مُلاحظة الكاتب: مقارنة متعمقة لأقوى 3 نماذج ذكاء اصطناعي لحل المسائل الرياضية في عام 2026، تتضمن بيانات معيارية موثوقة من AIME وMATH، لمساعدتك في العثور على نموذج الاستدلال الرياضي الأنسب.
يُعد اختيار نموذج الذكاء الاصطناعي الأمثل لحل المسائل الرياضية أحد أكثر القرارات أهمية للمطورين والطلاب. تقارن هذه المقالة بين أحدث نماذج الاستدلال الرياضي الصادرة في 2026: Gemini 3.1 Pro Preview، وClaude Sonnet 4.6، وGPT-5.4، وتقدم توصيات واضحة بناءً على نتائج الاختبارات المعيارية، والقدرة على الاستدلال، وسعر API، وسيناريوهات الاستخدام.
القيمة الأساسية: بعد قراءة هذه المقالة، ستعرف أي نموذج ذكاء اصطناعي تختار لمختلف سيناريوهات حل المسائل الرياضية، وكيفية استخدامه بأفضل تكلفة.

نظرة سريعة على نماذج الذكاء الاصطناعي لحل المسائل الرياضية الأساسية
قبل الدخول في التحليل التفصيلي، إليك جدول مقارنة للبيانات الأساسية لمساعدتك على فهم الاختلافات الرئيسية بين نماذج الذكاء الاصطناعي الثلاثة لحل المسائل الرياضية بسرعة.
| بُعد المقارنة | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| تاريخ الإصدار | 19 فبراير 2026 | أوائل 2026 | 6 مارس 2026 |
| AIME 2025 | 92% (بدون أدوات) | — | 100% (الدرجة الكاملة) |
| معيار MATH | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| سعر الإدخال | 2.00 دولار/1 مليون رمز | 3.00 دولار/1 مليون رمز | 2.50 دولار/1 مليون رمز |
| سعر الإخراج | 12.00 دولار/1 مليون رمز | 15.00 دولار/1 مليون رمز | 15.00 دولار/1 مليون رمز |
| التوصية الشاملة | ⭐ التوصية الأولى | ⭐ الخيار الأول للتعلم | ⭐ الخيار الأول للمسابقات |
ترتيب نماذج الذكاء الاصطناعي لحل المسائل الرياضية الموصى بها
من منظور القيمة الشاملة مقابل السعر، نقدم اقتراح الترتيب التالي:
- الأولوية: Gemini 3.1 Pro Preview: يتصدر معيار MATH بنسبة 95.1%، وهو الأقل سعرًا، ويتمتع بأقوى قدرات رياضية شاملة.
- الخيار الثاني: Claude Sonnet 4.6: قفزة في القدرات الرياضية بمقدار 27 نقطة مئوية، وعملية الحل واضحة وسهلة الفهم، ومناسبة لسيناريوهات التعلم.
- المستوى التنافسي: GPT-5.4: حصل على الدرجة الكاملة 100% في AIME 2025، ومناسب للمسابقات الرياضية عالية الصعوبة والبحث المتخصص.
🎯 نصيحة تقنية: يمكن استدعاء النماذج الثلاثة بشكل موحد عبر منصة APIYI (apiyi.com). نوصي باختبار كل نموذج على مسائل رياضية فعلية لتحديد النموذج الأنسب لاحتياجاتك.
شرح تفصيلي لقدرات حل المسائل الرياضية في Gemini 3.1 Pro Preview
Gemini 3.1 Pro Preview هو أحدث نموذج رئيسي أطلقته Google DeepMind في 19 فبراير 2026. هذه هي المرة الأولى التي تستخدم فيها Google زيادة إصدار ".1" (حيث كانت جميع التحديثات المتوسطة السابقة تستخدم ".5")، مما يشير إلى أن هذا التحديث يركز على ترقية قدرات الاستدلال الذكي بشكل موجه.
نتائج اختبارات معايير الرياضيات لـ Gemini 3.1 Pro
| اختبار المعيار | النتيجة | الشرح |
|---|---|---|
| MATH | 95.1% | اختبار رياضي شامل يغطي مجالات متعددة مثل الجبر والهندسة وحساب التفاضل والتكامل |
| AIME 2025 (بدون أدوات) | 92% | المسابقة الأمريكية للرياضيات، مستوى صعوبة مسابقة المدرسة الثانوية |
| AIME 2025 (تنفيذ الشفرة) | 100% | حصل الجيل السابق Gemini 3 Pro على الدرجة الكاملة بعد تفعيل تنفيذ الشفرة |
| GPQA Diamond | 94.3% | أسئلة وأجوبة علمية على مستوى الدراسات العليا، يتصدر جميع النماذج من نفس المستوى |
| ARC-AGI-2 | 77.1% | قدرات التفكير المجرد، ضعف الجيل السابق 3 Pro |
| MathArena Apex | يتقدم بشكل كبير | تحسن بأكثر من 20 ضعف مقارنة بالجيل السابق |
في 18 اختبار معيار رئيسي أعلنت عنها Google رسميًا، حقق Gemini 3.1 Pro المركز الأول في 12 منها. في مجال التفكير الرياضي، كان أداؤه البالغ 95.1% في معيار MATH بارزًا بشكل خاص، مما يعني أنه يتمتع بقدرات قوية جدًا في حل المسائل عبر جميع المجالات الفرعية للرياضيات مثل الجبر والهندسة والاحتمالات وحساب التفاضل والتكامل.
نظام التفكير ثلاثي المستويات في Gemini 3.1 Pro
يقدم Gemini 3.1 Pro ابتكارًا رئيسيًا في البنية – نظام التفكير ثلاثي المستويات:
- Low (الوضع السريع): يعالج العمليات الحسابية الرياضية البسيطة واستنتاج الصيغ، مع أسرع سرعة استجابة.
- Medium (الوضع المتوازن): طبقة وسيطة جديدة، تعالج المسائل الرياضية متوسطة الصعوبة، وتوازن بين السرعة والدقة.
- High (الوضع العميق): يعالج مشاكل الاستدلال متعددة الخطوات المعقدة، مثل المسائل الرياضية على مستوى المسابقات.
يتيح هذا النظام ثلاثي المستويات للمطورين توجيه المسائل الرياضية بمرونة بناءً على صعوبتها، دون الحاجة للاختيار بين "سريع لكن تقريبي" و"بطيء لكن دقيق". هذه الميزة المعمارية مفيدة بشكل خاص في السيناريوهات التي تعالج فيها دفعات من المسائل الرياضية بدرجات صعوبة مختلفة (مثل أنظمة التكيف في إصدار الأسئلة على منصات التعليم).
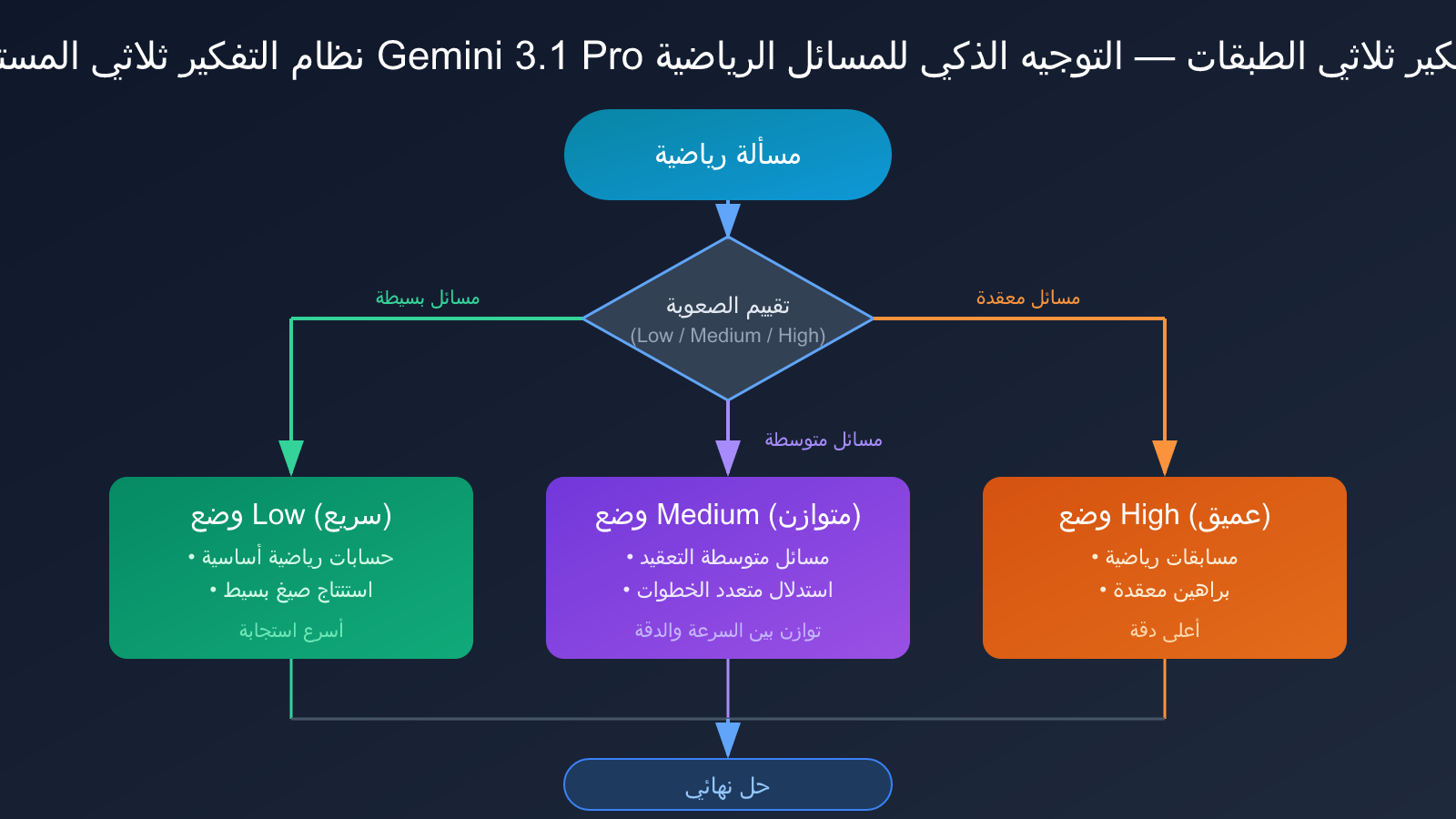
التجربة الفعلية لحل المسائل الرياضية باستخدام Gemini 3.1 Pro
يمكن تلخيص أداء Gemini 3.1 Pro Preview في حل المسائل الرياضية الفعلي بأنه "شامل ومستقر":
- مجال الجبر: عمليات متعددة الحدود، حل أنظمة المعادلات، إثبات المتباينات – تقريبًا بدون أخطاء، بفضل التغطية العالية لمعيار MATH بنسبة 95.1%.
- مجال الهندسة: سلسلة الاستدلال في الهندسة التحليلية والمجسمة كاملة، مع أداء ممتاز خاصة في مسائل الحسابات المتعلقة بنظام الإحداثيات.
- الاحتمالات والإحصاء: منطق الاستدلال في مسائل الاحتمال الشرطي والتوافيق والتقليب واضح، مع القدرة على معالجة الحسابات متعددة الخطوات المعقدة بشكل صحيح.
- حساب التفاضل والتكامل: حل التكاملات المحددة وغير المحددة دقيق، مع القدرة على التعرف على تقنيات التكامل الشائعة وتطبيقها بشكل صحيح.
لم يكن إنجاز Gemini 3.1 Pro بالحصول على المركز الأول في 12 من أصل 18 اختبار معيار رئيسي صدفة. فقد حصل على 57 نقطة في مؤشر الذكاء التحليلي الاصطناعي (Artificial Analysis Intelligence Index)، متساويًا مع GPT-5.4 (xhigh) في المركز الأول، متفوقًا بشكل كبير على المتوسط البالغ 28 نقطة، مما يعكس تفوقًا شاملاً في قدرات الاستدلال الذكي.
Claude Sonnet 4.6: شرح قدراته في حل المسائل الرياضية
Claude Sonnet 4.6 هو أحدث نموذج متوسط المدى من Anthropic، وقد حقق قفزة نوعية في قدرات التفكير الرياضي – حيث ارتفع من 62% في الجيل السابق Sonnet 4.5 إلى 89%، أي بزيادة قدرها 27 نقطة مئوية.
نتائج Claude Sonnet 4.6 في اختبارات قياس الأداء الرياضي
| اختبار قياس الأداء | Sonnet 4.6 | Sonnet 4.5 (الجيل السابق) | مقدار التحسن |
|---|---|---|---|
| الرياضيات الشاملة | 89% | 62% | +27 نقطة مئوية |
| ARC-AGI-2 | 58.3% | 13.6% | تحسن بمقدار 4.3 أضعاف |
| GPQA Diamond | 74.1% | — | تفكير علمي بمستوى الدراسات العليا |
| القدرات البرمجية | 79.6% | — | قريبة من 80.8% الخاصة بـ Opus 4.6 |
| التحليل المالي | 63.3% | — | الأفضل في فئته |
يمثل التحسن في القدرة الرياضية من 62% إلى 89% أحد أبرز التغييرات في Sonnet 4.6. وهذا يعني تحوله من "نموذج يرتكب أخطاءً أحيانًا في المسائل الرياضية" إلى "نموذج يمكنه التعامل بموثوقية مع الحسابات المعقدة".
آلية التفكير التكيفي في Claude Sonnet 4.6
من المزايا البارزة الأخرى في Claude Sonnet 4.6 آلية عمق التفكير التكيفي (Adaptive Thinking):
- المسائل البسيطة: استجابة سريعة، دون إهدار موارد التفكير. مثل: العمليات الحسابية الأساسية، حل المعادلات البسيطة.
- المسائل المتوسطة: توسيع سلسلة التفكير بشكل معتدل. مثل: العمليات الجبرية متعددة الخطوات، حساب الاحتمالات.
- المسائل المعقدة: تشغيل تلقائي لسلسلة تفكير عميقة. مثل: الرياضيات التوافقية، مسائل الإثبات، المسائل بمستوى المسابقات.
تكمن فائدة هذه الآلية التكيفية في الاستخدام العملي في أنك لست بحاجة إلى ضبط عمق التفكير يدويًا؛ فالنموذج سيحكم تلقائيًا على صعوبة المسألة الرياضية ويخصص موارد الحساب المناسبة، ليحقق التوازن الأمثل بين زمن الاستجابة والتكلفة.
الميزة الفريدة لـ Claude Sonnet 4.6: عملية الحل
في سيناريوهات حل المسائل الرياضية، يتمتع Claude Sonnet 4.6 بميزة فريدة معترف بها على نطاق واسع – وضوح عملية الحل. أشارت تقييمات متعددة إلى أن نماذج Claude تتفوق في شرح المفاهيم الرياضية. بالإضافة إلى ذلك، صمم Anthropic وضع التعلم (Learning Mode) خصيصًا لتوجيه عملية تفكير الطالب، بدلاً من تقديم الإجابة مباشرة.
هذا يجعل Claude Sonnet 4.6 مناسبًا بشكل خاص لـ:
- سيناريوهات التعليم الرياضي والتدريس.
- المتعلمين الذين يحتاجون إلى فهم خطوات الحل.
- الباحثين الذين يرغبون في التحقق من منهجية حل المسألة.
💡 نصيحة تعليمية: إذا كان احتياجك الأساسي هو "فهم عملية حل المسألة الرياضية" وليس مجرد الحصول على الإجابة، فإن Claude Sonnet 4.6 هو الخيار الأمثل. يمكنك الحصول على رصيد تجريبي مجاني من خلال APIYI على apiyi.com لتجربة مدى تفصيل عملية الحل.
GPT-5.4: شرح قدراته في حل المسائل الرياضية
GPT-5.4 هو أحدث نموذج رئيسي من OpenAI، صدر في 6 مارس 2026. وهو أول نموذج استدلالي من OpenAI يجمع في نموذج افتراضي واحد بين القدرات المتخصصة المتطورة، والقدرات البرمجية (المستمدة من GPT-5.3-Codex)، والتشغيل الأصلي للحاسوب، ونافذة سياق بسعة 1.05 مليون رمز.
نتائج GPT-5.4 في اختبارات قياس الأداء الرياضي
| اختبار قياس الأداء | النتيجة | الشرح |
|---|---|---|
| AIME 2025 | 100% (درجة كاملة) | مستوى مسابقات الرياضيات للمرحلة الثانوية، أداء مثالي |
| GSM8K | 99% | مسائل الرياضيات التطبيقية للمرحلة الابتدائية، أداء شبه مثالي |
| MATH | 88.6% | اختبار قياس الأداء الشامل للتفكير الرياضي |
| GPQA Diamond | 84.2% (قياسي) / 92.8% (تفكير عالٍ) | تفكير علمي بمستوى الدراسات العليا |
| ARC-AGI-2 | 73.3% (قياسي) / 83.3% (Pro) | قدرات التفكير المجرد |
| FrontierMath (الجيل السابق 5.2) | 40.3% | رقم قياسي جديد في الرياضيات المتطورة على مستوى الخبراء |
حقق GPT-5.4 نتيجة مذهلة بنسبة 100% في اختبار AIME 2025، مما يعني أنه يستطيع حل جميع المسائل عالية الصعوبة في المسابقة الأمريكية للمشاركة في الأولمبياد الرياضي بشكل مثالي. بالنسبة للمستخدمين الذين يحتاجون إلى حل مسائل رياضية بمستوى المسابقات، فإن هذا الأداء مقنع للغاية.
من الجدير بالملاحظة أن نتيجة GPT-5.4 في اختبار MATH كانت 88.6%، وهناك فجوة ملحوظة مقارنة بـ 95.1% الخاصة بـ Gemini 3.1 Pro. وهذا يشير إلى أنه على الرغم من الأداء المثالي لـ GPT-5.4 في المسائل الصعبة بمستوى المسابقات، إلا أنه ليس الأقوى في الاختبارات الشاملة التي تغطي مجالات رياضية واسعة.
خيارات تكوين التفكير في GPT-5.4
يقدم GPT-5.4 خيارات متعددة لتكوين التفكير لتناسب أنواعًا مختلفة من المسائل الرياضية:
- GPT-5.4 الإصدار القياسي: مناسب للحسابات الرياضية اليومية والمسائل متوسطة الصعوبة.
- GPT-5.4 Thinking: يُفعّل التفكير المتقدم، مناسب للاستدلالات المعقدة متعددة الخطوات وللإثباتات.
- GPT-5.4 Pro: تكوين الأداء الأعلى، حيث يصل إلى 83.3% في ARC-AGI-2، مناسب لأعلى سيناريوهات الصعوبة.
ومع ذلك، من المهم الانتباه إلى أن سعر GPT-5.4 Pro هو 30.00 دولارًا لكل مليون رمز إدخال + 180.00 دولارًا لكل مليون رمز إخراج، وهي تكلفة أعلى بكثير من الإصدار القياسي. بالنسبة لمعظم سيناريوهات حل المسائل الرياضية، فإن الإصدار القياسي كافٍ.
تجربة عملية لحل المسائل الرياضية باستخدام GPT-5.4
يُبهر أداء GPT-5.4 بشكل خاص في المسائل الرياضية بمستوى المسابقات:
- رياضيات المسابقات: مسائل شاملة في نظرية الأعداد، والتوافقيات، والهندسة بمستوى AMC/AIME تُحل بشكل شبه مثالي، والنتيجة الكاملة 100% في AIME تستحقها.
- مسائل الإثبات: القدرة على بناء سلاسل إثبات رياضية كاملة، منطقية ومترابطة بشكل طبيعي بين الخطوات.
- الرياضيات التطبيقية: نتيجة 99% في GSM8K تشير إلى أنه موثوق أيضًا في المسائل التطبيقية (مثل الحسابات الهندسية، النمذجة الاقتصادية).
- الاستدلال متعدد الخطوات: بفضل نافذة السياق الطويلة جدًا (1.05 مليون رمز)، يمكنه الحفاظ على سلسلة تفكير كاملة أثناء معالجة مسائل رياضية معقدة للغاية ومتعددة الخطوات.
تتمثل إحدى المزايا الفريدة لـ GPT-5.4 في أن الجيل السابق GPT-5.2 سجل رقمًا قياسيًا جديدًا بنسبة 40.3% في FrontierMath (الرياضيات المتطورة على مستوى الخبراء). وهذا يعني أن سلسلة GPT تمتلك أيضًا قدرة استكشافية معينة في المسائل الرياضية المتطورة حقًا وغير المحلولة، وهو ما يصعب على النماذج الأخرى تحقيقه حاليًا.
فهم اختبارات الأداء المعيارية لنماذج الذكاء الاصطناعي في حل المسائل الرياضية
قبل مقارنة نماذج الذكاء الاصطناعي لحل المسائل الرياضية، من الضروري فهم معنى وتركيز كل اختبار معياري للحكم بدقة أكبر على قدرات النموذج:
| الاختبار المعياري | الاسم الكامل | محتوى الاختبار | مستوى الصعوبة |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | أسئلة من المسابقة الأمريكية للرياضيات، تشمل نظرية الأعداد، التوافقيات، الهندسة، إلخ. | مستوى مسابقة المرحلة الثانوية (أفضل 5% من الطلاب) |
| MATH | Mathematics Aptitude Test of Heuristics | اختبار شامل يغطي 7 مجالات رئيسية مثل الجبر، الهندسة، التفاضل والتكامل | من مستوى المرحلة الثانوية إلى المستوى الجامعي |
| GSM8K | Grade School Math 8K | 8000 مسألة رياضية تطبيقية من المرحلة الابتدائية إلى الإعدادية | المستوى الأساسي |
| GPQA Diamond | Graduate-Level Google-Proof QA | أسئلة استدلال علمي على مستوى الدراسات العليا، مكتوبة من قبل خبراء المجال | مستوى الدراسات العليا/الدكتوراه |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | التعرف على أنماط منطقية جديدة تماماً، يختبر قدرة الاستدلال المجرد | مستوى الذكاء العام |
| FrontierMath | Frontier Mathematics | مسائل رياضية متقدمة على مستوى الخبراء، تتعلق بمجالات غير محلولة أو جديدة | مستوى الخبير/الباحث |
الفهم الأساسي: يركز اختبار AIME أكثر على مهارات الرياضيات على مستوى المسابقات والتفكير الإبداعي، بينما يركز اختبار MATH أكثر على قدرة التغطية الشاملة لمجالات واسعة. إذا حصل نموذج على درجة كاملة في AIME ولكن ليس على أعلى درجة في MATH (مثل GPT-5.4)، فهذا يشير إلى أنه قوي جداً في المسائل الذكية على مستوى المسابقات، ولكن تغطيته لبعض المجالات الأساسية قد تكون أقل قليلاً من النماذج التي تحقق درجات أعلى في MATH.
هذا هو السبب في أننا نوصي بـ Gemini 3.1 Pro Preview كخيار شامل أول – درجة 95.1% في MATH تعني أن أداءه أكثر توازناً عبر جميع المجالات الفرعية للرياضيات.
من المهم ملاحظة أن اختبار AIME 2025 المعياري أصبح الآن مشبعاً إلى حد كبير – حيث يمكن للعديد من النماذج الرائدة (المدمجة مع تنفيذ التعليمات البرمجية) تحقيق 95% أو أكثر، وحتى الدرجة الكاملة. لذلك، فإن الاختبارات المعيارية ذات الصعوبة الأعلى مثل MathArena Apex و FrontierMath هي التي يمكنها التمييز بشكل أفضل بين القدرات الرياضية الحقيقية للنماذج. في اختبار MathArena Apex، حقق Gemini 3.1 Pro Preview تحسناً يزيد عن 20 ضعفاً مقارنة بالجيل السابق، مما يظهر أساساً قوياً جداً للاستدلال الرياضي الداخلي.
بُعد آخر يستحق الاهتمام هو ARC-AGI-2 (قدرة الاستدلال المجرد). يقيم هذا الاختبار قدرة النموذج على التعرف على أنماط منطقية جديدة تماماً – وهي أنماط لم يصادفها النموذج مطلقاً أثناء التدريب. يتقدم Gemini 3.1 Pro Preview بنسبة 77.1%، مما يشير إلى أنه لا يستطيع فقط حل أنواع المسائل التي رآها من قبل، بل يمتلك أيضاً قدرة استدلال تعميم أقوى، وأداء أفضل عند مواجهة أنواع جديدة تماماً من المسائل الرياضية.
التطبيق العملي لاستدعاء نماذج الذكاء الاصطناعي لحل المسائل الرياضية عبر API
فيما يلي مثال بسيط جداً لشفرة برمجية لاستدعاء نماذج الذكاء الاصطناعي لحل المسائل الرياضية عبر API، حيث يمكن تشغيلها بـ 10 أسطر فقط:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # واجهة APIYI الموحدة
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # يمكن التبديل إلى claude-sonnet-4.6 أو gpt-5.4
messages=[{"role": "user", "content": "حل: إذا علم أن المتتابعة الحسابية {an} حدها الأول a1=2، وأساسها d=3، فما مجموع حدودها العشرين الأولى S20"}]
)
print(response.choices[0].message.content)
عرض شفرة استدعاء حل المسائل الرياضية الكاملة (بمقارنة متعددة النماذج)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
استدعاء نموذج ذكاء اصطناعي لحل مسألة رياضية
Args:
problem: وصف المسألة الرياضية
model: اسم النموذج، يدعم gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4
system_prompt: الموجه النظامي، يمكن من خلاله تحديد أسلوب الحل
Returns:
استجابة النموذج لحل المسألة
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # واجهة APIYI الموحدة
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "أنت خبير في حل المسائل الرياضية، يرجى حل المسائل الرياضية بخطوات واضحة، مع شرح أساس الاستدلال في كل خطوة."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# مثال للاستخدام: حل نفس المسألة باستخدام ثلاثة نماذج للمقارنة
problem = "في المثلث ABC، إذا علم أن a=5, b=7, C=60°، فما مساحة المثلث وطول الضلع الثالث c"
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"النموذج: {m}")
print(f"{='*50}")
result = solve_math(problem, model=m)
print(result)
اقتراح: احصل على رصيد تجريبي مجاني عبر APIYI على apiyi.com، حيث يمكنك باستخدام مفتاح API واحد استدعاء نماذج حل المسائل الرياضية الثلاثة المذكورة أعلاه، ومقارنة أدائها بسرعة على مسائلك الفعلية.
مقارنة أسعار ونسبة التكلفة إلى الأداء لنماذج الذكاء الاصطناعي لحل المسائل الرياضية
عند اختيار نموذج ذكاء اصطناعي لحل المسائل الرياضية، يعد السعر عاملاً لا يمكن تجاهله. فيما يلي مقارنة مفصلة لأسعار النماذج الثلاثة:
| بُعد السعر | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| سعر الإدخال | 2.00 دولار/مليون رمز | 3.00 دولار/مليون رمز | 2.50 دولار/مليون رمز |
| سعر الإخراج | 12.00 دولار/مليون رمز | 15.00 دولار/مليون رمز | 15.00 دولار/مليون رمز |
| السعر المختلط (3:1) | 4.50 دولار/مليون رمز | 6.00 دولار/مليون رمز | 5.63 دولار/مليون رمز |
| رسوم السياق الطويل | >200 ألف رمز: مضاعفة | لا يوجد | >272 ألف رمز: مضاعفة |
| نافذة السياق | 1 مليون رمز | نافذة قياسية | 1.05 مليون رمز |
| الحد الأقصى للإخراج | 65,536 رمز | إخراج قياسي | 128,000 رمز |
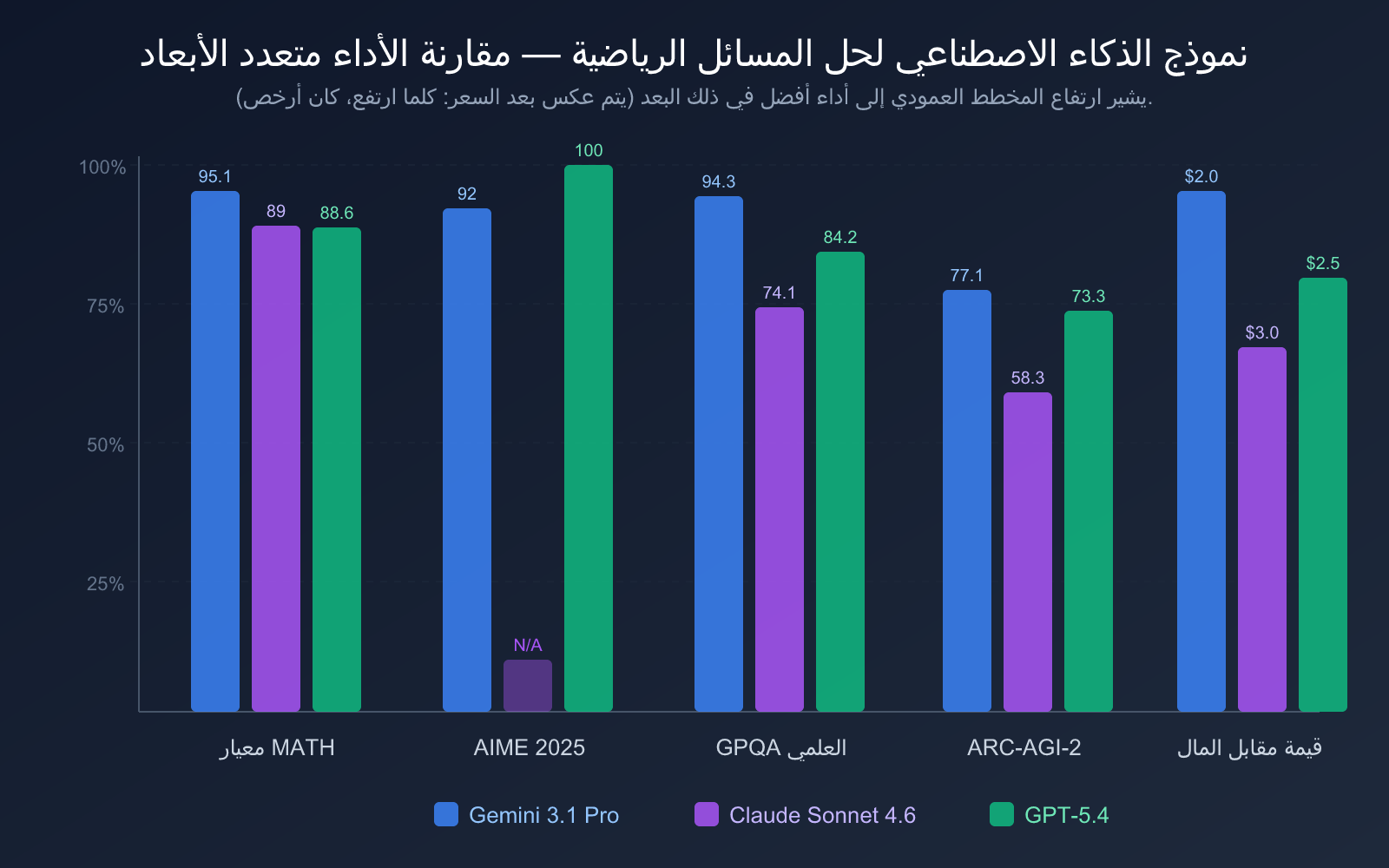
تحليل من منظور نسبة التكلفة إلى الأداء:
- Gemini 3.1 Pro Preview الأفضل من حيث نسبة التكلفة إلى الأداء: سعر الإدخال 2.00 دولار فقط لكل مليون رمز، مع أداء رائد في معيار MATH بنسبة 95.1%. وفقًا لتحليل Artificial Analysis، تبلغ تكلفة تشغيله حوالي 1/7.5 من تكلفة Claude Opus 4.6، بينما يتساوى أو يتفوق في معايير الرياضيات والبرمجة.
- Claude Sonnet 4.6 سعره معتدل: يظل التسعير 3.00 دولار/15.00 دولار كما هو في الإصدار السابق Sonnet 4.5، لكن القدرات الرياضية تحسنت بنسبة 27 نقطة مئوية، مما يحسن نسبة التكلفة إلى الأداء بشكل كبير.
- GPT-5.4 الإصدار القياسي سعره معقول: يقع التسعير 2.50 دولار/15.00 دولار ضمن النطاق المعقول، لكن استخدام GPT-5.4 Pro (30 دولارًا/180 دولارًا) سيزيد التكلفة بشكل كبير.
💰 نصيحة بشأن التكلفة: للاحتياجات اليومية لحل المسائل الرياضية، نوصي باستخدام Gemini 3.1 Pro Preview للحصول على أفضل نسبة تكلفة إلى أداء. إذا كنت بحاجة إلى تحسين التكلفة بشكل أكبر، يمكنك التفكير في استخدام منصة تجميع واجهات برمجة التطبيقات للحصول على خطة شحن أكثر مرونة.
تقدير التكلفة الفعلية لحل المسائل الرياضية
لمساعدتك على فهم اختلافات التكلفة بشكل أكثر وضوحًا، إليك تقدير تكلفة لسيناريو نموذجي لحل المسائل الرياضية:
افتراض السيناريو: حل 100 مسألة رياضية متوسطة الصعوبة يوميًا، مع متوسط استهلاك 500 رمز إدخال + 1500 رمز إخراج لكل مسألة.
| النموذج | تكلفة الإدخال اليومية | تكلفة الإخراج اليومية | التكلفة اليومية الإجمالية | التكلفة الشهرية (30 يومًا) |
|---|---|---|---|---|
| Gemini 3.1 Pro | 0.10 دولار | 1.80 دولار | 1.90 دولار | 57.00 دولار |
| GPT-5.4 | 0.13 دولار | 2.25 دولار | 2.38 دولار | 71.25 دولار |
| Claude Sonnet 4.6 | 0.15 دولار | 2.25 دولار | 2.40 دولار | 72.00 دولار |
| GPT-5.4 Pro | 1.50 دولار | 27.00 دولار | 28.50 دولار | 855.00 دولار |
| DeepSeek R2 | 0.03 دولار | 0.33 دولار | 0.36 دولار | 10.80 دولار |
من تقدير التكلفة يمكننا أن نرى بوضوح:
- تبلغ التكلفة الشهرية لـ Gemini 3.1 Pro Preview حوالي 57 دولارًا، وهي الأكثر اقتصادًا بين النماذج الرئيسية الثلاثة.
- تكلفة Claude Sonnet 4.6 و GPT-5.4 الإصدار القياسي متقاربة، حوالي 71-72 دولارًا شهريًا.
- تبلغ تكلفة GPT-5.4 Pro 855 دولارًا شهريًا، وهي مناسبة فقط للسيناريوهات التي تتطلب دقة قصوى مع ميزانية سخية.
- يقدم DeepSeek R2 حلًا تنافسيًا للغاية بتكلفة منخفضة جدًا تبلغ 10.80 دولارًا شهريًا.
مقارنة مؤشر الذكاء الشامل لنماذج الذكاء الاصطناعي في حل المسائل الرياضية
بالإضافة إلى الاختبارات المعيارية الفردية، يمكن لمؤشر الذكاء الشامل أن يعكس بشكل أكثر شمولية إمكانات النموذج في التفكير الرياضي. يُعد مؤشر الذكاء الاصطناعي التحليلي (Artificial Analysis Intelligence Index) أحد أكثر أنظمة التقييم الشامل موثوقية حاليًا، حيث يحسب النتيجة الشاملة للنموذج بناءً على أربعة أبعاد: التفكير، والمعرفة، والرياضيات، والبرمجة.
| النموذج | مؤشر الذكاء الشامل | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | التقييم الشامل |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | بطل مسائل المسابقات، يتصدر مؤشر الذكاء الشامل |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | يتصدر مؤشر الذكاء الشامل، الأكثر شمولية في الرياضيات |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | قدرات استثنائية في التفكير العلمي والتفسير |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | نسبة سعر/أداء ممتازة، خطوات الحل الأكثر وضوحًا |
من منظور مؤشر الذكاء الشامل، يتصدر كل من GPT-5.4 (xhigh) و Gemini 3.1 Pro Preview بنتيجة 57 نقطة، لكن لكل منهما نقاط قوة مختلفة:
- GPT-5.4: أداء مثالي (100%) في مسائل المسابقات مثل AIME، لكن أداؤه في المعيار الشامل MATH (88.6%) أقل قليلاً.
- Gemini 3.1 Pro: أكثر توازنًا في المعيار الشامل MATH (95.1%) وفي التفكير العلمي GPQA Diamond (94.3%).
هذا يعني أنه إذا كانت احتياجاتك الرياضية تميل نحو المسابقات والمسائل المتطرفة الصعوبة، فإن GPT-5.4 هو الخيار الأفضل. أما إذا كنت تحتاج إلى أداء مستقر يغطي مجالات رياضية واسعة، فإن Gemini 3.1 Pro Preview هو الخيار الأكثر أمانًا.
توصيات لنماذج الذكاء الاصطناعي لحل المسائل الرياضية حسب السيناريو
تتطلب سيناريوهات التطبيق الرياضية المختلفة نماذج مختلفة. فيما يلي توصيات مبنية على سيناريوهات الاستخدام الفعلية:
سيناريوهات الرياضيات لاختيار Gemini 3.1 Pro Preview
- منصات الدروس الخصوصية الرياضية الشاملة: يغطي جميع المجالات مثل الجبر والهندسة وحساب التفاضل والتكامل، حيث تبلغ قدرته الشاملة في MATH 95.1% وهي الأعلى.
- معالجة كميات كبيرة من المسائل الرياضية: الأقل سعرًا، يمكن لنظام التفكير ثلاثي المستويات التكيف تلقائيًا مع صعوبة السؤال، مما يخفض تكلفة المعالجة.
- سيناريوهات تجمع بين الرياضيات والحسابات العلمية: قدرة تفكير علمي تبلغ 94.3% في GPQA Diamond، مما يجعله مناسبًا للمسائل التي تجمع بين الفيزياء والكيمياء والرياضيات.
- المسائل الرياضية المرئية: في التعامل مع المسائل الرياضية التي تتضمن رسومًا بيانية وأشكالًا هندسية، تتمتع قدرات Gemini متعددة الوسائط بميزة.
سيناريوهات الرياضيات لاختيار Claude Sonnet 4.6
- التعليم الرياضي والدروس الخصوصية: خطوات الحل الأكثر وضوحًا، تم تصميم "وضع التعلم" خصيصًا لتوجيه الطالب في التفكير، حيث يوجه نحو التفكير ولا يعطي الإجابة مباشرة.
- تعلم خطوات حل المسائل: السيناريوهات التي تتطلب فهم "لماذا يتم الحل بهذه الطريقة"، حيث تُعتبر قدرة Claude على الشرح هي الأفضل بشكل عام. يفضل 70% من المستخدمين Sonnet 4.6 بدلاً من الإصدار السابق 4.5، مما يدل على قفزة نوعية في تجربة المستخدم.
- المساعدة في البحث الرياضي: مناسب للباحثين الذين يحتاجون إلى عمليات استنتاج مفصلة للتحقق من أفكارهم، حيث يمكن لعمق التفكير التكيفي المطابقة التلقائية لتعقيد المشكلة.
- الحسابات المكتبية والمالية: تحليل مالي بنسبة 63.3% وهو الأفضل في فئته، وأداء إنتاجية مكتبية GDPval-AA بنتيجة 1633 Elo يتفوق حتى على Opus 4.6 الأكثر تكلفة.
- الجمع بين البرمجة والرياضيات: قدرة برمجة تبلغ 79.6% تقترب من Opus 4.6، مما يجعله مناسبًا للمطورين الذين يحتاجون إلى كتابة برامج للحسابات الرياضية.
سيناريوهات الرياضيات لاختيار GPT-5.4
- مسابقات الرياضيات عالية الصعوبة: نتيجة كاملة 100% في AIME، النموذج المفضل لمسائل الرياضيات على مستوى المسابقات.
- التفكير الرياضي في المستندات الطويلة: نافذة سياق تبلغ 1.05 مليون رمز، مما يجعله مناسبًا لمعالجة المشكلات المعقدة التي تتطلب الكثير من المعلومات الخلفية الرياضية.
- البحث الرياضي المتخصص: حقق الإصدار السابق GPT-5.2 رقمًا قياسيًا جديدًا بنسبة 40.3% في FrontierMath، مما يدل على قدرات رياضية متقدمة على مستوى الخبراء.
- التمويل الاستثماري والكمي: نتيجة عالية تبلغ 87.3% في مهام النمذجة المصرفية الاستثمارية، مما يجعله مناسبًا لسيناريوهات الرياضيات المالية المتطورة.
استراتيجية الاستخدام المختلط: أفضل تركيبة لنماذج حل المسائل الرياضية
في بيئات الإنتاج الفعلية، تعتمد العديد من الفرق استراتيجيات استخدام مختلطة لتحقيق أفضل النتائج:
الاستراتيجية الأولى: التوجيه حسب مستوى الصعوبة
- المسائل الأساسية (الحساب، المعادلات البسيطة) → وضع Gemini 3.1 Pro Low، الأقل تكلفة.
- المسائل المتوسطة (تفكير متعدد الخطوات، مسائل تطبيقية) → وضع Claude Sonnet 4.6 التكيفي، خطوات الحل واضحة.
- المسائل عالية الصعوبة (مسابقات، براهين) → وضع التفكير GPT-5.4، أعلى دقة.
الاستراتيجية الثانية: التحقق المتبادل
- استخدام Gemini 3.1 Pro أولاً لحل المسائل بسرعة (منخفض التكلفة، سريع).
- التحقق من النتائج الرئيسية مرة ثانية باستخدام GPT-5.4 (دقة عالية).
- عند الحاجة لشرح النتيجة للمستخدم، إعادة صياغتها باستخدام Claude Sonnet 4.6 (تعبير واضح).
🚀 اقتراح للتنفيذ: يمكن تنفيذ استراتيجية الاستخدام المختلط المذكورة أعلاه بسهولة من خلال منصة APIYI على apiyi.com، حيث يمكن باستخدام مفتاح API واحد استدعاء جميع النماذج، مع التبديل بينها فقط من خلال معلمة
modelفي الكود.
توصيات لاختيار نماذج الذكاء الاصطناعي لحل المسائل الرياضية
بناءً على التحليل السابق، إليك توصيات لاختيار النموذج المناسب لمختلف فئات المستخدمين:
| نوع المستخدم | النموذج الموصى به | السبب |
|---|---|---|
| الطلاب/المتعلمون الذاتيون | Claude Sonnet 4.6 | عملية الحل واضحة، ووضع التعلم (Learning Mode) يوجه التفكير |
| مطورو المنصات التعليمية | Gemini 3.1 Pro Preview | أقوى قدرات شمولية، وأقل سعر، وتفكير ثلاثي الطبقات يتناسب مع مستويات الصعوبة |
| المتسابقون/المدربون في المسابقات | GPT-5.4 | حصل على الدرجة الكاملة في AIME، أقوى قدرة على حل المشكلات على مستوى المسابقات |
| الباحثون العلميون | Gemini 3.1 Pro Preview | حصل على 94.3% في GPQA Diamond، قدرة رائدة في المجالات العلمية والرياضية المتقاطعة |
| المعالجة الدفعية للشركات | Gemini 3.1 Pro Preview | أفضل قيمة مقابل السعر، سعر الإدخال $2.00/1M رموز |
| فرق الكم المالي | GPT-5.4 | حصل على 87.3% في نمذجة البنوك الاستثمارية، أقوى في سيناريوهات الرياضيات المالية |
💡 نصيحة للاختيار: يعتمد اختيار نموذج الذكاء الاصطناعي المناسب لحل المسائل الرياضية بشكل أساسي على سيناريو التطبيق الخاص بك. إذا كنت غير متأكد من النموذج الأنسب، نوصي باستخدام منصة APIYI على
apiyi.comلاختبار النماذج الثلاثة على نفس المسألة الرياضية، واتخاذ القرار النهائي بناءً على جودة الحل وسرعة الاستجابة. تدعم المنصة استدعاء واجهة موحدة، مما يسهل المقارنة السريعة والتبديل بين النماذج.
نماذج أخرى جديرة بالاهتمام لحل المسائل الرياضية
بالإضافة إلى النماذج الرئيسية الثلاثة المذكورة أعلاه، هناك عدة نماذج أخرى للذكاء الاصطناعي لحل المسائل الرياضية تستحق الاهتمام في سيناريوهات محددة:
| اسم النموذج | AIME 2025 | الميزة الأساسية | سعر API (إدخال/إخراج) | السيناريو المناسب |
|---|---|---|---|---|
| DeepSeek R2 | تفوق على Gemini 3.1 Pro | أفضل قيمة مقابل السعر | $0.55/$2.19 لكل 1M | المعالجة الدفعية للمسائل الرياضية الحساسة للميزانية |
| Claude Opus 4.6 | — | حصل على 91.3% في GPQA، أعمق تفسير | $15/$75 لكل 1M | البحث العلمي المتقدم والاستدلال العميق |
| Qwen3-235B | 89.2% | أقوى نموذج مفتوح المصدر | تكلفة النشر الذاتي | السيناريوهات التي تتطلب نشرًا خاصًا |
| DeepSeek R1 | حوالي 87.5% | معيار مفتوح المصدر، 671B MoE | تكلفة النشر الذاتي | البحث المجتمعي والتطوير الثانوي مفتوح المصدر |
| MiMo-V2-Flash | 94.1% | تكلفة الاستدلال 2.5% فقط من تكلفة Claude | منخفضة جدًا | الاستدلال واسع النطاق منخفض التكلفة |
من بينها، DeepSeek R2 يستحق اهتمامًا خاصًا، حيث تفوق على Gemini 3.1 Pro Preview في اختبار AIME، بينما سعره حوالي ربع سعر الأخير فقط. إذا كان سيناريو حل المسائل الرياضية الخاص بك حساسًا للغاية للميزانية، فإن DeepSeek R2 خيار تنافسي للغاية.
أما MiMo-V2-Flash فقد حقق درجة عالية تبلغ 94.1% في AIME 2025، بينما تبلغ تكلفة الاستدلال 2.5% فقط من تكلفة Claude، مما يجعله مناسبًا جدًا لمنصات تكنولوجيا التعليم التي تحتاج إلى معالجة دفعية واسعة النطاق للمسائل الرياضية.
نصائح لتحسين الموجهات (Prompts) لنماذج حل المسائل الرياضية
بغض النظر عن النموذج الذي تختاره، يمكن للموجهات الجيدة أن تحسن بشكل كبير من جودة حل المسائل الرياضية. إليك نصائح مجربة لتحسين الموجهات:
- تحديد نوع المسألة بوضوح: في الموجه، قم بتسمية "هذه مسألة في الرياضيات التوافقية" أو "هذه مسألة في الهندسة التحليلية"، لمساعدة النموذج على استدعاء استراتيجية الحل الصحيحة.
- طلب حل خطوة بخطوة: أضف "يرجى اشتقاق الحل خطوة بخطوة، مع ذكر النظرية أو الصيغة المستخدمة في كل خطوة"، لتحسين قابلية قراءة عملية الحل.
- تحديد تنسيق الإخراج: مثل "يرجى إخراج الصيغ الرياضية بتنسيق LaTeX" أو "تحديد الإجابة النهائية داخل مربع".
- توفير قيود السياق: مثل "افترض أن x عدد صحيح موجب" أو "أوجد الحل في نطاق الأعداد الحقيقية"، لتجنب قيام النموذج بإجراء مناقشات تصنيفية غير ضرورية.
- التحقق المتقاطع باستخدام نماذج متعددة: للنتائج الرئيسية، استخدم نماذج مختلفة للتحقق من اتساق الإجابات، لزيادة درجة الثقة.
الأسئلة الشائعة
س1: هل نتائج اختبارات معيارية (Benchmark) لنماذج الذكاء الاصطناعي لحل المسائل الرياضية موثوقة؟
توفر الاختبارات المعيارية أساسًا موحدًا للمقارنة الأفقية، لكن الفعالية الفعلية تتأثر أيضًا بعوامل مثل نوع المسألة وجودة الموجه (Prompt). تعتبر AIME و MATH حاليًا أكثر المعايير موثوقية للاستدلال الرياضي، وهي معترف بها على نطاق واسع من قبل الأوساط الأكاديمية والصناعية. نوصي، بالإضافة إلى الرجوع إلى بيانات الاختبارات المعيارية، بإجراء اختبارات باستخدام مسائلك الفعلية للتحقق من الأداء.
س2: أنا طالب، أي نموذج ذكاء اصطناعي لحل المسائل الرياضية يجب أن أختار؟
نوصي باختيار Claude Sonnet 4.6 كخيار أول. عملية حله للمسائل هي الأكثر وضوحًا، حيث يحتوي كل خطوة على شرح استدلالي واضح، مما يجعله مثاليًا للتعلم وفهم منهجيات حل المسائل الرياضية. يمكن لوظيفة "وضع التعلم" (Learning Mode) من Anthropic أيضًا توجيهك للتفكير بنفسك، بدلاً من تقديم الإجابة مباشرة. إذا واجهت مسابقة صعبة بشكل خاص، يمكنك التبديل إلى GPT-5.4 للحصول على المساعدة.
س3: كيف يمكنني البدء بسرعة في اختبار نماذج الذكاء الاصطناعي هذه لحل المسائل الرياضية؟
نوصي باستخدام منصة تجميع واجهات برمجة التطبيقات (API) التي تدعم واجهة موحدة متعددة النماذج لإجراء الاختبارات:
- قم بزيارة APIYI (apiyi.com) وإنشاء حساب
- احصل على مفتاح API والرصيد التجريبي المجاني
- استخدم نموذج كود Python المقدم في هذه المقالة، وقم بتعديل معلمة
modelللتبديل بين النماذج المختلفة - اختبر النماذج الثلاثة باستخدام نفس المسألة الرياضية، وقارن جودة الحل وسرعة الاستجابة
س4: هل تدعم نماذج الذكاء الاصطناعي هذه لحل المسائل الرياضية إخراج الصيغ بتنسيق LaTeX؟
تدعم النماذج الثلاثة إخراج الصيغ الرياضية بتنسيق LaTeX. ما عليك سوى إضافة "يرجى إخراج جميع الصيغ الرياضية بتنسيق LaTeX" إلى الموجه (Prompt). يكون تنسيق LaTeX في Gemini 3.1 Pro و GPT-5.4 أكثر دقة، بينما يقدم Claude Sonnet 4.6 شرحًا نصيًا أكثر تفصيلاً بين الصيغ. بالنسبة للسيناريوهات التي تحتاج فيها إلى نسخ الصيغ مباشرة إلى الأوراق البحثية، نوصي باستخدام Gemini أو GPT.
س5: هل يمكن لنماذج الذكاء الاصطناعي لحل المسائل الرياضية معالجة المسائل الرياضية الموجودة في الصور؟
يدعم كل من Gemini 3.1 Pro Preview و GPT-5.4 الإدخال متعدد الوسائط، مما يسمح لك برفع صور تحتوي على مسائل رياضية لحلها مباشرة. يتفوق Gemini بشكل خاص في معالجة الصور التي تحتوي على أشكال هندسية وصيغ مكتوبة بخط اليد. يدعم Claude Sonnet 4.6 أيضًا إدخال الصور، ولكنه أقل قليلاً من Gemini في التعرف على الأشكال الهندسية المعقدة. إذا كانت مسائلك الرياضية تظهر غالبًا في شكل صور (مثل البحث عن المسائل بالتقاط الصور)، فإن Gemini 3.1 Pro Preview هو الخيار الأفضل.
الخلاصة
النقاط الأساسية لاختيار نموذج الذكاء الاصطناعي لحل المسائل الرياضية:
- الخيار الأول للقدرات الشاملة: Gemini 3.1 Pro Preview: يتصدر بشكل شامل بنتيجة 95.1% في اختبار MATH، وأفضل سعر (2.00 دولار لكل مليون رمز)، ونظام تفكير ثلاثي المستويات يتكيف بمرونة مع الصعوبات المختلفة.
- الخيار الأول للتعلم والفهم: Claude Sonnet 4.6: قفزة في القدرات الرياضية بنسبة 27 نقطة مئوية إلى 89%، خطوات حل واضحة، وعمق تفكير تكيفي يوازن بين التكلفة والجودة.
- الخيار الأول لمسائل المسابقات الصعبة: GPT-5.4: نتيجة كاملة 100% في اختبار AIME 2025، سياق طويل جدًا (1.05 مليون رمز)، قدرات استدلالية عالية الصعوبة لا مثيل لها.
لا يوجد نموذج واحد هو الأفضل في جميع السيناريوهات الرياضية. يمكن تلخيص المشهد التنافسي لنماذج الذكاء الاصطناعي لحل المسائل الرياضية لعام 2026 على النحو التالي:
- التغطية الشاملة: يحتكر Gemini 3.1 Pro Preview موقع الخيار الأول الشامل بنتيجة 95.1% في اختبار MATH وأقل سعر.
- التعليم والتعلم: بفضل قفزته الرياضية البالغة 27 نقطة مئوية وقدرته الفائقة على شرح الحلول، أصبح Claude Sonnet 4.6 الخيار الأفضل في سيناريوهات التعليم.
- مسابقات المستوى المتقدم: بقدرة مطلقة بنتيجة كاملة في اختبار AIME، لا ينافس GPT-5.4 في مجال المسابقات الرياضية عالية الصعوبة.
- الأولوية للميزانية: يقدم DeepSeek R2 قدرات استدلال رياضية قابلة للمقارنة بأقل من ربع سعر Gemini.
الاستراتيجية الأكثر حكمة هي اختيار النموذج المناسب بناءً على احتياجاتك الفعلية، أو حتى استخدام عدة نماذج مختلطة للمسائل ذات الصعوبات المختلفة، والاستفادة الكاملة من المزايا الفريدة لكل نموذج.
نوصي باستخدام APIYI (apiyi.com) لاختبار ومقارنة هذه النماذج بسرعة. توفر المنصة رصيدًا مجانيًا وواجهة برمجة تطبيقات (API) موحدة، حيث يمكنك من خلال اتصال واحد استدعاء جميع نماذج الاستدلال الرياضي الرئيسية بمرونة، وتحقيق استراتيجية استخدام متعددة النماذج بسهولة.
📚 مراجع
-
بطاقة نموذج Google DeepMind Gemini 3.1 Pro: البيانات الأساسية الرسمية والتفاصيل التقنية
- الرابط:
deepmind.google/models/model-cards/gemini-3-1-pro/ - الشرح: يحتوي على نتائج اختبارات قياس الأداء الكاملة وشرح للهيكلية
- الرابط:
-
ملاحظات إصدار Anthropic Claude Sonnet 4.6: تفاصيل تحسين قدرات التفكير الرياضي
- الرابط:
docs.anthropic.com - الشرح: يحتوي على بيانات مقارنة بين Sonnet 4.6 والإصدارات السابقة وشرح لآلية التفكير التكيفي
- الرابط:
-
إعلان إصدار OpenAI GPT-5.4: أحدث ميزات النموذج والبيانات الأساسية
- الرابط:
openai.com/index/introducing-gpt-5-4/ - الشرح: يحتوي على نتائج اختبارات قياس الأداء الكاملة لـ GPT-5.4 وشرح لتكوين التفكير
- الرابط:
-
تقييم نماذج Artificial Analysis: منصة مقارنة قياسية مستقلة من طرف ثالث
- الرابط:
artificialanalysis.ai/evaluations/aime-2025 - الشرح: يوفر قوائم تصنيف وتحليلات مستقلة لاختبارات قياسية مثل AIME 2025
- الرابط:
-
قائمة تصنيف معيار AIME 2025: مقارنة موثوقة لقدرات التفكير الرياضي
- الرابط:
vals.ai/benchmarks/aime - الشرح: بيانات قائمة تصنيف مستمرة التحديث لمعايير التفكير الرياضي للذكاء الاصطناعي
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بمشاركتك لتجربتك في استخدام الذكاء الاصطناعي لحل المسائل الرياضية في قسم التعليقات. يمكنك زيارة مركز وثائق APIYI docs.apiyi.com لمزيد من دروس استدعاء النماذج.