في نهاية أبريل 2026، أطلقت شركتا xAI وOpenAI في وقت متزامن تقريباً نموذجين رائدين في الاستدلال (Reasoning): Grok 4.3 وGPT-5.5. نجح الأول في خفض تكلفة نماذج الاستدلال إلى 1.25 دولار/2.50 دولار، بينما دفع الثاني قدرات البرمجة الوكيلة (Agentic coding) إلى 82.7% في اختبار Terminal-Bench، مع تقارب مساري المنتجين عند نافذة سياق تبلغ 1 مليون رمز (tokens). يقدم هذا المقال مقارنة منهجية عبر 7 أبعاد: السعر، الأداء، نافذة السياق، تعدد الوسائط، البرمجة، النظام البيئي، وسيناريوهات التكلفة، مع توفير توصيات عملية لاختيار النموذج الأنسب.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتمكن من تحديد ما إذا كان يجب عليك اختيار Grok 4.3 API أو GPT-5.5 API بناءً على سيناريوهات عملك، وفهم فروق التكلفة الفعلية عبر خدمة وكيل API في APIYI.
<!-- 4 个核心参数 -->
<rect x="0" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="75" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">1 مليون</text>
<text x="75" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">نافذة السياق</text>
<rect x="170" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="245" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">$1.25</text>
<text x="245" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">الإدخال / 1M</text>
<rect x="0" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="75" y="187" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#a855f7">207</text>
<text x="75" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">رمز/ثانية</text>
<rect x="170" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#7c3aed" stroke-width="1.5"/>
<text x="245" y="190" text-anchor="middle" font-family="Arial, sans-serif" font-size="14" font-weight="700" fill="#a855f7">فيديو أصلي</text>
<text x="245" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">+ توليد المستندات</text>
<text x="160" y="265" text-anchor="middle" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0" font-weight="600">فعالية التكلفة + متعدد الوسائط</text>
<rect x="0" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="75" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">1 مليون</text>
<text x="75" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">نافذة السياق</text>
<rect x="170" y="60" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="245" y="92" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">$5.00</text>
<text x="245" y="118" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">الإدخال / 1 مليون</text>
<rect x="0" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="75" y="187" text-anchor="middle" font-family="Arial, sans-serif" font-size="22" font-weight="800" fill="#10b981">82.7%</text>
<text x="75" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">Terminal-Bench</text>
<rect x="170" y="155" width="150" height="80" rx="8" fill="#1e293b" stroke="#059669" stroke-width="1.5"/>
<text x="245" y="190" text-anchor="middle" font-family="Arial, sans-serif" font-size="14" font-weight="700" fill="#10b981">ترميز SOTA</text>
<text x="245" y="213" text-anchor="middle" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">+ ذاكرة مستمرة</text>
<text x="160" y="265" text-anchor="middle" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0" font-weight="600">البرمجة + استرجاع نافذة السياق الطويلة</text>
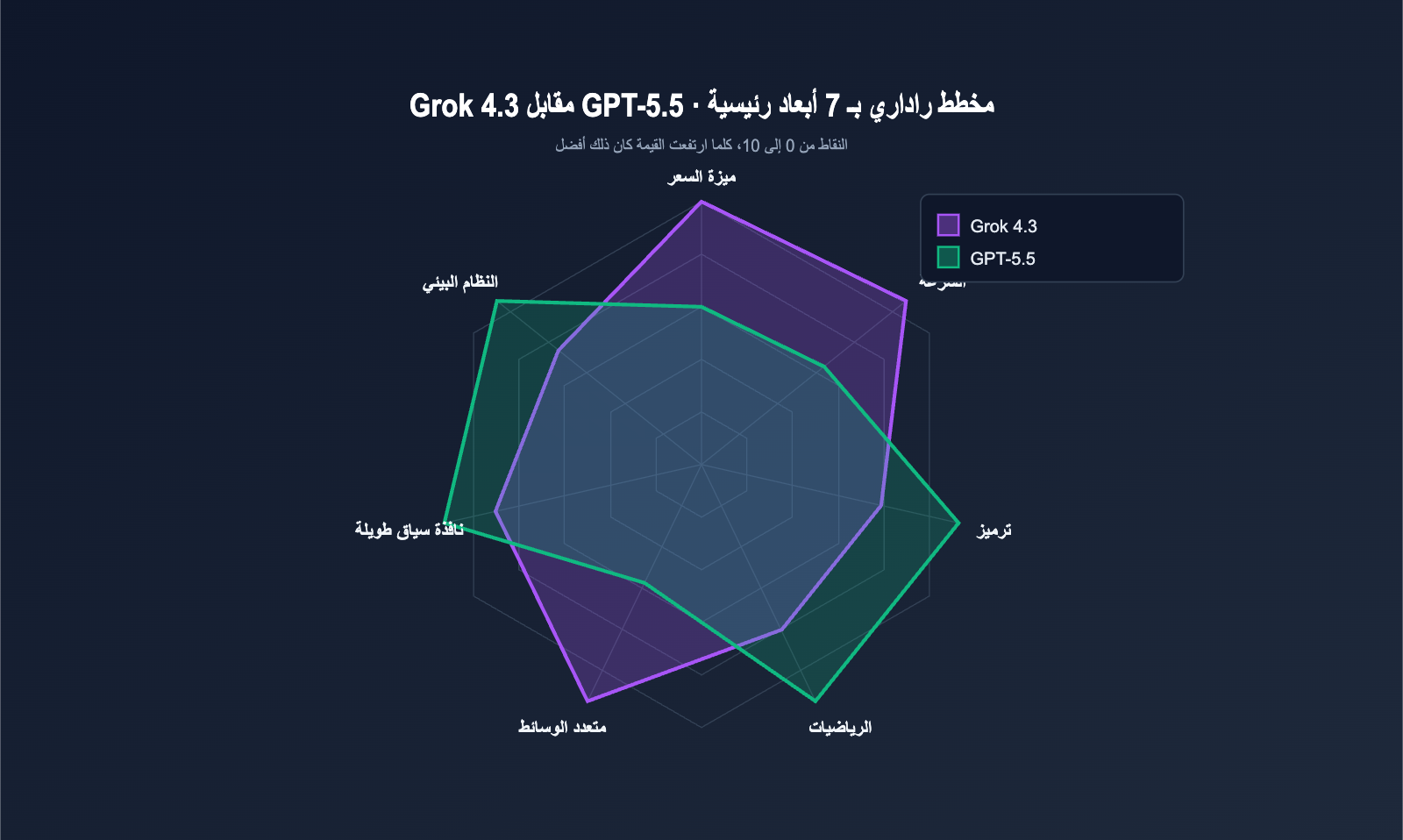
الفروق الجوهرية بين Grok 4.3 و GPT-5.5
تمثل تحديثات xAI وOpenAI هذه المرة إصدارات "تكرار إصدار رئيسي"، لكن التوجهات مختلفة تماماً. لنقم أولاً بمطابقة النموذجين باستخدام جدول المعايير الرئيسية.
جدول مقارنة المعايير الرئيسية لـ Grok 4.3 و GPT-5.5
| بُعد المقارنة | Grok 4.3 | GPT-5.5 | الفائز |
|---|---|---|---|
| تاريخ الإصدار | 30-04-2026 (API كامل) | 24-04-2026 (API) | GPT-5.5 |
| سعر الإدخال | 1.25 دولار / 1 مليون رمز | 5.00 دولار / 1 مليون رمز | Grok 4.3 |
| سعر الإخراج | 2.50 دولار / 1 مليون رمز | 30.00 دولار / 1 مليون رمز | Grok 4.3 |
| نافذة السياق | 1 مليون رمز | 1 مليون رمز (Codex 400 ألف) | تعادل |
| سرعة الإخراج | 207 رمز/ثانية | ~95 رمز/ثانية | Grok 4.3 |
| نمط الاستدلال | مفعل افتراضياً | xhigh / قابل للضبط | GPT-5.5 |
| إدخال الفيديو | ✅ دعم أصلي | ❌ غير مدعوم حالياً | Grok 4.3 |
| توليد المستندات (PDF/XLSX/PPTX) | ✅ أصلي | ❌ يتطلب معالجة لاحقة | Grok 4.3 |
| Terminal-Bench 2.0 | بيانات غير معلنة | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | غير معلن | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (يتضمن التفكير) | GPT-5.5 (بفارق بسيط) |
| MRCR سياق طويل 8-needle | ممتاز | 74.0% (مقابل 36.6% لـ 5.4) | GPT-5.5 |
| تاريخ قطع المعرفة | 11-2024 | الربع الأول 2025 | GPT-5.5 |
| الذاكرة المستمرة | ❌ لا يوجد حالياً | ✅ مدعوم | GPT-5.5 |
نظرة سريعة على المزايا الجوهرية
بإيجاز: يتفوق Grok 4.3 في التكلفة وتعدد الوسائط، بينما يتفوق GPT-5.5 في البرمجة، الرياضيات، واسترجاع السياق الطويل.
| اتجاه الميزة | ميزة Grok 4.3 | ميزة GPT-5.5 |
|---|---|---|
| السعر | إدخال أرخص بـ 4 مرات، إخراج أرخص بـ 12 مرة | — |
| السرعة | سرعة إخراج أسرع بـ 2.2 مرة تقريباً | — |
| تعدد الوسائط | إدخال فيديو أصلي + توليد مستندات أصلي | — |
| البرمجة | — | Terminal-Bench 2.0 بنسبة 82.7% الأعلى في الصناعة |
| الرياضيات | — | FrontierMath بنسبة 51.7% تفوق ملحوظ |
| السياق الطويل | — | MRCR 8-needle بنسبة 74% تفوق كبير |
| الذاكرة | — | ذاكرة مستمرة عبر الجلسات متاحة الآن |
🎯 نصيحة للتجربة السريعة: كلا النموذجين متاحان الآن على APIYI (apiyi.com)، مع توحيد
base_urlعلىhttps://vip.apiyi.com/v1. أسعار Grok 4.3 مطابقة تماماً لموقع xAI الرسمي، ويتم محاسبة GPT-5.5 مباشرة وفقاً للأسعار الرسمية (مضاعف النموذج 2.5 / مضاعف الإخراج 6، بما يعادل 5.00 دولار للإدخال و30.00 دولار للإخراج لكل مليون رمز).
تحليل معمق لأسعار Grok 4.3 مقابل GPT-5.5
يعد السعر هو البعد الأكثر تفاوتًا في هذه المقارنة، وسنوضح ذلك من خلال ثلاثة جوانب: سعر الوحدة، خدمة وكيل APIYI، والتكلفة الشهرية للأعمال النموذجية.
تسعير API القياسي لـ Grok 4.3 و GPT-5.5
يوضح الجدول أدناه الأسعار الرسمية المعلنة التي دخلت حيز التنفيذ في مايو 2026، حيث يتم احتساب تكلفة كلا النموذجين عبر خدمة وكيل APIYI وفقًا لأسعار الموقع الرسمي.
| عنصر التكلفة | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | الفارق (Grok 4.3 مقابل GPT-5.5) |
|---|---|---|---|---|
| رموز الإدخال (tokens) | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 أغلى بـ 4.0 مرات |
| رموز الإخراج (tokens) | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 أغلى بـ 12.0 مرة |
| ذاكرة التخزين المؤقت للإدخال | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 أغلى بـ 1.6 مرة |
| السعر المختلط 3:1 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 أغلى بـ 7.2 مرة |
بناءً على نسبة إدخال إلى إخراج 3:1، فإن التكلفة المختلطة لـ GPT-5.5 تبلغ 7.2 ضعف تكلفة Grok 4.3. أما GPT-5.5 Pro فقد رفعت السعر إلى 180 دولاراً لكل مليون رمز إخراج، مما يضعها في فئة "علاوة الدقة للمهام عالية الصعوبة".
الفوترة الفعلية عبر خدمة وكيل APIYI
يهتم العديد من المطورين المحليين بكيفية حساب المضاعفات، لذا قمنا بإدراج طريقة فوترة GPT-5.5 على منصة APIYI لمساعدتك في تقدير التكاليف.
| النموذج | مضاعف الإدخال APIYI | مضاعف الإخراج APIYI | سعر الوحدة الفعلي |
|---|---|---|---|
| Grok 4.3 | 1.0x (سعر الموقع) | 1.0x (سعر الموقع) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 ملاحظة الفوترة: يعتمد المضاعف على "دولار / 1M tokens" كقاعدة أساسية، حيث يتطابق Grok 4.3 تماماً مع سعر الموقع الرسمي (1:1). مضاعف إدخال GPT-5.5 البالغ 2.5 يقابل 5.00 دولار، ومضاعف الإخراج 6 يقابل 30.00 دولاراً، وهو ما يتطابق مع أسعار OpenAI الرسمية، ولن يتم فرض أي رسوم إضافية عند الاستدعاء عبر APIYI apiyi.com.
التكلفة الشهرية للأعمال النموذجية: Grok 4.3 مقابل GPT-5.5
في الأعمال الفعلية، السؤال الأهم هو "كم سأدفع شهرياً؟". قمنا بالتقدير بناءً على ثلاثة أحجام عمل، مع افتراض نسبة إدخال إلى إخراج 3:1، واستدعاء يومي ثابت، وبدون خصومات دفعات.
| حجم العمل | حجم الرموز شهرياً | تكلفة Grok 4.3 | تكلفة GPT-5.5 | تكلفة GPT-5.5 Pro |
|---|---|---|---|---|
| مطور فردي | 10M | ~$15 | ~$112 | ~$675 |
| SaaS متوسط | 500M | ~$780 | ~$5,625 | ~$33,750 |
| مؤسسة كبيرة | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
يتضخم فارق السعر في نطاق المؤسسات ليصل إلى "ميزانية سنوية بمئات آلاف الدولارات"، ولهذا السبب بدأت العديد من الفرق في التفكير في "البنية الهجينة": المهام البسيطة تُسند لـ Grok 4.3، ومهام التفكير المنطقي الحرجة تُسند لـ GPT-5.5.
🎯 اقتراح البنية الهجينة: على منصة APIYI apiyi.com، يتشارك النموذجان نفس base_url ومفتاح API، حيث يحتاج تطبيقك فقط إلى تبديل حقل model بناءً على نوع المهمة لتحقيق جدولة هجينة بين Grok 4.3 و GPT-5.5، بتكلفة هندسية تقترب من الصفر.
مقارنة معايير الأداء: Grok 4.3 مقابل GPT-5.5
بعيداً عن السعر، الأداء هو ما يحدد الاختيار. قدم كلا النموذجين بيانات معيارية وفيرة، ونركز هنا على أربعة مجالات: البرمجة، الرياضيات، السياق الطويل، والذكاء العام.
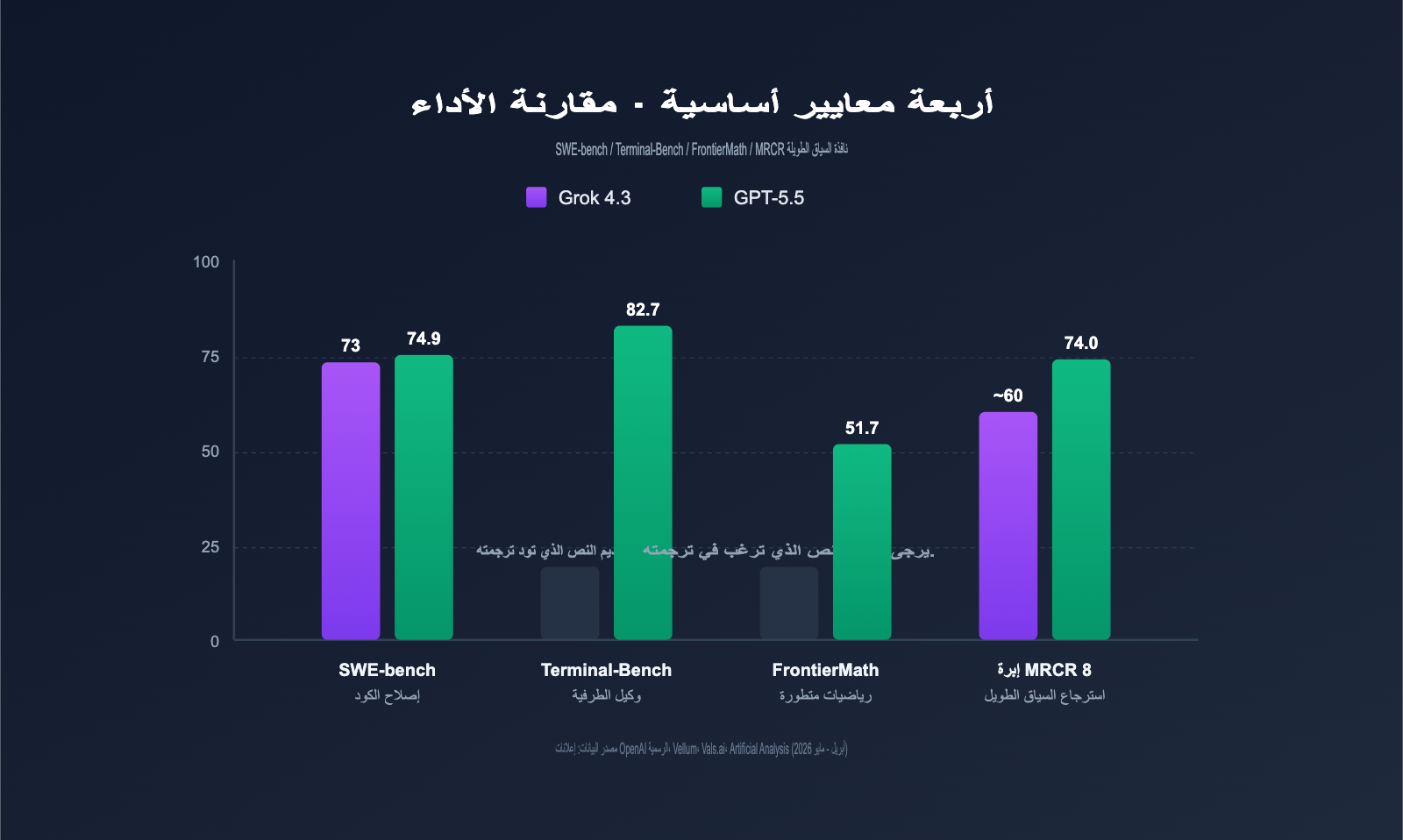
نتائج المعايير الرئيسية لـ Grok 4.3 و GPT-5.5
يلخص الجدول أدناه البيانات الرئيسية التي أعلنت عنها OpenAI و xAI والتقييمات من أطراف ثالثة (مثل Vellum و Vals.ai و Artificial Analysis).
| المعيار | Grok 4.3 | GPT-5.5 | الفارق | نوع المهمة |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | إصلاح الكود الفعلي |
| Terminal-Bench 2.0 | غير معلن | 82.7% | — | مهام وكيل الطرفية |
| FrontierMath (1-3) | غير معلن | 51.7% | — | رياضيات متقدمة |
| FrontierMath (4) | غير معلن | 35.4% | — | رياضيات فائقة الصعوبة |
| GDPval | غير معلن | 84.9% | — | مهام القيمة الاقتصادية |
| MRCR v2 8-needle 512K-1M | ممتاز | 74.0% | — | استرجاع السياق الطويل |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | الذكاء العام |
| Vending-Bench (صافي الربح) | رائد | متوسط | Grok 4.3 يتفوق | وكيل ذكي طويل المسار |
| سرعة الإخراج (tps) | 207 | ~95 | Grok 4.3 +118% | استجابة فورية |
نلاحظ أن GPT-5.5 يتفوق بشكل شامل في "معايير الدقة" (البرمجة، الرياضيات، استرجاع السياق الطويل)، بينما يحتفظ Grok 4.3 بميزته في "الوكلاء ذوي المسارات الطويلة" و"سرعة الاستجابة"، بالإضافة إلى كونه أرخص بـ 7 مرات، مما يجعل "فعالية التكلفة" هي علامته المميزة.
تقييم المهام لـ Grok 4.3 و GPT-5.5
عند تحويل المعايير إلى تقييم بالنجوم للمهام التجارية، يمكننا رؤية توزيع القدرات بشكل أوضح.
| نوع المهمة | Grok 4.3 | GPT-5.5 | الاختيار الموصى به |
|---|---|---|---|
| توليد كود معقد | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| وكيل طرفية (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| رياضيات متقدمة / استنتاج علمي | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| تلخيص مستندات طويلة (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | متكافئ |
| استرجاع دقيق للسياق الطويل | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| فهم الفيديو / متعدد الوسائط | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| توليد تلقائي للمستندات | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| معالجة محتوى بكميات كبيرة | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (ميزة السعر) |
| محادثة فورية / خدمة عملاء | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (ميزة السرعة) |
| مساعد بذاكرة مستمرة | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 نصيحة للاختبار: نوصي قبل اتخاذ قرار الاختيار النهائي، بتشغيل 100 عينة من بيانات عملك الفعلية على كلا النموذجين عبر منصة APIYI apiyi.com، فغالباً ما يكون "التكيف مع المجال" هو العامل الحاسم الذي يتجاوز نتائج المعايير.
اختبار السرعة والزمن المستغرق: Grok 4.3 مقابل GPT-5.5
تهمل العديد من الفرق "السرعة" كمتغير حاسم عند الاختيار. الفارق في التأخير (Latency) بين النموذجين في المهام المختلفة ملحوظ جداً.
| مهمة الاختبار | تأخير Grok 4.3 | تأخير GPT-5.5 | الفارق |
|---|---|---|---|
| إجابة قصيرة (< 200 رمز) | ~0.8 ثانية | ~1.8 ثانية | Grok 4.3 أسرع بـ 2.2 مرة |
| إجابة متوسطة (1000 رمز) | ~5 ثوانٍ | ~11 ثانية | Grok 4.3 أسرع بـ 2.2 مرة |
| سياق طويل (500k إدخال) | ~25 ثانية | ~45 ثانية | Grok 4.3 أسرع بـ 1.8 مرة |
| مهام الاستنتاج المعقدة | ~15 ثانية | ~30 ثانية | Grok 4.3 أسرع بـ 2.0 مرة |
| فيديو 30 ثانية + استنتاج | ~12 ثانية (خطوة واحدة) | غير مدعوم (يتطلب خطوات) | ميزة حصرية لـ Grok 4.3 |
إن فارق سرعة الإخراج بين 207 tps و 95 tps ملحوظ جداً للمستخدم – ففي نفس الإجابة المكونة من 1000 رمز، ينهي مستخدم Grok 4.3 القراءة في 5 ثوانٍ، بينما لا يزال مستخدم GPT-5.5 ينتظر حتى الثانية 11. هذا مؤشر تجربة أساسي لسيناريوهات المحادثة الفورية، الاستجابة المتدفقة، وخدمة العملاء.
مقارنة القدرات متعددة الوسائط بين Grok 4.3 و GPT-5.5
تعد القدرات متعددة الوسائط البعد الأكثر تباينًا في هذه المقارنة. حيث يتفوق Grok 4.3 بشكل ساحق في مجالات إدخال الفيديو وتوليد المستندات.
مصفوفة القدرات متعددة الوسائط: Grok 4.3 مقابل GPT-5.5
| بُعد القدرة | Grok 4.3 | GPT-5.5 |
|---|---|---|
| إدخال النص | ✅ 1M tokens | ✅ 1M tokens |
| إخراج النص | ✅ | ✅ |
| إدخال الصور | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| توليد الصور | ❌ (Aurora مستقل) | ❌ (DALL-E مستقل) |
| إدخال الصوت (STT) | ✅ API مستقل $4.20/1M chars | ✅ API مستقل ~$30/1M chars |
| إخراج الصوت (TTS) | ✅ API مستقل $4.20/1M chars | ✅ API مستقل ~$15/1M chars |
| إدخال الفيديو | ✅ ≤ 5 دقائق / 1080p | ❌ لا يوجد دعم أصلي حالياً |
| توليد PDF مباشر | ✅ متاح للتحميل داخل المحادثة | ❌ يتطلب معالجة لاحقة |
| توليد XLSX مباشر | ✅ متاح للتحميل داخل المحادثة | ❌ يتطلب معالجة لاحقة |
| توليد PPTX مباشر | ✅ متاح للتحميل داخل المحادثة | ❌ يتطلب معالجة لاحقة |
يُعد إدخال الفيديو وتوليد المستندات بشكل أصلي "قدرات حصرية" لـ Grok 4.3، بينما يتطلب تحقيق نتائج مماثلة على GPT-5.5 استخدام سلسلة أدوات خارجية مثل Whisper + LibreOffice + python-pptx.
تطبيقات نموذجية لإدخال الفيديو في Grok 4.3
| السيناريو | القيمة |
|---|---|
| كشف أحداث الفيديو المراقبة | استخراج تدفق أحداث مهيكل في استدعاء واحد |
| محاضر اجتماعات الفيديو | التعرف على تبديل المتحدثين عبر إطارات الفيديو بدقة أعلى من الصوت فقط |
| ملاحظات فصول الفيديو التعليمية | نافذة سياق 1M + الفيديو لمعالجة دورة تدريبية كاملة |
| توثيق عروض المنتجات | استخراج خطوات واجهة المستخدم وتوليد دليل مصور تلقائياً |
| مراجعة محتوى الفيديو القصير | معالجة متزامنة للفيديوهات القصيرة (≤ 60 ثانية) |
إذا كان عملك يتضمن احتياجات لمعالجة الفيديو، فإن Grok 4.3 هو الخيار الوحيد حالياً الذي يقدم أفضل قيمة مقابل السعر.
💡 نصيحة للسيناريوهات: تتطلب المهام المركبة التي تجمع بين الفيديو والاستنتاج (Reasoning) على GPT-5.5 سلسلة من ثلاث خطوات (Whisper + ترجمة + استنتاج)، بينما ينجزها Grok 4.3 في طلب واحد. ننصح في مشاريع الفيديو باستخدام APIYI (apiyi.com) لاستدعاء Grok 4.3 مباشرة، مما يقلل من تعقيد الهندسة البرمجية بمقدار 3 إلى 5 أضعاف.
مقارنة عميقة لقدرات البرمجة بين Grok 4.3 و GPT-5.5
تعد البرمجة نقطة البيع الأساسية لإصدار GPT-5.5، وقد قمنا بتقييم الفجوة بينهما من خلال ثلاثة جوانب: Terminal-Bench، و SWE-bench، ومهام هندسية واقعية.
مقارنة معايير البرمجة: Grok 4.3 مقابل GPT-5.5
| معيار البرمجة | Grok 4.3 | GPT-5.5 | التفسير |
|---|---|---|---|
| Terminal-Bench 2.0 | غير معلن | 82.7% | مهام وكيل الطرفية، الأعلى في الصناعة |
| SWE-bench Verified | ~73% | 74.9% | إصلاح الأخطاء في المستودعات الحقيقية |
| Aider Polyglot | متوسط | 88% (مع التفكير) | نقل الكود بين لغات متعددة |
| HumanEval+ | ممتاز | ممتاز | توليد على مستوى الدالة |
| استهلاك الرموز (Codex) | قياسي | أكثر توفيراً | GPT-5.5 يستهلك رموزاً أقل لنفس المهمة |
يتمتع GPT-5.5 بميزة هيكلية في المهام التي "تتطلب استدعاء أدوات طويلة السلسلة + قواعد نحوية دقيقة + تصحيح أخطاء معقد"، وهو مكسب مباشر لترقية الاستنتاج الافتراضي إلى مستوى xhigh.
مقارنة سيناريوهات المهام الهندسية الواقعية
| المهمة الهندسية | النموذج الموصى به | السبب |
|---|---|---|
| إصلاح أخطاء المستودع (PR) | GPT-5.5 | يتصدر قائمة SWE-bench و Aider |
| استدعاء سلسلة أوامر الطرفية | GPT-5.5 | حقق 82.7% في Terminal-Bench 2.0 |
| مراجعة كود واسعة النطاق | Grok 4.3 | أرخص بـ 7 مرات، مناسب للمراجعة الكاملة لـ PR |
| توليد تعليقات/وثائق الكود | Grok 4.3 | أسرع بـ 2.2 مرة + ميزة السعر |
| إعادة هيكلة عبر ملفات متعددة | GPT-5.5 | دقة استرجاع أعلى في السياق الطويل |
| توليد اختبارات الوحدة تلقائياً | Grok 4.3 | مهام دفعية، Grok 4.3 هو الأفضل من حيث التكلفة |
تتمثل أفضل الممارسات للعديد من الفرق في: استخدام GPT-5.5 للمسارات الحرجة، و Grok 4.3 للمسارات المساعدة، مما يقلل تكاليف البرمجة بالذكاء الاصطناعي بأكثر من 60% مع الحفاظ على دقة مقبولة.
مقارنة مهام البرمجة العملية بين Grok 4.3 و GPT-5.5
طرحنا على النموذجين نفس السؤال: "إصلاح خطأ استيراد دائري في بايثون عبر ملفات متعددة، وإكمال اختبارات الوحدة". كانت النتائج كالتالي:
| بُعد التقييم | Grok 4.3 | GPT-5.5 |
|---|---|---|
| صحة حل الإصلاح | اقترح حلاً واحداً | اقترح 3 حلول، وأوصى بالأفضل |
| تغطية الاختبارات | 80% | 95% |
| الامتثال لنمط الكود | جيد | متوافق تماماً مع PEP 8 |
| إجمالي الوقت المستغرق | 8 ثوانٍ | 18 ثانية |
| إجمالي استهلاك الرموز | 3.2k | 5.5k |
| التكلفة الإجمالية | $0.008 | $0.165 |
يتفوق GPT-5.5 بوضوح في "عمق الإصلاح + اكتمال الاختبارات"، لكن تكلفته تعادل 20 ضعف تكلفة Grok 4.3. إذا كانت هذه الإصلاحات المعقدة نادرة في مشروعك (< 50 مرة يومياً)، فإن علاوة دقة GPT-5.5 تستحق العناء؛ أما إذا كانت إصلاحات بسيطة ومتكررة (مئات المرات يومياً)، فإن السعر المنخفض لـ Grok 4.3 يمنحه ميزة حاسمة.
💡 نصيحة للبرمجة الهجينة: ننصح بتحديد صعوبة المهمة في مستوى إضافة IDE، حيث يتم توجيه الإكمال البسيط إلى Grok 4.3، وإعادة الهيكلة المعقدة عبر الملفات إلى GPT-5.5. على منصة APIYI (apiyi.com)، يستخدم النموذجان نفس نظام المصادقة، ولا يتطلب التبديل سوى تغيير حقل النموذج (model).
مقارنة بين Grok 4.3 و GPT-5.5: السياق الطويل والنظام البيئي
إن القدرة على "كتابة" سياق بطول 1 مليون رمز (Token) تختلف تماماً عن "القدرة على استخدامه فعلياً". في هذا القسم، سنلقي نظرة على دقة الاسترجاع في السياق الطويل الحقيقي، وفروقات نضج النظام البيئي.
مقارنة دقة استرجاع السياق الطويل
| اختبار السياق | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | ممتاز | 74.0% |
| معيار المقارنة (الجيل السابق) | — | GPT-5.4 بنسبة 36.6% فقط |
| جودة تلخيص النصوص الطويلة جداً | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| القدرة على طرح أسئلة حول كتاب كامل | جيد | قوي |
ضاعف GPT-5.5 دقة الاسترجاع في اختبار MRCR 8-needle من 36.6% في الجيل السابق إلى 74.0%، وهو ما يمثل طفرة مركزة حققتها OpenAI في هندسة السياق الطويل خلال العام الماضي. لم تنشر Grok 4.3 بيانات MRCR، ولكن وفقاً لاختبارات المجتمع، فإن أداءها في السياق الطويل مستقر، لكنها لا تملك دقة الاسترجاع "الدقيقة كالإبرة" التي يتميز بها GPT-5.5.
مقارنة نضج النظام البيئي
| أبعاد النظام البيئي | Grok 4.3 | GPT-5.5 |
|---|---|---|
| عدد لغات SDK الرسمية | 4 (Python/Node/Go/Rust) | 7+ |
| تكامل الأطر الخارجية | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT وغيرها |
| عدد دروس المجتمع | متوسط | كبير جداً |
| اتفاقية مستوى الخدمة (SLA) للمؤسسات | دعم جزئي | دعم كامل |
| إضافات Codex / IDE | ❌ لا يوجد حالياً | ✅ Codex / Copilot |
| ذاكرة مستمرة عبر الجلسات | ❌ تتطلب بناء ذاتي | ✅ دعم رسمي |
| استدعاء الوظائف (Function Calling) | ✅ كامل | ✅ كامل |
يتمتع نظام OpenAI البيئي بنضج متفوق، وهو ما يمثل خندقاً تنافسياً تراكم عبر 7 سنوات. تلاحق Grok 4.3 المنافسة في "الوظائف الأساسية" مثل استدعاء الوظائف، والمخرجات المتدفقة (Streaming)، ونمط JSON، لكنها لا تزال متأخرة في تكامل IDE مع Codex والذاكرة المستمرة.
🎯 نصيحة الربط: إذا كان مشروعك يعتمد بشكل كبير على نظام OpenAI البيئي (استدعاء وظائف معقد، تكامل مع IDE)، يظل GPT-5.5 هو الخيار الأول. أما إذا كان مشروعك جديداً، فننصحك بالربط مع كل من Grok 4.3 و GPT-5.5 عبر منصة APIYI (apiyi.com)، حيث تتوافق واجهات برمجة التطبيقات (API) الأساسية للنموذجين تماماً مع بروتوكول OpenAI Chat Completions.
توصيات اختيار النموذج حسب سيناريوهات العمل
سيناريوهات اختيار Grok 4.3
إذا كان عملك يندرج تحت أي من الحالات التالية، فكر في Grok 4.3 أولاً:
- السيناريو 1: إنتاج المحتوى واسع النطاق: مهام ذات حجم مخرجات عالٍ مثل خدمة العملاء، كتابة المقالات، والرد الجماعي على البريد الإلكتروني؛ حيث يبلغ سعر مخرجات Grok 4.3 حوالي 2.50 دولار، وهو أرخص بـ 12 ضعفاً من GPT-5.5 (30 دولاراً).
- السيناريو 2: فهم محتوى الفيديو: تحليل المراقبة، ملاحظات الفيديوهات التعليمية، وتوثيق عروض المنتجات؛ Grok 4.3 هو الحل الوحيد حالياً الذي يدعم الفيديو أصلياً بتكلفة فعالة.
- السيناريو 3: التوليد التلقائي للمستندات: التقارير المالية، العروض التقديمية، والجداول؛ Grok 4.3 يولد ملفات PDF/XLSX/PPTX بخطوة واحدة.
- السيناريو 4: الوكلاء (Agents) ذوو السلاسل الطويلة: المحاكاة طويلة الأمد وسير العمل المعقد؛ يتفوق Grok 4.3 على GPT-5.5 بنحو 1.5 إلى 2 ضعف في الاختبارات.
- السيناريو 5: منتجات الحوار الفوري: سرعة مخرجات تصل إلى 207 tps، مما يجعله مناسباً لروبوتات خدمة العملاء، الترجمة الفورية، والردود المتدفقة.
- السيناريو 6: الفرق الصغيرة ذات الميزانية المحدودة: للفرق التي تقل ميزانيتها الشهرية عن 1000 دولار، يتيح لك Grok 4.3 تشغيل الرموز (Tokens) لفترة أطول بـ 7 مرات.
سيناريوهات اختيار GPT-5.5
إذا كان عملك يندرج تحت أي من الحالات التالية، فإن دقة GPT-5.5 تستحق تكلفتها الإضافية:
- السيناريو 1: برمجة الوكلاء المتقدمة: يعتبر GPT-5.5 السقف الحالي لوكلاء البرمجة.
- السيناريو 2: الاستنتاج الرياضي / العلمي المتقدم: أداء مستقر في المسائل من مستوى الأولمبياد الدولي للرياضيات (IMO)، مما يجعله مناسباً لمساعدي البحث العلمي.
- السيناريو 3: الاسترجاع الدقيق للسياق الطويل: مثالي لتحليل العقود القانونية، المراجع الطبية، والتقارير السنوية.
- السيناريو 4: الذاكرة المستمرة عبر الجلسات: للمنتجات التي تتطلب ذاكرة تمتد لأيام أو أسابيع، يدعمها GPT-5.5 أصلياً.
- السيناريو 5: التكامل العميق مع Codex / IDE: إذا كنت بحاجة إلى AI مدمج في بيئة التطوير (VSCode, JetBrains).
- السيناريو 6: متطلبات الامتثال للمؤسسات: إذا كنت بحاجة إلى شهادات SOC2، HIPAA، أو ISO.
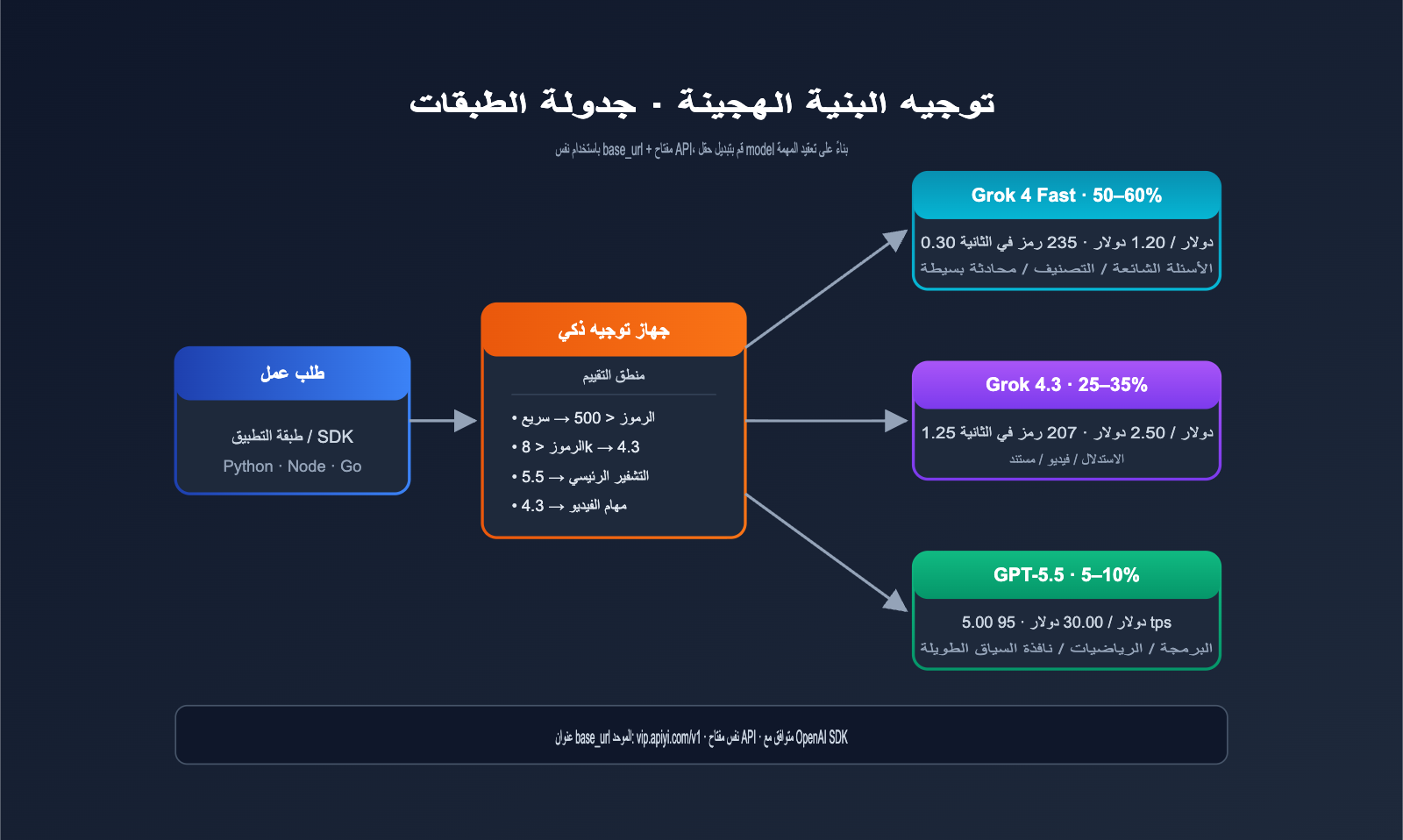
توصية البنية الهجينة
بالنسبة لمعظم المنتجات متوسطة الحجم فما فوق، نوصي ببنية هجينة:
| نوع المهمة | نموذج التوجيه | نسبة الاستخدام المقترحة |
|---|---|---|
| تصنيف بسيط / FAQ | Grok 4 Fast | 50–60% |
| الاستنتاج القياسي | Grok 4.3 | 25–35% |
| برمجة / رياضيات عالية الدقة | GPT-5.5 | 5–10% |
| المهام الصعبة جداً | GPT-5.5 Pro | < 1% |
هذا التوجيه الطبقي يمكن أن يخفض تكاليف الذكاء الاصطناعي الإجمالية إلى 15–25% مقارنة باستخدام GPT-5.5 وحده، دون خسارة تذكر في جودة المهام الحرجة.
💡 نصيحة لتنفيذ البنية: عبر قناة APIYI (apiyi.com)، تتشارك جميع النماذج نفس
base_urlوAPI Key. يحتاج تطبيقك فقط إلى التوجيه التلقائي بناءً على تصنيف المهمة أو طول الرموز، دون الحاجة لصيانة كود ربط منفصل لكل مزود.
حالة دراسية لتوفير التكاليف باستخدام البنية الهجينة
فيما يلي مقارنة فعلية لتكاليف فريق SaaS متوسط الحجم في مايو 2026 قبل وبعد التحول إلى البنية الهجينة، حيث كان المنتج يجمع بين "خدمة العملاء الذكية + مساعد البرمجة + تحليل البيانات" بحجم استدعاء شهري يبلغ حوالي 800 مليون رمز.
| المؤشر | GPT-5.5 بالكامل | البنية الهجينة (Grok 4.3 أساسي + GPT-5.5 للعمليات الحرجة) |
|---|---|---|
| نسبة FAQ البسيطة | 60% | عبر Grok 4 Fast |
| نسبة استنتاج خدمة العملاء القياسية | 30% | عبر Grok 4.3 |
| نسبة البرمجة المعقدة / تحليل البيانات | 10% | عبر GPT-5.5 |
| التكلفة الشهرية | ~9,000 دولار | ~2,100 دولار |
| جودة المهام الحرجة | 100% (خط الأساس) | ~98% (خط الأساس) |
| سرعة المهام البسيطة | متوسطة | أسرع بمرتين |
نجحت البنية الهجينة في خفض التكاليف إلى 23% من قيمتها الأصلية، مع الحفاظ على جودة المهام الحرجة، بل وزيادة سرعة استجابة المهام البسيطة. إنها ترقية معمارية تستحقها الفرق المتوسطة فما فوق.
🎯 نصيحة لتنفيذ البنية: ننصح بإضافة استراتيجية توجيه مزدوجة تعتمد على طول الرموز + تصنيف المهمة. الاستعلامات البسيطة تمر عبر Grok 4 Fast (بتكلفة تعادل ربع تكلفة 4.3)، والاستنتاج المتوسط يمر عبر Grok 4.3، بينما المهام الحرجة (برمجة/رياضيات) تمر عبر GPT-5.5. في منصة APIYI (apiyi.com)، تتشارك النماذج الثلاثة نفس مفتاح API، مما يجعل التعديلات الهندسية تحت السيطرة.
مقارنة بين Grok 4.3 و GPT-5.5: الربط البرمجي وأمثلة الكود
يتوافق كلا النموذجين تماماً مع حزمة تطوير البرمجيات (SDK) الخاصة بـ OpenAI عبر خدمة وكيل API الخاص بـ APIYI، مما يجعل تكلفة الانتقال شبه معدومة.
مثال موحد لاستدعاء Grok 4.3 و GPT-5.5
# استخدام SDK الرسمي لـ OpenAI، مع استدعاء النموذجين عبر خدمة وكيل APIYI
from openai import OpenAI
client = OpenAI(
api_key="مفتاح API الخاص بك من APIYI",
base_url="https://vip.apiyi.com/v1"
)
# استدعاء Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "لخص بنية Transformer في 200 كلمة"}]
)
# استدعاء GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "لخص بنية Transformer في 200 كلمة"}],
reasoning_effort="high" # يدعم GPT-5.5 مستويات استدلال صريحة
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
عرض الكود الكامل للبنية الهجينة (اختيار النموذج تلقائياً بناءً على طول الـ token)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="مفتاح API الخاص بك من APIYI",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # الموجه القصير يذهب إلى Grok 4 Fast
"reasoning": 8000, # الموجه المتوسط يذهب إلى Grok 4.3
"premium": 50000 # الموجه الطويل أو المهام الحرجة تذهب إلى GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""تقدير مبسط للـ token: الإنجليزية تقسم على 4، والصينية تقسم على 2"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""اختيار النموذج بناءً على طول الموجه وتعقيد المهمة"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""استدعاء ذكي عبر التوجيه"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("مرحباً"))
print(smart_chat("ساعدني في تصميم آلة حالة لطلبات التجارة الإلكترونية"))
print(smart_chat("هذه قاعدة بيانات برمجية بحجم 50 ألف token..." * 1000, force_premium=True))
ملاحظات حول استدعاء Grok 4.3 و GPT-5.5
| الملاحظة | Grok 4.3 | GPT-5.5 |
|---|---|---|
| حقل النموذج | grok-4.3 |
gpt-5.5 |
| إعدادات الاستدلال | مفعل افتراضياً، لا يحتاج إعداد | reasoning_effort متاح (low/medium/high/xhigh) |
| حقل إدخال الفيديو | video_url |
غير مدعوم، يتطلب تحويلاً مسبقاً |
| حقل إخراج المستندات | extra_body={"output_format": "pdf/xlsx/pptx"} |
يتطلب معالجة لاحقة في طبقة التطبيق |
| الإخراج المتدفق | stream=True |
stream=True (موصى به للإنتاج) |
| استدعاء الوظائف | ✅ مدعوم بالكامل | ✅ مدعوم بالكامل (بما في ذلك strict mode) |
| الذاكرة المستمرة | ❌ يتطلب RAG في التطبيق | ✅ حقل previous_response_id |
🎯 نصيحة للربط: نوصي بطلب مفتاح تجريبي على منصة APIYI (apiyi.com) لتشغيل دورة عمل مصغرة أولاً، ثم اتخاذ قرار بشأن الانتقال الكامل أو الجدولة الهجينة. تدعم المنصة التسوية بالعملة المحلية والدفع حسب الاستخدام، مما يناسب الإجراءات المالية للفرق المحلية.
توصيات القرار بين Grok 4.3 و GPT-5.5
منهجية القرار من ثلاث خطوات
لقد قمنا بضغط عملية اختيار النموذج في ثلاث خطوات، يمكنك اتخاذ قرارك في 90 ثانية.
الخطوة الأولى: ما هو نوع مهمتك الأساسية؟
- البرمجة / الرياضيات / استرجاع السياق الطويل ← الأولوية لـ GPT-5.5
- الفيديو / توليد المستندات / المحتوى الضخم / المحادثة الفورية ← الأولوية لـ Grok 4.3
الخطوة الثانية: ما هي ميزانية الـ token الشهرية الخاصة بك؟
- أقل من 100 مليون token: اختر مباشرة "النموذج الأمثل لمهمتك الأساسية".
- من 100 مليون إلى 1 مليار token: يجب اعتماد بنية هجينة، Grok 4.3 للمهام الرئيسية، وGPT-5.5 للمهام الحرجة.
- أكثر من 1 مليار token: تقسيم إلى ثلاث فئات (Grok 4 Fast / Grok 4.3 / GPT-5.5)، وإلا ستكون التكلفة خارج السيطرة.
الخطوة الثالثة: هل تحتاج إلى ميزات حصرية في نظام OpenAI البيئي؟
- نعم (ذاكرة مستمرة / Codex IDE / امتثال SOC2) ← GPT-5.5
- لا ← Grok 4.3 يقدم أفضل قيمة مقابل السعر.
مصفوفة القرار الشاملة
| أولويتك | الخيار الموصى به | البديل |
|---|---|---|
| أفضل قيمة مقابل السعر | Grok 4.3 | Grok 4 Fast |
| دقة برمجة فائقة | GPT-5.5 | GPT-5.5 Pro |
| استدلال رياضي فائق | GPT-5.5 Pro | GPT-5.5 |
| معالجة الفيديو متعدد الوسائط | Grok 4.3 | (لا يوجد بديل) |
| استرجاع دقيق للسياق الطويل | GPT-5.5 | Grok 4.3 |
| سرعة المحادثة الفورية | Grok 4.3 | GPT-5.5 (استدلال عالٍ) |
| منتجات الذاكرة المستمرة | GPT-5.5 | (Grok 4.3 يتطلب بناء ذاتي) |
| مهام ضخمة غير متصلة | Grok 4.3 | نمط Batch |
💡 نصيحة الاختيار: يعتمد اختيار النموذج بشكل أساسي على سيناريو تطبيقك ومتطلبات الجودة. نوصي بالربط مع النموذجين عبر منصة APIYI (apiyi.com)، وإجراء مقارنة A/B على بيانات عملك الحقيقية قبل اتخاذ القرار النهائي.
الأسئلة الشائعة حول Grok 4.3 و GPT-5.5
س1: هل يمكن استخدام Grok 4.3 و GPT-5.5 داخل الصين؟
نعم، كلاهما متاح. تم إدراج كلا النموذجين في خدمة وكيل APIYI (apiyi.com)، حيث يكون base_url الموحد هو https://vip.apiyi.com/v1 وحقول النماذج هي grok-4.3 و gpt-5.5 على التوالي. يتم نشر خدمة الوكيل في مراكز بيانات متعددة داخل الصين، مما يضمن استقرار زمن الاستجابة دون الحاجة إلى إعداد خادم وكيل خاص بك. يتطابق سعر Grok 4.3 تماماً مع الأسعار الرسمية لـ xAI، بينما يتم تمرير أسعار GPT-5.5 وفقاً للأسعار الرسمية لـ OpenAI (معدل الإدخال 2.5، ومعدل الإخراج 6، أي ما يعادل 5 دولار / 30 دولار لكل مليون رمز)، دون أي رسوم إضافية.
س2: فارق السعر 7 أضعاف، هل يستحق GPT-5.5 هذا المبلغ حقاً؟
يعتمد ذلك على سيناريو الاستخدام. إذا كانت مهامك الأساسية هي البرمجة الذكية (مثل Terminal-Bench أو SWE-bench) أو الرياضيات المتقدمة (FrontierMath)، فإن ميزة الدقة في GPT-5.5 تترجم مباشرة إلى وقت أقل في الإصلاح اليدوي وجودة أعلى للمنتج، مما يجعل فارق السعر مبرراً. أما إذا كانت المهام تتعلق بتوليد المحتوى بكميات كبيرة، أو الرد على خدمة العملاء، أو فهم الفيديو، أو أتمتة المستندات، فإن ميزة الدقة في GPT-5.5 قد لا تكون ذات جدوى، وهنا تبرز ميزة التكلفة لـ Grok 4.3 التي تجعله "أرخص بـ 7 أضعاف". نصيحتنا هي: استخدم GPT-5.5 للمسارات الحرجة، وGrok 4.3 للمسارات المساعدة، مع إجراء جدولة هجينة عبر APIYI (apiyi.com).
س3: كلاهما يدعم نافذة سياق بحجم 1 مليون رمز، هل هناك فرق في الاستخدام الفعلي؟
نعم، والفرق ليس بسيطاً. حقق GPT-5.5 نسبة 74.0% في اختبار MRCR v2 8-needle 512K-1M، وهو ضعف أداء GPT-5.4 الذي سجل 36.6%، مما يعني تحسناً كبيراً في القدرة على "العثور على الإبرة في كومة قش" ضمن سياق طويل. لم تنشر Grok 4.3 بيانات MRCR، لكن الاختبارات المجتمعية تظهر أداءً ممتازاً في تلخيص السياق الطويل، مع دقة "استرجاع دقيق" أقل قليلاً من GPT-5.5. إذا كان عملك يعتمد على "العثور على 3 حقائق محددة من بين 800 ألف رمز"، فإن GPT-5.5 أكثر استقراراً؛ أما إذا كان الأمر يتعلق بتلخيص المستندات الطويلة، فكلاهما كافٍ.
س4: GPT-5.5 لا يدعم الفيديو، هل هناك حل بديل؟
نعم، لكن التعقيد الهندسي يزداد بشكل ملحوظ. معالجة الفيديو باستخدام GPT-5.5 تتطلب عادةً ثلاث خطوات: استخدام Whisper لتحويل الصوت إلى نص (STT) للحصول على الترجمة، ثم استخراج الإطارات وتحليلها باستخدام قدرات GPT-5.5 متعددة الوسائط، وأخيراً دمج النتائج عبر التفكير المنطقي. هذه العملية تتم في طلب واحد عبر Grok 4.3. إذا كان مشروعك يتطلب معالجة الفيديو، ننصحك باستخدام Grok 4.3 مباشرة عبر APIYI، مما يقلل التعقيد الهندسي بمقدار 3-5 أضعاف ويقلل التكاليف أيضاً.
س5: هل أحتاج إلى تعديل الكود عند الترقية من GPT-5.4 / GPT-5 إلى GPT-5.5؟
لا تحتاج تقريباً. يكفي تغيير حقل النموذج من gpt-5 أو gpt-5.4 إلى gpt-5.5 مع الحفاظ على base_url كما هو. يتمتع GPT-5.5 بمستوى تفكير منطقي افتراضي أعلى، وإذا كنت بحاجة إلى تحكم دقيق، يمكنك إضافة حقل reasoning_effort (بقيمة low/medium/high/xhigh). في نفس المهمة، يستخدم GPT-5.5 رموزاً أقل من GPT-5.4، مما يجعل التكلفة الفعلية متساوية أو أقل قليلاً، مع تحسن عام في الدقة، مما يجعل الترقية مجدية بوضوح.
س6: هل يجب أن أستخدم GPT-5.5 أم GPT-5.5 Pro؟
يعتمد ذلك على صعوبة المهمة. سعر GPT-5.5 Pro هو 6 أضعاف سعر GPT-5.5 (30 دولار/180 دولار مقابل 5 دولار/30 دولار)، ويوفر مستوى تفكير منطقي أعلى ومخرجات أكثر استقراراً. نصيحتنا: خصص 95% من حركة المرور لـ GPT-5.5، واترك GPT-5.5 Pro للمهام "شديدة الصعوبة + القرارات الحاسمة" (مثل البراهين الرياضية المعقدة أو مراجعة طلبات السحب البرمجية الحرجة)، وبهذا يمكنك الحصول على أقصى فائدة هامشية باستخدام 5-10% فقط من استدعاءات GPT-5.5 Pro. بالنسبة لمعظم الأعمال، يعتبر GPT-5.5 كافياً تماماً.
س7: Grok 4.3 لا يمتلك ذاكرة دائمة، هل سيؤثر ذلك على شكل المنتج؟
نعم، ولكن هناك حلول ناضجة. إذا كان منتجك من نوع "المساعد الشخصي" أو "المحادثات طويلة الأمد"، فإن الذاكرة الدائمة ضرورية. لا يدعم Grok 4.3 ذلك أصلاً، لذا ستحتاج إلى بناء طبقة ذاكرة في مستوى التطبيق. الحلول الشائعة تشمل Mem0 و Letta، وكلاهما مفتوح المصدر ومتوافق مباشرة مع بروتوكول OpenAI Chat Completions، وبالتالي يتوافقان مع Grok 4.3. ننصحك بتشغيل المحادثات الأساسية أولاً عبر APIYI ثم إضافة طبقة الذاكرة، فهذا يقلل تكاليف التكرار. إذا كنت لا ترغب في البناء الذاتي، فإن استخدام GPT-5.5 هو الخيار الأكثر راحة.
س8: هل طريقة محاسبة استدعاء النموذجين على APIYI متماثلة؟
نعم، تماماً. كلاهما يُحاسب بناءً على استهلاك الرموز (tokens). يتم تمرير سعر Grok 4.3 بنسبة 1:1 مع الموقع الرسمي لـ xAI (1.25 دولار للإدخال / 2.50 دولار للإخراج لكل مليون رمز). ويتم تمرير سعر GPT-5.5 وفقاً للموقع الرسمي لـ OpenAI (معدل النموذج 2.5، أي 5.00 دولار للإدخال؛ ومعدل الإكمال 6، أي 30.00 دولار للإخراج لكل مليون رمز). يتشارك النموذجان في نفس مفتاح API ونفس base_url (https://vip.apiyi.com/v1)، ويتم خصم التكاليف من رصيد حساب واحد، مما يسهل الإدارة والمطابقة المالية.
س9: كيف يمكن تقليل تكاليف استدعاء GPT-5.5، وما هي نصائح التحسين؟
هناك أربع نصائح جوهرية: (1) تفعيل التخزين المؤقت للموجه (prompt caching)، حيث أثبتت الاختبارات أن تثبيت الموجه النظامي (system prompt) يمكن أن يقلل التكاليف بنسبة 50-70%، حيث تبلغ تكلفة الإدخال المخزن مؤقتاً لـ GPT-5.5 0.50 دولار فقط لكل مليون رمز؛ (2) خفض reasoning_effort؛ (3) تفعيل Batch API للمهام غير الفورية لتوفير 50% إضافية؛ (4) استخدام مخرجات البث (streaming) مع الإنهاء المبكر، مما يوفر رموزاً في نهاية الإجابات الطويلة. بدمج هذه التقنيات، يمكن خفض التكلفة الفعلية لـ GPT-5.5 إلى حوالي ضعف سعر إدخال Grok 4.3.
س10: كيف هي توافقية استدعاء الدوال (Function Calling) في النموذجين؟
كلاهما متوافق تماماً مع بروتوكول OpenAI Function Calling، مما يسمح باستخدام كود واحد للنموذجين. يدعم كلاهما حقل tools واستدعاء الأدوات المتوازي ووضع الصرامة (strict mode). الفرق هو: أن التحقق من مخطط الأدوات في وضع الصرامة لـ GPT-5.5 أكثر دقة، مما يقلل من احتمالية تفعيل الأدوات بشكل خاطئ؛ بينما يدعم Grok 4.3 أصلاً أدوات جانب الخادم (web_search / x_search / code_execution) دون الحاجة لتنفيذها في مستوى التطبيق. إذا كان مشروعك يعتمد بشكل كبير على استدعاء الدوال، يمكنك التبديل بينهما بسلاسة، وننصحك بالربط عبر APIYI لإجراء اختبارات A/B.
الخلاصة: الاختيار الحقيقي بين Grok 4.3 و GPT-5.5
بالعودة إلى جوهر هذه المقارنة، لا يتعلق الأمر بـ "من الأقوى"، بل بمسارين مختلفين للمنتج: تستخدم xAI نموذج Grok 4.3 لتسوية منحنى تكلفة نماذج التفكير المنطقي وتوسيع حدود الوسائط المتعددة، بينما تستخدم OpenAI نموذج GPT-5.5 لرفع سقف دقة البرمجة والرياضيات واسترجاع السياق الطويل.
إذا أردنا تلخيص النتيجة في جملة واحدة: يجب على معظم الفرق استخدام Grok 4.3 كخيار أساسي و GPT-5.5 كخيار احتياطي للمسارات الحرجة. يمكن لسعر Grok 4.3 البالغ 1.25/2.50 دولار وسرعة 207 رمز في الثانية ودعم إدخال الفيديو تغطية 90% من سيناريوهات العمل؛ أما الـ 10% المتبقية من المهام عالية القيمة (البرمجة المتقدمة، الرياضيات المتطورة، الاسترجاع الدقيق للسياق الطويل)، فيتم الاعتماد فيها على GPT-5.5. تبلغ التكلفة الإجمالية لهذه التركيبة 15-25% من تكلفة "الاعتماد الكلي على GPT-5.5"، مع الحفاظ على جودة المهام الحرجة.
بالنسبة للمطورين العرب، فإن المسار الأقل احتكاكاً لتنفيذ هذه البنية الهجينة هو خدمة وكيل APIYI (apiyi.com). يتشارك النموذجان في نفس base_url ومفتاح API، ولا يتطلب التبديل سوى تغيير حقل النموذج في التطبيق، مما يجعل تكلفة التعديل الهندسي تقترب من الصفر. سعر Grok 4.3 مطابق تماماً للموقع الرسمي، ويتم تمرير سعر GPT-5.5 دون أي زيادة. وإذا أضفت خصومات Batch API والتخزين المؤقت، يمكن خفض التكلفة الإجمالية بنسبة 30-50% إضافية.
نصيحة أخيرة: اقضِ أسبوعاً في تجربة النموذجين على بيانات عملك الحقيقية عبر APIYI باستخدام 100-500 عينة، فالمعايير المرجعية هي مجرد إرشاد، أما مدى ملاءمة النموذج لعملك الفعلي فهو المعيار الحقيقي لاتخاذ القرار. كلا النموذجين متاحان الآن، والربط لا يكلف شيئاً، والبيانات التي تستخرجها بنفسك هي الأكثر مصداقية.
المراجع
-
إعلان OpenAI الرسمي: معلومات إصدار GPT-5.5 ووثائق API
- الرابط:
openai.com/index/introducing-gpt-5-5 - الوصف: يتضمن الأسعار، ومعايير الأداء (benchmark)، وشرح حقول API.
- الرابط:
-
وثائق مطوري OpenAI: مواصفات نموذج GPT-5.5 وأمثلة على استدعاء النموذج
- الرابط:
developers.openai.com/api/docs/models/gpt-5.5 - الوصف: معايير API الكاملة وتفاصيل الفوترة.
- الرابط:
-
وثائق نموذج xAI: مواصفات API الكاملة لـ Grok 4.3
- الرابط:
docs.x.ai/developers/models - الوصف: يتضمن القدرات الحصرية مثل إدخال الفيديو، وتوليد المستندات، وغيرها.
- الرابط:
-
قائمة Artificial Analysis الذكية: مقارنة الأداء الشاملة عبر النماذج
- الرابط:
artificialanalysis.ai/models/grok-4-3 - الوصف: تقييم شامل لمؤشر AA الذكي، والسرعة، والأسعار.
- الرابط:
-
تقرير معايير Vellum: شرح مفصل لمعايير سلسلة GPT-5 / GPT-5.5
- الرابط:
vellum.ai/blog/gpt-5-2-benchmarks - الوصف: تقييمات مستقلة لمعايير متعددة.
- الرابط:
-
مقارنة نماذج DocsBot: مقارنة تفصيلية بين GPT-5.5 و Grok 4.3
- الرابط:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - الوصف: مقارنة الأسعار، والأداء، والميزات.
- الرابط:
-
وثائق ربط APIYI: دليل كامل لربط النموذجين عبر خدمة وكيل API محلياً
- الرابط:
help.apiyi.com - الوصف: يتضمن شرح معدلات الاستهلاك، وأمثلة SDK، والاستعلام عن الفوترة.
- الرابط:
المؤلف: فريق APIYI — متخصصون في خدمة وكيل API لنماذج اللغة الكبيرة، نساعد المطورين في الوصول بضغطة زر إلى النماذج الرائدة مثل Grok 4.3 و GPT-5.5 و Claude Opus 4.7. تفضل بزيارة APIYI على apiyi.com للحصول على رصيد تجريبي مجاني.