作者注:深度解析 Nano Banana Pro (gemini-3-pro-image-preview) 多轮对话出图 API 的字段结构、contents 数组构造、thoughtSignature 机制与代码实战。
很多开发者第一次接入 Nano Banana Pro 都会遇到同一个困惑:在 gemini.google.com 网页端可以连续追问「把背景换成黄昏」「再加一只猫」,模型完美记得上一张图;但调用官方 API 时,模型却像断片一样什么都不记得。原因是 Gemini API 本身是无状态的,多轮上下文必须由调用方手动构造。本文将彻底讲清 Nano Banana Pro 多轮对话出图 API 的底层字段、Python SDK 与 REST 两套实现,以及关键的 thoughtSignature 机制,帮你 3 步搭建出像网页版一样流畅的上下文出图体验。
核心价值: 读完本文,你将掌握 contents 数组的正确构造方式、能在自己的应用里实现「基于上一张图继续编辑」的多轮工作流,并避免「图片忘记」「token 浪费」「signature 丢失」三大典型坑。

Nano Banana Pro 多轮对话出图 核心要点
| 要点 | 说明 | 价值 |
|---|---|---|
| API 无状态 | gemini-3-pro-image-preview 接口本身不记得任何历史 | 多轮上下文需调用方主动维护 |
| contents 数组 | user/model 角色交替,每次请求携带完整历史 | 一次请求即可让模型「看到」过往对话 |
| 图片回传 | 之前生成的图片需以 inline_data 形式塞回 contents | 模型据此进行持续编辑而非重新生成 |
| thoughtSignature | 加密的思考签名,跨轮保留推理上下文 | 关键编辑指令不会被遗忘 |
| SDK 自动化 | 官方 Python SDK 的 chat 对象自动管理历史 |
从 REST 直接迁移可省 80% 代码 |
多轮对话出图 与 网页版 Agent 的本质区别
gemini.google.com 是 Google 官方搭建的 Agent 应用,它在前端帮你维护了一份完整的「对话状态」(包含每轮的文本、生成的图片、思考签名),每次你输入新消息时,这个 Agent 会把所有历史一次性打包发送给底层模型。这就是为什么网页端体验如此流畅——所有「记忆」工作都被 Agent 包揽了。
而当你直接调用 generateContent API 时,你拿到的是「赤裸」的模型调用接口。每次 HTTP 请求都是一次独立的推理,模型对你之前的对话毫无概念。要复现网页版的多轮体验,本质上就是在你的代码里自己实现一个 Agent——把历史 user 消息、model 响应(含图片和签名)按规范填入 contents,再发起请求。
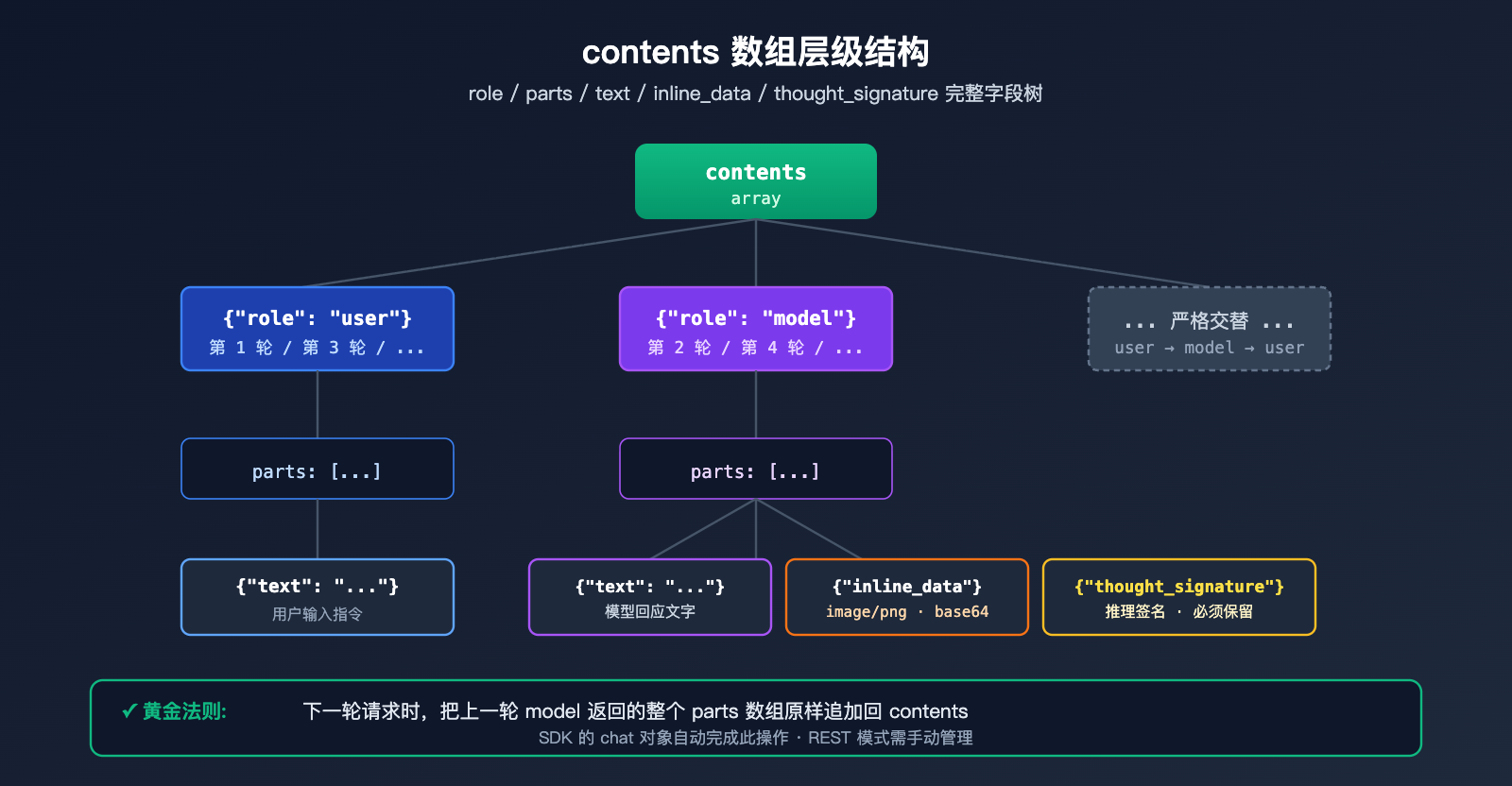
Nano Banana Pro 多轮对话出图 字段结构详解
contents 数组的核心规范
contents 是 Gemini API 表达对话历史的标准字段,它是一个 JSON 数组,每个元素代表一轮发言:
| 字段 | 类型 | 说明 |
|---|---|---|
role |
string | "user" 或 "model",必须严格交替 |
parts |
array | 该轮发言的内容片段,可以混合文本/图片/签名 |
parts[].text |
string | 文本内容,如指令或对话 |
parts[].inline_data.mime_type |
string | 图片格式,通常为 "image/png" |
parts[].inline_data.data |
string | 图片的 base64 编码数据 |
parts[].thought_signature |
string | 模型生成的加密签名(仅在 model role 中出现) |
一个完整的两轮对话请求体长这样:
{
"contents": [
{"role": "user", "parts": [{"text": "生成一只在沙滩奔跑的金毛犬"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<第一轮生成图base64>"}},
{"thought_signature": "<加密签名>"}
]},
{"role": "user", "parts": [{"text": "把场景改成黄昏时分"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
图片回传的两种方式
第二轮请求里,模型必须能「看到」第一轮生成的图片。Nano Banana Pro 支持两种回传姿势:
# 方式一:inline_data 内嵌 base64(适合小图,简单直接)
{
"inline_data": {
"mime_type": "image/png",
"data": base64.b64encode(image_bytes).decode()
}
}
# 方式二:file_data 引用 Files API 上传后的资源(适合大图或复用)
{
"file_data": {
"mime_type": "image/png",
"file_uri": "files/abc123xyz"
}
}
关键提示:
inline_data是直接调用最常用的方式,适合一次性场景;file_data引用模式适合需要在多轮中复用同一张大图的场景,可显著降低请求体大小和上传开销。
Nano Banana Pro 多轮对话出图 快速上手
极简示例(Python SDK 自动管理)
如果你使用官方 Python SDK,最简洁的写法只需要 10 行:
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
chat = client.chats.create(model="gemini-3-pro-image-preview")
# 第一轮:生成初始图
r1 = chat.send_message("生成一只在沙滩奔跑的金毛犬")
# 第二轮:基于第一张图继续编辑(chat 对象自动携带历史)
r2 = chat.send_message("把场景改成黄昏时分,加一只飞翔的海鸥")
# 第三轮:继续追加修改
r3 = chat.send_message("再把狗的颜色换成深棕色")
chat 对象内部维护了完整的 contents 列表(包括每轮的 thoughtSignature),开发者无需关心字段细节。每次 send_message 都会自动把历史打包发送。
查看 OpenAI 兼容接口完整调用示例
如果你使用 API易 apiyi.com 这类 OpenAI 兼容平台调用 Nano Banana Pro,可以直接复用 OpenAI SDK:
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 维护一个本地的 messages 列表(即 contents 概念)
messages = [
{"role": "user", "content": "生成一只在沙滩奔跑的金毛犬"}
]
# 第一轮
response1 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
img1_url = response1.choices[0].message.content # 提取图片URL或base64
# 把模型响应加入历史
messages.append({"role": "assistant", "content": img1_url})
# 第二轮:追加新指令
messages.append({"role": "user", "content": "把场景改成黄昏时分"})
response2 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
# 第三轮继续追加...
messages.append({"role": "assistant", "content": response2.choices[0].message.content})
messages.append({"role": "user", "content": "再加一只飞翔的海鸥"})
response3 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
关键点:在 OpenAI 兼容模式下,messages 数组等同于原生 contents,role 字段从 "model" 改为 "assistant",平台层会自动转换。
建议: 对于多轮编辑场景,推荐使用 SDK 的
chat对象或维护本地 messages 列表,避免每次手动拼接 contents。可在 API易 apiyi.com 注册免费额度,先用 SDK 跑通再考虑 REST 优化。
Nano Banana Pro 多轮对话出图 REST 手动构造
不依赖 SDK 的纯 REST 实现
某些场景(例如服务端中转、ComfyUI 节点、低代码平台)无法使用官方 SDK,需要直接构造 REST 请求。以下是完整的 curl 调用:
# 第一轮:纯文本指令生成图
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "生成一只在沙滩奔跑的金毛犬"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
# 响应中会有: parts[0].inline_data.data (base64图片)
# 以及 parts[0].thought_signature
第二轮请求时,必须把第一轮的整个 model 响应(包括图片和签名)原样塞回 contents:
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "生成一只在沙滩奔跑的金毛犬"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<第一轮返回的base64>"}},
{"thought_signature": "<第一轮返回的signature>"}
]},
{"role": "user", "parts": [{"text": "把场景改成黄昏时分"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
三种调用模式对比
| 调用方式 | 历史管理 | 适合场景 | 学习成本 |
|---|---|---|---|
官方 Python SDK (chat 对象) |
自动 | 后端服务、Notebook 实验 | ⭐ 最低 |
| OpenAI 兼容接口 (messages 数组) | 半自动 | 已有 OpenAI 项目迁移 | ⭐⭐ 较低 |
| 原生 REST (contents 数组) | 完全手动 | ComfyUI、低代码、跨语言 | ⭐⭐⭐ 中等 |

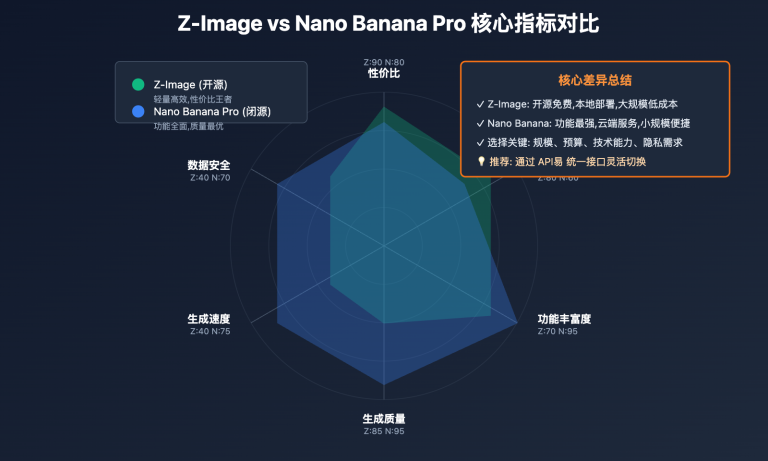
数据说明: 上图展示了 Agent 自动管理 vs API 手动管理的核心差异,可通过 API易 apiyi.com 平台直接对比两种调用方式的实际表现差异。
Nano Banana Pro 多轮对话出图 thoughtSignature 机制
什么是 thoughtSignature
thoughtSignature 是 Gemini 3 系列引入的「加密思考签名」。它是模型对自己内部推理状态的一个紧凑编码,肉眼不可读,但模型在下一轮可以用它快速恢复上下文。具体作用:
- 保留细节决策: 例如第一轮里模型「决定」用浅色调,第二轮通过签名继承这个风格
- 提升一致性: 角色、场景、构图在多轮编辑中保持稳定
- 节省 token: 避免在 prompt 里反复重申「保持原风格」
何时必须携带 signature
| 场景 | 是否必须携带 signature |
|---|---|
| 单轮独立请求(一次性出图) | ❌ 不需要 |
| 多轮编辑(基于上一张图修改) | ✅ 必须 |
| 跨会话恢复历史 | ✅ 必须(需自行持久化) |
| 仅文本对话(无图片) | ✅ 必须,用于推理连续性 |
实战:手动管理 signature 的代码模式
import requests
import base64
import json
API_BASE = "https://vip.apiyi.com/v1beta"
MODEL = "gemini-3-pro-image-preview"
HEADERS = {
"x-goog-api-key": "YOUR_API_KEY",
"Content-Type": "application/json"
}
class NanoBananaChat:
"""手动维护 contents + signature 的极简 chat 客户端"""
def __init__(self):
self.contents = []
def send(self, text: str, attach_image_b64: str = None) -> dict:
# 构造本轮 user message
user_parts = [{"text": text}]
if attach_image_b64:
user_parts.append({
"inline_data": {"mime_type": "image/png", "data": attach_image_b64}
})
self.contents.append({"role": "user", "parts": user_parts})
# 发起请求
resp = requests.post(
f"{API_BASE}/models/{MODEL}:generateContent",
headers=HEADERS,
json={
"contents": self.contents,
"generationConfig": {"responseModalities": ["TEXT", "IMAGE"]}
}
).json()
# 把 model 响应(含 signature)原样追加回 contents
model_parts = resp["candidates"][0]["content"]["parts"]
self.contents.append({"role": "model", "parts": model_parts})
return model_parts
# 使用示例
chat = NanoBananaChat()
parts1 = chat.send("生成一只在沙滩奔跑的金毛犬")
parts2 = chat.send("把场景改成黄昏时分") # 自动携带历史和signature
parts3 = chat.send("再加一只飞翔的海鸥")
优化建议: 通过 API易 apiyi.com 接入时,平台层会原样透传 thought_signature 字段,开发者只需保证「把整个 model parts 数组追加回 contents」即可,无需关心签名的具体内容。
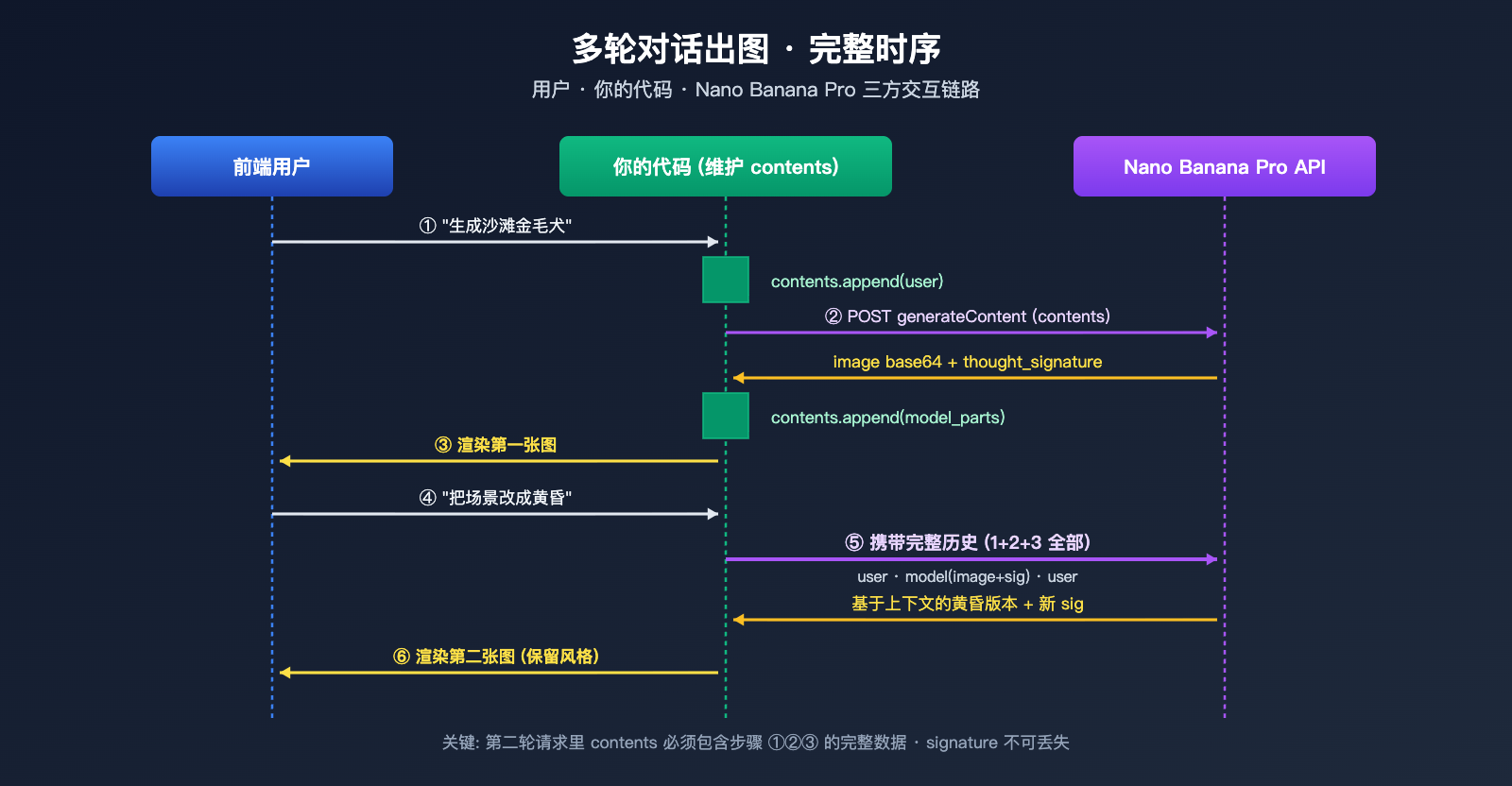
Nano Banana Pro 多轮对话出图 实战场景
场景 1:渐进式品牌图设计
营销团队常见需求:基于一张产品概念图,逐步调整文案、配色、排版。多轮对话出图 API 的优势在于每次只需描述「增量变化」,不必从头描述整张图:
chat = client.chats.create(model="gemini-3-pro-image-preview")
chat.send_message("设计一张深蓝渐变背景的咖啡品牌海报,左侧放产品图")
chat.send_message("把标题文案改成「Awaken Your Morning」")
chat.send_message("右下角加一个二维码占位")
chat.send_message("整体风格再现代一点,去掉装饰花边")
场景 2:基于参考图的多轮编辑
Nano Banana Pro 支持单次最多 14 张参考图。结合多轮对话,可以构建强大的图像融合工作流:
# 上传一张人像 + 一张服装参考图
chat.send_message([
"把第一张图的人物穿上第二张图里的服装",
{"inline_data": {"mime_type": "image/png", "data": person_b64}},
{"inline_data": {"mime_type": "image/png", "data": outfit_b64}}
])
# 后续微调
chat.send_message("把领口改成 V 字领")
chat.send_message("背景换成简洁的灰色")
场景 3:跨会话恢复历史
如果用户在前端关闭页面后重新打开,希望继续上次对话,需要把 contents 数组持久化到数据库:
import json
# 保存
with open(f"sessions/{user_id}.json", "w") as f:
json.dump(chat.get_history(), f)
# 恢复
with open(f"sessions/{user_id}.json") as f:
history = json.load(f)
restored_chat = client.chats.create(
model="gemini-3-pro-image-preview",
history=history
)
restored_chat.send_message("继续上次的,把背景再亮一点")
上下文窗口限制
| 资源 | 限制 |
|---|---|
| 输入上下文 | 64K tokens |
| 输出上下文 | 32K tokens |
| 单请求最大参考图数量 | 14 张 |
| 推荐历史轮数 | 不超过 8-10 轮 |
| 单图最大分辨率 | 2K (默认 1K) |
场景建议: 当对话超过 8-10 轮时,建议主动「截断」前面的历史或用 LLM 摘要替代,否则 token 会快速逼近 64K 上限。生产环境务必加入 token 计数器,提前在客户端做截断决策。
常见问题
Q1: 我直接调 API 没有上下文,要怎么实现网页版那种连续对话?
API 是无状态的,必须由你的代码维护一份本地的 contents 数组(或 SDK 里的 chat 对象)。每次请求把完整历史(包括用户文本、模型生成的图片、thought_signature)一起发回去,模型才会「记得」之前的对话。最简单的方式是用官方 Python SDK 的 client.chats.create(),由 SDK 自动管理。
Q2: 上一轮生成的图片,下一轮要传什么字段?
要把图片以 inline_data 的形式(base64 编码 + mime_type)放入「上一轮 model 角色」的 parts 数组中。同时务必把模型返回的 thought_signature 也一并带回。如果使用 API易 apiyi.com 等 OpenAI 兼容接口,平台会自动处理这些字段映射,开发者只需维护标准的 messages 列表。
Q3: thoughtSignature 必须传吗?不传会怎样?
强烈建议传。不传的话,模型在多轮编辑时可能「忘记」上一轮的关键决策(如风格、配色、构图),导致每次都像在重新生成。官方文档明确指出多轮场景下 signature 必须保留。SDK 会自动处理,REST 模式下需要手动把 model parts 完整追加回 contents。
Q4: 历史太长了怎么办?token 超 64K 会报错吗?
会的,超过 64K 输入 token 会被拒绝。常见优化策略:
- 截断: 只保留最近 4-6 轮历史
- 图片下采样: 历史图片传 1K 而不是 2K 分辨率
- 摘要替代: 用 LLM 把前几轮压缩成一段文字描述
- 分段会话: 当对话主题切换时主动开新会话
Q5: 如何快速测试 Nano Banana Pro 多轮出图效果?
推荐使用 API易 apiyi.com 这类支持 Gemini 模型的聚合平台快速验证:
- 注册账号获取 API Key 和免费额度
- 选择
gemini-3-pro-image-preview模型 - 用本文的 Python SDK 示例代码连续发起 3-5 轮编辑
- 对比每轮输出的连贯性,判断是否符合业务需求
总结
Nano Banana Pro 多轮对话出图 API 的核心要点:
- 无状态本质: API 不记忆任何历史,必须由调用方维护
contents数组 - 角色交替: user 与 model 严格交替,每轮 parts 可混合 text/image/signature
- 图片回传: 上一轮生成的图必须以
inline_data形式塞回,否则模型「看不到」 - 签名机制: thought_signature 是多轮一致性的关键,REST 模式下必须手动携带
- SDK 简化: 官方 Python SDK 的
chat对象可自动管理上述所有细节
对于希望快速实现网页版体验的开发者,最佳路径是使用官方 SDK 的 chat 对象或 OpenAI 兼容接口的 messages 模式,避免手动构造 REST 带来的复杂度。
推荐通过 API易 apiyi.com 接入 Nano Banana Pro 多轮对话出图能力,平台支持原生 Gemini 字段与 OpenAI 兼容双模式调用,提供免费测试额度,便于快速验证多轮编辑效果并平滑迁移现有项目。
📚 参考资料
-
Gemini API 图像生成官方文档: 多轮对话出图的权威说明
- 链接:
ai.google.dev/gemini-api/docs/image-generation - 说明: 包含 contents 字段规范、Python SDK 与 REST 完整示例
- 链接:
-
Gemini 3 Pro Image Preview 模型卡: 模型能力与限制说明
- 链接:
ai.google.dev/gemini-api/docs/models/gemini-3-pro-image-preview - 说明: 上下文窗口、分辨率、参考图数量等关键参数
- 链接:
-
Google AI Developers Forum – Multi-turn Nano Banana: 社区实战示例
- 链接:
discuss.ai.google.dev/t/multi-turn-nano-banana-example - 说明: 真实开发者讨论的多轮对话最佳实践
- 链接:
-
Vertex AI Gemini 3 Pro Image 文档: 企业级部署参考
- 链接:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro-image - 说明: 包含 thought_signature 与 file_data 引用的高级用法
- 链接:
-
API易 Nano Banana Pro 接入文档: 国内开发者快速上手
- 链接:
help.apiyi.com - 说明: 包含 OpenAI 兼容接口、原生 Gemini 接口双模式示例
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区分享你在多轮对话出图中遇到的实战问题,更多 Nano Banana Pro 配置技巧可访问 API易 docs.apiyi.com 文档中心