用 Nano Banana 生成图片时,很多开发者都遇到过一个让人抓狂的问题:图片画得很漂亮,但上面的文字要么拼写错误、要么糊成一团、要么干脆变成了乱码。
好消息是,Google 官方文档里其实给出了一个关键提示:先让模型生成文字内容,然后再要求生成包含该文字的图片。这就是所谓的「两步法」(Two-Step Approach),能显著提升文字渲染的准确率。
本文将深度分析这个现象背后的技术原因,并给出 6 个经过实测有效的文字渲染技巧,帮你让 Nano Banana 出图时的文字又清晰又准确。
核心价值: 读完本文,你将理解 Nano Banana 文字渲染的工作原理,掌握两步法等 6 个实用技巧,把图片文字准确率从"碰运气"提升到可控水平。
Nano Banana 文字渲染的现状:能力很强但需要技巧
先说结论:Nano Banana 系列模型的文字渲染能力在 AI 图像生成领域属于顶级水平,但它不是"随便写个 prompt 就能完美出字"的。
Nano Banana 文字渲染准确率数据
| 模型 | 文字准确率 | 多语言支持 | 最长可靠文字 | 说明 |
|---|---|---|---|---|
| Nano Banana Pro | ~94% | 优秀 | 约 25 字符 | 最高精度,适合商业级海报 |
| Nano Banana 2 | ~87% | 优秀 | 约 20 字符 | 速度快,性价比高 |
| DALL-E 3 | ~78% | 良好 | 约 15 字符 | 长文字容易出错 |
| Stable Diffusion XL | ~45% | 较差 | 约 8 字符 | 基本不可靠 |
| Midjourney v6 | ~65% | 一般 | 约 12 字符 | 风格好但文字弱 |
可以看到,Nano Banana Pro 的 94% 准确率已经是业界最高水平。但剩下的 6% 失败场景——拼写错误、文字模糊、字符缺失——对于商业场景来说是不可接受的。
为什么 AI 图像生成的文字渲染这么难
要理解为什么需要"两步法",先要明白 AI 生成图片中文字的难点:
- 像素级精确要求: 图片中的文字必须像素级准确,差一个笔画就变成了错别字。而 AI 生成的其他内容(风景、人物)允许一定程度的模糊
- 字符组合爆炸: 英文 26 个字母、中文数千个汉字,加上大小写、字体、排列组合,可能性几乎无限
- 上下文干扰: 模型在生成图片整体构图时,容易"分心"——既要画好背景、又要排好文字,两个任务互相争夺注意力
- 训练数据偏差: 训练集中完美文字的图片比例有限,模型对某些字体和排版组合的学习不够充分
🎯 技术建议: 理解了文字渲染的难点,才能有针对性地优化 prompt。通过 API易 apiyi.com 平台调用 Nano Banana Pro 和 Nano Banana 2,可以快速对比两个模型的文字渲染效果,选择最适合你场景的方案。
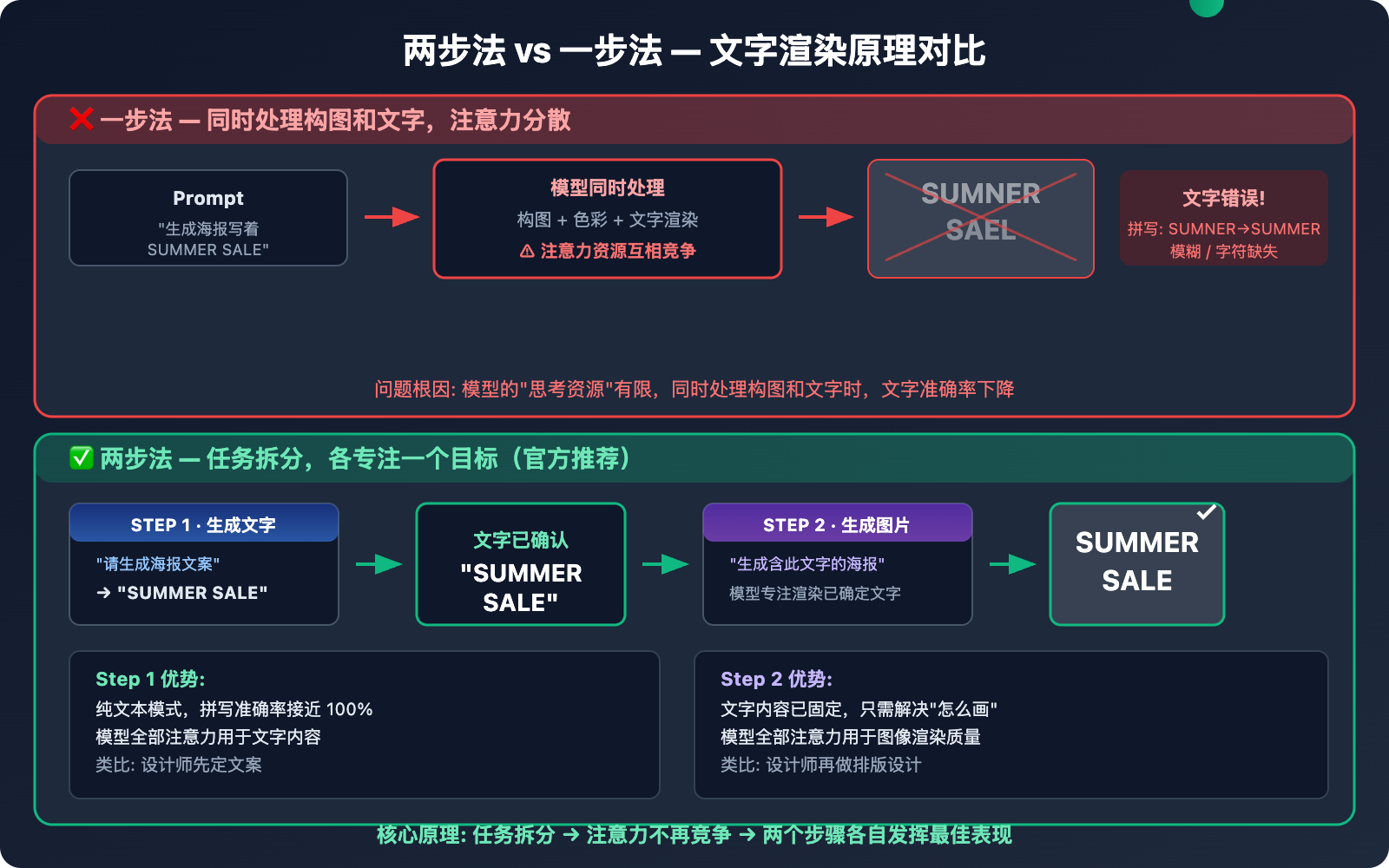
核心技巧一:两步法——官方推荐的文字渲染最佳实践
这是 Google 官方文档明确推荐的方法,也是本文最重要的技巧。
两步法的原理
传统一步法(效果差):
"生成一张海报,上面写着 'SUMMER SALE 50% OFF'"
→ 模型同时处理构图和文字 → 文字容易出错
两步法(效果好):
第一步: "请帮我生成海报文案: 夏季促销50%折扣"
→ 模型输出文字: "SUMMER SALE 50% OFF"
第二步: "生成一张海报图片,上面精确显示文字 'SUMMER SALE 50% OFF'"
→ 模型专注于将已确定的文字渲染到图片中 → 准确率大幅提升
为什么两步法有效——技术层面的解释
Nano Banana 是基于 Gemini 多模态大模型构建的。当你用一步法直接要求"生成一张包含某些文字的图片"时,模型需要同时完成两个任务:
- 理解并规划图像构图 — 场景、色彩、布局
- 精确渲染文字字符 — 拼写、字体、位置
这两个任务在模型的注意力机制中会互相竞争。模型的"思考资源"是有限的,同时处理两个高精度任务时,文字部分往往成为牺牲品。
而两步法的核心思路是任务拆分:
- 第一步让模型专注于文字内容的生成和确认 — 此时模型处于纯文本模式,拼写准确率极高
- 第二步让模型专注于将已确定的文字渲染进图片 — 文字内容已经固定,模型只需要解决"怎么画"的问题
这就像让一个画家先确定海报上要写什么字(文案阶段),再去画海报(设计阶段)。两个阶段分开做,效率和准确率都更高。
两步法 API 代码实现
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易 统一接口
)
# ========== 第一步: 让模型生成/确认文字内容 ==========
text_response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{
"role": "user",
"content": "我需要一张咖啡店的宣传海报。请帮我生成海报上需要展示的英文文案,要求简洁有力,不超过 20 个字符。只输出文案文字,不要其他内容。"
}]
)
poster_text = text_response.choices[0].message.content.strip()
print(f"第一步 - 生成文案: {poster_text}")
# 输出示例: "BREW YOUR PERFECT DAY"
# ========== 第二步: 用确定的文字生成图片 ==========
image_response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{
"role": "user",
"content": f'Generate an image: A warm-toned coffee shop promotional poster. Display the exact text "{poster_text}" in bold serif font, centered at the top. Background shows a cozy cafe interior with warm lighting.'
}]
)
print("第二步 - 图片生成完成")
两步法的关键细节
| 细节 | 说明 | 原因 |
|---|---|---|
| 第一步用纯文本模式 | 不要在第一步就要求生成图片 | 让模型专注于文字质量 |
| 文字用双引号包裹 | 第二步 prompt 中用 "..." 包裹文字 |
明确告诉模型这是需要原样渲染的内容 |
| 第二步用英文 prompt | 图片生成指令建议用英文 | 英文 prompt 的理解准确率更高 |
| 指定字体风格 | 加上 bold serif font 等描述 |
帮助模型选择更易渲染的字体 |
| 限制文字长度 | 第一步就控制在 25 字符以内 | 超过 25 字符准确率显著下降 |
核心技巧二:25 字符黄金法则
这是 Nano Banana 文字渲染最重要的硬约束。
Nano Banana 文字渲染准确率与字符数的关系
| 字符数范围 | 准确率 | 建议 |
|---|---|---|
| 1-10 字符 | ~98% | 最佳区间,几乎不出错 |
| 11-20 字符 | ~92% | 安全区间,偶有小问题 |
| 21-25 字符 | ~85% | 可用但需检查,可能需重试 |
| 26-40 字符 | ~60% | 高风险区间,频繁出错 |
| 40+ 字符 | <40% | 不推荐,基本不可靠 |
超过 25 字符的应对策略
当你的文字确实超过 25 字符时,有 3 种处理方式:
策略一:拆分为多行短文字
# ❌ 一次性渲染长文字
prompt = 'Generate a poster with text "ANNUAL SUMMER CLEARANCE SALE - UP TO 70% OFF ALL ITEMS"'
# ✅ 拆分为多行短文字
prompt = '''Generate a poster with two lines of text:
Line 1 (large, bold): "SUMMER SALE 70% OFF"
Line 2 (smaller, below): "ALL ITEMS INCLUDED"'''
策略二:多轮对话逐步添加
# 第1轮: 生成只有主标题的图片
# 第2轮: 在上一轮结果基础上添加副标题
# 第3轮: 再添加底部说明文字
策略三:关键文字用图片,长文字用后期合成
对于确实需要大量文字的场景(如信息图表),建议只用 Nano Banana 生成关键的短标题,长段落文字在后期用设计工具叠加。
核心技巧三:双引号包裹 + 字体显式指定
这两个小技巧组合使用,能让文字渲染准确率再提升一个台阶。
双引号的作用
双引号告诉模型:引号内的内容是需要逐字符精确渲染的文字,而不是一般性描述。
# ❌ 没有引号,模型可能自由发挥
prompt = "Generate a sign that says Welcome to Tokyo"
# 可能输出: "WELCOME TO TOKIO" (拼写错误) 或完全不同的文字
# ✅ 双引号包裹,强制逐字渲染
prompt = 'Generate a sign that displays the exact text "Welcome to Tokyo"'
# 输出: "Welcome to Tokyo" (大概率精确)
字体显式指定
明确指定字体类型可以帮助模型选择更容易渲染的字体形态:
| 字体指定 | Prompt 写法 | 效果 |
|---|---|---|
| 粗体衬线 | bold serif font |
最清晰,推荐海报标题 |
| 无衬线 | clean sans-serif font |
现代感,适合科技主题 |
| 手写体 | handwritten script |
文字准确率较低,慎用 |
| 等宽字体 | monospace font |
适合代码截图场景 |
| 特定字体 | in Helvetica style |
风格参考,不保证完全匹配 |
💡 实用提示: 粗体衬线字体(bold serif)是文字渲染准确率最高的字体类型。因为笔画粗、结构清晰,模型更容易准确生成。手写体和花体字的准确率最低,尽量避免用于关键文字。
核心技巧四:多语言文字渲染的特殊处理
Nano Banana 在多语言文字渲染上表现优秀,但不同语言的处理策略有差异。
不同语言的文字渲染表现
| 语言 | 渲染准确率 | 最佳字符数 | 特殊注意 |
|---|---|---|---|
| 英文 | ~94% | ≤25 | 全大写效果最好 |
| 中文 | ~85% | ≤8 个汉字 | 简体优于繁体 |
| 日文 | ~82% | ≤10 | 平假名优于汉字 |
| 韩文 | ~80% | ≤12 | 需明确指定韩文 |
| 阿拉伯文 | ~75% | ≤8 | 注意右到左排列 |
多语言文字渲染 Prompt 模板
# 英文 — 最可靠
prompt = 'Generate a poster with bold text "HELLO WORLD" in white serif font'
# 中文 — 指定语言 + 简短
prompt = 'Generate a poster with Chinese text "欢迎光临" in bold Chinese calligraphy style font, centered'
# 日文 — 明确语种
prompt = 'Generate a Japanese store sign with text "いらっしゃいませ" in clean sans-serif Japanese font'
# 混合语言 — 分行处理
prompt = '''Generate a bilingual poster:
Top line in English: "GRAND OPENING"
Bottom line in Chinese: "盛大开业"
Both in bold, high contrast against dark background'''
🎯 技术建议: 多语言文字渲染建议通过 API易 apiyi.com 平台反复测试对比。不同语言的效果差异较大,实际测试比理论参数更可靠。平台支持 Nano Banana Pro 和 Nano Banana 2 两个模型的快速切换。
核心技巧五:Prompt 结构化模板(实战必备)
把前面的所有技巧组合成一个标准化的 Prompt 模板,用于不同场景。
Nano Banana 文字渲染万能 Prompt 模板
Generate an image:
[场景描述, 100字以内].
Display the exact text "[你的文字, ≤25字符]" in [字体风格] font,
positioned at [位置], [大小描述].
The text should be [颜色] with high contrast against the background.
Ensure the text is perfectly legible and correctly spelled.
不同场景的实战示例
场景一:商业海报
prompt = '''Generate an image:
A vibrant summer sale promotional poster with tropical beach background.
Display the exact text "SUMMER SALE" in bold white serif font,
positioned at the center top, large and prominent.
Below it, display "50% OFF" in bold yellow sans-serif font.
The text should have high contrast against the background.
Ensure all text is perfectly legible and correctly spelled.'''
场景二:Logo 设计
prompt = '''Generate an image:
A minimalist tech company logo on a clean white background.
Display the exact text "NEXUS" in modern bold sans-serif font,
positioned at the center, medium size.
The text should be dark navy blue (#1a1a2e).
Ensure the text is perfectly legible and correctly spelled.'''
场景三:社交媒体配图
prompt = '''Generate an image:
An inspirational quote card with soft gradient background (blue to purple).
Display the exact text "START NOW" in elegant white serif font,
positioned at the center, large and prominent.
The text should be pure white with subtle drop shadow.
Ensure the text is perfectly legible and correctly spelled.'''

核心技巧六:多轮对话迭代修正
即使使用了前 5 个技巧,文字渲染仍然可能不完美。Nano Banana 的一大优势是支持多轮对话编辑——不满意就直接在上一轮结果基础上修正。
文字修正对话流程
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
messages = []
# 第1轮: 生成初始图片
messages.append({
"role": "user",
"content": 'Generate an image: A coffee shop menu board with text "TODAY\'S SPECIAL" in chalk-style white font on dark background'
})
response_1 = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=messages
)
messages.append({"role": "assistant", "content": response_1.choices[0].message.content})
# 第2轮: 检查并修正文字
messages.append({
"role": "user",
"content": 'The text is slightly blurry. Please regenerate with the text "TODAY\'S SPECIAL" rendered more sharply and clearly. Make the font bolder and increase the contrast.'
})
response_2 = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=messages
)
常用修正指令
| 问题 | 修正 Prompt |
|---|---|
| 文字模糊 | "Make the text sharper and bolder, increase contrast" |
| 拼写错误 | "Fix the spelling. The correct text should be exactly '[正确文字]'" |
| 文字缺失 | "The text '[文字]' is missing. Add it at [位置] in [字体]" |
| 字体不对 | "Change the font to bold serif, keep the same text content" |
| 位置偏移 | "Move the text to the center of the image, keep everything else" |
| 大小不合适 | "Make the text larger/smaller while keeping it legible" |
🚀 快速开始: 多轮对话编辑非常适合对文字效果有高要求的场景。通过 API易 apiyi.com 平台调用 Nano Banana,每轮编辑约 $0.02,3-4 轮迭代即可达到满意效果。
Nano Banana 文字渲染完整工作流
把 6 个技巧整合成一个标准化的工作流:
第一步:规划文字内容
- 确定需要渲染的文字(≤25 字符)
- 超过 25 字符则拆分为多行
- 确认拼写准确
第二步:两步法生成
- 先让模型确认/优化文字内容
- 再用确定的文字生成图片
第三步:Prompt 优化
- 双引号包裹文字
- 显式指定字体风格
- 使用结构化模板
- 添加
"Ensure text is perfectly legible"约束
第四步:检查与迭代
- 检查生成结果的文字是否准确
- 不满意则用多轮对话修正
- 通常 1-3 轮即可达到满意效果
查看完整的文字渲染工作流代码
#!/usr/bin/env python3
"""
Nano Banana 文字渲染优化工作流
两步法 + 6 大技巧的完整实现
"""
import openai
import base64
import re
from datetime import datetime
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://api.apiyi.com/v1"
client = openai.OpenAI(api_key=API_KEY, base_url=BASE_URL)
def render_text_in_image(
scene_description: str,
desired_text: str,
font_style: str = "bold serif",
text_color: str = "white",
text_position: str = "centered",
model: str = "gemini-3.1-flash-image-preview",
max_fix_rounds: int = 2
):
"""
使用两步法生成带有准确文字的图片
Args:
scene_description: 场景描述(不含文字要求)
desired_text: 需要渲染的文字(建议≤25字符)
font_style: 字体风格
text_color: 文字颜色
text_position: 文字位置
model: 使用的模型
max_fix_rounds: 最大修正轮数
"""
# 检查文字长度
if len(desired_text) > 25:
print(f"⚠️ 文字长度 {len(desired_text)} 超过 25 字符,准确率可能下降")
# ===== 第一步: 确认文字内容 =====
print(f"📝 第一步: 确认文字内容 → '{desired_text}'")
text_check = client.chat.completions.create(
model=model,
messages=[{
"role": "user",
"content": f"Please verify this text is correctly spelled and formatted: '{desired_text}'. Only reply with the verified text, nothing else."
}]
)
verified_text = text_check.choices[0].message.content.strip().strip("'\"")
print(f"✅ 确认文字: '{verified_text}'")
# ===== 第二步: 生成含文字的图片 =====
print(f"🎨 第二步: 生成图片...")
image_prompt = f'''Generate an image:
{scene_description}.
Display the exact text "{verified_text}" in {font_style} font,
positioned at {text_position}, with {text_color} color.
The text should have high contrast against the background.
Ensure the text is perfectly legible and correctly spelled.'''
messages = [{"role": "user", "content": image_prompt}]
response = client.chat.completions.create(
model=model,
messages=messages
)
content = response.choices[0].message.content
print(f"✅ 图片生成完成")
# 保存图片
save_image(content, f"text_render_{datetime.now().strftime('%H%M%S')}.png")
return content
def save_image(content, filename):
"""从响应中提取并保存图片"""
patterns = [
r'data:image/[^;]+;base64,([A-Za-z0-9+/=]+)',
r'([A-Za-z0-9+/=]{1000,})'
]
for pattern in patterns:
match = re.search(pattern, content)
if match:
data = base64.b64decode(match.group(1))
with open(filename, 'wb') as f:
f.write(data)
print(f"💾 保存到: {filename} ({len(data):,} 字节)")
return True
print("⚠️ 未找到图片数据")
return False
# ===== 使用示例 =====
if __name__ == "__main__":
# 示例 1: 商业海报
render_text_in_image(
scene_description="A vibrant promotional poster with tropical beach background, summer vibes",
desired_text="SUMMER SALE",
font_style="bold white serif",
text_position="top center, large and prominent"
)
# 示例 2: Logo
render_text_in_image(
scene_description="A minimalist tech company logo on clean white background",
desired_text="NEXUS",
font_style="modern bold sans-serif",
text_color="dark navy blue",
text_position="centered"
)
# 示例 3: 中文
render_text_in_image(
scene_description="A traditional Chinese restaurant sign with red and gold decorations",
desired_text="福满楼",
font_style="bold Chinese calligraphy",
text_color="gold",
text_position="centered, large"
)
Nano Banana Pro 与 Nano Banana 2 文字渲染对比
两个模型在文字渲染上各有侧重:
| 对比维度 | Nano Banana Pro | Nano Banana 2 | 选择建议 |
|---|---|---|---|
| 文字准确率 | ~94% | ~87% | 商业级要求选 Pro |
| 最大可靠字符 | ~25 | ~20 | Pro 容错空间更大 |
| 多语言支持 | 优秀 | 优秀 | 两者持平 |
| 字体风格多样性 | 更丰富 | 够用 | Pro 更多字体选择 |
| 生成速度 | 10-20 秒 | 3-8 秒 | 快速迭代选 Banana 2 |
| API 价格 | ~$0.04/次 | ~$0.02/次 | 成本敏感选 Banana 2 |
| 迭代修正能力 | 优秀 | 优秀 | 两者持平 |
| 模型 ID | gemini-3.0-pro-image |
gemini-3.1-flash-image-preview |
可通过 API易 apiyi.com 同时调用 |
文字渲染的模型选择建议
- 商业海报/品牌物料: 选 Nano Banana Pro — 94% 准确率 + 更多字体风格
- 社交媒体配图/快速原型: 选 Nano Banana 2 — 速度快 + 性价比高
- 需要反复迭代的场景: 选 Nano Banana 2 — 速度快意味着迭代成本低
- 多语言文字: 两者差异不大,按速度/成本需求选择
常见问题
Q1: 为什么 Google 官方建议”先生成文字再生成图片”?
这是因为多模态模型同时处理"生成文字内容"和"渲染文字到图片"两个任务时,注意力资源会互相竞争,导致文字准确率下降。两步法通过任务拆分,让模型在第一步专注于文字的正确性(纯文本模式,接近 100% 准确),第二步专注于将已确定的文字渲染进图片。这个原理类似于人类设计师先定文案再做设计。通过 API易 apiyi.com 平台两步法调用非常方便,两次 API 调用总成本也不到 $0.05。
Q2: 25 字符的限制是硬性的吗?超过就一定出错?
不是硬性限制,而是准确率的分水岭。25 字符以内准确率在 85%-98% 之间,超过 25 字符后准确率会显著下降到 60% 以下。如果必须使用较长文字,建议拆分为多行(每行 ≤15 字符),或使用多轮对话逐步添加。
Q3: 中文文字渲染效果怎么样?比英文差很多吗?
Nano Banana 的中文文字渲染效果比大多数竞品好得多,但确实比英文略逊。实测中文准确率约 85%(英文 94%)。建议中文控制在 8 个汉字以内,使用粗体风格,并在 prompt 中明确指定 "Chinese text" 和 "Chinese calligraphy font" 或 "bold Chinese font"。通过 API易 apiyi.com 平台可以快速测试不同 prompt 写法的中文渲染效果。
Q4: 两步法会不会增加很多成本?
两步法确实需要调用两次 API,但第一步是纯文本生成(不涉及图片),成本极低(不到 $0.001)。第二步才是图片生成($0.02-$0.04)。所以总成本只增加了不到 5%,但文字准确率提升非常显著。考虑到不用两步法时可能需要重试 3-5 次才能得到正确的文字,两步法实际上更省钱。
Q5: 有没有完全不出错的方法?
目前 AI 图像生成的文字渲染还不能保证 100% 准确。即使用了所有优化技巧,仍然建议在工作流中加入人工检查环节——尤其是商业用途的图片。对于要求绝对准确的场景(如法律文档截图、正式证书),建议用 AI 生成背景和构图,文字部分用设计工具后期叠加。
总结
Nano Banana 的文字渲染能力在 AI 图像生成领域已经是顶级水平(Pro 94%,Banana 2 87%),但要稳定发挥这个能力需要掌握正确的技巧。
6 个核心技巧按重要性排序:
- 两步法 — 先生成文字再生成图片,官方推荐,效果最显著
- 25 字符法则 — 控制文字长度,超长文字拆分处理
- 双引号 + 字体指定 — 强制逐字渲染 + 选择高准确率字体
- 多语言特殊处理 — 不同语言用不同策略
- 结构化 Prompt 模板 — 标准化提升稳定性
- 多轮对话修正 — 不满意就迭代优化
掌握这些技巧后,Nano Banana 的文字渲染就从"碰运气"变成了可控可预期的能力。推荐通过 API易 apiyi.com 快速开始测试,找到最适合你场景的参数组合。
参考资料
-
Google 官方 – Nano Banana Image Generation Documentation
- 链接:
ai.google.dev/gemini-api/docs/image-generation - 说明: 包含"先生成文字再生成图片"的官方建议
- 链接:
-
Google Developers Blog – Prompting Tips for Nano Banana Pro
- 链接:
blog.google/products/gemini/prompting-tips-nano-banana-pro/ - 说明: 官方 prompt 优化技巧
- 链接:
-
Google Developers Blog – How to Prompt Gemini 2.5 Flash Image Generation
- 链接:
developers.googleblog.com/how-to-prompt-gemini-2-5-flash-image-generation-for-the-best-results/ - 说明: Flash 系列模型的出图优化策略
- 链接:
📝 作者: APIYI Team | 技术交流和 API 接入请访问 apiyi.com