen Reasoning, bilden die drei Modelle eine klare Hierarchie:
- Pro-Klasse: Mit 98,3 bei AIME 2025 und 97,3 bei HMMT markiert dieses Modell die aktuelle Obergrenze für mathematisches Reasoning bei Großsprachmodellen und konkurriert direkt mit GPT-5.2 und Gemini 3 Pro.
- Lite-Klasse: Erreicht 93,0 bei AIME 2025. Bei MMLU-Pro übertrifft Lite mit 87,7 sogar leicht die 87,0 der Pro-Version, was zeigt, dass Lite bei Wissensverständnis-Aufgaben fast Flaggschiff-Niveau erreicht.
- Mini-Klasse: 87,0 bei AIME 2025 ist für ein Modell, das auf hohe Parallelität und Leichtgewichtigkeit ausgelegt ist, ein hervorragender Wert.
Seed 2.0 Code- und Engineering-Fähigkeiten im Vergleich
| Testpunkt | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Beschreibung |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | Rating in Programmierwettbewerben |
| LiveCodeBench v6 | 87,8 | 81,7 | 64,1 | Echtzeit-Programmierbewertung |
| SWE-Bench Verified | 76,5 | 73,5 | 67,9 | Reale Software-Engineering-Aufgaben |
In Bezug auf die Programmierfähigkeiten erreicht das Pro-Modell mit einem Codeforces-Rating von 3020 das Niveau einer internationalen Goldmedaille. Bemerkenswert ist der geringe Abstand bei SWE-Bench Verified: Pro 76,5 vs. Lite 73,5 vs. Mini 67,9. Die Differenz bei realen Software-Engineering-Aufgaben ist viel kleiner als bei Wettbewerbsprogrammierung, was die hohe Praxistauglichkeit von Lite und Mini im Entwickleralltag unterstreicht.
Seed 2.0 Multimodale Fähigkeiten und Video-Verständnis im Vergleich
| Testpunkt | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Beschreibung |
|---|---|---|---|---|
| MMMU | 85,4 | 83,7 | 79,7 | Multimodales Verständnis |
| MMMU-Pro | 78,2 | 76,0 | 71,4 | Professionelles multimodales Verständnis |
| VideoMME | 89,5 | 87,7 | 81,2 | Videoinhaltsanalyse |
| MotionBench | 75,2 | 70,9 | 64,4 | Bewegungswahrnehmung |
| TempCompass | 89,6 | 87,0 | 83,7 | Zeitliches Reasoning |
Multimodalität ist eine der Kernstärken der Seed 2.0-Serie. Die 89,5 Punkte von Pro bei VideoMME demonstrieren ein überragendes Video-Verständnis; die Fähigkeiten in der Bewegungswahrnehmung und im zeitlichen Reasoning übertreffen sogar menschliche Basiswerte. Lite liegt beim Video-Verständnis (87,7) und zeitlichen Reasoning (87,0) dicht hinter Pro und ist damit eine kosteneffiziente Wahl für Videoanalyse-Szenarien in Unternehmen.
Seed 2.0 Agent-Fähigkeiten im Vergleich
| Testpunkt | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Beschreibung |
|---|---|---|---|---|
| BrowseComp | 77,3 | 72,1 | 48,1 | Verständnis beim Webbrowsing |
| Terminal Bench | 55,8 | 45,0 | 36,9 | Terminal-Bedienungsfähigkeiten |
| WideSearch | 74,7 | 74,5 | 37,7 | Breit angelegte Suchaufgaben |
| HLE-Verified | 73,6 | 70,7 | 56,4 | Verifizierung hochkomplexer Reasoning-Aufgaben |
Die Agent-Fähigkeiten sind die entscheidende Dimension zur Unterscheidung der drei Modelle. Pro und Lite liegen bei BrowseComp und WideSearch extrem nah beieinander (Pro 74,7 vs. Lite 74,5), was zeigt, dass Lite bei der autonomen Suche und Informationsintegration fast Flaggschiff-Niveau erreicht. Mini schneidet bei Agent-Aufgaben deutlich schwächer ab und eignet sich eher als ausführende Komponente (für einfache Befehle) in einem Agent-System, weniger als Entscheidungsträger.
Seed 2.0 Mini Modellkarte: Detaillierte Parameter
Seed 2.0 Mini ist das erste Modell der Seed 2.0-Serie, das bereits über die APIYI-Plattform verfügbar ist. Hier sind die vollständigen Modellparameter:
| Parameter | Spezifikation |
|---|---|
| Modell-ID | seed-2-0-mini-260215 |
| Modell-Preise (Prompt ≤ 128K) | Eingabe $0,1/M Tokens, Ausgabe $0,4/M Tokens |
| Eingabetyp | Text + Bild + Video |
| Ausgabetyp | Text |
| Kontextfenster | 256K |
| Maximale Eingabe-Tokens | 256K |
| Maximale Ausgabe-Tokens | 128K |
| Maximale Thinking-Tokens | 128K |
| TPM (Tokens Per Minute) | 1.500K |
| RPM (Requests Per Minute) | 30K |
| Inferenzmodus | 4 Stufen einstellbar: minimal / low / medium / hi |
| Verfügbare Plattformen | APIYI apiyi.com (BytePlus-Partner) |
Die Preisgestaltung von Seed 2.0 Mini ist äußerst wettbewerbsfähig: Eingabe $0,1/M Tokens, Ausgabe $0,4/M Tokens. Zum Vergleich: Der Eingabepreis für GPT-5.2 liegt bei $1,75/M Tokens, für Claude Opus 4.5 bei $5,0/M Tokens. Die Eingabekosten für Seed 2.0 Mini betragen lediglich 1/17,5 von GPT-5.2, was ein herausragendes Preis-Leistungs-Verhältnis bietet.
💰 Kostenoptimierung: Für kostensensible Projekte bietet Seed 2.0 Mini ein extremes Preis-Leistungs-Verhältnis. Über den Zugang via APIYI (apiyi.com) entsprechen die Preise denen der offiziellen BytePlus-Website. Ab einer Aufladung von 100 USD gibt es einen Bonus von mindestens 10 %, was effektiv einem Rabatt von bis zu 20 % entspricht.
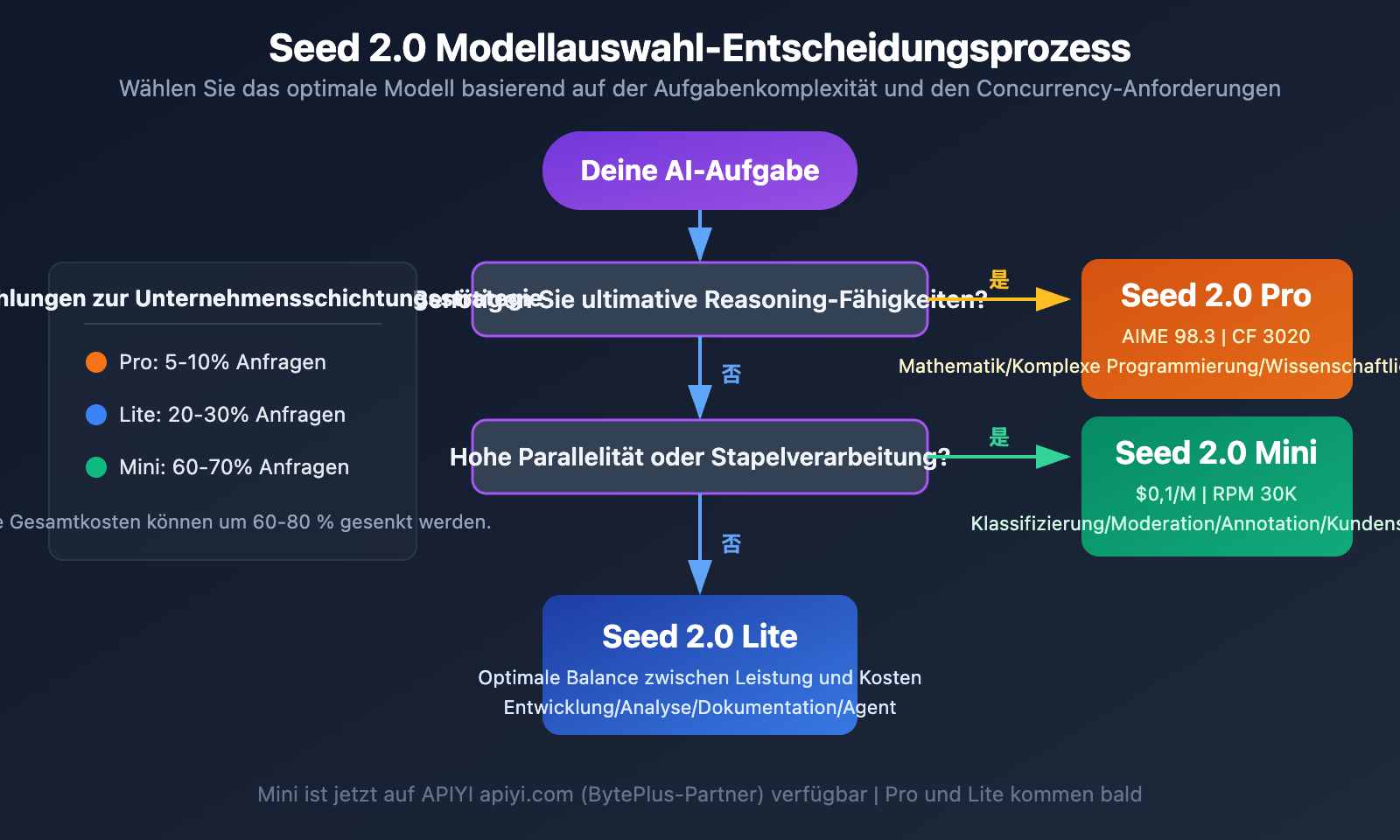
Empfehlungen zur Modellauswahl für Seed 2.0
Szenarien für Seed 2.0 Pro
Seed 2.0 Pro ist die Flaggschiff-Wahl für maximale Intelligenz und eignet sich für folgende hochwertige Szenarien:
- Spitzenforschung: Mathematische Beweise, wissenschaftliches Denken, Unterstützung bei wissenschaftlichen Arbeiten (AIME 98.3, GPQA 88.9).
- Anspruchsvolle Programmierung: Algorithmen-Wettbewerbe, komplexes Systemarchitektur-Design (Codeforces 3020).
- Komplexe Agenten-Aufgaben: Autonomes Browsing, mehrstufige Suche, Orchestrierung komplexer Tools (BrowseComp 77.3, WideSearch 74.7).
- Professionelle Videoanalyse: Verständnis langer Videos, Bewegungswahrnehmung, zeitliches Denken (VideoMME 89.5).
- KI auf Entscheidungsebene: Kernentscheidungen im Business, die höchste Inferenzqualität erfordern.
Szenarien für Seed 2.0 Lite
Seed 2.0 Lite ist die beste Balance für Unternehmens-Produktionsumgebungen:
- Allgemeine Unternehmensaufgaben: Tägliche Code-Entwicklung, Dokumentenverarbeitung, Datenanalyse (SWE-Bench 73.5).
- Inhaltserstellung: Werbetexte, technische Dokumentation, Berichterstellung (MMLU-Pro 87.7).
- Multimodale Geschäftsprozesse: Bild-Text-Verständnis, Video-Zusammenfassungen, Dokumentenanalyse (MMMU 83.7, VideoMME 87.7).
- Agenten-Workflows: Suchassistenten, Informationsintegration, Tool-Aufrufe (WideSearch 74.5, fast auf Pro-Niveau).
- Kostensensible Inferenzaufgaben: Mittlere bis große Unternehmen, die hohe Qualität bei begrenztem Budget benötigen.
Szenarien für Seed 2.0 Mini
Seed 2.0 Mini ist die optimale Wahl für Szenarien mit hoher Parallelität und niedrigen Kosten:
- Batch-Verarbeitung von Inhalten: Textklassifizierung, Sentiment-Analyse, Keyword-Extraktion (RPM 30K, TPM 1500K).
- Inhaltsmoderation: Bildprüfung, Videoüberwachung, Compliance-Checks (Reduzierung von Anomalien um 40 %).
- Echtzeit-Kundenservice: Dialoge mit hoher Parallelität, automatische FAQ-Beantwortung, intelligentes Routing.
- Unterstützung bei der Datenannotation: Batch-Annotation, Formatkonvertierung, strukturierte Ausgabe.
- Leichtgewichtige Code-Aufgaben: Code-Vervollständigung, einfache Bugfixes, Code-Reviews (SWE-Bench 67.9).
- Kosteneffiziente Szenarien: Nur $0,1 pro Million Tokens (Eingabe), ultimatives Preis-Leistungs-Verhältnis.
💡 Auswahlberatung: Welches Seed 2.0-Modell Sie wählen sollten, hängt primär von der Komplexität Ihrer Aufgabe und den Anforderungen an die Parallelität ab. Für die meisten Unternehmen empfehlen wir eine gestaffelte Strategie: „Lite als Hauptmodell + Mini als Unterstützung“. Über die APIYI-Plattform (apiyi.com) können Sie Seed 2.0 Mini bereits jetzt erleben; Pro und Lite werden unmittelbar nach ihrem Release ebenfalls unterstützt.
Seed 2.0 Modellvergleich und Entscheidungshilfe
Seed 2.0 Schichtbasierte Implementierungsstrategie
Für Unternehmen, die sowohl Qualität als auch Kosten optimieren möchten, empfiehlt sich die folgende schichtbasierte Architektur:
Entscheidungsebene (Pro) — ca. 5-10 % des Anfragevolumens:
Diese Ebene übernimmt Kernaufgaben, die höchste Qualität beim logischen Schlussfolgern erfordern, wie komplexe Analysen, strategische Entscheidungen und die Generierung hochwertiger Inhalte. Die Werte von Pro bei AIME (98,3) und Codeforces (3020) garantieren Ergebnisse auf Spitzenniveau.
Ausführungsebene (Lite) — ca. 20-30 % des Anfragevolumens:
Hier werden tägliche Aufgaben mittlerer Komplexität verarbeitet, darunter Code-Entwicklung, Dokumentenerstellung und multimodale Analysen. Die Ergebnisse von Lite bei SWE-Bench (73,5) und WideSearch (74,5) zeigen, dass es in realen Arbeitsszenarien äußerst zuverlässig ist – bei deutlich geringeren Kosten als die Pro-Version.
Durchsatzebene (Mini) — ca. 60-70 % des Anfragevolumens:
Diese Ebene ist für hochfrequente, standardisierte Batch-Aufgaben wie Klassifizierung, Inhaltsmoderation und Formatkonvertierung zuständig. Mit einer RPM von 30K und einer TPM von 1500K bietet Mini eine extrem hohe Durchsatzkapazität. Der Preis von $0,1 pro 1 Mio. Token (Input) ist dabei unschlagbar wettbewerbsfähig.
Seed 2.0 vs. Wettbewerber: Preisvergleich
| Modell | Preis Input ($/M Token) | Preis Output ($/M Token) | Positionierung |
|---|---|---|---|
| Seed 2.0 Mini | $0,10 | $0,40 | Leichtgewichtig, hoher Durchsatz |
| GPT-4.1 mini | $0,40 | $1,60 | Leichtgewichtig, universell |
| GPT-5.2 | $1,75 | $14,00 | Flaggschiff-Reasoning |
| Claude Sonnet 4.6 | $3,00 | $15,00 | Ausgewogen und effizient |
| Claude Opus 4.5 | $5,00 | $25,00 | Ultimatives Reasoning |
| Gemini 3 Pro | $1,25 | $10,00 | Multimodales Flaggschiff |
Der Input-Preis von Seed 2.0 Mini beträgt lediglich ein Viertel von GPT-4.1 mini, ebenso der Output-Preis. Im Vergleich zu GPT-5.2 sind die Input-Kosten 17,5-mal und die Output-Kosten sogar 35-mal niedriger, was Seed 2.0 einen überwältigenden Vorteil beim Preis-Leistungs-Verhältnis verschafft.
Seed 2.0 Modellvergleich: Häufig gestellte Fragen (FAQ)
Q1: Ist Seed 2.0 Mini derzeit die einzige verfügbare Version?
Ja, Stand Februar 2026 ist Seed 2.0 Mini (Modell-ID: seed-2-0-mini-260215) das erste Modell der Seed 2.0 Serie, das über die BytePlus-Plattform veröffentlicht wurde. APIYI (apiyi.com) hat als BytePlus-Partner dieses Modell sofort integriert, wobei die Preise denen der offiziellen Website entsprechen. Seed 2.0 Pro und Lite werden voraussichtlich in Kürze folgen und dann ebenfalls direkt bei APIYI verfügbar sein.
Q2: In welchen Szenarien kann Seed 2.0 Lite die Pro-Version ersetzen?
Den Benchmark-Daten zufolge kommt Lite in vielen Bereichen sehr nah an Pro heran: WideSearch (74,5 vs. 74,7), MMLU-Pro (87,7 vs. 87,0 – hier ist Lite sogar leicht besser) und SWE-Bench (73,5 vs. 76,5). Für die tägliche Entwicklung, Dokumentenverarbeitung und Informationsrecherche kann Lite die Pro-Version vollständig ersetzen und dabei signifikante Kosten sparen. Nur bei extremen Anforderungen wie hochgradig komplexem mathematischem Schlussfolgern (AIME 98,3 vs. 93,0) oder Programmierwettbewerben auf höchstem Niveau (Codeforces 3020 vs. 2233) bietet Pro einen deutlichen Vorteil.
Q3: Wie beeinflussen die 4 Reasoning-Stufen des Seed 2.0 Mini die Modellauswahl?
Seed 2.0 Mini unterstützt den Parameter reasoning_effort mit vier Stufen: minimal (kein Reasoning), low, medium und hi. Im minimal-Modus erreicht das Modell etwa 85 % der Leistung des hi-Modus, verbraucht aber nur etwa ein Zehntel der Token. Das bedeutet, dass die Kombination aus Mini + minimal ideal für Aufgaben ohne tiefes logisches Denken ist (Klassifizierung, Tagging, Formatierung), während Mini + hi bereits das Leistungsniveau der Lite-Benchmarks erreicht. Über die Plattform von APIYI (apiyi.com) lassen sich diese Modi flexibel konfigurieren, um eine präzise Kostenkontrolle zu ermöglichen.
Q4: Wie schlägt sich die Seed 2.0 Serie im Vergleich zu GPT und Claude?
Basierend auf den Benchmarks erreicht Seed 2.0 Pro in vielen Tests das Niveau von GPT-5.2 und Gemini 3 Pro und belegt in der LMSYS Arena Platz 6 (Text) bzw. Platz 3-4 (Vision). Der entscheidende Wettbewerbsvorteil von Seed 2.0 liegt jedoch im Preis: Der Input-Preis von Mini ($0,1/M Token) ist 17,5-mal günstiger als der von GPT-5.2, und selbst die Pro-Version kostet nur etwa ein Viertel (1/3,7) von GPT-5.2. Bei vergleichbarer Leistung bietet die Seed 2.0 Serie somit einen massiven Kostenvorteil.
Q5: Wie lässt sich die Seed 2.0 Mini API schnell integrieren?
Seed 2.0 Mini ist kompatibel mit dem OpenAI SDK-Standard, was den Migrationsaufwand minimal hält. Sie müssen lediglich die base_url auf https://api.apiyi.com/v1 ändern und das model auf seed-2-0-mini-260215 setzen. Die Plattform APIYI (apiyi.com) bietet eine sofort einsatzbereite, einheitliche Schnittstelle, die den Wechsel zwischen verschiedenen gängigen Modellen unterstützt. Bei einer Aufladung von 100 USD erhalten Sie zudem einen Bonus ab 10 %.
Seed 2.0 Modellvergleich: Zusammenfassung
Die Seed 2.0-Serie ist die neue Generation der Großen Sprachmodelle des Seed-Teams von ByteDance. Die drei Kernmitglieder haben jeweils eine klare Positionierung: Pro strebt nach der ultimativen Intelligenz-Obergrenze (AIME 98.3, Codeforces 3020), Lite bietet ein ausgewogenes Verhältnis zwischen Leistung und Kosten (SWE-Bench 73.5, WideSearch 74.5), und Mini konzentriert sich auf hohe Parallelität und niedrige Latenz (RPM 30K, Eingabe nur 0,1 $/M Tokens).
Aktuell ist Seed 2.0 Mini bereits als erstes Modell verfügbar. Über die Plattform APIYI (apiyi.com) ist ein schneller Zugriff möglich – zu Preisen, die denen der offiziellen BytePlus-Website entsprechen, wobei Nutzer bei Aufladungen von zusätzlichen Rabatten profitieren. Die Versionen Pro und Lite werden sukzessive veröffentlicht. Entwickler können dann nahtlos über dieselbe Plattform zwischen der gesamten Modellserie wechseln und diese vergleichen.
Referenzen
-
ByteDance Seed 2.0 Offizielle Seite: Modellvorstellung und vollständige Benchmark-Daten
- Link:
seed.bytedance.com/en/seed2 - Beschreibung: Enthält Evaluierungsvergleiche der gesamten Pro-, Lite- und Mini-Serie.
- Link:
-
Seed 2.0 Model Card Technisches Whitepaper: Detaillierte Modellarchitektur und Evaluierungsmethoden
- Link:
github.com/ByteDance-Seed/Seed2.0 - Beschreibung: Enthält Trainingsmethoden und Details zu den Evaluierungs-Datensätzen.
- Link:
-
LMSYS Chatbot Arena: Weltweit größter Blindtest für menschliche Präferenzen
- Link:
lmarena.ai - Beschreibung: Seed 2.0 Pro Preview belegt Platz #6 im Bereich Text und Platz #3-4 im Bereich Vision.
- Link:
-
Seed 2.0 Benchmarks Guide: Zusammenfassung von Drittanbieter-Bewertungen
- Link:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - Beschreibung: Enthält Quervergleiche mit GPT-5.2 und Claude Opus 4.5.
- Link:
Autor: APIYI Team | Weitere Informationen zu API-Vergleichen und Auswahlhilfen für KI-Modelle finden Sie im Technologie-Blog von APIYI unter apiyi.com.