Nano Banana 2 出图失败是开发者在使用 Gemini 图片生成 API 时最常遇到的问题。2026 年 2 月 27 日 Nano Banana 2 正式上线后,谷歌的内容安全机制发生了 重大升级,知名人物、金融信息修改、人物换装换脸、隐性性暗示等场景的安全过滤更加严格。
核心价值: 读完本文,你将全面了解 Nano Banana 2 的双层安全架构、8 类出图失败的具体原因、API 错误码的含义,以及针对不同场景的应对策略。
Nano Banana 2 内容安全机制 核心要点
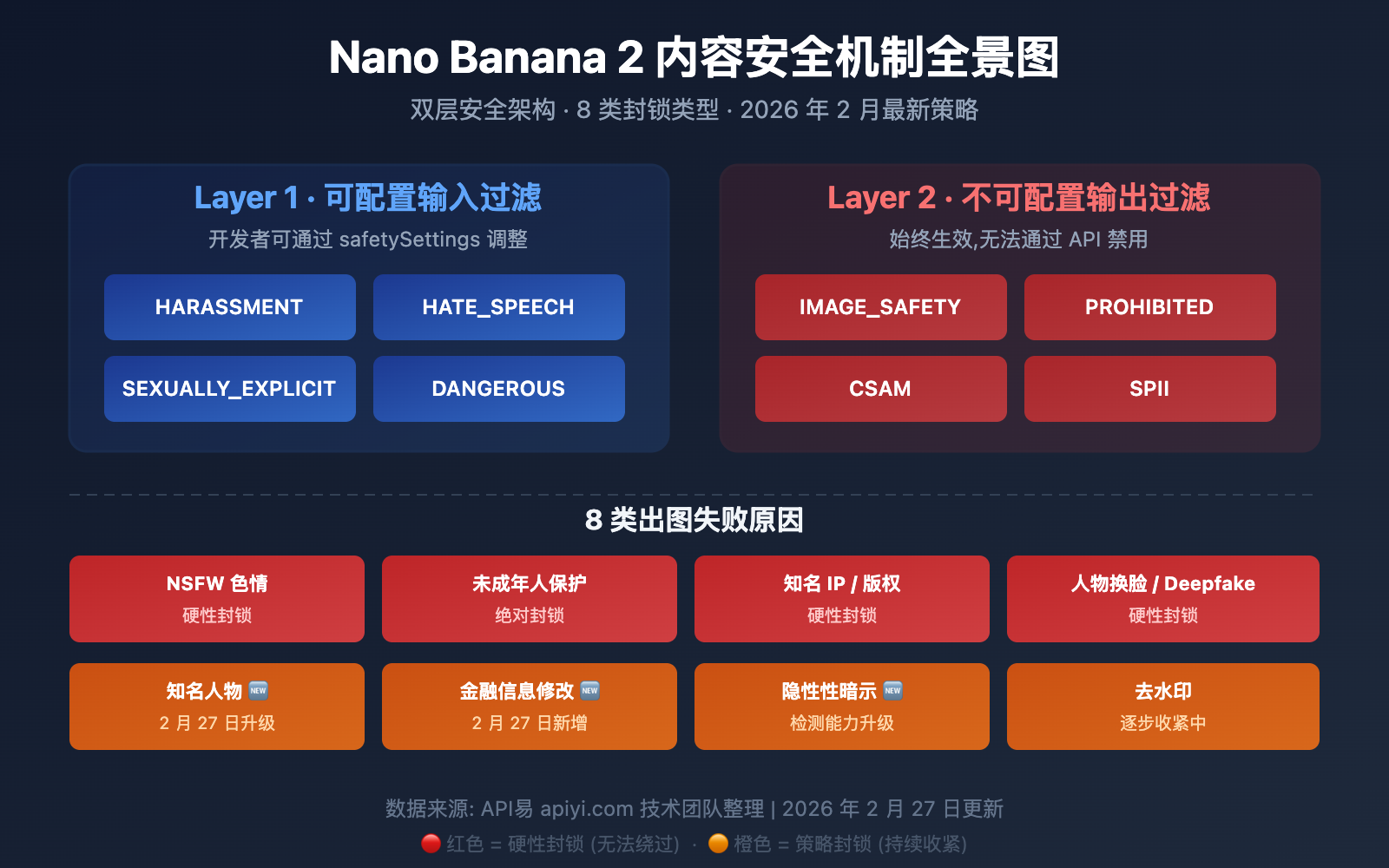
Nano Banana 2 (即 Gemini 图片生成模型) 的安全机制并非简单的关键词过滤,而是一套 双层安全架构,理解这套架构是解决出图失败问题的关键。
| 要点 | 说明 | 对开发者的影响 |
|---|---|---|
| 双层架构 | Layer 1 可配置输入过滤 + Layer 2 不可配置输出过滤 | 即使设置 BLOCK_NONE 也无法绕过所有限制 |
| 8 类封锁 | NSFW、水印、知名 IP、未成年人、名人、金融、换脸、隐性暗示 | 不同类型需要不同的应对策略 |
| 策略收紧 | 2026 年 1 月 + 2 月两次重大更新 | 之前能通过的内容现在可能被拦截 |
| 透明代理 | API易直接转发谷歌原始响应 | 状态码 200 但无图 = 谷歌安全过滤器拦截 |
Nano Banana 2 内容安全 双层架构详解
Layer 1 — 可配置输入过滤 (Safety Settings)
这是开发者可以通过 API 参数调整的第一层过滤,应用在文本提示词进入模型之前。包含 4 个可调节的危害分类:
HARM_CATEGORY_HARASSMENT— 骚扰内容HARM_CATEGORY_HATE_SPEECH— 仇恨言论HARM_CATEGORY_SEXUALLY_EXPLICIT— 色情内容HARM_CATEGORY_DANGEROUS_CONTENT— 危险内容
每个分类支持 5 个阈值等级:
| 阈值设置 | 行为 | 严格程度 |
|---|---|---|
BLOCK_LOW_AND_ABOVE |
封锁低、中、高概率内容 | 最严格 |
BLOCK_MEDIUM_AND_ABOVE |
封锁中、高概率内容 | 默认值 |
BLOCK_ONLY_HIGH |
仅封锁高概率内容 | 较宽松 |
BLOCK_NONE |
禁用该分类的概率封锁 | 最宽松 |
HARM_BLOCK_THRESHOLD_UNSPECIFIED |
使用平台默认值 | 依赖平台 |
Layer 2 — 不可配置输出过滤 (Hard Blocks)
这是始终激活、无法通过任何 API 参数禁用的第二层过滤,应用在图片生成之后:
IMAGE_SAFETY— 图片内容安全评估PROHIBITED_CONTENT— 违反禁止内容策略 (版权/IP)CSAM— 儿童性虐待材料检测 (绝对硬性封锁)SPII— 敏感个人身份信息
🎯 关键认知: 很多开发者把所有安全分类都设置为
BLOCK_NONE后发现图片仍然被封锁,原因就在于 Layer 2 的硬性封锁始终生效。通过 API易 apiyi.com 平台调用时,我们透明代理直接转发谷歌的原始响应,因此您看到的错误信息就是谷歌安全系统的真实反馈。
Nano Banana 2 出图失败 8 类原因完整分析
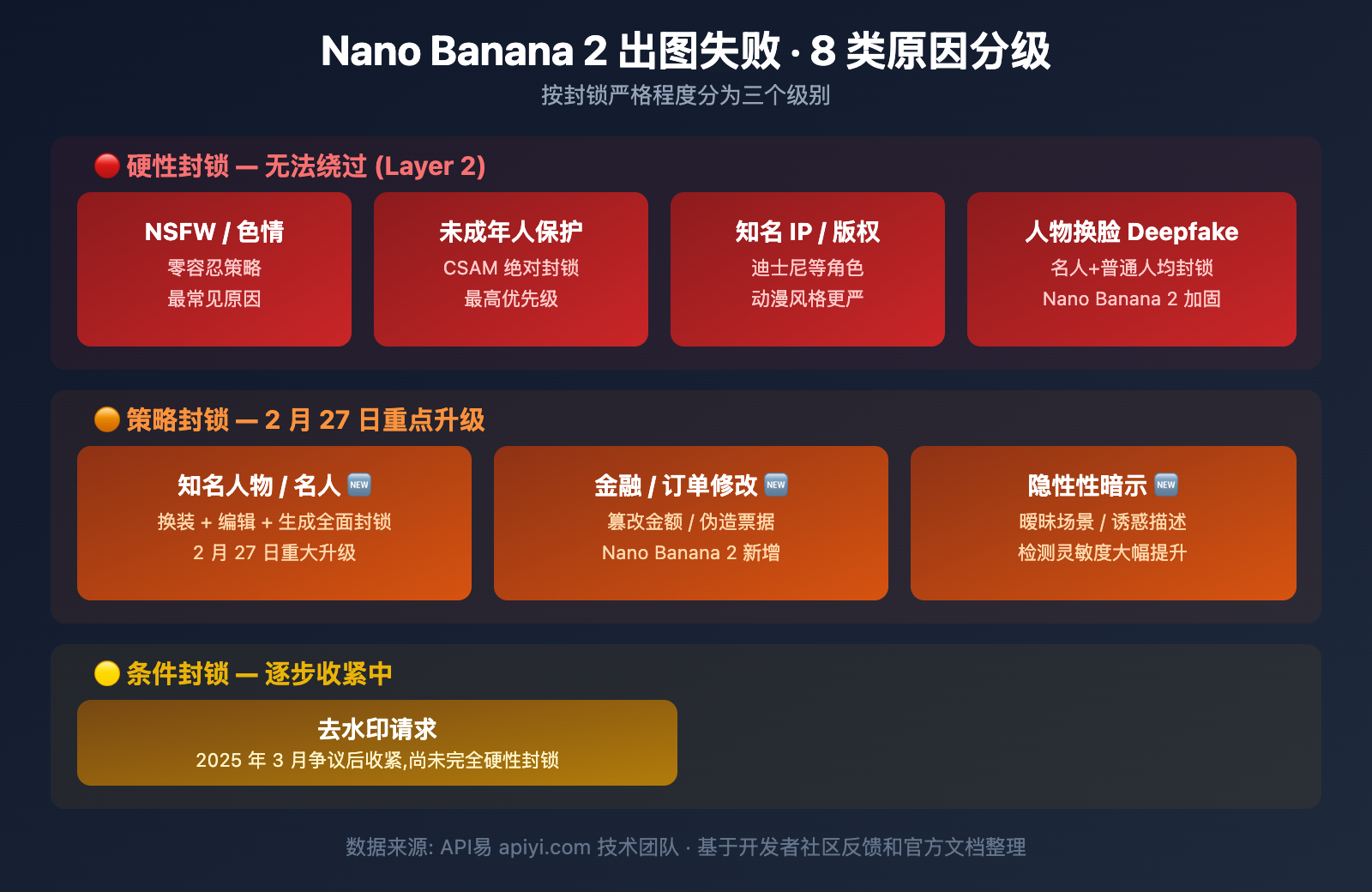
根据谷歌安全策略和开发者社区的大量反馈,Nano Banana 2 出图失败的原因可以归纳为以下 8 类:
第一类: NSFW / 色情内容 (硬性封锁)
封锁级别: 🔴 硬性封锁 — 无法绕过
这是最常见的出图失败原因。Gemini 对色情内容采取「零容忍」策略,比其他主流 AI 模型更加严格。
被封锁的内容包括:
- 色情或情色内容
- 性暴力、性虐待场景
- 真实或虚构人物的性爱场景
- 暴露性内容和裸露
典型错误信息:
"I can't generate that image."
"The prompt couldn't be submitted — it might violate our policies."
开发者注意: 2025 年 11 月的一项安全评估发现,虽然直接的色情提示词被有效拦截,但多轮对话升级和重复提示注入在 21 个测试案例中有 19 个成功绕过了审核。谷歌正在持续加固这方面的防线。
第二类: 去水印请求 (特殊封锁)
封锁级别: 🟠 策略封锁 — 2025 年 3 月后逐步收紧
去水印是一个比较特殊的场景。2025 年 3 月,媒体广泛报道 Gemini 2.0 Flash 能够去除 Getty Images 等版权水印并无缝修复画面,引发了巨大争议。
关键发现:
- 消费端 Gemini App 会显示伦理警告
- 但通过 AI Studio API 访问时,相同模型 缺少 这些护栏
- Anthropic Claude 和 OpenAI GPT-4o 明确拒绝去水印请求
当前状态: 谷歌声明去水印违反服务条款,正在逐步加强技术层面的封锁。但与 NSFW 不同,去水印的封锁尚未达到 100% 硬性封锁的程度。
第三类: 知名 IP / 版权角色 (硬性封锁)
封锁级别: 🔴 硬性封锁 — 几乎无法绕过
迪士尼角色、知名动漫角色等受版权保护的 IP 会触发 PROHIBITED_CONTENT 过滤器。
特殊现象 — 动漫风格过度封锁:
开发者社区广泛报告一个问题: 动漫 (Anime) 风格的图片比写实风格被 更激进地 封锁。同样的猫咪图片提示,动漫风格被拦截,写实风格却能通过。这似乎是一个过度敏感的启发式算法,而非有意为之的策略。
第四类: 未成年人保护 (绝对封锁)
封锁级别: 🔴🔴 绝对硬性封锁 — 无任何例外
CSAM (儿童性虐待材料) 检测是所有安全机制中级别最高的,在任何配置下都无法禁用。
- 任何涉及未成年人的性相关内容均被绝对封锁
- 2025 年初有媒体发现即使 13 岁注册的账户,通过多轮对话也可能绕过安全限制 — 谷歌已确认并修复该问题
第五类: 知名人物 / 名人 (2 月 27 日重大升级)
封锁级别: 🔴 硬性封锁 — Nano Banana 2 后更严格
这是 2026 年 2 月 27 日 Nano Banana 2 上线后变化最大的领域。
之前的限制主要针对:
- 政治人物
- 明星、名人的写实图像
Nano Banana 2 新增限制:
- 任何可识别的知名人物图像生成被更严格地封锁
- 人物换装 (给名人换衣服) 被拦截
- 人物换脸 (将名人面部替换到其他场景) 被拦截
- 即使上传名人照片进行编辑,也会被识别并拦截
典型错误信息:
"I can't generate that image. It involves a celebrity in a distorted
or exaggerated context, which isn't allowed."
"I can't complete the modification of xxx."
💡 背景说明: 2025 年末 Gemini 2.5 Flash 推出更强大的图片编辑功能后,研究者发现上传名人照片并要求"重新想象"可以绕过文本提示词的封锁。谷歌在 24 小时内修复了这个漏洞,并在 Nano Banana 2 中进一步加固了整个名人识别系统。
第六类: 金融 / 订单信息修改 (2 月 27 日新增)
封锁级别: 🟠 策略封锁 — Nano Banana 2 新增
这是 Nano Banana 2 上线后新增的封锁类别。
以下场景现在会触发安全过滤:
- 修改财务文档中的金额
- 篡改订单信息、发票内容
- 伪造银行对账单
- 修改合同中的关键数字
这类封锁基于谷歌「生成式 AI 禁止使用策略」中的欺诈和欺骗条款。虽然在公开技术文档中没有作为独立的过滤器分类出现,但在实际使用中已经被有效拦截。
第七类: 人物换装 / 换脸 (Deepfake 防范)
封锁级别: 🔴 硬性封锁
人脸替换和虚拟换装是 Deepfake 技术的核心应用场景,Gemini 对此采取严格封锁:
| 场景 | Nano Banana Pro (之前) | Nano Banana 2 (现在) |
|---|---|---|
| 给照片中人物换衣服 | 部分可用 | 大部分被拦截 |
| 将 A 的脸替换到 B 身上 | 已被封锁 | 完全封锁 |
| 名人换装编辑 | 部分可用 | 完全封锁 |
| 原创角色换装 | 通常可用 | 通常可用 |
第八类: 隐性性暗示内容 (2 月 27 日升级)
封锁级别: 🟠 策略封锁 — 检测能力大幅提升
Nano Banana 2 对隐性性暗示内容的检测能力显著增强。即使提示词中没有明显的色情关键词,但暗含性暗示的内容也会被拦截:
- 暧昧的肢体语言描述
- 暗示性的场景设定
- 诱惑性的穿着描述
- 含蓄的性暗示文案
错误信息通常为:
"I can't complete xxx modification."
"This content is not permitted."
Nano Banana 2 安全策略 时间线演进
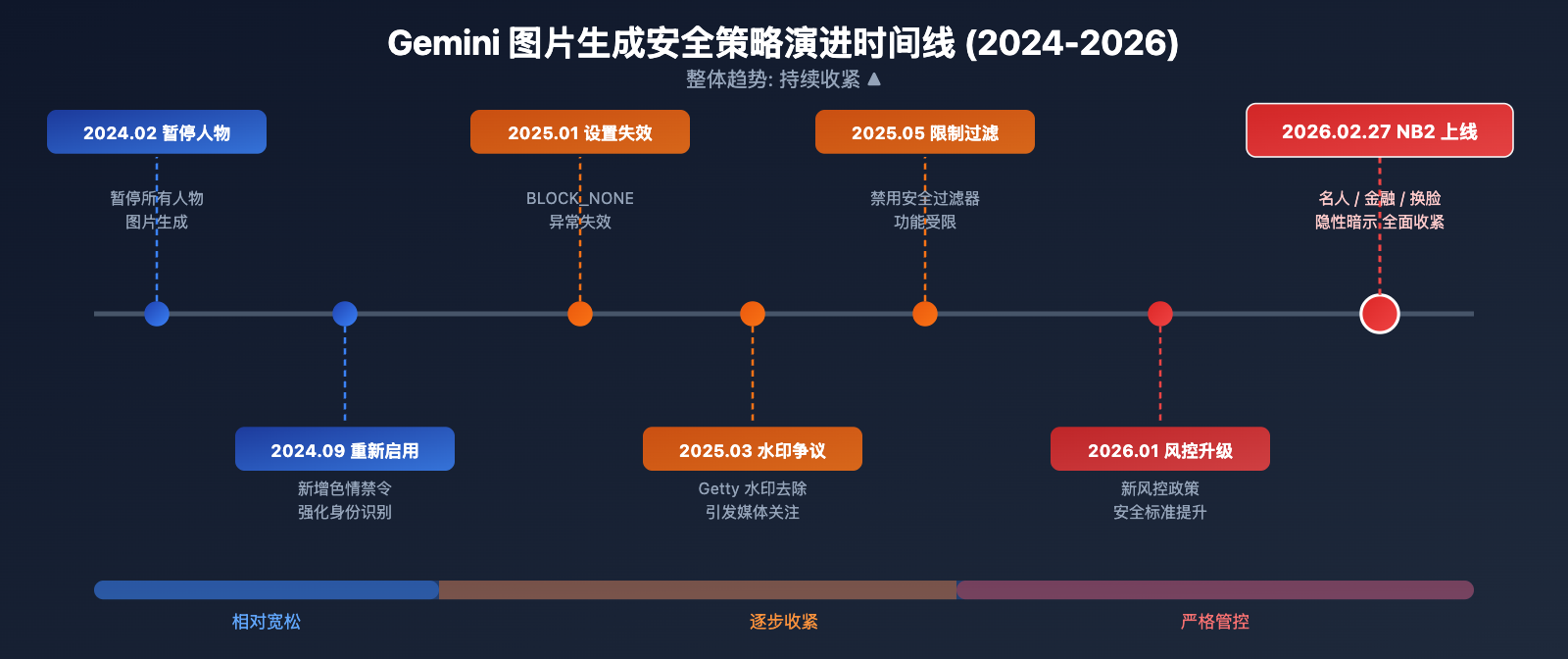
了解安全策略的演进历程有助于开发者理解当前的限制逻辑:
| 时间 | 事件 | 影响 |
|---|---|---|
| 2024 年 2 月 | 谷歌暂停 Gemini 所有人物图片生成 | 因历史人物描绘不准确引发公众争议 |
| 2024 年 9 月 | 重新启用人物图片生成 | 新增色情内容禁令,强化身份识别限制 |
| 2025 年 1 月 | BLOCK_NONE 设置失效 |
开发者报告安全设置被错误覆盖 |
| 2025 年 3 月 | 水印去除争议 | 媒体报道后谷歌加强相关封锁 |
| 2025 年 5 月 | 限制禁用安全过滤器 | 部分配置下无法再使用 BLOCK_NONE |
| 2025 年末 | Deepfake 漏洞曝光 | 上传照片绕过文本封锁被修复 |
| 2026 年 1 月 23 日 | 谷歌调整新风控政策 | 整体安全标准再次提升 |
| 2026 年 2 月 27 日 | Nano Banana 2 上线 | 名人、金融、换脸、隐性暗示全面收紧 |
整体趋势: 谷歌从 2024 年到 2026 年一直在 持续收紧 安全限制,这个趋势短期内不会逆转。
Nano Banana 2 出图失败 API 错误码解读
当 Nano Banana 2 安全过滤器拦截图片生成时,API 会返回特定的 finishReason 值。正确理解这些错误码是排查问题的第一步。
| finishReason | 含义 | 触发层级 | 可否通过配置解决 |
|---|---|---|---|
SAFETY |
命中可配置安全分类阈值 | Layer 1 | ✅ 可调整 safetySettings |
IMAGE_SAFETY |
生成后图片内容不合规 | Layer 2 | ❌ 无法配置 |
PROHIBITED_CONTENT |
违反禁止内容策略 (IP/版权) | Layer 2 | ❌ 无法配置 |
OTHER |
未明确分类的封锁 (通常是 IP 相关) | Layer 2 | ❌ 无法配置 |
出图失败排查流程
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 通过 API易 统一接口调用
)
try:
response = client.images.generate(
model="nano-banana-2",
prompt="your prompt here",
n=1,
size="1024x1024"
)
# 成功获取图片
print(response.data[0].url)
except Exception as e:
error_msg = str(e)
# 根据错误信息判断封锁类型
if "SAFETY" in error_msg:
print("Layer 1 安全过滤: 尝试调整 safetySettings")
elif "PROHIBITED_CONTENT" in error_msg:
print("Layer 2 禁止内容: 可能涉及版权 IP")
elif "IMAGE_SAFETY" in error_msg:
print("Layer 2 图片安全: 生成内容不合规")
else:
print(f"其他错误: {error_msg}")
查看 Gemini 原生 API 调用示例 (含安全设置)
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# 配置安全设置 — 注意: 这只影响 Layer 1
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_ONLY_HIGH"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_ONLY_HIGH"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_ONLY_HIGH"
}
]
model = genai.GenerativeModel(
model_name="gemini-2.0-flash-exp",
safety_settings=safety_settings
)
response = model.generate_content(
"Generate an image of a sunset over mountains"
)
# 检查安全过滤结果
if response.candidates:
candidate = response.candidates[0]
print(f"Finish Reason: {candidate.finish_reason}")
if candidate.safety_ratings:
for rating in candidate.safety_ratings:
print(f" {rating.category}: {rating.probability}")
🚀 快速排查建议: 如果您遇到状态码 200 但没有返回图片的情况,这确实是谷歌安全过滤器的拦截结果。通过 API易 apiyi.com 平台调用时,我们作为透明代理直接转发谷歌的原始响应,不做任何额外拦截 — 我们当然希望每位客户都能成功出图。
Nano Banana 2 内容安全 SynthID 隐形水印机制
除了输入端和输出端的安全过滤,谷歌还在所有 Gemini 生成的图片中嵌入了 SynthID 隐形水印:
| 特性 | 说明 |
|---|---|
| 嵌入方式 | 像素级隐形水印,肉眼不可见 |
| 抗干扰性 | 裁剪、缩放、调色、截图后依然有效 |
| 去除难度 | 去除水印会显著降低图片质量 |
| 适用范围 | 所有 Gemini 生成的图片,无论付费层级 |
| 验证方式 | 第三方可通过 SynthID 验证图片是否为 AI 生成 |
值得注意的矛盾: 谷歌在自己生成的图片上打上不可去除的水印,但其模型又曾被发现可以去除他人图片上的水印 — 这个不对称性在 2025 年 3 月引发了广泛讨论。
Nano Banana 2 出图失败 应对策略
针对不同类型的出图失败,开发者可以采取不同的应对策略:
可调整的场景 (Layer 1)
如果错误码为 SAFETY,说明是 Layer 1 可配置过滤器触发的:
- 调整 safetySettings: 将相关分类阈值从
BLOCK_MEDIUM_AND_ABOVE调整为BLOCK_ONLY_HIGH - 优化提示词: 避免使用可能触发安全分类的敏感词汇
- 分步生成: 将复杂场景拆解为多个简单步骤
不可调整的场景 (Layer 2)
如果错误码为 IMAGE_SAFETY、PROHIBITED_CONTENT 或 OTHER:
- 调整创作方向: 避开名人、版权角色等敏感主题
- 使用原创角色: 自行设计角色避免 IP 冲突
- 简化场景: 减少可能触发安全检测的复杂元素
- 检查图片输入: 如果使用图生图,确保输入图片不含名人面部
C 端产品开发者的特别建议
如果你正在开发面向终端用户的产品,强烈建议:
- 前置内容审核: 在调用 API 之前对用户输入进行预过滤
- 错误友好提示: 将 API 的英文错误信息转化为用户友好的中文提示
- 重试策略: 对 Layer 1 的
SAFETY错误可以尝试调整后重试,对 Layer 2 错误不要重试 - 用量监控: 被安全过滤器拦截的请求仍然消耗 API 配额
💰 成本提醒: 安全过滤器拦截的请求虽然没有返回图片,但仍然会产生一定的 API 调用费用。通过 API易 apiyi.com 平台可以查看详细的调用日志,帮助优化提示词减少无效调用。
如果你正在做 C 端产品,推荐参考这篇更详细的错误处理指南: 《Gemini 3 Pro Image Preview API 错误处理指南》 xinqikeji.feishu.cn/wiki/Rslqw724YiBwlokHmRLcMVKHnRf
Nano Banana Pro vs Nano Banana 2 内容安全对比
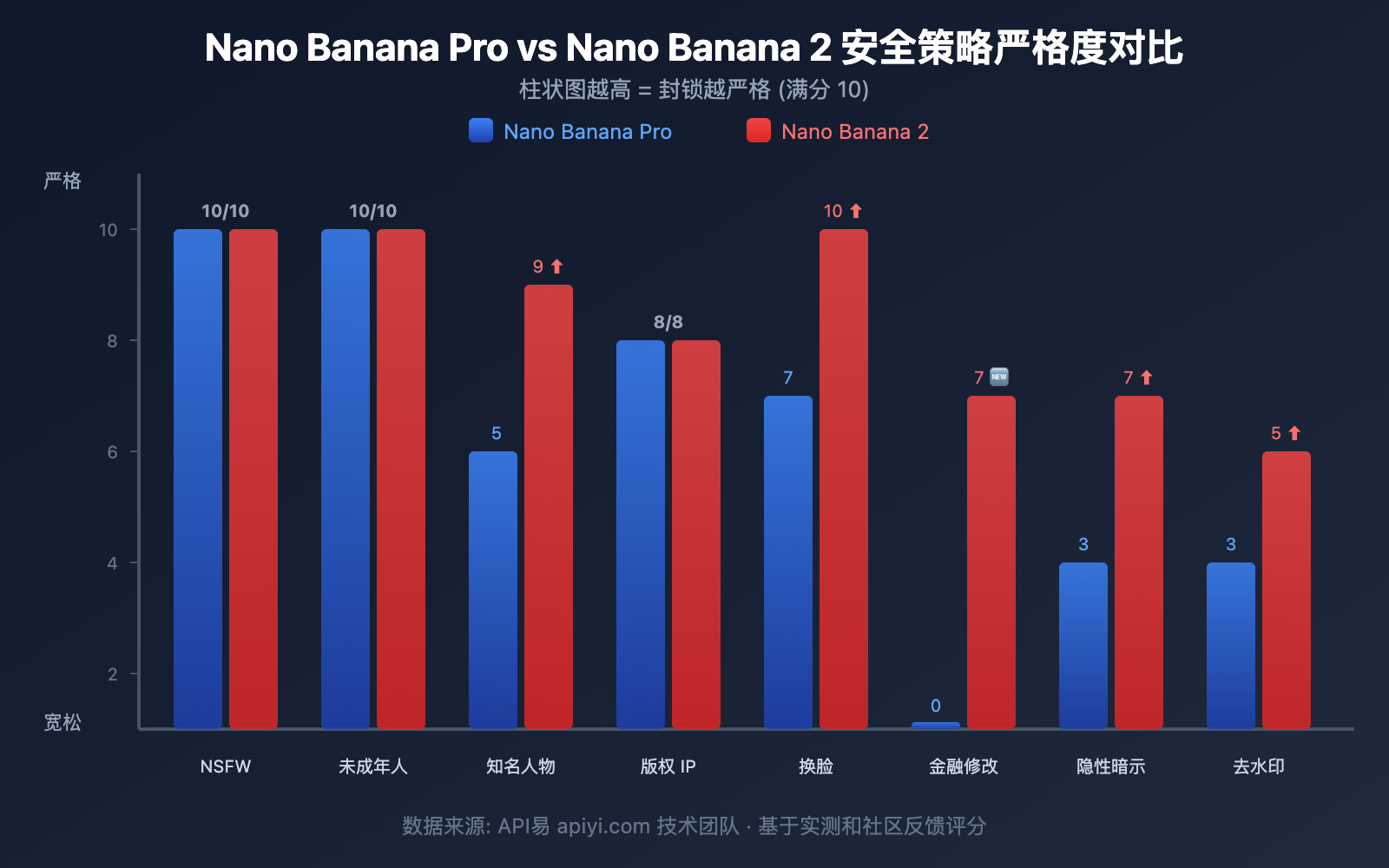
| 安全维度 | Nano Banana Pro | Nano Banana 2 | 变化 |
|---|---|---|---|
| NSFW 色情内容 | 严格封锁 | 严格封锁 | 持平 |
| 知名人物生成 | 部分封锁 | 全面封锁 | ⬆️ 大幅收紧 |
| 人物换装编辑 | 部分可用 | 大部分封锁 | ⬆️ 大幅收紧 |
| 人物换脸 | 封锁 | 完全封锁 | ⬆️ 小幅收紧 |
| 金融信息修改 | 无明确封锁 | 新增封锁 | 🆕 全新限制 |
| 隐性性暗示 | 部分检测 | 增强检测 | ⬆️ 检测能力提升 |
| 版权 IP | 封锁 | 封锁 | 持平 |
| 未成年人保护 | 绝对封锁 | 绝对封锁 | 持平 |
| 去水印 | 部分可用 | 逐步收紧 | ⬆️ 持续收紧 |
| 动漫风格误判 | 存在 | 存在 | 持平 (待改善) |
常见问题
Q1: 状态码 200 但没有返回图片,是什么原因?
状态码 200 表示 API 请求本身是成功的,但图片生成被谷歌的 Layer 2 安全过滤器拦截了。通过 API易 apiyi.com 平台调用时,我们作为透明代理直接转发谷歌的原始响应,不做任何额外限制。检查返回数据中的 finishReason 字段可以了解具体的封锁原因。
Q2: 设置了 BLOCK_NONE 为什么图片还是被封锁?
BLOCK_NONE 只能禁用 Layer 1 (可配置输入过滤) 中的概率封锁。Layer 2 (不可配置输出过滤) 的 IMAGE_SAFETY、PROHIBITED_CONTENT、CSAM 等过滤器始终生效,无法通过任何 API 参数禁用。这是谷歌的设计意图,不是 Bug。
Q3: Nano Banana 2 比 Nano Banana Pro 封锁更多内容吗?
是的。2026 年 2 月 27 日 Nano Banana 2 上线后,谷歌在知名人物、金融信息修改、人物换装/换脸、隐性性暗示四个维度显著收紧了安全策略。如果你之前使用 Nano Banana Pro 没有问题的提示词现在出图失败,很可能是这些新增限制导致的。建议通过 API易 apiyi.com 的调用日志排查具体原因。
Q4: 为什么动漫风格的图片更容易被封锁?
这是开发者社区广泛报告的问题。相同的提示词,动漫风格被封锁但写实风格通过,这似乎是安全过滤器中一个过度敏感的启发式算法。可能与动漫风格更容易触发版权 IP 检测有关。目前没有官方解释,但这确实不是有意为之的策略限制。
Q5: 如何区分是 API易 的限制还是谷歌的限制?
API易作为透明代理,直接转发谷歌的原始响应,不做任何额外的内容限制。如果出图失败,100% 是谷歌安全过滤器的反馈。API易当然希望每位客户都能成功出图。可以通过 API易 apiyi.com 平台查看详细的 API 调用日志来确认。
总结
Nano Banana 2 的内容安全机制经历了从 2024 年到 2026 年的持续演进,整体趋势是 不断收紧。对于开发者而言:
- 理解双层架构 是解决出图失败问题的基础 — Layer 1 可调,Layer 2 不可调
- 关注策略变化 — 2026 年 1 月和 2 月的两次更新带来了显著的新限制
- 优化提示词 比调整安全设置更有效 — 大部分封锁发生在 Layer 2
- 做好错误处理 — 尤其是 C 端产品,需要优雅地处理各类安全拦截
推荐通过 API易 apiyi.com 平台进行 Nano Banana 2 的 API 调用测试,该平台提供统一接口和详细的调用日志,便于快速排查出图失败的具体原因。
📝 作者: APIYI Team | API易技术团队
🔗 技术交流: 访问 apiyi.com 获取更多 AI 模型使用指南和技术支持
📅 更新日期: 2026 年 2 月 27 日