Anmerkung des Autors: Ein tiefgehender Vergleich der im Februar 2026 veröffentlichten Open-Source-Modelle MiniMax-M2.5 und GLM-5. Wir analysieren ihre Stärken in den sechs Dimensionen Programmierung, Reasoning, Agenten, Geschwindigkeit, Preis und Architektur.
Am 11. und 12. Februar 2026 veröffentlichten zwei führende chinesische KI-Unternehmen fast zeitgleich ihre Flaggschiff-Modelle: Zhipu GLM-5 (744 Mrd. Parameter) und MiniMax-M2.5 (230 Mrd. Parameter). Beide basieren auf einer MoE-Architektur (Mixture of Experts) und stehen unter der MIT-Lizenz, setzen jedoch in ihren Fähigkeiten deutlich unterschiedliche Schwerpunkte.
Kernwert: Nach der Lektüre dieses Artikels werden Sie genau wissen, warum GLM-5 bei Reasoning und Wissenszuverlässigkeit glänzt, während MiniMax-M2.5 seine Stärken in der Programmierung und beim Tool-Calling für Agenten ausspielt. So können Sie für Ihre spezifischen Szenarien die optimale Wahl treffen.

MiniMax-M2.5 und GLM-5: Kernunterschiede im Überblick
| Vergleichsdimension | MiniMax-M2.5 | GLM-5 | Vorteil bei |
|---|---|---|---|
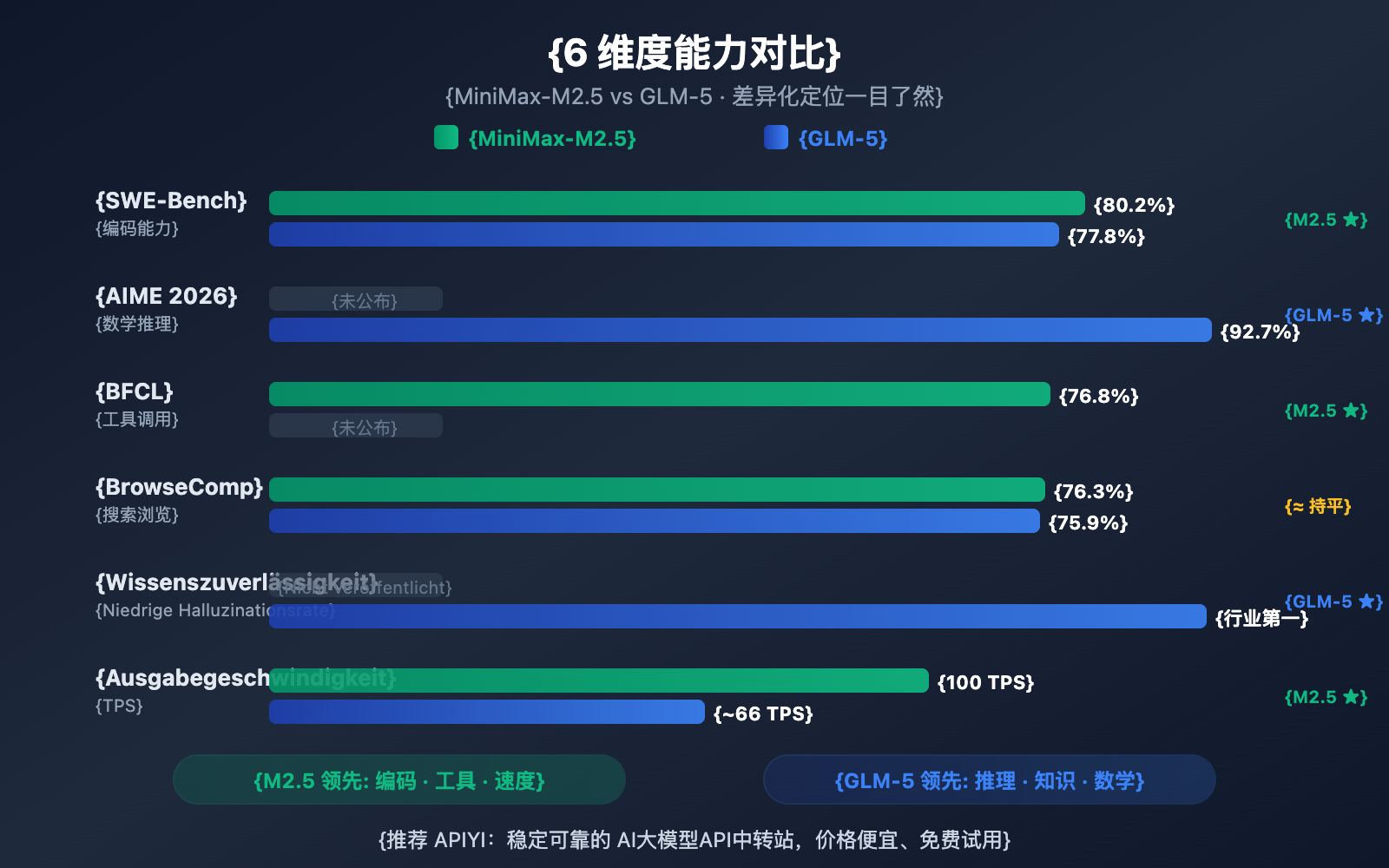
| SWE-Bench Coding | 80,2 % | 77,8 % | M2.5 führt mit 2,4 % |
| AIME Mathe-Logik | — | 92,7 % | GLM-5 spezialisiert |
| BFCL Tool-Aufrufe | 76,8 % | — | M2.5 spezialisiert |
| BrowseComp Suche | 76,3 % | 75,9 % | Nahezu gleich |
| Ausgabepreis/M Tokens | 1,20 $ | 3,20 $ | M2.5 ist 2,7-mal günstiger |
| Ausgabegeschwindigkeit | 50-100 TPS | ~66 TPS | M2.5 Lightning ist schneller |
| Gesamtparameter | 230B | 744B | GLM-5 ist größer |
| Aktive Parameter | 10B | 40B | M2.5 ist leichtgewichtiger |
Die Kernstärken von MiniMax-M2.5: Coding und Agenten
MiniMax-M2.5 sticht besonders in Coding-Benchmarks hervor. Mit einem Score von 80,2 % im SWE-Bench Verified liegt es nicht nur vor den 77,8 % von GLM-5, sondern übertrifft auch GPT-5.2 (80,0 %) und liegt nur knapp hinter Claude Opus 4.6 (80,8 %). Im Multi-SWE-Bench, der die Zusammenarbeit über mehrere Dateien hinweg testet, erreicht es 51,3 %, und bei Tool-Aufrufen im BFCL Multi-Turn erzielt es beeindruckende 76,8 %.
Dank der MoE-Architektur (Mixture of Experts) aktiviert M2.5 lediglich 10B Parameter (etwa 4,3 % der insgesamt 230B). Das macht es zur "leichtgewichtigsten" Wahl unter den Tier-1-Modellen mit einer extrem hohen Inferenz-Effizienz. Die Lightning-Version erreicht bis zu 100 TPS und gehört damit zu den derzeit schnellsten Spitzenmodellen.
Die Kernstärken von GLM-5: Logik und Wissenszuverlässigkeit
GLM-5 besitzt deutliche Vorteile bei Aufgaben, die logisches Schließen und tiefes Wissen erfordern. Im mathematischen Reasoning-Benchmark AIME 2026 erreicht es 92,7 %, beim wissenschaftlichen Schließen (GPQA-Diamond) 86,0 %. Mit 50,4 Punkten im "Humanity's Last Exam" (mit Tools) übertrifft es sogar Claude Opus 4.5 (43,4 Punkte).
Die herausragendste Fähigkeit von GLM-5 ist die Wissenszuverlässigkeit: Im AA-Omniscience Halluzinations-Benchmark erreicht es ein branchenführendes Niveau und verbessert sich gegenüber der Vorgängergeneration um 35 Punkte. Für Szenarien, die hochpräzise Faktenausgaben erfordern – wie das Verfassen technischer Dokumentationen, akademische Forschungsunterstützung oder den Aufbau von Wissensdatenbanken – ist GLM-5 die zuverlässigere Wahl. Zudem verleihen die 744B Parameter und die 28,5 Billionen Tokens an Trainingsdaten dem Modell einen tieferen Wissensschatz.
MiniMax-M2.5 vs. GLM-5: Detaillierter Vergleich der Coding-Fähigkeiten
Die Coding-Fähigkeit ist derzeit eine der wichtigsten Dimensionen für Entwickler bei der Auswahl eines KI-Modells. Zwischen den beiden Modellen gibt es hier deutliche Unterschiede.
| Coding-Benchmark | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (Referenz) |
|---|---|---|---|
| SWE-Bench Verified | 80,2 % | 77,8 % | 80,8 % |
| Multi-SWE-Bench | 51,3 % | — | 50,3 % |
| SWE-Bench Multilingual | — | 73,3 % | 77,5 % |
| Terminal-Bench 2.0 | — | 56,2 % | 65,4 % |
| BFCL Multi-Turn | 76,8 % | — | 63,3 % |
MiniMax-M2.5 liegt beim SWE-Bench Verified mit 80,2 % gegenüber 77,8 % um 2,4 Prozentpunkte vor GLM-5. Dieser Abstand gilt bei Coding-Benchmarks bereits als signifikanter Unterschied – die Programmierleistung von M2.5 bewegt sich auf dem Niveau von Opus 4.6, während GLM-5 eher dem Level von Gemini 3 Pro entspricht.
GLM-5 liefert Daten zum mehrsprachigen Coding (SWE-Bench Multilingual 73,3 %) und zum Coding in Terminal-Umgebungen (Terminal-Bench 56,2 %), was verschiedene Facetten der Coding-Kompetenz beleuchtet. Im entscheidenden SWE-Bench Verified ist der Vorsprung von M2.5 jedoch eindeutig.
Auch bei der Effizienz glänzt M2.5: Die Erledigung einer SWE-Bench-Einzelaufgabe dauert nur 22,8 Minuten, was einer Steigerung von 37 % gegenüber dem Vorgänger M2.1 entspricht. Dies ist auf seinen einzigartigen „Spec-writing“-Stil zurückzuführen – erst wird die Architektur dekonstruiert, dann erfolgt die effiziente Implementierung, wodurch unnötige Trial-and-Error-Zyklen reduziert werden.
🎯 Empfehlung für Coding-Szenarien: Wenn Ihr Hauptfokus auf KI-gestütztem Coding liegt (Bugfixing, Code-Reviews, Feature-Implementierung), ist MiniMax-M2.5 die bessere Wahl. Über APIYI apiyi.com können Sie beide Modelle gleichzeitig für praktische Vergleichstests anbinden.
MiniMax-M2.5 vs. GLM-5: Detaillierter Vergleich der Reasoning-Fähigkeiten
Die Reasoning-Fähigkeit (logisches Schlussfolgern) ist die Kernstärke von GLM-5, insbesondere in den Bereichen Mathematik und wissenschaftliches Reasoning.
| Reasoning-Benchmark | MiniMax-M2.5 | GLM-5 | Beschreibung |
|---|---|---|---|
| AIME 2026 | — | 92,7 % | Mathematisches Reasoning auf Olympia-Niveau |
| GPQA-Diamond | — | 86,0 % | Wissenschaftliches Reasoning auf Doktoranden-Niveau |
| Humanity's Last Exam (w/tools) | — | 50,4 | Übertrifft Opus 4.5 mit 43,4 |
| HMMT Nov. 2025 | — | 96,9 % | Nahe an GPT-5.2 mit 97,1 % |
| τ²-Bench | — | 89,7 % | Reasoning im Telekommunikationsbereich |
| AA-Omniscience Wissenszuverlässigkeit | — | Branchenführend | Niedrigste Halluzinationsrate |
GLM-5 nutzt eine neue Trainingsmethode namens SLIME (Asynchronous Reinforcement Learning Infrastructure), die die Post-Training-Effizienz massiv steigert. Dies hat GLM-5 bei Reasoning-Aufgaben zu einem Quantensprung verholfen:
- AIME 2026 Score von 92,7 %: Fast auf Augenhöhe mit Claude Opus 4.5 (93,3 %) und weit über dem Niveau der GLM-4.5-Ära.
- GPQA-Diamond 86,0 %: Wissenschaftliches Reasoning auf Doktoranden-Niveau, nah an den 87,0 % von Opus 4.5.
- Humanity's Last Exam 50,4 Punkte (mit Tools): Übertrifft Opus 4.5 (43,4 Punkte) und GPT-5.2 (45,5 Punkte).
Die einzigartigste Fähigkeit von GLM-5 ist die Wissenszuverlässigkeit. In der AA-Omniscience-Halluzinationsbewertung verbesserte sich GLM-5 im Vergleich zum Vorgänger um 35 Punkte und erreichte ein branchenführendes Niveau. Das bedeutet, dass GLM-5 bei der Beantwortung von Faktenfragen seltener Inhalte „erfindet“, was für Szenarien, die eine hochpräzise Informationsausgabe erfordern, von enormem Wert ist.
Zu MiniMax-M2.5 sind weniger öffentliche Daten zum reinen Reasoning verfügbar, da sich das Reinforcement-Learning-Training hier stark auf Coding- und Agenten-Szenarien konzentriert. Das Forge RL Framework von M2.5 legt den Fokus auf Aufgabenzerlegung und die Optimierung von Tool-Aufrufen in über 200.000 realen Umgebungen, statt auf rein theoretisches Reasoning.
Vergleichs-Fazit: Wenn Ihr Kernbedarf in mathematischem Reasoning, wissenschaftlicher Analyse oder hochzuverlässigen Wissensfragen liegt, hat GLM-5 Vorteile. Wir empfehlen, die Performance beider Modelle für Ihre spezifischen Reasoning-Aufgaben über die Plattform APIYI apiyi.com praktisch zu testen.
MiniMax-M2.5 vs. GLM-5: Vergleich der Agenten- & Suchfähigkeiten
| Agent-Benchmarks | MiniMax-M2.5 | GLM-5 | Vorteil bei |
|---|---|---|---|
| BFCL Multi-Turn | 76,8 % | — | M2.5 Tool-Aufrufe führend |
| BrowseComp (m. Kontext) | 76,3 % | 75,9 % | Nahezu gleichauf |
| MCP Atlas | — | 67,8 % | GLM-5 Multi-Tool-Koordination |
| Vending Bench 2 | — | $4.432 | GLM-5 Langfristige Planung |
| τ²-Bench | — | 89,7 % | GLM-5 Domänenspezifisches Schließen |
Die beiden Modelle weisen deutliche Unterschiede in ihren Agenten-Fähigkeiten auf:
MiniMax-M2.5 glänzt als "ausführender" Agent: Er zeigt hervorragende Leistungen in Szenarien, die häufige Tool-Aufrufe, schnelle Iterationen und eine effiziente Ausführung erfordern. Ein Wert von 76,8 % im BFCL bedeutet, dass M2.5 Tool-Nutzungen wie Funktionsaufrufe, Dateioperationen und API-Interaktionen präzise durchführen kann, wobei die Anzahl der Tool-Aufrufrunden im Vergleich zur Vorgängergeneration um 20 % reduziert wurde. Innerhalb von MiniMax werden bereits 80 % des neuen Codes von M2.5 generiert und 30 % der täglichen Aufgaben durch das Modell erledigt.
GLM-5 glänzt als "entscheidungsbasierter" Agent: Er hat Vorteile in Szenarien, die tiefgehendes logisches Schließen, langfristige Planung und komplexe Entscheidungsfindungen erfordern. 67,8 % im MCP Atlas demonstrieren die Fähigkeit zur Koordination umfangreicher Tools. Der simulierte Umsatz von 4.432 $ im Vending Bench 2 zeigt die Fähigkeit zur langfristigen Geschäftsplanung, während 89,7 % im τ²-Bench tiefgehendes domänenspezifisches Schließen belegen.
In Bezug auf die Web-Such- und Browsing-Fähigkeiten liegen beide fast gleichauf – BrowseComp 76,3 % vs. 75,9 % – und sind beide führend in diesem Bereich.
🎯 Empfehlung für Agenten-Szenarien: Wählen Sie M2.5 für hochfrequente Tool-Aufrufe und automatisierte Codierung; wählen Sie GLM-5 für komplexe Entscheidungen und langfristige Planung. Die Plattform APIYI (apiyi.com) unterstützt beide Modelle gleichzeitig, sodass Sie je nach Szenario flexibel wechseln können.
MiniMax-M2.5 im Vergleich zu GLM-5: Architektur und Kosten
| Architektur & Kosten | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| Gesamtparameter | 230B | 744B |
| Aktivierte Parameter | 10B | 40B |
| Aktivierungsrate | 4,3 % | 5,4 % |
| Trainingsdaten | — | 28,5 Billionen Token |
| Kontextfenster | 205K | 200K |
| Maximale Ausgabe | — | 131K |
| Eingabepreis | $0,15/M (Standard) | $1,00/M |
| Ausgabepreis | $1,20/M (Standard) | $3,20/M |
| Ausgabegeschwindigkeit | 50-100 TPS | ~66 TPS |
| Trainings-Chips | — | Huawei Ascend 910 |
| Trainings-Framework | Forge RL | SLIME asynchrones RL |
| Attention-Mechanismus | — | DeepSeek Sparse Attention |
| Open-Source-Lizenz | MIT | MIT |
Architekturanalyse der Vorteile von MiniMax-M2.5
Der zentrale Vorteil der M2.5-Architektur liegt in ihrer „extremen Leichtigkeit“ – mit nur 10B aktivierten Parametern erreicht das Modell Coding-Fähigkeiten, die fast an Opus 4.6 heranreichen. Dies führt zu:
- Extrem niedrigen Inferenzkosten: Der Ausgabepreis von $1,20/M entspricht nur 37 % der Kosten von GLM-5.
- Extrem hoher Inferenzgeschwindigkeit: Die Lightning-Version erreicht 100 TPS und ist damit 52 % schneller als die ~66 TPS von GLM-5.
- Niedrigeren Hürden für das Deployment: 10B aktivierte Parameter ermöglichen potenziell den Einsatz auf Consumer-GPUs.
Architekturanalyse der Vorteile von GLM-5
Mit 744B Gesamtparametern und 40B aktivierten Parametern bietet GLM-5 eine größere Wissenskapazität und eine höhere Reasoning-Tiefe:
- Größeres Wissensreservoir: 28,5 Billionen Token an Trainingsdaten übertreffen die Vorgängergeneration bei Weitem.
- Stärkere Reasoning-Fähigkeiten: 40B aktivierte Parameter unterstützen komplexere logische Schlussfolgerungsketten.
- Unabhängigkeit durch heimische Rechenleistung: Das Training erfolgte vollständig auf Huawei Ascend-Chips, was technologische Souveränität demonstriert.
- DeepSeek Sparse Attention: Effiziente Verarbeitung von langen Kontexten bis zu 200K.
Empfehlung: Für kostensensible Szenarien mit hoher Aufruffrequenz bietet M2.5 einen deutlichen Preisvorteil (der Ausgabepreis beträgt nur 37 % von GLM-5). Es wird empfohlen, das Preis-Leistungs-Verhältnis beider Modelle für Ihre spezifischen Aufgaben über die Plattform APIYI (apiyi.com) zu testen.
MiniMax-M2.5 vs. GLM-5: Schnelle API-Integration
Über die APIYI-Plattform können beide Modelle über eine einheitliche Schnittstelle aufgerufen werden, was einen schnellen Vergleich ermöglicht:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 编码任务测试 - M2.5 更擅长
code_task = "用 Rust 实现一个无锁并发队列"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# 推理任务测试 - GLM-5 更擅长
reason_task = "证明所有大于 2 的偶数都可以表示为两个素数之和(哥德巴赫猜想的验证思路)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
Empfehlung: Holen Sie sich kostenloses Testguthaben auf APIYI (apiyi.com), um beide Modelle in Ihrem spezifischen Szenario zu testen. Probieren Sie M2.5 für Coding-Aufgaben und GLM-5 für komplexe Reasoning-Aufgaben aus, um die für Sie optimal passende Lösung zu finden.
Häufig gestellte Fragen
Q1: Worin liegen die jeweiligen Stärken von MiniMax-M2.5 und GLM-5?
MiniMax-M2.5 glänzt beim Coding und bei Tool-Aufrufen für Agenten – mit 80,2 % im SWE-Bench liegt es nah an Opus 4.6, und mit 76,8 % im BFCL ist es Branchenführer. GLM-5 ist spezialisiert auf Reasoning und Wissenszuverlässigkeit – AIME 92,7 %, GPQA 86,0 % und die niedrigste Halluzinationsrate der Branche. Kurz gesagt: Für die Programmierung wählen Sie M2.5, für logisches Denken (Reasoning) GLM-5.
Q2: Wie hoch ist der Preisunterschied zwischen den beiden Modellen?
Die Standardversion von MiniMax-M2.5 kostet im Output $1,20/M Tokens, während GLM-5 bei $3,20/M Tokens liegt. Damit ist M2.5 etwa 2,7-mal günstiger. Wenn Sie die Hochgeschwindigkeitsversion M2.5 Lightning ($2,40/M) wählen, liegt der Preis näher an GLM-5, bietet aber eine höhere Geschwindigkeit. Über die Plattform APIYI (apiyi.com) erhalten Sie zudem attraktive Rabatte auf Ihr Guthaben.
Q3: Wie lassen sich die praktischen Ergebnisse beider Modelle schnell vergleichen?
Wir empfehlen den zentralen Zugriff über die Plattform APIYI (apiyi.com):
- Account registrieren, API-Key erhalten und Gratis-Guthaben nutzen.
- Zwei Arten von Testaufgaben vorbereiten: Coding und Reasoning.
- Dieselbe Aufgabe jeweils mit MiniMax-M2.5 und GLM-5 aufrufen.
- Ausgabequalität, Antwortgeschwindigkeit und Token-Verbrauch vergleichen.
- Dank der OpenAI-kompatiblen Schnittstelle müssen Sie zum Modellwechsel lediglich den
model-Parameter anpassen.
Fazit
Hier sind die Kernpunkte des Vergleichs zwischen MiniMax-M2.5 und GLM-5:
- Coding-Favorit M2.5: Mit 80,2 % im SWE-Bench gegenüber 77,8 % liegt M2.5 vorn. Bei Tool-Aufrufen (BFCL) ist es mit 76,8 % Branchenführer.
- Reasoning-Favorit GLM-5: Mit Werten wie AIME 92,7 %, GPQA 86,0 % und 50,4 Punkten im "Humanity's Last Exam" übertrifft es sogar Opus 4.5.
- Führend bei Wissenszuverlässigkeit: GLM-5 belegt im AA-Omniscience Halluzinations-Ranking den ersten Platz; faktische Ausgaben sind hier vertrauenswürdiger.
- Besseres Preis-Leistungs-Verhältnis bei M2.5: Der Output-Preis beträgt nur 37 % von GLM-5, zudem bietet die Lightning-Version eine höhere Geschwindigkeit.
Beide Modelle basieren auf der MoE-Architektur und sind unter der MIT-Lizenz Open Source, verfolgen jedoch unterschiedliche Schwerpunkte: M2.5 ist der „König der Coding- und Ausführungs-Agenten“, während GLM-5 als „Pionier für Reasoning und Wissenszuverlässigkeit“ gilt. Wir empfehlen, je nach Bedarf flexibel über die Plattform APIYI (apiyi.com) zwischen den Modellen zu wechseln und von den günstigen Konditionen der Auflade-Aktionen zu profitieren.
📚 Referenzen
-
MiniMax M2.5 Offizielle Ankündigung: M2.5 Kern-Coding-Fähigkeiten und Forge RL Trainingsdetails
- Link:
minimax.io/news/minimax-m25 - Beschreibung: Vollständige Benchmark-Daten wie SWE-Bench 80,2 %, BFCL 76,8 % usw.
- Link:
-
GLM-5 Offizielle Veröffentlichung: Zhipu GLM-5's 744B MoE Architektur und SLIME Trainingstechnologie
- Link:
docs.z.ai/guides/llm/glm-5 - Beschreibung: Enthält Reasoning-Benchmarks wie AIME 92,7 %, GPQA 86,0 % usw.
- Link:
-
Artificial Analysis Unabhängige Bewertung: Standardisierte Benchmarks und Rankings für beide Modelle
- Link:
artificialanalysis.ai/models/glm-5 - Beschreibung: Intelligence Index, Geschwindigkeitstests, Preisvergleich und weitere unabhängige Daten.
- Link:
-
BuildFastWithAI Tiefenanalyse: Umfassende GLM-5 Benchmarks und Wettbewerbsvergleich
- Link:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - Beschreibung: Detaillierte Vergleichstabelle mit Opus 4.5 und GPT-5.2.
- Link:
-
MiniMax HuggingFace: M2.5 Open-Source-Modellgewichte
- Link:
huggingface.co/MiniMaxAI - Beschreibung: MIT-Lizenz, unterstützt vLLM/SGLang Deployment.
- Link:
Autor: APIYI Team
Technischer Austausch: Teilen Sie gerne Ihre Testergebnisse zum Modellvergleich im Kommentarbereich. Weitere Tutorials zur Integration von KI-Modell-APIs finden Sie in der APIYI apiyi.com Technik-Community.