一个值得开发者关注的更新~ 字节跳动 Dola 基础模型家族在 2026 年 4 月 28 日上线了首款全模态(Omnimodal)理解模型 Seed-2.0-lite-260428,统一支持视频、图像、音频与文本四种模态的原生输入。这是 Dola Seed 家族中第一个能"既看得见又听得见"的模型,并在 Agent、Coding、GUI 等任务上同步做了增强。本文基于 BytePlus ModelArk 官方规格与 ByteDance Seed 公开基准,结合 API易 apiyi.com 的接入实测,系统讲解模型能力、音频理解细节与典型应用场景。

一、Seed-2.0-lite-260428 是什么:核心定位与升级要点
Seed-2.0-lite-260428 是 ByteDance Seed 在 2026 年 4 月 28 日发布的一次重要迭代,基础模型沿用了 3 月初发布的 Seed-2.0-Lite,但首次把"音频输入"作为原生能力加入,从而把这条产品线推进到真正的"全模态(Omnimodal)"阶段。模型名称中的 260428 即对应 2026 年 4 月 28 日的版本号。
1.1 来自字节 Dola 家族的首个全模态模型
在此前的 Dola Seed 家族里,文本与多模态能力是分别放在不同分支的。Seed-2.0-lite-260428 把视频、图像、音频与文本统一在同一个模型里推理,意味着它可以同时"看视频画面"和"听音频内容",并据此进行联合判断与时序检索。这种统一架构对 Agent 类应用尤为关键,因为很多真实任务(例如视频审核、会议总结、客服质检)天然需要跨模态推理。
1.2 模型的核心规格速览
下表整理了 Seed-2.0-lite-260428 当前在 BytePlus ModelArk 上的核心参数,便于读者快速判断是否符合自家业务需求。
| 规格项 | 具体参数 |
|---|---|
| API 模型 ID | seed-2-0-lite-260428 |
| 模型家族 | ByteDance Seed / Dola |
| 发布日期 | 2026-04-28 |
| 上下文窗口 | 262,144 tokens(约 256K) |
| 最大输出 | 131,072 tokens(约 128K) |
| 输入模态 | 文本 + 图像 + 视频 + 音频 |
| 输入价格 | $0.25 / M tokens |
| 输出价格 | $2.00 / M tokens |
| 接口兼容 | OpenAI Compatible API |
二、Seed-2.0-lite-260428 的全模态理解 4 项关键能力
模型的全模态能力不是简单地把多种输入"接进来",而是通过统一表征做联合推理。官方文档把它的核心能力概括为四个方向。
2.1 音视频联合推理与时序检索
模型可以同时分析视频中的视觉与音频信息,准确判断"看到的画面"与"听到的声音"是否一致。例如可以判断一段视频里的人物表情是否与说话情绪相符,或者画面中的物体动作是否对应了正确的音效。这种音视频对齐能力,在视频审核、深度伪造检测等场景下非常实用。
2.2 视频深度分解与长时序跟踪
针对长视频,Seed-2.0-lite-260428 支持跨多个时间段抽取关键线索,持续追踪人物与事件进展,并在多帧之间进行多步推理,重建事件关系与行为上下文。比起逐帧描述的传统做法,它的"长时序理解"能力更适合监控视频复盘、纪录片剪辑助手等任务。
2.3 增强的 Agent 与编码能力
模型在复杂长时序任务上具备稳定可靠的执行能力,并具备深度全栈开发能力。这意味着开发者可以把它接入 Agent 框架,执行包含规划、调用工具、回看历史步骤、生成代码的完整闭环,而不必把任务拆分给多个不同模型。
2.4 GUI 理解与操作执行的统一接口
GUI 能力被整合到同一个接口里,模型既能理解屏幕截图(按钮、表单、菜单),也能输出操作指令(点击坐标、键入文本)。这对自动化测试、桌面 Agent 与 RPA 类应用是直接的能力升级。
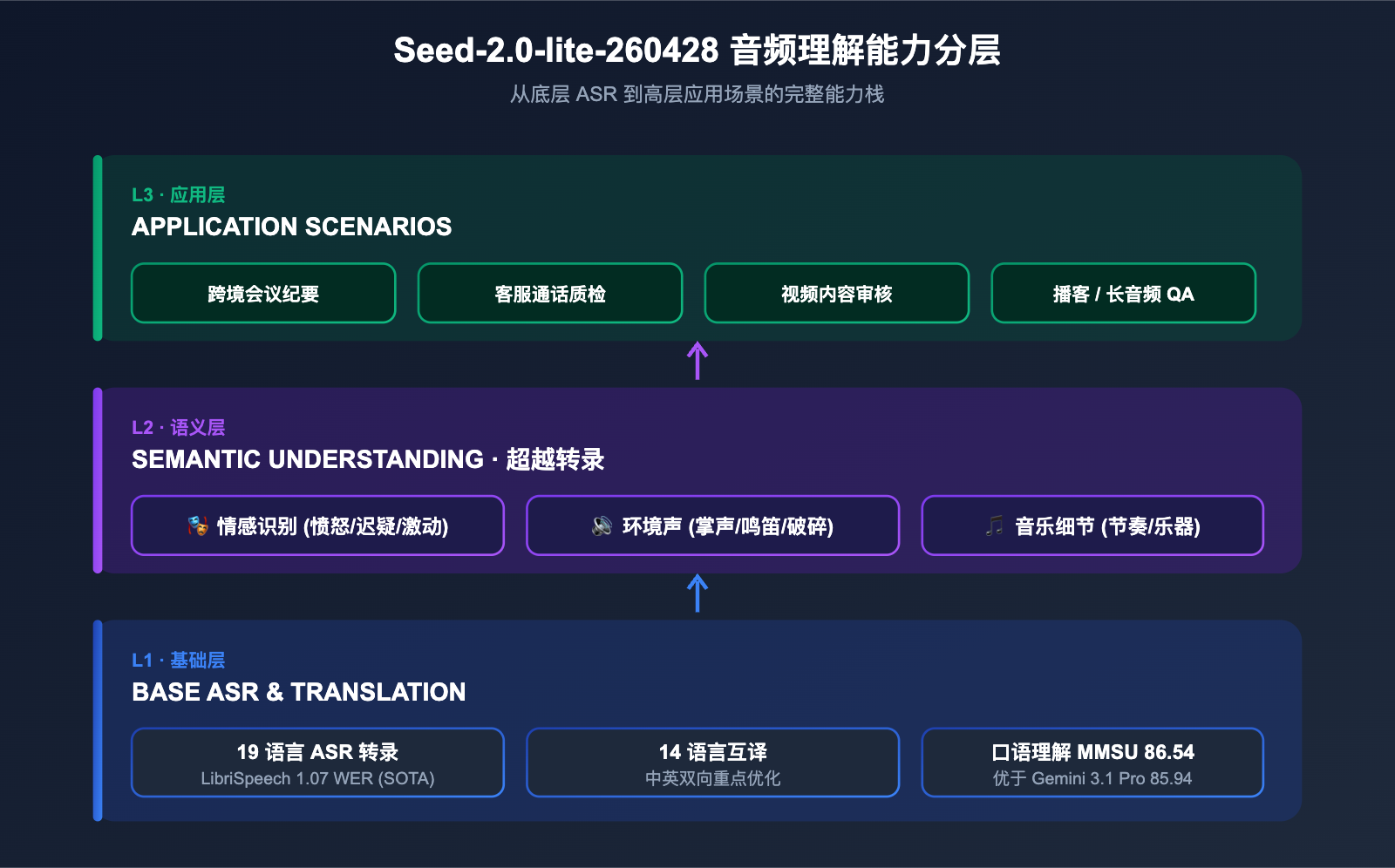
三、Seed-2.0-lite-260428 的音频理解能力深度解析
音频是这一次更新最大的差异化能力,所以单独展开讲。模型在多项主流音频基准上交出了相当亮眼的成绩。
3.1 主流音频基准的实测分数
下表汇总了 ByteDance Seed 官方公开的基准成绩,涵盖语音识别(ASR)、口语理解、野外语音场景三个维度。
| 基准 | 任务类型 | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | 英文 ASR(干净) | 1.07 WER |
| LibriSpeech test-other | 英文 ASR(噪声) | 2.17 WER |
| WenetSpeech test-net | 中文 ASR(网络) | 4.47 WER |
| WenetSpeech test-meeting | 中文会议 ASR | 5.31 WER |
| Fleurs(15 语言) | 多语种 ASR | 74.70 |
| MMSU | 口语理解 | 86.54 |
| WildSpeech | 野外语音 | 75.81 |
LibriSpeech test-clean 上 1.07 的 WER 已经处于业界顶尖水准,优于公开 Whisper large-v3 的同类成绩;MMSU 与 WildSpeech 分数也略高于 Gemini 3.1 Pro 的公开数据,说明模型在"理解"层面同样达到主流旗舰水平,而不仅仅是"听写"。
3.2 19 种语言转录与 14 种语言互译
官方文档说明,模型支持 19 种语言的语音转录与 14 种语言之间的互译,其中中英双向翻译被列为重点优化方向。这意味着同一段多语种会议录音,模型可以输出统一语言的字幕与翻译,适合跨境团队、跨境电商客服等场景。
3.3 超越"转录":情感、环境声与音乐细节
与传统 ASR 模型最大的不同,是 Seed-2.0-lite-260428 还能捕捉超出"文字内容"之外的语义层信息:说话人的情绪波动(愤怒、迟疑、激动)、背景环境声(玻璃破碎、掌声、汽车鸣笛)、音乐细节(节奏、乐器、风格)。这些维度对于客服质检、内容审核、音乐推荐等业务都有直接价值。
🎯 接入建议:在跨境会议纪要、客服质检、视频内容审核等需要"音频 + 文本"协同的场景里,我们建议直接通过 API易 apiyi.com 调用 Seed-2.0-lite-260428,一个 base_url 即可同时获得多模态推理与 256K 长上下文的双重收益,无需自建语音管线。
四、Seed-2.0-lite-260428 与主流多模态模型的横向对比
要判断这款模型在 2026 年的位置,最好的方式是把它和 GPT-4o、Gemini 3 Pro 等同期旗舰多模态模型放在一起对比。
4.1 主流多模态模型能力对照
| 维度 | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| 文本输入 | ✓ | ✓ | ✓ |
| 图像输入 | ✓ | ✓ | ✓ |
| 视频输入 | ✓ | ✓ | ✓ |
| 音频输入 | ✓ | ✓ | ✓ |
| 上下文窗口 | 262K | 128K | 1M |
| 输入价格 / M | $0.25 | $2.50 | $1.25 |
| 输出价格 / M | $2.00 | $10.00 | $10.00 |
| 音频情感识别 | ✓ | ✓ | ✓ |
| 中文音频优化 | 强(WenetSpeech 优化) | 一般 | 一般 |
可以看出,Seed-2.0-lite-260428 的核心优势是"价格 + 中文音频 + 256K 长上下文"的组合,在多语种音视频处理、长会议复盘等任务上的性价比尤为突出。GPT-4o 与 Gemini 3 Pro 仍然在英文综合能力与生态广度上具备优势,适合通用场景。

🎯 选型建议:如果你的业务以中文音视频处理为主、对成本敏感,Seed-2.0-lite-260428 是当下性价比极高的选择;如果是英文为主或重度多语种创意生成,可以通过 API易 apiyi.com 统一网关同时接入这三家旗舰,按场景做路由。
五、通过 APIYI 调用 Seed-2.0-lite-260428 的快速上手
模型完全兼容 OpenAI 风格接口,迁移成本极低。下面给出一个极简的调用示例,用于把一段图像或音频转成结构化描述。
5.1 OpenAI 兼容接口的最小示例
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "请描述这段音频的内容、情绪与背景声。"},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
把 base_url 指向 API易 apiyi.com 的统一接入端点,再切换 model 即可在同一个 SDK 里调用 Seed-2.0-lite-260428 与其他多模态模型,业务侧无需重写代码。
5.2 适合 Seed-2.0-lite-260428 的典型应用场景
下表整理了几类典型场景,以及它们能从这款模型的"音频 + 视频 + 文本统一推理"特性中获得什么收益。
| 应用场景 | 关键能力 | 业务价值 |
|---|---|---|
| 跨境会议纪要 | 19 语言 ASR + 14 语言翻译 + 256K 上下文 | 多语种会议一键转双语纪要 |
| 客服通话质检 | 情感识别 + 环境声检测 + 长音频分析 | 自动标记愤怒/插话/超时 |
| 视频内容审核 | 音视频联合推理 + 长时序跟踪 | 同步识别危险画面与可疑声音 |
| 播客 / 长视频 QA | 256K 长上下文 + 音频转录 | 直接问答多小时音频内容 |
| 桌面 Agent 自动化 | GUI 理解 + 工具调用 | 完成跨应用复杂工作流 |
六、Seed-2.0-lite-260428 常见问题解答
6.1 API 调用时 model 字段应该怎么填
直接填 seed-2-0-lite-260428 即可。注意中间是连字符,不是下划线;后缀 260428 是版本号(2026-04-28),不要省略,否则可能被路由到旧版本。模型列表可以在 API易 apiyi.com 控制台查询,确保和最新发布保持一致。
6.2 支持哪些音频格式与时长
模型遵循 OpenAI 风格的 input_audio 字段约定,常见的 MP3、WAV、M4A、FLAC 格式都支持。具体最大时长与采样率以官方 ModelArk 文档为准,建议单次输入不超过 30 分钟以保证推理稳定。超长音频可以先按段切分再合并结果。
6.3 与无 260428 后缀的 Seed-2.0-Lite 有什么区别
无后缀版本是 3 月 10 日发布的初代 Seed-2.0-Lite,只支持文本、图像、视频;260428 是 4 月 28 日发布的全模态升级版,新增音频输入与音视频联合推理能力。如果业务用到音频,必须用带后缀的版本。
6.4 调用是按 token 还是按音频时长计费
模型按 token 统一计费,音频会被内部编码为 token 后参与计算。当前定价为 $0.25 / M 输入、$2.00 / M 输出。具体一段音频对应的 token 数可在 API易 apiyi.com 控制台的"账单流水"中查看,便于做成本预估与优化。
6.5 是否支持流式输出与 Function Call
完全支持。Seed-2.0-lite-260428 兼容标准 OpenAI Chat Completions 协议中的 stream=true 与 tools 字段,可以直接接入 LangChain、LangGraph、OpenAI Agents SDK 等主流框架,无需特殊改造。
七、总结:全模态模型让多模态应用进入"统一推理"时代
Seed-2.0-lite-260428 的价值不仅是"多一种音频能力",更在于把视频、图像、音频与文本统一在同一个模型内完成推理。这种"统一推理"对那些天然跨模态的业务(会议、客服、内容审核、视频分析、Agent 自动化)来说,是一次真正意义上的架构简化:不再需要 ASR、视觉、文本三套模型拼接,也不再担心跨模型上下文丢失。
从成本与中文场景的角度看,这款模型在主流旗舰之中具备非常明显的性价比优势,$0.25 / M 输入的价格让大规模音视频处理在工程上成为可能,256K 上下文也足以覆盖多小时长音频与长视频场景。
如需在同一个 base_url 下统一调用 Seed-2.0-lite-260428 与各家旗舰多模态模型,可以访问 API易 apiyi.com 官方文档查看完整接入示例与模型列表。
作者:APIYI Team — 持续为全球 AI 开发者提供稳定、高效的 API 中转与多模型路由服务,详情访问 apiyi.com