Dass Nano Banana Pro Bilder langsam generiert, ist ein häufiges Feedback von Entwicklern. Kunden fragen oft: „Warum dauert die Generierung manchmal 20 Sekunden und manchmal über 50? Ist das Zufall?“ – Die Antwort lautet: Die Bildgenerierungszeit wird durch drei Hauptfaktoren bestimmt: Auflösung, Thinking Level (Denkstufe) und Netzwerkübertragung. In diesem Artikel stellen wir 6 praxiserprobte Optimierungstipps vor, mit denen Sie die 2K-Bildgenerierung von Nano Banana Pro stabil unter 50 Sekunden halten.
Kernwert: Nach der Lektüre beherrschen Sie die komplette Methodik zur Geschwindigkeitsoptimierung für Nano Banana Pro und können die Parameter je nach Geschäftsszenario flexibel anpassen, um die beste Balance zwischen Qualität und Geschwindigkeit zu finden.

Kernfaktoren für die Bildgeschwindigkeit von Nano Banana Pro
Bevor wir optimieren, müssen wir verstehen, was die Generierungsgeschwindigkeit von Nano Banana Pro maßgeblich beeinflusst. Basierend auf Testdaten lässt sich die Gesamtzeit in drei Phasen unterteilen:
| Phase | Zeitanteil | Haupteinflussfaktoren | Optimierungspotenzial |
|---|---|---|---|
| API-Verarbeitung | 60-70% | Auflösung, Thinking Level, Modelllast | Hoch |
| Bildübertragung/-download | 20-30% | Bandbreite, Base64-Datenmenge, Standort | Mittel |
| Verbindungsaufbau | 5-10% | Verbindungswiederverwendung, TLS-Handshake | Mittel |
Messdaten zur Bildgenerierungszeit von Nano Banana Pro
Basierend auf den Geschwindigkeitsdaten der APIYI-Plattform (imagen.apiyi.com):
| Auflösung | Thinking Level | Durchschn. Zeit | P95-Zeit | Empfohlenes Szenario |
|---|---|---|---|---|
| 1K | low | 15-20s | 25s | Vorschau, Batch-Generierung |
| 2K | low | 30-40s | 50s | Standard-Produktion, Web-Anzeige |
| 2K | high | 45-60s | 75s | Komplexe Komposition, feiner Text |
| 4K | low | 50-70s | 90s | Druck, High-End Design |
| 4K | high | 80-120s | 150s | Professioneller Output |
🎯 Fazit: Die Kombination aus 2K-Auflösung + Low Thinking Level bietet das beste Preis-Leistungs-Verhältnis. Damit lassen sich 2K-Bilder absolut stabil in unter 50 Sekunden generieren. Wenn Ihr Business-Szenario kein 4K erfordert, ist 2K die dringende Empfehlung.

Nano Banana Pro Geschwindigkeits-Optimierungstipp 1: Wahl der richtigen Auflösung
Die Auflösung ist der direkteste Faktor, der die Generierungsgeschwindigkeit von Nano Banana Pro beeinflusst. Aus technischer Sicht gilt:
- 4K-Bilder (4096×4096): ca. 16 Millionen Pixel, benötigt etwa 2000 Output-Token
- 2K-Bilder (2048×2048): ca. 4 Millionen Pixel, benötigt etwa 1120 Output-Token
- 1K-Bilder (1024×1024): ca. 1 Million Pixel, benötigt etwa 560 Output-Token
Nano Banana Pro: Vergleichstabelle Auflösung vs. Geschwindigkeit
| Auflösung | Pixelanzahl | Token-Verbrauch | Relative Geschwindigkeit | Anwendungsbereiche |
|---|---|---|---|---|
| 1K | 1M | ~560 | Basis (1x) | Vorschau, schnelle Iteration |
| 2K | 4M | ~1120 | ca. 1,8x | Reguläre Produktion |
| 4K | 16M | ~2000 | ca. 3,5x | Druckqualität |
Empfehlungen zur Auflösungswahl
# Beispiel zur Auflösungswahl für Nano Banana Pro
def choose_resolution(use_case: str) -> str:
"""Wählt die optimale Auflösung basierend auf dem Anwendungsfall"""
resolution_map = {
"preview": "1024x1024", # Schnelle Vorschau, am schnellsten
"web_display": "2048x2048", # Web-Darstellung, ausgewogen
"social_media": "2048x2048", # Social Media, 2K ist ausreichend
"print_design": "4096x4096", # Printdesign, 4K erforderlich
"batch_process": "1024x1024" # Stapelverarbeitung, Geschwindigkeit hat Priorität
}
return resolution_map.get(use_case, "2048x2048")
💡 Optimierungstipp: Für die meisten Web-Anwendungen ist eine 2K-Auflösung völlig ausreichend. Nur für den Druck oder extrem große Displays wird 4K benötigt. Die Wahl von 2K spart etwa 45 % der Generierungszeit bei identischem Preis ($0,134/Bild offizieller Preis, $0,05/Bild auf der APIYI-Plattform).
Nano Banana Pro Geschwindigkeits-Optimierungstipp 2: Anpassung der Thinking-Level-Parameter
Nano Banana Pro verfügt über einen integrierten „Thinking“-Mechanismus (Denkprozess), der auf einem Großem Sprachmodell (Gemini 3 Pro) basiert. Bei einfachen Eingabeaufforderungen kann dieser Reasoning-Prozess unnötige Verzögerungen verursachen.
Nano Banana Pro: Details zum Parameter thinking_level
| Thinking-Level | Reasoning-Tiefe | Zusätzliche Zeit | Anwendungsbereiche |
|---|---|---|---|
| low | Basis-Reasoning | +0s | Einfache Prompts, klare Anweisungen |
| medium | Standard-Reasoning | +5-10s | Reguläre kreative Generierung |
| high | Tiefgreifendes Reasoning | +15-25s | Komplexe Kompositionen, präzises Text-Rendering |
Code-Beispiel: Thinking-Level festlegen
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Nutzt die vereinheitlichte APIYI-Schnittstelle
)
# Einfaches Szenario: Thinking-Level „low“ verwenden
response = client.images.generate(
model="nano-banana-pro",
prompt="Eine orangefarbene Katze sitzt auf dem Fensterbrett",
size="2048x2048",
extra_body={
"thinking_level": "low" # Einfacher Prompt, niedriges Thinking-Level
}
)
# Komplexes Szenario: Thinking-Level „high“ verwenden
response = client.images.generate(
model="nano-banana-pro",
prompt="Eine professionelle Produkt-Infografik mit dem Titel 'Neuerscheinung 2025', drei Produktmerkmalen, Preisschild $99,99, in technischem Blau-Farbschema",
size="2048x2048",
extra_body={
"thinking_level": "high" # Komplexes Text-Rendering, erfordert hohes Thinking-Level
}
)
🚀 Praxis-Tipp: Für einfache Szenarien wie „eine Katze“ oder „ein Wald“ spart das Setzen des
thinking_levelauflowetwa 20-30 % der Generierungszeit. Die Einstellunghighist nur bei präzisem Text-Rendering oder komplexen räumlichen Beziehungen erforderlich.
Nano Banana Pro Optimierungstipps zur Geschwindigkeit Teil 3: Optimierung der Netzwerkübertragung
Viele Entwickler ignorieren eine einfache Tatsache: Eine schnelle Antwortzeit der API-Schnittstelle bedeutet nicht zwangsläufig eine kurze Gesamtdauer. Reale Daten zeigen, dass die Netzwerkübertragung etwa 20–30 % der gesamten Zeit in Anspruch nehmen kann.
Analyse der Netzwerkverzögerung bei Nano Banana Pro
Am Beispiel eines 2K-Bildes (ein base64-kodiertes 2K-PNG-Bild ist ca. 4–6 MB groß):
| Phase | Datenmenge | 10 Mbps Bandbreite | 100 Mbps Bandbreite | 1 Gbps Bandbreite |
|---|---|---|---|---|
| Request-Upload | ~1 KB | < 0,1 s | < 0,1 s | < 0,1 s |
| Response-Download | ~5 MB | 4 s | 0,4 s | 0,04 s |
| TLS-Handshake | – | 0,1–0,3 s | 0,1–0,3 s | 0,1–0,3 s |
Praxis der Netzwerkoptimierung
import httpx
import time
# Optimierung 1: Verbindungs-Wiederverwendung aktivieren (Keep-Alive)
# Ein Team konnte durch die Aktivierung von Keep-Alive die P95-Latenz von 3,5 s auf 0,9 s senken.
client = httpx.Client(
base_url="https://api.apiyi.com/v1",
http2=True, # HTTP/2 aktivieren
timeout=60.0,
limits=httpx.Limits(
max_keepalive_connections=10, # Verbindungs-Pool aufrechterhalten
keepalive_expiry=30.0 # Lebensdauer der Verbindung
)
)
# Optimierung 2: Detaillierte Zeitprotokolle hinzufügen
def generate_with_timing(prompt: str, size: str = "2048x2048"):
"""Bildgenerierung mit Zeitstatistik"""
timings = {}
start = time.time()
# Anfrage senden
response = client.post(
"/images/generations",
json={
"model": "nano-banana-pro",
"prompt": prompt,
"size": size,
"response_format": "b64_json"
},
headers={"Authorization": f"Bearer {api_key}"}
)
timings["api_total"] = time.time() - start
# Antwort parsen
parse_start = time.time()
result = response.json()
timings["parse_time"] = time.time() - parse_start
print(f"API-Zeit: {timings['api_total']:.2f}s")
print(f"Parsing-Zeit: {timings['parse_time']:.2f}s")
return result
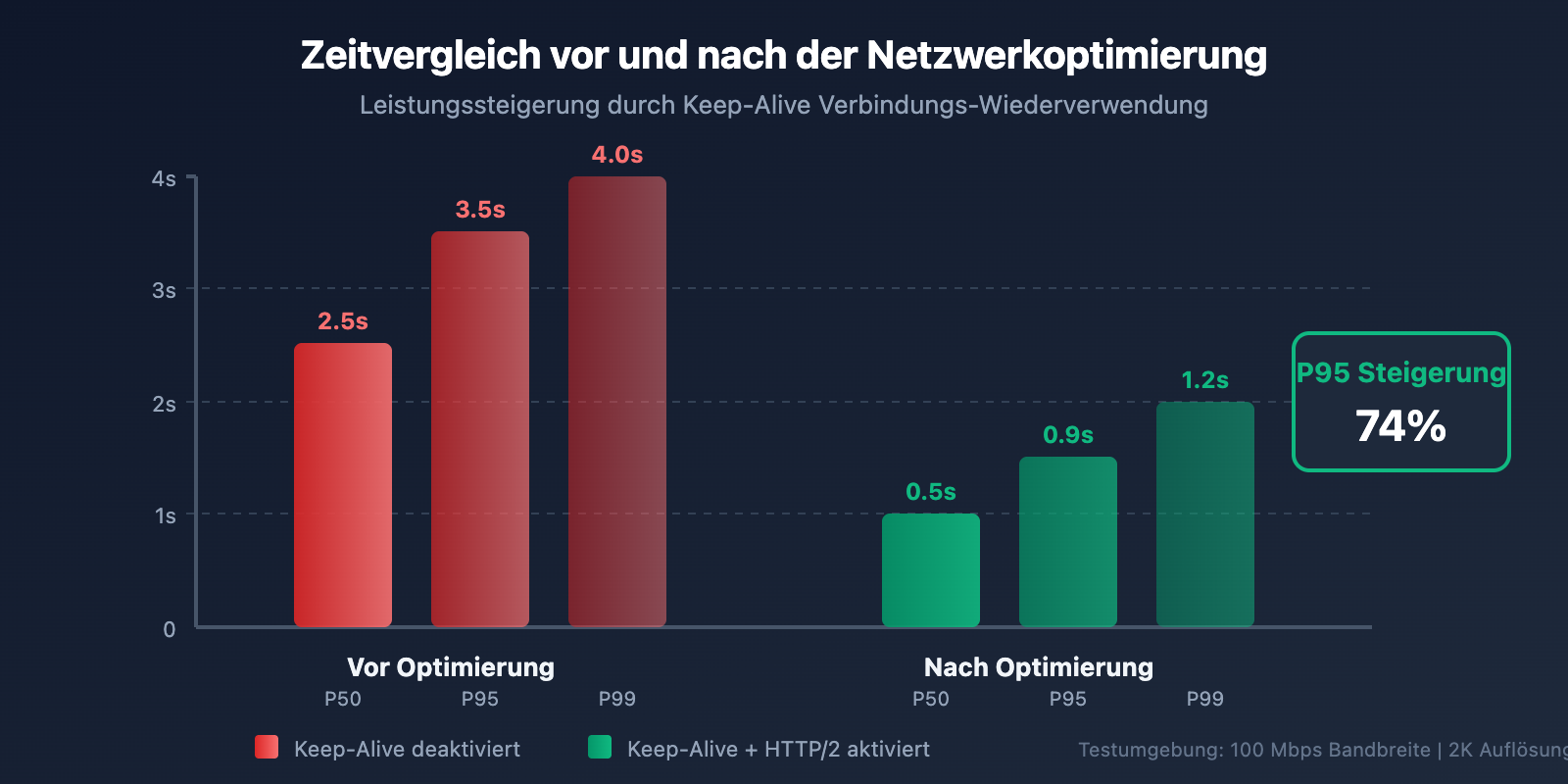
📊 Reale Testdaten: Geschwindigkeitsmessungen auf der APIYI-Plattform (imagen.apiyi.com) zeigen, dass für Nutzer, die über optimierte Knoten zugreifen, die API-Antwortzeit für ein 2K-Bild etwa 20–30 Sekunden beträgt. Zusammen mit der Downloadzeit kann die Gesamtdauer stabil unter 50 Sekunden gehalten werden.
Nano Banana Pro Speed-Optimierungstipp 4: Batch-Erzeugung mittels Grid-Generierung
Wenn Sie schnell kreative Richtungen erkunden oder mehrere Varianten erstellen möchten, ist die Grid-Generierung ein unterschätzter Beschleunigungs-Trick.
Grid-Generierung vs. Einzelbild-Generierung im Vergleich
| Erzeugungsmethode | Zeitaufwand für 4 Bilder | Kosten pro Bild | Anwendungsfall |
|---|---|---|---|
| Einzelbild × 4 | 4 × 30s = 120s | $0.05 | Unabhängige Kontrolle für jedes Bild erforderlich |
| 2×2 Grid | ca. 40s | ~$0.034 | Schnelle Exploration, kreative Iteration |
Code-Beispiel für Grid-Generierung
# Schnelle Erzeugung mehrerer Varianten mittels Grid-Generierung
response = client.images.generate(
model="nano-banana-pro",
prompt="Wohnzimmerdesign im modernen, minimalistischen Stil",
size="2048x2048",
extra_body={
"grid": "2x2", # Erzeugt ein 2x2-Grid
"thinking_level": "low" # Niedriges Thinking-Level für die Explorationsphase
}
)
# In ca. 40 Sekunden entstehen 4 verschiedene Varianten, ca. $0.034 pro Bild
🎯 Empfehlung: Nutzen Sie in der kreativen Explorationsphase die Grid-Generierung für schnelle Iterationen. Sobald die Richtung feststeht, wechseln Sie zur qualitativ hochwertigen Einzelbild-Generierung. Bei Aufrufen über die Plattform APIYI (apiyi.com) wird die Grid-Generierung ebenfalls unterstützt und bietet flexiblere Abrechnungsmodelle.
Nano Banana Pro Speed-Optimierungstipp 5: Sinnvolle Timeouts und Retries setzen
In Produktionsumgebungen verhindern angemessene Timeout- und Retry-Strategien (Wiederholungsversuche) Anfragenfehler durch gelegentliche Latenzspitzen.
Empfohlene Timeout-Konfiguration
| Auflösung | Empfohlener Timeout | Anzahl Retries | Retry-Intervall |
|---|---|---|---|
| 1K | 45s | 2 | 5s |
| 2K | 90s | 2 | 10s |
| 4K | 180s | 3 | 15s |
Code-Beispiel für die Produktion
import openai
from tenacity import retry, stop_after_attempt, wait_exponential
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1", # Einheitliche APIYI-Schnittstelle
timeout=90.0 # Empfohlener 90-Sekunden-Timeout für 2K-Bilder
)
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=5, max=30)
)
def generate_image_with_retry(prompt: str, size: str = "2048x2048"):
"""Bildgenerierung mit Exponential Backoff Retry"""
return client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=size,
extra_body={"thinking_level": "low"}
)
# Anwendung
try:
result = generate_image_with_retry("Ein goldenes Weizenfeld bei Sonnenuntergang")
print("Generierung erfolgreich!")
except Exception as e:
print(f"Generierung fehlgeschlagen: {e}")
Nano Banana Pro Geschwindigkeitstipps 6: Auswahl des richtigen API-Anbieters
Die Infrastrukturunterschiede zwischen verschiedenen API-Anbietern wirken sich direkt auf die Reaktionsgeschwindigkeit aus.
Vergleich der Nano Banana Pro API-Anbieter
| Anbieter | Zugriffslatenz (China) | 2K-Generierungsgeschwindigkeit | Einzelpreis | Merkmale |
|---|---|---|---|---|
| Google Offiziell | 3-8s zusätzliche Latenz | 30-50s | $0.134 | Erfordert ausländische Kreditkarte |
| APIYI | Optimierte Knoten | 30-40s | $0.05 | Unterstützt Alipay/WeChat |
| Andere Relay-Dienste | Instabil | 40-60s | $0.08-0.15 | Schwankende Qualität |
💰 Kostenoptimierung: Durch den Aufruf von Nano Banana Pro über APIYI (apiyi.com) beträgt der Einzelpreis nur $0.05 pro Bild. Im Vergleich zum offiziellen Preis von $0.134 sparen Sie etwa 63 %. Gleichzeitig ist die Zugriffslatenz aus China geringer, was die Gesamterfahrung verbessert. Für Großkunden gibt es zusätzliche Boni bei Aufladungen, wodurch der Preis auf bis zu $0.04 pro Bild sinken kann.
Vollständiges Beispiel für die Konfigurationsoptimierung
Klicken Sie hier, um den vollständigen Code anzuzeigen
"""
Vollständiges Beispiel zur Geschwindigkeitsoptimierung für Nano Banana Pro
Aufruf über die APIYI-Plattform unter Integration aller Optimierungstechniken
"""
import openai
import time
import base64
from pathlib import Path
from tenacity import retry, stop_after_attempt, wait_exponential
class NanoBananaProClient:
"""Optimierter Nano Banana Pro Client"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1", # Einheitliche APIYI-Schnittstelle
timeout=90.0,
max_retries=0 # Eigene Retry-Logik verwenden
)
def choose_params(self, use_case: str, quality: str = "balanced"):
"""Intelligente Parameterwahl basierend auf dem Szenario"""
configs = {
"preview": {
"size": "1024x1024",
"thinking_level": "low"
},
"production": {
"size": "2048x2048",
"thinking_level": "low" if quality == "fast" else "medium"
},
"premium": {
"size": "4096x4096",
"thinking_level": "high"
}
}
return configs.get(use_case, configs["production"])
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=5, max=30)
)
def generate(
self,
prompt: str,
use_case: str = "production",
quality: str = "balanced"
) -> dict:
"""Bildgenerierung mit automatischer Parameteroptimierung"""
params = self.choose_params(use_case, quality)
start_time = time.time()
response = self.client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=params["size"],
response_format="b64_json",
extra_body={
"thinking_level": params["thinking_level"]
}
)
elapsed = time.time() - start_time
return {
"image_data": response.data[0].b64_json,
"elapsed_seconds": elapsed,
"size": params["size"],
"thinking_level": params["thinking_level"]
}
def generate_batch(
self,
prompts: list[str],
use_case: str = "preview"
) -> list[dict]:
"""Batch-Generierung, nutzt automatisch niedrige Konfigurationen zur Beschleunigung"""
results = []
for prompt in prompts:
result = self.generate(prompt, use_case=use_case, quality="fast")
results.append(result)
return results
def save_image(self, b64_data: str, output_path: str):
"""Speichert base64-Bilddaten in eine Datei"""
image_bytes = base64.b64decode(b64_data)
Path(output_path).write_bytes(image_bytes)
# Anwendungsbeispiel
if __name__ == "__main__":
client = NanoBananaProClient(api_key="your-api-key")
# Szenario 1: Schnelle Vorschau
preview = client.generate(
prompt="Eine orangefarbene Katze",
use_case="preview"
)
print(f"Zeitaufwand Vorschau: {preview['elapsed_seconds']:.2f}s")
# Szenario 2: Produktionsumgebung
production = client.generate(
prompt="Professionelles E-Commerce-Produktfoto, weißer Hintergrund, 45-Grad-Winkel",
use_case="production"
)
print(f"Zeitaufwand Produktion: {production['elapsed_seconds']:.2f}s")
# Szenario 3: High-End-Design
premium = client.generate(
prompt="4K Ultra-HD, modernes minimalistisches Wohnzimmer, große bodentiefe Fenster, Sonnenlicht",
use_case="premium"
)
print(f"Zeitaufwand Premium: {premium['elapsed_seconds']:.2f}s")
Nano Banana Pro Geschwindigkeit: Häufig gestellte Fragen (FAQ)
F1: Warum variiert die Generierungszeit bei gleicher Eingabeaufforderung?
Die Generierungszeit von Nano Banana Pro wird von mehreren Faktoren beeinflusst:
- Lastschwankungen des Modells: Zu Stoßzeiten (z. B. während der US-Arbeitszeit) ist die Serverlast höher, was die Antwortzeit um 10-30 % erhöhen kann.
- Komplexität der Eingabeaufforderung: Selbst bei ähnlichen Prompts können die internen Inferenzpfade des Modells variieren.
- Netzwerkbedingungen: Grenzüberschreitende Datenübertragungen unterliegen Schwankungen.
Optimierungsvorschlag: Nutzen Sie die APIYI-Plattform (apiyi.com). Deren optimierte Knoten können Netzwerkprobleme teilweise mildern. Zudem empfiehlt es sich, Stoßzeiten zu vermeiden (meiden Sie die US-Hauptzeiten, ca. 21:00-02:00 Uhr Pekinger Zeit).
F2: 2K und 4K kosten das Gleiche. Warum nicht direkt 4K verwenden?
Gleicher Preis bedeutet nicht gleiche Effizienz:
| Dimension | 2K | 4K | Differenz |
|---|---|---|---|
| Generierungszeit | 30-40s | 50-70s | 4K ist ca. 60 % langsamer |
| Datenübertragung | ~3MB | ~10MB | 4K hat ein größeres Datenvolumen |
| Speicherkosten | Basis | ca. 3,3x | Hohe langfristige Speicherkosten |
Fazit: Sofern Ihr Business nicht ausdrücklich 4K erfordert (z. B. für Druckerzeugnisse oder riesige Displays), ist 2K die klügere Wahl. Bei Batch-Aufrufen über die APIYI-Plattform wird der Effizienzvorteil von 2K noch deutlicher.
F3: Wie stelle ich fest, ob der Engpass bei der API oder beim Netzwerk liegt?
Detaillierte Zeitprotokolle (Logs) sind der Schlüssel zur Diagnose:
import time
# Zeit bei Anfragebeginn
t1 = time.time()
response = client.images.generate(...)
t2 = time.time()
# Zeit der Datenverarbeitung
data = response.data[0].b64_json
t3 = time.time()
print(f"API-Antwortzeit: {t2-t1:.2f}s")
print(f"Datenverarbeitungszeit: {t3-t2:.2f}s")
Wenn die API schnell antwortet, die Gesamtzeit aber hoch ist, liegt der Engpass bei der Netzwerkübertragung. Sie können die Performance auf der API-Seite mit dem Online-Geschwindigkeitstest-Tool unter imagen.apiyi.com überprüfen.
F4: Wie maximiere ich den Durchsatz bei der Batch-Generierung?
Strategien zur Optimierung der Batch-Generierung:
- Parallele Anfragen: Stellen Sie die Anzahl der gleichzeitigen Anfragen passend zu den API-Rate-Limits ein (üblicherweise 5-10 gleichzeitig).
- Grid-Generierung: Ein 2×2-Raster erzeugt 4 Bilder auf einmal und steigert die Effizienz um das Dreifache.
- Konfiguration senken: Nutzen Sie für Batches bevorzugt 1K + "low thinking".
- Asynchrone Verarbeitung: Verwenden Sie
asynciooder Thread-Pools für die parallele Abarbeitung.
Bei der Nutzung von APIYI profitieren Sie von höheren Limits für gleichzeitige Anfragen, was ideal für große Batch-Aufträge ist.
Nano Banana Pro: Zusammenfassung der Geschwindigkeitsoptimierung

In diesem Artikel stellen wir 6 Techniken zur Optimierung der Bildgenerierungsgeschwindigkeit mit Nano Banana Pro vor:
| Technik | Optimierungseffekt | Schwierigkeit | Priorität |
|---|---|---|---|
| 2K-Auflösung wählen | 45% Zeitersparnis | Niedrig | ⭐⭐⭐⭐⭐ |
| Thinking-Level anpassen | 20-30% Ersparnis | Niedrig | ⭐⭐⭐⭐⭐ |
| Netzwerk-Optimierung | 10-20% Ersparnis | Mittel | ⭐⭐⭐⭐ |
| Batch-Generierung (Grid) | 3x Effizienzsteigerung | Niedrig | ⭐⭐⭐⭐ |
| Timeout- & Retry-Strategie | Stabilität verbessern | Mittel | ⭐⭐⭐ |
| Premium-Anbieter wählen | Gesamtverbesserung | Niedrig | ⭐⭐⭐⭐⭐ |
Fazit: Mit der Kombination aus 2K-Auflösung, "low" Thinking-Level und Connection Reuse lässt sich eine Generierungszeit von stabil unter 50 Sekunden pro 2K-Bild zuverlässig erreichen.
🎯 Abschließende Empfehlung: Wir empfehlen die Nutzung von APIYI (apiyi.com), um diese Optimierungseffekte direkt zu testen. Die Plattform bietet mit imagen.apiyi.com ein Online-Tool zur Geschwindigkeitsmessung, mit dem sich die Latenz der einzelnen Schritte überwachen lässt. Zudem helfen die Preise von $0,05 pro Bild (nur 37% der offiziellen $0,134), die Testkosten effizient zu kontrollieren.
Dieser Artikel wurde vom APIYI-Entwicklerteam verfasst. Für weitere Tipps zur Nutzung von KI-Bildgenerierungs-APIs besuchen Sie apiyi.com für technischen Support.