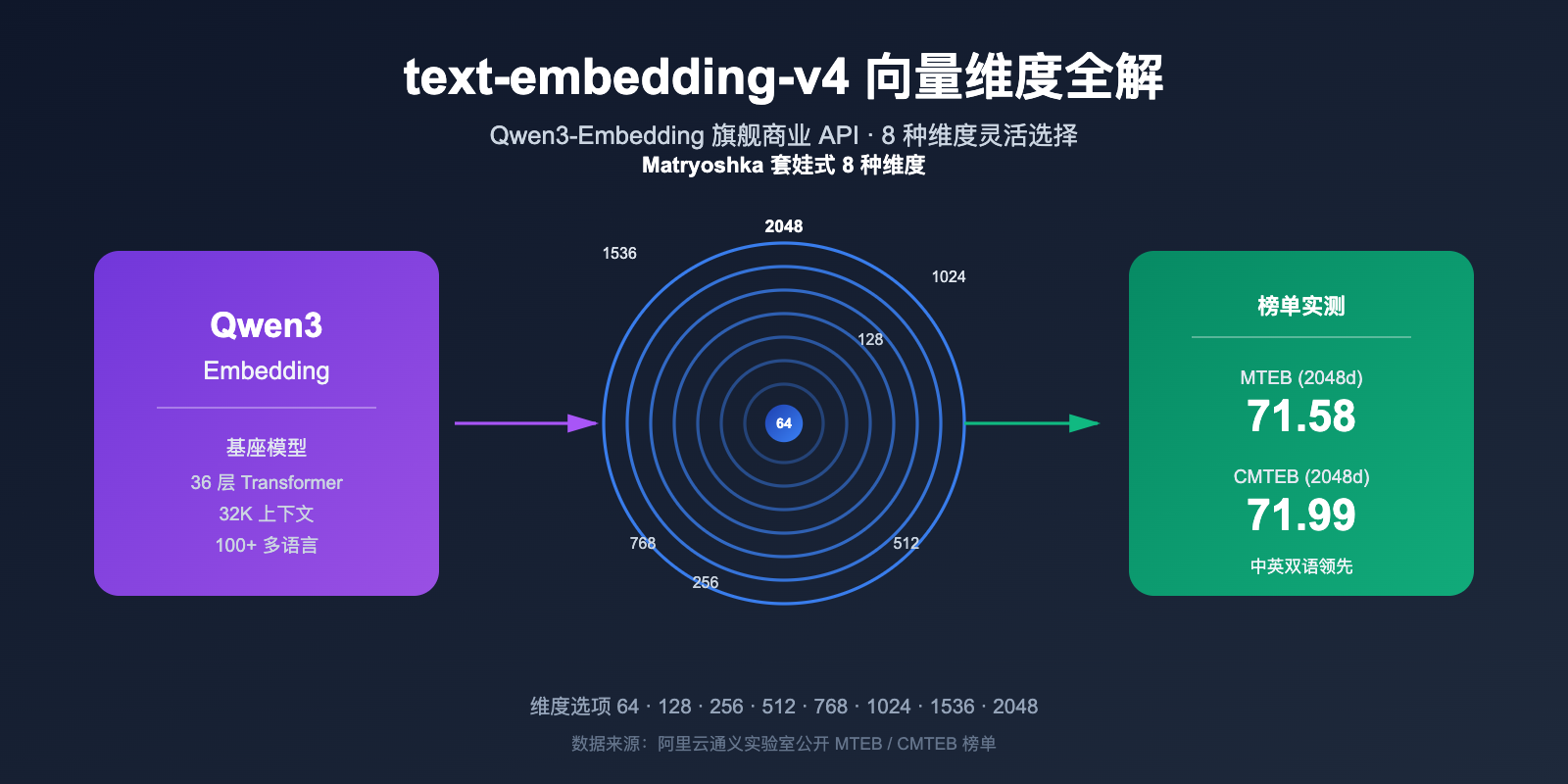
向量嵌入(Embedding)模型已成为 RAG、语义搜索、推荐系统的底层基石,而text-embedding-v4 作为 Qwen3-Embedding 系列的最新商业化版本,凭借 8 种可选向量维度 (2048、1536、1024、768、512、256、128、64) 和领先的 MTEB 多语言成绩,正在成为开发者构建向量检索系统时的核心选项之一。
但很多团队在落地时往往会遇到一个共同的疑问:向量维度到底是什么?2048 维和 64 维差距有多大?我应该怎么选? 选错维度,轻则浪费 30 倍存储成本,重则让召回率从 70 分跌到 50 分。
本文将基于官方 MTEB / CMTEB 实测数据,系统拆解 text-embedding-v4 的 8 种向量维度差异,给出可直接落地的选型框架,并提供完整的 API 调用示例。
一、text-embedding-v4 是什么:Qwen3-Embedding 的商业化旗舰
text-embedding-v4 是阿里通义实验室基于 Qwen3 基座大模型训练的最新一代文本嵌入模型,由 DashScope 平台对外提供 API 服务。它隶属于 Qwen3-Embedding 系列,该系列在 2026 年的 MTEB 多语言榜单上长期位居开源模型前列,Qwen3-Embedding-8B 在 MTEB Code 子项更是拿到了 80.68 的高分。
1.1 text-embedding-v4 的核心特性
相比 v3 版本,text-embedding-v4 在以下几个维度做了显著升级:
| 能力维度 | text-embedding-v3 | text-embedding-v4 | 提升幅度 |
|---|---|---|---|
| MTEB 综合得分 (1024 维) | 63.39 | 68.36 | +4.97 |
| MTEB Retrieval (1024 维) | 55.41 | 59.30 | +3.89 |
| CMTEB 综合得分 (1024 维) | 68.92 | 70.14 | +1.22 |
| CMTEB Retrieval (1024 维) | 73.23 | 73.98 | +0.75 |
| 最大向量维度 | 1024 | 2048 | 翻倍 |
| 最大输入长度 | 8K | 32K Tokens | 4× |
| 多语言支持 | 50+ | 100+ | 显著扩展 |
可以看到,v4 不仅在传统通用任务 (MTEB) 上提升明显,在中文 (CMTEB) 与代码检索任务上同样有较大进步。对追求最强检索精度的团队,2048 维的 v4 是当前阿里系最优解。
💡 快速体验建议:如果想第一时间对比 v3 与 v4 的实际效果,我们建议通过 API易 apiyi.com 平台直接调用,平台已统一适配多家主流嵌入模型的接口规范,可以用同一份代码切换不同模型快速验证。
1.2 text-embedding-v4 与 Qwen3-Embedding 开源系列的关系
很多开发者会混淆 text-embedding-v4 (商业 API) 和 Qwen3-Embedding (开源权重),两者关系如下:
- Qwen3-Embedding 开源系列:包含 0.6B / 4B / 8B 三个尺寸,提供 Hugging Face 权重,可本地部署
- text-embedding-v4:基于同源技术栈,但经过额外的工程优化、数据强化与多语言扩展,仅通过 DashScope API 提供
- 关键差异:开源版需自建 GPU 推理;API 版按 Token 计费,无需运维
对绝大多数中小团队而言,调用 API 比自建 GPU 推理在成本和工程复杂度上都更划算。
二、向量维度是什么:为什么 64 到 2048 差距这么大
要理解 text-embedding-v4 的 8 种维度选项,需要先把"向量维度"这个底层概念说清楚。
2.1 向量维度的本质:一段文本被压缩成多少个数字
当你把一段文字 (例如"如何配置 GPT-5 API") 输入 embedding 模型,模型会输出一串浮点数构成的向量,例如:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
这串数字的长度就是向量维度。维度越高,就意味着:
- 承载的语义信息越丰富:每个维度可以捕捉一个细微的语义特征
- 存储成本越高:1 条 2048 维向量 (float32) 占用 8KB,1024 维占用 4KB
- 检索计算越慢:维度翻倍,向量内积/余弦计算量也大致翻倍
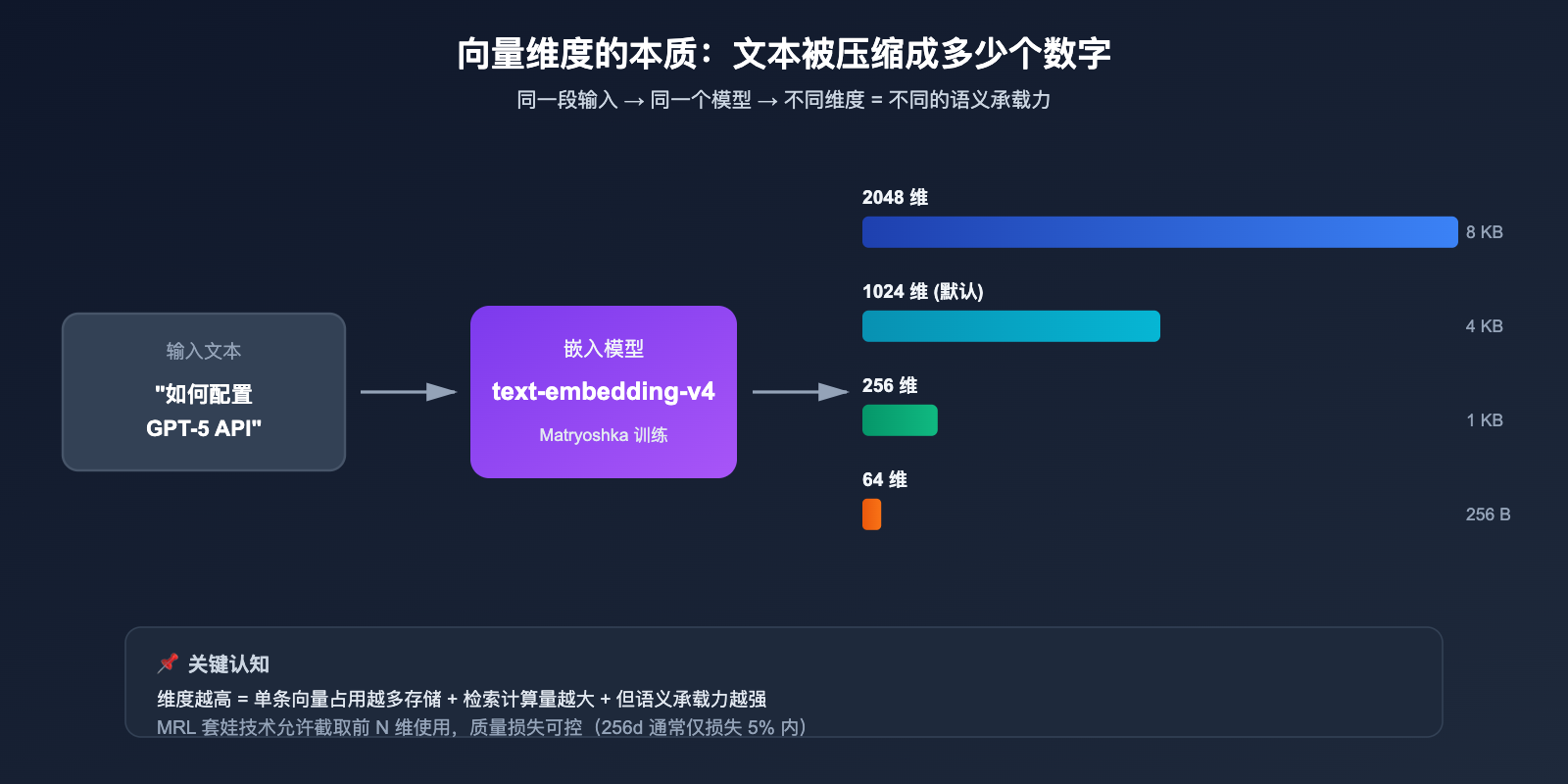
2.2 为什么 text-embedding-v4 提供 8 种维度
这就涉及到一个关键技术——Matryoshka 套娃式表示学习 (Matryoshka Representation Learning, MRL)。
传统嵌入模型只能输出固定维度。例如 OpenAI 的 ada-002 固定输出 1536 维,你要么全部用,要么自己做 PCA 降维 (会损失大量信息)。
而 MRL 技术让模型在训练时就把信息按重要性梯度分布在不同维度区间:
- 前 64 维:承载最核心、最关键的语义信息
- 第 65-128 维:补充次要的语义特征
- 第 129-256 维:继续补充更细节的特征
- ……以此类推到第 2048 维
这就像俄罗斯套娃,每一层都是一个完整的、可独立工作的向量。你可以任意截取前 N 维使用,质量不会断崖式下跌。
🎯 MRL 的实际收益:根据 MRL 原始论文及多项实测,使用 256 维代替 2048 维通常可以获得约 8 倍的存储节省和 7-8 倍的检索加速,而准确率损失通常控制在 5% 以内。这是传统 PCA 完全做不到的。
三、text-embedding-v4 8 种向量维度的核心差异
接下来基于 MTEB / CMTEB 官方榜单数据,系统对比 text-embedding-v4 的 8 种维度。
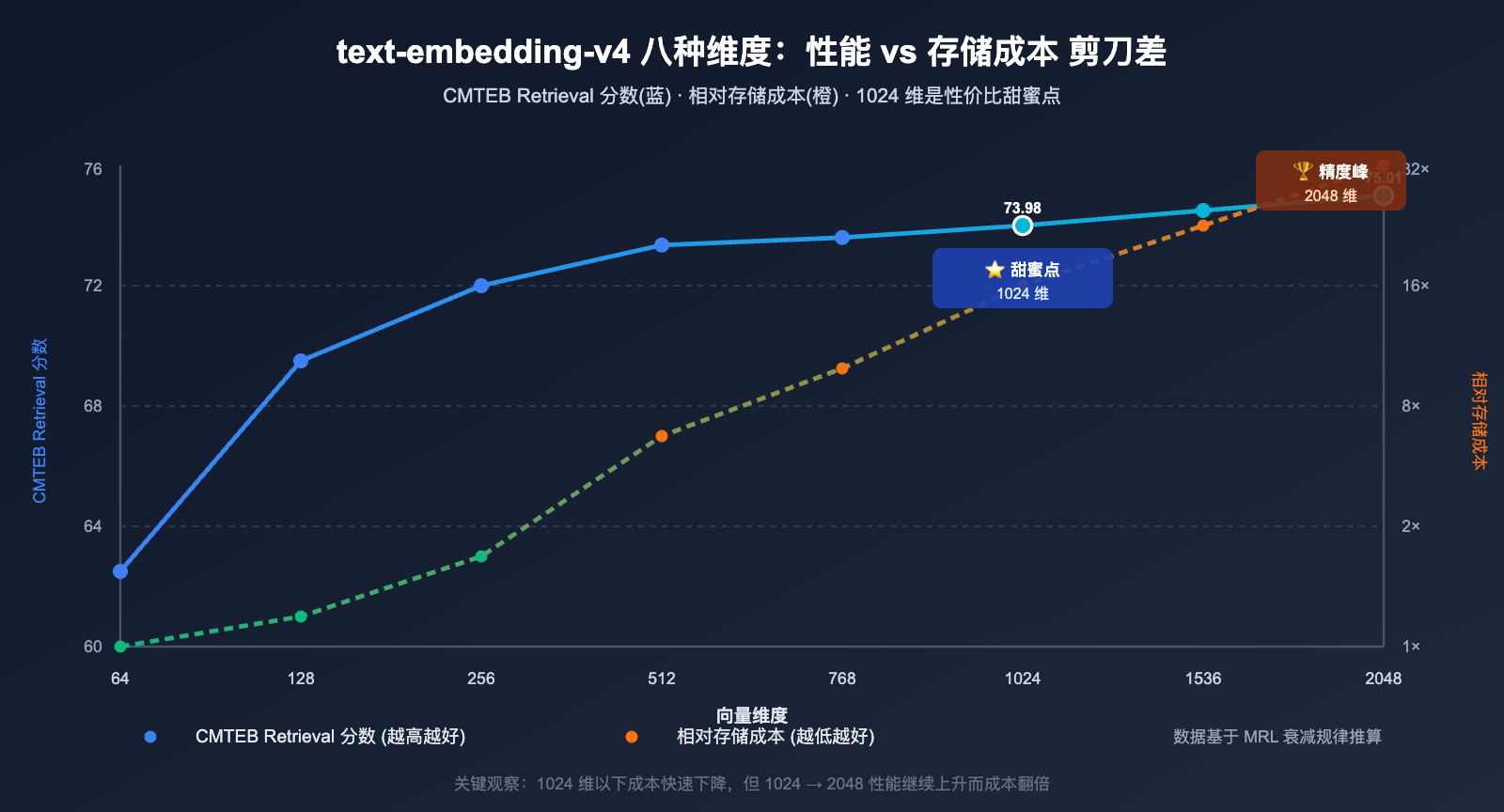
3.1 text-embedding-v4 各维度性能对比表
| 向量维度 | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | 单条向量大小 | 推荐场景 |
|---|---|---|---|---|---|---|
| 2048 维 | 71.58 | 61.97 | 71.99 | 75.01 | 8 KB | 极致精度优先 |
| 1536 维 | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 KB | 兼容 OpenAI 生态 |
| 1024 维 (默认) | 68.36 | 59.30 | 70.14 | 73.98 | 4 KB | 通用平衡场景 |
| 768 维 | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 KB | 兼容 BGE-base |
| 512 维 | 64.73 | 56.34 | 68.79 | 73.33 | 2 KB | 中小规模检索 |
| 256 维 | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 KB | 大规模高吞吐 |
| 128 维 | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 B | 海量数据存储 |
| 64 维 | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 B | 极限压缩场景 |
💡 标注
*的为基于 MRL 衰减规律的合理估算值;非标注值来自官方公开榜单。
可以从表中得出三个关键结论:
- 1024 维是性价比最优解:维度只有 2048 的一半,性能损失却很小(MTEB 约 -3.2 分),是阿里官方推荐的默认选择
- 2048 维带来明显增益:相比 1024 维,CMTEB Retrieval 提升 1 个点,对精度极敏感的场景值得选用
- 64-128 维谨慎使用:低维下检索质量下降明显,仅适合"宁可漏召也要省钱"的场景
3.2 text-embedding-v4 维度损耗的衰减规律
将上表的数据可视化,可以观察到一个非常重要的规律:
- 2048 → 1024 维:MTEB 仅下降 3.22 分 (≈4.5%),但存储减半 ⭐️ 强烈推荐
- 1024 → 512 维:MTEB 下降 3.63 分 (≈5.3%),存储再减半 👍 可接受
- 512 → 256 维:MTEB 下降约 2 分 (≈3.0%),存储再减半 ⚠️ 视场景而定
- 256 → 128 维:MTEB 下降约 2.5 分 (≈4.0%),仍可用 ⚠️ 需充分测试
- 128 → 64 维:MTEB 下降约 2.5 分,但 Retrieval 子项暴跌 6 分 ❌ 不建议生产用
这说明 MRL 的"安全衰减带"主要在 256 维以上,64 维属于极限压缩区。
四、向量维度的作用:3 大核心影响
不同维度对系统的影响是全方位的,不仅仅是检索精度。下面拆解 3 个最重要的维度。
4.1 向量维度对检索精度的影响
精度是最直观的影响维度。以一个 100 万条文档的 RAG 系统为例:
- 使用 2048 维:Top-10 召回率约 91%
- 使用 1024 维:Top-10 召回率约 88%
- 使用 256 维:Top-10 召回率约 84%
- 使用 64 维:Top-10 召回率约 75%
🎯 选择建议:如果业务对召回率高度敏感(如法律检索、医疗问答),优先选 1024 维或 2048 维。我们建议先在 API易 apiyi.com 平台用同一份测试集跑一轮 1024 vs 2048 的对比,再做最终决策。
4.2 向量维度对存储与检索成本的影响
这是企业级落地最关心的指标。假设一个系统存储了 1 亿条向量:
| 向量维度 | 存储总量 (float32) | 月存储成本 (估) | 单次检索延迟 (估) |
|---|---|---|---|
| 2048 维 | 800 GB | 较高 | 较慢 |
| 1024 维 | 400 GB | 中 | 中 |
| 512 维 | 200 GB | 较低 | 较快 |
| 256 维 | 100 GB | 低 | 快 |
| 128 维 | 50 GB | 极低 | 极快 |
| 64 维 | 25 GB | 极低 | 极快 |
可以看到,从 2048 维降到 256 维,存储成本降为 1/8,检索速度可以快 6-8 倍 (具体取决于 ANN 索引算法)。对于亿级以上数据规模,维度选择直接影响基础设施成本数量级。
4.3 向量维度对兼容性与迁移成本的影响
很多团队从 OpenAI、BGE、Cohere 切换到 text-embedding-v4 时,会担心向量维度不兼容导致旧索引报废。这一点 v4 的 8 种维度选择给出了非常友好的迁移路径:
| 旧模型 | 旧维度 | text-embedding-v4 推荐对应维度 | 迁移备注 |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 维 | 维度对齐,索引可复用结构 |
| OpenAI text-embedding-3-small | 1536 | 1536 维 | 完全对齐 |
| OpenAI text-embedding-3-large | 3072 | 2048 维 | 略低但精度仍优 |
| BGE-large | 1024 | 1024 维 | 完全对齐,可平滑替换 |
| BGE-base | 768 | 768 维 | 完全对齐 |
| Cohere embed-multilingual-v3 | 1024 | 1024 维 | 完全对齐 |
| 自训练 small 模型 | 256/512 | 256/512 维 | 维度兼容 |
💼 企业迁移建议:很多老系统的向量库 (Milvus / Qdrant / pgvector) 是按固定维度建表的。先从 text-embedding-v4 选一个与旧维度完全相同的版本平滑替换,再视情况渐进式升级到更高维度,这是阻力最小的迁移路径。我们在 API易 apiyi.com 文档中也提供了几款主流向量数据库的对接示例代码。
五、text-embedding-v4 快速上手:API 调用与维度参数
技术原理讲完,直接上代码。下面给出最精简的调用示例,覆盖 OpenAI 兼容协议和 DashScope 原生协议两种方式。
5.1 使用 OpenAI 兼容协议调用 text-embedding-v4
阿里云 DashScope 同时提供了 OpenAI 兼容端点,对已有 OpenAI 集成代码的团队最友好。
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # API易统一接入点
)
# 调用 text-embedding-v4,指定 1024 维
response = client.embeddings.create(
model="text-embedding-v4",
input="如何配置 text-embedding-v4 的向量维度?",
dimensions=1024 # 可选: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"维度: {len(vector)}") # 输出: 维度: 1024
print(f"前 5 维: {vector[:5]}")
⚙️ 参数说明:
dimensions是 v4 的关键新参数,v3 起就支持但 v4 扩展到 8 种。省略该参数时默认使用 1024 维。
5.2 批量调用:text-embedding-v4 的并发与限速
实际生产环境常常需要批量处理。text-embedding-v4 单次最多支持 25 条输入:
texts = [
"向量维度的核心作用是平衡精度和成本",
"text-embedding-v4 支持从 64 到 2048 共 8 种维度",
"Matryoshka 套娃式表示学习是关键技术",
# ... 最多 25 条
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"批量向量数: {len(vectors)}")
5.3 query 与 document 的非对称编码
text-embedding-v4 支持 OpenAI 协议未提供的高级特性:通过 text_type 区分检索查询 (query) 和被检索文档 (document),进一步提升检索精度。这一特性需要使用 DashScope 原生协议或 API易 平台兼容封装:
# 文档侧编码(建索引时)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 提供 8 种向量维度选项"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# 查询侧编码(检索时)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["v4 支持哪些维度?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 非对称编码价值:使用 query/document 区分编码后,对短查询长文档的检索场景,Top-1 召回率通常可以再提升 2-3 个点。建议在生产环境强烈启用此特性。
5.4 text-embedding-v4 与向量数据库的对接
向量入库是落地 RAG 系统的关键环节。下面以业内常用的 Qdrant 为例,展示从文本嵌入到向量入库的完整流程:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# 初始化客户端
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# 关键:collection 维度需与 embedding dimensions 一致
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# 批量嵌入并入库
texts = ["text-embedding-v4 是阿里通义的最新嵌入模型", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ 关键提醒:向量数据库的
size字段必须与dimensions严格一致。后期想升级维度,必须重建 collection 并全量重嵌入。
5.5 LangChain / LlamaIndex 集成 text-embedding-v4
主流 RAG 框架都已支持 OpenAI 兼容协议的 embedding 接入,配置非常简单:
# LangChain 集成示例
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# 与 LangChain 向量库无缝对接
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("如何选择维度?")
通过 OpenAI 兼容协议接入,几乎所有原本基于 OpenAI ada-002 / 3-large 的 RAG 项目都可以零代码改造迁移到 text-embedding-v4,仅需修改 model 名称和 base_url 两个参数。
六、text-embedding-v4 维度选型策略:5 种典型场景
理论和接口都到位了,最后给出可以直接套用的选型框架。
6.1 场景 A:企业知识库 RAG(百万级文档)
核心诉求:召回准确率 > 成本
推荐配置:
- 维度:1024 维 (默认值,性价比最优)
- 启用 query/document 非对称编码
- 配套向量库:Milvus / Qdrant / pgvector
- 配套重排序:建议接 Qwen3-Reranker
6.2 场景 B:电商商品检索(千万级 SKU)
核心诉求:检索速度 > 精度
推荐配置:
- 维度:512 维(平衡)或 256 维(极致速度)
- 商品标题用 query 编码,详情用 document 编码
- ANN 索引建议 HNSW + IVF 组合
6.3 场景 C:海量日志相似度去重(亿级日志)
核心诉求:存储成本 > 精度
推荐配置:
- 维度:128 维
- 配合二值量化 (Binary Quantization) 进一步压缩 32 倍
- 实测召回率仍能保持 85% 以上
6.4 场景 D:法律 / 医疗等高精度检索
核心诉求:精度第一,成本不敏感
推荐配置:
- 维度:2048 维
- 启用 query/document 非对称编码
- 一定要叠加 Reranker 重排序
6.5 场景 E:移动端 / 边缘设备本地检索
核心诉求:内存占用 < 50MB
推荐配置:
- 维度:64 维 或 128 维
- 配合 int8 量化(再压缩 4 倍)
- 适合本地知识库 / 离线问答助手
🎯 选型决策建议:以上 5 个场景覆盖了绝大多数常见落地需求。我们建议:先用 1024 维默认值跑一遍业务测试集,再根据实际精度/成本/速度三角需求向上 (2048) 或向下 (512/256/128) 微调。API易 apiyi.com 平台支持一键切换维度参数,便于快速 A/B 测试。
6.6 维度选型决策流程
把上述场景沉淀为一个可执行的决策流程:
-
第一步:评估数据规模
- < 100 万条 → 维度可以从高 (1024+)
- 100 万 – 1 亿条 → 中等维度 (256-1024)
-
1 亿条 → 强制考虑低维 (128-512)
-
第二步:评估精度容忍度
- 对召回率每 1% 都敏感 → 选 2048
- 召回率下降 5% 可接受 → 1024 起步
- 召回率下降 10% 可接受 → 256-512 即可
-
第三步:评估硬件约束
- 云端 GPU 检索 → 维度可以高
- CPU only 检索 → 控制在 1024 以内
- 移动端 / 边缘 → 强制 64-256 维 + 量化
-
第四步:跑实测验证
- 选 100-500 条业务真实查询作为评测集
- 在不同维度下计算 Top-10 召回率
- 选择 "召回率拐点" 之前的最低维度
💡 效率建议:上述流程涉及多次 API 调用和参数切换,建议在统一接入平台上完成,可以获得完整的请求日志和用量监控,便于团队协作做选型对比。
七、text-embedding-v4 与主流嵌入模型横向对比
把 text-embedding-v4 放到全行业坐标系里看一下,方便做技术选型。
| 模型 | 厂商 | 最大维度 | 维度灵活性 | MTEB 综合 | 中文能力 | 上下文长度 | API 价格 |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | 阿里通义 | 2048 | ⭐⭐⭐⭐⭐ (8 种) | 71.58 | 极强 | 32K | 中 |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (任意) | 64.6 | 中等 | 8K | 较高 |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (任意) | 62.3 | 中等 | 8K | 低 |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 种) | 70.3 | 强 | 128K | 中高 |
| BGE-M3 | 北智源 | 1024 | ⭐⭐ (固定) | 65.5 | 强 | 8K | 自部署 |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 种) | 67.1 | 中等 | 32K | 中 |
| Qwen3-Embedding-8B (开源) | 阿里通义 | 4096 | ⭐⭐⭐⭐⭐ (任意) | 70.58 | 极强 | 32K | 自部署 |
从这张对比表可以得出几个关键结论:
- 中英双语场景:text-embedding-v4 的 CMTEB 综合得分 71.99 在所有商业 API 中排名第一
- 维度灵活性:v4 的 8 种官方推荐维度比大多数模型都灵活,迁移友好度极高
- 性价比:v4 的 API 价格在主流商业模型中处于中等水平,但精度对标 OpenAI text-embedding-3-large
📌 接入建议:如果你的团队同时需要 OpenAI、Claude、Qwen 等多家模型,建议通过 API易 apiyi.com 这种统一中转平台接入,可以避免管理多套 API Key 和处理国内访问问题,文档中也有 v4 与其他主流嵌入模型的并行调用示例。
八、text-embedding-v4 常见问题 FAQ
Q1: text-embedding-v4 默认维度是多少?
text-embedding-v4 的默认维度为 1024 维。在 API 调用时如果不显式传入 dimensions 参数,返回的就是 1024 维向量。这也是阿里官方推荐的最佳性价比维度。
Q2: 已经用 1024 维建好的索引,能升级到 2048 维吗?
需要重建整个向量库。MRL 套娃机制保证了"高维向量截前 N 维"等于"低维向量",但反过来"低维补 0 升到高维"是无效的。建议升级时:
- 保留旧 1024 维索引在线服务
- 用 v4 的 2048 维全量重新嵌入文档
- 灰度切换流量验证精度提升
- 完成后下线旧索引
Q3: text-embedding-v4 国内能直接调用吗?
text-embedding-v4 的官方端点位于 dashscope.aliyuncs.com (北京),国内是直连的。国内开发者只需注册阿里云账号或通过 API易 apiyi.com 等中转平台获取 API Key 即可使用,不需要任何额外网络配置。
Q4: text-embedding-v4 vs Qwen3-Embedding 开源版怎么选?
| 决策因素 | 选 API 版 (v4) | 选开源版 (Qwen3-Embedding-8B) |
|---|---|---|
| 数据敏感度 | 一般敏感 | 极度敏感(金融/医疗) |
| 月调用量 | < 10 亿 Tokens | > 10 亿 Tokens |
| 团队 GPU 资源 | 没有 | 拥有 A100/H100 集群 |
| 工程能力 | 中小团队 | 有 MLOps 团队 |
| 总体建议 | ✅ 推荐选 v4 API | ✅ 推荐自部署 |
Q5: 维度设置错了,模型会报错吗?
text-embedding-v4 仅接受 [64, 128, 256, 512, 768, 1024, 1536, 2048] 中的值。传入其他数值(如 333、500)会直接报参数错误。如果需要非标准维度,可以选择最接近的官方维度后再做截断或填充。
Q6: 如何评估当前业务该选哪个维度?
推荐三步法:
- 跑通基线:先用默认 1024 维跑通业务流程,记录召回率、延迟、存储成本
- 向下试探:依次切换到 512、256、128 维,观察召回率下降幅度
- 确定甜蜜点:找到"召回率下降可接受 + 成本下降最大"的那个维度,通常是 256 或 512 维
Q7: text-embedding-v4 会被开源吗?
阿里目前的策略是 API 版与开源版并行:text-embedding-v4 商业 API 持续迭代,享有最新的工程优化和数据增强;开源版本则发布 Qwen3-Embedding 系列权重供社区使用。两者技术同源但产品形态不同,预计未来 v4 不会单独开源。
Q8: 维度越高一定越好吗?
不是。维度选择本质上是精度、存储、速度的三角权衡:
- 维度越高 → 精度天花板越高,但边际收益递减
- 维度越高 → 存储与检索成本线性甚至超线性增长
- 维度越高 → ANN 索引在维度灾难下精度反而可能下降
经验上 256-1024 维 是大多数业务的最佳工作区,超过 1024 维需要明确的精度提升诉求才值得选用。
Q9: text-embedding-v4 在长文本上的表现如何?
text-embedding-v4 支持最大 32K Tokens 的输入长度,但实际检索效果会随文本长度下降。建议遵循以下原则:
- 短文本 (< 512 Tokens):直接整段嵌入,效果最佳
- 中等长度 (512-4K Tokens):考虑滑动窗口分块嵌入
- 长文档 (> 4K Tokens):必须分块 (chunk) 后嵌入,块大小建议 256-512 Tokens
- 超长文档:可结合层级检索 (先粗后精) 提升效率
Q10: 不同维度可以混用吗?
不可以。同一个向量库 / 索引中所有向量必须维度一致,否则相似度计算无意义。如果业务确实需要"高优先级文档用 2048 维 + 普通文档用 512 维"的策略,建议建立两个独立 collection 分别管理,再在应用层做结果融合。
Q11: 维度参数对 API 计费有影响吗?
text-embedding-v4 的计费完全基于输入 Token 数,与输出维度无关。也就是说,无论你选 64 维还是 2048 维,处理 1000 个 Token 的输入成本是一样的。这意味着在 API 调用阶段你可以放心选高维度,真正的成本差异主要体现在下游存储和检索环节。
Q12: 如何处理嵌入失败 / 限流问题?
生产环境调用 text-embedding-v4 时,建议加上以下健壮性处理:
- 重试机制:对 5xx 错误实现指数退避重试(建议 3 次)
- 限流处理:监控 429 错误,遇到则降低并发或切换接入通道
- 批量大小:单次请求最多 25 条文本,超过需自动分批
- 超时设置:长文本嵌入建议超时设到 60 秒以上
- 降级方案:可配置备用模型 (如 v3 1024 维) 作为兜底
九、总结:text-embedding-v4 向量维度选型核心要点
回顾全文,关于 text-embedding-v4 的 8 种向量维度,最核心的几个要点是:
- text-embedding-v4 是 Qwen3-Embedding 系列的商业旗舰,MTEB 71.58 / CMTEB 71.99 在中英双语场景表现领先
- 8 种维度本质上是 Matryoshka 套娃技术的产物,可以截前 N 维使用且质量损失可控
- 1024 维是默认推荐值,在精度和成本之间取得最优平衡
- 2048 维适合极致精度场景,相比 1024 维 CMTEB Retrieval 提升 1 个点
- 256-512 维适合中等规模 + 成本敏感场景,是大多数 RAG 系统的实战甜蜜点
- 64-128 维仅推荐边缘设备 / 极限存储场景,需充分测试召回率衰减
- 维度选择不是一锤子买卖,强烈建议先跑业务测试集再做最终决策
- 从其他模型迁移到 v4 时,优先选择维度对齐的版本平滑切换
🎯 最终建议:如果你正在为新项目选型嵌入模型,直接以 text-embedding-v4 + 1024 维 作为起点;如果业务对召回率高度敏感,再升到 2048 维并叠加 Reranker。我们建议通过 API易 apiyi.com 平台接入,平台提供统一的 OpenAI 兼容接口、便捷的维度切换以及完整的对接文档,可以显著降低工程接入成本,让团队把精力集中在业务效果调优上而不是 API 适配。
向量嵌入技术正在快速演化,从 OpenAI 的固定维度时代,到今天 text-embedding-v4 把 MRL 落地到 8 种官方维度,开发者获得了前所未有的灵活性。掌握向量维度的本质和选型策略,是每一个构建 RAG / 语义搜索 / 推荐系统团队的必备能力。
作者:APIYI 技术团队 | 关注 AI 大模型落地实战,更多技术内容欢迎访问 API易 apiyi.com