作者注:解答开发者最常问的问题:大模型 API 能否直接传 PDF?答案是绝大多数不支持。本文详解文字化提取、图片理解、客户端处理 3 种实用方案
"大模型 API 能不能直接把 PDF 文件传进去?"——这是我们客服群里被问得最多的问题之一。很多开发者在网页版 ChatGPT 或 Claude 里用惯了"拖入 PDF 直接对话"的功能,就以为 API 也能这样操作。
实际情况是:绝大多数大模型 API 不支持直接输入 PDF 文件。即使是 OpenAI、Anthropic 这样的头部厂商,API 接口的核心输入格式仍然是文本和图片——PDF 并不在标准支持范围内。更重要的是,API易等第三方 API 中转平台同样不支持 PDF 直传,因为底层协议就不支持。
但别担心,PDF 处理其实有 3 种成熟的解决方案。本文将带你搞清楚来龙去脉,选出最适合你的方式。
核心价值: 读完本文,你将理解大模型 API 为什么不支持 PDF,以及如何用 3 种预处理方案高效解决 PDF 输入需求。

大模型 API PDF 输入核心要点
| 要点 | 说明 | 影响 |
|---|---|---|
| API 不直接接受 PDF | GPT、DeepSeek、Llama、Qwen 等主流模型 API 的标准输入是文本和图片 | 需要前置预处理流程 |
| 网页版 ≠ API | ChatGPT、Claude 网页版的 PDF 上传是前端预处理后再调用 API | 不要把网页体验等同于 API 能力 |
| 第三方平台同样不支持 | API易等中转平台透传原始 API 协议,底层不支持则平台也不支持 | 不要期望中转平台额外处理 PDF |
| 3 种预处理方案成熟可靠 | 文字化提取、图片理解、客户端处理各有适用场景 | 选对方案比找"支持 PDF 的 API"更实际 |
大模型 API 为什么不支持 PDF 输入
很多开发者会困惑:网页版明明可以上传 PDF,为什么 API 不行?原因很简单——网页版的"上传 PDF"功能并不是模型本身在处理 PDF,而是前端/后端在你看不到的地方做了预处理:
- 文本提取: 前端把 PDF 里的文字提取出来,转成纯文本再传给模型
- 页面渲染: 把 PDF 每页渲染成图片,通过 Vision 能力让模型理解
- RAG 检索: 将 PDF 内容向量化存储,对话时只检索相关片段发送给模型
这些预处理步骤在网页版产品中被封装了,用户无感知。但当你直接调用 API 时,这些预处理需要你自己完成。
大模型 API PDF 支持情况速查
| 模型 | API 直传 PDF | 标准输入格式 | PDF 处理建议 |
|---|---|---|---|
| GPT-4o / GPT-4.1 | 不支持 | 文本 + 图片(Base64) | 先提取文本或转图片 |
| Claude | 部分支持(Beta) | 文本 + 图片 | 建议仍走预处理流程更稳定 |
| Gemini | 部分支持 | 文本 + 图片 | 建议仍走预处理流程更可控 |
| DeepSeek | 不支持 | 纯文本 | 必须先提取文本 |
| Llama / Qwen | 不支持 | 文本(部分支持图片) | 必须先提取文本 |
| API易等第三方 | 不支持 | 透传原始协议 | 需在调用前自行预处理 |
🎯 重要说明: 虽然 Claude 和 Gemini 的官方 API 文档中提到了 PDF 输入功能,但该功能存在兼容性和稳定性的不确定性,且通过 API易等第三方中转平台调用时不支持 PDF 直传。我们建议统一走预处理方案,兼容性最好、最稳定。
大模型 API PDF 处理方案一:前置文字化提取
这是最通用、成本最低、兼容所有模型的方案。核心思路:先用 Python 库把 PDF 转成 Markdown 或纯文本,再将文本作为 prompt 传给 API。
PDF 文字化提取工具对比
| 工具 | 速度 | 最佳场景 | 特点 |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/文档 | 通用文本 + 表格提取 | 速度与质量最佳平衡,输出 Markdown |
| pdfplumber | 中等 | 表格数据提取 | 坐标级表格提取精度高 |
| Marker-PDF | ~11s/文档 | 复杂版面保真转换 | 结构保留最好,速度较慢 |
| PyPDF2 | 快 | 简单纯文本 PDF | 轻量级,适合基础提取 |
PDF 文字化提取代码示例
以下是最常用的方案,提取 PDF 文本后传给大模型 API:
import pymupdf4llm
import openai
# 步骤1: PDF 转 Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# 步骤2: 纯文本传给任意大模型
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"请总结这份报告的核心要点:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
适用场景: 合同、论文、报告、技术文档等以文字为主的 PDF。只要 PDF 内嵌了文本层(非扫描件),提取效果都很好。
建议: 文字化提取方案兼容所有大模型——GPT、Claude、DeepSeek、Llama、Qwen 都可以。通过 API易 apiyi.com 获取 API Key,一个 Key 可以调用所有模型进行对比测试。
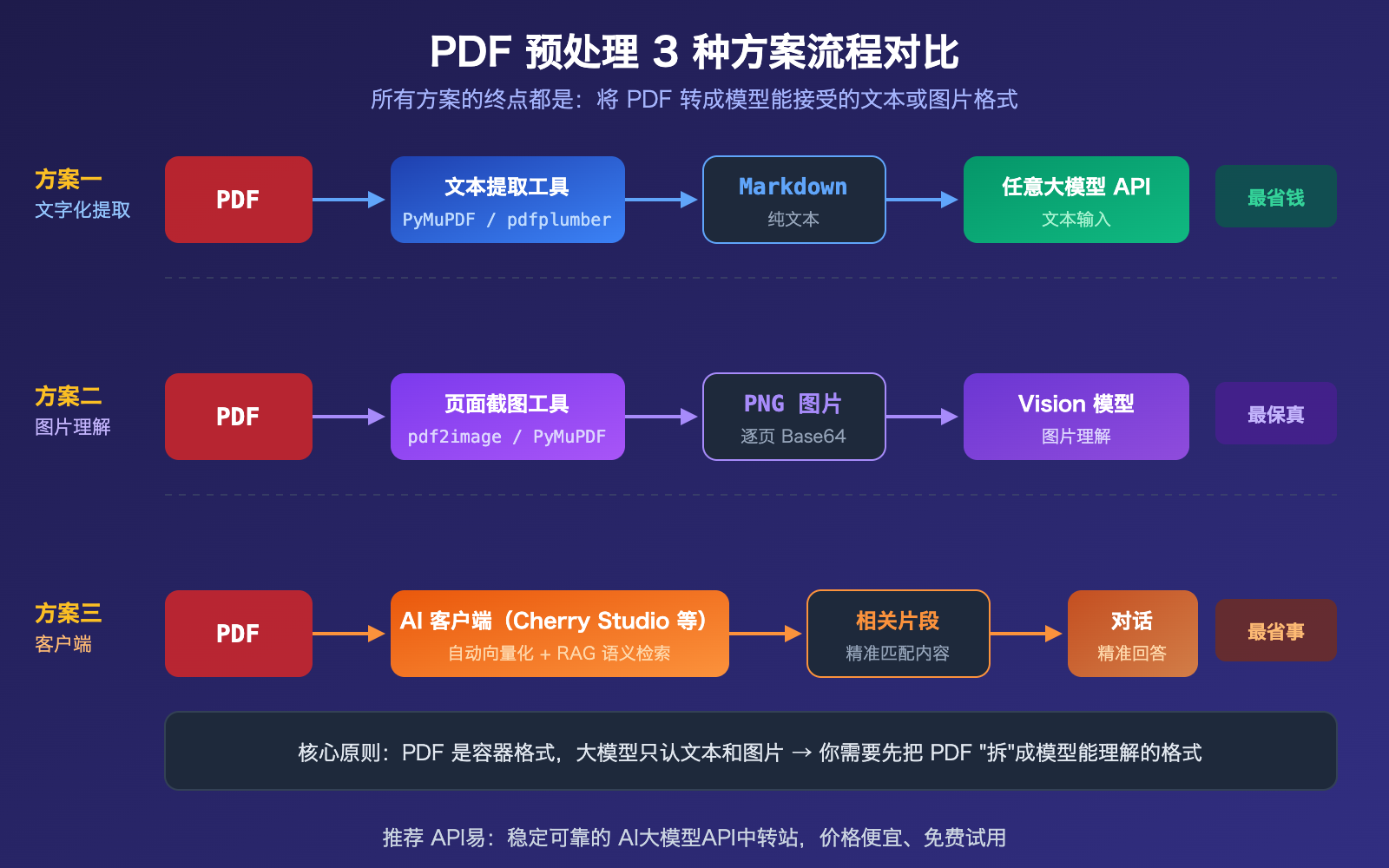
大模型 API PDF 处理方案二:转图片 + 视觉理解
当 PDF 中包含图表、扫描件、复杂排版等视觉信息时,纯文本提取会丢失这些内容。这时需要将 PDF 每页渲染成图片,通过支持 Vision 的模型进行图片理解。
PDF 转图片代码示例
import fitz # PyMuPDF
import base64
import openai
# 步骤1: PDF 逐页转为 PNG 图片
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
查看完整代码:图片传入 Vision API
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""将 PDF 转图片后传入 Vision API"""
doc = fitz.open(pdf_path)
# 构建多图消息(注意控制页数避免 Token 超量)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# 使用示例
result = pdf_to_vision(
"financial_report.pdf",
"请分析这份财报中的趋势图表,总结核心数据",
max_pages=5 # 控制页数,每页约消耗 765 tokens
)
print(result)
适用场景: 带图表的研报、扫描件、发票、建筑图纸等视觉信息丰富的 PDF。
成本提醒: 每页图片约消耗 765 tokens(GPT-4o 标准分辨率),10 页 PDF 就是约 7,650 tokens 的图片成本,加上文字提问和回答可能超过 10,000 tokens。务必控制页数。
🎯 成本控制建议: 不要一次传入整份 PDF 的所有页面。先用方案一提取文本做粗筛,确定关键页面后再用方案二对特定页面做图片理解。通过 API易 apiyi.com 的用量面板可以实时监控 Token 消耗。
大模型 API PDF 处理方案三:AI 客户端处理
如果你不想写代码,只是日常对话中需要"问 PDF 里的内容",使用 AI 客户端是最省事的方式。
Cherry Studio 等客户端的 PDF 处理原理
这类客户端实际上就是帮你自动完成了方案一和方案二的工作:
- 自动向量化: 将 PDF 内容提取后切分成小块,存入本地向量数据库
- 语义检索: 你提问时,客户端先检索最相关的内容片段
- 精准发送: 只把相关片段(而非全文)发送给大模型 API
- 节省 Token: 通过 RAG 检索大幅减少发送给模型的内容量
客户端处理 PDF 的注意事项
- 配置 API Key: 在客户端中填入 API易 apiyi.com 的 API Key,即可通过一个 Key 访问所有模型
- 控制文件大小: 超大 PDF(几百页)向量化时间较长,建议拆分后处理
- 注意 Token 费用: 虽然 RAG 会压缩内容,但长文档仍可能产生较高费用
- 选择合适模型: 简单问答可用便宜模型(如 GPT-4o-mini),复杂分析用旗舰模型
大模型 API PDF 处理 3 种方案对比

| 方案 | Token 成本 | 图表支持 | 开发难度 | 模型兼容 | 最佳场景 |
|---|---|---|---|---|---|
| 文字化提取 | 最低(300-1500/页) | 不支持 | 中等 | 所有模型 | 纯文本 PDF、大批量 |
| 转图片理解 | 较高(~765/页) | 完整支持 | 中等 | 需 Vision 模型 | 图表、扫描件 |
| 客户端处理 | 中等(RAG 压缩) | 取决于客户端 | 零代码 | 所有模型 | 日常对话、非开发 |
对比说明: 三种方案不是互斥的,实际项目中往往组合使用。例如先用方案一提取文本做粗筛,再对关键页面用方案二做图片理解。通过 API易 apiyi.com 可以统一接入所有模型。
常见问题
Q1: 为什么 ChatGPT 网页版可以上传 PDF,但 API 不支持?
网页版的"上传 PDF"功能是产品前端帮你做了预处理——提取文本、渲染图片、建立检索索引——然后再调用底层 API。API 本身的核心输入格式是文本和图片,PDF 作为一种复杂的文档容器格式不在标准支持范围内。你调用 API 时,需要自己完成这些预处理步骤。
Q2: API易等第三方中转平台能帮我处理 PDF 吗?
不能。API易等中转平台的本质是透传 API 请求,底层协议不支持 PDF 的话,平台也无法处理。你需要在调用 API 之前自行完成 PDF 的预处理(提取文本或转图片),然后将处理后的文本或图片通过 API易 apiyi.com 发送给大模型。
Q3: 处理 PDF 时如何控制 Token 费用?
几个实用技巧:
- 优先用方案一(文字化提取),成本最低
- 只处理需要的页面,不要一次传整份文档
- 使用 RAG 技术切分+检索,只发送相关片段给模型
- 简单问答用便宜模型(GPT-4o-mini),复杂分析用旗舰模型
- 通过 API易 apiyi.com 的用量面板实时监控消耗
总结
大模型 API PDF 输入的核心要点:
- 绝大多数 API 不支持直接 PDF 输入: 大模型的核心输入是文本和图片,PDF 需要预处理后才能使用
- 第三方平台同样不支持: API易等中转平台透传原始协议,无法额外处理 PDF
- 3 种方案按需选择: 纯文本 PDF 用文字化提取(最省钱),带图 PDF 转图片理解(最保真),日常对话用客户端(最省事)
不必纠结于"哪个 API 支持 PDF",而是把精力放在选对预处理方案上——这才是正确的思路。
推荐通过 API易 apiyi.com 获取免费额度,预处理 PDF 后用一个 API Key 调用 GPT、Claude、DeepSeek 等所有主流模型进行测试对比。
📚 参考资料
-
PyMuPDF4LLM 文档: PDF 文字化提取工具
- 链接:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - 说明: 速度最快的 PDF 转 Markdown 工具,推荐首选
- 链接:
-
pdfplumber 文档: 表格提取专用工具
- 链接:
github.com/jsvine/pdfplumber - 说明: PDF 中表格数据提取精度最高的工具
- 链接:
-
Cherry Studio: 开源 AI 客户端
- 链接:
github.com/CherryHQ/cherry-studio - 说明: 支持 PDF 拖入对话的免费客户端,可配置 API易作为后端
- 链接:
-
API易平台文档: 统一接入各大模型 API
- 链接:
docs.apiyi.com - 说明: API Key 获取、模型列表和调用示例
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心