ملاحظة من الكاتب: يستمر نموذج Grok 4.20 Beta الرائد من xAI في التطور، حيث حقق أدنى معدل هلوسة في الصناعة بنسبة 78%، مع دعم أصلي للتعاون متعدد الوكلاء (4 Agents)، ونافذة سياق تصل إلى 2 مليون Token، بالإضافة إلى دعم المحادثات الصوتية وتوليد الصور والفيديو. يقدم هذا المقال تحليلاً عميقاً لقدراته الأساسية وقيمته العملية.
أطلقت شركة xAI التابعة لإيلون ماسك نموذج Grok 4.20 Beta في مطلع عام 2026، ومنذ ذلك الحين وهو يشهد تحديثات مستمرة. تتمثل السمة الأكثر تميزاً لهذا النموذج في "أدنى معدل هلوسة في الصناعة" — حيث سجل نسبة 78% من عدم الهلوسة في اختبارات Artificial Analysis Omniscience، كما أدخل هيكلية تعاون متعدد الوكلاء (4 Agents) ونافذة سياق بسعة 2 مليون Token. وقد أدت تحديثات شهر أبريل الأخيرة إلى تحسين دقة اتباع التعليمات، وتنسيق LaTeX، وتفعيل البحث عن الصور.
القيمة الأساسية: تعرف في 5 دقائق على القدرات الجوهرية لنموذج Grok 4.20 Beta، والفروقات بين متغيراته الثلاثة، وقدراته متعددة الوسائط، وموقعه التنافسي مقارنة بـ Claude وGPT.

نظرة سريعة على المعلومات الأساسية لـ Grok 4.20 Beta
| عنصر المعلومات | التفاصيل |
|---|---|
| تاريخ الإصدار | 17 فبراير 2026 (تجريبي) / 10 مارس (API) |
| المطور | xAI (إيلون ماسك) |
| التمركز الأساسي | موثوقية عالية + متعدد الوكلاء + رائد متعدد الوسائط |
| معدل الهلوسة | 78% عدم هلوسة (الأعلى في الصناعة) |
| نافذة السياق | 2 مليون Token (ترقية من 256K في Grok 4) |
| متغيرات النموذج | استنتاجي / غير استنتاجي / متعدد الوكلاء |
| سرعة المخرجات | 247.8 رمز/ثانية (متوسط نماذج الاستنتاج 68.5) |
| التسعير | $2/مليون Token للمدخلات، $6/مليون Token للمخرجات |
| متعدد الوسائط | إدخال وإخراج للنصوص/الصور/الفيديو/الصوت |
التمركز السوقي لـ Grok 4.20 Beta
في مشهد المنافسة بين نماذج اللغة الكبيرة، اختار Grok 4.20 Beta مساراً متميزاً: فهو لا يسعى لتحقيق أعلى الدرجات في جميع الاختبارات، بل يبني ميزته الفريدة في ثلاثة أبعاد: المصداقية (انخفاض الهلوسة)، السرعة، والتعاون متعدد الوكلاء.
حصل النموذج على 48 نقطة في مؤشر الذكاء من Artificial Analysis، وهو أعلى من متوسط النماذج في نفس الفئة السعرية (31 نقطة)، لكنه لا يزال بعيداً عن الدرجات القصوى التي يحققها Claude Opus 4.5 وGPT-5.4. استراتيجية xAI هي — بدلاً من تقديم نموذج يبهرك أحياناً ولكنه يخطئ كثيراً، نقدم لك نموذجاً موثوقاً دائماً.
شرح مفصل للقدرات الأساسية لنموذج Grok 4.20 Beta
القدرة 1: أدنى معدل هلوسة في القطاع
تتمثل أبرز قدرات Grok 4.20 Beta في التحكم في الهلوسة:
| التقييم | Grok 4.20 | متوسط القطاع | ملاحظات |
|---|---|---|---|
| معدل عدم الهلوسة AA-Omniscience | 78% | ~60-70% | الأعلى في القطاع |
| اتباع التعليمات | ممتاز | – | التزام صارم بالموجه |
| تنسيق LaTeX | تحسين مستمر | – | تحسينات تحديث أبريل |
يعني معدل عدم الهلوسة البالغ 78% أن Grok 4.20 دقيق في حوالي 4 من كل 5 إجابات عند طرح أسئلة واقعية، وهو المعدل الأعلى بين جميع النماذج التي تم اختبارها. بالنسبة للمجالات التي تتطلب موثوقية عالية (مثل الاستشارات الطبية، التحليل القانوني، والبحث الأكاديمي)، قد تكون نسبة الهلوسة المنخفضة أكثر قيمة من "مؤشر الذكاء" المرتفع.
تحسينات أبريل المستمرة: أدى التكرار الأخير إلى تحسين قدرات اتباع التعليمات وتنسيق المعادلات الرياضية بـ LaTeX، كما تم تعزيز دقة تفعيل البحث عن الصور.
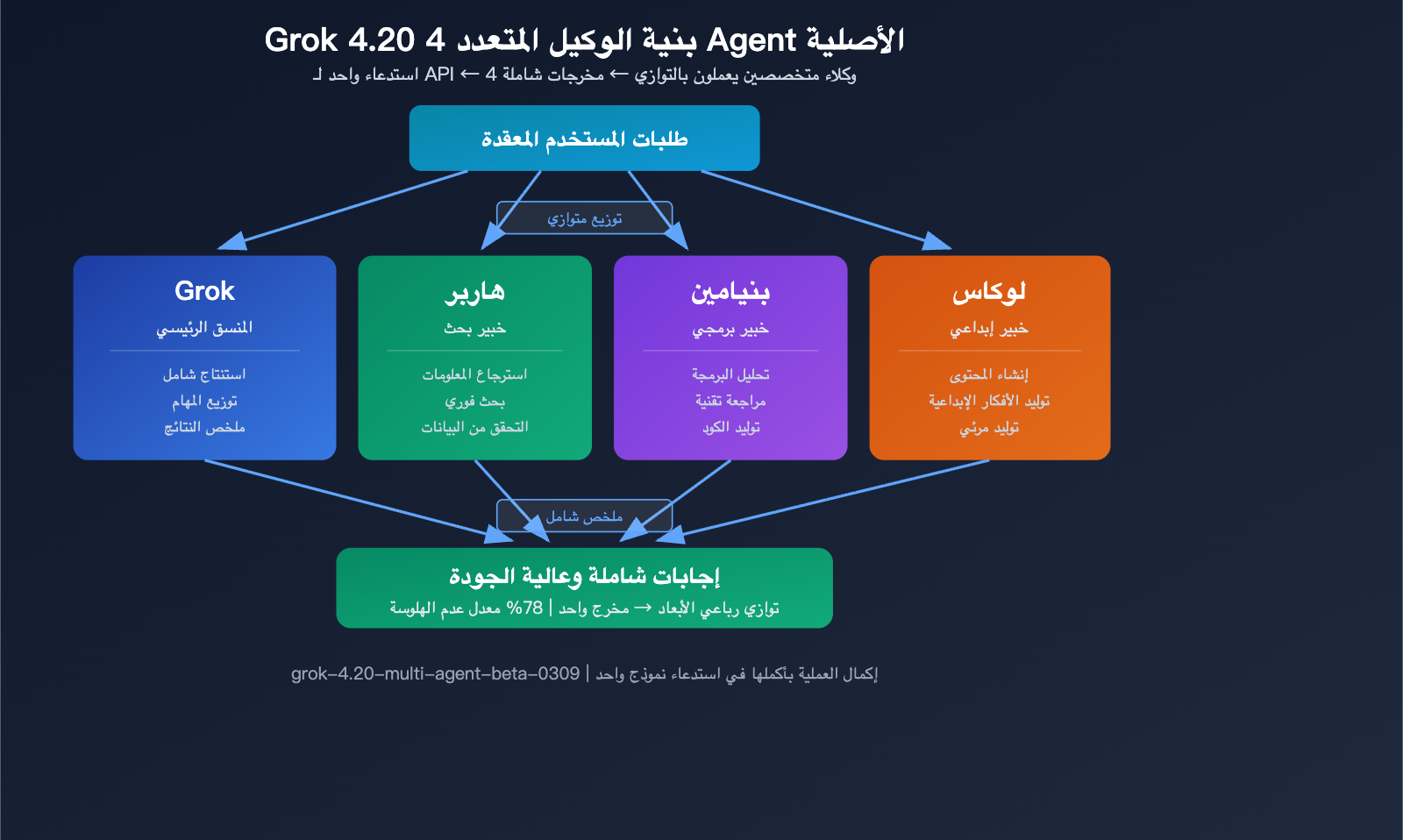
القدرة 2: بنية الوكيل المتعدد (4 Agents) الأصلية
يقدم Grok 4.20 Beta أول واجهة برمجة تطبيقات (API) أصلية للوكلاء المتعددين في القطاع، حيث يتم استدعاء API واحد ليعمل في الخلفية 4 وكلاء متخصصين بالتوازي:
| اسم الوكيل | التخصص | الدور |
|---|---|---|
| Grok | الاستنتاج الشامل والمحادثة | المنسق الرئيسي |
| Harper | البحث واسترجاع المعلومات | خبير البحث |
| Benjamin | البرمجة والتحليل التقني | خبير الكود |
| Lucas | الإبداع وتوليد المحتوى | خبير الإبداع |
عند إرسال استعلام معقد عبر واجهة برمجة تطبيقات الوكلاء المتعددين، يعمل الوكلاء الأربعة بالتوازي في وقت واحد، حيث يطبق كل منهم خبرته الخاصة، ليقوم Grok في النهاية بجمع النتائج وتلخيصها. هذه البنية أكثر كفاءة عند التعامل مع المهام المعقدة التي تتطلب قدرات متعددة الأبعاد.
القدرة 3: نافذة سياق بسعة 2 مليون Token
قفزت نافذة السياق في Grok 4.20 من 256 ألف Token في الجيل السابق Grok 4 إلى 2 مليون Token، وهي الأطول حالياً بين جميع نماذج API الرئيسية:
| النموذج | نافذة السياق | المقارنة |
|---|---|---|
| Grok 4.20 Beta | 2 مليون Token | الأطول في القطاع |
| GPT-5.4 (موسع) | 1 مليون Token | ضعف Grok |
| Claude Opus 4.5 | 200 ألف Token | 10 أضعاف Grok |
| Gemini 2.5 Pro | 1 مليون Token | ضعف Grok |
يعادل 2 مليون Token حوالي 1.5 مليون حرف صيني أو 3 مليون كلمة إنجليزية، وهو ما يكفي لاستيعاب رواية طويلة كاملة أو مستودع برمجيات ضخم.
🎯 نصيحة للمطورين: يتمتع Grok 4.20 Beta بمزايا فريدة في التحكم في الهلوسة وطول نافذة السياق. يمكنك عبر خدمة وكيل API الخاص بـ APIYI (apiyi.com) الوصول إلى Grok 4.20 بالإضافة إلى Claude وGPT، لمقارنة موثوقية ودقة النماذج المختلفة في مهامك العملية.
متغيرات نموذج Grok 4.20 Beta الثلاثة
عائلة نماذج Grok 4.20
أطلقت xAI ثلاثة متغيرات مختلفة من نموذج Grok 4.20، والتي تأتي بنفس التسعير تماماً ولكن بقدرات متنوعة:
| المتغير | معرف النموذج (Model ID) | القدرات الأساسية | سيناريوهات الاستخدام |
|---|---|---|---|
| بدون استنتاج (Non-Reasoning) | grok-4.20-beta-0309-non-reasoning | إجابات سريعة ومباشرة | المحادثات اليومية، المهام البسيطة |
| استنتاجي (Reasoning) | grok-4.20-beta-0309-reasoning | سلسلة استنتاج عميقة | التحليل المعقد، الرياضيات |
| متعدد الوكلاء (Multi-Agent) | grok-4.20-multi-agent-beta-0309 | 4 وكلاء يعملون بالتوازي | المهام المعقدة ومتعددة الأبعاد |
تحليل تسعير Grok 4.20
| بند التسعير | Grok 4.20 | Grok 4 (الجيل السابق) | التغير |
|---|---|---|---|
| المدخلات | $2/MTok | $3/MTok | انخفاض 33% |
| المخرجات | $6/MTok | $15/MTok | انخفاض 60% |
| المتغيرات الثلاثة | نفس السعر | – | اختر ما يناسبك |
يتمتع تسعير Grok 4.20 بتنافسية عالية جداً: 2 دولار للمدخلات و6 دولارات للمخرجات، وهو انخفاض بنسبة 33-60% مقارنة بالجيل السابق Grok 4. وبالمقارنة مع المنافسين: GPT-5.4 النسخة القياسية بسعر 2.5/15 دولاراً، بينما يعد Claude Opus 4.5 أغلى ثمناً. من بين النماذج في نفس الفئة السعرية، يتميز Grok 4.20 بأقل معدل هلوسة وأسرع أداء (247.8 رمز/ثانية).
بنية التعلم السريع (Rapid Learning) في Grok 4.20
إحدى التقنيات الفريدة في Grok 4.20 هي بنية التعلم السريع (Rapid Learning): حيث يقوم النموذج بتحديث قدراته تلقائياً كل أسبوع بناءً على بيانات استخدام المستخدمين الحقيقية، دون الحاجة لإصدار نسخ جديدة يدوياً. هذا يعني أن Grok 4.20 الذي تستخدمه سيستمر في التحسن بمرور الوقت—فنسخة شهر أبريل من Grok 4.20 أصبحت بالفعل أقوى من نسخة شهر فبراير.
💡 ميزة التمايز: التعلم السريع (Rapid Learning) خاص بـ Grok فقط—فالنماذج الأخرى تتطلب إصدار أرقام نسخ جديدة للتحديث، بينما يتطور Grok 4.20 باستمرار داخل نفس الإصدار. ولهذا السبب فإن "التكرار المستمر في أبريل" يعد أمراً بالغ الأهمية لمستخدمي Grok.
قدرات الوسائط المتعددة في Grok 4.20 Beta
مصفوفة الوسائط المتعددة الكاملة لـ Grok 4.20
| النمط | المدخلات | المخرجات | ملاحظات |
|---|---|---|---|
| النص | ✓ | ✓ | القدرة الأساسية |
| الصور | ✓ | ✓ | واجهة Grok Imagine البرمجية |
| الفيديو | ✓ | ✓ | توليد فيديو شامل (End-to-End) |
| الصوت | ✓ | ✓ | Grok Voice بزمن انتقال منخفض |
| الكود | ✓ | ✓ | تخصص وكيل Benjamin |
| البحث | – | ✓ | بحث فوري عبر الإنترنت |
قدرات Grok Voice الصوتية
تعد Grok Voice واحدة من أكثر قدرات الوسائط المتعددة تميزاً في Grok 4.20:
- صوت بزمن انتقال منخفض: دعم محادثات صوتية فورية بعشرات اللغات
- استدعاء الأدوات: إمكانية تفعيل استدعاء الأدوات والبحث في الوضع الصوتي
- بيانات فورية: الوصول إلى بيانات الإنترنت الحية أثناء المحادثات الصوتية
- واجهة برمجة تطبيقات الوكلاء (Agent API): يمكن دمجها في تطبيقات الطرف الثالث عبر API
هذا يجعل من Grok 4.20 ليس مجرد نموذج نصي، بل مساعد ذكاء اصطناعي شامل يمكنه "الاستماع، التحدث، الرؤية، والبحث".
توليد الصور والفيديو عبر Grok Imagine
أطلقت xAI في Grok 4.20 واجهة Grok Imagine البرمجية—وهي مجموعة أدوات موحدة لتوليد الفيديو والصوت بشكل شامل. تدعم توليد الصور والفيديوهات من الأوصاف النصية، وقد تم تحسين دقة تفعيل البحث عن الصور بشكل أكبر في تحديث شهر أبريل.

مقارنة بين Grok 4.20 Beta والمنافسين
Grok 4.20 مقابل GPT-5.4 مقابل Claude Opus 4.5
| بُعد المقارنة | Grok 4.20 Beta | GPT-5.4 | Claude Opus 4.5 |
|---|---|---|---|
| معدل الهلوسة | 78% (الأقل) | ~65% | ~70% |
| مؤشر الذكاء | 48 | ~55+ | ~55+ |
| نافذة السياق | 2 مليون Token | 272K-1M | 200K |
| سرعة الإخراج | 247.8 tok/s | ~100 tok/s | ~80 tok/s |
| سعر الإدخال | $2/MTok | $2.5/MTok | أعلى |
| سعر الإخراج | $6/MTok | $15/MTok | أعلى |
| الوكلاء المتعددون | 4 وكلاء أصليين | لا يوجد | لا يوجد |
| المحادثة الصوتية | دعم أصلي | محدود | لا يوجد |
| التحكم في الحاسوب | لا يوجد | دعم أصلي | محدود |
| تقييم البرمجة | متوسط إلى مرتفع | ممتاز | ممتاز |
نقاط قوة Grok 4.20: التحكم في الهلوسة، السرعة، التسعير، طول نافذة السياق، الوكلاء المتعددون، والمحادثة الصوتية.
نقاط ضعف Grok 4.20: الذكاء الخام/تقييم الاستنتاج، والتقييم المتخصص في البرمجة.
نصيحة الاختيار: إذا كنت تعطي الأولوية لدقة وموثوقية الإجابات، فإن Grok 4.20 هو خيارك الأول. أما إذا كنت تركز على القدرات البرمجية والاستنتاج المعقد، فإن Claude/GPT هما الأقوى.
🚀 نصيحة للمقارنة: يمكنك عبر APIYI (apiyi.com) الوصول إلى Grok 4.20 وGPT-5.4 وClaude في وقت واحد، باستخدام مفتاح API واحد للتبديل بحرية بين النماذج الثلاثة، مما يساعدك على العثور بسرعة على النموذج الأنسب لاحتياجاتك.
الوصول إلى API الخاص بـ Grok 4.20 Beta
الوصول السريع عبر APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# وضع Non-Reasoning (إجابة سريعة)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[{"role": "user", "content": "اشرح المبادئ الأساسية للحوسبة الكمومية"}]
)
print(response.choices[0].message.content)
عرض استدعاء وضعي Reasoning و Multi-Agent
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# وضع Reasoning (استنتاج عميق)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[{"role": "user", "content": "حلل نقاط المخاطر في سلسلة توريد رقائق الذكاء الاصطناعي العالمية"}]
)
# وضع Multi-Agent (4 وكلاء يعملون بالتوازي)
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[{
"role": "user",
"content": "اكتب تقريراً بحثياً حول آفاق تسويق الحوسبة الكمومية"
}]
)
# 4 وكلاء (Grok/Harper/Benjamin/Lucas) يعملون بالتوازي
print(response.choices[0].message.content)
💰 ميزة التكلفة: يعد تسعير Grok 4.20 البالغ $2/$6 من بين الأقل حالياً بين النماذج الرائدة. من خلال استدعاء API عبر APIYI (apiyi.com)، يمكنك تحسين التكاليف بشكل أكبر، مع دعم التبديل حسب الحاجة بين Grok وClaude وGPT وGemini.
الأسئلة الشائعة
س1: أي من متغيرات Grok 4.20 الثلاثة يجب أن أختار؟
للمحادثات اليومية، اختر Non-Reasoning (الأسرع)، وللتحليلات المعقدة اختر Reasoning (أكثر عمقاً)، أما للمهام المعقدة متعددة الأبعاد فاختر Multi-Agent (حيث تعمل 4 وكلاء بالتوازي). المتغيرات الثلاثة لها نفس التسعير (2 دولار / 6 دولار لكل مليون رمز)، ويمكنك التبديل بينها بحرية حسب المهمة. يمكنك استدعاء جميع المتغيرات باستخدام مفتاح API واحد من APIYI (apiyi.com).
س2: ماذا يعني أن Grok 4.20 لديه أقل معدل هلوسة؟
معدل عدم الهلوسة بنسبة 78% يعني أنه في الإجابات الواقعية، يعد Grok أقل عرضة "لاختلاق" المعلومات مقارنة بالنماذج الأخرى. بالنسبة للسيناريوهات التي تتطلب موثوقية عالية (الطب، القانون، الأكاديميا، قرارات الشركات)، فإن هذا الأمر له قيمة عملية أكبر من مجرد "مؤشر ذكاء" مرتفع. ومع ذلك، في سيناريوهات الكتابة الإبداعية والعصف الذهني، قد تكون "الهلوسة" المعتدلة ميزة إضافية.
س3: هل سيستمر تحديث Grok 4.20؟
نعم. يعتمد Grok 4.20 على بنية التعلم السريع (Rapid Learning)، حيث يتم تحسينه تلقائياً كل أسبوع بناءً على بيانات استخدام المستخدمين. لقد أدت تحديثات شهر أبريل إلى تحسين اتباع التعليمات، وتنسيق LaTeX، والبحث عن الصور. ستستمر القدرات تحت نفس معرف النموذج (Model ID) في التحسن دون الحاجة لانتظار رقم إصدار جديد. عند الاستدعاء عبر APIYI (apiyi.com)، ستستفيد تلقائياً من أحدث التحسينات.
ملخص
تقييم القيمة الجوهرية لنموذج Grok 4.20 Beta:
- أقل معدل هلوسة في الصناعة: معدل عدم هلوسة بنسبة 78%، مما يمنحه ميزة فريدة في السيناريوهات التي تتطلب موثوقية عالية.
- وكلاء متعددون أصليون (Native Multi-Agent): تعاون متوازٍ لـ 4 وكلاء (Grok/Harper/Benjamin/Lucas)، مما يرفع كفاءة المهام المعقدة.
- نافذة سياق فائقة الطول تصل إلى 2 مليون رمز: هي الأطول بين نماذج API السائدة، مع ميزة سرعة تصل إلى 247.8 رمز/ثانية.
- تطور مستمر: تحديثات تلقائية أسبوعية عبر التعلم السريع، حيث أصبح إصدار أبريل أقوى من إصدار فبراير الأول.
اتخذ Grok 4.20 Beta مساراً متميزاً؛ فهو لا يسعى ليكون الأقوى في كل شيء، بل يتصدر الصناعة في ثلاثة أبعاد: المصداقية، السرعة، والوكلاء المتعددون. نوصي بالوصول إلى Grok 4.20 بالإضافة إلى Claude وGPT عبر APIYI (apiyi.com)، حيث يمكنك استخدام مفتاح واحد للمقارنة بين نماذج متعددة والعثور على الحل الأنسب لسيناريوهات عملك.
📚 المراجع
-
تحديثات Grok 4.20 الرسمية من xAI: أحدث الإعلانات والميزات
- الرابط:
x.ai/news - الوصف: يتضمن سجل التحديثات المستمر والميزات الجديدة لنموذج Grok 4.20
- الرابط:
-
تقييم Artificial Analysis لنموذج Grok 4.20: تقييمات وبيانات من طرف ثالث مستقل
- الرابط:
artificialanalysis.ai/models/grok-4-20 - الوصف: يتضمن تحليلاً مفصلاً لمؤشر الذكاء، معدل الهلوسة، السرعة، والتسعير
- الرابط:
-
شرح مفصل للوكلاء المتعددين في Grok 4.20: مقارنة كاملة لـ 4 متغيرات من النموذج
- الرابط:
help.apiyi.com/en/grok-4-20-beta-4-models-multi-agent-reasoning-api-guide-en.html - الوصف: يتضمن سيناريوهات الاستخدام التفصيلية للنماذج التي تعتمد على الاستدلال (Reasoning)، النماذج العادية، والوكلاء المتعددين (Multi-Agent)
- الرابط:
-
قراءة شاملة لـ Grok 4.20 Beta: تحليل معمق للبنية والميزات
- الرابط:
buildfastwithai.com/blogs/grok-4-20-beta-explained-2026 - الوصف: يتضمن شرحاً مفصلاً لبنية التعلم السريع (Rapid Learning) وقدرات النموذج متعدد الوسائط
- الرابط:
المؤلف: فريق APIYI التقني
تبادل الخبرات: نرحب بمشاركتكم لتجاربكم مع Grok 4.20 في قسم التعليقات، وللمزيد من المعلومات حول دمج نماذج الذكاء الاصطناعي، يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com